

В последние годы использование технологий Deep Learning позволило достичь значительного прогресса в таких областях, как распознавание образов, автоматический перевод и др. Этот успех, а также разработки в области беспилотных автомобилей и достижения компьютера в игре GO, позволили фантазировать о том, что Искусственный Интеллект скоро будет делать ту работу, которую сейчас выполняют люди, и будет претендовать на их рабочие места.
Повсеместная замена людей на роботов — процесс увлекательный, но не быстрый. Однако уже сейчас можно использовать возросшие вычислительные мощности компьютеров для того, чтобы облегчить решение задач, с которыми люди сталкиваются каждый день. Например, процесс написания программ. Использование систем, которые облегчают процесс программирования, не является чем-то исключительным, любая среда разработки предоставляет множество таких инструментов.
В этой статье представленна технология, помогающая программисту написать тест на основе модуля на языке Java. Технология позволяет значительно сэкономить время по сравнению с написанием теста вручную.
Тесты
В процессе создания программного модуля мы всегда хотим быть уверены, что запрограммированный функционал соответствует нашим требованиям. Для того чтобы знать, что реальное поведение созданной нами программы соответствует ожидаемому результату, используются тесты.
Необходимость, все плюсы и минусы написания тестов перечислены здесь. Однако несомненно то, что написание тестов требует значительного времени (исследования показывают, что разработчики тратят до 30% времени на создание тестов). Кроме того, эта деятельность не развивает функциональность основного программного модуля, поэтому логично, что многие команды стараются избежать написания тестов. С другой стороны, поддержка старого функционала и программирование нового сильно осложняются без использования тестов.
Помимо контроля правильности выполнения программы тесты могут также объяснять функциональность выполняемой программы на “естественном языке”. То есть тестовые скрипты могут сопровождаться текстом-документацией, которая объясняет поведение теста и тестируемой программы в парадигме BDD .
В данной статье мы обсуждаем технологию автоматической генерации тестов. При синтезе тестов мы будем использовать Gherkin-нотацию.
Пример теста на русском языке с использованием Gherkin:
# language: ru
@all
Функция: Аутентификация банковской карты
Банкомат должен спросить у пользователя PIN-код банковской карты
Банкомат должен выдать предупреждение, если пользователь ввел неправильный PIN-код
Аутентификация успешна, если пользователь ввел правильный PIN-код
Предыстория:
Допустим пользователь вставляет в банкомат банковскую карту
И банкомат выдает сообщение о необходимости ввода PIN-кода
@correct
Сценарий: Успешная аутентификация
Если пользователь вводит корректный PIN-код
То банкомат отображает меню и количество доступных денег на счету
@fail
Сценарий: Некорректная аутентификация
Если пользователь вводит некорректный PIN-код
То банкомат выдает сообщение, что введённый PIN-код неверныйBDD, TDD
Техники TDD и BDD подразумевают, что тест пишется до начала разработки самого тестируемого модуля (https://ru.wikipedia.org/wiki/Разработка_через_тестирование),
Test -> Module
Не обсуждая плюсы и минусы подхода TDD и BDD, нужно сказать, что в жизни очень часто встречаются ситуации (а, возможно, таких случаев большинство), когда тесты пишутся после готовности модуля, или тесты не пишутся вовсе. Это приводит к тому, что код становится нечитаемым и сложно поддерживаемым, приводя, в частности, к феномену legacy code.
Таким образом, мы предлагаем возможность синтезировать тест и описание кода в формате BDD на основе готового кода — в том случае, если тестов вообще не было или тесты собирались писать после создания программного модуля.
Module -> Test
Синтез
Процесс создания тестов начинается с анализа готового программного модуля. В данный момент мы работаем с классами, написанными на Java. Общая схема работы такая — вначале мы собираем логи и информацию о выполнении программного модуля, затем на основе этих логов обучаем нейронную сеть, далее используем нейронную сеть для генерации готовых тестовых скриптов.
