
В этой серии статей вы познакомитесь с основными принципами функционального программирования и поймёте, что значит «мыслить функционально» и как этот подход отличается от объектно-ориентированного или императивного программирования.

Теперь, когда вы увидели некоторые из причин, по которым стоит использовать F#, в статье «Погружение в F#. Пособие для C#-разработчиков», сделаем шаг назад и обсудим основы функционального программирования. Что в действительности означает «программировать функционально», и чем этот подход отличается от объектно-ориентированного или императивного программирования?
Смена образа мышления (Intro)
Важно понимать, что функциональное программирование — это не просто отдельный стиль программирования. Это совсем другой способ мышления в программировании, который отличается от «традиционного» подхода так же значительно, как настоящее ООП (в стиле Smalltalk) отличается от традиционного императивного языка — такого, как C.
F# позволяет использовать нефункциональные стили кодирования, и это искушает программиста сохранить его существующие привычки. На F# вы можете программировать так, как привыкли, не меняя радикально мировоззрения, и даже не представляя, что при этом упускаете. Однако, чтобы получить от F# максимальную отдачу, а также научиться уверенно программировать в функциональном стиле вообще, очень важно научиться мыслить функционально, а не императивно.
Цель данной серии статей — помочь читателю понять подоплёку функционального программирования и изменить его способ мышления.
Это будет довольно абстрактная серия, хотя я буду использовать множество коротких примеров кода для демонстрации некоторых моментов. Мы рассмотрим следующие темы:
- Математические функции. Первая статья знакомит с математическими представлениями, лежащими в основе функциональных языков и преимуществами, которые приносит данный подход.
- Функции и значения. Следующая знакомит с функциями и значениями, объясняет чем «значения» отличаются от переменных, и какие есть сходства между функциями и простыми значениями.
- Типы. Затем мы перейдем к основным типам, которые работают с функциями: примитивные типы, такие как string и int, тип unit, функциональные типы, и обобщённые типы (generic).
- Функции с несколькими параметрами. Далее я объясню понятия «каррирования» и «частичного применения». В этом месте чьим-то мозгам будет больно, особенно если у этих мозгов только императивное прошлое.
- Определение функций. Затем несколько постов будут посвящены множеству различных способов определения и комбинирования функций.
- Сигнатуры функций. Далее будет важный пост о критическом значении сигнатур функций, что они значат, и как использовать сигнатуры для понимания содержимого функций.
- Организация функций. Когда станет понятно, как создавать функции, возникнет вопрос: как можно их организовать, чтобы сделать доступными для остальной части кода?
Математические функции
Функциональное программирование вдохновлено математикой. Математические функции имеют ряд очень приятных особенностей, которые функциональные языки пытаются претворить в жизнь.
Давайте начнем с математической функции, которая добавляет 1 к числу.
Add1(x) = x+1Что на самом деле означает это выражение? Выглядит довольно просто. Оно означает, что существует такая операция, которая берет число и прибавляет к нему 1.
Добавим немного терминологии:
- Множество допустимых входных значений функции называются domain (область определения). В данном примере, это могло быть множество действительных чисел, но сделаем жизнь проще и ограничимся здесь только целыми числами.
- Множество возможных результатов функции (область значений) называется range (технически, изображение codomain-а). В данном случае также множество целых.
- Функцией называют отображение (в оригинале map) из domain-а в range. (Т.е. из области определения в область значений.)
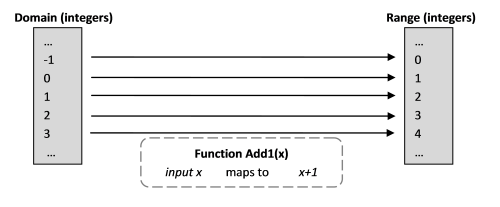
Вот как это определение будет выглядеть на F#.
let add1 x = x + 1Если ввести его в F# Interactive (не забудьте про двойные точку с запятой), то можно увидеть результат («сигнатуру» функции):
val add1 : int -> intРассмотрим вывод подробно:
- Общий смысл — это функция
add1сопоставляет целые числа (из области определения) с целыми числами (из области значений). - «
add1» определена как «val», сокращение от «value» (значения). Хм? что это значит? Мы обсудим значения чуть позже. - Стрелочная нотация «->» используется, чтобы показать domain и range. В данном случае, domain является типом 'int', как и range.
