

В статье приведён анализ решений в сфере IDS и систем обработки траффика, краткий анализ атак и разбор принципов функционирования IDS. После чего сделана попытка разработки модуля для обнаружения аномалий в сети, на основе нейросетевого метода анализа сетевой активности, со следующими целями:
- Обнаружение вторжений в вычислительную сеть.
- Получения данных о перегрузках и критических режимах работы сети.
- Обнаружение проблем с сетью и сбоев в работе сети.
Цели и задачи статьи
Целью статьи является попытка применения аппарата нейронных сетей в прикладной области, в основном ради изучения вопроса.
Задачей, реализующей цель, будет построение нейросетевого модуля обнаружения отклонений в работе сети передачи данных от её нормальных режимов.
Структура статьи
Исследование и обоснование:
- Типы систем обнаружения вторжений.
- Краткое исследование рынка существующих решений.
- Краткое исследование работ в области нейросетевых решений.
Разработка:
- Требования к модулю и выполняемые им задачи.
- Проектирование модуля.
- Реализация концепта.
- Заключение:
- Тестирование концепта.
- Возможности по улучшению.
- Использованные материалы.
Типы систем обнаружения вторжений
Существует классическое деление СОВ на [11]:
- Системы уровня сети, на которые отводится трафик с маршрутизатора (Network-based).
- Системы уровня хоста, которые обнаруживают изменения на отдельно взятой машине, например анализируя журналы или сетевую активность (Host-based).
- Системы, основанные на оценке уязвимостей (Vulnerability-assessment).
В данной статье я хочу несколько расширить это деление.
Собственно, целью любой такой системы является ответ на вопрос: есть ли проблемы и какие?
Решение выносится на основе полученных данных.
Т.е. задачи системы состоят из:
- Получения данных.
- Интерпретации полученных данных.
- Представления результата.
Соответственно, все системы возможно позиционировать по значениям следующих признаков:
- Тип собираемых данных.
- Метод получения данных.
- Метод интерпретации данных
- Метод представления результата.
Внесистемной характеристикой я считаю тип реакции на результат:
- Информационный.
- Активный.
В первом случае, производится информирование заинтересованных лиц.
Во втором — активные действия, например блокирование диапазона адресов атакующего.
По этому признаку данные системы обычно искусственно разделяются на IDS и IPS.
Характеристика эта внесистемная, потому что я предполагаю разбиение системы
на "разведывательную" и "силовую" части. И любая IDS может быть включена в состав IPS.
Далее, к этому вопросу я не буду возвращаться.
Классы типа собираемых данных
Следуя классическому делению, я введу два класса и добавлю третий, чтобы возможно было представить класс, как "координату в конфигурационном пространстве" (просто для того, чтобы позже все перестановки быстро получить):
- Данные, собираемые об узле сети.
- Данные, собираемые обо всей сети.
- Гибридная система.
Типы данных, собираемые об узле сети — это данные, которые касаются только одного узла и частично тех, кто с ним взаимодействует.
Анализ таких данных позволяет ответить на вопрос: "Идёт ли атака на данный хост?"
Как правило, удобнее собирать эти данные непосредственно на узле, но это не обязательно.
Например, сетевые сканеры могут получить список открытых портов на конкретном узле извне, не имея возможности запускать там код.
Этот класс включает данные следующих типов (к каждому из которых относятся конкретные собираемые показатели):
- Сетевая активность узла.
- Сетевые настройки узла.
- Данные о файлах (списки и контрольные суммы, метаданные, действия с файлами и т.п..).
- Данные о процессах.
При этом, узлы могут быть как рабочими станциями, не предполагающими их использования в качестве серверов, предоставляющих службы, так и серверами.
Я разделяю хосты на типы, потому что хочу выделить отдельный случай: хост может быть специально сделан уязвимым, с целью изучения методов атак (в том числе дообучения нейронных сетей) и выявления атакующих узлов.
Возможно предполагать, что любое взаимодействие с данным узлом будет являться попыткой атаки.
Данные, собираемые о сети — это цельная картина сетевого взаимодействия.
Как правило, полные сетевые данные не собираются, т.к. это ресурсоёмко и считается, что нарушитель либо не может находиться внутри сети, либо ему обязательно нужна связь с внешним миром (что, конечно, не обязательно так, ведь провести атаку возможно и на физически изолированную сеть, для чего существуют техники "преодоления воздушного зазора").
В этом случае, IDS анализирует трафик, идущий через маршрутизатор, для чего в маршрутизаторе имеется SPAN порт, с которого трафик перенаправляется в IDS.
В принципе, ничего не мешает собирать данные с узла, на котором работает IDS, это даже полезно и привносит дополнительный контроль.
Также возможно собирать трафик сети на её узлах. Но это заставляет сетевой адаптер узла работать в режиме захвата всего трафика, чего обычно не предполагается при штатной работе, плюс это явно избыточно (единственный вариант, когда это может быть полезно, с большой натяжкой, — распределённый анализ потока).
Классы методов получения данных
Классы методов получения данных:
- Пассивный. Система не влияет напрямую на работоспособность сети. Она просто производит анализ трафика.
- Активный. Система пытается провести "разведку боем", активно воздействуя на сеть, например с целью найти знакомые сигнатуры в ответном трафике.
- Смешанный. Используются оба вышеуказанных класса.
Пассивное обнаружение
При пассивном обнаружении, система просто наблюдает за обстановкой. Большинство IDS используют данный класс методов. Системы уровня хоста также, обычно используют данный класс методов. Например, они не пытаются удалить системный файл из под пользователя и проверить, что он был удалён, а просто оценивают соответствие прав на данный файл, шаблону в базе, и если соответствие не наблюдается, выдают предупреждение.
Активный поиск уязвимостей
В данном классе методов ошибки провоцируются путём некоторых действий, как известных, так и неизвестных (fuzzy системы).
После этого, по базе анализируется реакция на данные действия. Данный класс методов характерен для сканеров уязвимостей.
Для интерпретации результатов применимы оба класса методов:
- Есть вариант анализа ответов по базе (например, характерные ответы на типичные шаблоны SQL инъекций), либо поведенческий анализ (как себя стала после этого цель вести и как отвечает на следующие запросы).
Например, посылка некорректно составленного IP пакета должна привести к падению уязвимого сервера, после чего он перестанет отвечать. - Есть вариант обнаружения аномальной активности.
Например, если после посылки ICMP пакета размером 777 байт с заполнением 0xDEADBEEF, в сети резко возрастает уровень сетевой активности, а затем падает — это аномалия (нормальная ситуация — уровень сетевой активности не меняется).
Плюсы очевидны:
- Превентивное обнаружение вторжений.
Какая-либо атака может ни разу не произойти, но сеть будет оставаться к ней уязвимой.
Данный класс методов выявит потенциальные уязвимости. - Проверка сети аналогично атакующему, что повышает шансы обнаружить уязвимости.
Минусы:
- Дополнительная нагрузка на сеть.
- Возможность реализовать успешную атаку в процессе сканирования, например DoS некоторых сервисов.
- Как правило, зависимость от базы атак, которая устаревает.
- Неочевидный минус — иллюзия безопасности. Может возникнуть ощущение, что "если сканер ничего не нашёл, то всё ok".
При этом, риски направленных атак всё-равно остаются. Этот риск, возможно в меньшей степени, имеет место быть и для других классов методов.
Классы методов интерпретации данных
Возможно выделить следующие классы, каждый из которых может включать несколько методов:
- Методы обнаружения известных нарушений.
- Методы обнаружения аномалий.
- Смешанный метод, включающий оба вышеназванных.
Обнаружение известных нарушений
Сводится к поиску признаков уже известных атак.
Преимущества:
- Методы почти не подвержены ложным срабатываниям.
- Методы, реализованные как сопоставление с образцом, как правило выполняются достаточно быстро и не требуют больших затрат ресурсов.
Недостатком этих методов является невозможность обнаруживать неизвестные системе атаки.
В классическом варианте реализация предполагает сравнение сигнатур пакетов с сигнатурами в базе. Сравнение может быть, как точное, так и с шаблоном или по регулярному выражению.
Большинство известных IDS используют методы данного класса.
Сюда же возможно отнести методы нечёткого сравнения:
- Обученный перцептрон.
- Методы сравнения с нечёткой логикой.
Обнаружение аномалий
Суть в том, чтобы записать шаблон нормальной активности сети и реагировать на отклонения от этого шаблона.
Возможен вариант реализации в виде базы сигнатур "нормальных" пакетов в сети
и статистической системы обнаружения отклонений, когда анализатор ищет какие-то редкие действия, или активности. События в системе исследуются статистически, чтобы найти те из них, проявление которых выглядит аномальным.
Представленный ниже детектор будет пытаться обнаружить аномалии.
Методы представления результата
Как показал анализ существующих решений, обычно используются два типа методов:
- Двуклассовый. Система отвечает на вопрос "Есть ли проблемы?", ответом "да/нет".
Данный способ характерен для академических статей и исследований, но он может быть применим для написания модулей или датчиков реальных СОВ. - Многоклассовый. Система отвечает на вопрос "Какие сейчас есть проблемы?". Если проблем нет, то "никакие".
Результат также может быть представлен с определённым уровнем достоверности. И любая нейросеть представляет результат, не как "да" или "нет", а как множество вероятностей результатов.
В существующих подходах вероятность аппроксимируется к единичной или нулевой (например, изо всех возможных атак на выходе сети, выбирается первая с самой высокой вероятностью) и нигде дальше не учитывается.
Типы IDS
На данном этапе параметр "Метод представления результата" не представляет интереса (он был введён для разделения детекторов).
from itertools import product
data_type_class = ('host_data', 'net_data', 'hybrid_data')
analyzer_type_class = ('passive_analyzer', 'active_analyzer', 'mixed_analyzer')
detector_type_class = ('known_issues_detector', 'anomaly_detector', 'mixed_detector')
liter = list(product(data_type_class, analyzer_type_class, detector_type_class))
print(len(liter))
for n, i in enumerate(liter):
print('Type {}:\ndata_type_class = {}, analyzer_type_class = {}, detector_type_class = {}.'.format(n, i[0], i[1], i[2]))
print('-' * 10)Далее, я сведу их в меньшее количество типов:
- Типы: 0, 1, 2. IDS уровня узла, основанная на поиске сигнатур, обнаруживающая аномальное поведение, либо гибридная. Подобных IDS существует достаточно много. Сюда же возможно отнести антивирусы.
- Типы: 3, 4, 5. Сканер уязвимостей уровня узла, основанный на поиске сигнатур, обнаруживающий аномальное поведение, либо гибридный. Сканеры незакрытых уязвимостей. Функционал встроен в антивирусы. С натяжкой в качестве представителя группы возможно выделить AVZ. Далее я этот тип отдельно не разбираю.
- Типы: 6, 7, 8. Гибридные IDS уровня узла, как отслеживающие атаки пассивно, так и позволяющие провести активное сканирование.
- Типы: 9, 10, 11. IDS уровня сети, основанная на поиске сигнатур, обнаруживающая аномальное поведение, либо гибридная.
- Типы: 12, 13, 14. Сканер уязвимостей уровня сети, основанный на поиске сигнатур, обнаруживающий аномальные реакции, либо гибридный.
- Типы: 15, 16, 17. Гибридная IDS уровня сети, обнаруживающая аномальное поведение, либо гибридная. Должна позволять, как проводить сканирование, так и обнаруживать проблемы в пассивном режиме. Это комплексные решения уровня сети. Обычно, они не существуют в таком виде и сливаются со следующим типом.
- Тип 26 (типы 18-25 обычно не имеют смысла по отдельности и сводятся к данному типу). Гибридная система, основанная на агентах, каждый из которых может иметь один из вышеперечисленных типов.
- Отдельным пунктом, который не попадает в классификацию, потому что не является IDS, но имеет место быть как вспомогательная система, является honeypot.
Ниже указаны примеры существующих решений, попадающие в вышеназванные группы.
Существующие решения
Действующие системы
Snort
Snort является классической IDS уровня сети и анализирует трафик на совпадение с базой правил (фактически с базой сигнатур). Т.е., данная система ищет известные нарушения. Для Snort возможно несложно реализовать свой модуль, что и было сделано в одной из работ. На базе Snort реализовано много известных коммерческих решений, в том числе русских.
Помимо работы с базой сигнатур, построенная на базе Snort IDS, вполне может иметь в своём составе эвристические, нейросетевые и подобные модули обнаружения. Как минимум, существует в рабочем виде статистический детектор аномалий для Snort.
Suricata
Suricata также, как и Snort является системой уровня сети.
У данной системы есть несколько особенностей:
- Базы сигнатур совместимы со Snort.
- Оценивает не только сетевой/транспортный уровень, но работает и на уровне прикладных протоколов.
- Есть возможность реализовывать правила на Lua, интерпретируемом языке, что расширяет диапазон возможностей.
- Может анализировать трафик между двумя хостами, в целом, а не только отдельные пакеты/соединения. Это позволяет, например, обнаруживать попытки подбора паролей.
- Есть подсистема IP reputation, позволяющая присваивать "уровень репутации" каждому IP адресу.
Т.е., эта система, хотя и обнаруживают известные нарушения, также как предыдущая, обладает большей адаптивностью и возможностью обучаться (уровень репутации хоста может изменяться в процессе работы системы и влиять на принятие ей решения).
Bro
Платформа для создания IDS уровня сети. Является гибридной системой, с упором на обнаружение известных нарушений. Работает на транспортном, сетевом уровне и уровне приложений. Поддерживает свой язык сценариев.
Имеется возможность обнаружения аномалий, например, множественное подключение к сервисам на разных портах — не свойственное для нормального узла поведение, которое будет обнаружено.
Это реализовано, во-первых, на основе на основе проверок передаваемых данных на нормальность (например, TCP-пакет со всеми установленными флагами, наверное тут что-то не то, несмотря на то, что он корректен).
Во-вторых, на базе политик, описывающих как должна функционировать сеть в норме.
Bro не только обнаруживает атаки, но также помогает при диагностике сетевых проблем (заявленный функционал).
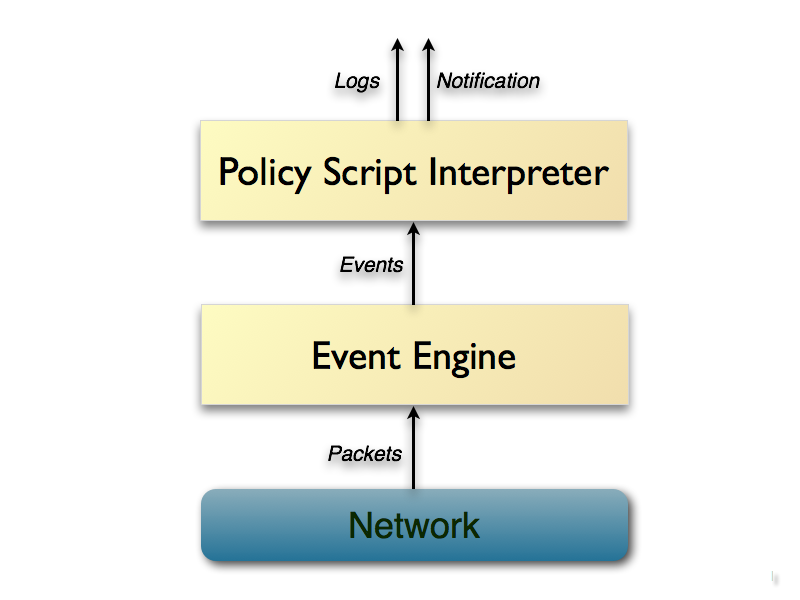
Технически Bro реализован достаточно интересно: он не производит анализ трафика напрямую по признакам, а прогоняет пакеты на "событийной машине", которая преобразует поток пакетов в серию высокоуровневых событий.
Эту машину возможно считать дополнительным уровнем абстракции, позволяющим отобразить сетевую (как правило, хотя и не обязательно) активность в терминах нейтральных относительно политик (события просто сигнализируют, о том, что нечто произошло, но о том почему, событийный движок ничего не говорит, т.к. это задача интерпретатора политик).
Например, HTTP запрос будет преобразован в событие http_request с соответствующими параметрами, которое передаётся на уровень анализа.
Интерпретатор политик выполняет сценарий, в котором устанавливаются обработчики событий. В данных обработчиках могут рассчитываться статистические параметры трафика. При этом, обработчики могут сохранять контекст, а не просто реагировать на отдельно взятый пакет.
Т.е., учитывается временная динамика, "история" потока.
Краткая схема работы ядра Bro:
TripWire, OSSEC, Samhain
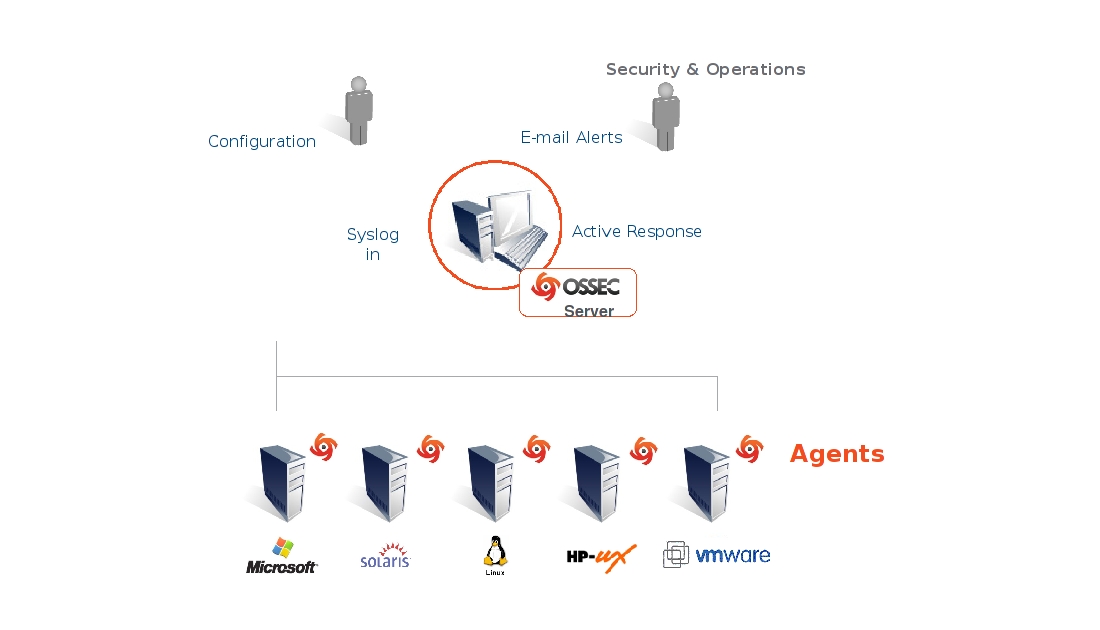
По классической терминологии, это представители систем уровня хоста.
Совмещают в себе методы обнаружения известных нарушений и методы поиска аномальной активности.