Сбор логов
Допустим, у нас есть модуль, обслуживающий клиентский банковский счет.
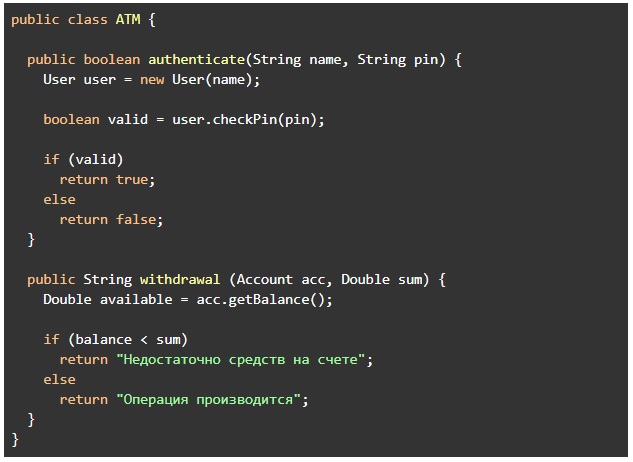
Мы собираем логи на каждом шаге программы, начиная с информации об input и output, и заканчивая изменениями переменных

Сам сбор происходит следующим образом:
Мы берем инпуты — это могут быть данные из access логов, или варианты, предоставленные программистом, или автоматически сформированные данные с помощью различных генетических или рандомных механизмов (Evosuite, Randoop).
В особых случаях мы можем оставить модуль сбора логов в продакшене, но в общем случае это не рекомендуется.
Обучение нейросети
Обучение нейронной сети происходит в парадигме Neural Programmer-Interpreters.
NPI работает так: на основе входных данных (на картинке, “previous NPI state”, “environment observation”, “input program”) предсказывает команда (“output program”).

Умея распознавать environment для предскзывания простых программ (операции сложения, ссотировки), программа может предсказывать Gherkin нотацию для этих данных. Качество использования NPI зависит как от возможности обрабатывать определенные входные данные, так и от развития архитектуры нейросети.
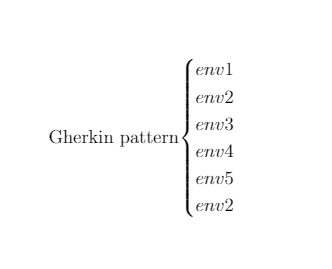
Таким образом, обученная нейросеть решает традиционную для программного синтеза задачу — как найти правильную программу (Gherkin нотацию, тест-кейс) для текущих входных данных (env1’).
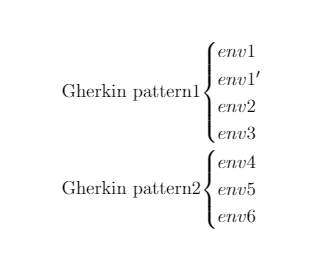
Генерация скриптов.
На основе обученной нейросети генерируются тест-кейсы. В самом простом случае — списки данных, которые прошли валидно, и списки данных, которые валидацию не прошли.

Готовые скрипты можно редактировать с учетом финальных требований. Тесты Gherkin написаны на “естественном языке”, что подразумевает возможность прочтения и редактирования этих тестов всей командой, как теми, кто писал код, так и теми, кто не имел отношения к разработке модуля.
При каждом выполнении тесты будут проверять те условия, которые в них закодированы. В том случае, если функционал тестируемого программного модуля изменился, нейронную сеть можно обучить повторно для генерации новых тестов.
Выполнение тестов на языка Gherkin производится на тестовом фреймворке Cucumber.
Фреймворк поддерживает автоматическое выполнение скриптов при сборке с помощью Maven.
<dependency>
<groupId>info.cukes</groupId>
<artifactId>cucumber-java</artifactId>
<version>1.2.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>info.cukes</groupId>
<artifactId>cucumber-junit</artifactId>
<version>1.2.4</version>
</dependency>Также Cucumber интегрируется с другими инструментами continuous integration, такими как Jenkins и прочее.
