
Привет, Хабр!
Сегодня я расскажу вам про один из методов решения задачи pose estimation. Задача состоит в детектировании частей тела на фотографиях, а метод называется DeepPose. Этот алгоритм был предложен ребятами из гугла еще в 2014 году. Казалось бы, не так давно, но не для области глубокого обучения. С тех пор появилось много новых и более продвинутых решений, но для полного понимания необходимо знакомство с истоками.

Давайте сначала вкратце про постановку задачи. У вас есть фотографии, на которых присутствует человек (один или несколько), и хочется на этих фото разметить части тела. То есть сказать, где находятся руки, ноги, голова и так далее.
Где бы такая разметка могла пригодиться? Первое же, что приходит на ум, это видеоигры. Можно играть в свою любимую RPG, размахивая виртуальным мечом, а не кликая мышкой. Для этого достаточно уметь лишь распознавать движения ваших рук.
Конечно, есть и куда более практичные применения. Например, отслеживание того, как покупатели в магазине кладут товары себе в корзину, а иногда ставят обратно на полочку. Тогда можно автоматически отслеживать, что купил посетитель, и необходимость в кассах исчезнет. Amazon уже реализовал эту идею в своих магазинах AmazonGo.
Думаю, приведенные примеры использования уже достаточно интересны, чтобы взяться за решение задачи. Однако, если у вас есть оригинальные идеи того, где еще можно применить рассмотренные концепты, смело пишите их в комментариях.
Как решать эту задачу без нейронных сетей? Можно представить скелет человека в виде графа, где вершинами будут суставы, а ребрами — кости. А дальше придумать какую-нибудь математическую модель, которая будет описывать вероятность появления того или иного сустава в конкретном месте изображения, а также будет учитывать, насколько реалистично эти суставы расположены по отношению друг к другу. Например, чтобы ваша левая пятка не находилась на вашем же правом плече. Хотя, не исключаю того, что есть способные на это люди.
Один из вариантов такой мат. модели реализован во фреймворке pictorial structures model еще в 1973 году.
Но можно подойти к решению задачи и менее хитрым способом. Когда нам дают новую картинку, давайте просто искать в нашем исходном наборе размеченных картинок похожую и выдавать ее разметку. Если у нас изначально будет не очень много различных поз людей, то этот метод вряд ли взлетит, но, согласитесь, реализовать его не представляет труда. Для поиска похожих картинок тут обычно используют классические методы извлечения фич из области обработки изображений: HOG, дескриптор Фурье, SIFT и другие.
Есть и другие классические подходы, но здесь я не буду на них останавливаться и перейду к основной части поста.
Как вы уже могли догадаться, авторы статьи DeepPose (Alexander Toshev, Christian Szegedy) предложили своё решение с использованием глубоких нейронных сетей. Они решили рассмотреть эту задачу как задачу регрессии. То есть, для каждого сустава на фотографии нужно определить его координаты.
Далее я продолжу описание модели на более формальном языке. Но для этого необходимо ввести некоторые обозначения. Для удобства буду придерживаться нотаций авторов.
Обозначим входное изображение как , а вектор позы как , где содержит координаты -го сустава. То есть мы сейчас представляем скелет человека графом из вершин. Тогда размеченное изображение будет обозначаться как , где — наш тренировочный датасет.
Поскольку картинки могут иметь разный размер, а также люди на фотографиях могут быть представлены в разных масштабах и находиться в различных частях кадра, то было решено использовать ограничивающие области (bounding box, AABB), которые бы выделяли нужную область изображения (тело человека целиком или что-то более детальное, если нас интересует конкретная часть тела). Относительно центра такой области можно также считать нормализованные координаты внутренних точек. В самом тривиальном случае, областью может быть вся исходная картинка.
Обозначим bounding box с центром в точке , шириной и высотой тройкой чисел .
Тогда нормализованный вектор позы относительно области можно записать так
То есть мы вычли из всех координат центр нужной области, а затем поделили -координату на ширину прямоугольника, а -координату на высоту. Теперь все координаты стали лежать в интервале от до включительно.
Наконец, за обозначим обрезание исходной картинки ограничивающей областью . Тривиальный бокс, который равен исходной картинке, обозначим за .
Если мы теперь возьмем функцию ( — входное изображение, — параметры модели, — количество определяемых суставов), которая по выдает нормализованный вектор позы, то вектор позы в исходных координатах .
