
19-21 марта в Лондоне состоялась конференция Gartner Data & Analytics Summit. Я был посетителем этого мероприятия и хочу поделиться с вами своими мыслями и наблюдениями.

Я был знаком с деятельностью компании Gartner задолго до конференции благодаря знаменитым «волшебным квадрантам» и «циклам хайпа». Отправляясь на конференцию, я сформулировал следующие личные цели:
Ожидание, что организаторы смогут меня удивить чем-то новым, сформировалось чисто умозрительно. Компания, изучающая высокотехнологичный и динамичный цифровой рынок, наверняка сама должна была демонстрировать лучшие практики этого рынка при проведении конференции.
Первое, что хочется отметить, это мобильное приложение конференции — Gartner Events Navigator. Сначала, глядя на требуемые привилегии, я не хотел его устанавливать, т.к. опасался, что не получу ничего ценного для себя (помимо того, что уже есть на сайте), но зато предоставлю очень много данных о себе сторонней компании. Но, прочитав все возможности приложения, я установил его и в итоге был очень приятно удивлен, насколько востребованным и продуманным его сделали авторы. Судите сами, в приложении вы получаете:
а) Персональный планировщик с возможностью смотреть расписание, запланировать посещение понравившихся презентаций и скачать материалы в PDF на телефон
б) Социальная сеть и чат участников
в) Схема расположения залов
г) Инструменты обратной связи
д) Рекомендательный сервис, который подберет лучшие презентации к посещению в зависимости от ваших интересов.
Я активно пользовался приложением все три дня и я думаю, со мной произошло то, о чем недавно говорили эксперты из области этики больших данных — пользователи будут охотно сами делиться своими персональными данными с приложением, если будут понимать, какую ценность получают взамен.
Второе, что хотелось бы отметить, это оцифрованность людских потоков на конференции.
Каждый участник конференции носил на себе бейдж со штрих-кодом, а на входе в каждый зал и у каждой демонстрационной будки организаторы с помощью вот такого устройства сканировали всех посетителей, проявлявших интерес именно к этой теме:

Учитывая, что каждый участник при регистрации указал достаточно профессиональной информации о себе, всего было примерно 1500 участников, а мероприятие длилось 3 дня, весь этот интернетвещей людей сгенерировал очень интересный массив данных, который, помимо непосредственного изучения, наверняка можно еще и монетизировать.
Плюс что понравилось еще — каждое выступление начиналось и заканчивалось строго вовремя, минута в минуту.
Переходя к самой конференции, нельзя не отметить сверхнасыщенную (pdf) повестку. Было несколько типов мероприятий: презентации, круглые столы и мастер-классы и выставка с более чем 50 вендорами. Нужно было заранее принять, что все 100% мероприятий посетить не получится, с самого начала нужно настраиваться на компромисс и осуществлять мучительный выбор.
Для меня интересно уже пост-фактум проанализировать статистику тем, затронутых на конференции (презентации и круглые столы):
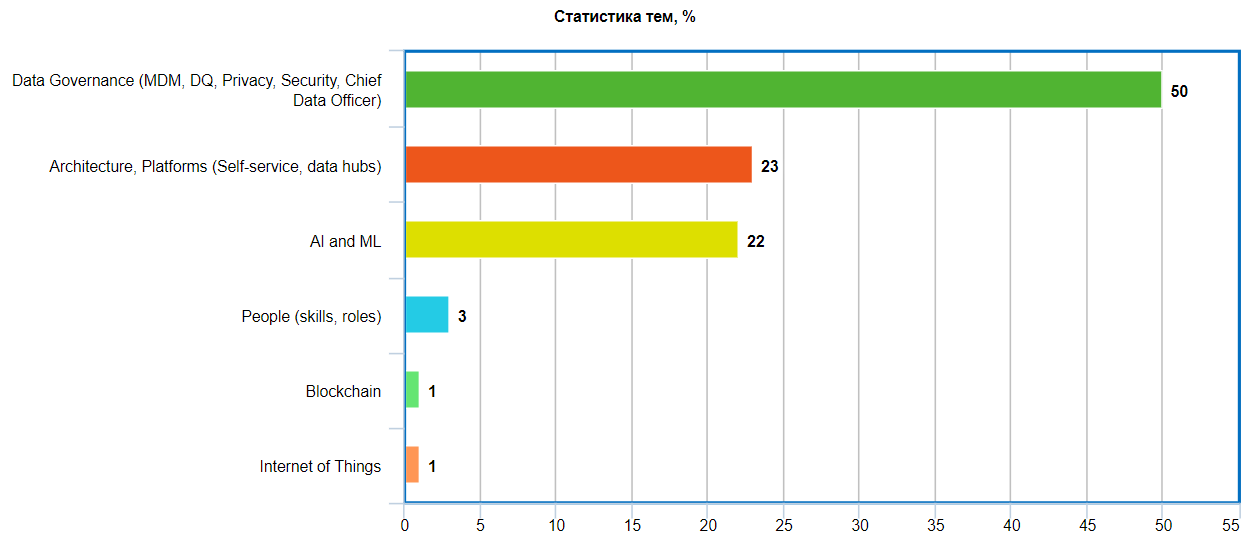