Механизм поиска аномалий основан на том, что при установке, система сохраняет в базе хэши системных файлов и метаинформацию о них. При обновлении пакетов операционной системы, хэши пересчитываются.
В случае неконтролируемого изменения какого-либо наблюдаемого файла, через некоторое время система даст об этом знать (как правило, сканирование запускается планировщиком, хотя возможны системы, реагирующие на события ФС).
Помимо наблюдения за файлами, данные системы могут наблюдать за процессами, соединениями и анализировать системные журналы.
Также, ими может использоваться база известных нарушений, которая периодически обновляется.
Некоторые имеют централизованный интерфейс, который позволяет анализировать данные одновременно на многих узлах.
Неплохо суть описана на сайте Samhain:
The Samhain host-based intrusion detection system (HIDS) provides file integrity checking and log file monitoring/analysis, as well as rootkit detection, port monitoring, detection of rogue SUID executables, and hidden processes.
Samhain been designed to monitor multiple hosts with potentially different operating systems, providing centralized logging and maintenance, although it can also be used as standalone application on a single host.
Пример развёртывания OSSEC:
Prelude SIEM, OSSIM
Это гибридные системы, позиционируемые, как SIEM. Prelude сочетает в себе сенсорную сеть и анализатор. Заявлено, что данная система обеспечивает повышенный уровень безопасности, поскольку взломщик может обойти одну IDS, но сложность обхода многочисленных механизмов защиты возрастает экспоненциально.
Система хорошо масштабируется: по заявлениям разработчиков, сенсорная сеть может покрывать континент или даже мир.
Система совместима со многими существующими IDS по формату данных (IDMEF) в том числе с: AuditD, Nepenthes, NuFW, OSSEC, Pam, Samhain, Sancp, Snort, Suricata, Kismet и т.д..
Примерно тоже самое возможно сказать про OSSIM.
Сканеры уязвимостей
Это системы, которые занимаются активным поиском уязвимостей на узле, либо в сети.
Самые простые ищут только известные проблемы, которые есть в базе, более серьёзные системы могут совмещать в себе как методы обнаружения известных нарушений, так и аномальной активности.
Сканеры уязвимостей появились давно и наделать их успели достаточно много.
Приведу только несколько известных продуктов, которые представлены на рынке:
- Nmap — бесплатный сетевой сканер, который используют скорее, как вспомогательный инструмент: он позволяет определить ОС, получить список открытых портов и сервисов, которые их открыли, и т.п… При этом, включает Netmap Scripting Engine, что позволяет на его основе строить автоматизированные решения (например, совместить сканирование с запуском брутфосера на нужных портах).
- XSpider — классический сканер уязвимостей с базой, эвристиками, поиском аномального поведения и т.д..
- Metasploit — фреймворк, содержащий наборы эксплоитов, сканеры, готовые нагрузки, запускаемые на атакуемом узле и т.п… Позволяет провести исследование узла или группы узлов на подверженность известным уязвимостям.
- OpenVAS — фреймворк, сочетающий в себе сканер и решение для управления уязвимостями. Содержит базу с более чем 50000 уязвимостями, опознаёт указанные цели и проверяет их реакцию на применение соответствующих эксплоитов.
Возможности данных систем на примере вышеприведённого XSpider:
- Идентификация сервисов на случайных портах для выявления уязвимостей серверов с нестандартной конфигурацией.
- Эвристический метод определения типов и имен сервисов (HTTP, FTP, SMTP, POP3, DNS, SSH и др.) для определения настоящего имени сервера и корректной работы проверок.
- Обработка RPC-сервисов (Windows и *nix) с полной идентификацией, включая определение детальной конфигурации компьютера.
- Проверка слабости парольной защиты: оптимизированный подбор паролей практически во всех сервисах, требующих аутентификации.
- Глубокий анализ контента веб-сайтов, включая выявление уязвимостей в скриптах: SQLi, XSS, запуск произвольных программ и др.
- Анализ структуры HTTP-серверов для поиск слабых мест в конфигурации.
- Расширенная проверка узлов под управлением Windows.
- Проведение проверок на нестандартные DoS-атаки.
- Возможность автоматизации.
Honeypot
Системы специально сделанные уязвимыми, с целью привлечения к ним атак. Могут быть использованы для исследования действий атакующего.
Пример развёртывания:
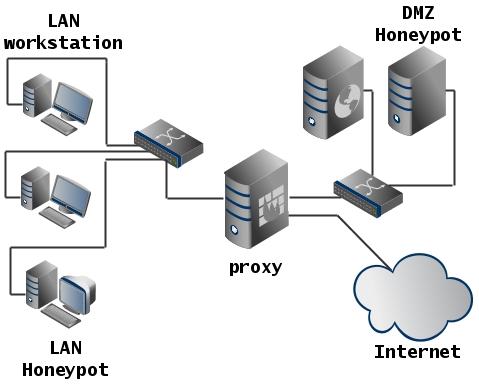
- HoneyWeb — honeypot, запускающий WEB сервисы.
- Honeyd — позволяет создавать виртуальные хосты, на которых работают сервисы. Может эмулировать разные ОС.
Вообще, готовых honeypot решений достаточно много.
Сюда же могут относиться ловушки типа tarpits, замедляющие атаку (повышает требования к ресурсам атакующего, даёт время на реагирование), которые возможно считать "активным" вариантом honeypot.
Варианты подходов к решению задачи и нейросетевые решения
В работе [14] проведён анализ упоминаний широко используемой базы KDD.
- Машины опорных векторов — 24.
- Решающие деревья — 19.
- Генетические алгоритмы — 16.
- Метод главных компонент — 13.
- Метод роя частиц — 9.
- Поиск k-ближайших соседей — 9.
- Кластеризация по k-значениям — 9.
- Наивные Байесовские классификаторы — 9.
- Нейросети, многослойный перцептрон — 8.
- Генетическое программирование — 6.
- Грубые множества — 6.
- Байесовы сети — 5.
- Лес случайных деревьев — 5.
- Искусственная имунная система — 5.
- Использование нечётких правил (Fuzzy Rules Mining) — 4.
- Нейронные сети (самоорганизующиеся карты) — 4.
Как видно, нейронные сети в работах за 2015-2016 годы представлены не столь широко, к тому же, это как правило, сети прямого распространения.
На практике же, решения, в том числе и приведённые выше, в основном опираются на следующие технологии анализа:
- Методы обнаружения известных нарушений:
- Сигнатурный анализ. Сравнение сигнатуры данных, либо сигнатуры поведения с сигнатурой в обновляемой базе. Сигнатура может быть представлена также шаблоном или регулярным выражением.
- Экспертные системы на основе правил [1] .
- Методы обнаружения аномалий:
- Пороговые детекторы (реагирующие, например, на стабильное превышение загрузки CPU на сервере) [1] .
- Статистические системы (например, Байесовские классификаторы, либо системы обучаемых классификаторов).
- Поведенческий анализ (возможно отнести к нечётким правилам).
- Использование модели "искусственная имунная система".
Про некоторые варианты решений, которых я не коснулся, возможно также посмотреть здесь.
У данных решений есть свои проблемы:
- Сигнатурный поиск не реагирует на неизвестные атаки, и достаточно не сильно больших изменений сигнатуры атаки, для того, чтобы детектор её более не обнаружил.
- Для экспертных систем, основанных на правилах, также как и для сигнатурного поиска, требуется поддерживать актуальность базы.
- Для систем основанных на правилах, незначительные вариации в последовательности действий при атаке могут повлиять на процесс сравнения "деятельность-правило" до такой степени, что атака не обнаруживается соответствующим механизмом обнаружения. Увеличение уровня отвлеченности у таких систем предоставляет частичное решение этой задачи, однако это сильно увеличивает число ложных срабатываний [10].
- Системы на основе правил зачастую не обладают достаточной гибкостью в структуре правил.
- Статистические системы не чувствительны к порядку следования событий (что верно не для всех существующих систем).
- Для них и для пороговых детекторов трудно задать пороговые значения отслеживаемых системой обнаружения атак характеристик.
- С течением времени, статистические системы могут быть переобучены нарушителями так, чтобы атакующие действия рассматривались как нормальные.
Нейронные сети, прежде всего стоит рассматривать, в качестве замены статистических детекторов аномалий, либо дополнения к ним, но в какой-то мере, они могут заменить сигнатурный поиск и прочие методы.
Кроме того, гибридные системы, скорее всего будут применяться в ближайшем будущем.
Нейронные сети имеют, как свои преимущества:
- Возможность анализа неполных входных данных или зашумлённого сигнала.
- Отсутствие необходимости формализации знаний (заменяется обучением).
- Отказоустойчивость: выход из строя некоторых элементов сети или разрушение связи не всегда делает сеть полностью неработоспособной.
- Возможность простого распараллеливания работы.
- Нейронные сети требуют меньшего вмешательства оператора.
- Существует вероятность обнаружения неизвестных атак.
- Сеть способна обучаться автоматически и в процессе работы.
- Возможность обработки многомерных данных без сильного увеличения трудоемкости.
Так и недостатки:
- Большинство подходов являются эвристическими и часто не приводят к однозначным решениям.
- Для построения модели объекта на основе нейростей требуется предварительное обучение сети, что требует вычислительных и временных затрат.
- Для того, чтобы обучить сеть, надо подготовить обучающую и тестовую выборки, что не всегда просто.
- Обучение сети в ряде случаев приводит к тупиковым ситуациям: сети могут быть подвержены переобучению, либо не сходиться.
- Поведение сети не всегда может быть однозначно предсказуемо, что вносит риски ложных срабатываний, либо пропуска инцидентов.
- Трудно объяснить, почему сеть приняла то или иное решение (проблема вербализации).
- Следовательно невозможно гарантировать повторяемость и однозначность получения результатов.
Существующие решения и предложения, основанные на нейронных сетях
Обобщу подходы, описанные в литературе:
- В работах Мустафаева [2], Жигулина и Подворчана [6], Halenar [7] предлагается использовать многослойный перцептрон, предварительно обученный на базе атак (например, KDD).
- В работе Haibo Zhang [3] и соавторов предлагается использовать нейронную сеть и вэйвлет-преобразование.
- Min-Joo Kang [4] и соавторы используют глубокое обучение для обнаружения проблем в бортовой CAN сети автомобиля.
- Талалаев и соавторы [8] предлагают использовать рециркуляционную нейронную сеть или метод главных компонент для сжатия пространства признаков, после чего исследуют применение как двуслойного перцептрона, так и карты Кохонена.
- Балахонцев и соавторы [10] используют трёхслойный перцептрон.
- Корнев и Пылькин [13] исследуют существующие подходы и указывают на возможность применения перцептронов с разным количеством слоёв, однослойных классификаторов для детектирования нормального состояния, а также гибридной сети, состоящей из карты Кохонена и перцептрона.
И практически используемые:
- Компания DeepInstinct предлагает решения с использованием глубокого обучения, но деталей технологии, которую они используют, и каких-либо сравнений я не не нашёл. Судя по тому, что у них представлено на сайте, они используют обучение с учителем.
- По неофициальным данным, разработка нейросетевых детекторов активно ведётся компаниями, в том числе и несколькими российскими.
Выводы по существующим решениям
Средства управления и мониторинга СПД эволюционируют в сторону комплексных решений.
Современные системы, в целом стремятся к тому, чтобы не только выполнять узкую задачу обнаружения вторжений, но и помогать в диагностике неисправностей сети, при этом реализуя как методы обнаружения аномалий, так и методы обнаружения известных нарушений.
В состав такой комплексной системы входят различные распределённые по сети сенсоры, которые могут быть, как пассивными, так и активными. Используя данные сенсоров, которыми могут являться целые экземпляры IDS, центральный коррелятор (в терминологии Prelude SIEM) анализирует общее состояние сети.
При этом, возрастают объёмы данных, которые требуется обработать, и их размерность.
В литературе, в основном, рассмотрены нейросетевые методы, основанные на перцептронах, либо картах Кохонена. Есть не заполненная ниша в виде разработок, на базе последних исследований, касающихся соревновательных нейросетей или свёрточных сетей. Хотя данные методы хорошо себя зарекомендовали в смежных областях, где требуется сложный анализ.
Явно наблюдается разрыв между потребностями рынка и предложением в виде существующих решений.
Поэтому, имеет смысл проводить исследования в данном направлении.
Проектирование модуля
Возможные атаки
Чтобы понять от чего надо защищаться, стоит определиться, где искать атаки, и что они из себя вообще представляют [16].
Во-первых, рассматривать канальный уровень и ниже я не буду, поскольку его протоколы специфичны для оборудования и большинство IDS не работает на данном уровне (здесь есть, разве что обнаружение ARP спуфинга, специфичного для Ethernet, про обнаружение же атак на PPP и подобные протоколы, я недостаточно знаю).
Если смотреть на динамику атак по уровням, видно что с сетевого и транспортного в конце 90-х — начале 2000-х, они смещаются в сторону прикладного уровня.
Ранее были популярны атаки типа Ping of the Death, IP Spoofing, SYN flood или ARP cache poison, а сейчас нижний уровень начинается где-то в районе DNS.
От атак типа инъекций кода (например, SQL injection или PHP injection), которые ещё изредка встречаются, атакующие перешли к XSS и CSRF, которые они могут использовать для получения учётных данных, либо для выполнения неавторизованных запросов на серверах внутри сети.
Сейчас кроссайтовый скриптинг закрыт в большинстве фрэймворков. Но может оставаться в самописных сайтах (в том числе, прошивках устройств).
Активно проводятся атаки на Active Directory, из относительно свежих "олд-скул" атак на протоколы известна атака на SMB.
Пока не завершён переход на HTTPS с HSTS, могут встречаться атаки типа SSL stripping.
Также, могут быть использованы эксплоиты для устаревших версий ПО (например, тот же, наделавший много шуму HeartBleed), от чего может помочь сканирование сети.
Эти атаки проводятся, прежде всего с целью перехвата управления или раскрытия данных.
Отдельно стоит выделить DoS атаки, которые как правило, проводятся на конкретный сервер.
Прежде они могли реализовываться на транспортном уровне (например, SYN Flood) и ниже, теперь же, чаще всего реализуются на прикладном (например, посылкой большого количества HTTP запросов) в виде DDoS.
Фишинговые атаки также пока не потеряли своей актуальности.
Во-вторых, рассматривать только сетевые атаки было бы наивно. В конечном итоге, не имеет значения, как будет осуществлён DoS: атакой на канал сервера, либо через взлом Windows-машины администратора сети, хранящей SSH ключи. Мало того, атака на целевые узлы сети часто начинается с захвата наиболее уязвимых пользовательских узлов.
Кроме того, "классические" атаки прикладного уровня (например, на сервисы, такие как ftpd, либо дырявый sendmail), также уступают место атакам на уровне хоста. Причём, многие из них сейчас требуют тех или иных действий пользователя: просмотра каталога, открытия pdf документа, перехода на сайт и т.п..
Обнаружение атак уровня хоста IDS уровня сети не столь эффективно: как правило, атакующий рассчитывает на то, что сообщения будут проверены. Потому могут быть использованы обфускация, шифрование, либо внесение атакующего агента через сторонние каналы, в обход сети.
С задачами обнаружения таких атак справляется антивирус. Но антивирус, без централизованного управления и анализа данных способен только лишь распознать локальную угрозу и устранить её.
Он не способен определить, что это: случайно попавший файл, неудачная попытка целевой атаки с использованием плохо обфусцированного агента, либо начало проникновения червя в сеть.
Также, использование буткитов, как правило, сводит функционирование антивируса на нет.
В-третьих, для осуществления почти любой атаки требуется знание о сети (пример, когда не требуется: физическое отключение сегмента, — и то здесь надо быть уверенным, что канал связи с внешним миром только один). Это знание возможно получить прямо или косвенно (кражей данных о топологии, например). Прямое получение данных о сети и её узлах осуществляется за счёт сканирования.
Сканирование подразделяется на следующие типы:
- Поиск узлов сети посредством сканирования диапазона адресов.
- Обнаружение сервисов, предоставляемых узлом, посредством сканирования диапазона портов.
- Обнаружение узлов, предоставляющих сервисы, например посылая широковещательные запросы.
Сканирование диапазона адресов может быть совмещено со сканированием портов для поиска сервисов, которые могут оказаться уязвимыми.
Сканирование может производиться "наивным методом", к примеру используя посылку ICMP ping. Но может быть замаскировано.
Пример маскировки — посылка TCP SYN на указанные порты без последующего установления соединения.
Как правило, современные IDS могут отловить оба варианта. Маскировка сканирования также может осуществляться разнесением его на длительное время, либо выполнением с нескольких узлов.
Помимо сканирования, топология сети может быть определена менее точно, но более скрытно:
- Обнаружением узлов, рассылающих широковещательные запросы. Обнаружить такое практически невозможно: машина работает в обычном режиме.
- Прослушиванием трафика. Может быть обнаружено, кроме того современные топологии сетей препятствуют данной атаке (физическая общая шина редко используется).
Теперь возможно выделить типы атак для каждого класса.
Атаки уровня узла
Несколько примеров типов атак:
- Несанкционированная попытка повышения привилегий.
- Несанкционированный запуск кода с привилегиями зарегистрированного пользователя.
- Несанкционированный запуск кода с привилегиями демона/службы.
- Попытка изменения учётных данных (например, регистрации нового пользователя).
- Попытка прямой записи в дисковое устройство в обход драйверов ФС.
- Несанкционированное изменение файлов (в том числе массовое, либо изменение исполняемых модулей).
- Несанкционированное изменение системных настроек (например, с целью вывода системы из строя).
Конечно, большинство из этих атак также возможно маскировать, но при этом, возможно обнаружить попытку маскировки и также её интерпретировать, как атаку (самый простой пример: многие антивирусы обнаруживают такую технику маскировки, как внедрение в процесс, считая её за вредоносную активность).
Некоторые атаки на хост возможно распознать по изменению потребления ресурсов. Запуск дополнительного кода, как правило, ведёт к повышению потребления памяти, увеличению частоты обращения к диску и увеличению использования CPU.
Обычно данные аспекты не маскируют, т.к. они являются незначительными. Однако, при поражении большого количества узлов, возможно выделить характерные паттерны.
Часто, начиная с какого-то момента, хост начинает проявлять нетипичную для него сетевую активность, например попытку регулярного обращения к сайтам, на которые ранее обращений не было, либо к сайтам, доменные имена которых не разбиваются на словарные слова (ну или имеют высокую энтропию относительно "нормальных" имён). На стороне узла данная активность, как правило успешно маскируется (поскольку, если был антивирус, он её пропустил), но она может быть видна сетевой IDS.
Атаки уровня сети
Типы атак:
- Отказ в обслуживании: DoS/DDoS.
- Перехват управления.
- Несанкционированное получение данных пользователя. Как пассивное, так и активное.
Про конкретные атаки подробнее было написано выше.