Генерация тестовых скриптов, ограничения
У автоматического генератора есть сразу несколько ограничений. Все они обусловлены тем, что программа не «учится» программировать или «понимать» алгоритмы. Цель программы — уметь сопоставлять понятные ей виды входных данных с выходными данными, и подбирать лейблы, что является простым случаем conditional program generation:
Простые кейсы
Не обладая интуицией или глубоким пониманием логики работы программы, система может выявлять только простые случаи сбоев программы (например, параметры которые приводят к сообщениях об ошибках), в то же время остаются кейсы, которые могут быть выявлены только программистом.
Ограниченный набор логируемых параметров
Легко логировать и анализировать нейросетью примитивные типы (строчки, цифры), сложнее логировать и анализировать объекты.
Выявление простых взаимосвязей
Соответственно, легко выявлять простые взаимосвязи в простых данных. Все вышеперечисленное подразумевает, что, на данный момент, валидация и доработка автоматических тестов происходит вручную.
Перспективы
Главное направление развития системы — увеличение количества и сложности распознаваемых паттернов.
В случае интереса, буду рад обсудить более подробно — email to nayname@gmail.com
Комментарии (17)

atomheart
15.05.2018 20:27Извините, но не понятно, для чего в описанной вами задаче нужна нейронная сеть? Приложение пишет логи и по сути сохраняет операцию и ее входящие данные (возможно, даже исходящие). И, как я понял, вы хотите выделять отдельно кейсы для последующего преобразования их в кейсы. Что мешает при логировании сохранять вместе с записью лога еще и сессию пользователя и потом просто разбивать логи по сессиям и паузам между действиями пользователя? Сами кейсы разделяются по "паттерну поведения", т.е. последовательности определенных действий или определенных входящих/исходящих данных, что можно задать заранее или преобразовывать все найденные таким образом кейсы, а потом группировать их по схожести "паттернов". Это достаточно простые шаги для простого перебора логов. Или я как-то неправильно понял цели или задачу? Поясните пожалуйста, потому что тема интересная.
Fedor11111 Автор
15.05.2018 20:43Если я в свою очередь правильно понял)))
>> Сами кейсы разделяются по «паттерну поведения», т.е. последовательности
>> определенных действий или определенных входящих/исходящих данных
Дело как раз в сопоставлении набора данных и паттерна. Эта классическая задача для программного синтеза — по набору данных найти программу. И с ней в общем сложно справиться:
а) потому что у нас очень много разных видов программ (паттернов), практически бесконечное количество.
б) потому что у нас очень большое количество фич, по которым нужно сопоставлять паттерн и данные.
То есть мы не можем завести таблицу в БД, в которой написать — елси входной параметр единица — то паттерн 1, если 0 — то паттерн 2. Потнециально, это будет таблица с огромным количеством столбцов (фич) и огромным количеством строк (паттернов).
Нейросеть облегчает этот случай программного синтеза именно в смысле поиска по фичам. Мы можем уже не запоминать и разбираться каким фичам соотвествует тот или иной параметр. Для программного синтеза нейросеть лучше ищет по ограниченному объему паттернов и большому объему фичей — тысячи и тысячи).
Проблему практически бесконечного количества вариантов программ(паттернов) это не решает. Я надеюсь на тот вопрос ответил))) Если что, буду рад уточнить.atomheart
16.05.2018 15:12Спасибо за разъяснение. Но это не совсем то, что я хотел узнать.
Есть несколько моментов:
- Кол-во кейсов все таки ограничено количеством функций системы, которые разрабатываются программистами (а значит, их конечное число).
- Если программа генерирует лог в определенном формате, не проще ли написать преобразователь этого формата в конечные кейсы (или хотя бы в транзакции, которые потом можно будет объединять)?
- Кейсы тестирования все таки должны подразумевать параметризацию — те же входящие данные могут различаться для одного и того же паттерна поведения, а какие-то данные различаться не должны (например, идентификатор открытой вкладки). Как планируете разрешать эти вопросы?