В качестве функции у нас выступает нейронная сеть, веса которой описываются . То есть мы подаем на вход трехканальное изображение фиксированного размера, а получаем на выходе пар координат суставов:
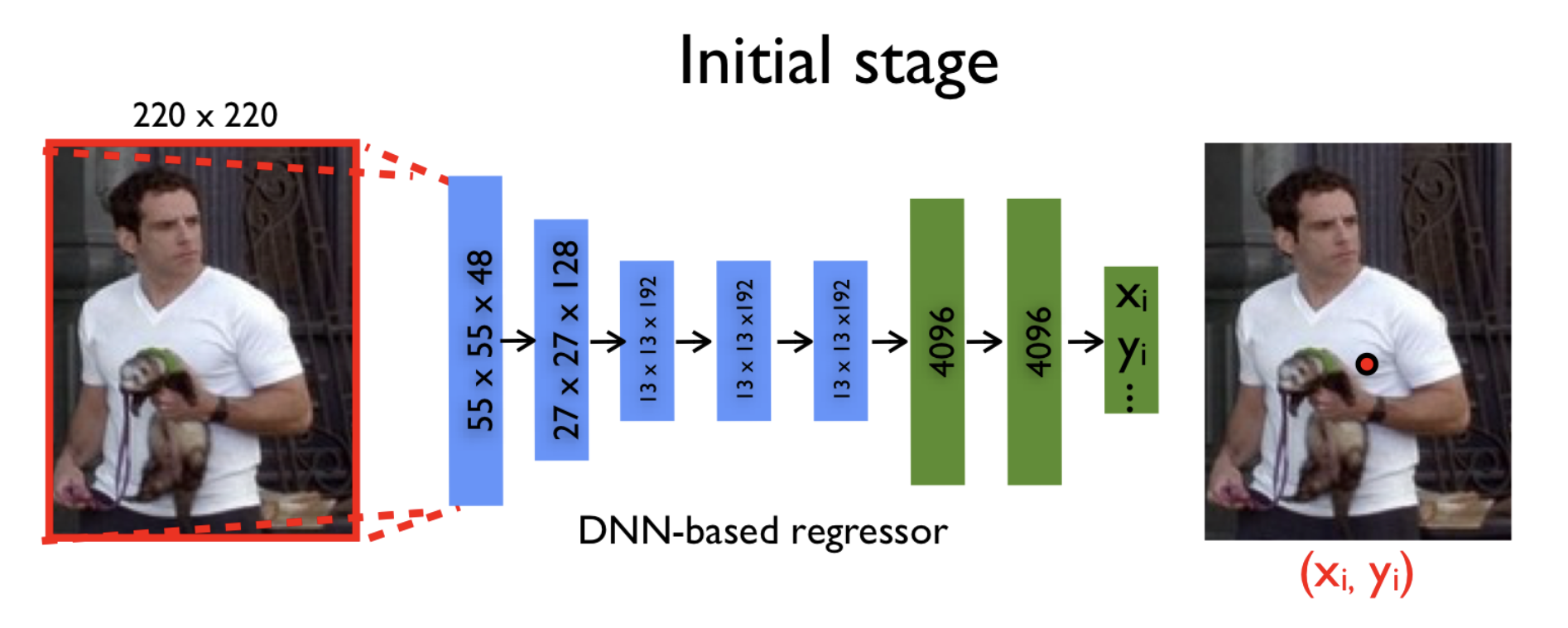
Казалось бы, уже на данном этапе мы можем взять какую-нибудь глубокую нейронную сеть (например, AlexNet, которая отлично себя показала на задаче классификации изображений, выиграв соревнование ImageNet в 2012 году), и обучить ее регрессии. Найдем такие параметры модели, чтобы минимизировать сумму квадратов отклонений предсказанных координат от истинных. То есть идеальные параметры . Таким образом, мы пытаемся восстановить исходные координаты суставов независимо друг от друга.
Однако, поскольку на вход нейронная сеть принимает картинку фиксированного размера (а именно, пикселей), часть информации теряется, если картинка изначально была в лучшем разрешении. Поэтому у модели нет возможности проанализировать все мелкие детали изображения. Модель “видит” всё в крупном масштабе и может попытаться восстановить позу лишь приблизительно.
Можно было бы просто увеличить размер входа, однако вместе с этим пришлось бы увеличить и без того немаленькое число параметров внутри сетки. Напомню, что классическая архитектура AlexNet содержит более 60 миллионов параметров! Версия модели, описанная в этой статье, — более 40 миллионов.
Компромиссом в желании подавать на вход картинку в хорошем разрешении и в необходимости сохранить адекватное число параметров стало использование каскада нейронных сетей. Что это значит? Сначала по исходной картинке, сжатой до пикселей, предсказываются приблизительные координаты суставов, а каждая последующая нейронная сеть уточняет эти координаты уже по новой картинке. Эта новая картинка — не что иное, как некоторая нужная часть предыдущей (та самая ограничивающая область вокруг предсказаний с предыдущего этапа), тоже приведенная к размеру .
Благодаря такому способу, последовательность моделей с каждым шагом наблюдает картинки все более высокого разрешения, что позволяет модели сосредоточиться на мелких деталях и поднять качество предсказаний.
Авторы используют одну и ту же архитектуру сети на каждом этапе (всего этапов ), однако обучают их отдельно. Давайте обозначим параметры сети на этапе за , а саму модель, предсказывающую координаты суставов, за .
