
- пишут код;
- отлаживают, тестируют;
- после этого упаковывают в jar;
- отправляют на Linux, и оно работает.
В том, что оно работает, нет особой магии. Но это приводит к тому, что такие разработчики немножечко «засахариваются» в своём мире кроссплатформенности и не очень хотят разбираться, а как оно на самом деле работает в реальной операционной системе.

С другой стороны, есть те, кто занимается администрированием серверов, на их сервера устанавливают JVM, отправляют jar и war-файлы, а с точки зрения мира Linux все это:
- чужеродное;
- проприетарное;
- собирается не из исходников;
- поставляется какими-то jar-архивами;
- «отъедает» всю память на сервере;
- вообще, ведёт себя не по-человечески.
Цель доклада Алексея Рагозина на Highload++, расшифровка которого идет далее, была в том, чтобы рассказать особенности Java для «линуксоидов» и, соответственно, Linux — Java-разработчикам.
Доклад не будет разбором полётов, потому что проблем много, они все интересные, и снаряд дважды в одну воронку не попадает. Поэтому затыкать уже известные «дыры» — пораженческая позиция. Вместо этого поговорим про:
- особенности реализации JVM;
- особенности реализации Linux:
- как они могут не стыковаться.

В Java есть виртуальная машина, и Linux, как и любая другая современная операционная система, по сути, — это тоже виртуальная машина. И в Java и в Linux есть управление памятью, потоки, API.
Слова похожи, но на самом деле под ними очень часто скрываются совершенно разные вещи. Собственно, по этим пунктам мы и пройдёмся, наибольшее внимание уделив памяти.
Память в Java
Сразу замечу, что я буду говорить только про реализацию JVM HotSpot, это Open JDK и Oracle JDK. То есть, наверняка в IBM J9 есть какие-то свои особенности, но я, к сожалению, про них не знаю. Если же мы говорим про HotSpot JVM, то картина мира выглядит следующим образом. Прежде всего в Java есть область, где живут java-объекты — так называемый Heap или, по-русски, куча, где работает сборщик мусора. Эта область памяти, как правило, занимает большую часть пространства процесса. Куча в свою очередь разбита на молодое и старое пространство (Young Gen / Old Gen). Не вдаваясь в дербри сайзинга JVM, важно то, что у JVM есть параметр «-Xmх», определяющий максимальный размер, до которого может вырасти пространство кучи.
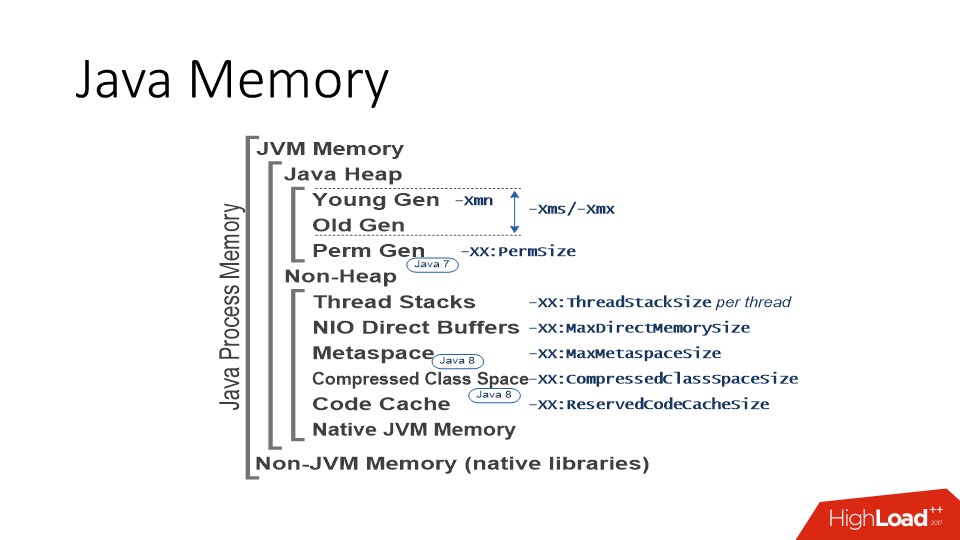
А дальше есть много вариантов:
- можно управлять отдельно размерами молодого пространства;
- можно сразу выставить максимальный размер кучи;
- либо дать возможность ему расти постепенно.
Деталей слишком много — важно, что есть лимит. И, в принципе, это общий подход ко всем областям, которые используют JVM. То есть практически все области, перечисленные на картинке выше, имеют определённый лимит. JVM сразу резервирует адресное пространство, исходя из лимита, а потом по мере необходимости запрашивает реальные ресурсы памяти в этом диапазоне. Это важно понимать.
Помимо кучи есть другие потребители памяти. Наиболее важными из них являются области памяти для стеков потоков. Потоки в Java — это обычные linux-потоки, у них есть стек, для которого резервируется определённый размер памяти. Чем больше у вас потоков, тем больше стеков выделено в памяти процесса. Поскольку число потоков в Java может измеряться сотнями и тысячими, иногда эта цифра может становиться достаточно существенной, особенно, если у вас какой-нибудь stateless microservice, в котором куча на 200 Мб, а ThreadPool на 50-100 потоков.
Кроме этого, есть ещё так называемые NIO Direct Buffers — это специальные объекты в Java, которые позволяют работать с памятью вне кучи. Они, как правило, используются для работы c I/O, потому что это память, к которой может напрямую обращаться как Си так и Java-код. Соответственно, эта область доступна через API, и у неё тоже есть максимальный лимит.
Остальное — это метаданные, какой-то сгенерированный код, память для них обычно не вырастает до больших величин, но она есть.
Помимо этих специальных областей не надо забывать, что JVM написана на C++, соответственно, там есть
- malloc и обычная аллокация памяти;
- библиотеки, которые подгружаются в JVM (статически или динамически слинкованные, которые тоже могут использовать память).
И эта память не классифицируется по нашей схеме, а просто является памятью, выделенной стандартными средствами C Runtime. C ней тоже иногда бывают проблемы, причём на достаточно ровном месте.
Например, вот у нас java код распространяется в jar виде. Jar — это zip-архив, для работы с ним используется библиотека zlib. Для того, чтобы что-то разархивировать zlib надо аллоцировать буфер, который будет использован для декомпрессии и, конечно, для него требуется память. Всё бы ничего, но сейчас есть мода на так называемые uber-jar, когда создается один здоровенный jar, и возникают нюансы.
При попытке старта из такого jar-файла открывается одновременно слишком много потоков zlib на распаковку. Причём с точки зрения Java всё хорошо: куча маленькая, все области маленькие, но потребление памяти процессом растёт. Это, конечно же «клинический» случай, но такие потребности JVM надо принимать ао внимание. Например, если вы установили -Xmx в 1 Гбайт, посадили Java в Docker-контейнер и поставили лимит памяти на контейнер тоже в 1 Гбайт, то JVM в него не поместится. Надо ещё чуть-чуть накинуть, а сколько точно — зависит от многих факторов, в том числе от количества потоков и от того, что именно ваш код делает.
Итак, это то, как JVM работает с памятью.
Теперь, так сказать, для другой части аудитории.
Память в Linux
В Linux нет никакого сборщика мусора. Его работа с точки зрения памяти совершенно другая. У него есть физическая память, которая разбита на страницы; есть процессы, у которых есть своё адресное пространство. Ему надо ресурсы этой памяти в виде страниц как-то разделить между процессами, чтобы они работали в своём виртуальном адресном пространстве и делали своё дело.

