

О рекомендательной системе в ivi, которая занимается подбором контента на основе пользовательских интересов (внутреннее название — Hydra) мы писали тут и тут. Прошло уже много времени и код проекта значительно изменился: оффлайн часть переехала на Spark, онлайн часть адаптировалась к высоким нагрузкам, Hydra начала использовать другую рекомендательную модель — все эти изменения будут освещены в статье.
Архитектура Hydra
В далёком 2014 Hydra была создана в виде Python приложения: данные для рекомендательной модели подгружались отдельным скриптом — «оффлайн-частью» — из внешних источников (Vertica, Mongo, Postgres). Скрипт готовил user-item матрицу размерностью , где m — число пользователей в обучающей выборке, а n — размер каталога (количество уникальных единиц контента), подробнее про item-based персональные рекомендации можно почитать в статьях Сергея Николенко.
История смотрения юзера — это вектор размерности , в котором для каждого контента, с которым взаимодействовал пользователь (посмотрел, оценил), стоят единицы, остальные элементы нулевые. Так как каждый юзер взаимодействует с деcятками единиц контента, а размер каталога составляет тысячи единиц, мы получаем разреженный вектор-строку, в котором очень много нулей и матрица user-item состоит из таких векторов. Онлайн-кинотеатр ivi собирает богатый фидбэк от пользователей — просмотры контента, оценки (по десятибальной шкале), результаты онбординга (бинарные предпочтения «нравится — не нравится», вот презентация с примером от Netflix) — на этих данных и обучается модель.
Для выдачи рекомендаций использовался классический memory-based алгоритм — Hydra «запоминала» обучающую выборку и хранила матрицу пользовательских просмотров (и оценок) в памяти. С ростом аудитории сервиcа пропорционально рос и размер матрицы user-item. Архитектура рекомендательного сервиса на тот момент выглядела следующим образом:
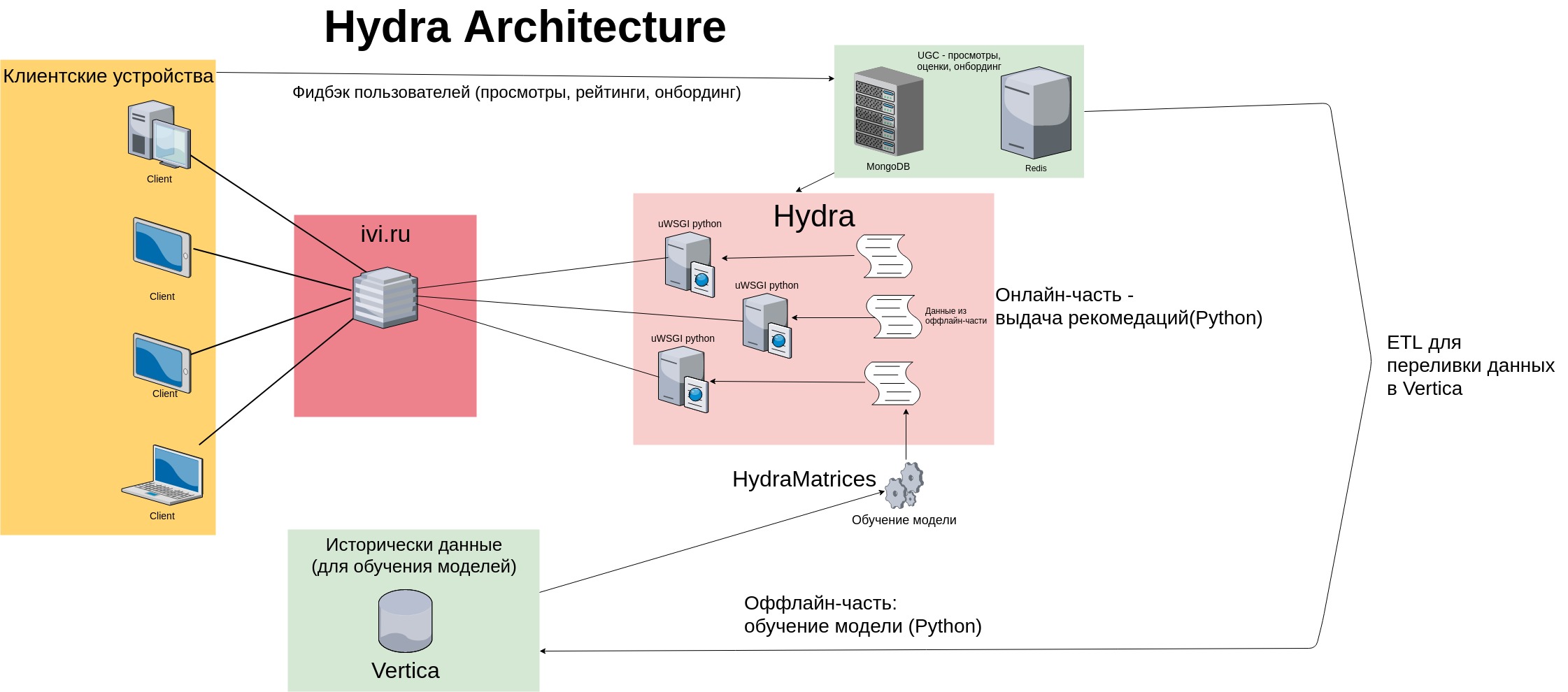
Недостатки Hydra
Как видно на схеме, фидбэк от пользователей (просмотры, оценки контента, отметки онбординга) сохраняется в быстрые key-value хранилища (MongoDB и Redis) и в Vertica — колоночное хранилище данных. В вертику данные льются инкрементально с помощью специальных ETL процедур.
