
1. Введение
Распределение случайных величин описывается функцией Гаусса, что предполагает наличие связи между отсутствием взаимной корреляции случайных величин и математическим свойством самой функции Гаусса, которое определяется в данном вычислительном методе. В отношении негауссовых данных используется термин качественные данные в нечисловой статистике [1]. Если к гауссовым данным допустимо применять количественное сравнение с привлечением среднего значения, то к негауссовым данным такой подход неприменим, что оставляет возможным лишь качественный анализ, который во многих случаях является неоднозначным, трудоемким и часто экспертным. При этом такие данные широко распространены, а задача их анализа является актуальной для многих областей науки.
Далее представлен вычислительный метод, преобразующий исходные негауссовы данные в гауссовы, что позволяет в дальнейшем сравнивать количественно структурные характеристики больших наборов данных.
2. Вычислительный метод
Преобразованное значение негауссовых данных, допускающее количественное сравнение, должно быть инвариантно относительно любых линейных преобразований значений исходных данных [1]. Задача имеет решение только для упорядоченных странных данных и с учётом окрестности, в которой проявляется нелинейность. Как показано в работе, преобразование должно обладать ренормгрупповой инвариантностью в отношении размера окрестности, в которой происходит количественное сравнение проявлений нелинейности.
Далее приводятся ключевые шаги вывода формулы отношения сигнала к шуму, допускающего количественное сравнение. Фрактал пыль Кантора или геометрическая прогрессия с произвольным значением 0<q<1 (в классическом фрактале множества Кантора q=2/3) имеет вид:
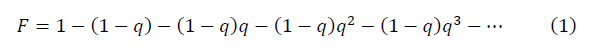
Предлагается следующий способ построения фрактального многообразия. Фрактальное многообразие для n=5 произвольного набора пяти упорядоченных чисел
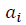 имеет вид:
имеет вид: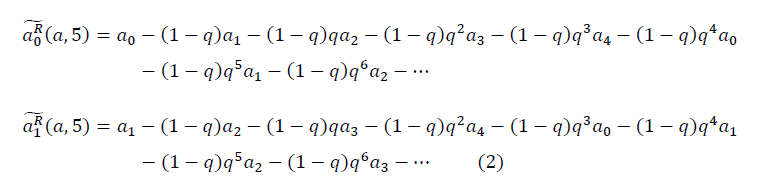
С каждым фрактальным циклом m, где m>?, появляется новое число
из выборки негауссовых данных n и далее по замкнутому контуру. Различается левое и правое направление обхода контура. В общем виде: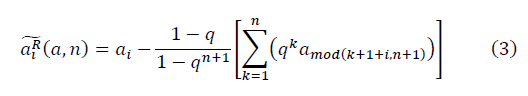
Аналогично для
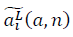 получается:
получается: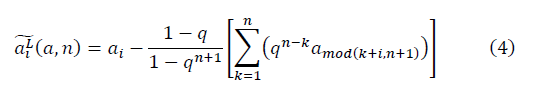
Здесь и далее формулы в обозначении Mathcad.
Множества
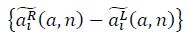 и
и 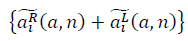 образуют фрактальные многообразия. Определяется выражение для отношения сигнала к шуму:
образуют фрактальные многообразия. Определяется выражение для отношения сигнала к шуму: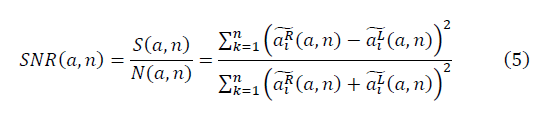
Уникальность функций Гаусса, Бесселя состоит в том, что отношение сигнала к шуму SNR в определении (5) не зависит от значения n. При аппроксимации данных функциями Бесселя коллективный эффект не проявляется.
При моделировании негауссовых данных полуволной
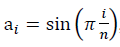 , что применяется в расчётах с предварительной аппроксимацией данных конечным рядом Фурье, для достаточно больших значений n выражение отношения сигнала к шуму имеет вид:
, что применяется в расчётах с предварительной аппроксимацией данных конечным рядом Фурье, для достаточно больших значений n выражение отношения сигнала к шуму имеет вид: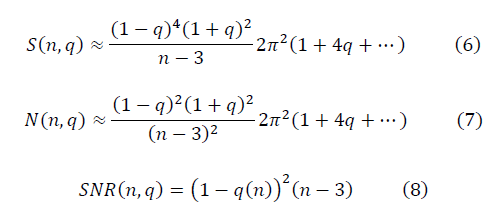
Потребуем выполнение условия ренормгрупповой инвариантности SNR(n,q), приближающее странные данные к гауссовым: при изменении n>n' происходит преобразование q>q', оставляющее значение SNR(n,q) (8) неизменным в методе ренормализационной группы [2]. Требование ренормгрупповой инвариантности выполняется при условии:
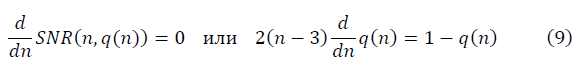
Решение дифференциального уравнения имеет вид:
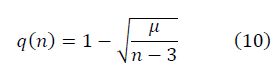
Выбор постоянной величины ? задаёт масштаб отношения сигнала к шуму.
