
Codec 2 предназначен для кодирования только речи. И хотя битрейт впечатляет, звук не такой качественный, как в случае Opus, что можно услышать в аудиопримерах. Тем не менее, в сочетании с нейросетью (WaveNet) кодек демонстрирует впечатляющие результаты.
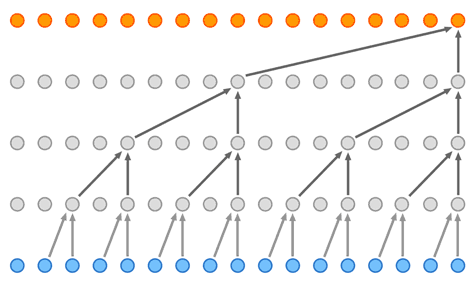
Слои нейронной сети WaveNet
Введение
Codec 2 распространяется с открытым исходным кодом и предназначен для кодирования речи. Он ориентируется на битрейт от 700 до 3200 бит/с.
Разработчик — Дэвид Роу, инженер-электроник, в настоящее время живущий в Южной Австралии. Он начал проект в сентябре 2009 года с целью совершенствования недорогой радиосвязи для людей в отдалённых районах мира. С этой целью он собирался разработать кодек, который значительно уменьшит размер файлов и требования к пропускной способности канала при потоковой передаче.
Другой мотивацией, по словам Дэвида, было создание свободного от патентного обременения кодека как альтернативы проприетарным кодекам, которые, по его мнению, «требуют оформления дорогостоящих и неуклюжих лицензий и душат инновации». Он считает, что можно обойтись без запатентованных кодеков, поэтому всю работу распространяет под свободной лицензией.
Потенциальное применение
Автор называет различные применения кодека, среди них VoIP, голосовая связь по узкой полосе цифрового ВЧ/УВЧ радио (особенно для любительского радио, во избежание проблем с использованием проприетарных кодеков), связь в развивающихся странах и удалённых регионах, включая армию, полицию и спасательные службы.
Мы в компании Auphonic заинтересованы в потенциальном применении кодека для лучшего сжатия подкастов, презентаций и аудиокниг, что позволяет уменьшить объём занимаемого места и свести к минимуму эффект плохих сетевых соединений.
Как это работает
Для снижения битрейта необходимо свести речь к минимально возможной информации/данным, то есть минимизировать объём избыточно передаваемой информации.
Для этого Codec 2 использует гармоническое синусоидальное кодирование речи. Он разделяет речь на сегменты по 10?30 мс, которые называются кадрами. Каждый кадр затем анализируется на предмет фундаментального уровня (pitch) и количества гармоник, которые вписываются в полосу пропускания 4 кГц. Далее для каждой гармоники в диапазоне 4 кГц записываются амплитуда и фаза.