Оффлайн-часть запускается ежедневно по крону: выкачивает данные, обучает модель, сохраняет её в виде текcтовых и бинарных файлов (разреженные матрицы, python-объекты в формате .pkl). Онлайн-часть формирует выдачу рекомендаций на основе модели и истории целевых действий пользователя — просмотров, оценок, покупок контента (пользовательский фидбэк читаем из Redis/Mongo). Рекомендации выдаются с помощью нескольких десятков процессов python, запущенных на каждом сервере (всего в кластере Hydra 8 серверов).
Такая архитектура порождала несколько проблем:
- Hydra — это пачка python-процессов, каждый из которых поднимает в память свой комплект файлов из оффлайн-части — это приводит к тому, что потребление памяти растёт с течением времени (размер файлов растёт вместе количеством пользователей), что затрудняет масштабирование системы. К тому же при старте сервиса каждый процесс должен считать файлы с диска — это медленно;
- пользователей становится всё больше, сбор данных начинает занимать много времени;
- Hydra была монолитным приложением: подготовка данных становилась всё более сложной, мало использовала остальные микросервисы ivi — из-за этого приходилось разрабатывать различные вспомогательные скрипты.
Hydra: revival
Система в таком виде (с постоянными доработками и улучшениями) дожила до февраля 2017 года. Время на загрузку данных в оффлайн-части росло алгоритм модели оставался неизменным. В начале 2017 мы решили переехать с memory-based рекомендательной модели на более свежий алгоритм ALS (на Coursera есть видео об этой модели).
Если коротко — алгоритм пытается представить нашу огромную разреженную user-item матрицу в виде произведения двух «плотных» матриц: матрицы пользователей и матрицы контента:
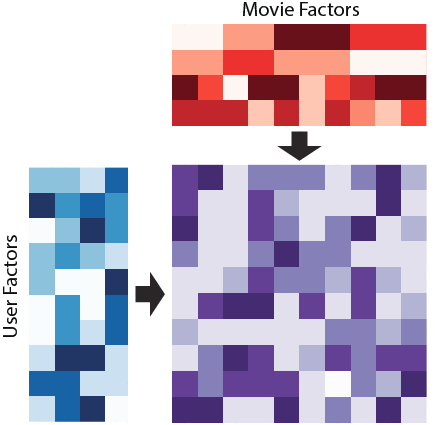
ALS позволяет обучить для каждого пользователя вектор размерности — т.н. «скрытые факторы» пользователя. Каждой единице контента соответствует вектор такой же размерности, «скрытые факторы» контента. При этом , размерность пространства скрытых факторов сильно меньше чем размер каталога, каждого пользователя описывает плотный вектор низкой размерности (обычно ).