- Непонятно на счет Gerkin скрипта, т.к. для его работы должны быть расписана логика действия (что выполняется и при каких параметрах). Как я понял, генерацию этой части приведенное решение не включает?
Если вы решаете задачу генерации тест кейсов по логам приложения, то мне непонятна роль описанного классификатора на нейросети и не понятно, почему не справится предложенный мной в первом комментарии классификатор (тем более что и данные не с промышленной среды, а с тестовой, и их не много).
Тем более, что, если я правильно понял, вы предлагаете по сути "прокликать" функционал в системе, собрать лог, отправить его в нейросеть для распознавания уже известных паттернов? Или для генерации новых, но не понятно по каким данным?
Честно, я несколько раз перечитал статью. Примеры в статье немного синтетичные, из конкретики только два метода на стороне приложения, в которых обозначено логирование, а так же пример работы нейросети, которая обучается складывать числа. Как это транслировать на реальную системы, я вот никак не пойму.
Fedor11111 Автор
16.05.2018 15:34>Кол-во кейсов все таки ограничено количеством функций системы, которые >разрабатываются программистами (а значит, их конечное число).
Количество кейсов конечно в отдельной функции, в отдельном модуле или одной программе. Если мы хотим собрать все возможные кейсы которые в теории можно написать на Java то это конечно не будет бесконечное количество вариантов, но примерно как варианты ходов в шахматах.
> Если программа генерирует лог в определенном формате, не проще ли написать
> преобразователь этого формата в конечные кейсы (или хотя бы в транзакции,
> которые потом можно будет объединять)?
Тут в каком месте вручную не оптимизируй количество кейсов, это будет не очень качественно. Вообще тут ручная оптимизация не очень хорошо работает. Представьте обратную ситуацию — вам на основе спецификации Gherkin нужно сгенерировать программу. МОжно сделать распознователь ключевых слов в спецификации, какие то регулярки. Но руками это наоптимизироват невероятно сложно. Тут обратная задача, но не менее сложная.
Смотрите, чтобы проще было понять зачем нужна тут нейросеть, нужно сформулировать реальную задачу. Синтетический лог который я в статье привел конечно можно раскидать руками.
Но сформулируйте задачу для неизестного количества паттернов. Того, что мы накопили прогнав милион программ. Тогда это задача типа k-means, когда у вас есть векторное пространство паттернов, вам дают на вход кусок лога, и вам нужно найти вектор, который лучше всего подходит для этого куска лога. Здесь лучше никаких преобразователей самому не писать, а воспользоваться уже применяемыми для этой общей задачи методами.atomheart
16.05.2018 15:47Если можно, давайте на конкретном примере разберем.
Есть сайт Яндекс.Почта (или любая другая почта).
Возмем базовые кейсы:
- авторизация,
- просмотр списка писем,
- открытие любого письма для просмотра,
- открытие формы создания нового письма и отправка письма (это один кейс).
Что мне интересно:
- Как будут выглядеть (примерно) логи для этих действий?
- Какая информация и в каком виде из этих логов будет подаваться на нейронную сеть?
- Что будет отдавать нейронная сеть на выходе?
- Как будет выглядеть процесс создания кейсов тестирования?
Fedor11111 Автор
16.05.2018 16:41Для какой-нибудь авторизации логируются входные данные (имя пользователя, пароль) выходные данные (результат работы программы). В нейронную сеть подаются эти данные, и сопоставляется что для этого пользователя с этим паролем программа либо авторизует либо нет. На выходе будет кейс типа того, что приведен в статье
When("^ user \"([^\"]*)\" and pin \"([^\"]*)\" in authenticate is valid")
public void user_and_pin_in_authenticate_is_valid(String arg1, String arg2) throws Throwable {
…
}
When("^ user \"([^\"]*)\" and pin \"([^\"]*)\" in authenticate is not valid")
public void user_and_pin_in_authenticate_is_not_valid(String arg1, String arg2) throws Throwable {
…
}
и для такого теста нам не нужна нейросеть, тут можно использовать то что вы называете преобразователем
НО
если мы представим что сама операция авторизации состоит из условных операций:
начать коннекшн к БД (просто логируем тип БД, Gherkin паттерн «Пытаемся приконнектится к БД», тест кейс — прокерка что установился коннект)
авторизоваться в БД
взять пароль из БД для пользователя
сверить пароль с паролем пользователя
если да, то прописать куку
для этих операция мы тоже можем собрать логи и тоже прописать кейсы с спецификацией Gherkin.