На начальном этапе () мы используем ограничивающую область (исходную картинку полностью) для предсказания приблизительных координат суставов:
Далее, на каждой новой итерации () и для каждого сустава мы уточняем его координаты с помощью модели :
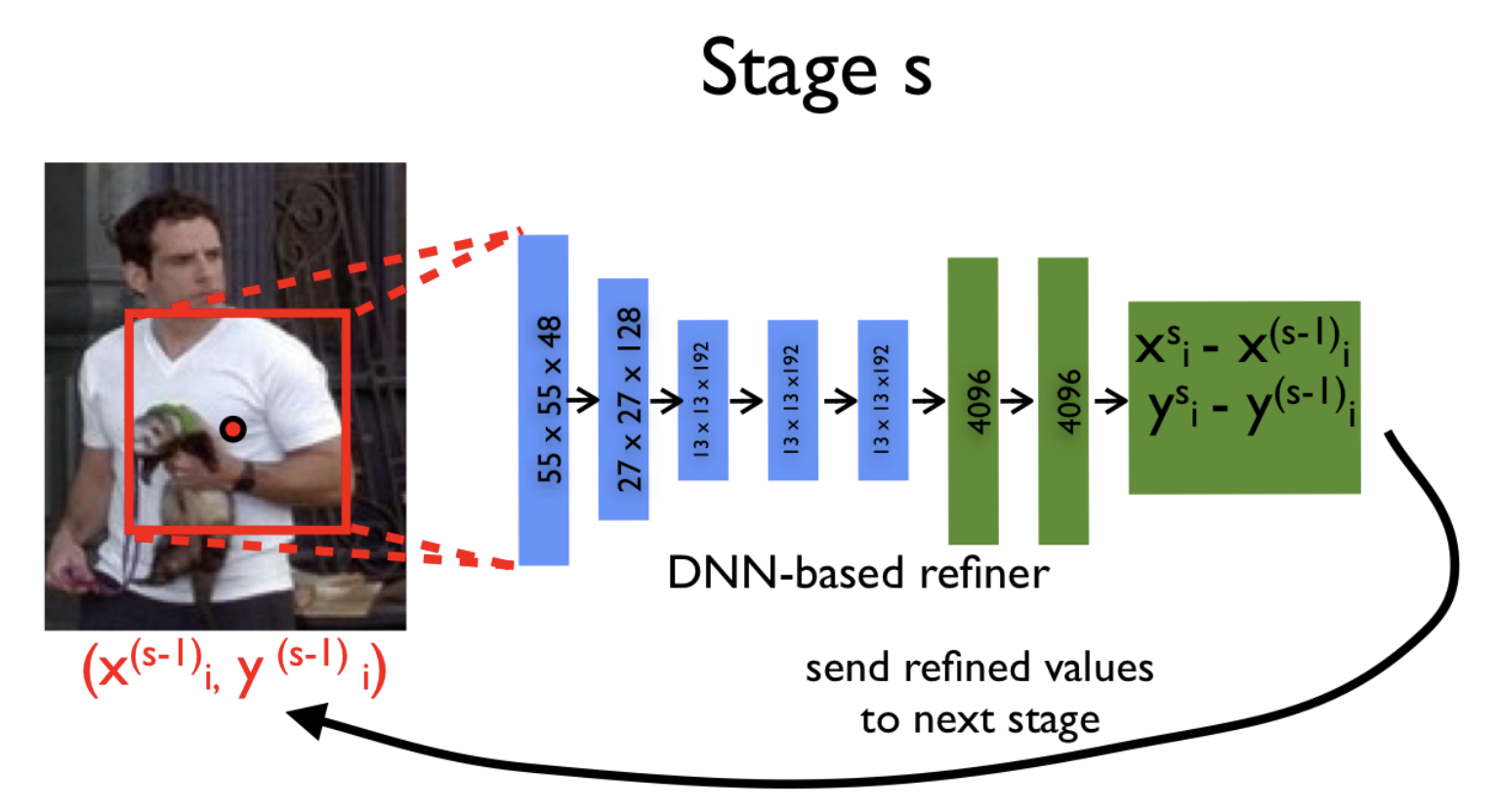
И уже теперь мы могли бы приступить к обучению такой модели, если бы не одно но. Обучение сложной нейронной сети, а тем более каскада сетей, требует большого количества сэмплов (размеченных изображений, в нашем случае). Например, AlexNet обучали на ImageNet-е, который состоит из 15 миллионов размеченных картинок размером . Но даже такой датасет Алекс и его команда увеличивали более чем в 2048 раз, путем выбора случайных подызображений меньшего размера и их зеркальных отображений.
Чтобы в рассматриваемой задаче небольшой размер датасета не стал серьезной проблемой, важно было придумать хороший способ аугментирования данных, который бы подошел для каскада сетей.
Однако и тут авторы нашли довольно изящное решение. Вместо того, чтобы использовать предсказания координат суставов только с предыдущего этапа, они предложили генерировать эти координаты самостоятельно. Это можно сделать, сместив координаты -го сустава на вектор, сгенерированный из двумерного нормального распределения со средним и дисперсией, равными среднему значению и дисперсии наблюдаемых отклонений от по всем примерам из тренировочной выборки.
Таким образом, мы моделируем работу предыдущих слоев на якобы новых картинках. Классная особенность этого метода заключается в том, что мы не ограничены сверху каким-то фиксированным количеством изображений, которые мы можем сгенерировать. Однако же, если их будет очень много, то они будут сильно похожи друг на друга, а следовательно, это перестанет приносить пользу.
Для задачи pose estimation существуют два известных открытых датасета, которые исследователи часто используют в своих научных работах:
Название этого датасета говорит само за себя. Он представляет собой 5000 аннотированных кадров из различных фильмов. Для каждой картинки нужно предсказать координаты 10 суставов.

Этот датасет состоит из фотографий людей, занимающихся спортом. Однако, не по всем фотографиям у вас сложится о нем правильное представление:
Но это скорее исключения, а типичные примеры с разметкой выглядят так:
Этот датасет содержит уже 12000 изображений. От FLIC он отличается тем, что здесь нужно предсказывать координаты 14 точек вместо 10.
Последнее, с чем нам осталось разобраться, это понять, как оценивать качество полученной разметки. Авторы статьи в своей работе использовали сразу две метрики.
Это процент корректно распознанных частей тела. Под частью тела подразумевается пара суставов, которые соединены между собой. Мы считаем, что корректно распознали часть тела, если расстояние между предсказанными и реальными координатами двух суставов не превышает половину ее длины. Как следствие, при одной и той же ошибке результат детекции будет зависеть от расстояния между суставами. Но, несмотря на этот недостаток, метрика является довольно популярной.