Произведение вектора пользователя на вектор контента — это релевантность контента пользователю: чем она выше, тем больше шансов у фильма попасть в выдачу. Выхлоп ALS перемалывается в мясорубке бизнес-правил, потому что кроме задачи «показать контент, который понравится пользователю» у рекомендательной системы есть ряд задач, связанных с монетизацией контента, позиционированием сервиса и т.д. Бизнес-правила немного искажают вектор рекомендаций — этот факт нужно учитывать, например, при проведении оффлайн-оценки модели.
Новая архитектура
Была проведена большая работа по перепроектированию сервиса, результаты которой выглядят следующим образом:

- подготовку данных для обучения модели перенесли в Spark — вместо обращений к Vertica читаем из Hadoop-хранилища Hive. Вертика очень быстрая БД, но с ростом объёмов данных передавать их по сети становится долго, а Spark позволяет производить вычисления распределённо, на нодах кластера. К тому же в Spark реализована модель ALS для неявного фидбэка (модель обучается на данных о длительности просмотра контента пользователем);
- данные из оффлайн-части, которые раньше поднимал в память каждый процесc, переехали в Redis. Теперь вместо дублирования объектов в памяти, Hydra обращается к Redis-хранилищу — мы получаем один экземпляр данных для всех процессов на сервере, потребление памяти сократилось в 2 раза. Время на рестарт сервиса сократилось с получаса до 6 минут — ждать пока несколько десятков процессов прочитают данные из файлов долго, а теперь данные уже находятся в Redis, на момент рестарта Hydra всего лишь проверяет их доступность
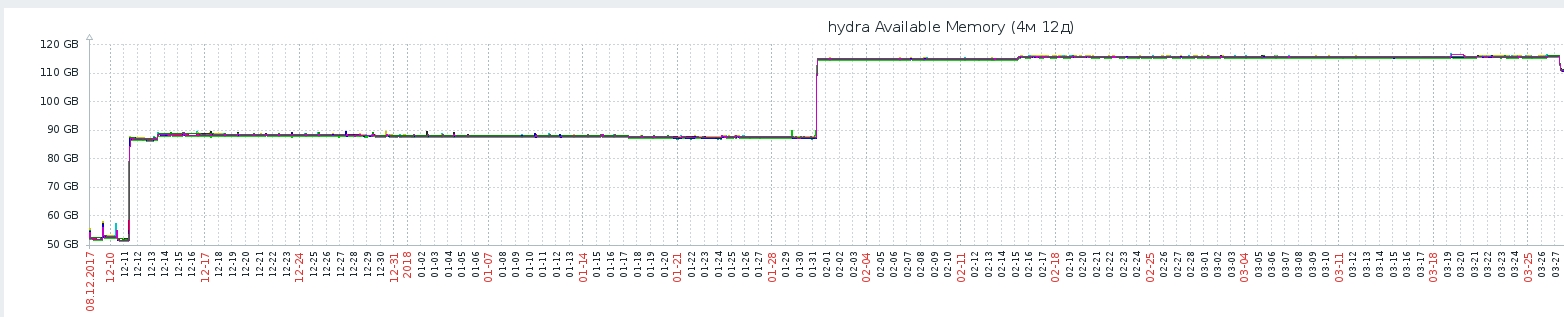
- Hydra пересчитывала рекомендации в ответ на каждый переход пользователя между экранами приложения — даже если пользователь не совершал целевых действий, которые могли бы изменить его рекомендации (посмотрел контент, поставил оценку). Производить огромное количество вычислений оказалось очень дорого по процессорным ресурсам. В глубинах метода получения рекомендаций по модели ALS мы используем немного линейной алгебры из numpy (например, numpy.linalg.solve), при этом каждый python-процесс использует несколько ядер, чтобы считать быстрее — это сильно нагружает CPU. Как видно на картинке, после внедрения рекомендательной модели ALS Response Time системы увеличивался с каждым днём (это связано с тем, что АБ-тест новой модели захватывал всё новых пользователей). Чтобы избежать линейной зависимости нагрузки от числа пользователей, была разработана система кеширования вектора рекомендаций: кеш сбрасывался (и рекомендации пересчитывались) только после нового “целевого действия” пользователя: просмотра или оценки.