С моей точки зрения, такая диспропорция в пользу Data Governance является несколько искусственной. Мне показалось, что истинным лидером с точки зрения пользовательского интереса была тема «AI & ML», во всяком случае, мне не удалось попасть ни на один круглый стол или мастер-класс по ML по причине того, что регистрации на них уже к началу мероприятия были закрыты, в то время как на мероприятиях по Data Governance были свободные слоты.
Ниже привожу несколько тезисов/терминов/мыслей, которые запомнились мне после прошедших трех дней презентаций и докладов:
Организационная структура — наиболее распространена гибридная модель. Имеется Chief Data Officer, который подчиняется CEO или CIO. Data Scientist'ы в организации как правило бывают двух типов: при конкретной бизнес-функции или в обособленном Center of Excellence. Назначение Center of Excellence — RnD и инновационные задачи, которые нельзя отнести ни к одному из имеющихся бизнесов. За координацию Data Scientist'ов отвечает CDO. Он же определяет цели и стратегию развития.
Только 20% опрошенных посетителей имеют в своей штатной структуре роль CDO. Прогноз Gartner — к 2020 году эта цифра должна вырасти до 40-50%.
Data Lake — наиболее распространены следующие реализации:
1. Hadoop
2. Object Store (например, Amazon S3)
3. RDBMS
Data Lake не является «убийцей» Enterprise DWH, а дополняет его на корпоративном ИТ ландшафте.
Безопасность в Data Lake/Hadoop — это реальный риск, как по причине того, нет стандартных инструментов в отличие от RDBMS, так и по причине того, что практически никто не инвестирует в реализацию политик безопасности в Hadoop: аутентификацию, авторизацию, аудит.
Data Literacy (грамотность с т.з. работы с данными) — актив, в который надо инвестировать. Всего около 5% организаций могут похвастаться тем, что у них реализуются сквозные программы по повышению уровня Data Literacy на всех уровнях — от Executive Management до Junior специалистов.
Logical DWH — способ организации доступа к данным, при котором не происходит централизованного хранения данных, как, например, в DWH/Data Lake. Тем не менее, для пользователей такая организация абсолютно прозрачна, и они могут совершенно спокойно пользоваться данными, не задумываясь о том, как организован доступ к ним. (Оказывается, есть уже очень много решений на эту тему, см. ниже.)
Open Source — многие вендоры начинают делать Community версии своих коммерческих продуктов и распространять их бесплатно, таким образом, признавая состоятельность такой модели, а заодно зарабатывая лояльную базу поклонников (Однако, не все. У меня был диалог с одним вендором на тему того, как я могу попробовать их решение. Ответ был такой, что для того, чтобы они выслали мне активационные ключи, я должен написать им письмо, подписать NDA, составить договор PoC, в котором прописать критерии успешности и обязательства приобрести их продукт, если все критерии успешности будут выполнены. ?\_(?)_/? )
Помимо презентаций и докладов, которые шли в несколько потоков, в центре конференции в большом зале постоянно действовала выставочная зона, в которой можно было познакомиться поближе с представителями компаний и посмотреть демо их продуктов.