Для компенсации минусов первой метрики, авторы приняли решение использовать еще одну. Вместо того, чтобы считать количество правильно распознанных частей тела, было решено смотреть на количество корректно предсказанных суставов. Это избавляет нас от зависимости от размеров частей тела. Сустав считается корректно распознанным, если расстояние между предсказанными и реальными координатами не превышает значения, зависящего от размера тела на картинке.
Напомню, что вышеописанная модель состоит из этапов. Однако, мы пока так и не уточнили, как выбирается эта константа. Чтобы подобрать хорошие значения для этого и других гиперпараметров, в статье было взято 50 картинок из обоих датасетов в качестве валидационной выборки. Так авторы остановились на трех этапах (). То есть по начальному изображению мы получаем первое приближение позы, а затем дважды делаем уточнение координат.
Начиная со второго этапа, было сгенерировано по 40 изображений для каждого сустава из реального примера. Например, таким образом для LCP датасета (где предсказываем 14 различных суставов), с учетом зеркальных отображений, получается миллионов примеров! Еще стоит отметить, что для FLIC в качестве исходного bounding box использовались ограничительные прямоугольники, полученные детектирующим человека алгоритмом. Это позволяло заранее отсекать ненужные части изображения.
Первая нейросеть в каскаде обучалась приблизительно на 100 машинах в течение 3 дней. Однако утверждается, что точность, достаточно близкая к максимальной, была достигнута уже за первые 12 часов. Каждая из моделей на следующих этапах обучалась уже по 7 дней, поскольку работала с датасетом, который в 40 раз превосходил по размеру оригинальный.
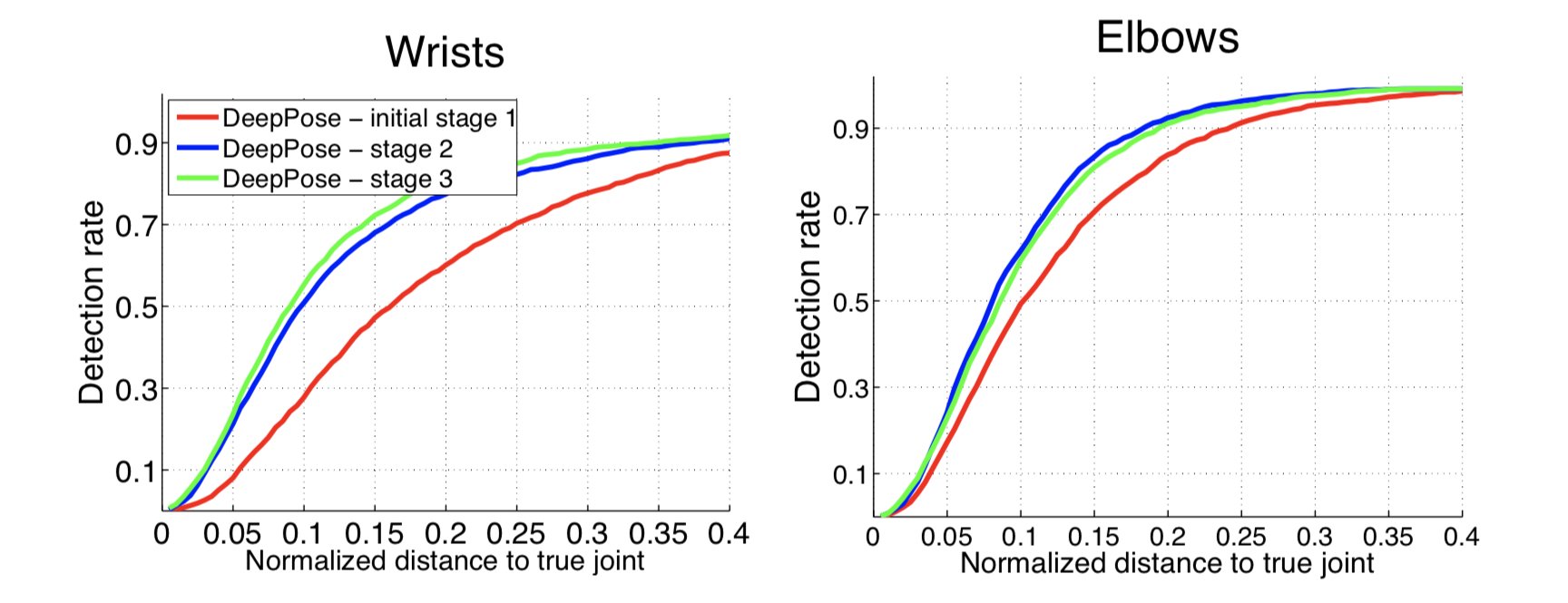
Далее на графиках можно увидеть точность распознавания кистей и локтей на разных этапах модели. По оси — значение трешхолда в метрике PDJ (если разность предсказанных и настоящих координат меньше трешхолда, считаем, что сустав определен верно). Из графиков видно, что дополнительные этапы дают существенное улучшение точности.
Интересно также посмотреть, как уточняет координаты каждая последующая нейронная сеть. На изображениях ниже зеленым цветом нарисована истинная поза, а красным — поза, предсказанная моделью.

Еще приведу сравнения результатов данной модели с другими пятью state-of-the-art алгоритмами того времени.

На мой взгляд, из интересного в этой работе можно выделить способ построения модели, где путем последовательного соединения нескольких нейронных сетей одинаковой архитектуры получилось неплохо увеличить точность. А также метод генерации дополнительных примеров с целью расширения тренировочного датасета. Считаю, что задумываться над вторым стоит всегда, когда вы работаете с ограниченным набором данных. И чем больше способов аугментации вы знаете, тем проще придете к нужному именно вам.