Размер страницы — обычно 4 килобайта. На самом деле это не так, в архитектуре x86 уже очень давно существует поддержка больших страниц. В Linux она появилась относительно недавно, и с ней пока немножко непонятная ситуация. Когда поддержка больших страниц (Transparent Huge Tables) появилась в Linux, очень многие люди наступили на грабли, связанные с performance degradation из-за некоторых нюансов обслуживания больших страниц в Linux. И вскоре интернет заполнился рекомендациями выключать их от греха подальше. После этого какие-то баги, связанные с работой больших страниц в Linux, починили, но осадок остался.
Но на текущий момент нет чёткого понимания, например, с какой версии поддержку больших страниц можно включить по умолчанию и не беспокоиться.
Поэтому будьте осторожны. Если вдруг на вашем Linux сервер внезапно на ровном месте вырастет потребление ресурсов ядром, то проблема может быть как раз в том, что у вас включены большие страницы, а сейчас они включены по умолчанию в большинстве дистрибутивов.
Итак, с точки зрения ядра у Linux есть множество страниц, которыми надо управлять. С точки зрения процесса — есть адресное пространство, в котором он резервирует диапазоны адресов. Зарезервированное адресное пространство — это ничто, не ресурс, в нём ничего нет. Если обратитесь по этому адресу, вы получите segfault, потому что там ничего нет.
Для того, чтобы в адресном пространстве появилась страница, нужен немножко другой syscall, и тогда процесс говорит операционной системе: «Мне, пожалуйста, в этих адресах нужен 1 Гбайт памяти». Но даже в этом случае память там появляется тоже не сразу и со своими хитростями.
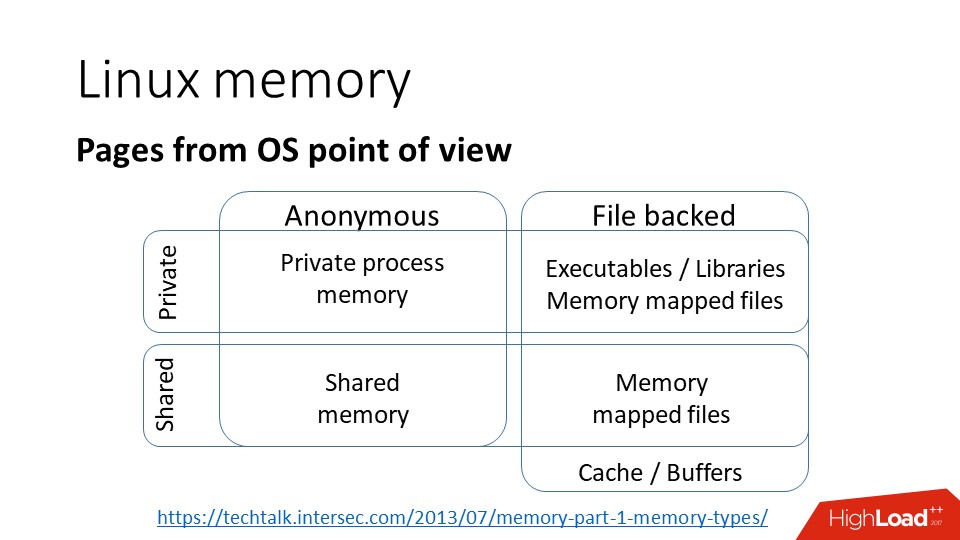
С точки зрения ядра классификация страниц выглядит следующим образом, есть страницы:
a) приватные, то есть это значит, что они принадлежат одному процессу и доступны в адресном пространстве только одного процесса;
b) анонимные — это обычная память, не связанная в файлами;
c) memory mapped files — отображение файлов в память;
d) используемые совместно, которые могут быть либо:
- Copy-On-Write, то есть, при ветвлении процесса, память становится доступна обоим процессам до тех пор, пока не будет записана и страницы не превратятся в приватные;
- через Shared файл, т.е., если несколько процессов отображают в память один и тот же файл, то страницы могут использоваться совместно.
В общем, с точки зрения ядра операционной системы всё достаточно просто.
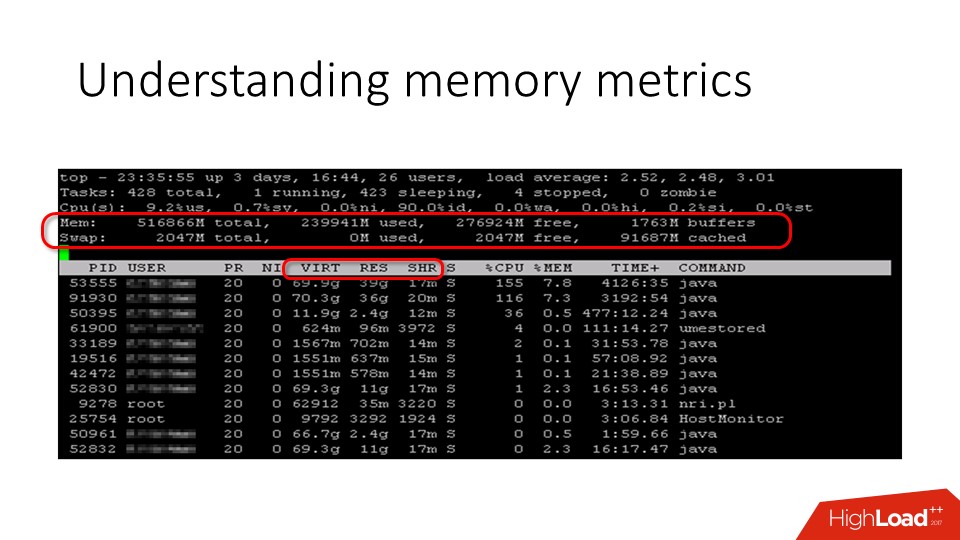
Просто, да не совсем.
Когда мы хотим понять, что происходит на сервере с точки зрения памяти, мы идём в top и видим там какие-то цифры. В частности, там есть использованная память и свободная память. Есть разные мнения насчет того, сколько должно быть свободной памяти на сервере. Кто-то думает, что это 5%, но, на самом деле, и 0% от физической памяти — также норма, потому что то, что мы видим в качестве счётчика свободной памяти, — это в действительности не вся свободная память. Её на самом деле намного больше, просто она, как правило, скрыта в кэше страниц.
С точки зрения процесса top показывает три интересные колонки:
- virtual memory;
- resident memory;
- shared memory.
Последняя память в списке — просто те страницы, которые являются совместно используемыми. А вот с resident memory всё немножко хитрее. Остановимся более подробно на этих метриках.