В структурированном виде вот какие компании удалось там посмотреть:
Крупные известные вендоры:
— Oracle — представляли свою облачную платформу
— Qlik — решения Self-service BI
— Tableau — решения Self-service BI
— Ataccama — решения Data Quality, Master Data Management, Data Govenance
— Google Cloud — облачная платформа
— IBM — представляли решения для Data Science: DSX & SPSS
— Attunity — решение по репликации данных / CDC
— Teradata
— SAS
— SAP
— Microstrategy
— Informatica
— Information Builders
Коммерческие сборки Hadoop:
— Cloudera
— MapR
— Hortonworks
Решения для Data Science:
— Dataiku
— Rapid Miner
— R Studio
— Angoss
Решения для Data Governance:
— Alation
— Backoffice Associates
— Collibra
— Semarchy
— Stibo Systems
Решения для Self Service BI:
— Arcadia Data
— Looker
— Sinequa
— ThoughtSpot
Софт для построения логического DWH:
— Actian
— BI Builders
— Denodo
— Domo
— Dremio
— Iguazio
— Sisense
— Snowflake
— Trifacta
— Wherescape
Это конечно же не все решения, которые были представлены, но отсмотреть их все за такое короткое время в перерывах между презентациями это почти невозможная задача, особенно если учесть, что после третьей-четвертой компании в голове все начинает смешиваться.
Кратко о выводах
Поставленные цели в общем-то достигнуты. Было получено представление о том, в каком направлении развивается рынок, какие игроки есть на нем, а также где мы сейчас находимся с точки зрения технологий (Hadoop, Data Lake, Streaming) и процессов (Governance, Security, обучение персонала итд) относительно услышанного на саммите. Эти выводы лягут в основу ближайших планов развития.
Что больше всего удивило — большое количество относительно молодых вендоров, которые целятся в сегмент «Logical DWH», и за которыми, в общем-то, не успевают гиганты. Для меня «Logical DWH» это однозначно тема, в которой предстоит разобраться более детально и углубленно.
Ну и в целом я подтвердил для себя вывод, что такие мероприятия полезны с точки зрения расширения кругозора и понимания, в каком направлении движется прогрессивное сообщество, чтобы проще было понять, куда развиваться дальше.
Я был знаком с деятельностью компании Gartner задолго до конференции благодаря знаменитым «волшебным квадрантам» и «циклам хайпа». Отправляясь на конференцию, я сформулировал следующие личные цели:
- открыть для себя что-то новое в самой компании Gartner;
- поискать новые идеи в области работы с данными;
- ну и бонусом — поучиться искусству публичных выступлений у специалистов мирового уровня (но эта тема выходит за рамки этой статьи).
Ожидание, что организаторы смогут меня удивить чем-то новым, сформировалось чисто умозрительно. Компания, изучающая высокотехнологичный и динамичный цифровой рынок, наверняка сама должна была демонстрировать лучшие практики этого рынка при проведении конференции.
Первое, что хочется отметить, это мобильное приложение конференции — Gartner Events Navigator. Сначала, глядя на требуемые привилегии, я не хотел его устанавливать, т.к. опасался, что не получу ничего ценного для себя (помимо того, что уже есть на сайте), но зато предоставлю очень много данных о себе сторонней компании. Но, прочитав все возможности приложения, я установил его и в итоге был очень приятно удивлен, насколько востребованным и продуманным его сделали авторы. Судите сами, в приложении вы получаете:
а) Персональный планировщик с возможностью смотреть расписание, запланировать посещение понравившихся презентаций и скачать материалы в PDF на телефон
б) Социальная сеть и чат участников
в) Схема расположения залов
г) Инструменты обратной связи
д) Рекомендательный сервис, который подберет лучшие презентации к посещению в зависимости от ваших интересов.
Я активно пользовался приложением все три дня и я думаю, со мной произошло то, о чем недавно говорили эксперты из области этики больших данных — пользователи будут охотно сами делиться своими персональными данными с приложением, если будут понимать, какую ценность получают взамен.
Второе, что хотелось бы отметить, это оцифрованность людских потоков на конференции.