Сканирование
Подразделяется на:
- Поиск узлов: n узлов будут отправлять m узлам сходные запросы. При этом, я считаю, что узел не будет отправлять запрос сам себе.
- Поиск сервисов узла: n узлов обращаются к m узлам на p портов.
Первый вариант атаки проще обнаружить сетевой IDS: трафик сканирования будет заметен, если он компактно расположен во времени.
В ином случае, следует использовать методы слабо чувствительные к временным разрывам.
Второй вариант проще всего обнаружить с использованием данных, полученных непосредственно с узла.
Собираемые данные
Данные узла
Считая, что вышеназванные атаки вызовут отклонения в использовании ресурсов, будут собираться следующие параметры:
- Загрузка CPU (процентов).
- Дисковые IO операции (операций в секунду).
- Потребление памяти (в процентах).
- Сетевая активность (МБит в секунду).
Параметры узлов объединяются в вектор.
Данные сети
В работе [12] предлагается собирать следующие сетевые параметры:
- Последовательность TCP пакетов, флаги, номера портов отправителя и получателя и IP адрес отправителя.
- Последовательность ICMP пакетов, IP адрес отправителя,
ICMP_ID. - IP адрес источника, длину пакета и UDP порты источника и получателя.
В работе [6] представлен обширный список параметров, взятый из базы NSL-KDD.
duration— продолжительность соединения в секундах.protocol_type— тип используемого протокола: TCP, UDP и пр..service— тип используемого обслуживания: HTTP, FTP, TELNET и пр..flag— флаг соединения: норма или ошибка.scr_bytes— число байт данных от источника к получателю.dst_bytes— число байт данных от получателя к источнику.land— 1 если соединение из/на таком же хосте/порте.wrong_fragments— количество "неверных" фрагментов.urgent— количество срочных (urgent) пакетов.hot— число "горячих" индикаторов.num_failed_logins— число ошибочных попыток входа.logged_in— 1 — успешный вход, 0 в противном случае.num_compromised— число скомпрометированных условий.root_shell— 1 — если получена корневая оболочка, 0 — в противном случае.su_attempted— 1 — если была попытка выполнить "su root", 0 — в др. случае.num_root— число доступов типа "root".num_file_creations— число операций создания файла.num_shells— число "подсказок оболочки".num_access_files— число получений доступа к контролю над файлами.num_outbound_cmds— количество исходящих команд через ftp сессию.is_host_login— 1 — если логин принадлежит к "host" списку.is_quest_login— 1 — если подключение типа "гость".count— число подключений к этому хосту за последние 2 секунды.srv_count— число подключений к этому сервису за последние 2 сек..serror_rate— процент подключений с syn ошибками.srv_serror_rate— процент подключений к сервису с syn ошибками.rerror_rate— процент подключений с rej ошибками.srv_rerror_rate— процент подключений к сервису с rej ошибками.same_srv_rate— процент подключений к такому сервису.diff_srv_rate— процент подключений к различным сервисам.srv_diff_hast_rate— процент подключений к различным хостам.dst_host_count— количество соединений к локальному хосту, установленных удаленной стороной.dst_host_srv_count— количество соединений к локальному хосту, установленных удаленной стороной и использующих одну и ту же службу.dst_host_same_srv_rate— процентное число соединений к локальному хосту, установленных удаленной стороной и использующих одну и ту же службу.dst_host_diff_srv_rate— процентное число соединений к локальному хосту, установленных удаленной стороной и использующих различные службы.dst_host_same_src_port_rate— процентное число соединений к данному хосту при текущем номере порта источника.dst_host_srv_diff_host_rate— процентное число соединений к службе разных хостов.dst_host_serror_rate— процентное число соединений c ошибкой типа syn для данного хоста-приемника.dst_host_srv_serror_rate— процентное число соединений c ошибкой типа syn для данной службы приемника.dst_host_rerror_rate— процентное число соединений c ошибкой типа rej для данного хоста-приемника.dst_host_srv_rerror_rate— процентное число соединений c ошибкой типа rej для данной службы приемника.
duration— длительность соединения (секунды).protocol_type— тип протокола (TCP, UDP, и др.).service— сетевая служба получателя (HTTP, TELNET и др.).flag— cостояние соединения.src_bytes— число байтов переданных от источника получателю.dst_bytes— число байтов переданных от получателя источнику.land— 1 если соединение по идентичным портам; 0 в других случаях.wrong_fragment— количество "неверных" пакетов.urgent— количество пакетов с флагом URG.
Одной из интересных особенностей в данной работе является то, что признаки нейросети могут настраиваться пользователем.
Хотя это и не актуально для концепта в данной статье, но может быть учтено при разработке законченного продукта.
- ID protocol — тип протокола, ассоциированный с пакетом.
- Source port — номер порта отправителя TCP или UDP.
- Destination port — номер порта получателя TCP или UDP.
- Source Address — IP адрес отправителя.
- Destination Address — IP адрес получателя.
- ICMP type — тип ICMP пакета.
- Length of data transferred — размер пакета данных в байтах.
- FLAGS — флаги в заголовке протокола.
- TCP window size — размер TCP окна.
Номер порта отправителя, как правило, не имеет смысла учитывать, поскольку он генерируется автоматически.
При разработке концепта, я буду использовать базу NSL-KDD для эмуляции сетевой активности, поскольку с ней удобно работать. Соответственно, параметры будут взяты оттуда. В реальной же системе, как следует из обзора, желательно подробно разбирать пакеты прикладных протоколов.
Я выбрал параметры, отталкиваясь от работы [6] и несколько дополнив их.
duration— длительность соединения.protocol_type— тип протокола (TCP, UDP, и др.).service— сетевая служба получателя (HTTP, TELNET и др.).flag— cостояние соединения.src_bytes— число байтов переданных от источника получателю.dst_bytes— число байтов переданных от получателя источнику.land— 1 если соединение по идентичным портам; 0 в других случаях.wrong_fragment— количество "неверных" пакетов.urgent— количество пакетов с флагом URG.count— число подключений к этому хосту за последние 2 сек..srv_count— число подключений к этому сервису за последние 2 сек..serror_rate— процент подключений с syn ошибками.diff_srv_rate— процент подключений к различным сервисам.srv_diff_host_rate— процент подключений к различным хостам.dst_host_srv_count— количество соединений к локальному хосту, установленных удаленной стороной и использующих одну и ту же службу.
Описание типовой архитектуры IDS
Типичная IDS состоит из следующих компонентов:
Датчики:
- Модули захвата.
- Модуль сбора.
- Модуль сопряжения.
Подсистема анализа:
- Модули декодирования.
- Модули обнаружения.
- Подсистема вывода:
- Модули реагирования.
- Модули вывода.
Датчиков в современных IDS, как правило несколько, и они могут быть распределены по машинам пользователя. Лучше всего это видно на примерах Prelude SIEM и OSSIM, описанных выше. Задачей датчиков является захват данных, их накопление и отправка центральной системе.
- Датчики приложений – предоставляют данные о работе конкретного программного обеспечения защищаемой системы.
- Датчики хоста – предоставляют данные о функционировании отдельной рабочей станции защищаемой системы.
- Датчики сети – отвечают за сбор данных для оценки сетевого трафика.
- Межсетевые датчики – содержат характеристики данных, циркулирующих между сетями.
Полученная от датчиков информация декодируется в набор признаков и проводится через цепочку модулей анализа.
Модуль анализа принимает информацию из источника данных и анализирует данные на наличие признаков атак или нарушений политики безопасности. Он может использоваться, как для обнаружения вторжений, эксплуатирующих известные шаблоны атак, так и для обнаружения аномальной активности.
Анализаторы известных атак могут опираться на обновляемую базу сигнатур, либо быть реализованы на основе сети прямого распространения, обученной на примерах атак.
Анализаторы аномалий могут учитывать не только состояние датчиков, но и результаты работы предыдущих анализаторов.
После того, как анализаторы отработали, в том или ином виде выводится их совокупное состояние. Это может быть, как вывод данных пользователю через один из интерфейсов, за что отвечают модули вывода, так и указание цели активной системе защиты (например, брандмауэру на блокирование соединения), за что отвечают модули реагирования.
Кратко это выглядит так:
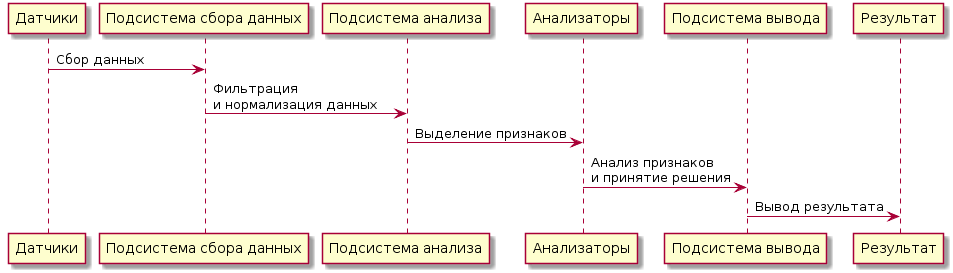
Датчики -> "Подсистема сбора данных": Сбор данных
"Подсистема сбора данных" -> "Подсистема анализа": Фильтрация\nи нормализация данных
"Подсистема анализа" -> "Анализаторы": Выделение признаков
"Анализаторы" -> "Подсистема вывода": Анализ признаков\nи принятие решения
"Подсистема вывода" -> Результат: Вывод результатаОписание принципа построения нейросетевого анализатора
Изо всего вышесказанного следует, что детектор должен быть комбинированным: обнаруживать аномалии и известные атаки. Либо это должно быть несколько разных детекторов в цепи. Кроме того, желательно чтобы IDS периодически запускала активное сканирование с целью обнаружения потенциальных уязвимостей.
В связи с объёмом работы, требуемой для реализации полноценного детектора, в данной статье я решаю ограниченную задачу построения концепта модуля обнаружения аномалий. Предполагается, что данные мне поставлены модулем декодирования в понятной форме, в виде набора признаков, которые я могу подать на входы сети (это база NSL-KDD). Данные хостов будут сгенерированы.
С учётом предпосылки в начале статьи, метод представления результатов детектора желательно реализовать многоклассовым (чтобы не только обнаруживать наличие аномальной активности, но и определять её тип), но с целью упрощения будет реализован двуклассовый детектор.
Все детекторы аномалий, независимо от модели использованной при их построении, действуют по принципу сравнения данных эталона с текущей обстановкой и сигнализации, при выходе за указанный порог.
Любая модель от статистической, до искусственной имунной системы должна иметь такой эталон.
В случае нейросети, эталон создаётся в процессе обучения во время нормальной работы сети передачи данных (СПД), затем сеть, функционируя, выявляет отклонения, выходящие за указанные границы.
Сложности данного подхода заключаются в том, что:
Сеть надо обучить при нормальном функционировании СПД, но нельзя быть уверенным, что в данный момент не ведётся атака, и сеть не обучится на "аномальной активности".
Остановить СПД или отключить её от внешних сетей тоже нельзя: даже если возможно прервать её работу, в будущем активность подключенной СПД будет трактоваться, как аномальная.
- Объём данных, следовательно и период обучения, должен быть достаточно большим: функционирование СПД почти гарантированно различается в разные периоды суток и даже может отличаться в разные кварталы года.
От проблемы обучения на при нормальном функционировании уйти не представляется возможным (её решают написанием правил, описывающих функционирование СПД в нормальном режиме, но здесь это не применимо).
Проблему большого объёма данных, разнесённого во времени, возможно смягчить, используя адаптивную подстройку.
Как возможно видеть на визуализации ниже, сетевая активность при атаках отлична от нормальной активности сети (данные взяты из NSL-KDD):

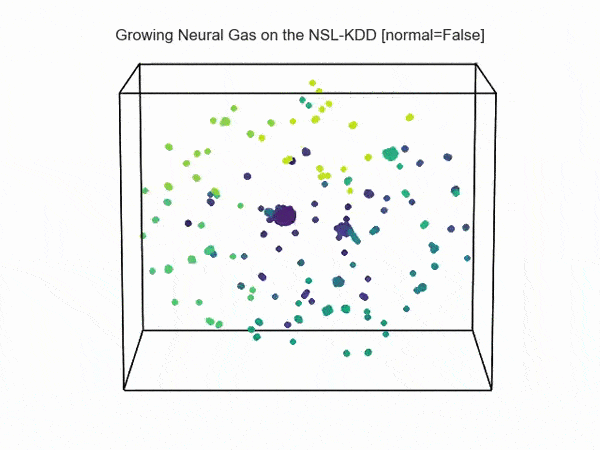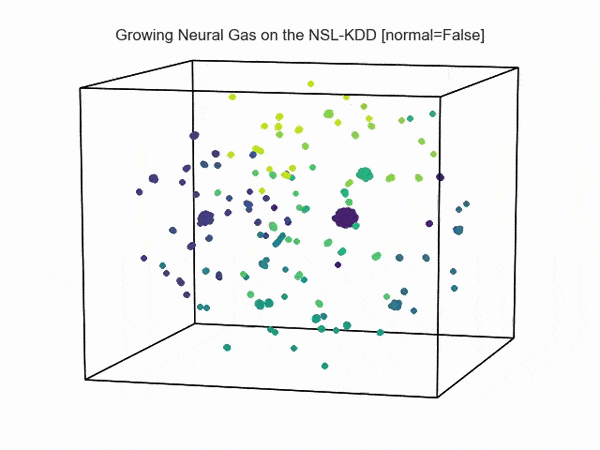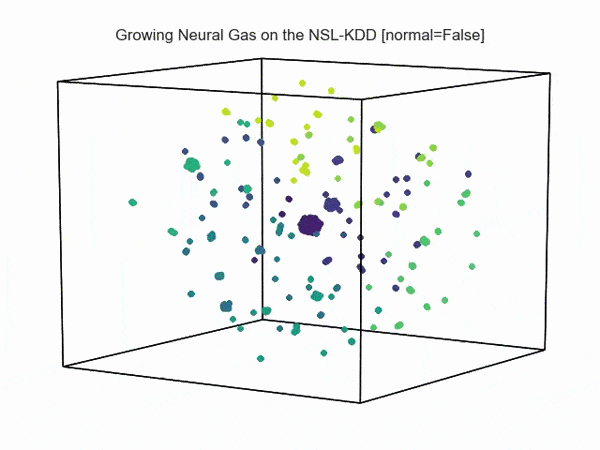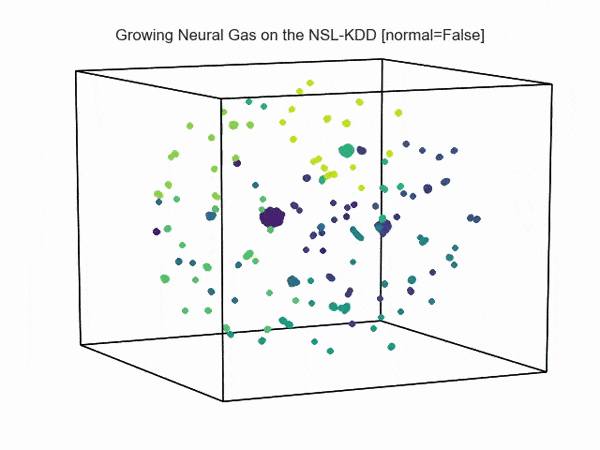
Т.е., возможно увидеть аномальную активность атаки на фоне нормальной активности сети:

import hypertools as hyp
from collections import OrderedDict
import csv
def read_ids_data(data_file, is_normal=True, labels_file='NSL_KDD/Field Names.csv', with_host=False):
selected_parameters = ['duration', 'protocol_type', 'service', 'flag', 'src_bytes', 'dst_bytes', 'land', 'wrong_fragment', 'urgent']
# "Label" - "converter function" dictionary.
label_dict = OrderedDict()
result = []
with open(labels_file) as lf:
labels = csv.reader(lf)
for label in labels:
if len(label) == 1 or label[1] == 'continuous':
label_dict[label[0]] = lambda l: np.float64(l)
elif label[1] == 'symbolic':
label_dict[label[0]] = lambda l: sh(l)
f_list = [i for i in label_dict.values()]
n_list = [i for i in label_dict.keys()]
data_type = lambda t: t == 'normal' if is_normal else t != 'normal'
with open(data_file) as df:
# data = csv.DictReader(df, label_dict.keys())
data = csv.reader(df)
for d in data:
if data_type(d[-2]):
# Skip last two fields and add only specified fields.
net_params = tuple(f_list[n](i) for n, i in enumerate(d[:-2]) if n_list[n] in selected_parameters)
if with_host:
host_params = generate_host_activity(is_normal)
result.append(net_params + host_params)
else:
result.append(net_params)
hyp.plot(np.array(result), '.', normalize='across', reduce='UMAP', ndims=3,
n_clusters=10, animate='spin', palette='viridis',
title='Growing Neural Gas on the NSL-KDD [normal={}]'.format(is_normal),
# vectorizer='TfidfVectorizer',
# precog=False, bullettime=True, chemtrails=True, tail_duration=100,
duration=3, rotations=1, legend=False, explore=False, show=True,
save_path='./video.mp4')
read_ids_data('NSL_KDD/20 Percent Training Set.csv')
read_ids_data('NSL_KDD/20 Percent Training Set.csv', is_normal=False)Потому, обнаруживать аномалии предлагается с помощью кластеризации "картины сетевой активности".
Как правило, задача кластеризации в рамках нейросетевого подхода решается с использованием самоорганизующихся карт Кохонена.
Дополнительными проблемами, которые вносит данный подход, являются:
- Необходимость задания количества кластеров.
- Необходимость переобучать детектор, при изменении топологии СПД.
Чтобы исключить данные проблемы, для построения детектора аномалий, я решил обратиться к адаптивным нейросетевым алгоритмам кластеризации.
Идея обнаружения такова: сеть учится в режиме нормального функционирования СПД в течение некоторого времени. При этом, образуется некоторое количество кластеров данных, которые при правильной настройке сети, полностью характеризуют нормальное функционирование СПД.
Есть следующие варианты обнаружения:
- Обучение сети на поступающих данных. В случае появления аномалий, структура и количество кластеров начинают изменяться.
- Предоставление поступивших данных обученной сети и проверка того, насколько близко они подходят одному из кластеров.
В первом случае, аномалии возможно обнаружить по:
- Изменению количества кластеров.
- Динамике скорости создания и удаления новых нейронов и связей.
Во втором случае аномалии обнаруживаются по отклонению значения новых измерений от среднего для данных, на которых сеть обучена.
В сетевых алгоритмах расчёт динамики выполнить сложно: сеть может изменять количество нейронов и связей на каждой итерации, при том что некоторые алгоритмы создают и удаляют фиксированное количество нейронов на каждой итерации.
Изменение количества кластеров не является надёжным показателем. Кроме того, обучение сети в процессе обнаружения ставит несколько других проблем (таких, как переобучение, например).
Достаточно надёжным вариантом является измерение отклонений. Именно этот вариант будет применён.