Как я уже сказал, используемая и свободная память, достаточно бесполезные метрики. У сервера ещё остается память, которая никогда не была использована, потому что у операционной системы есть файловый кэш, и все современные ОС всю свободную память используют под него, так как из файлового кэша страницу памяти всегда можно очистить и использовать для более важных задач. Поэтому вся свободная память постепенно уходит в кэш и не возвращается обратно.
Метрика виртуальной памяти —это вообще не ресурс с точки зрения операционной системы. Вы запросто можете аллоцировать 100 терабайт адресного пространства, и всё. Сделали это и можете гордиться, что с адреса X по адрес Y пространство зарезервировано, но не более. Поэтому смотреть на неё как на ресурс и, например, ставить алерт, что виртуальный размер процесса превысил какой-то порог, довольно бессмысленно.
Вернёмся к Java, она все свои специальные области резервирует заранее, потому что код JVM ожидает, что эти области будут непрерывными с точки зрения адресного пространства. А значит адреса надо застолбить заранее. В связи с этим, запуская процесс с кучей на 256 Мбайт, вы можете внезапно увидеть, что виртуальный размер у него больше двух гигабайт. Не потому, что эти гигабайты нужны и что JVM способна их когда-либо утилизировать, а просто дефолт такой. От него ни холодно, ни жарко, по крайне мере, так думали те, кто писал JVM. Это, правда, не всегда соответствует мнению тех, кто потом занимается поддержкой серверов.
Residence size — наиболее близкая к реальности метрика — это количество страниц памяти, которые используются процессом, находящимся в памяти, не в свопе. Но она тоже немножечко своеобразная.