Каждый участник конференции носил на себе бейдж со штрих-кодом, а на входе в каждый зал и у каждой демонстрационной будки организаторы с помощью вот такого устройства сканировали всех посетителей, проявлявших интерес именно к этой теме:
Учитывая, что каждый участник при регистрации указал достаточно профессиональной информации о себе, всего было примерно 1500 участников, а мероприятие длилось 3 дня, весь этот интернет
Плюс что понравилось еще — каждое выступление начиналось и заканчивалось строго вовремя, минута в минуту.
Переходя к самой конференции, нельзя не отметить сверхнасыщенную (pdf) повестку. Было несколько типов мероприятий: презентации, круглые столы и мастер-классы и выставка с более чем 50 вендорами. Нужно было заранее принять, что все 100% мероприятий посетить не получится, с самого начала нужно настраиваться на компромисс и осуществлять мучительный выбор.
Для меня интересно уже пост-фактум проанализировать статистику тем, затронутых на конференции (презентации и круглые столы):
С моей точки зрения, такая диспропорция в пользу Data Governance является несколько искусственной. Мне показалось, что истинным лидером с точки зрения пользовательского интереса была тема «AI & ML», во всяком случае, мне не удалось попасть ни на один круглый стол или мастер-класс по ML по причине того, что регистрации на них уже к началу мероприятия были закрыты, в то время как на мероприятиях по Data Governance были свободные слоты.
Ниже привожу несколько тезисов/терминов/мыслей, которые запомнились мне после прошедших трех дней презентаций и докладов:
Организационная структура — наиболее распространена гибридная модель. Имеется Chief Data Officer, который подчиняется CEO или CIO. Data Scientist'ы в организации как правило бывают двух типов: при конкретной бизнес-функции или в обособленном Center of Excellence. Назначение Center of Excellence — RnD и инновационные задачи, которые нельзя отнести ни к одному из имеющихся бизнесов. За координацию Data Scientist'ов отвечает CDO. Он же определяет цели и стратегию развития.
Только 20% опрошенных посетителей имеют в своей штатной структуре роль CDO. Прогноз Gartner — к 2020 году эта цифра должна вырасти до 40-50%.
Data Lake — наиболее распространены следующие реализации:
1. Hadoop
2. Object Store (например, Amazon S3)
3. RDBMS
Data Lake не является «убийцей» Enterprise DWH, а дополняет его на корпоративном ИТ ландшафте.
Безопасность в Data Lake/Hadoop — это реальный риск, как по причине того, нет стандартных инструментов в отличие от RDBMS, так и по причине того, что практически никто не инвестирует в реализацию политик безопасности в Hadoop: аутентификацию, авторизацию, аудит.
Data Literacy (грамотность с т.з. работы с данными) — актив, в который надо инвестировать. Всего около 5% организаций могут похвастаться тем, что у них реализуются сквозные программы по повышению уровня Data Literacy на всех уровнях — от Executive Management до Junior специалистов.
Logical DWH — способ организации доступа к данным, при котором не происходит централизованного хранения данных, как, например, в DWH/Data Lake. Тем не менее, для пользователей такая организация абсолютно прозрачна, и они могут совершенно спокойно пользоваться данными, не задумываясь о том, как организован доступ к ним. (Оказывается, есть уже очень много решений на эту тему, см. ниже.)
Open Source — многие вендоры начинают делать Community версии своих коммерческих продуктов и распространять их бесплатно, таким образом, признавая состоятельность такой модели, а заодно зарабатывая лояльную базу поклонников (Однако, не все. У меня был диалог с одним вендором на тему того, как я могу попробовать их решение. Ответ был такой, что для того, чтобы они выслали мне активационные ключи, я должен написать им письмо, подписать NDA, составить договор PoC, в котором прописать критерии успешности и обязательства приобрести их продукт, если все критерии успешности будут выполнены. ?\_(?)_/? )
Помимо презентаций и докладов, которые шли в несколько потоков, в центре конференции в большом зале постоянно действовала выставочная зона, в которой можно было познакомиться поближе с представителями компаний и посмотреть демо их продуктов.