Заметьте, что тип не был указан явно, но компилятор F# решил, что функция работает с int-ами. (Можно ли это изменить? Да, и скоро мы это увидим).
Ключевые свойства математических функций
Математические функции имеют ряд свойств, которые очень сильно отличают их от функций, которые используются в процедурном программировании.
- Функция всегда имеет один и тот же результат для одного и того же входного значения.
- Функция не имеет побочных эффектов.
Эти свойства дают ряд заметных преимуществ, которые функциональные языки программирования пытаются по мере сил реализовать в своем дизайне. Рассмотрим каждое из них по очереди.
Математические функции всегда возвращают одинаковый результат на заданное значение
В императивном программировании мы думаем, что функции либо что-то «делают», либо что-то «подсчитывают». Математические функции ничего не считают, это чистые сопоставления из input в output. В самом деле, другое определение функции — это простое множество всех отображений. Например, очень грубо можно определить функцию «'add1'» (в C#) как
int add1(int input)
{
switch (input)
{
case 0: return 1;
case 1: return 2;
case 2: return 3;
case 3: return 4;
etc ad infinitum
}
}Очевидно, что невозможно иметь по case-у на каждое возможное число, но принцип тот же. При такой постановке никаких вычислений не производится, осуществляется лишь поиск.
Математические функции свободны от побочных эффектов
В математической функции, входное и выходное значения логически две различные вещи, обе являющиеся предопределенными. Функция не изменяет входные или выходные данные и просто отображает предопределенное входное значение из области определения в предварительно определенное выходное значение в области значений.
Другими словами, вычисление функции не может иметь каких либо эффектов на входные данные или еще что-нибудь в подобном роде. Следует запомнить, что вычисление функции в действительности не считает и не манипулирует чем-либо, это просто перехваленный поиск.
Эта «иммутабельность» значений очень тонкая, но в тоже время очень важная вещь. Когда я занимаюсь математикой, я не жду, что числа будут изменяться в процессе их сложения. Например, если у меня дано:
x = 5
y = x+1То я не ожидаю, что x изменится при добавлении к нему 1. Я ожидаю, что получу другое число (y), и x должен остаться нетронутым. В мире математики целые числа уже существуют в неизменяемом множестве, и функция «add1» просто определяет отношения между ними.
Сила чистых функций
Те разновидности функций, что имеют повторяемые результаты и не имеют побочных эффектов называются «чистыми / pure функциями», и с ними можно сделать некоторые интересные вещи:
- Их легко распараллелить. Скажем, можно бы взять целые числа в диапазоне от 1 до 1000 и раздать их 1000 различных процессоров, после чего поручить каждому CPU выполнить «
add1» над соответствующим числом, одновременно будучи уверенным, что нет необходимости в каком-либо взаимодействии между ними. Не потребуется ни блокировок, ни мьютексов, ни семафоров, ни т.п. - Можно использовать функции лениво, вычисляя их тогда, когда это необходимо для логики программы. Можно быть уверенным, что ответ будет точно таким же, независимо от того, проводятся вычисления сейчас или позже.
- Можно лишь один раз провести вычисления функции для конкретного входа, после чего закешировать результат, потому что известно, что данные входные значения будут давать такой же выход.
- Если есть множество чистых функций, их можно вычислять в любом порядке. Опять же, это не может повлиять на финальный результат.
Соответственно, если в языке программирования есть возможность создавать чистые функции, можно немедленно получить множество мощных приемов. И несомненно, все это можно сделать в F#:
- Пример параллельных вычислений был в серии «Why use F#?».
- Ленивое вычисление функций будет обсуждено в серии «Optimization».
- Кэширование результатов функций называется мемоизацией и также будет обсуждено в серии «Optimization».
- Отсутствие необходимости в отслеживании порядка выполнения делает параллельное программирование гораздо проще и позволяет не сталкиваться с багами вызванными сменой порядка функций или рефакторинга.
«Бесполезные» свойства математических функций
Математические функции также имеют некоторые свойства кажущиеся не очень полезными при программировании.
- Входные и выходные значения неизменяемы
- Функции всегда имеют один вход и один выход
Данные свойства отражаются в дизайне функциональных языков программирования. Стоит рассмотреть их по отдельности.
Входные и выходные значения неизменяемы
Иммутабельные значения в теории кажутся хорошей идеей, но как можно реально сделать какую-либо работу, если нет возможности назначить переменную традиционным способом.