Кэш
Возвращаюсь к кэшу. Как я уже сказал, кэш — это, в принципе, свободная память, но иногда бывают исключения. Потому что страницы в кэше бывают чистые и грязные (содержащие не сохранённые изменения). Если страница в кэше модифицирована, то прежде, чем она может быть использована для другой цели, её сначала надо записать на диск. А это уже совсем другая история. Пример, JVM пишет большой-большой Heap Dump. Делает она это неспешно, процесс происходи так:
- JVM быстренько пишет в память;
- операционная система выдаёт ей всю свободную память, которая у неё есть, под write behind cache, вся эта память оказывается «грязной»;
- идет медленная запись на диск.
Если размер этого дампа сопоставим с размером физической памяти сервера, может возникнуть ситуация, что для всех остальных процессов свободной памяти просто не будет.
То есть у нас, например, открывается новая ssh-сессия — чтобы запустить shell-процесс, надо выделить память. Процесс идёт за памятью, а ядро говорит ему: «Подожди, пожалуйста, сейчас я что-нибудь найду». Находит, но прежде, чем оно успевает отдать эту страницу SSHD, Java успевает «запачкать» ещё несколько страниц, потому что она тоже «висит» в Page Fault и, как только появляется свободная страница, она быстренько успевает выхватить эту память раньше, чем какие-то другие процессы. На практике такая ситуация приводила, например, к тому, что система мониторинга просто решала, что этот сервер «не живой» раз зайти на него через ssh не получается. Но это, конечно, крайний случай.
Еще процесс в Linux помимо virtual size и resident size имеет committedsize — это та память, которую процесс реально собирается использовать, то есть это адресное пространство, при обращении к которому вы не получите segfault, при обращении к которому ядро обязано предоставить вам физическую страницу памяти.
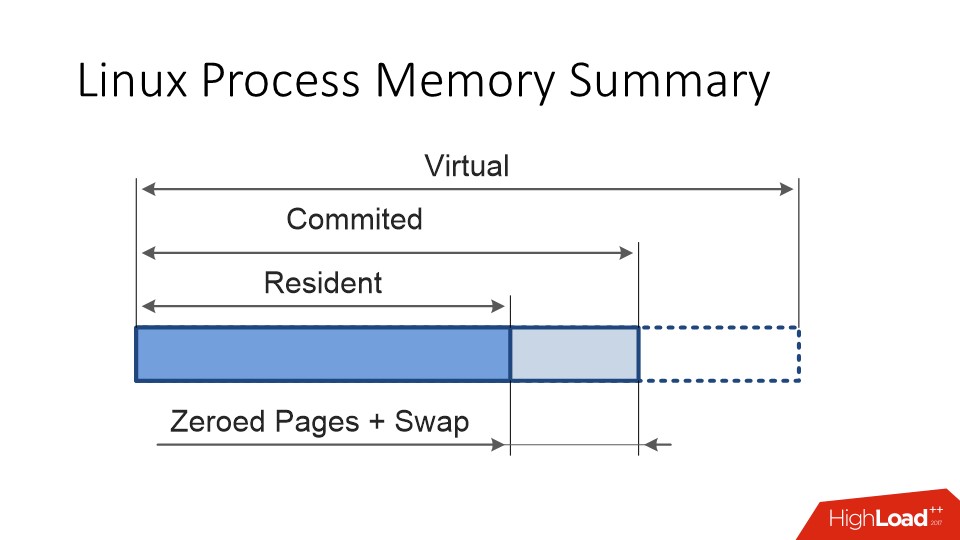
В идеальной ситуации committed и re sident должны были быть одним и тем же. Но, во-первых, страницы могут «свопиться».
Во-вторых, память в Linux выделяется всегда лениво.
- Вы говорите ему: «Дай мне, пожалуйста, 10 Гбайт». Он говорит: «Бери пожалуйста».
- Другой процесс: «Дай мне тоже 10 Гбайт» — «Бери пожалуйста».
- Третий процесс: «Дай мне тоже 10 Гбайт» — «Бери пожалуйста».
Потом оказывается, что физической памяти всего 16, а он всем раздал по 10. И начинается «кто первый взял, того и тапочки, а кому не повезло, за тем придёт OMKiller». Это особенности управления памятью Linux.
Важные факты о JVM
Первое, JVM очень не любит swapping. Если мне жалуются, что java-приложение почему-то тормозит, то первое, что я делаю, это смотрю, нет ли на сервере своппинга. Потому что есть два фактора, делающих Java очень нетолерантной к свопингу:
- Сборка мусора в Java постоянно бегает по страничкам, и если она «промахивается» мимо резидентных страниц, то вызывает перекладывание страниц с диска в память и обратно.
- Если в JVM хотя бы один поток «наступил» на страницу, которой в памяти нет, то это может привести к заморозке всех потоков этой JVM.
Есть механизм safe-point, который используется в JVM для всякой чёрной магии вроде перекомпиляции кода на лету, сборки мусора и так далее. Если один поток попал на Page Fault и ждёт, то JVM не может нормально войти в состояние safe-point, потому что не получает подтверждение от потока, который ждёт «приезда» страницы памяти. А все остальные потоки уже остановились и тоже ждут. Все стоят, ждут один этот несчастный поток. Поэтому, как только у вас начинается пейджинг, может начаться очень существенная деградация производительности.
Второе, Java никогда не отдаёт память операционной системе. Она будет использовать столько, сколько вы разрешили, даже если ей сейчас не очень нужны эти ресурсы, она их обратно не отдаст. Есть сборщики мусора, которые технически умеют это делать, но не надо рассчитывать, что они будут это делать.
У сборщика мусора такая логика работы: он либо использует больше
CPU, либо больше памяти. Если вы ему разрешили использовать 10 Гбайт, значит он разумно предполагает, что можно экономить ресурсы CPU, а эти 10 гигабайт с мусором подождут, а CPU пока пусть лучше делает делает что-то полезное, вместо чистки памяти, которая ещё не выходит за лимит.
В связи с этим важно правильно и обоснованно выставлять размер JVM. А если у вас несколько процессов в рамках одного контейнера, разумно распределять ресурсы памяти между ними.
Иначе пострадают все, что находится в этом контейнере.
Когда заканчивается память
Это еще одна из тех ситуаций, которыеочень по-разному воспринимаются «джавистами» и «линуксоидами».