Для больших значений n, асимптотики параметров длины фрактальных многообразий
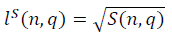 и
и 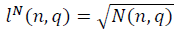 в модели полуволны
в модели полуволны 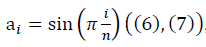 , с учётом ренормгруппового уравнения для q(n) (10) имеют вид:
, с учётом ренормгруппового уравнения для q(n) (10) имеют вид: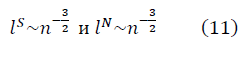
Хаусдорфова фрактальная размерность по Колмогорову [3] для фрактальных многообразий, построенных с учётом направления обхода замкнутого контура из n чисел:
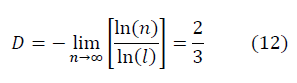
Среднее как для гауссовых чисел:
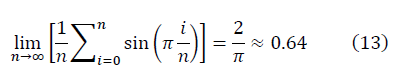
отличается от среднего по Колмогорову для D=2/3
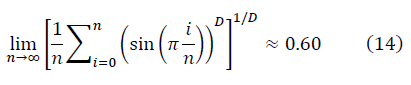
В качестве иллюстрации метода фрактального многообразия приводятся вычисления для биномиальных коэффициентов, близких к гауссову множеству, нормированных на асимптотику:
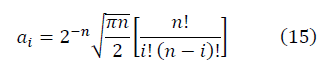
Для достаточно больших значений n выражение отношения сигнала к шуму имеет вид:
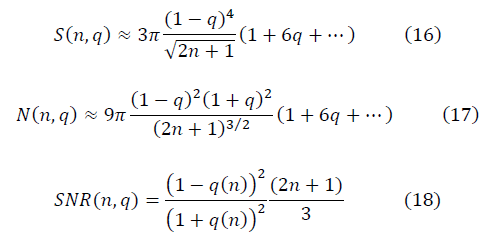
Ренормгрупповое уравнение для q(n):
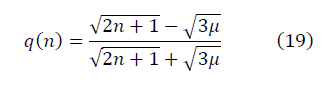
Фрактальная размерность для нормированных биномиальных коэффициентов D=4/5.
Выбор среднего для негауссовых данных как для гауссовых чисел часто применяемый в расчётах, не является однозначным [1]. Не только само значение среднего, но и вид формулы для вычисления среднего значения определяется странными данными. Метод фрактального многообразия позволяет точнее определить такую известную характеристику структуры как среднее значение, используя в качестве инструмента более мелкий масштаб
 , по сравнению с евклидовым масштабом
, по сравнению с евклидовым масштабом 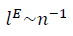 и выявить качественно новую структурную характеристику – степень взаимной корреляции данных или степень коллективного состояния данных, определяемой SNR.
и выявить качественно новую структурную характеристику – степень взаимной корреляции данных или степень коллективного состояния данных, определяемой SNR. Таким образом, появление зависимости SNR от числа выборки n для негауссовых данных объясняется наличием взаимной корреляцией негауссовых данных. Внедрение параметра q фрактала пыль Кантора и применение метода ренормгрупповой инвариантности в отношении SNR позволяет перейти к традиционному анализу гауссовых данных – степени корреляции данных в определении SNR(5).
Проводятся предварительные вычисления при q=0 по формулам (24)-(26). На предварительном этапе расчётов, при сравнении различных наборов упорядоченных данных, получаются критические размеры дескрипторов n(кр1), n(кр2) обеспечивающие максимальные коллективные состояния в наборах данных. Тогда принимается значение
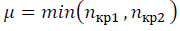 -3 в формуле (10) и уточняется значение
-3 в формуле (10) и уточняется значение 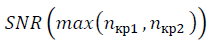 с учётом ренормгрупповой инвариантности (20)-(23). Сравнение значений SNR разных наборов данных является корректным при вычислении, выполненном в одном масштабе ?. Пиковые значения
с учётом ренормгрупповой инвариантности (20)-(23). Сравнение значений SNR разных наборов данных является корректным при вычислении, выполненном в одном масштабе ?. Пиковые значения 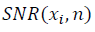 характеризуют наличие структуры в данных переменной x, обозначают окрестность коллективного состояния. Понятие критического или коллективного состояния характерно в подходе странной кинетики, обозначая кластер степеней свободы с сильной корреляцией. Поведение системы в окрестности коллективного состояния носит универсальный характер и не зависит от природы взаимодействия, вызывающего корреляцию [5], как и универсальность распределения случайных величин в отсутствии взаимной корреляции.
