
В прошлый раз мы рассказывали, как доказать всем участникам проекта, что тестирование — полезная штука. Надеемся, что доводы были убедительны. Теперь можно поговорить о том, как подойти к созданию и планированию тестов, их классификации и оценке.

Эффективное распределение тестов с точки зрения их автоматизации можно представить в виде пирамиды.
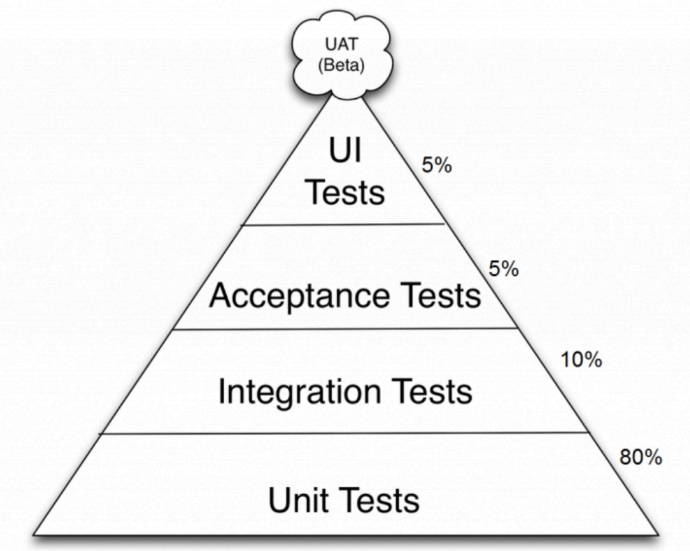
Большая часть функциональности ПО перекрывается простыми модульными тестами, а для оставшейся функциональности создаются более сложные. Если эту пирамиду перевернуть, мы получим воронку с множеством различных багов на входе и небольшим количеством гейзенбагов на выходе. Рассмотрим подробнее каждую группу.
В начале проекта и в молодых командах ручные тесты отнимают много времени и сил, а автоматические — почти не используются. Из-за этого снижается эффективность тестирования, и от этого необходимо избавляться: уходить от ручных и наращивать количество модульных тестов.
По сравнению с UI-тестами модульные тесты выполняются быстрее, требуют меньше времени на разработку. Они могут запускаться локально, без мощных ферм или отдельных устройств. Обратная связь от модульных тестов в разы быстрее, чем от UI-тестов. От изменений в API или XML-файле UI-тесты начинают массово падать, их надо каждый раз переписывать. На этом фоне важным преимуществом модульных тестов является большая устойчивость.

С точки зрения покрытия кода модульные тесты эффективнее, но полностью перекрыть ими тестирование нельзя. Нужно постоянно держать баланс, при котором модульные тесты закрывают базовые кейсы, а UI-тесты решают более сложные задачи.
Важно понимать, что тесты высокого уровня сигнализируют о незакрытых багах в тестах на нижних уровнях, поэтому при появлении ошибки, например, в боевом коде, стоит сразу сделать соответствующий модульный тест. Когда воскресают баги, это гораздо обиднее чем когда они обнаруживаются в первый раз.
Кроме известных принципов SOLID, которые определяют качество и красоту кода, при программировании тестов нужно учитывать еще два требования: к скорости и надежности. Их можно достичь, руководствуясь пятью основными принципами, объединенными акронимом FIRST.