Эта информация затем кодируется, а декодер восстанавливает звук на основе этих данных.
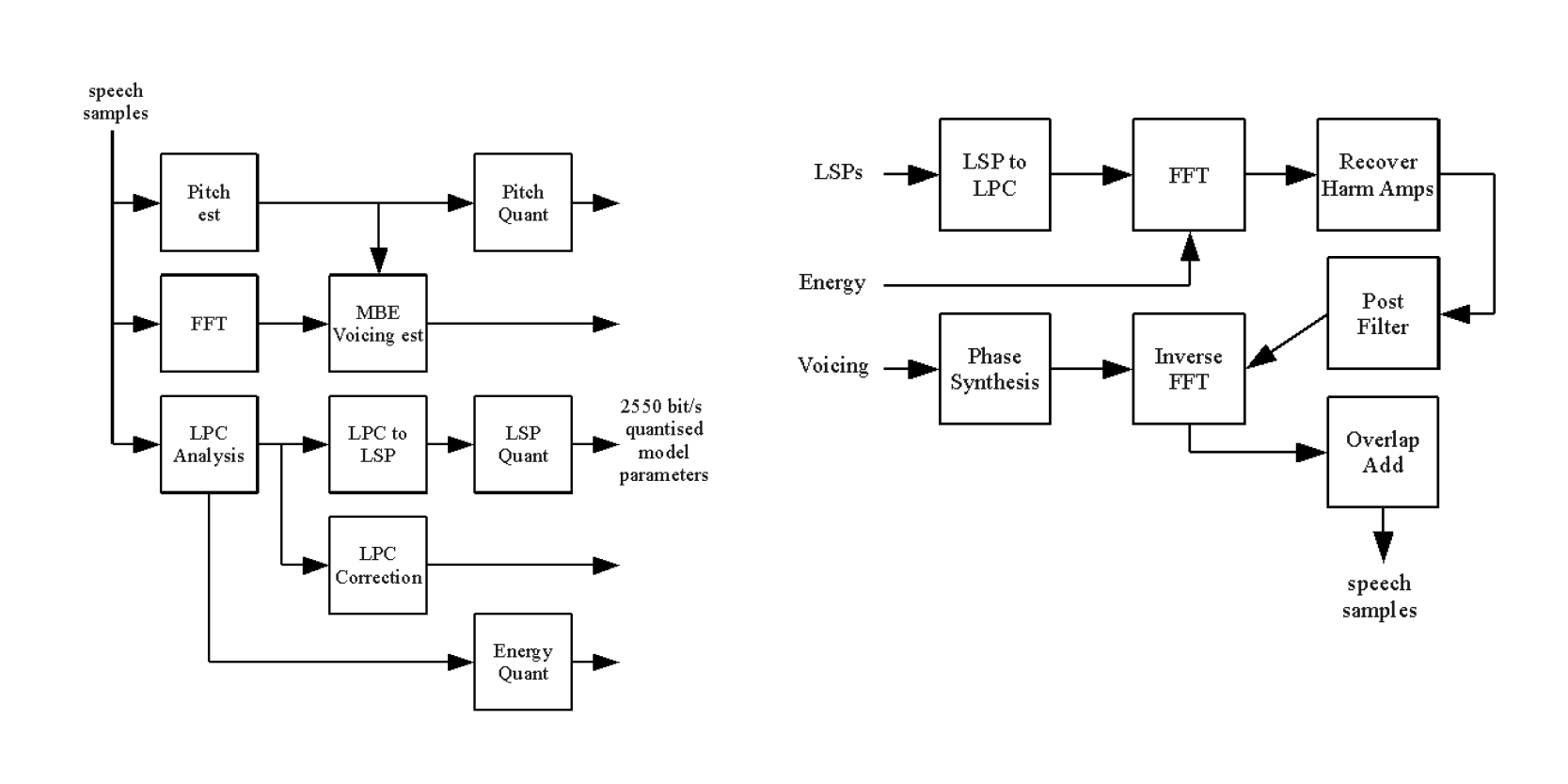
Блок-схемы Codec 2: энкодер (слева) и декодер (справа). Иллюстрация от Rowtel
Аудио примеры и сравнение с другими кодеками
Хотя всё это звучит здорово в теории, но что в реальности? Давайте послушаем. Вот короткий звуковой файл wav:
intro-orig.wav — 1,3 МБ
Применим Codec 2 (без декодера WaveNet) на разных доступных битрейтах: 3200 бит/с, 2400 бит/с, 1600 бит/с, 1200 бит/с и 700 бит/с.
Эти примеры показывают значительное уменьшение размера файлов.
Посмотрим на файлы с точки зрения их объёма для хранения 1 часа звука:
- На 3200 бит/с, один час звука требует всего 1,37 МБ (поместится на одной старой 3?-дюймовой дискете!)
- Битрейт 2400 бит/с соответствует 1,03 МБ/ч
- Битрейт 1600 бит/с равняется 0,68 МБ/ч (или примерно два часа звука на одной дискете!)
- 1200 бит/с — до 0,51 МБ/ч
- 700 бит/с — до 0,3 МБ/ч
Сжатие очень сильное, но результат явно звучит неестественно.
Для сравнения, тот же звук в MP3 на 8 Кбит/с.
Размер файла значительно больше, чем у Codec 2, и качество, вероятно, всё ещё неприемлемо. Можно хорошо слышать то, что иногда называют шипением (sizzle) — странные металлические звуки, присущие MP3 низкого качества.
Есть последний кодек, с которым можно провести сравнение. Кажется, он объединяет оба мира, то есть обеспечивает приемлемое качество на низком битрейте: Opus.
Благодаря его убедительной производительности на низких битрейтах компания Auphonic уже предлагает пользователям кодирование Opus вплоть до 6 Кбит/с, самого низкого битрейта, который поддерживает кодек.
На скорости 6 Кбит/с кодек Opus кажется значительно лучше, чем MP3 8 Кбит/с. Голос немного приглушенный, но всё ещё звучит естественно.
Возвращаясь к Codec 2 чисто ради интереса послушаем, как у него получается кодирование музыки! (Имейте в виду, что Codec 2 не предназначен для кодирования музыки, а только для речи).
Исходный файл
MP3 8 Кбит/с
Лично я не могу слушать MP3 на таком битрейте, поэтому давайте посмотрим на результаты Codec 2! Итак, 3200 бит/с, 2400 бит/с, 1600 бит/с, 1200 бит/с, 700 бит/с.
Несложно понять, что для этой цели он вообще не подходит!
Codec 2 и WaveNet
Как мы уже слышали, несмотря на впечатляющее сжатие, в результате получается не очень естественное звучание.