В структурированном виде вот какие компании удалось там посмотреть:
Крупные известные вендоры:
— Oracle — представляли свою облачную платформу
— Qlik — решения Self-service BI
— Tableau — решения Self-service BI
— Ataccama — решения Data Quality, Master Data Management, Data Govenance
— Google Cloud — облачная платформа
— IBM — представляли решения для Data Science: DSX & SPSS
— Attunity — решение по репликации данных / CDC
— Teradata
— SAS
— SAP
— Microstrategy
— Informatica
— Information Builders
Коммерческие сборки Hadoop:
— Cloudera
— MapR
— Hortonworks
Решения для Data Science:
— Dataiku
— Rapid Miner
— R Studio
— Angoss
Решения для Data Governance:
— Alation
— Backoffice Associates
— Collibra
— Semarchy
— Stibo Systems
Решения для Self Service BI:
— Arcadia Data
— Looker
— Sinequa
— ThoughtSpot
Софт для построения логического DWH:
— Actian
— BI Builders
— Denodo
— Domo
— Dremio
— Iguazio
— Sisense
— Snowflake
— Trifacta
— Wherescape
Это конечно же не все решения, которые были представлены, но отсмотреть их все за такое короткое время в перерывах между презентациями это почти невозможная задача, особенно если учесть, что после третьей-четвертой компании в голове все начинает смешиваться.
Кратко о выводах
Поставленные цели в общем-то достигнуты. Было получено представление о том, в каком направлении развивается рынок, какие игроки есть на нем, а также где мы сейчас находимся с точки зрения технологий (Hadoop, Data Lake, Streaming) и процессов (Governance, Security, обучение персонала итд) относительно услышанного на саммите. Эти выводы лягут в основу ближайших планов развития.
Что больше всего удивило — большое количество относительно молодых вендоров, которые целятся в сегмент «Logical DWH», и за которыми, в общем-то, не успевают гиганты. Для меня «Logical DWH» это однозначно тема, в которой предстоит разобраться более детально и углубленно.
Ну и в целом я подтвердил для себя вывод, что такие мероприятия полезны с точки зрения расширения кругозора и понимания, в каком направлении движется прогрессивное сообщество, чтобы проще было понять, куда развиваться дальше.
a-l-e-x
Большое спасибо.
Вы не могли бы рассказать немного подробнее и привести примеры, пожалуйста. Сначала я подумал, что это что-то типа Cisco Information Server — для data virtualisation, но Trifacta в списке софта меня несколько смущает. Ведь это просто инструмент для «начального» анализа данных и встроен в GCP Dataprep насколько я понимаю…Я не очень хорошо понял, что подразумевается под
msetkin Автор
Вы правы, я скорее всего ошибся при наборе тескта, я бы Trifacta перенес бы в раздел Self Service BI.
Logical DWH — это по сути еще одно название для data virtualisation, я почитал про Cisco Information Server (я так понял, их весь бизнес по виртуализации данных приобрела компания Tibco, которая тоже была на конференции, но я на нее не обратил внимания), да, похоже это Logical DWH в терминологии Gartner и есть.
Ключевое отличие от классического DWH заключается в том, что то место, через которое осуществляются все запросы к данным, не является физически тяжеловесным централизованным хранилищем данных, я представляет собой лишь тонкий слой метаданных (ну может еще и кэш), который знает, где в Enterprise какие данные лежат.
Причем для пользователя такая архитектура является абсолютно прозрачной, т.е. он все так же работает с данными, как до этого привык, и не замечает никакой разницы. Всю работу по прокидыванию запросов пользователя к реальным данным, хранящимся, вообще говоря, в разных технологиях, осуществляет под капотом софт этого самого Logical DWH.
И что самое главное, это может быть не просто проксирование запросов к месту хранения данных, это может быть и джойн нескольких физических источников в одном запросе на Logical DWH. То есть я, как пользователь, захожу на Logical DWH и вижу, что мне доступны «таблицы» Client и Transactions, я определяю витрину, содержащую join этих таблиц, а Logical DWH сам определяет, как бы ему пооптимальней отдать мне результат этого запроса, учитывая, что, например, история Transactions это петабайтный файл на Hadoop, а Client это 100-тысячная таблица на неком слабеньком mySQL.
Все вендоры в один голос утверждали, что их софт обработает такую ситуацию корректно, а именно, разобьет один логический запрос на два (для Hadoop и mySQL), соптимизирует каждый из запросов, отправит на источники, и потом склеит (где-то) результат и вернет его мне, причем сделает это достаточно быстро.