Я могу заверить, что это не такая большая проблема как можно представить. В ходе данной серии статей будет ясно, как это работает на практике.
Математические функции всегда имеют один вход и один выход
Как видно из диаграмм, для математической функции всегда существует только один вход и только один выход. Это также верно для функциональных языков программирования, хотя может быть неочевидным при первом использовании.
Это похоже на большое неудобство. Как можно сделать что-либо полезное без функций с двумя (или более) параметрами?
Оказывается, существует путь сделать это, и более того он является абсолютно прозрачным на F#. Называется он «каррированием», и заслуживает отдельного поста, который появится в ближайшее время.
На самом деле, позже выяснится, что эти два «бесполезных» свойства станут невероятно ценными, и будут ключевой частью, которая делает функциональное программирование столь мощным.
Дополнительные ресурсы
Для F# существует множество самоучителей, включая материалы для тех, кто пришел с опытом C# или Java. Следующие ссылки могут быть полезными по мере того, как вы будете глубже изучать F#:
Также описаны еще несколько способов, как начать изучение F#.
И наконец, сообщество F# очень дружелюбно к начинающим. Есть очень активный чат в Slack, поддерживаемый F# Software Foundation, с комнатами для начинающих, к которым вы можете свободно присоединиться. Мы настоятельно рекомендуем вам это сделать!
Не забудьте посетить сайт русскоязычного сообщества F#! Если у вас возникнут вопросы по изучению языка, мы будем рады обсудить их в чатах:
- комната
#ru_generalв Slack-чате F# Software Foundation - чат в Telegram
- чат в Gitter
Об авторах перевода
Автор перевода @kleidemos
 Перевод и редакторские правки сделаны усилиями русскоязычного сообщества F#-разработчиков. Мы также благодарим @schvepsss и @shwars за подготовку данной статьи к публикации.
Перевод и редакторские правки сделаны усилиями русскоязычного сообщества F#-разработчиков. Мы также благодарим @schvepsss и @shwars за подготовку данной статьи к публикации.
Комментарии (46)

Nerlin
03.07.2018 11:13Если есть множество чистых функций, их можно вычислять в любом порядке. Опять же, это не может повлиять на финальный результат.
Думаю, вот этот момент нуждается в пояснении, потому что банальный пример ниже показывает нам обратное (python):
def add2(value): return value + 2 def mul2(value): return value * 2 print add2(mul2(2)) print mul2(add2(2))
Функции чистые, но порядок их применения играет роль, потому что на вход в разных случаях будут подаваться разные значения.shwars Автор
03.07.2018 11:16Я думаю тут речь про то, что некоторое заданное фиксированное выражение на функциональном языке можно вычислять по-разному, и при этом будет получаться одинаковый результат. На математическом языке это называется следствием из теоремы Чёрча-Россера.
fireSparrow
03.07.2018 11:27Речь шла о том, что вот такое будет иметь одинаковый результат:
# Вариант 1 res_add = add2(2) res_mul = mul2(2) # Вариант 2 res_mul = mul2(2) res_add = add2(2)
И в первом, и во втором случае res_mul будет тем же, и res_add будет тем же.
Очевидно, только для чистых функций это гарантировано, потому что если функции используют какую-то глобальную переменную, или ввод-вывод, то порядок их вызова может влиять на результат.
pawlo16
03.07.2018 12:49+1Не обнаружил в статье ни единого аргумента в пользу функционального программирования или языка F#. Наивно было бы ожидать здесь демонстрации решения практических задач методами ФП, но автор не соизволил даже показать традиционный в таких случаях факториал и Фибоначчи, ограничился add1. Это вызывает недоумение.
Далее, говоря о преимуществах ФП, автор забыл отметить недостатки:
— проблемы эффективности функциональных и неизменяемых структур данных
— неоправданный рост когнитивной нагрузки на чтение и понимание кода.
— функциональный код невозможно нормально отлаживать, дебагер не может перейти внутрь однострочного лямбда выражения, из которых состоит типичный ФП код.
Это ставит под сомнение ценность и объективность статьи.Szer
03.07.2018 13:17проблемы эффективности функциональных и неизменяемых структур данных
У них есть как плюсы, так и минусы. Когда минусы перевешивают плюсы в F# достаточно объявить идентификатор как "mutable"
неоправданный рост когнитивной нагрузки на чтение и понимание кода.