Пост написан совместно с avgaydashenko.
Сегодня я расскажу вам про один из методов решения задачи pose estimation. Задача состоит в детектировании частей тела на фотографиях, а метод называется DeepPose. Этот алгоритм был предложен ребятами из гугла еще в 2014 году. Казалось бы, не так давно, но не для области глубокого обучения. С тех пор появилось много новых и более продвинутых решений, но для полного понимания необходимо знакомство с истоками.
Обзор задачи
Давайте сначала вкратце про постановку задачи. У вас есть фотографии, на которых присутствует человек (один или несколько), и хочется на этих фото разметить части тела. То есть сказать, где находятся руки, ноги, голова и так далее.
Где бы такая разметка могла пригодиться? Первое же, что приходит на ум, это видеоигры. Можно играть в свою любимую RPG, размахивая виртуальным мечом, а не кликая мышкой. Для этого достаточно уметь лишь распознавать движения ваших рук.
Конечно, есть и куда более практичные применения. Например, отслеживание того, как покупатели в магазине кладут товары себе в корзину, а иногда ставят обратно на полочку. Тогда можно автоматически отслеживать, что купил посетитель, и необходимость в кассах исчезнет. Amazon уже реализовал эту идею в своих магазинах AmazonGo.
Думаю, приведенные примеры использования уже достаточно интересны, чтобы взяться за решение задачи. Однако, если у вас есть оригинальные идеи того, где еще можно применить рассмотренные концепты, смело пишите их в комментариях.
Обзор классики
Как решать эту задачу без нейронных сетей? Можно представить скелет человека в виде графа, где вершинами будут суставы, а ребрами — кости. А дальше придумать какую-нибудь математическую модель, которая будет описывать вероятность появления того или иного сустава в конкретном месте изображения, а также будет учитывать, насколько реалистично эти суставы расположены по отношению друг к другу. Например, чтобы ваша левая пятка не находилась на вашем же правом плече. Хотя, не исключаю того, что есть способные на это люди.
Один из вариантов такой мат. модели реализован во фреймворке pictorial structures model еще в 1973 году.
Но можно подойти к решению задачи и менее хитрым способом. Когда нам дают новую картинку, давайте просто искать в нашем исходном наборе размеченных картинок похожую и выдавать ее разметку. Если у нас изначально будет не очень много различных поз людей, то этот метод вряд ли взлетит, но, согласитесь, реализовать его не представляет труда. Для поиска похожих картинок тут обычно используют классические методы извлечения фич из области обработки изображений: HOG, дескриптор Фурье, SIFT и другие.
Есть и другие классические подходы, но здесь я не буду на них останавливаться и перейду к основной части поста.
Новый подход
Общая идея
Как вы уже могли догадаться, авторы статьи DeepPose (Alexander Toshev, Christian Szegedy) предложили своё решение с использованием глубоких нейронных сетей. Они решили рассмотреть эту задачу как задачу регрессии. То есть, для каждого сустава на фотографии нужно определить его координаты.
Предобработка данных
Далее я продолжу описание модели на более формальном языке. Но для этого необходимо ввести некоторые обозначения. Для удобства буду придерживаться нотаций авторов.
Обозначим входное изображение как , а вектор позы как , где содержит координаты -го сустава. То есть мы сейчас представляем скелет человека графом из вершин. Тогда размеченное изображение будет обозначаться как , где — наш тренировочный датасет.
Поскольку картинки могут иметь разный размер, а также люди на фотографиях могут быть представлены в разных масштабах и находиться в различных частях кадра, то было решено использовать ограничивающие области (bounding box, AABB), которые бы выделяли нужную область изображения (тело человека целиком или что-то более детальное, если нас интересует конкретная часть тела). Относительно центра такой области можно также считать нормализованные координаты внутренних точек. В самом тривиальном случае, областью может быть вся исходная картинка.
Обозначим bounding box с центром в точке , шириной и высотой тройкой чисел .
Тогда нормализованный вектор позы относительно области можно записать так
То есть мы вычли из всех координат центр нужной области, а затем поделили -координату на ширину прямоугольника, а -координату на высоту. Теперь все координаты стали лежать в интервале от до включительно.
Наконец, за обозначим обрезание исходной картинки ограничивающей областью . Тривиальный бокс, который равен исходной картинке, обозначим за .
Если мы теперь возьмем функцию ( — входное изображение, — параметры модели, — количество определяемых суставов), которая по выдает нормализованный вектор позы, то вектор позы в исходных координатах .
В качестве функции у нас выступает нейронная сеть, веса которой описываются . То есть мы подаем на вход трехканальное изображение фиксированного размера, а получаем на выходе пар координат суставов:
Казалось бы, уже на данном этапе мы можем взять какую-нибудь глубокую нейронную сеть (например, AlexNet, которая отлично себя показала на задаче классификации изображений, выиграв соревнование ImageNet в 2012 году), и обучить ее регрессии. Найдем такие параметры модели, чтобы минимизировать сумму квадратов отклонений предсказанных координат от истинных. То есть идеальные параметры . Таким образом, мы пытаемся восстановить исходные координаты суставов независимо друг от друга.
Каскад сетей
Однако, поскольку на вход нейронная сеть принимает картинку фиксированного размера (а именно, пикселей), часть информации теряется, если картинка изначально была в лучшем разрешении. Поэтому у модели нет возможности проанализировать все мелкие детали изображения. Модель “видит” всё в крупном масштабе и может попытаться восстановить позу лишь приблизительно.