характеризуют наличие структуры в данных переменной x, обозначают окрестность коллективного состояния. Понятие критического или коллективного состояния характерно в подходе странной кинетики, обозначая кластер степеней свободы с сильной корреляцией. Поведение системы в окрестности коллективного состояния носит универсальный характер и не зависит от природы взаимодействия, вызывающего корреляцию [5], как и универсальность распределения случайных величин в отсутствии взаимной корреляции. Параметры аппроксимации конечного ряда Фурье и размер дескриптора n при прохождении упорядоченных данных с единичным шагом определяются из условия максимума целевой функции – максимального коллективного состояния в системе.
В матричном виде ренорм-инвариантные формулы для отношения сигнала к шуму имеют вид:
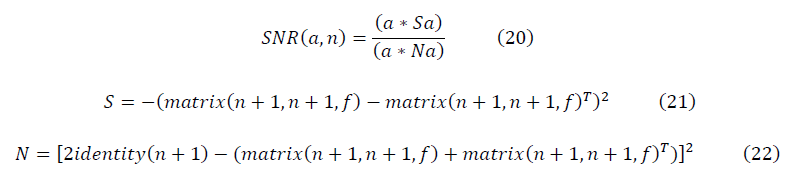
где
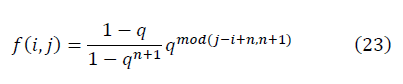
Результаты вычислений по формулам (11)-(14) эквивалентны результатам исходных вычислений по формулам (3)-(5), при этом позволяют составление алгоритма.
В расчётах из K=n/2+1 уникальных упорядоченных данных спектра строится симметричный вектор:
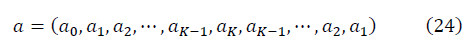
Для достаточно больших K, когда выполняется условие ренормгрупповой инвариантности, и q=0, с учётом симметрии матриц S и N, формулы для отношения сигнала к шуму приобретают вид:
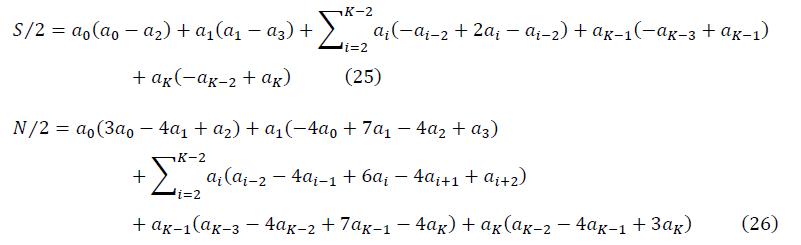
При сопоставлении значений SNR со шкалой упорядочивания, шкала сдвигается влево на размер дескриптора K. Упорядоченный набор данных, с предварительной аппроксимацией конечным рядом Фурье k, проходят дескриптором, размером K, с единичным шагом. Вычисляется
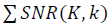 по проходу всех точек в наборе данных. Целевая функция определяется как
по проходу всех точек в наборе данных. Целевая функция определяется как 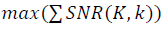 при переборе параметров K и k. Как уже отмечалось, корректное сравнение структурных характеристик SNR разных наборов данных должно осуществляться в едином масштабе ? с учётом ренормгрупповой инвариантности((20)-(23)). Подобно сравнению измерений, выполненных в сантиметрах и дюймах.
при переборе параметров K и k. Как уже отмечалось, корректное сравнение структурных характеристик SNR разных наборов данных должно осуществляться в едином масштабе ? с учётом ренормгрупповой инвариантности((20)-(23)). Подобно сравнению измерений, выполненных в сантиметрах и дюймах. Вычислительный метод применяется для больших наборов данных, полученных в хорошем разрешении, что позволяет увеличить масштаб сравнения ? с сохранением ренормгрупповой инвариантности. По порядку величин, в задаче с конформерами общее число данных в спектре рентгеноструктурного анализа – 2250 значений, оптимальный размер дескриптора для данного разрешения K=585, максимальная гармоника конечного ряда Фурье k=3.