Но тут дело становится интереснее, если посмотреть на работу Бастиана Кляйна из Библиотеки Корнельского университета. Он использовал Codec 2 на битрейте 2400 бит/с для кодирования, но заменил декодер Codec 2 на генеративную модель глубокого обучения WaveNet (для дополнительной информации см. статью «Кодирование речи с низким битрейтом на основе Wavenet»).
Вот несколько примеров от авторов:
Мужской голос
Исходный файл
Codec 2
С декодером WaveNet
Женский голос
Исходный файл
Codec 2
С декодером WaveNet
По сравнению с Codec 2 мы слышим значительное улучшение качества, а если сравнить с оригиналом, то существенного снижения качества нет.
Сам Дэвид Роу заявил, что считает результат «кардинальным улучшением в кодировании речи при низкой скорости передачи» и «хорошим широкополосным речевым кодеком 8000 бит/с».
Вывод
Хотя (оригинальный) кодек Codec 2 представляет собой очень интересную работу, его сфера использования ограничена, а конечный результат не подходит для подкастинга. Также по аудиопримерам понятно, что его можно использовать для сжатия только голоса, но не музыки.
Тем не менее, Codec 2 в сочетании с декодером WaveNet значительно улучшает качество, а низкий битрейт (2400 бит/с) будет чрезвычайно интересен для распространения подкастов и аудиокниг: на один час звука требуется всего 1,03 МБ места!
Auphonic добавит поддержку Codec 2 в файлы выдачи, когда декодер WaveNet появится в удобной для использования форме. Пока мы добавили поддержку Codec 2 только для входных файлов.
Комментарии (19)

sav6622
28.06.2018 20:36Декодер Wavenet заранее настроен на голос? Или адаптируется самостоятельно под разные голоса?
andrey_gavrilov
28.06.2018 20:39+1«не читал, но обсуждаю!»:
предельным нейросетевым кодеком речи будет писаться нечто, типа текста (фонетического, Ok, и артикуляционных настроек «говорилки» (функционального акустического речевого тракта, реализованного как в сетке-кодировщике, так и в сетке-декодировщике).
Ну, [может] еще и настроек, задающих тип голоса, если кодек «для любого человека». Более широкий еще позволит писать звуки, выпадающие за такое кодирование.
Я к тому, что да, «битрейт» у него очень маленьким может быть в легкую.immaculate
29.06.2018 05:04В комментариях на Hacker News носители языка отметили, что многие слова после кодирования заменяются на другие, с похожим звучанием.
Поскольку я слушаю и смотрю подкасты на других языках с целью развить свое чувство языка, то этот кодек категорически не подходит для подкастов.
Более того, очевидно, что он может непредсказуемым образом изменить смысл передаваемой информации (на HN приводились примеры для английского, я уже не помню, но помню, что числительные менялись, типа 17->70 или наоборот).
Пускай армия США использует этот кодек. «Обнаружено 17 танков противника!» Или 70?
Я лично мало смысла вижу в таком кодировании, которое может радикально изменить смысл кодируемой информации.
truggvy
29.06.2018 10:24Ну уж извините, но при использовании обычного кодека в плохом качестве вы тоже можете не расслышать разницы между «seventeen» и «seventy».
Мне кажется идею просто нужно доработать по аналогии с кодеками для видео (H264/H265). В этих кодеках, помимо прочего, вычисляется и передаётся разница между оригинальным и восстановленным (на стороне энкодера) кадром (residual), что как раз позволяет восстановить мелкие (высокочастотные) детали.immaculate
29.06.2018 10:32Там еще приводились примеры, когда у слов заменяется смысл при использовании данного кодека, как будто он подставляет слова с похожим звучанием. Короче, я не знаю, меня как-то не впечатлило.
Напомнило старую шутку про архиватор, который любой объем пакует в архив размером в 1 байт. Только разархивировать пока невозможно.
Может быть какая-то научная ценность в подобных экспериментах с кодеками и есть, но точно не практическая. Я не знаю, где бы я хотел использовать такой своенравный кодек.
truggvy
29.06.2018 10:56«Другое слово с похожим звучанием» — это как раз и есть ошибка восстановления. И для устранение таких ошибок как раз можно попробовать использовать residual.