В Java это происходит так: есть оператор new, который выделяет объект (на слайде это большой массив), если в куче недостаточно места, чтобы выделить память под этот большой массив, мы получаем Out of Memory error.

В Linux всё по-другому. Как мы помним, Linux легко может пообещать больше памяти, чем есть на самом деле, и вы начинаете с ней работать (выше условный код). И в отличии от JVM вы получите не ошибку, а аварийное завершение процесса выбранного OMKiller или смерть всего конейнера, если речь идёт о превышении квоты cgroups.
Когда память заканчивается в JVM
Теперь, разберемся чуть подробнее. В Java у нас есть так называемая область молодых объектов и область старых. Когда мы вызываем оператор new, объект выделяется в пространстве молодых объектов. Если же место в пространстве молодых объектов закончилось, происходит либо молодая, либо полная сборка мусора, если молодой сборки недостаточно. Суть в том, что, во-первых, если у нас не хватает памяти, происходит сборка мусора. И прежде, чем произойдёт Out of Memory error пройдет по крайне мере одна полная сборка, т.е. такая неспешная через всю нашу десятигигабайтную кучу. В некоторых случаях она будет ещё и в один поток, потому что full GC — особый случай.

При этом сборщик мусора наверняка чего-нибудь да наскребёт. Но если этого чего-нибудь меньше, чем 5% от размера кучи, всё равно будет выброшена ошибка, потому что это уже «не жизнь, а сплошное мучение». Но если этот Out of Memory error произойдёт в потоке, автор кода которого решил, что его поток должен работать, не взирая на любые ошибки, он может эту агонию продлевать путём перехвата исключений.
Вообще, после того, как стрельнула Out of Memory error, JVM уже нельзя считать живой. Внутренне состояние уже может быть разрушено, и есть такая опция (
-XX:OnOutOfMemoryError="kill -9 %p"), которая позволяет сразу убить этот процесс. Опять же есть нюансы. Если у вас размер JVM сопоставим с размером физической памяти бокса, то в момент вызова этой команды у вас произойдёт форк, который. приведёт к тому, что образ JVM будет продублирован. Соответственно, с точки зрения Linux память для JVM может немножечко превысить предел максимальной памяти, которую он готов выделить и эта команда не сработает. Такая проблема типична для Hadoop-серверов, например, когда большущий узел пытается запустить Python через shell. Естественно, этому дочернему процессу столько памяти не нужно, просто форк делает копию всего, а уже потом освобождает ненужную память. Только «потом» не всегда наступает.Может быть другая ситуация, возможно, что куча ещё не максимального размера (меньше -Xmx), но сборка мусора не собрала достаточно памяти, и JVM решила, что надо увеличить кучу. Пошла к операционной системе, говорит: «дай мне больше памяти», а ОС говорит: «нет». Правда, как я уже сказал, Linux так не говорит, но другие системы говорят. Любая ошибка выделения памяти операционной системы с точки зрения JVM — это crash, без вопросов, никаких эксепшенов, никаких логов, только стандартный crash dump, и немедленное завершение процесса.
Есть ещё второй тип Out of Memory, который связан с так называемыми direct memory buffers. Это специальные объекты в Java, которые ссылаются на память вне кучи. Соответственно, они же её и аллоцируют, управляют жизненным циклом этой памяти, то есть определённая сборка мусора там всё равно есть. Чтобы такими буферами нельзя было занять бесконечно большое количество памяти, на них есть лимит, который JVM сама себе выставляет. Иногда возникает необходимость его подкорректировать, на что, естественно, есть магическая -XX опция, например,
-XX:MaxDirectMemorySize=16g. В отличие от нормального Out of Memory этот Out of Memory — recoverable, потому что он возникает в определённом месте и его возможно отличить от другого типа ошибок.Выделяем память в Java
Как я уже говорил, JVM на старте важно знать, сколько вы ей позволите использовать памяти, потому что исходя из этого строятся все эвристики сборщика мусора.
Сколько выделять памяти «в граммах» — это вопрос сложный, но вот основные тезисы:
- Вы должны понимать, сколько полезных объектов должны находиться в памяти постоянно (Live set). Это правильнее всего измерять эмпирически, то есть надо:
- производить тесты;
- делать Heap Dump;
- смотреть, из чего состоит куча и как она будет расти при увеличении числа запросов или количества данных.
- Молодое поколение либо берётся по умолчанию в процентном отношении от кучи, либо выставляется динамически. Например, фишка G1 collector как раз в том, что он сам умеет правильно выбирать размер young space. Для остальных сборщиков мусора лучше его выставлять руками, опять же исходя из эмпирических соображений.
- Сборщику мусора обязательно нужен резерв, так как для того, чтобы собирать мусор, он где-то должен в памяти быть. Чем больше у вас памяти под мусор, тем меньше CPU будет тратиться на 1 Гбайт освобождённой памяти. Этот баланс никогда нельзя «выкрутить в ноль». Размер резерва зависит от особенностей вашего приложения и используемого сборщика мусора, как правило, это 30–50%.
- Итого, общий размер вашей кучи (-Xmx) состоит из:
- размерамолодого поколения;
- размера live set;
- резерва.
- размерамолодого поколения;
Помимо кучи есть ещё direct buffers, какой-то резервJVM, который тоже надо определять эмпирически.
Таким образом footprint процесса в целом всегда будет больше, чем -Xmx, причем это не просто какой-то процент, а сочетание различных факторов вроде количества потоков.
Выделяем память в Linux
Двигаемся дальше, в Linux есть такая штука как ulimit — это такая странная конструкция, на мой взгляд джависта. Для процесса есть набор квот, который задает операционная система. Квоты есть разные, на количество открытых файлов, что логично, и ещё на какие-то другие вещи.