Архитектура модуля
Данные с узлов пересылаются агентами и для каждого параметра вычисляется среднее. Эти данные объединяются в один вектор с данными сетевой активности, получаемыми от IDS.
В прототипе данные хостов генерируются функцией, которая увеличивает потребление ресурсов в определённом проценте атак (на данный момент, выбрано 25%).
Данные сети предоставляются модулю IDS в стандартизованном виде. В прототипе это записи NSL-KDD.
Реализован будет алгоритм обнаружения отклонений от среднего:

@startuml
start
partition Обучение {
: Обучить сеть на нормальных данных;
: Рассчитать среднеквадратическое отклонение\nмежду измерениями и ближайшими к ним узлами;
}
partition Обнаружение {
: Поступило новое измерение;
: Получить ближайший к нему узел;
if (Разница выходит за стандартное отклонение) then (Нет)
-[#blue]->
: Считать данные нормальными;
if (Требуется дообучение) then (Да)
-[#green]->
: Добавить данные в граф и запустить\nпроход обучения сети.;
else (Нет)
-[#blue]->
endif
else (Да)
-[#green]->
: Увеличить значение\nсуммарного отклонения;
if (Суммарное отклонение превышает порог) then (Да)
-[#green]->
: Сигнализировать об аномалии;
else (Нет)
-[#blue]->
: Продолжить;
endif
endif
}
stop
@endumlКак видно из диаграммы, в данном алгоритме может быть использована адаптивная подстройка, напоминающая метод обучения с частичным привлечением учителя.
С целью улучшения качества обнаружения, считается не одно отклонение, а средние отклонения для лучше всего подходящих нейронов.
Потом для кластера вычисляется корень из среднего арифметического всех значений отклонений, входящих в него нейронов.
Для поданного на проверку сэмпла данных ищется ближайший нейрон, считается расстояние между ними и сравнивается с посчитанным среднеквадратическим отклонением для кластера, в который входит нейрон.
Если расстояние между сэмплом и нейроном больше отклонения по кластеру, данный сэмпл считается аномальным.
Это гибрид метода классификации по среднему расстоянию, который используется для определения класса нейронов, в статье 20 и метода по классификации по минимальному расстоянию.
Сначала используется первый: выбирается лучший нейрон. Затем, считается разница между средним отклонением по кластеру.
Ещё один вариант — классификация по методу большинства, когда нейрон получает класс по максимальному количеству точек в его области Вороного здесь не применим.
Ядро детектора представляет собой объект, реализующий один из алгоритмов "растущего нейронного газа" или GNG, который обучен на сетевой активности во время нормального функционирования СПД.
GNG позволяет кластеризовать данные, самостоятельно определяя необходимое количество кластеров.
В частности, это может быть один из следующих алгоритмов:
- GNG [18] — классический растущий нейронный газ, о котором подробнее здесь, либо в работе [17], где он впервые описан.
- IGNG [19] — инкрементальный растущий нейронный газ. Достаточно сильно отличается от классического. Имеет более высокую скорость сходимости. В статье 20 он называется "Быстрорастущий GNG", а зрелые и зародышевые нейроны называются фиксированными и нефиксированными, соответственно (авторы использовали в своей работе оригинальную статью [19]).
Модуль хранит данные, на которых он обучался, в виде структуры сети и получает новые данные во время работы.
На выходе модуль должен постоянно выводить результат: есть аномальная активность, либо нет, либо вероятность наличия данной активности.
На следующем рисунке показан пример кластеризации, с использованием GNG (на ограниченном подмножестве, с целью наглядности), где ясно видно, как алгоритм сходится.
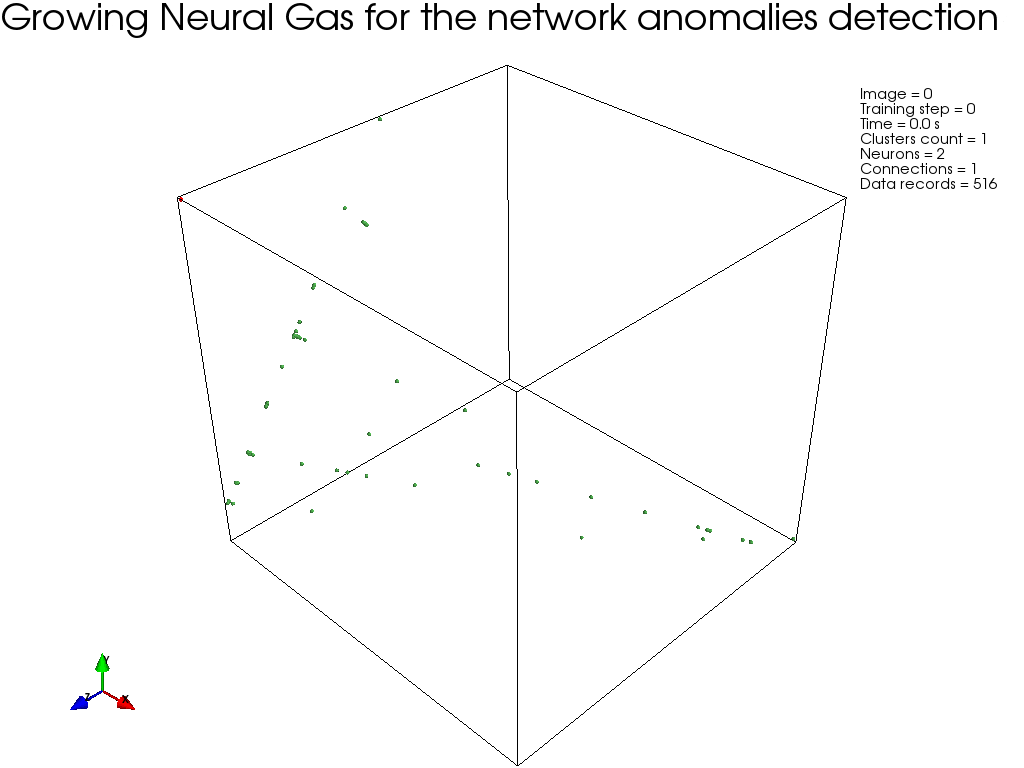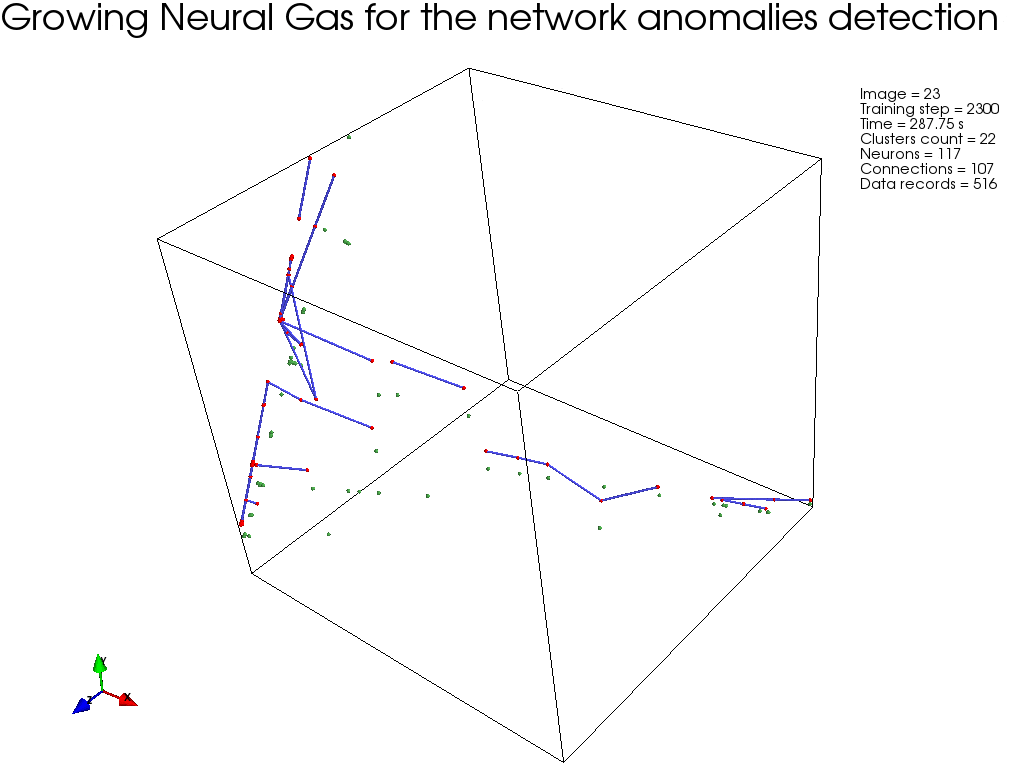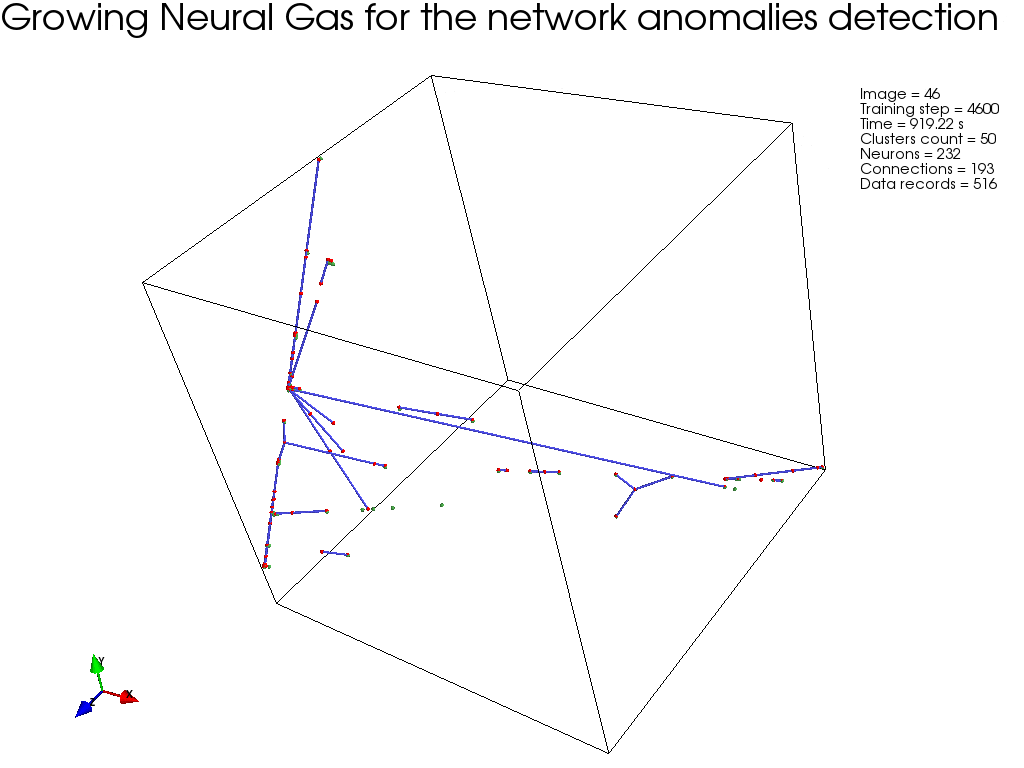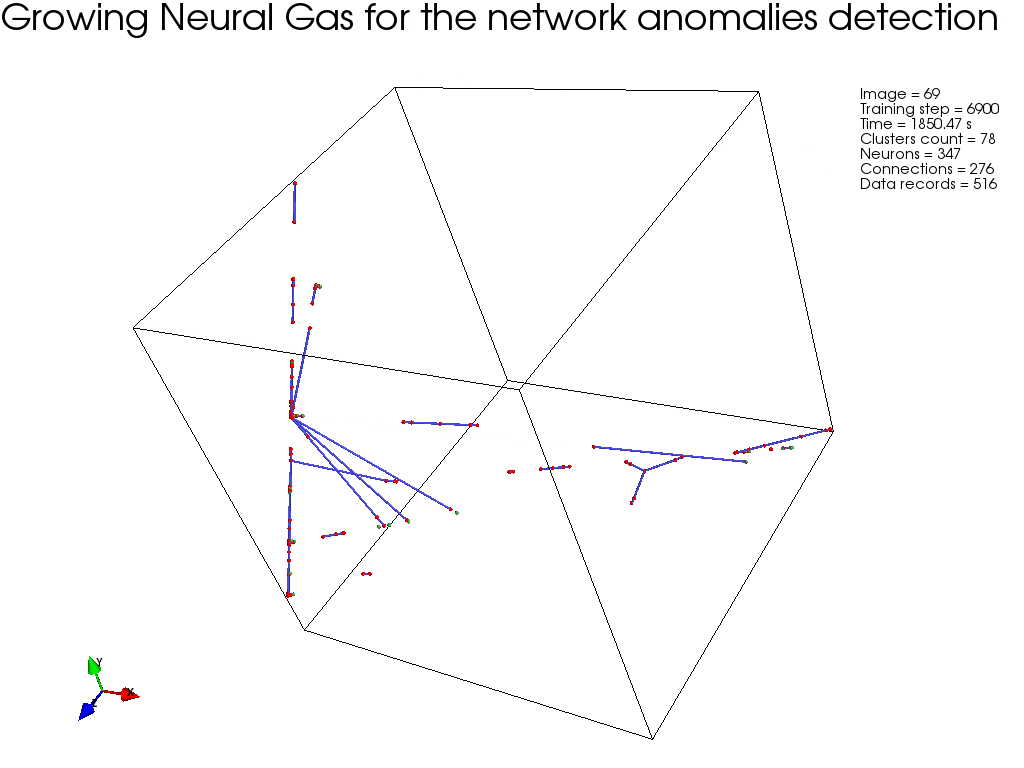
Реализация модуля
Существует несколько реализаций GNG, как минимум:
Реализация на MQL-5 в вышеприведённой статье [18]. Язык сильно похож на C++ и легко понимается. В целом, общий стиль данной реализации мне не понравился.
- На R. И там же есть реализация на C++.
- На MATLAB.
- На Go.
- На JavaScript. Симулятор многих алгоритмов.
- И две реализации на Python из которых я взял вторую, т.к. она заработала сразу после установки зависимостей.
Соответственно, в качестве языка реализации прототипа используется Python. С реализациями IGNG дело обстоит хуже, и я не нашёл ни одной, хотя конечно же они есть, т.к. авторы статьи получали результаты для своего алгоритма. В результате, IGNG реализацию пришлось реализовывать полностью самостоятельно.
Краткое описание кода
Точкой входа является функция main(), которая устанавливает параметры и вызывает функцию test_detector(), гоняющую детектор так, как задумано.
В функции test_detector() предварительно загружаются данные для обучения детектора.
Затем, производится обучение, используя метод train(), и вызывается обнаружение на разных наборах данных, используя метод detect_anomalies().
Все данные загружаются функцией read_ids_data().
Функция читает данные из базы NSL-KDD с использованием стандартного модуля csv. Какие данные будут прочитаны: нормальные, аномальные или полные, задаётся параметром activity_type.
Также функция, если было запрошено, может сгенерировать активность хостов, вызвав generate_host_activity(), и добавить полученные данные к данным сети.
Функция вернёт результат в виде ненормализованного массива Numpy.
После возврата из функции, данные будут нормализованы, используя функцию normalize() модуля preprocessing библиотеки Scikit-Learn. Далее, вся работа производится только с нормализованными данными.
На прочитанных данных строится ненаправленный граф, как объект класса Graph библиотеки NetworkX через вызов функции create_data_graph().
Этот граф нужен только для визуализации.
Данные передаются конструктору класса детектора. В конструкторе данные запоминаются во внутренний атрибут класса и создаётся пустой граф, в который будут добавляться нейроны и связи.
Основным классом детектора является GNG или IGNG, в зависимости от реализованного алгоритма. Эти классы являются наследниками абстрактного класса NeuralGas, в котором реализованы общие методы.
В методе train() многократно вызывается кластеризующий метод и периодически сохраняется картинка с визуализацией через вызов метода __save_img().
Кластеризующему методу передаётся одно из значений, которое представляет собой набор координат точки данных в многомерном пространстве.
Получая данные этой точки, кластеризующий метод выбирает наиболее близкие нейроны внутреннего графа (того, который был создан в конструкторе) и, если они не удовлетворительны, создаёт новые нейроны и связи.
В методе __save_img() для формирования картинки используются функции draw_dots3d(), либо draw_graph3d(), который вызывается два раза: сначала для отрисовки данных, затем для отрисовки нейронной сети поверх данных.
Внутри визуализация реализована с помощью библиотеки Mayavi и основной вызов, рисующий точки — это mayavi.points3d().
После завершения обучения, сохранённые картинки сшиваются в GIF, используя модуль ImageIO.
Полный исходный код находится здесь:
https://github.com/artiomn/GNG
Код сначала был адаптирован для многомерных данных и частично переписан. По ходу этого, выяснилось, что код индусский, и алгоритм вообще реализован некорректно (см. например на использование переменной i в методе train оригинала: благодаря этому багу, код работал). Затем, в связи с низкой скоростью работы, был реализован алгоритм IGNG.