3. Выводы
Метод применим в определении областей с сильной корреляцией степеней свободы между собой и количественном сравнении степени корреляции больших наборов упорядоченных данных. Например, когда неприменимо приближение Хартри-Фока. Интерпретация результатов обработки данных основана на построении фрактального многообразия, которое моделирует коллективное или критическое состояние [4] в одномерном пространстве. Интерпретацию усложняет неоднозначность терминологии, описывающей коллективное состояние в разных задачах.
Коллективным состоянием в химии называют гибкость или подвижность молекулярных фрагментов. Гипотеза Кошланда индуцированного соответствия при проявлении биологической активности, основанная на допущении гибкости активного центра фермента, удовлетворительно объясняет действие ферментов. При приближении субстрата к активному центру фермента, в молекуле фермента синхронно происходит конформационная перестройка, затрагивающая большое число степеней свободы. Применение вычислительного метода к спектру трёх конформеров показывает значительное увеличение коллективного эффекта у конформера, отличающегося биологической активностью. Аналогичный, с проявлением биологической активности, пример коллективного эффекта проявляется в методе термомеханической кривой для полимеров с разной молекулярной массой в области высокой эластичности.
Применение универсальной формулы преобразования к большим наборам негауссовых данным с учётом свойств инвариантности относительно любых линейных преобразований и ренормгрупповой инвариантности, делает возможным количественное сравнение коллективных состояний. Метод применяется при решении задач data science в предварительном преобразовании исходных негауссовых данных и сравнении степени взаимной корреляции данных и в поиске количественных соотношений структура – свойство.
4. Литература
- Орлов А.И. Прикладная статистика. — М.: Экзамен, 2006. — 574 с
- Боголюбов Н. Н., Ширков Д. В. Введение в теорию квантованных полей. — 4-е изд., испр. — М.: Наука Главной редакции физико-математической литературы, 1984. — 600 с.
- Колмогоров А.Н., Новый метрический инвариант транзитивных динамических систем и автоморфизмов пространств Лебега, — 1958, Доклады АН СССР, №5, С. 861 — 864
- Зелёный Л.М., Милованов А.В. Успехи физических наук, Фрактальная топология и странная кинетика: от теории перколяции к проблемам космической электродинамики, — 2004, №8, С.809 – 852
Комментарии (18)

erondondon
04.05.2018 23:08Вы бы пример реальной задачи привели и ее решение, а не теоретические выкладки.
kovserg
04.05.2018 23:40Извините конечно. Но статья лютый бред.
vladob
05.05.2018 02:22Бывает.
А можно подробнее?kovserg
05.05.2018 09:31Постановка проблемы — невнятная, мысль постоянно мечется от одного к другому, пропуская целые логические блоки. Выводы не логичны. Результаты сомнительны. Приводятся примеры не привязанные ни к чему.
То что данные можно прогнать через фильтр и так ясно. Почему сигнал aL-aR а шум aL+aR, после взвешивания сингала a с коэф сглаживающего фильтра? Зачем так усложнять, что мешает анализировать энергию сигнала или спектр энергии?
В качестве «не гаусовых» но упорядоченных данных приводится sin(k*x) или если с линейным преобразованием a[x]=A*sin(k*x)+B. Зачем много шума и оказывается длинна истории 0<q<1 определяет масштаб и её еще надо зачем-то подбирать решая какое-то уравнение. Как его составить для сигнала неизвестной природы?
Потом вдуг оказывается что еще это применялось для рентгеновского спектра, даже фигурирую какие-то цифры.
Ни примеров, ни внятного объяснения с чем борются, ни четких определений, ни последовательного изложения, даже полученный результат не понятно куда пристроили.
В общем в лучших традициях.
Vital18 Автор
05.05.2018 16:19Тема сложная.
Распределение случайных чисел описывается функцией Гаусса. Если же между данными существенна корреляция (негауссовы данные), тогда применяется метод фрактального многообразия.
Основной результат работы – найден критерий (SNR) отличающий Функцию Гаусса от других функций.kovserg
05.05.2018 16:52Есть центральная предельная теорема. Если же у вас величины коррелируют между собой, то учитывайте эту связь. Причем тут фракталы?
Вот основной результат-то и не очевиден. Почему именно такой SNR как он отличает случайную величину распределённую нормально, от других распределений.
Почему просто не построить распределение и не сравнивать его форму?Vital18 Автор
05.05.2018 17:17Таким образом определённый SNR не зависит от числа выборки n для функции Гаусса, а уже для полуволны и других функций появляется зависимость от n.
Фрактальное многообразие понадобилось для построения этого критерия отличия. Должен признаться, что способ выглядит экзотическим.