Именно для управления ресурсами ulimits работают не очень — для того, чтобы ограничивать ресурс контейнера, используется другой инструмент. В ulimits есть максимальный размер памяти, который на Linux не работает, но там же есть ещё максимальный размер виртуальной памяти. Это такая интересная штука, потому что, как я уже говорил, виртуальная память — не ресурс. В принципе, от того, что я зарезервирую 100 Тбайт адресного пространства, операционной системе ни холодно ни жарко. Но ОС скорее всего не даст мне этого сделать, пока я для своего процесса не становлю соответствующий ulimit.
По умолчанию этот лимит есть и может помешать запускаться вашей JVM, особенно опять же если размер JVM сопоставим с физической памятью, потому что значение по умолчанию часто считается как раз от размера физической памяти. Это вызывает некоторое недоумение, когда, допустим, у меня на сервере 500 Гбайт, я пытаюсь запустить JVM на 400 Гбайт, а она просто падает на старте с какими-то непонятными ошибками. Потом выясняется, что JVM на старте выделяет себе все эти адресные пространства, и в какой-то момент ОС ей говорит: «Нет, что-то много ты брешь адресного пространства, мне жалко». И, как я уже сказал, в этом случае JVM просто «умирает». Поэтому иногда этот параметрам нужно не забыть настроить.
Бывают другие клинические ситуации, когда люди почему-то решают, что если у них для JVM на сервере выделено 20 Гбайт, то надо ей размер виртуального адресного пространства тоже выставить в 20 Гбайт. Это проблема, потому что некоторые участки памяти, которые JVM резервирует, никогда не будут использованы, и их достаточно много. Таким образом вы намного сильнее ограничиваете ресурсы памяти этого процесса, чем можете подумать.
Поэтому обращаюсь к линуксоидам, пожалуйста, не делайте так, пожалейте своих джавистов.
Пару слов про Docker
То есть не про сам Docker, а про управление ресурсами в контейнере. В Docker управление ресурсами для контейнеров работает через механизм cgroups. Это механизм ядра, который позволяет для дерева процессов ограничить всевозможные ресурсы, например CPU и память. В том числе для памяти можно ограничить размер резидентной памяти, занимаемой всем контейнером, количество swap, количество страниц и др. Эти лимиты, в отличие от ulimits, нормальные ограничения на весь контейнер; если процесс форкает какие-то дочерние процессы, то они попадают в ту же группу ограничения ресурсов.
Что важно:
- Если вы запускаете Java в docker-контейнер, она смотрит, сколько на хосте физической памяти, и исходя из того, сколько физической памяти реально на хосте, а не в контейнере считает ограничения по умолчанию. И очень быстро умирает, потому что ей столько не дают. Поэтому -Xmx обязательно — без этого не взлетит.
- Всегда под контейнер надо давать немножко больше памяти, чем под JVM. Допустим, вы делаете контейнер на 2 Гбайта, запускаете JVM с параметром
-Xmx2048m, оно как-то начинает работать, потому что память аллоцируется лениво. Но потихонечку все эти страницы так или иначе начинают использоваться, и сначала ваш контейнер начинает уходить в локальный своп, а потом просто умирает. Причём умирает он в лучших традициях — просто исчезает.
Если оно просто стартовало, это ещё ничего не значит, потому что ресурсы выделяются реально лениво.
Потоки в Java
Про потоки в Java важно знать, что они — нормальные потоки операционной системы. Когда-то в первых JVM были реализованы так называемые green threads — зелёные потоки, когда на самом деле стек java-потока как-то жил своей жизнью, и один поток операционной системы выполнял то один java-поток, то другой. Это всё развивалось до тех пор, пока в операционных системах не появилась нормальная многопоточность. После этого все забыли «зелёные» потоки как страшный сон, потому что с нативными потоками код работает лучше.
Это значит, что stack trace на пол тысячи фреймов реально лежит в том пространстве стека, который выделила операционная система. Если вы вызываете какой-то нативный код из Java это код будет использовать тоже самый стек, что и java-код. Это означает возможность использования диагностического инструментария, который есть в Linux, для работы так же и с java-потоками.
Как найти java-потоки

Если мы воспользуемся командой ps для JVM, мы увидим такую непонятную картину, потому что все потоки называются одинаково. Но на практике там в порядке очереди идут:
- потоки сборщика мусора;
- так называемый operational thread JVM;
- application потоки,
но это наугад.