На всякий случай (потому что неизвестно, что будет с Github в течение ближайшего года) продублирую здесь код прототипа.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from abc import ABCMeta, abstractmethod
from math import sqrt
from mayavi import mlab
import operator
import imageio
from collections import OrderedDict
from scipy.spatial.distance import euclidean
from sklearn import preprocessing
import csv
import numpy as np
import networkx as nx
import re
import os
import shutil
import sys
import glob
from past.builtins import xrange
from future.utils import iteritems
import time
def sh(s):
sum = 0
for i, c in enumerate(s):
sum += i * ord(c)
return sum
def create_data_graph(dots):
"""Create the graph and returns the networkx version of it 'G'."""
count = 0
G = nx.Graph()
for i in dots:
G.add_node(count, pos=(i))
count += 1
return G
def get_ra(ra=0, ra_step=0.3):
while True:
if ra >= 360:
ra = 0
else:
ra += ra_step
yield ra
def shrink_to_3d(data):
result = []
for i in data:
depth = len(i)
if depth <= 3:
result.append(i)
else:
sm = np.sum([(n) * v for n, v in enumerate(i[2:])])
if sm == 0:
sm = 1
r = np.array([i[0], i[1], i[2]])
r *= sm
r /= np.sum(r)
result.append(r)
return preprocessing.normalize(result, axis=0, norm='max')
def draw_dots3d(dots, edges, fignum, clear=True,
title='',
size=(1024, 768), graph_colormap='viridis',
bgcolor=(1, 1, 1),
node_color=(0.3, 0.65, 0.3), node_size=0.01,
edge_color=(0.3, 0.3, 0.9), edge_size=0.003,
text_size=0.14, text_color=(0, 0, 0), text_coords=[0.84, 0.75], text={},
title_size=0.3,
angle=get_ra()):
# https://stackoverflow.com/questions/17751552/drawing-multiplex-graphs-with-networkx
# numpy array of x, y, z positions in sorted node order
xyz = shrink_to_3d(dots)
if fignum == 0:
mlab.figure(fignum, bgcolor=bgcolor, fgcolor=text_color, size=size)
# Mayavi is buggy, and following code causes sockets leak.
#if mlab.options.offscreen:
# mlab.figure(fignum, bgcolor=bgcolor, fgcolor=text_color, size=size)
#elif fignum == 0:
# mlab.figure(fignum, bgcolor=bgcolor, fgcolor=text_color, size=size)
if clear:
mlab.clf()
# the x,y, and z co-ordinates are here
# manipulate them to obtain the desired projection perspective
pts = mlab.points3d(xyz[:, 0], xyz[:, 1], xyz[:, 2],
scale_factor=node_size,
scale_mode='none',
color=node_color,
#colormap=graph_colormap,
resolution=20,
transparent=False)
mlab.text(text_coords[0], text_coords[1], '\n'.join(['{} = {}'.format(n, v) for n, v in text.items()]), width=text_size)
if clear:
mlab.title(title, height=0.95)
mlab.roll(next(angle))
mlab.orientation_axes(pts)
mlab.outline(pts)
"""
for i, (x, y, z) in enumerate(xyz):
label = mlab.text(x, y, str(i), z=z,
width=text_size, name=str(i), color=text_color)
label.property.shadow = True
"""
pts.mlab_source.dataset.lines = edges
tube = mlab.pipeline.tube(pts, tube_radius=edge_size)
mlab.pipeline.surface(tube, color=edge_color)
#mlab.show() # interactive window
def draw_graph3d(graph, fignum, *args, **kwargs):
graph_pos = nx.get_node_attributes(graph, 'pos')
edges = np.array([e for e in graph.edges()])
dots = np.array([graph_pos[v] for v in sorted(graph)], dtype='float64')
draw_dots3d(dots, edges, fignum, *args, **kwargs)
def generate_host_activity(is_normal):
# Host loads is changed only in 25% cases.
attack_percent = 25
up_level = (20, 30)
# CPU load in percent.
cpu_load = (10, 30)
# Disk IO per second.
iops = (10, 50)
# Memory consumption in percent.
mem_cons = (30, 60)
# Memory consumption in Mb/s.
netw_act = (10, 50)
cur_up_level = 0
if not is_normal and np.random.randint(0, 100) < attack_percent:
cur_up_level = np.random.randint(*up_level)
cpu_load = np.random.randint(cur_up_level + cpu_load[0], cur_up_level + cpu_load[1])
iops = np.random.randint(cur_up_level + iops[0], cur_up_level + iops[1])
mem_cons = np.random.randint(cur_up_level + mem_cons[0], cur_up_level + mem_cons[1])
netw_act = np.random.randint(cur_up_level + netw_act[0], cur_up_level + netw_act[1])
return cpu_load, iops, mem_cons, netw_act
def read_ids_data(data_file, activity_type='normal', labels_file='NSL_KDD/Field Names.csv', with_host=False):
selected_parameters = ['duration', 'protocol_type', 'service', 'flag', 'src_bytes', 'dst_bytes', 'land', 'wrong_fragment', 'urgent', 'serror_rate',
'diff_srv_rate', 'srv_diff_host_rate', 'dst_host_srv_count', 'count']
# "Label" - "converter function" dictionary.
label_dict = OrderedDict()
result = []
with open(labels_file) as lf:
labels = csv.reader(lf)
for label in labels:
if len(label) == 1 or label[1] == 'continuous':
label_dict[label[0]] = lambda l: np.float64(l)
elif label[1] == 'symbolic':
label_dict[label[0]] = lambda l: sh(l)
f_list = [i for i in label_dict.values()]
n_list = [i for i in label_dict.keys()]
if activity_type == 'normal':
data_type = lambda t: t == 'normal'
elif activity_type == 'abnormal':
data_type = lambda t: t != 'normal'
elif activity_type == 'full':
data_type = lambda t: True
else:
raise ValueError('`activity_type` must be "normal", "abnormal" or "full"')
print('Reading {} activity from the file "{}" [generated host data {} included]...'.
format(activity_type, data_file, 'was' if with_host else 'was not'))
with open(data_file) as df:
# data = csv.DictReader(df, label_dict.keys())
data = csv.reader(df)
for d in data:
if data_type(d[-2]):
# Skip last two fields and add only specified fields.
net_params = tuple(f_list[n](i) for n, i in enumerate(d[:-2]) if n_list[n] in selected_parameters)
if with_host:
host_params = generate_host_activity(activity_type != 'abnormal')
result.append(net_params + host_params)
else:
result.append(net_params)
print('Records count: {}'.format(len(result)))
return result
class NeuralGas():
__metaclass__ = ABCMeta
def __init__(self, data, surface_graph=None, output_images_dir='images'):
self._graph = nx.Graph()
self._data = data
self._surface_graph = surface_graph
# Deviation parameters.
self._dev_params = None
self._output_images_dir = output_images_dir
# Nodes count.
self._count = 0
if os.path.isdir(output_images_dir):
shutil.rmtree('{}'.format(output_images_dir))
print("Ouput images will be saved in: {0}".format(output_images_dir))
os.makedirs(output_images_dir)
self._start_time = time.time()
@abstractmethod
def train(self, max_iterations=100, save_step=0):
raise NotImplementedError()
def number_of_clusters(self):
return nx.number_connected_components(self._graph)
def detect_anomalies(self, data, threshold=5, train=False, save_step=100):
anomalies_counter, anomaly_records_counter, normal_records_counter = 0, 0, 0
anomaly_level = 0
start_time = self._start_time = time.time()
for i, d in enumerate(data):
risk_level = self.test_node(d, train)
if risk_level != 0:
anomaly_records_counter += 1
anomaly_level += risk_level
if anomaly_level > threshold:
anomalies_counter += 1
#print('Anomaly was detected [count = {}]!'.format(anomalies_counter))
anomaly_level = 0
else:
normal_records_counter += 1
if i % save_step == 0:
tm = time.time() - start_time
print('Abnormal records = {}, Normal records = {}, Detection time = {} s, Time per record = {} s'.
format(anomaly_records_counter, normal_records_counter, round(tm, 2), tm / i if i else 0))
tm = time.time() - start_time
print('{} [abnormal records = {}, normal records = {}, detection time = {} s, time per record = {} s]'.
format('Anomalies were detected (count = {})'.format(anomalies_counter) if anomalies_counter else 'Anomalies weren\'t detected',
anomaly_records_counter, normal_records_counter, round(tm, 2), tm / len(data)))
return anomalies_counter > 0
def test_node(self, node, train=False):
n, dist = self._determine_closest_vertice(node)
dev = self._calculate_deviation_params()
dev = dev.get(frozenset(nx.node_connected_component(self._graph, n)), dist + 1)
dist_sub_dev = dist - dev
if dist_sub_dev > 0:
return dist_sub_dev
if train:
self._dev_params = None
self._train_on_data_item(node)
return 0
@abstractmethod
def _train_on_data_item(self, data_item):
raise NotImplementedError()
@abstractmethod
def _save_img(self, fignum, training_step):
"""."""
raise NotImplementedError()
def _calculate_deviation_params(self, distance_function_params={}):
if self._dev_params is not None:
return self._dev_params
clusters = {}
dcvd = self._determine_closest_vertice
dlen = len(self._data)
#dmean = np.mean(self._data, axis=1)
#deviation = 0
for node in self._data:
n = dcvd(node, **distance_function_params)
cluster = clusters.setdefault(frozenset(nx.node_connected_component(self._graph, n[0])), [0, 0])
cluster[0] += n[1]
cluster[1] += 1
clusters = {k: sqrt(v[0]/v[1]) for k, v in clusters.items()}
self._dev_params = clusters
return clusters
def _determine_closest_vertice(self, curnode):
"""."""
pos = nx.get_node_attributes(self._graph, 'pos')
kv = zip(*pos.items())
distances = np.linalg.norm(kv[1] - curnode, ord=2, axis=1)
i0 = np.argsort(distances)[0]
return kv[0][i0], distances[i0]
def _determine_2closest_vertices(self, curnode):
"""Where this curnode is actually the x,y index of the data we want to analyze."""
pos = nx.get_node_attributes(self._graph, 'pos')
l_pos = len(pos)
if l_pos == 0:
return None, None
elif l_pos == 1:
return pos[0], None
kv = zip(*pos.items())
# Calculate Euclidean distance (2-norm of difference vectors) and get first two indexes of the sorted array.
# Or a Euclidean-closest nodes index.
distances = np.linalg.norm(kv[1] - curnode, ord=2, axis=1)
i0, i1 = np.argsort(distances)[0:2]
winner1 = tuple((kv[0][i0], distances[i0]))
winner2 = tuple((kv[0][i1], distances[i1]))
return winner1, winner2
class IGNG(NeuralGas):
"""Incremental Growing Neural Gas multidimensional implementation"""
def __init__(self, data, surface_graph=None, eps_b=0.05, eps_n=0.0005, max_age=10,
a_mature=1, output_images_dir='images'):
"""."""
NeuralGas.__init__(self, data, surface_graph, output_images_dir)
self._eps_b = eps_b
self._eps_n = eps_n
self._max_age = max_age
self._a_mature = a_mature
self._num_of_input_signals = 0
self._fignum = 0
self._max_train_iters = 0
# Initial value is a standard deviation of the data.
self._d = np.std(data)
def train(self, max_iterations=100, save_step=0):
"""IGNG training method"""
self._dev_params = None
self._max_train_iters = max_iterations
fignum = self._fignum
self._save_img(fignum, 0)
CHS = self.__calinski_harabaz_score
igng = self.__igng
data = self._data
if save_step < 1:
save_step = max_iterations
old = 0
calin = CHS()
i_count = 0
start_time = self._start_time = time.time()
while old - calin <= 0:
print('Iteration {0:d}...'.format(i_count))
i_count += 1
steps = 1
while steps <= max_iterations:
for i, x in enumerate(data):
igng(x)
if i % save_step == 0:
tm = time.time() - start_time
print('Training time = {} s, Time per record = {} s, Training step = {}, Clusters count = {}, Neurons = {}, CHI = {}'.
format(round(tm, 2),
tm / (i if i and i_count == 0 else len(data)),
i_count,
self.number_of_clusters(),
len(self._graph),
old - calin)
)
self._save_img(fignum, i_count)
fignum += 1
steps += 1
self._d -= 0.1 * self._d
old = calin
calin = CHS()
print('Training complete, clusters count = {}, training time = {} s'.format(self.number_of_clusters(), round(time.time() - start_time, 2)))
self._fignum = fignum
def _train_on_data_item(self, data_item):
steps = 0
igng = self.__igng
# while steps < self._max_train_iters:
while steps < 5:
igng(data_item)
steps += 1
def __long_train_on_data_item(self, data_item):
"""."""
np.append(self._data, data_item)
self._dev_params = None
CHS = self.__calinski_harabaz_score
igng = self.__igng
data = self._data
max_iterations = self._max_train_iters
old = 0
calin = CHS()
i_count = 0
# Strictly less.
while old - calin < 0:
print('Training with new normal node, step {0:d}...'.format(i_count))
i_count += 1
steps = 0
if i_count > 100:
print('BUG', old, calin)
break
while steps < max_iterations:
igng(data_item)
steps += 1
self._d -= 0.1 * self._d
old = calin
calin = CHS()
def _calculate_deviation_params(self, skip_embryo=True):
return super(IGNG, self)._calculate_deviation_params(distance_function_params={'skip_embryo': skip_embryo})
def __calinski_harabaz_score(self, skip_embryo=True):
graph = self._graph
nodes = graph.nodes
extra_disp, intra_disp = 0., 0.
# CHI = [B / (c - 1)]/[W / (n - c)]
# Total numb er of neurons.
#ns = nx.get_node_attributes(self._graph, 'n_type')
c = len([v for v in nodes.values() if v['n_type'] == 1]) if skip_embryo else len(nodes)
# Total number of data.
n = len(self._data)
# Mean of the all data.
mean = np.mean(self._data, axis=1)
pos = nx.get_node_attributes(self._graph, 'pos')
for node, k in pos.items():
if skip_embryo and nodes[node]['n_type'] == 0:
# Skip embryo neurons.
continue
mean_k = np.mean(k)
extra_disp += len(k) * np.sum((mean_k - mean) ** 2)
intra_disp += np.sum((k - mean_k) ** 2)
return (1. if intra_disp == 0. else
extra_disp * (n - c) /
(intra_disp * (c - 1.)))
def _determine_closest_vertice(self, curnode, skip_embryo=True):
"""Where this curnode is actually the x,y index of the data we want to analyze."""
pos = nx.get_node_attributes(self._graph, 'pos')
nodes = self._graph.nodes
distance = sys.maxint
for node, position in pos.items():
if skip_embryo and nodes[node]['n_type'] == 0:
# Skip embryo neurons.
continue
dist = euclidean(curnode, position)
if dist < distance:
distance = dist
return node, distance
def __get_specific_nodes(self, n_type):
return [n for n, p in nx.get_node_attributes(self._graph, 'n_type').items() if p == n_type]
def __igng(self, cur_node):
"""Main IGNG training subroutine"""
# find nearest unit and second nearest unit
winner1, winner2 = self._determine_2closest_vertices(cur_node)
graph = self._graph
nodes = graph.nodes
d = self._d
# Second list element is a distance.
if winner1 is None or winner1[1] >= d:
# 0 - is an embryo type.
graph.add_node(self._count, pos=cur_node, n_type=0, age=0)
winner_node1 = self._count
self._count += 1
return
else:
winner_node1 = winner1[0]
# Second list element is a distance.
if winner2 is None or winner2[1] >= d:
# 0 - is an embryo type.
graph.add_node(self._count, pos=cur_node, n_type=0, age=0)
winner_node2 = self._count
self._count += 1
graph.add_edge(winner_node1, winner_node2, age=0)
return
else:
winner_node2 = winner2[0]
# Increment the age of all edges, emanating from the winner.
for e in graph.edges(winner_node1, data=True):
e[2]['age'] += 1
w_node = nodes[winner_node1]
# Move the winner node towards current node.
w_node['pos'] += self._eps_b * (cur_node - w_node['pos'])
neighbors = nx.all_neighbors(graph, winner_node1)
a_mature = self._a_mature
for n in neighbors:
c_node = nodes[n]
# Move all direct neighbors of the winner.
c_node['pos'] += self._eps_n * (cur_node - c_node['pos'])
# Increment the age of all direct neighbors of the winner.
c_node['age'] += 1
if c_node['n_type'] == 0 and c_node['age'] >= a_mature:
# Now, it's a mature neuron.
c_node['n_type'] = 1
# Create connection with age == 0 between two winners.
graph.add_edge(winner_node1, winner_node2, age=0)
max_age = self._max_age
# If there are ages more than maximum allowed age, remove them.
age_of_edges = nx.get_edge_attributes(graph, 'age')
for edge, age in iteritems(age_of_edges):
if age >= max_age:
graph.remove_edge(edge[0], edge[1])
# If it causes isolated vertix, remove that vertex as well.
#graph.remove_nodes_from(nx.isolates(graph))
for node, v in nodes.items():
if v['n_type'] == 0:
# Skip embryo neurons.
continue
if not graph.neighbors(node):
graph.remove_node(node)
def _save_img(self, fignum, training_step):
"""."""
title='Incremental Growing Neural Gas for the network anomalies detection'
if self._surface_graph is not None:
text = OrderedDict([
('Image', fignum),
('Training step', training_step),
('Time', '{} s'.format(round(time.time() - self._start_time, 2))),
('Clusters count', self.number_of_clusters()),
('Neurons', len(self._graph)),
(' Mature', len(self.__get_specific_nodes(1))),
(' Embryo', len(self.__get_specific_nodes(0))),
('Connections', len(self._graph.edges)),
('Data records', len(self._data))
])
draw_graph3d(self._surface_graph, fignum, title=title)
graph = self._graph
if len(graph) > 0:
#graph_pos = nx.get_node_attributes(graph, 'pos')
#nodes = sorted(self.get_specific_nodes(1))
#dots = np.array([graph_pos[v] for v in nodes], dtype='float64')
#edges = np.array([e for e in graph.edges(nodes) if e[0] in nodes and e[1] in nodes])
#draw_dots3d(dots, edges, fignum, clear=False, node_color=(1, 0, 0))
draw_graph3d(graph, fignum, clear=False, node_color=(1, 0, 0), title=title,
text=text)
mlab.savefig("{0}/{1}.png".format(self._output_images_dir, str(fignum)))
#mlab.close(fignum)
class GNG(NeuralGas):
"""Growing Neural Gas multidimensional implementation"""
def __init__(self, data, surface_graph=None, eps_b=0.05, eps_n=0.0006, max_age=15,
lambda_=20, alpha=0.5, d=0.005, max_nodes=1000,
output_images_dir='images'):
"""."""