Можно было бы просто увеличить размер входа, однако вместе с этим пришлось бы увеличить и без того немаленькое число параметров внутри сетки. Напомню, что классическая архитектура AlexNet содержит более 60 миллионов параметров! Версия модели, описанная в этой статье, — более 40 миллионов.
Компромиссом в желании подавать на вход картинку в хорошем разрешении и в необходимости сохранить адекватное число параметров стало использование каскада нейронных сетей. Что это значит? Сначала по исходной картинке, сжатой до пикселей, предсказываются приблизительные координаты суставов, а каждая последующая нейронная сеть уточняет эти координаты уже по новой картинке. Эта новая картинка — не что иное, как некоторая нужная часть предыдущей (та самая ограничивающая область вокруг предсказаний с предыдущего этапа), тоже приведенная к размеру .
Благодаря такому способу, последовательность моделей с каждым шагом наблюдает картинки все более высокого разрешения, что позволяет модели сосредоточиться на мелких деталях и поднять качество предсказаний.
Авторы используют одну и ту же архитектуру сети на каждом этапе (всего этапов ), однако обучают их отдельно. Давайте обозначим параметры сети на этапе за , а саму модель, предсказывающую координаты суставов, за .
На начальном этапе () мы используем ограничивающую область (исходную картинку полностью) для предсказания приблизительных координат суставов:
Далее, на каждой новой итерации () и для каждого сустава мы уточняем его координаты с помощью модели :
Генерация данных
И уже теперь мы могли бы приступить к обучению такой модели, если бы не одно но. Обучение сложной нейронной сети, а тем более каскада сетей, требует большого количества сэмплов (размеченных изображений, в нашем случае). Например, AlexNet обучали на ImageNet-е, который состоит из 15 миллионов размеченных картинок размером . Но даже такой датасет Алекс и его команда увеличивали более чем в 2048 раз, путем выбора случайных подызображений меньшего размера и их зеркальных отображений.
Чтобы в рассматриваемой задаче небольшой размер датасета не стал серьезной проблемой, важно было придумать хороший способ аугментирования данных, который бы подошел для каскада сетей.
Однако и тут авторы нашли довольно изящное решение. Вместо того, чтобы использовать предсказания координат суставов только с предыдущего этапа, они предложили генерировать эти координаты самостоятельно. Это можно сделать, сместив координаты -го сустава на вектор, сгенерированный из двумерного нормального распределения со средним и дисперсией, равными среднему значению и дисперсии наблюдаемых отклонений от по всем примерам из тренировочной выборки.
Таким образом, мы моделируем работу предыдущих слоев на якобы новых картинках. Классная особенность этого метода заключается в том, что мы не ограничены сверху каким-то фиксированным количеством изображений, которые мы можем сгенерировать. Однако же, если их будет очень много, то они будут сильно похожи друг на друга, а следовательно, это перестанет приносить пользу.
Датасеты
Для задачи pose estimation существуют два известных открытых датасета, которые исследователи часто используют в своих научных работах:
Frames Labeled In Cinema (FLIC)
Название этого датасета говорит само за себя. Он представляет собой 5000 аннотированных кадров из различных фильмов. Для каждой картинки нужно предсказать координаты 10 суставов.
Leeds Sports Pose Dataset (LSP)
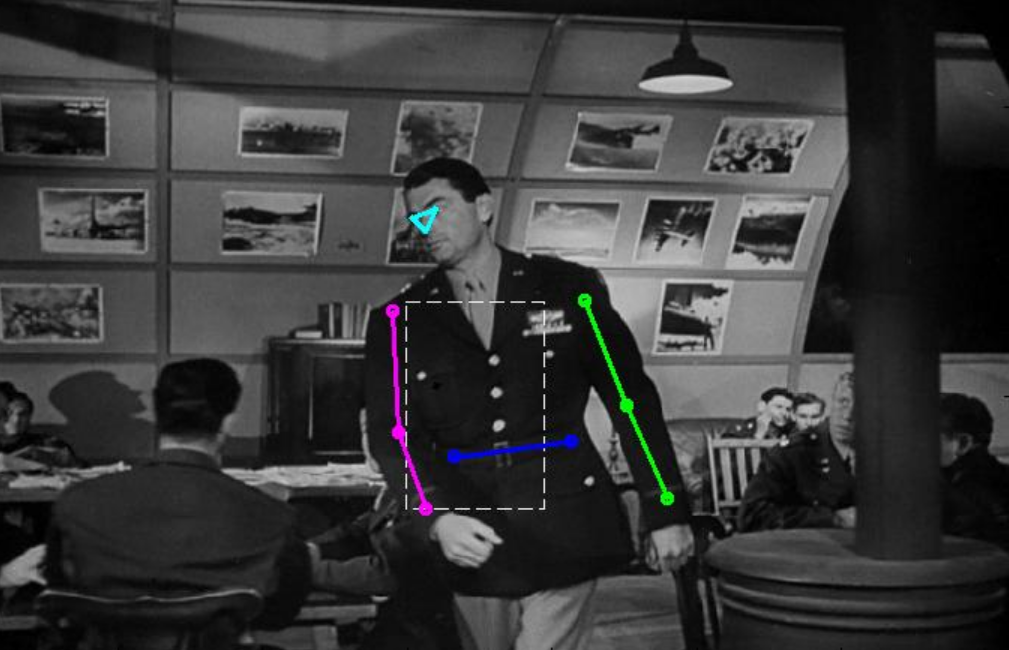
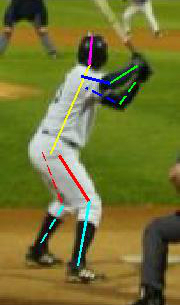
Этот датасет состоит из фотографий людей, занимающихся спортом. Однако, не по всем фотографиям у вас сложится о нем правильное представление:
 |
 |
Но это скорее исключения, а типичные примеры с разметкой выглядят так:
 |
 |
 |
Этот датасет содержит уже 12000 изображений. От FLIC он отличается тем, что здесь нужно предсказывать координаты 14 точек вместо 10.