На самом деле? если вы снимете thread dump с JVM с помощью командыjstack, то там будет шестнадцатеричное число «TID» — это идентификатор реального линуксового потока. То есть вы можете понять, какие java-потоки соответствуют каким потокам операционной системы и расшифровать ps.
Единственное, если вы уже видите, как напишете скрипт на perl, который будет это делать, не вызывайте jstack в цикле, лучше наоборот. Потому что каждый раз, когда вы вызываете jstack, вы вызываете глобальную паузу всех потоков JVM. В нормальных обстоятельствах это быстро, меньше, чем полмиллисекунды, но если делать такое 20 раз в секунду, то это уже может заметно отразится на производительности.
Можно, так же, вытащить эту информацию из самой JVM, в которой есть свой диагностический интерфейс. В частности, можете воспользоваться моим инструментом, который оттуда эту информацию вытягивает и просто для JVM печатает топ по потокам. Помимо CPU usage он ещё умеет печатать интенсивность аллокаций памяти кучи Java потоками.
Итого о потоках

Java-потоки — это обычные потоки операционной системы. В современных версиях JVM есть ключ
PreserveFramePointer — это опция JIT-компилятора, позволяющая инструментам типа perf корректно парсить стек Java потоков.Также есть на GitHub проект, который позволяет экспортировать «на лету» символы для скомпилированного java-кода, и с помощью того же perf получать вполне читабельный стек вызовов.
И небольшое напоминание, что у нас есть ещё потоки сборщика мусора.
Если у вас контейнер, на котором вы выделили два CPU, то надо количество параллельных потоков сборщика мусора тоже сделать два, потому что по умолчанию их будет больше, и они будут друг другу только мешать.
С другой стороны, в тот момент, когда работает сборщик мусора, все остальные потоки не делают ничего. Поэтому под сборщика мусора можно выделять 100% ресурсов контейнера, которые вы собираетесь выделить для Java.
IO и Networking
Сетевому стеку в Linux нужен тюнинг. Про это очень хорошо помнят те, кто занимается фронтенд-серверами, например, с Nginx, но то же самое неплохо бы делать на application и бэкенд-серверах — про это иногда забывают. И всё работает нормально до тех пор, пока у вас система становится геораспределенной и не начинается перегон данных через Атлантику. И упс, оказывается, надо было увеличить лимит на буферы.

Если вы используете UDP коммуникации, это тоже требует отдельной настройки на уровне операционной системы. Есть опции, которые код сам должен выставлять через API на сокетах, но они должны быть разрешены на уровне лимитов операционной системы. Иначе они просто не работают.
Второй интересный момент связан с особенностями работы с ресурсами в JVM.
У нас есть ограниченный ресурс — лимит на количество файлов, куда попадают сокеты и т.д., для процесса. Если у нас этот лимит превышен, то мы не можем:
- открывать соединение;
- открывать файлы;
- принимать соединения и т.д.
В Java на всех этих объектах есть методы для того, чтобы их явным образом закрывать и, соответственно, освобождать дескрипторы Linux.

Но если ленивый джавист этого не сделал, то сборщик мусора придёт и всё равно за него всё закроет. И всё бы хорошо, если бы этот сборщик мусора приходил по расписанию, но он приходит, когда посчитает нужным. Если у вас вся куча забита незакрытыми сокетами, то с точки зрения кучи это копейки, потому что там лежат только метаданные этого сокета и номер дескриптора из операционной системы. Поэтому если у вас есть вот такая комбинация внешних ресурсов, на которые ссылается java-код, то сборщик мусора иногда может вести себя не очень адекватно в этом плане.
Соединения и файлы всегда надо закрывать руками.
Даже если у вас произошла ошибка на сокете, всё равно, после того как вы словили exception, сокет надо закрыть. Потому что с точки зрения операционной системы то, что она вернула вам код ошибки, и вы в Java получили exception, ещё не значит, что сокет закрыт. С точки зрения операционной системы он будет продолжать считаться открытым, и операционная система честно будет готова вернуть код ошибки снова при проверке следующего обращения к нему. Соответственно, если мы что-то неправильно сконфигурировали, а сокеты должным образом не закрываются, через какое-то время лимит на файлы закончится, и приложению станет совсем плохо.
Есть пара ресурсов в JVM, которые нельзя освободить явным образом:
- memory map файлы;
- NIO direct buffers.
Поэтому с ними надо работать аккуратно, и желательно не выбрасывать, а переиспользовать. С точки зрения диагностики у нас есть heap dump, из которого всю эту информацию можно вытащить.
И, наконец, последние напутствия.