NeuralGas.__init__(self, data, surface_graph, output_images_dir)
self._eps_b = eps_b
self._eps_n = eps_n
self._max_age = max_age
self._lambda = lambda_
self._alpha = alpha
self._d = d
self._max_nodes = max_nodes
self._fignum = 0
self.__add_initial_nodes()
def train(self, max_iterations=10000, save_step=50, stop_on_chi=False):
"""."""
self._dev_params = None
self._save_img(self._fignum, 0)
graph = self._graph
max_nodes = self._max_nodes
d = self._d
ld = self._lambda
alpha = self._alpha
update_winner = self.__update_winner
data = self._data
CHS = self.__calinski_harabaz_score
old = 0
calin = CHS()
start_time = self._start_time = time.time()
train_step = self.__train_step
for i in xrange(1, max_iterations):
tm = time.time() - start_time
print('Training time = {} s, Time per record = {} s, Training step = {}/{}, Clusters count = {}, Neurons = {}'.
format(round(tm, 2),
tm / len(data),
i, max_iterations,
self.number_of_clusters(),
len(self._graph))
)
for x in data:
update_winner(x)
train_step(i, alpha, ld, d, max_nodes, True, save_step, graph, update_winner)
old = calin
calin = CHS()
# Stop on the enough clusterization quality.
if stop_on_chi and old - calin > 0:
break
print('Training complete, clusters count = {}, training time = {} s'.format(self.number_of_clusters(), round(time.time() - start_time, 2)))
def __train_step(self, i, alpha, ld, d, max_nodes, save_img, save_step, graph, update_winner):
g_nodes = graph.nodes
# Step 8: if number of input signals generated so far
if i % ld == 0 and len(graph) < max_nodes:
# Find a node with the largest error.
errorvectors = nx.get_node_attributes(graph, 'error')
node_largest_error = max(errorvectors.items(), key=operator.itemgetter(1))[0]
# Find a node from neighbor of the node just found, with a largest error.
neighbors = graph.neighbors(node_largest_error)
max_error_neighbor = None
max_error = -1
for n in neighbors:
ce = g_nodes[n]['error']
if ce > max_error:
max_error = ce
max_error_neighbor = n
# Decrease error variable of other two nodes by multiplying with alpha.
new_max_error = alpha * errorvectors[node_largest_error]
graph.nodes[node_largest_error]['error'] = new_max_error
graph.nodes[max_error_neighbor]['error'] = alpha * max_error
# Insert a new unit half way between these two.
self._count += 1
new_node = self._count
graph.add_node(new_node,
pos=self.__get_average_dist(g_nodes[node_largest_error]['pos'], g_nodes[max_error_neighbor]['pos']),
error=new_max_error)
# Insert edges between new node and other two nodes.
graph.add_edge(new_node, max_error_neighbor, age=0)
graph.add_edge(new_node, node_largest_error, age=0)
# Remove edge between old nodes.
graph.remove_edge(max_error_neighbor, node_largest_error)
if True and i % save_step == 0:
self._fignum += 1
self._save_img(self._fignum, i)
# step 9: Decrease all error variables.
for n in graph.nodes():
oe = g_nodes[n]['error']
g_nodes[n]['error'] -= d * oe
def _train_on_data_item(self, data_item):
"""IGNG training method"""
np.append(self._data, data_item)
graph = self._graph
max_nodes = self._max_nodes
d = self._d
ld = self._lambda
alpha = self._alpha
update_winner = self.__update_winner
data = self._data
train_step = self.__train_step
#for i in xrange(1, 5):
update_winner(data_item)
train_step(0, alpha, ld, d, max_nodes, False, -1, graph, update_winner)
def _calculate_deviation_params(self):
return super(GNG, self)._calculate_deviation_params()
def __add_initial_nodes(self):
"""Initialize here"""
node1 = self._data[np.random.randint(0, len(self._data))]
node2 = self._data[np.random.randint(0, len(self._data))]
# make sure you dont select same positions
if self.__is_nodes_equal(node1, node2):
raise ValueError("Rerun ---------------> similar nodes selected")
self._count = 0
self._graph.add_node(self._count, pos=node1, error=0)
self._count += 1
self._graph.add_node(self._count, pos=node2, error=0)
self._graph.add_edge(self._count - 1, self._count, age=0)
def __is_nodes_equal(self, n1, n2):
return len(set(n1) & set(n2)) == len(n1)
def __update_winner(self, curnode):
"""."""
# find nearest unit and second nearest unit
winner1, winner2 = self._determine_2closest_vertices(curnode)
winner_node1 = winner1[0]
winner_node2 = winner2[0]
win_dist_from_node = winner1[1]
graph = self._graph
g_nodes = graph.nodes
# Update the winner error.
g_nodes[winner_node1]['error'] += + win_dist_from_node**2
# Move the winner node towards current node.
g_nodes[winner_node1]['pos'] += self._eps_b * (curnode - g_nodes[winner_node1]['pos'])
eps_n = self._eps_n
# Now update all the neighbors distances.
for n in nx.all_neighbors(graph, winner_node1):
g_nodes[n]['pos'] += eps_n * (curnode - g_nodes[n]['pos'])
# Update age of the edges, emanating from the winner.
for e in graph.edges(winner_node1, data=True):
e[2]['age'] += 1
# Create or zeroe edge between two winner nodes.
graph.add_edge(winner_node1, winner_node2, age=0)
# if there are ages more than maximum allowed age, remove them
age_of_edges = nx.get_edge_attributes(graph, 'age')
max_age = self._max_age
for edge, age in age_of_edges.items():
if age >= max_age:
graph.remove_edge(edge[0], edge[1])
# If it causes isolated vertix, remove that vertex as well.
for node in g_nodes:
if not graph.neighbors(node):
graph.remove_node(node)
def __get_average_dist(self, a, b):
"""."""
return (a + b) / 2
def __calinski_harabaz_score(self):
graph = self._graph
nodes = graph.nodes
extra_disp, intra_disp = 0., 0.
# CHI = [B / (c - 1)]/[W / (n - c)]
# Total numb er of neurons.
#ns = nx.get_node_attributes(self._graph, 'n_type')
c = len(nodes)
# Total number of data.
n = len(self._data)
# Mean of the all data.
mean = np.mean(self._data, axis=1)
pos = nx.get_node_attributes(self._graph, 'pos')
for node, k in pos.items():
mean_k = np.mean(k)
extra_disp += len(k) * np.sum((mean_k - mean) ** 2)
intra_disp += np.sum((k - mean_k) ** 2)
def _save_img(self, fignum, training_step):
"""."""
title = 'Growing Neural Gas for the network anomalies detection'
if self._surface_graph is not None:
text = OrderedDict([
('Image', fignum),
('Training step', training_step),
('Time', '{} s'.format(round(time.time() - self._start_time, 2))),
('Clusters count', self.number_of_clusters()),
('Neurons', len(self._graph)),
('Connections', len(self._graph.edges)),
('Data records', len(self._data))
])
draw_graph3d(self._surface_graph, fignum, title=title)
graph = self._graph
if len(graph) > 0:
draw_graph3d(graph, fignum, clear=False, node_color=(1, 0, 0),
title=title,
text=text)
mlab.savefig("{0}/{1}.png".format(self._output_images_dir, str(fignum)))
def sort_nicely(limages):
"""Numeric string sort"""
def convert(text): return int(text) if text.isdigit() else text
def alphanum_key(key): return [convert(c) for c in re.split('([0-9]+)', key)]
limages = sorted(limages, key=alphanum_key)
return limages
def convert_images_to_gif(output_images_dir, output_gif):
"""Convert a list of images to a gif."""
image_dir = "{0}/*.png".format(output_images_dir)
list_images = glob.glob(image_dir)
file_names = sort_nicely(list_images)
images = [imageio.imread(fn) for fn in file_names]
imageio.mimsave(output_gif, images)
def test_detector(use_hosts_data, max_iters, alg, output_images_dir='images', output_gif='output.gif'):
"""Detector quality testing routine"""
#data = read_ids_data('NSL_KDD/20 Percent Training Set.csv')
frame = '-' * 70
training_set = 'NSL_KDD/Small Training Set.csv'
#training_set = 'NSL_KDD/KDDTest-21.txt'
testing_set = 'NSL_KDD/KDDTest-21.txt'
#testing_set = 'NSL_KDD/KDDTrain+.txt'
print('{}\n{}\n{}'.format(frame, '{} detector training...'.format(alg.__name__), frame))
data = read_ids_data(training_set, activity_type='normal', with_host=use_hosts_data)
data = preprocessing.normalize(np.array(data, dtype='float64'), axis=1, norm='l1', copy=False)
G = create_data_graph(data)
gng = alg(data, surface_graph=G, output_images_dir=output_images_dir)
gng.train(max_iterations=max_iters, save_step=50)
print('Saving GIF file...')
convert_images_to_gif(output_images_dir, output_gif)
print('{}\n{}\n{}'.format(frame, 'Applying detector to the normal activity using the training set...', frame))
gng.detect_anomalies(data)
for a_type in ['abnormal', 'full']:
print('{}\n{}\n{}'.format(frame, 'Applying detector to the {} activity using the training set...'.format(a_type), frame))
d_data = read_ids_data(training_set, activity_type=a_type, with_host=use_hosts_data)
d_data = preprocessing.normalize(np.array(d_data, dtype='float64'), axis=1, norm='l1', copy=False)
gng.detect_anomalies(d_data)
dt = OrderedDict([('normal', None), ('abnormal', None), ('full', None)])
for a_type in dt.keys():
print('{}\n{}\n{}'.format(frame, 'Applying detector to the {} activity using the testing set without adaptive learning...'.format(a_type), frame))
d = read_ids_data(testing_set, activity_type=a_type, with_host=use_hosts_data)
dt[a_type] = d = preprocessing.normalize(np.array(d, dtype='float64'), axis=1, norm='l1', copy=False)
gng.detect_anomalies(d, save_step=1000, train=False)
for a_type in ['full']:
print('{}\n{}\n{}'.format(frame, 'Applying detector to the {} activity using the testing set with adaptive learning...'.format(a_type), frame))
gng.detect_anomalies(dt[a_type], train=True, save_step=1000)
def main():
"""Entry point"""
start_time = time.time()
mlab.options.offscreen = True
test_detector(use_hosts_data=False, max_iters=7000, alg=GNG, output_gif='gng_wohosts.gif')
print('Working time = {}'.format(round(time.time() - start_time, 2)))
test_detector(use_hosts_data=True, max_iters=7000, alg=GNG, output_gif='gng_whosts.gif')
print('Working time = {}'.format(round(time.time() - start_time, 2)))
test_detector(use_hosts_data=False, max_iters=100, alg=IGNG, output_gif='igng_wohosts.gif')
print('Working time = {}'.format(round(time.time() - start_time, 2)))
test_detector(use_hosts_data=True, max_iters=100, alg=IGNG, output_gif='igng_whosts.gif')
print('Full working time = {}'.format(round(time.time() - start_time, 2)))
return 0
if __name__ == "__main__":
exit(main())
Результаты
Прототип однопоточный и медленный. Потому, его обучение на больших выборках занимает достаточно много времени (по нескольку часов для каждого алгоритма), а распределение результатов примерно соответствует маленькой выборке.
Потому, и в связи с недостатком времени, финальное обучение я провёл на маленькой выборке.
Сначала детектор был обучен на обучающей выборке, затем применён к выборке на которой он учился.
После чего, обученный детектор был применён к аномальным и к полным данным из того же множества, из которого была построена обучающая выборка.
Затем, тоже самое было повторено на тестовых выборках.
Заданные параметры:
- Количество шагов обучения для GNG: 7000.
- Количество нормальных записей в обучающей выборке: 516.
- Количество аномальных записей для первой проверки: 495.
- Количество нормальных записей в тестовой выборке: 2152.
- Количество аномальных записей в тестовой выборке: 9698.
- Полный размер тестовой выборки: 11850.
----------------------------------------------------------------------
GNG detector training...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was not included]...
Records count: 516
Ouput images will be saved in: images
Training time = 0.0 s, Time per record = 5.54461811864e-09 s, Training step = 1/7000, Clusters count = 1, Neurons = 2
Training time = 0.04 s, Time per record = 7.09027282951e-05 s, Training step = 2/7000, Clusters count = 1, Neurons = 2
Training time = 0.07 s, Time per record = 0.000142523022585 s, Training step = 3/7000, Clusters count = 1, Neurons = 2
Training time = 0.11 s, Time per record = 0.000216007694718 s, Training step = 4/7000, Clusters count = 1, Neurons = 2
Training time = 0.16 s, Time per record = 0.000302943610406 s, Training step = 5/7000, Clusters count = 1, Neurons = 2
Training time = 0.2 s, Time per record = 0.000389085259548 s, Training step = 6/7000, Clusters count = 1, Neurons = 2
Training time = 0.25 s, Time per record = 0.000486224658729 s, Training step = 7/7000, Clusters count = 1, Neurons = 2
Training time = 0.3 s, Time per record = 0.000579897285432 s, Training step = 8/7000, Clusters count = 1, Neurons = 2
Training time = 0.35 s, Time per record = 0.000673654929612 s, Training step = 9/7000, Clusters count = 1, Neurons = 2
...
Training time = 1889.7 s, Time per record = 3.66220002119 s, Training step = 6986/7000, Clusters count = 78, Neurons = 351
Training time = 1890.16 s, Time per record = 3.66309242239 s, Training step = 6987/7000, Clusters count = 78, Neurons = 351
Training time = 1890.61 s, Time per record = 3.6639701858 s, Training step = 6988/7000, Clusters count = 78, Neurons = 351
Training time = 1891.07 s, Time per record = 3.66486349586 s, Training step = 6989/7000, Clusters count = 78, Neurons = 351
Training time = 1891.52 s, Time per record = 3.66574243797 s, Training step = 6990/7000, Clusters count = 78, Neurons = 351
Training time = 1891.98 s, Time per record = 3.66663252291 s, Training step = 6991/7000, Clusters count = 78, Neurons = 351
Training time = 1892.43 s, Time per record = 3.6675082556 s, Training step = 6992/7000, Clusters count = 78, Neurons = 351
Training time = 1892.9 s, Time per record = 3.66840752705 s, Training step = 6993/7000, Clusters count = 78, Neurons = 351
Training time = 1893.35 s, Time per record = 3.66929203087 s, Training step = 6994/7000, Clusters count = 78, Neurons = 351
Training time = 1893.81 s, Time per record = 3.6701756531 s, Training step = 6995/7000, Clusters count = 78, Neurons = 351
Training time = 1894.26 s, Time per record = 3.67105510068 s, Training step = 6996/7000, Clusters count = 78, Neurons = 351
Training time = 1894.71 s, Time per record = 3.67192640508 s, Training step = 6997/7000, Clusters count = 78, Neurons = 351
Training time = 1895.18 s, Time per record = 3.67282555408 s, Training step = 6998/7000, Clusters count = 78, Neurons = 351
Training time = 1895.63 s, Time per record = 3.67370033726 s, Training step = 6999/7000, Clusters count = 78, Neurons = 351
Training complete, clusters count = 78, training time = 1896.09 s
Saving GIF file...
----------------------------------------------------------------------
Applying detector to the normal activity using the training set...
----------------------------------------------------------------------
Abnormal records = 0, Normal records = 1, Detection time = 0.2 s, Time per record = 0 s
Abnormal records = 0, Normal records = 101, Detection time = 0.24 s, Time per record = 0.00244196891785 s
Abnormal records = 0, Normal records = 201, Detection time = 0.28 s, Time per record = 0.00141963005066 s
Abnormal records = 0, Normal records = 301, Detection time = 0.32 s, Time per record = 0.00107904990514 s
Abnormal records = 0, Normal records = 401, Detection time = 0.36 s, Time per record = 0.000907952189445 s
Abnormal records = 0, Normal records = 501, Detection time = 0.4 s, Time per record = 0.000804873943329 s
Anomalies weren't detected [abnormal records = 0, normal records = 516, detection time = 0.41 s, time per record = 0.000791241956312 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the training set...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was not included]...
Records count: 495
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 62, Normal records = 39, Detection time = 0.04 s, Time per record = 0.000383739471436 s
Abnormal records = 133, Normal records = 68, Detection time = 0.08 s, Time per record = 0.000377835035324 s
Abnormal records = 198, Normal records = 103, Detection time = 0.12 s, Time per record = 0.000388882954915 s
Abnormal records = 269, Normal records = 132, Detection time = 0.15 s, Time per record = 0.000385674834251 s
Anomalies were detected (count = 7) [abnormal records = 344, normal records = 151, detection time = 0.19 s, time per record = 0.000390153461032 s]
----------------------------------------------------------------------
Applying detector to the full activity using the training set...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was not included]...
Records count: 1011
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 29, Normal records = 72, Detection time = 0.04 s, Time per record = 0.000397310256958 s
Abnormal records = 58, Normal records = 143, Detection time = 0.08 s, Time per record = 0.000394929647446 s
Abnormal records = 90, Normal records = 211, Detection time = 0.12 s, Time per record = 0.000392502943675 s
Abnormal records = 123, Normal records = 278, Detection time = 0.16 s, Time per record = 0.000393797159195 s
Abnormal records = 156, Normal records = 345, Detection time = 0.2 s, Time per record = 0.000392875671387 s
Abnormal records = 188, Normal records = 413, Detection time = 0.24 s, Time per record = 0.000391929944356 s
Abnormal records = 218, Normal records = 483, Detection time = 0.27 s, Time per record = 0.000391151223864 s
Abnormal records = 259, Normal records = 542, Detection time = 0.31 s, Time per record = 0.000390258729458 s
Abnormal records = 294, Normal records = 607, Detection time = 0.35 s, Time per record = 0.000389169851939 s
Abnormal records = 335, Normal records = 666, Detection time = 0.39 s, Time per record = 0.000388996839523 s
Anomalies were detected (count = 7) [abnormal records = 344, normal records = 667, detection time = 0.39 s, time per record = 0.000388572524964 s]
----------------------------------------------------------------------
Applying detector to the normal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was not included]...
Records count: 2152
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 368, Normal records = 633, Detection time = 0.4 s, Time per record = 0.000396910905838 s
Abnormal records = 737, Normal records = 1264, Detection time = 0.81 s, Time per record = 0.000405857920647 s
Anomalies were detected (count = 7) [abnormal records = 794, normal records = 1358, detection time = 0.88 s, time per record = 0.00040672259703 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was not included]...
Records count: 9698
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 776, Normal records = 225, Detection time = 0.39 s, Time per record = 0.000390892028809 s
Abnormal records = 1547, Normal records = 454, Detection time = 0.78 s, Time per record = 0.000388429045677 s
Abnormal records = 2332, Normal records = 669, Detection time = 1.16 s, Time per record = 0.000386790037155 s
Abnormal records = 3117, Normal records = 884, Detection time = 1.56 s, Time per record = 0.000389873743057 s
Abnormal records = 3899, Normal records = 1102, Detection time = 1.95 s, Time per record = 0.000389337825775 s
Abnormal records = 4700, Normal records = 1301, Detection time = 2.33 s, Time per record = 0.000388201673826 s
Abnormal records = 5502, Normal records = 1499, Detection time = 2.71 s, Time per record = 0.000387295722961 s
Abnormal records = 6277, Normal records = 1724, Detection time = 3.1 s, Time per record = 0.000387670874596 s
Abnormal records = 7063, Normal records = 1938, Detection time = 3.49 s, Time per record = 0.000387644237942 s
Anomalies were detected (count = 154) [abnormal records = 7605, normal records = 2093, detection time = 3.75 s, time per record = 0.000387096114935 s]
----------------------------------------------------------------------
Applying detector to the full activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was not included]...
Records count: 11850
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 698, Normal records = 303, Detection time = 0.39 s, Time per record = 0.000389461040497 s
Abnormal records = 1396, Normal records = 605, Detection time = 0.77 s, Time per record = 0.000386721491814 s
Abnormal records = 2092, Normal records = 909, Detection time = 1.17 s, Time per record = 0.000389091014862 s
Abnormal records = 2808, Normal records = 1193, Detection time = 1.56 s, Time per record = 0.00038931697607 s
Abnormal records = 3519, Normal records = 1482, Detection time = 1.95 s, Time per record = 0.000389059782028 s
Abnormal records = 4229, Normal records = 1772, Detection time = 2.33 s, Time per record = 0.000388749321302 s
Abnormal records = 4957, Normal records = 2044, Detection time = 2.72 s, Time per record = 0.000388323715755 s
Abnormal records = 5668, Normal records = 2333, Detection time = 3.11 s, Time per record = 0.00038857537508 s
Abnormal records = 6376, Normal records = 2625, Detection time = 3.51 s, Time per record = 0.000389481120639 s
Abnormal records = 7079, Normal records = 2922, Detection time = 3.89 s, Time per record = 0.000389060306549 s
Abnormal records = 7800, Normal records = 3201, Detection time = 4.27 s, Time per record = 0.000388331630013 s
Anomalies were detected (count = 161) [abnormal records = 8399, normal records = 3451, detection time = 4.61 s, time per record = 0.000388800504338 s]
Working time = 1914.96
----------------------------------------------------------------------
GNG detector training...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was included]...