И
в другой программе у нас тоже есть коннекшн к БД. Тогда задача нашей нейросети в другой программе распознать по логам что это тоже коннекшн к БД, выдать нам соответствующий паттерн в Gherkin и тест кейс коннекшна. И елси мы натренировали нейросеть правильно, мы не пишем ей правил соотвествия между описанием лога коннекшна к БД в одной программе, и логом коннекшном в другой программе.
atomheart
16.05.2018 16:59Теперь понятнее стало, спасибо. Решается, вероятно, задача генерации unit-тестов, т.е. тестирование непосредственно программных функций приложения, а не генерация комплексных функциональных и/или нагрузочных тестов, где каждый кейс — это реальный пользовательский кейс с определенной последовательностью вызовов функций приложения через доступные только пользователям каналы взаимодействия (например, трафик http) и связью между этими шагами (сохранение сессий, сквозная передача параметров и пр.)
vba
15.05.2018 22:27Да сбывается мечта одних, моих, бывших сингапурских коллег индийского происхождения. Которым тесты писать, явно в антикарму шло и которые в попытке обойти минимальное покрытие в CI тупо засылали псевдотесты без
assertблоков.
Может покажусь консерватором, но я бы машине не стал доверять это дело. Если вы напортачили с учебной выборкой в задаче классификации изображений, то это будет видно сразу при тестировании модели(террорист с калашом вверх распознаваемый как счастливый и веселый это конечно не в счет). Как вы можете гарантировать качество обучения в данном случае?
Fedor11111 Автор
15.05.2018 22:40Ну никто пока не доверяет полностью машине создание тест-кейсов. Сейчас программа может распознавать самые простые случаи, которые не опасно ей доверить. Если брать аналогию по распознаванию террориста с калашом, то в случае тестов мы сейчас умеем разве что квадрат от треугольника отличать. Но путь такой же — когда-нибудь научимся и программных террористов с калашами.
Качество работы тут может повышаться также, как и в случае с изображениями — постепенно начинаем с простых случаев и примитивных форм, постепенно набиваем руку и увеличиваем количество паттернов.
Fedor11111 Автор
15.05.2018 22:45Другое дело тут, впрочем как в изображениях — вы доверите распознавание рака на картинке машине или врачу? — есть элемент интуиции и человеческого знания, недоступного сейчас для того что называют ИИ в принципе. Поэтому в данном в статье написан обучаемый автокомплитер тестов, но не то чему безоговорочно можно доверить QA. На текущий момент.
Mishok2000
16.05.2018 16:57Спасибо за статью, заставила задуматься о многом )
Я правильно понял, что в идеальном случаи программа должна логировать:
Значение каждогой переменной каждого объекта (даже временного, типа ретурна функции которая возвращает текущее время в качестве аргумента другой функции) в программе (нужного для теста) и при её инициализации, не только при прямом её измение?Fedor11111 Автор
16.05.2018 18:09В идеальном случае да. Другое дело что сейчас есть скорее проблема «фичизирования» всего, что залогировали. Так что прямо сейчас работаем только с примитивными типами.
brickerino
А при чем здесь Subnautica? Типа, не запускай космический корабль, если тесты не прогнал?
Fedor11111 Автор
Ну намек был на это. Плюс еще картинка красивая :-)
GDragon
Игра если честно — не только красивая но и очень хорошо зашла :)