Метрики
Последнее, с чем нам осталось разобраться, это понять, как оценивать качество полученной разметки. Авторы статьи в своей работе использовали сразу две метрики.
Percentage of Correct Parts (PCP)
Это процент корректно распознанных частей тела. Под частью тела подразумевается пара суставов, которые соединены между собой. Мы считаем, что корректно распознали часть тела, если расстояние между предсказанными и реальными координатами двух суставов не превышает половину ее длины. Как следствие, при одной и той же ошибке результат детекции будет зависеть от расстояния между суставами. Но, несмотря на этот недостаток, метрика является довольно популярной.
Percent of Detected Joints (PDJ)
Для компенсации минусов первой метрики, авторы приняли решение использовать еще одну. Вместо того, чтобы считать количество правильно распознанных частей тела, было решено смотреть на количество корректно предсказанных суставов. Это избавляет нас от зависимости от размеров частей тела. Сустав считается корректно распознанным, если расстояние между предсказанными и реальными координатами не превышает значения, зависящего от размера тела на картинке.
Эксперимент
Напомню, что вышеописанная модель состоит из этапов. Однако, мы пока так и не уточнили, как выбирается эта константа. Чтобы подобрать хорошие значения для этого и других гиперпараметров, в статье было взято 50 картинок из обоих датасетов в качестве валидационной выборки. Так авторы остановились на трех этапах (). То есть по начальному изображению мы получаем первое приближение позы, а затем дважды делаем уточнение координат.
Начиная со второго этапа, было сгенерировано по 40 изображений для каждого сустава из реального примера. Например, таким образом для LCP датасета (где предсказываем 14 различных суставов), с учетом зеркальных отображений, получается миллионов примеров! Еще стоит отметить, что для FLIC в качестве исходного bounding box использовались ограничительные прямоугольники, полученные детектирующим человека алгоритмом. Это позволяло заранее отсекать ненужные части изображения.
Первая нейросеть в каскаде обучалась приблизительно на 100 машинах в течение 3 дней. Однако утверждается, что точность, достаточно близкая к максимальной, была достигнута уже за первые 12 часов. Каждая из моделей на следующих этапах обучалась уже по 7 дней, поскольку работала с датасетом, который в 40 раз превосходил по размеру оригинальный.
Результаты
Далее на графиках можно увидеть точность распознавания кистей и локтей на разных этапах модели. По оси — значение трешхолда в метрике PDJ (если разность предсказанных и настоящих координат меньше трешхолда, считаем, что сустав определен верно). Из графиков видно, что дополнительные этапы дают существенное улучшение точности.
Интересно также посмотреть, как уточняет координаты каждая последующая нейронная сеть. На изображениях ниже зеленым цветом нарисована истинная поза, а красным — поза, предсказанная моделью.
Еще приведу сравнения результатов данной модели с другими пятью state-of-the-art алгоритмами того времени.
Выводы
На мой взгляд, из интересного в этой работе можно выделить способ построения модели, где путем последовательного соединения нескольких нейронных сетей одинаковой архитектуры получилось неплохо увеличить точность. А также метод генерации дополнительных примеров с целью расширения тренировочного датасета. Считаю, что задумываться над вторым стоит всегда, когда вы работаете с ограниченным набором данных. И чем больше способов аугментации вы знаете, тем проще придете к нужному именно вам.
Пост написан совместно с avgaydashenko.
picul
А как уточняющие сети могут уточнять положение суставов, если у них нет всей картинки? Если, например, картинки со спортсменами будут иметь разрешение UltraHD, то кусочек 220х220 в районе сустава особо полезной информации не предоставит. Или модель не рассчитана на такие данные? / Или я что-то не так понял?
Rebryk Автор
Приведу простой пример.
Изначально есть большая картинка, на которой есть маленький человечек. Он на столько маленький, что, упихнув всю картинку в 220x220, становится еле видно его ноги и руки. Нейронная сеть на первом этапе находит их, но очень примерно. Далее же, мы уже откинем здоровенную часть исходной картинки, так как будем смотреть на кусочки вокруг предсказанных координат. Поскольку исходная картинка была большой, то на новых кусочках, упиханных в 220x220, будет отчетливее видны детали человечка. Поэтому следующий слой нейронной сети сможет сделать более точные предсказания.
Вот так это работает. Стало понятнее? Если нет, то спрашивайте.
picul
В данном примере да. Но в моем примере на большой картинке есть такой же большой человечек. Не понимаю, как сети сработают в этом случае.
Ktator
Если я правильно понял, то картинка произвольного размера масштабируется до необходимых размеров.
vire
Нейронка специально этому обучалась, поэтому она может распознавать по частям тела, перекрытые объекты, объекты которые не в фас — иначе чудес не будет.
Для примера здесь процесс ручной аннотации — машина наполовину перекрыта трейлером. В нейронку при обучении попадает сама эта картинка и маска(уже с полным контуром машины).
vire
Возьмем сложные картинки и пропустим через github.com/psycharo/cpm






Как видно, если картинка человека неполная, то нейронная сеть рисует суставы в том месте, где они должны были быть — получается полная фигня, естественно)
picul
То есть модель не работает на больших картинках?
vire
Размер картинки на входе сети фиксирован и это зависит от конфигурации модели.