Records count: 516
Ouput images will be saved in: images
Training time = 0.0 s, Time per record = 6.00666962853e-09 s, Training step = 1/7000, Clusters count = 1, Neurons = 2
Training time = 0.04 s, Time per record = 7.04014024069e-05 s, Training step = 2/7000, Clusters count = 1, Neurons = 2
Training time = 0.07 s, Time per record = 0.000143418940463 s, Training step = 3/7000, Clusters count = 1, Neurons = 2
Training time = 0.11 s, Time per record = 0.000213542649912 s, Training step = 4/7000, Clusters count = 1, Neurons = 2
Training time = 0.15 s, Time per record = 0.000284942083581 s, Training step = 5/7000, Clusters count = 1, Neurons = 2
Training time = 0.19 s, Time per record = 0.00037281781204 s, Training step = 6/7000, Clusters count = 1, Neurons = 2
Training time = 0.23 s, Time per record = 0.0004449033922 s, Training step = 7/7000, Clusters count = 1, Neurons = 2
Training time = 0.27 s, Time per record = 0.000518457372059 s, Training step = 8/7000, Clusters count = 1, Neurons = 2
Training time = 0.3 s, Time per record = 0.00058810701666 s, Training step = 9/7000, Clusters count = 1, Neurons = 2
Training time = 0.34 s, Time per record = 0.000659637672957 s, Training step = 10/7000, Clusters count = 1, Neurons = 2
Training time = 0.38 s, Time per record = 0.000728998073312 s, Training step = 11/7000, Clusters count = 1, Neurons = 2
Training time = 0.41 s, Time per record = 0.0007999751919 s, Training step = 12/7000, Clusters count = 1, Neurons = 2
...
Training time = 1832.99 s, Time per record = 3.55230925804 s, Training step = 6987/7000, Clusters count = 82, Neurons = 351
Training time = 1833.46 s, Time per record = 3.55321220973 s, Training step = 6988/7000, Clusters count = 82, Neurons = 351
Training time = 1833.92 s, Time per record = 3.5541091127 s, Training step = 6989/7000, Clusters count = 82, Neurons = 351
Training time = 1834.39 s, Time per record = 3.55502607194 s, Training step = 6990/7000, Clusters count = 82, Neurons = 351
Training time = 1834.85 s, Time per record = 3.55591803882 s, Training step = 6991/7000, Clusters count = 82, Neurons = 351
Training time = 1835.32 s, Time per record = 3.55682536844 s, Training step = 6992/7000, Clusters count = 82, Neurons = 351
Training time = 1835.78 s, Time per record = 3.55772192857 s, Training step = 6993/7000, Clusters count = 82, Neurons = 351
Training time = 1836.26 s, Time per record = 3.55863503107 s, Training step = 6994/7000, Clusters count = 82, Neurons = 351
Training time = 1836.72 s, Time per record = 3.55953075026 s, Training step = 6995/7000, Clusters count = 82, Neurons = 351
Training time = 1837.19 s, Time per record = 3.56043755823 s, Training step = 6996/7000, Clusters count = 82, Neurons = 351
Training time = 1837.65 s, Time per record = 3.56133750012 s, Training step = 6997/7000, Clusters count = 82, Neurons = 351
Training time = 1838.11 s, Time per record = 3.56223588766 s, Training step = 6998/7000, Clusters count = 82, Neurons = 351
Training time = 1838.58 s, Time per record = 3.56314611851 s, Training step = 6999/7000, Clusters count = 82, Neurons = 351
Training complete, clusters count = 82, training time = 1839.05 s
Saving GIF file...
----------------------------------------------------------------------
Applying detector to the normal activity using the training set...
----------------------------------------------------------------------
Abnormal records = 0, Normal records = 1, Detection time = 0.22 s, Time per record = 0 s
Abnormal records = 0, Normal records = 101, Detection time = 0.26 s, Time per record = 0.00264456033707 s
Abnormal records = 0, Normal records = 201, Detection time = 0.31 s, Time per record = 0.00152621984482 s
Abnormal records = 0, Normal records = 301, Detection time = 0.35 s, Time per record = 0.00115152041117 s
Abnormal records = 0, Normal records = 401, Detection time = 0.39 s, Time per record = 0.000965242385864 s
Abnormal records = 0, Normal records = 501, Detection time = 0.43 s, Time per record = 0.000851732254028 s
Anomalies weren't detected [abnormal records = 0, normal records = 516, detection time = 0.43 s, time per record = 0.00083744387294 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the training set...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was included]...
Records count: 495
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 45, Normal records = 56, Detection time = 0.04 s, Time per record = 0.000407500267029 s
Abnormal records = 96, Normal records = 105, Detection time = 0.08 s, Time per record = 0.000401464700699 s
Abnormal records = 151, Normal records = 150, Detection time = 0.12 s, Time per record = 0.000398120085398 s
Abnormal records = 203, Normal records = 198, Detection time = 0.16 s, Time per record = 0.000406047701836 s
Anomalies were detected (count = 5) [abnormal records = 265, normal records = 230, detection time = 0.2 s, time per record = 0.000403349808972 s]
----------------------------------------------------------------------
Applying detector to the full activity using the training set...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was included]...
Records count: 1011
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 20, Normal records = 81, Detection time = 0.04 s, Time per record = 0.00041876077652 s
Abnormal records = 50, Normal records = 151, Detection time = 0.08 s, Time per record = 0.000415489673615 s
Abnormal records = 76, Normal records = 225, Detection time = 0.13 s, Time per record = 0.000419800281525 s
Abnormal records = 101, Normal records = 300, Detection time = 0.17 s, Time per record = 0.000416232347488 s
Abnormal records = 125, Normal records = 376, Detection time = 0.21 s, Time per record = 0.000413020133972 s
Abnormal records = 155, Normal records = 446, Detection time = 0.25 s, Time per record = 0.000409803390503 s
Abnormal records = 190, Normal records = 511, Detection time = 0.29 s, Time per record = 0.000409148420606 s
Abnormal records = 220, Normal records = 581, Detection time = 0.33 s, Time per record = 0.000412831306458 s
Abnormal records = 253, Normal records = 648, Detection time = 0.37 s, Time per record = 0.000414616531796 s
Abnormal records = 289, Normal records = 712, Detection time = 0.41 s, Time per record = 0.000414277076721 s
Anomalies were detected (count = 5) [abnormal records = 298, normal records = 713, detection time = 0.42 s, time per record = 0.000413806219129 s]
----------------------------------------------------------------------
Applying detector to the normal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was included]...
Records count: 2152
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 324, Normal records = 677, Detection time = 0.4 s, Time per record = 0.000400429010391 s
Abnormal records = 646, Normal records = 1355, Detection time = 0.8 s, Time per record = 0.000398404955864 s
Anomalies were detected (count = 6) [abnormal records = 695, normal records = 1457, detection time = 0.86 s, time per record = 0.000401378675021 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was included]...
Records count: 9698
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 716, Normal records = 285, Detection time = 0.39 s, Time per record = 0.000391721010208 s
Abnormal records = 1424, Normal records = 577, Detection time = 0.79 s, Time per record = 0.000395292520523 s
Abnormal records = 2144, Normal records = 857, Detection time = 1.18 s, Time per record = 0.000393549998601 s
Abnormal records = 2877, Normal records = 1124, Detection time = 1.57 s, Time per record = 0.000393224000931 s
Abnormal records = 3591, Normal records = 1410, Detection time = 1.97 s, Time per record = 0.000394224214554 s
Abnormal records = 4337, Normal records = 1664, Detection time = 2.36 s, Time per record = 0.000393829345703 s
Abnormal records = 5089, Normal records = 1912, Detection time = 2.77 s, Time per record = 0.000395649433136 s
Abnormal records = 5798, Normal records = 2203, Detection time = 3.16 s, Time per record = 0.000395138502121 s
Abnormal records = 6532, Normal records = 2469, Detection time = 3.55 s, Time per record = 0.000394880347782 s
Anomalies were detected (count = 131) [abnormal records = 7027, normal records = 2671, detection time = 3.84 s, time per record = 0.000396096625262 s]
----------------------------------------------------------------------
Applying detector to the full activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was included]...
Records count: 11850
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 622, Normal records = 379, Detection time = 0.4 s, Time per record = 0.000395487070084 s
Abnormal records = 1251, Normal records = 750, Detection time = 0.79 s, Time per record = 0.000395890474319 s
Abnormal records = 1876, Normal records = 1125, Detection time = 1.19 s, Time per record = 0.000395860671997 s
Abnormal records = 2528, Normal records = 1473, Detection time = 1.6 s, Time per record = 0.000399308979511 s
Abnormal records = 3184, Normal records = 1817, Detection time = 1.99 s, Time per record = 0.000397848176956 s
Abnormal records = 3824, Normal records = 2177, Detection time = 2.39 s, Time per record = 0.000397575179736 s
Abnormal records = 4498, Normal records = 2503, Detection time = 2.79 s, Time per record = 0.000398371560233 s
Abnormal records = 5145, Normal records = 2856, Detection time = 3.18 s, Time per record = 0.00039776262641 s
Abnormal records = 5792, Normal records = 3209, Detection time = 3.59 s, Time per record = 0.000398459778892 s
Abnormal records = 6424, Normal records = 3577, Detection time = 3.98 s, Time per record = 0.000397949695587 s
Abnormal records = 7080, Normal records = 3921, Detection time = 4.38 s, Time per record = 0.000397751092911 s
Anomalies were detected (count = 138) [abnormal records = 7619, normal records = 4231, detection time = 4.72 s, time per record = 0.000398021931387 s]
Working time = 3772.93
----------------------------------------------------------------------
IGNG detector training...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was not included]...
Records count: 516
Ouput images will be saved in: images
Iteration 0...
Training time = 0.0 s, Time per record = 4.85154085381e-08 s, Training step = 1, Clusters count = 1, Neurons = 1, CHI = -1.0
Training time = 0.48 s, Time per record = 0.000924686128779 s, Training step = 1, Clusters count = 11, Neurons = 22, CHI = -1.0
Training time = 0.96 s, Time per record = 0.00185829262401 s, Training step = 1, Clusters count = 10, Neurons = 28, CHI = -1.0
Training time = 1.45 s, Time per record = 0.00280647129976 s, Training step = 1, Clusters count = 11, Neurons = 31, CHI = -1.0
Training time = 1.93 s, Time per record = 0.0037418566933 s, Training step = 1, Clusters count = 11, Neurons = 33, CHI = -1.0
Training time = 2.42 s, Time per record = 0.00468139177145 s, Training step = 1, Clusters count = 11, Neurons = 36, CHI = -1.0
Training time = 2.9 s, Time per record = 0.00562962635543 s, Training step = 1, Clusters count = 14, Neurons = 40, CHI = -1.0
...
Training time = 542.57 s, Time per record = 1.05149506783 s, Training step = 1, Clusters count = 20, Neurons = 65, CHI = -1.0
Training time = 543.07 s, Time per record = 1.05246509692 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 543.57 s, Time per record = 1.05343477717 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 544.07 s, Time per record = 1.05440813395 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 544.59 s, Time per record = 1.05540252148 s, Training step = 1, Clusters count = 19, Neurons = 65, CHI = -1.0
Training time = 545.08 s, Time per record = 1.05635387398 s, Training step = 1, Clusters count = 20, Neurons = 65, CHI = -1.0
Training time = 545.58 s, Time per record = 1.05732676179 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 546.22 s, Time per record = 1.05855851395 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 546.72 s, Time per record = 1.0595340641 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 547.22 s, Time per record = 1.06049638571 s, Training step = 1, Clusters count = 20, Neurons = 65, CHI = -1.0
Training time = 547.71 s, Time per record = 1.06145610689 s, Training step = 1, Clusters count = 20, Neurons = 65, CHI = -1.0
Training time = 548.21 s, Time per record = 1.06243183955 s, Training step = 1, Clusters count = 20, Neurons = 65, CHI = -1.0
Training time = 548.7 s, Time per record = 1.06338078292 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 549.2 s, Time per record = 1.0643380252 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 549.7 s, Time per record = 1.06530855654 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training time = 550.19 s, Time per record = 1.0662655932 s, Training step = 1, Clusters count = 19, Neurons = 65, CHI = -1.0
Training time = 550.69 s, Time per record = 1.06722681606 s, Training step = 1, Clusters count = 20, Neurons = 65, CHI = -1.0
Training time = 551.19 s, Time per record = 1.06818968427 s, Training step = 1, Clusters count = 21, Neurons = 65, CHI = -1.0
Training complete, clusters count = 21, training time = 551.68 s
Saving GIF file...
----------------------------------------------------------------------
Applying detector to the normal activity using the training set...
----------------------------------------------------------------------
Abnormal records = 0, Normal records = 1, Detection time = 0.53 s, Time per record = 0 s
Abnormal records = 0, Normal records = 101, Detection time = 0.63 s, Time per record = 0.00633862018585 s
Abnormal records = 0, Normal records = 201, Detection time = 0.73 s, Time per record = 0.00366881489754 s
Abnormal records = 0, Normal records = 301, Detection time = 0.83 s, Time per record = 0.00277556975683 s
Abnormal records = 0, Normal records = 401, Detection time = 0.93 s, Time per record = 0.00232824504375 s
Abnormal records = 0, Normal records = 501, Detection time = 1.03 s, Time per record = 0.00206651210785 s
Anomalies weren't detected [abnormal records = 0, normal records = 516, detection time = 1.05 s, time per record = 0.00203575598177 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the training set...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was not included]...
Records count: 495
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 19, Normal records = 82, Detection time = 0.11 s, Time per record = 0.00108736038208 s
Abnormal records = 41, Normal records = 160, Detection time = 0.21 s, Time per record = 0.00104064464569 s
Abnormal records = 59, Normal records = 242, Detection time = 0.31 s, Time per record = 0.00102363348007 s
Abnormal records = 78, Normal records = 323, Detection time = 0.41 s, Time per record = 0.00101397752762 s
Anomalies were detected (count = 1) [abnormal records = 110, normal records = 385, detection time = 0.5 s, time per record = 0.00100804242221 s]
----------------------------------------------------------------------
Applying detector to the full activity using the training set...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was not included]...
Records count: 1011
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 6, Normal records = 95, Detection time = 0.1 s, Time per record = 0.00101613998413 s
Abnormal records = 18, Normal records = 183, Detection time = 0.2 s, Time per record = 0.00100832462311 s
Abnormal records = 30, Normal records = 271, Detection time = 0.3 s, Time per record = 0.00100745360057 s
Abnormal records = 38, Normal records = 363, Detection time = 0.41 s, Time per record = 0.00101710498333 s
Abnormal records = 48, Normal records = 453, Detection time = 0.51 s, Time per record = 0.00101808595657 s
Abnormal records = 58, Normal records = 543, Detection time = 0.61 s, Time per record = 0.00101492325465 s
Abnormal records = 68, Normal records = 633, Detection time = 0.71 s, Time per record = 0.00101190873555 s
Abnormal records = 76, Normal records = 725, Detection time = 0.81 s, Time per record = 0.00101043373346 s
Abnormal records = 88, Normal records = 813, Detection time = 0.91 s, Time per record = 0.00100836992264 s
Abnormal records = 105, Normal records = 896, Detection time = 1.01 s, Time per record = 0.00100904512405 s
Anomalies were detected (count = 1) [abnormal records = 110, normal records = 901, detection time = 1.02 s, time per record = 0.00100898412521 s]
----------------------------------------------------------------------
Applying detector to the normal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was not included]...
Records count: 2152
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 165, Normal records = 836, Detection time = 1.01 s, Time per record = 0.00101356911659 s
Abnormal records = 344, Normal records = 1657, Detection time = 2.04 s, Time per record = 0.00101889550686 s
Anomalies weren't detected [abnormal records = 372, normal records = 1780, detection time = 2.19 s, time per record = 0.00101830303447 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was not included]...
Records count: 9698
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 289, Normal records = 712, Detection time = 1.01 s, Time per record = 0.0010106010437 s
Abnormal records = 531, Normal records = 1470, Detection time = 2.03 s, Time per record = 0.00101473748684 s
Abnormal records = 806, Normal records = 2195, Detection time = 3.05 s, Time per record = 0.00101690498988 s
Abnormal records = 1085, Normal records = 2916, Detection time = 4.07 s, Time per record = 0.00101814824343 s
Abnormal records = 1340, Normal records = 3661, Detection time = 5.1 s, Time per record = 0.00102022538185 s
Abnormal records = 1615, Normal records = 4386, Detection time = 6.11 s, Time per record = 0.00101814981302 s
Abnormal records = 1910, Normal records = 5091, Detection time = 7.12 s, Time per record = 0.00101696658134 s
Abnormal records = 2177, Normal records = 5824, Detection time = 8.13 s, Time per record = 0.00101655423641 s
Abnormal records = 2437, Normal records = 6564, Detection time = 9.14 s, Time per record = 0.00101562854979 s
Anomalies were detected (count = 27) [abnormal records = 2602, normal records = 7096, detection time = 9.84 s, time per record = 0.00101498390724 s]
----------------------------------------------------------------------
Applying detector to the full activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was not included]...
Records count: 11850
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 264, Normal records = 737, Detection time = 1.01 s, Time per record = 0.00101314496994 s
Abnormal records = 496, Normal records = 1505, Detection time = 2.04 s, Time per record = 0.00101831400394 s
Abnormal records = 748, Normal records = 2253, Detection time = 3.07 s, Time per record = 0.0010246480306 s
Abnormal records = 1000, Normal records = 3001, Detection time = 4.08 s, Time per record = 0.00101987397671 s
Abnormal records = 1264, Normal records = 3737, Detection time = 5.09 s, Time per record = 0.00101791639328 s
Abnormal records = 1488, Normal records = 4513, Detection time = 6.1 s, Time per record = 0.00101627349854 s
Abnormal records = 1761, Normal records = 5240, Detection time = 7.11 s, Time per record = 0.00101523229054 s
Abnormal records = 2019, Normal records = 5982, Detection time = 8.11 s, Time per record = 0.00101378926635 s
Abnormal records = 2282, Normal records = 6719, Detection time = 9.11 s, Time per record = 0.00101193467776 s
Abnormal records = 2530, Normal records = 7471, Detection time = 10.11 s, Time per record = 0.00101094179153 s
Abnormal records = 2781, Normal records = 8220, Detection time = 11.12 s, Time per record = 0.00101091491092 s
Anomalies were detected (count = 28) [abnormal records = 2974, normal records = 8876, detection time = 11.97 s, time per record = 0.00101001697251 s]
Working time = 5537.67
----------------------------------------------------------------------
IGNG detector training...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was included]...
Records count: 516
Ouput images will be saved in: images
Iteration 0...