- Для формирования вектора пользовательских рекомендаций начали использовать гибридную модель. Раньше в бизнес-правилах рекомендательной системы (а у нас очень много бизнес-правил) существовала т.н. “граница персонализации”: если у пользователя менее 5-ти просмотров, рекомендации представляли собой топ популярного контента, а после 5-го просмотра пользователь начинал получать персональные рекомендации — это приводило к ситуации, когда пользовательские рекомендации кардинально менялись после пятого просмотра. В новой модели при формировании рекомендаций объединяется информация о том, что популярно на сервисе в данный момент и персональные рекомендации пользователя: чем больше накопилось фидбека от пользователя, тем меньше в топе становится популярного и больше персонального — пользователь получает (немного) персонализованную выдачу уже после первого просмотра.
- На схеме есть стрелочка с клиентских приложений сразу в Hive — это данные из системы событийной аналитики groot, данные из которой (пользовательские клики, локальное время клиентского приложения) Hydra начала использовать более активно: например, мы проводили тесты контекстно-зависимых рекомендаций, когда для одного и того же пользователя вектор рекомендаций адаптировался под контекст — например, время просмотра (утро или вечер, будни или выходные).
- Раньше результатом работы оффлайн-части была пачка файлов, которые поднимались каждым процессом Hydra в память в момент рестарта сервиса. Теперь данные попадают в Redis из оффлайн-части напрямую, минуя промежуточные файлы. Такая схема сильно ускоряет рестарт сервиса — не нужно ничего читать с диска, данные уже находятся в памяти и готовы для использования.
Заключение
Hydra за год сильно изменилась как в архитектурном плане, так и в алгоритмической части. Более подробно об этих изменениях будет рассказано в цикле статей.
Комментарии (6)

YetAnotherSlava
24.04.2018 15:09Обычно под организацией «Гидра» понимается что-то совсем другое, хоть и близкое — с поставщиками, рекомендациями…
achekalin
24.04.2018 21:36Обычные рекомендаторы страдают от:
- Неверного понимания интересов человека. Скажем, человек ищет все фильмы с Сигалом — это машине понятно. Но найти все, где сюжет интереснее тупого голливудского "шел хороший, увидел плохого, добро победило" — тут никак.
- Плохого тегирования даже имеющегося контента. Кино, где есть и тайна, и поцелуи, и погоня, пойдет в рубрики детектив, экшен, боевик, мелодрама, может ещё комедия — а это делает рекомендации неэффективными изначально.
- Попыток рекомендаций на основе названий. Это вообще клиника.
Как с этим у вас?
nikolay_karelin
25.04.2018 19:51Если я ничего ни путаю, то у автора идет рекомендация по принципу "подскажи, что еще смотрят люди, которые смотрят тоже, что и я" (на основе user-item матрицы). Содержание или описание фильма систему рекомендаций особо не интересуют.
achekalin
25.04.2018 19:55Идея хороша, но чтобы она давала плоды, другие должны смотреть адекватно выбрамюнные фильмы. А если в системе все без мысли в голове, то рекомендации будут лишь инфошумом.
Что и имеем сегодня почти во всех рекомендаторах. Работает либо модель с тегами (умно расставленными), либо принимать во внимание только мнения доверенных людей.
Иначе получаем те же "Ответы Мейл ру".Dju Автор
26.04.2018 07:45Мощь рекомендательных систем,, основанных на методах коллаборативной фильтрации, как раз в способности отфильтровывать «информационный шум» и вылавливать ценную информацию о взаимосвязях между фильмами среди десятков миллионов пользовательских просмотров. Теги в ivi, конечно, используются — но работают они только на ранних этапах, когда контент недавно появился на сервисе и не успел набрать статистику. С ростом числа просмотров рекомендательный движок начинает понимать, какой аудитории предложить данный контент.
DenimTornado