Конечно, лучше на конкретном примере показать работу метода. Мог бы оттолкнуться от задач посетителей. У меня были данные ИК-спектров, рентгеноструктурного анализа (это не картинки, а наборы числовых данных), координаты графического планшета в задаче верификации подписей.Hedgehogues
06.05.2018 23:44А про верификацию подписей можно поподробнее? Я занимаюсь смежной темой. Мне нужно выцепить подписи из доков. Эта тема аще не проработана. Все предполагают, что уже есть готовая подпись, хорошего качества. Хотя на практике это не так.
Vital18 Автор
07.05.2018 03:53Скорее всего, у Вас подписи на бумаге, работа с растровой графикой. Действительно, это очень сложная задача. И как долго ещё будут бумажные технологии?
Предлагаемый метод работает в векторной графике, когда подпись выполнена на графическом планшете.
vladob
07.05.2018 05:24Ну… У меня есть знакомые — «чистые математики» — у них часто так. Но мысль, случается, бУдят, как декабристы Герцена.
vladob
05.05.2018 01:10Спасибо за статью.
Несколько практических вопросов.
Я допускаю, что что-нить пропустил в тексте.
Если можно ответить ответ в простых словах.
1. Переменные с двумя состояниями — это упорядоченные, они сюда подходят? Есть ли смысл делать это с ними? И если есть — то какой?
2. Как и на что влияет объем выборки?
3. Во что это выливается вычислительно?
Если есть примеры приложений — можно ссылочки?Vital18 Автор
05.05.2018 16:01Метод применялся для ИК-спектров, рентгеноструктурного анализа, в задаче верификации подписей, выполненных на графическом планшете. Возможно применение метода для верификации голоса. Проводится преобразование исходных данных.
«Переменные с двумя состояниями» — можно пояснить?
«Гауссовы наборы числовых данных» – описываются нормальным распределением, функцией Гаусса. Распределение случайных величин в отсутствии корреляции между данными описывается функцией Гаусса.vladob
07.05.2018 05:27По отсутствию ссылок на наглоязычные источники, я так понял, разъяснений можно ожидать только на родном языке, так?
А можно ли ожидать «ликбеза» по совокупности затронутых в статье понятий?
Я не понял, что здесь называется «данными». Можно аналогии на английском?
Что есть «данные» в понятии автора?
— Data set? Тогда, что такое «гаусовый» data set? А что такое он же, но «не гаусовый»? И что такое некорелированные данные?
Или тут разговор о процессах во времени и пространстве, раз уж про Фурье и прочие векторности упомянуто?..
В общем, не дайте погибнуть в невежестве или от любопытства!Vital18 Автор
07.05.2018 06:17Мой интерес к этой теме возник после получения результатов измерений, которые не подчиняются нормальному гауссовому распределению. Есть публикации Орлова по теме нечисловой статистике, показательная шкала качественных данных. На английском эту тему не нашёл.
Мы часто, не приходя в сознание, вычисляем среднеарифметическое значение от наборов данных, но это сомнительная характеристика структуры данных. Если набор данных подчиняется нормальному гауссову распределению, то между этими данными отсутствует взаимная корреляция, другими словами, это случайные величины и среднее совпадает со среднеарифметическим.
Если же существует внутренняя структура данных, некое коллективное состояние данных, то набор данных становится негауссовым или странным, т.е. не подчиняется гауссову распределению. Важный физический пример коллективного состояния это солнечные протуберанцы, что определило актуальность изучения коллективных состояний, негауссовых данных. В физике Ньютона коллективные состояния не описываются. В обзоре Зелёного-Милованова предлагается подход к описанию коллективных состояний, где ключевая роль отводится фрактальному многообразию, но примеров построения фрактального многообразия они не привели.
В нашем общении лучше опираться на конкретную задачу. Вы можете назвать свою задачу в достаточно общем виде?vladob
07.05.2018 06:57Такой задачи, данными которой я мог бы поделиться у меня нет.
А нельзя ли нам попробовать с чем-нить «общеупребимым»?
Как насчет nist к примеру?
Ну, или что -нить по вашему выбору отсюда?Vital18 Автор
07.05.2018 09:24Метод может применяться к задачам kaggle. Вначале делается SNR преобразование исходных данных. Сравнение происходит не самих исходных данных, а их преобразованных значений.
Происходит сравнение коллективных эффектов, которые содержаться в данных. Для случайных величин (в отсутствии взаимной корреляции данных) коллективный эффект отсутствует.
kovserg
А что такое «гауссовы наборы числовых данных»?
Hedgehogues
Плюсую, поясните. Вы клоните к гауссовым целым числам что ли? Но то, что Вы описываете не очень связано с их свойствами.