Выставляйте правильный размер JVM. Сама JVM не знает, сколько памяти ей нужно взять.
Учитесь пользоваться инструментами, в Linux есть инструменты, которые достаточно неплохо работают с Java, в JDK есть инструменты, которые позволяют получать много информации именно через командную строку. В Java есть JMX (Java Management Extensions) диагностический интерфейс, но для того, чтобы с ним работать, нужен другой java-процесс, что не всегда удобно.
В частности, не забывайте, про сочетание инструментов. Например, если у вас есть Linux core dump JVM, то вы можете с помощью инструментов JDK вытащить из него heap dump для Java и посмотреть его уже нормальным джавовским анализатором вместо того, чтобы делать этот heap dump непосредственно с живого процесса.
И уже совсем напоследок несколько ссылок на разные темы.
Java Memory Tuning and Diagnostic:
- http://blog.ragozin.info/2016/10/hotspot-jvm-garbage-collection-options.html
- https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html
- Using JDK tools with Linux core dumps
https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/bugreports004.html#CHDHDCJD
Linux Transparent Huge Pages reading:
- https://www.perforce.com/blog/tales-field-taming-transparent-huge-pages-linux
- https://tobert.github.io/tldr/cassandra-java-huge-pages.html
- https://alexandrnikitin.github.io/blog/transparent-hugepages-measuring-the-performance-impact/
Profiling and performance monitoring:
Контакты:
Если у вас остались вопросы, то можно перескочить на соответствующую часть
доклада, может быть, кто-то это уже уточнил.
Короткое послесловие
РИТ++ уже 28 и 29 мая, расписание здесь, а это прямая ссылка на покупку билетов.
До Highload++ Siberia времени чуть больше, она пройдет 25 и 26 июня. Но программа уже активно формируется, вы можете подписаться на рассылку и быть в курсе обновлений.
Комментарии (12)

Mishiko
16.05.2018 14:53Существенная проблема запуска Java-приложений на Linux — это работа с файловой системой: местоположение tmp, права на папки и файлы, лимит на файловые дескрипторы (раз уж вспомнили ulimit).
Еще не увидел ничего про StackOverflowError (threads-max, ulimit -s) — тоже популярные грабли в многопоточных приложениях.
degs
16.05.2018 21:04в момент вызова этой команды у вас произойдёт форк, который. приведёт к тому, что образ JVM будет продублирован
Вот тут как-то сомнительно. А как же copy-on-write? Или совсем уж древний vfork()?
loginsin
16.05.2018 23:35JAVA в Linux (в Windows, как правило, стандарт де-факто — JVM от самих Oracle. Там попроще, но не всегда) превращается в боль, к примеру, когда есть
зоопарк серверов разной степени свежести и где Remote console сделана в виде jar-ников. И тогда начинается гуглеж… От простейшего: «запусти Java Configure, зайди в Security, добавь хост (а их взоопарке много) в список доверенных, кильни все jvm процессы, перезапусти браузер со всеми его вкладками» до ковыряния глубоко упрятанных каких-то конфигов. При этом вероятность того, что ты в эту консоль попадешь, остается весьма низкой.
Зато увидишь много различных окон об опасности запуска подобных jar-ников:
«Файлик-то получен не из доверенного источника. Запустить?»
«О! Еще он не по https получен. Точно-точно запустить??»
«Так по https сертификатик-то такой себе… Точно-точно-точно запустить?»
«Да ну, он не соответствует моим политикам безопасности. Не запущу!» (здесь экран монитора уже разбит)
Не, можно понять обеспокоенность безопасностью запуска недоверенного софта. Но сделайте же вы кнопулечку (может и слегка спрятанную где-то в показанном диалоге о предупреждении нарушения безопасности): «Вот прям сейчас я хочу довериться этому jar-нику как самому себе, потому что мне это очень надо!!!»
Отдельного котла заслуживают те, кто встраивает ява-апплеты прямо в веб-страницу на своем сайте (хотя, к счастью, это мало сейчас уже распространено).Areso
17.05.2018 08:09Широко распространено в сфере ГОСТовских ЭП/ЭЦП. Всякие госзакупки, еговы, госуслуги и тому подобное.
Regis
17.05.2018 03:40Java никогда не отдаёт память операционной системе
Неправда же!
Например, если используется Shenandoah GC, то память вполне может возвращаться обратно операционной системе.
firk
Очень много воды.
Это что вообще за нелепое нытьё ни о чём? Если убрать ерунду, останется предложение "java-программы склонны жрать много ресурсов и сложно понять, на что они там расходуются".
По поводу остального — весьма странно проводить "сравнение" между системным менеджером памяти и менеджером памяти уровня приложения. Это примерно то же самое, как делать сравнительные таблицы между протоколами TCP и FTP. Объяснить особенности работы обоих менеджеров, приводящие к известному поведению памяти — полезная идея, но не надо было оформлять это сравнением.
DoctorMoriarty
Я бы вообще поставил под сомнение допустимость самой этой формулировки. Раз на Linux-сервер в принципе, с точки зрения самой ОС, а не какой-то там идеологии про «чужеродное», можно поставить JVM и можно запустить на исполнение jar и т.п. — то всё это вполне себе есть часть «мира».
vagran
К тому же всё это относится и к другим ОС. При чём тут Линукс.