Здесь вход это 650x400px и такого разрешения достаточно под эту задачу.
Это значит, что сделай мы модель под ultrahd, 4k,100500k мы получим такой же результат, а зачем платить больше?
toivo61
Еще один кирпич в стену цифрового концлагеря.
Это дистанционный Бертильонаж.
vire
Да, с такой штукой можно устроить идеальную массовую слежку. Вышел из метро — камера распознала лицо, а другая камера посмотрела как ты уходишь вдаль, ну, еще и походку записала.
И все, теперь нам подойдет домофонное качество видео, чтобы определить тебя за километр по походке — с распознаванием лиц такое не сработает, а тут прям идеально)
StpMax
Интересующимся данной темой рекомендую посмотреть на проект openpose. Дает хорошие результаты в распознавании поз, лица и рук. Там же ссылка на датасет, на котором тренировалась их сеть.
BingoBongo
а не будет ли точнее решена задача, если каким-нить «edge detection»-ом отделить «тело» от фона, а потом с помощью «ridig + nonrigid image registration» совместить изображение с наиболее подходящим из уже размеченных в заранее заготовленной базе?
Rebryk Автор
Не могу знать наверняка. Однако решение, которое ищет позы в базе данных, кажется более ограниченным.
Можно погуглить, возможно кто-то ровно такое и делал.
BelBES
1) Сети куда эффективней сегментируют сцену на человек/не человек, чем edge detector’ы на традиционном зрении.
2) Параметризовать человека, а потом пытаться вписать параметрическую модель в сцену, минимизируя какую-нибудь ошибку репроекции — это так раньше делали, но trainable подходы, основаные на сетках работают лучше. Посмотрите на видосики того, как работает DensePose, «классикой» вряд ли получится такое качество получить.
vire
Видео там потрясные. Сделать такое «классическими алгоритмами» ну очень не просто.

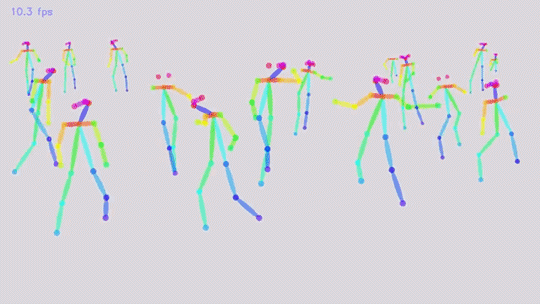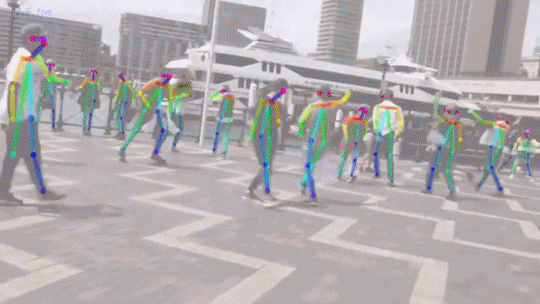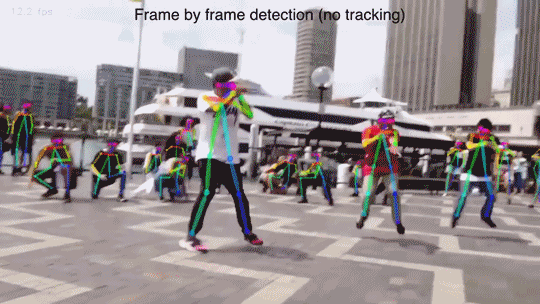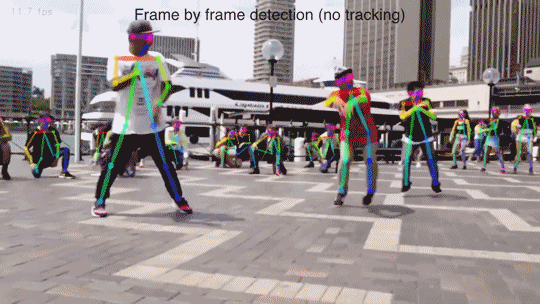
BingoBongo
я знаю рабочий подход для сегментации органов в 3D без нейросетей, но потом подумал: получается, что в 2D руки и ноги постоянно перекрывают друг друга, образуя «кашу», что делает задачу более нетривиальной.
vire
Прелесть нейронки — она за один проход найдет все объекты, и за константное время. Все что нужно — аннотированный датасет и обучить сеть.
Теперь проще нанять тыщу индусов, которые будут аннотировать картинки, чем писать алгоритмы:)
BingoBongo
в том и дело, что во время работы нейросети на результат мы получаем прелесть, а во время подготовки примеров и самого процесса обучения прелестями даже не пахнет )
vire
Это не проблема — уволить сто программистов и нанять 10 тысяч людей, которое будут тупо смотреть на картинку и нажимать три кнопки. Потом и их заменят на нейронку) Корпорации уже держат такие отделы. Получается быстрее и результат — бриллиант.
Плюс, здесь мы решаем одну задачу — pose estimation, а с алгоритмами придется решить сто адовых задач, прежде чем мы дойдем хотя бы до выяснения позы. А у нас получается, что это как бы из коробки — мы сеть заставляем распознавать позы людей обучая на фото людей и инфе о позе — вот она и распознает сходу и людей, и позы.
SGordon123
А датчик расстояния ( как в кинекте) дает что то алгоритму или он не подходит?