Если совсем упрощать, то тесты должны быть быстрыми и надежными. Для этого важна синхронность, отсутствие ожидания внешних реакций и внутренних тайм-аутов.
В рамках TDD (test-driven-development) на сегодняшний день сложилось две школы тестирования. В Чикагской школе акцент делается на результаты, которые выдают тестируемые классы и методы. В Лондонской школе тестирование сосредоточено на поведении и подразумевает использование mock-объектов.
Предположим, у нас есть некий класс, который умножает два числа, например, 7 и 5. Чикагская школа просто проверяет, что результат будет 35 — в ней неважно, как мы это узнаем. Лондонская школа говорит о том, что нужно замокировать внутренний калькулятор, который существует в нашем классе, проверить, что он вызывается с правильным набором методов и данных, и удостовериться, что он возвращает замокированные данные. Чикагская школа тестирует «по черному ящику», Лондонская — по белому. В разных тестах имеет смысл использовать оба метода.
Даже если вы покрываете тестами 100% кода, гарантировать отсутствие багов все равно нельзя. А стремление достичь 100%-ного покрытия только мешает в работе: разработчики начинают стремиться к этой цифре, создавая тесты ради показателей. О качестве тестов говорит не уровень покрытия, а более простые факты: до итогового продукта доходит мало багов и при закрытии найденного бага не появляются новые. Уровень покрытия сигнализирует только о том, о чем по определению должен, — есть ли у нас непокрытые участки кода или нет.
В следующем материале нашего цикла про тестирование мы перейдем к оформлению, разберем различные нотации тестирования и виды тестовых объектов, а также требования к качеству тестового кода.
Пирамида тестирования
Эффективное распределение тестов с точки зрения их автоматизации можно представить в виде пирамиды.
Большая часть функциональности ПО перекрывается простыми модульными тестами, а для оставшейся функциональности создаются более сложные. Если эту пирамиду перевернуть, мы получим воронку с множеством различных багов на входе и небольшим количеством гейзенбагов на выходе. Рассмотрим подробнее каждую группу.
- Модульное или блочное тестирование работает с определенными функциями, классами или методами отдельно от остальных частей системы. Благодаря этому при возникновении бага можно по очереди изолировать каждый блок и определить, где ошибка. В этой группе выделяют поведенческое тестирование. По сути оно похоже на модульное, но предполагает жесткий регламент написания тестового кода, который регламентирован набором ключевых слов.
- Интеграционное тестирование сложнее модульного, так как в нем проверяется взаимодействие кода приложения с внешними системами. Например, UI-тесты на EarlGrey отслеживают, как приложение взаимодействует с API-ответами сервера.
- Приемочное тестирование проверяет, что функции, описанные в техническом задании, работают правильно. Оно состоит из наборов больших кейсов интеграционного тестирования, которые расширены или сужены с точки зрения тестового окружения и конкретных условий запуска.
- UI-тестирование проверяет, как интерфейс приложении соответствует спецификациям от дизайнеров или запросам пользователей. В нем выделяют snapshot-тестирование, когда скриншот приложения попиксельно сравнивают с эталонным. При таком способе невозможно закрыть все приложение, так как сравнение двух картинок требует много ресурсов и загружает тестовые сервера.
- Ручное или регрессионное тестирование остается после автоматизации всех остальных сценариев. Эти кейсы выполняются QA-специалистами, когда нет времени на написание UI-тестов или надо поймать плавающую ошибку.
В начале проекта и в молодых командах ручные тесты отнимают много времени и сил, а автоматические — почти не используются. Из-за этого снижается эффективность тестирования, и от этого необходимо избавляться: уходить от ручных и наращивать количество модульных тестов.
Unit vs UI
По сравнению с UI-тестами модульные тесты выполняются быстрее, требуют меньше времени на разработку. Они могут запускаться локально, без мощных ферм или отдельных устройств. Обратная связь от модульных тестов в разы быстрее, чем от UI-тестов. От изменений в API или XML-файле UI-тесты начинают массово падать, их надо каждый раз переписывать. На этом фоне важным преимуществом модульных тестов является большая устойчивость.
С точки зрения покрытия кода модульные тесты эффективнее, но полностью перекрыть ими тестирование нельзя. Нужно постоянно держать баланс, при котором модульные тесты закрывают базовые кейсы, а UI-тесты решают более сложные задачи.
Важно понимать, что тесты высокого уровня сигнализируют о незакрытых багах в тестах на нижних уровнях, поэтому при появлении ошибки, например, в боевом коде, стоит сразу сделать соответствующий модульный тест. Когда воскресают баги, это гораздо обиднее чем когда они обнаруживаются в первый раз.
Требования к коду тестов
Кроме известных принципов SOLID, которые определяют качество и красоту кода, при программировании тестов нужно учитывать еще два требования: к скорости и надежности. Их можно достичь, руководствуясь пятью основными принципами, объединенными акронимом FIRST.
- F — Fast. Хорошие тесты дают максимально быстрый отклик. Cам тест, установка его в окружение и очистка ресурсов после выполнения должны занимать несколько миллисекунд.
- I — Isolated. Тесты должны быть изолированными. Проверку тест осуществляет самостоятельно, и все данные для нее берутся из окружения, не зависят от других тестов и тестовых модулей. Приятный бонус для следующих этому принципу: порядок тестов не важен, и их можно запускать параллельно.
- R — Repeatable. У тестов должно быть предсказуемое поведение. Тест должен давать четкий результат, вне зависимости от количества повторов и окружения.
- S — Self-verifying. Результат теста должен быть налицо, отображаться в каком-нибудь очевидном логе.
- T — Thorough / Timely. Тесты необходимо разрабатывать параллельно с кодом, хотя бы в рамках одного pull request. Это гарантирует покрытие именно боевого кода, а также актуальность самих тестов и то, что их не нужно будет дополнительно изменять.
Если совсем упрощать, то тесты должны быть быстрыми и надежными. Для этого важна синхронность, отсутствие ожидания внешних реакций и внутренних тайм-аутов.
Что должны покрывать тесты
В рамках TDD (test-driven-development) на сегодняшний день сложилось две школы тестирования. В Чикагской школе акцент делается на результаты, которые выдают тестируемые классы и методы. В Лондонской школе тестирование сосредоточено на поведении и подразумевает использование mock-объектов.
Предположим, у нас есть некий класс, который умножает два числа, например, 7 и 5. Чикагская школа просто проверяет, что результат будет 35 — в ней неважно, как мы это узнаем. Лондонская школа говорит о том, что нужно замокировать внутренний калькулятор, который существует в нашем классе, проверить, что он вызывается с правильным набором методов и данных, и удостовериться, что он возвращает замокированные данные. Чикагская школа тестирует «по черному ящику», Лондонская — по белому. В разных тестах имеет смысл использовать оба метода.
Почему невозможно 100%-ное покрытие тестами
Даже если вы покрываете тестами 100% кода, гарантировать отсутствие багов все равно нельзя. А стремление достичь 100%-ного покрытия только мешает в работе: разработчики начинают стремиться к этой цифре, создавая тесты ради показателей. О качестве тестов говорит не уровень покрытия, а более простые факты: до итогового продукта доходит мало багов и при закрытии найденного бага не появляются новые. Уровень покрытия сигнализирует только о том, о чем по определению должен, — есть ли у нас непокрытые участки кода или нет.
В следующем материале нашего цикла про тестирование мы перейдем к оформлению, разберем различные нотации тестирования и виды тестовых объектов, а также требования к качеству тестового кода.