Training time = 0.0 s, Time per record = 5.03636145777e-08 s, Training step = 1, Clusters count = 1, Neurons = 1, CHI = -1.0
Training time = 0.5 s, Time per record = 0.000959633856781 s, Training step = 1, Clusters count = 11, Neurons = 24, CHI = -1.0
Training time = 1.0 s, Time per record = 0.00193044566369 s, Training step = 1, Clusters count = 11, Neurons = 32, CHI = -1.0
Training time = 1.5 s, Time per record = 0.00290305069251 s, Training step = 1, Clusters count = 13, Neurons = 38, CHI = -1.0
Training time = 2.0 s, Time per record = 0.0038706590963 s, Training step = 1, Clusters count = 16, Neurons = 40, CHI = -1.0
Training time = 2.5 s, Time per record = 0.00484266669251 s, Training step = 1, Clusters count = 14, Neurons = 42, CHI = -1.0
Training time = 3.0 s, Time per record = 0.00581014156342 s, Training step = 1, Clusters count = 17, Neurons = 46, CHI = -1.0
...
Training time = 555.39 s, Time per record = 1.07633200958 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 555.9 s, Time per record = 1.07732224233 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 556.41 s, Time per record = 1.07831773093 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 556.93 s, Time per record = 1.07931286651 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 557.44 s, Time per record = 1.08031143421 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 557.95 s, Time per record = 1.08129599806 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 558.47 s, Time per record = 1.08229697305 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 558.98 s, Time per record = 1.08329910687 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 559.51 s, Time per record = 1.08431409496 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 560.02 s, Time per record = 1.08530911826 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 560.53 s, Time per record = 1.0863001707 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 561.05 s, Time per record = 1.08729686062 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 561.57 s, Time per record = 1.08831085854 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 562.07 s, Time per record = 1.08928472682 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 562.58 s, Time per record = 1.09027189525 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 563.09 s, Time per record = 1.09126116693 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 563.61 s, Time per record = 1.09226539523 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 564.13 s, Time per record = 1.09326583933 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 564.64 s, Time per record = 1.09426376385 s, Training step = 1, Clusters count = 23, Neurons = 70, CHI = -1.0
Training time = 565.15 s, Time per record = 1.09525539755 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 565.67 s, Time per record = 1.09626085259 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 566.2 s, Time per record = 1.09728375193 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 566.72 s, Time per record = 1.09829355996 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training time = 567.24 s, Time per record = 1.09930341697 s, Training step = 1, Clusters count = 22, Neurons = 70, CHI = -1.0
Training complete, clusters count = 22, training time = 567.74 s
Saving GIF file...
----------------------------------------------------------------------
Applying detector to the normal activity using the training set...
----------------------------------------------------------------------
Abnormal records = 0, Normal records = 1, Detection time = 0.58 s, Time per record = 0 s
Abnormal records = 0, Normal records = 101, Detection time = 0.69 s, Time per record = 0.00693108081818 s
Abnormal records = 0, Normal records = 201, Detection time = 0.81 s, Time per record = 0.00403473496437 s
Abnormal records = 0, Normal records = 301, Detection time = 0.92 s, Time per record = 0.00306363026301 s
Abnormal records = 0, Normal records = 401, Detection time = 1.03 s, Time per record = 0.00257846474648 s
Abnormal records = 0, Normal records = 501, Detection time = 1.15 s, Time per record = 0.00229543209076 s
Anomalies weren't detected [abnormal records = 0, normal records = 516, detection time = 1.16 s, time per record = 0.00225632181463 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the training set...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was included]...
Records count: 495
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 19, Normal records = 82, Detection time = 0.11 s, Time per record = 0.00114132165909 s
Abnormal records = 42, Normal records = 159, Detection time = 0.23 s, Time per record = 0.00113487005234 s
Abnormal records = 59, Normal records = 242, Detection time = 0.34 s, Time per record = 0.00112538019816 s
Abnormal records = 79, Normal records = 322, Detection time = 0.45 s, Time per record = 0.00113292753696 s
Anomalies were detected (count = 1) [abnormal records = 111, normal records = 384, detection time = 0.56 s, time per record = 0.0011294605756 s]
----------------------------------------------------------------------
Applying detector to the full activity using the training set...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/Small Training Set.csv" [generated host data was included]...
Records count: 1011
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 6, Normal records = 95, Detection time = 0.11 s, Time per record = 0.00112770080566 s
Abnormal records = 18, Normal records = 183, Detection time = 0.23 s, Time per record = 0.00115751504898 s
Abnormal records = 30, Normal records = 271, Detection time = 0.34 s, Time per record = 0.00114720344543 s
Abnormal records = 38, Normal records = 363, Detection time = 0.45 s, Time per record = 0.00113685250282 s
Abnormal records = 47, Normal records = 454, Detection time = 0.57 s, Time per record = 0.00113049221039 s
Abnormal records = 57, Normal records = 544, Detection time = 0.68 s, Time per record = 0.00112626830737 s
Abnormal records = 67, Normal records = 634, Detection time = 0.79 s, Time per record = 0.00113069295883 s
Abnormal records = 75, Normal records = 726, Detection time = 0.9 s, Time per record = 0.00112736135721 s
Abnormal records = 87, Normal records = 814, Detection time = 1.01 s, Time per record = 0.00112713442908 s
Abnormal records = 104, Normal records = 897, Detection time = 1.13 s, Time per record = 0.00112596797943 s
Anomalies were detected (count = 1) [abnormal records = 109, normal records = 902, detection time = 1.14 s, time per record = 0.0011247270303 s]
----------------------------------------------------------------------
Applying detector to the normal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading normal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was included]...
Records count: 2152
Abnormal records = 1, Normal records = 0, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 165, Normal records = 836, Detection time = 1.13 s, Time per record = 0.00113072776794 s
Abnormal records = 343, Normal records = 1658, Detection time = 2.25 s, Time per record = 0.00112573599815 s
Anomalies weren't detected [abnormal records = 371, normal records = 1781, detection time = 2.42 s, time per record = 0.00112456171929 s]
----------------------------------------------------------------------
Applying detector to the abnormal activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading abnormal activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was included]...
Records count: 9698
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 281, Normal records = 720, Detection time = 1.14 s, Time per record = 0.0011370780468 s
Abnormal records = 514, Normal records = 1487, Detection time = 2.27 s, Time per record = 0.00113358747959 s
Abnormal records = 785, Normal records = 2216, Detection time = 3.39 s, Time per record = 0.00112900535266 s
Abnormal records = 1057, Normal records = 2944, Detection time = 4.51 s, Time per record = 0.00112772023678 s
Abnormal records = 1297, Normal records = 3704, Detection time = 5.63 s, Time per record = 0.00112658400536 s
Abnormal records = 1568, Normal records = 4433, Detection time = 6.76 s, Time per record = 0.00112644219398 s
Abnormal records = 1850, Normal records = 5151, Detection time = 7.89 s, Time per record = 0.00112774443626 s
Abnormal records = 2105, Normal records = 5896, Detection time = 9.02 s, Time per record = 0.00112706288695 s
Abnormal records = 2357, Normal records = 6644, Detection time = 10.14 s, Time per record = 0.00112684233983 s
Anomalies were detected (count = 22) [abnormal records = 2521, normal records = 7177, detection time = 10.92 s, time per record = 0.00112578553695 s]
----------------------------------------------------------------------
Applying detector to the full activity using the testing set without adaptive learning...
----------------------------------------------------------------------
Reading full activity from the file "NSL_KDD/KDDTest-21.txt" [generated host data was included]...
Records count: 11850
Abnormal records = 0, Normal records = 1, Detection time = 0.0 s, Time per record = 0 s
Abnormal records = 253, Normal records = 748, Detection time = 1.13 s, Time per record = 0.00112664413452 s
Abnormal records = 479, Normal records = 1522, Detection time = 2.26 s, Time per record = 0.00113046598434 s
Abnormal records = 722, Normal records = 2279, Detection time = 3.38 s, Time per record = 0.00112577366829 s
Abnormal records = 971, Normal records = 3030, Detection time = 4.51 s, Time per record = 0.00112768054008 s
Abnormal records = 1225, Normal records = 3776, Detection time = 5.64 s, Time per record = 0.00112878522873 s
Abnormal records = 1439, Normal records = 4562, Detection time = 6.76 s, Time per record = 0.00112742733955 s
Abnormal records = 1707, Normal records = 5294, Detection time = 7.89 s, Time per record = 0.00112738772801 s
Abnormal records = 1956, Normal records = 6045, Detection time = 9.01 s, Time per record = 0.00112660801411 s
Abnormal records = 2205, Normal records = 6796, Detection time = 10.14 s, Time per record = 0.00112647589048 s
Abnormal records = 2441, Normal records = 7560, Detection time = 11.26 s, Time per record = 0.0011262802124 s
Abnormal records = 2685, Normal records = 8316, Detection time = 12.39 s, Time per record = 0.00112592681971 s
Anomalies were detected (count = 23) [abnormal records = 2878, normal records = 8972, detection time = 13.34 s, time per record = 0.00112551166035 s]
Full working time = 6245.14Обозначения:
l_time— Время обучения в секундах.te_l_time— Время проверки в секундах на наборе, из которого была сформирована обучающая выборка.te_t_time— Время проверки в секундах на полном наборе данных тестовой выборки.g_l_perc— Процент найденных аномалий для полного набора, из которого была сформирована обучающая выборка.g_t_perc— Процент найденных аномалий для полного набора данных тестовой выборки.f_l_perc— Процент ложных срабатываний для полного набора, из которого была сформирована обучающая выборка.f_t_perc— Процент ложных срабатываний для полного набора данных тестовой выборки.
| Тип | l_time | te_l_time | te_t_time | g_l_perc | g_t_perc | f_l_perc | f_t_perc |
|---|---|---|---|---|---|---|---|
| GNG без host | 1869 | 0.39 | 4.61 | 69.5 | 78.4 | 0 | 36.9 |
| GNG с host | 1839 | 0.42 | 4.72 | 60.2 | 72.5 | 0 | 47.7 |
| IGNG без host | 551 | 1.02 | 11.97 | 22.2 | 26.8 | 0 | 17.3 |
| IGNG с host | 567 | 1.14 | 13.34 | 28.9 | 27.0 | 0 | 20.8 |
Выводы:
- Добавление нескольких дополнительных полей не влияет значительно на скорость обучения детектора.
- Во все случаях на обучающей выборке детекторы показали нулевое количество ложных срабатываний.
- IGNG показал результаты хуже. Возможно, это связано с тем, что некорректно подобраны коэффициенты, либо я некорректно его реализовал (вероятно, проблема в условии остановки).
- В целом, детектор на основе GNG работает, т.к. процент обнаружения превышает процент ложных срабатываний в 1.5-2 раза.
Что возможно улучшить
- Подобрать лучшие параметры для IGNG.
- Исправить адаптивное обучение, которое пока не работает корректно.
- Сделать нормальное адаптивное обучение. Я использую "наивный" вариант адаптивного обучения. Существуют более оптимальные методы. Например, как в статье.
- Сделать нормальную визуализацию. Существуют техники, используемые для визуализации многомерных данных в трёхмерном пространстве. То, как свожу данные к трёхмерным я, полностью не отражает отношений между ними.
- Для улучшения обнаружения, надо учитывать порядок следования событий, что в данной статье обойдено стороной. Лишь частично он мог бы учитываться с использованием адаптивной подстройки, которая сейчас не работает.
- Возможно осуществлять остановку GNG по индексу Калинского-Харабаза. Сейчас, как в классике — по достижении фиксированного количества итераций.
- Существует более эффективный алгоритм — Fast GNG (примерно в 50 раз быстрее, чем GNG), также существуют GPU реализации GNG. Несомненно, что этот факт возможно использовать для ускорения.
Заключение
Получилось хуже, чем я ожидал. Но уже закончился отпуск, так что доделать и изучить ещё несколько моментов я не успеваю. Кратко опишу их здесь.
Касательно топологий и алгоритмов
- Про использование Fast GNG было сказано выше.
- Также возможно поэкспериментировать с "фактором полезности" нейронов о котором упомянуто в статье [21] и в конце статьи [18].
- Алгоритм SOINN возможно мог бы подойти даже лучше, чем GNG, но эту тему надо исследовать.
Состав собираемых данных
- Как видно из структуры атак, важно собирать и анализировать данные протоколов прикладного уровня.
- Дополнительно на узле возможно было бы анализировать системные журналы на наличие странных событий.
Сопутствующие идеи, которые я не затронул
- Как использовать сканер в составе методов обнаружения.
- Обучение на honeypot. Любое взаимодействие с honeypot может считать атакой и быть использовано для обучения детектора.
- Автоматизация подбора параметров обучения. Тема для отдельной статьи, но на данном примере было бы интересно попробовать применить. Например, используя TPOT. Применение генетического алгоритма к параметрам, позволило бы подобрать их быстрее и точнее, чем вручную.
Жду замечаний, вопросов и уточнений.
[1] http://www.irjcs.com/volumes/vol4/iss09/08.SISPCS10095.pdf "J.Rubina Parveen — Neural networks in cyber security — 2017"
[2] http://e-notabene.ru/nb/article_18834.html "Мустафаев А.Г. — Нейросетевая система обнаружения компьютерных атак на основе анализа сетевого трафика — 2016"
[3] https://www.sciencedirect.com/science/article/pii/S2352864816300281 "Haibo Zhang, Qing Huang, Fangwei Li, Jiang Zhu — A network security situation prediction model based on wavelet neural network with optimized parameters — 2016"
[4] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4896428/pdf/pone.0155781.pdf "Min-Joo Kang, Je-Won Kang — Intrusion Detection System Using Deep Neural Network for In-Vehicle Network Security — 2016"
[5] https://journals.nstu.ru/vestnik/download_article?id=3366 "Д.К. Левоневский, Р.Р. Фаткиева — Разработка системы обнаружения аномалий сетевого трафика — 2014"
[6] https://storage.tusur.ru/files/425/КИБЭВС-1005_Жигулин_П.В__Подворчан_Д.Э.pdf "Жигулин П.Э., Подворчан Д.В. — Анализ сетевого трафика с помощью нейронных сетей — 2013"
[7] https://www.sciencedirect.com/science/article/pii/S1877705814003579 "Halenar Igor, Juhasova Bohuslava, Juhas Martin, Nesticky Martin — Application of Neural Networks in Computer Security — 2013"
[8] http://psta.psiras.ru/read/psta2011_3_3-15.pdf "Талалаев А.А., Тищенко И.П., Фраленко В.П., Емельянова Ю.Г. — Нейросетевая технология обнаружения сетевых атак на информационные ресурсы — 2011"
[9] https://pdfs.semanticscholar.org/94f8/e1914ca526f53e9932890a0356394f9806f8.pdf "E.Kesavulu Reddy — Neural Networks for Intrusion Detection and Its Applications — 2013"
[10] http://elib.bsu.by/bitstream/123456789/179040/1/119-122.pdf "Балахонцев А.Ю., Сидорик Д.В., Сидоревич А.Н., Якутович М.В. — Нейросетевая система для обнаружения атак в локальных вычислительных сетях — 2004"
[11] https://www.sans.org/reading-room/whitepapers/detection/application-neural-networks-intrusion-detection-336 "SANS Institute — Application of Neural Networks to Intrusion Detection — 2001"
[12] http://dom8a.ru/cupnewyear2014/prezentation/evlanenkova_paper.pdf "Евлаленкова О. — Применение нейронных сетей для обнаружения вторжений — ?"
[13] https://www.science-education.ru/pdf/2014/6/1632.pdf "Корнев П.А., Пылькин А.Н., Свиридов А.Ю. — Применение инструментария искусственного интеллекта в системах обнаружения вторжений в вычислительные сети — ?"
[14] https://www.researchgate.net/publication/309038723_A_review_of_KDD99_dataset_usage_in_intrusion_detection_and_machine_learning_between_2010_and_2015 "Atilla Ozgur — A review of KDD99 dataset usage in intrusion detection and machine learning between 2010 and 2015 — 2016"
[15] http://citforum.ru/security/internet/ids_overview/ "Корниенко А.А., Слюсаренко И.И. — Системы и методы обнаружения вторжений: современное состояние и направления совершенствования — 2009"
[16] https://moluch.ru/conf/tech/archive/5/1115/ "Боршевников А.В. — Сетевые атаки. Виды. Способы борьбы — 2011"
[17] https://papers.nips.cc/paper/893-a-growing-neural-gas-network-learns-topologies.pdf "Fritzke B. — A Growing Neural Gas Network Learns
Topologies — 1993"
[18] https://www.mql5.com/ru/articles/163 "Субботин А. — Растущий нейронный газ, реализация на языке программирования MQL5 — 2010"
[19] https://www.researchgate.net/publication/4202425_An_incremental_growing_neural_gas_learns_topologies "Prudent Y., Ennaji A. — An incremental growing neural gas learns topologies — 2005"
[20] https://cyberleninka.ru/article/v/modifitsirovannyy-algoritm-rastuschego-neyronnogo-gaza-primenitelno-k-zadache-klassifikatsii "Муравьёв А.С., Белоусов А.А. — Модифицированный алгоритм растущего нейронного газа, применительно к задаче классификации — 2014
[21] http://www.booru.net/download/MasterThesisProj.pdf "Jim Holmstrom — Growing Neural Gas
Experiments with GNG, GNG with Utility and Supervised GNG — 2002"
Комментарии (2)

artiom_n Автор
15.06.2018 12:07Я раньше не был знаком с GNG семейством алгоритмов кластеризации. Всегда приятно открыть для себя что-то новое и, возможно в будущем, полезное :)
Самый интересный момент в том, что их действительно семейство. Но в русском сегменте Интернета (да и в английском тоже) чаще всего упоминают только один алгоритм GNG, который был описан ещё в 90-х.
Один единственный совет: для оценки качества в данном случае лучше использовать такие метрики как: ROC-кривая, AUC-ROC и EER. Если у вас сохранились «сырые» результаты детектирования (до отсечки по порогу), то еще не поздно добавить эти метрики в статью. Было бы очень интересно на них взглянуть.
В таблице и в протоколе приведены именно данные классификатора до отсечки (той, которая определяет наличие аномалии по порогу). Данные для каждого сэмпла я сейчас не сохраняю. Оценку по ROC в данный момент делать не буду: просто нет времени, надо заниматься с другим проектом. Если имеется желание, код открыт, на вопросы по нему отвечу и в меру наличия времени попытаюсь помочь с решением проблем, если возникнут.
truggvy
Спасибо за отличную статью с приличной детализацией!
Я раньше не был знаком с GNG семейством алгоритмов кластеризации. Всегда приятно открыть для себя что-то новое и, возможно в будущем, полезное :)
Один единственный совет: для оценки качества в данном случае лучше использовать такие метрики как: ROC-кривая, AUC-ROC и EER. Если у вас сохранились «сырые» результаты детектирования (до отсечки по порогу), то еще не поздно добавить эти метрики в статью. Было бы очень интересно на них взглянуть.