А вот пример с архиватором тут не совсем подходит, так как большинство современных кодеков (как аудио, так и видео/отдельных изображений), в отличии от архиваторов, используют сжатие с потерями. Восстановить в точности исходную информацию при таком подходе практически не реально, зато степень сжатия бывает значительно больше (сравните размер PNG и JPG для одного и того же изображения). Борьба идет за минимизацию размера при «приемлемых» искажениях. А вот что считать «приемлемым» — каждый решает для себя сам. «Аудиофилы» плюются от любого MP3, но для многих задач и 8 kb/s MP3 бывает вполне достаточно :)
Alter2
29.06.2018 12:31Проблема существует и в радиопереговорах. Поэтому в авиации, на флоте и в армии проговаривают цифры по отдельности, а буквы по кодам («чарли шесть четыре зулу фокстрот один»).
trapwalker
29.06.2018 13:20Ну ок, хотя бы рэп можно будет декодировать с помощью этой сетки. Кому там какое дело до смысла.
xa6p
28.06.2018 21:01Вот короткий звуковой файл wav:
intro-orig.wav — 1,3 МБ
$ ffmpeg -i https://auphonic.com/media/audio-examples/codec2/intro-orig.wav
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 44100 Hz, 1 channels, s16, 705 kb/s
Применим Codec 2 (без декодера WaveNet) на разных доступных битрейтах: 3200 бит/с…
$ ffmpeg -i https://auphonic.com/media/audio-examples/codec2/intro-orig_3200bps.c2.wav
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 8000 Hz, 1 channels, s16, 128 kb/sчто к чему применили...
а так-то awb 6 kb/s для аудиокниг очень хорошо. жаль кнопочная мобила такого не понимает, приходиться увеличивать размер в 1.5 раза конвертируя в mp3 8 kb/s 16000 Hz.
barbos6
29.06.2018 01:25Вспомнилось. Лет 27 назад развлекался в том числе и передачей голоса со скоростью 2400, ваял курсовой жене.
Принцип почти копировал вокодер — ацп 1113пв1 на isa шине, дпф, сортировка по мощности, передавались амплитуда и сильно огрубленная фаза для пяти самых значимых частот.
Кроме дпф были испробованы преобразования Уолша, Мерсенна, Ферма.
Прототип был написан на Паскале, потом процентов на 80 переписан на ассемблере, как оказалось, зря, ускорение всего на четверть. Вся арифметика целочисленная.
Производительности 386dx40 под DOSом вполне хватало на два дуплексных канала.
Голос передавался весьма разборчиво, иногда с занятными призвуками, абсолютно лишенный индивидуальной тембровой окраски.
Пайка и писанина заняли, помнится, чуть больше недели вечерами.
SopaXT
29.06.2018 07:44Эх, интересно, насколько можно сжать видео с низким разрешением, например монохромное 128x64 @ 15fps.
xa6p
29.06.2018 11:50+1h264: снижение качества начинается после 48 кб/с, а вполне различимо и на 16 кб/с. 10 секунд умещается в 52 и 18 килобайт соответственно. не сильно много движения, собачка ходит по тропинке.
trapwalker
29.06.2018 13:38Это смотря что на видео. Можно, например, распознавать изображение, строить 3d-модель сцены на основе готовых паттернов, передавать текстуры и слать оранжировку.
Смутно вспоминается какое-то произведение научной фантастики, где интеллектуальные системы космических кораблей ухитрялись передавать через очень тонкие каналы прям видеоконференции. Сперва видео шло в высоком качестве, потом канал истончался, а система деградировала сперва внося артефакты простого сжатия, потом переходила на реконструирование сцены, а потом вообще на текстовый чат, в котором даже слова некоторые не несущие особого смысла опускались.
Не уверен, что у человечества будут когда-то стоять такие задачи, когда вычислительные мощности гигантские, а каналы по какой-то причине мизерные.
Кстати, кто напомнит что за книжка мне вспомнилась, получит большое спасибо.SopaXT
29.06.2018 16:52Не уверен, что у человечества будут когда-то стоять такие задачи, когда вычислительные мощности гигантские, а каналы по какой-то причине мизерные.
У радиолюбителей есть узкополосное телевидение (NBTV) — стандартом является 32 строки, 12.5 кадров в секунду, 3-4 кГц полосы пропускания.
Мне стало интересно, можно ли придумать цифровой кодек такого типа.
daserge
29.06.2018 17:25Случаем не «Пламя над бездной»?
trapwalker
29.06.2018 17:42Может быть. У меня очень плохая ассоциативная память на названия, но про «Пламя над бездной» я точно помню, что там крутотень какая-то, но какая именно не помню уже. Надо освежить=) Спасибо.
rPman
30.06.2018 01:23Жаль, что не помните, какой это рассказ.
Не уверен, что у человечества будут когда-то стоять такие задачи, когда вычислительные мощности гигантские, а каналы по какой-то причине мизерные.
межзвездная связь, где из-за большого расстояния и огромных энергозатрат, каждый байт может стоить значительно дороже любых вычислительных мощностей для кодирования.
x893
А прикрутить можно к github.com/x893/codec2?