Сильно Linq увеличивает когнитивную нагрузку на программиста? Вроде наоборот снижает.
функциональный код невозможно нормально отлаживать, дебагер не может перейти внутрь однострочного лямбда выражения, из которых состоит типичный ФП код.
да всё он может, хватит придумывать.
Брекпоинт внутрь однострочной лямбды:

pawlo16
03.07.2018 14:14-2У них есть как плюсы, так и минусы.
По эффективности у них нет плюсов.
Когда минусы перевешивают плюсы в F# достаточно объявить идентификатор как «mutable»
Если связный список объявить как «mutable», то армотизированная сложность вычисления списка с заменой элемента внезапно станет О(1) как у нормального массива? Не в этой жизни.
Сильно Linq увеличивает когнитивную нагрузку на программиста? Вроде наоборот снижает.
Я бы сказал для типичных простых инструкций, которые в нём пишут, он либо не влияет, либо не критично ухудшает читаемость. Для сложных, которыми любят злоупотреблять новички, читаемость ухудшается значительно, да.
да всё он может, хватит придумывать.
Вы как то нервно реагируете почему-то. У меня не ставится. Возможно, потому что я «забыл» для этого установить какую нибудь vs2018 на 30+ гБ. Увы, внутрь Seq.map я всё ещё попасть не могу чтобы посмотреть значение её второго аргумента. А между тем программа на F# в точности такой же набор инструкций как и её аналог на C#. по логике программистов F# отказ от возможностей отладчика по контролю выполнения кода должен дать какие-то преимущества. Хотелось бы понять — какие именно.JobberNet
03.07.2018 14:17По эффективности у них нет плюсов
А что с какой-то легендарной игрой написанной не на C++, а на Лиспе?
Кто в курсе что и как и почему?
mayorovp
03.07.2018 14:41Для сложных, которыми любят злоупотреблять новички, читаемость ухудшается значительно, да.
По сравнению с чем? С пятью циклами и промежуточными переменными вида
Dictionary<K, List<V>>?pawlo16
04.07.2018 10:46Обычно достаточно одного цикла.
Dictionary<K, List> не потребуется писать явно, в C# есть вывод типов,
Про промежуточные переменные открою секрет — они создаются в любом случае. Даже если их нет в коде, они будут сгенерированы компилятором. Поэтому не вижу в них абсолютно ничего плохого. Промежуточные переменные упрощают отладку кода, когда один из методов делает что-то не то и хочется посмотреть на возвращаемое им значение. Они так же упрощают чтение кода и дают представление об уровне разработчика. Если промежуточные переменные имеют скверные имена, неоправданно длинные или бессмысленно короткие, значит автор кода плохо понимает решаемую им задачу или не ориентируется в предметной области. Это хороший индикатор.
Szer
03.07.2018 15:57+1Возможно, потому что я «забыл» для этого установить какую нибудь vs2018 на 30+ гБ. Увы, внутрь Seq.map я всё ещё попасть не могу чтобы посмотреть значение её второго аргумента.
Это только Ваша проблема. Можно поставить VS Code (40 мегабайт осилите?).
Тот же пример с работающим брекпоинтом в VS Code:

Окошко Locals:

pawlo16
03.07.2018 16:42Это вообще не проблема, поскольку я предпочитаю не связываться с сомнительными инструментами вроде F#. Но вы лукавите, VS Code весит что-то около 250, плюс что-то около 4-х гБ build tools. И F# плагин для неё у меня тоже не функционирует. Естественно это я неумелый, а все перечисленные инструменты идеальные, а настроить их элементарно. Видимо слишком идеальные для меня. Поэтому я предпочитаю C#, который не ломается никогда и умеет в step inside в функции на подобие Seq.map, а не только в брекпойнт на x+1
0xd34df00d
03.07.2018 21:02По эффективности у них нет плюсов.
Есть, если вы пишете многопоточный код. Персистентность означает, что вам нужно сильно меньше заморачиваться.
Если связный список объявить как «mutable», то армотизированная сложность вычисления списка с заменой элемента внезапно станет О(1) как у нормального массива? Не в этой жизни.
Как вы посчитали O(1)?
FoggyFinder
03.07.2018 23:06Если связный список объявить как «mutable», то армотизированная сложность вычисления списка с заменой элемента внезапно станет О(1) как у нормального массива?
Нет, речь не в этом. Сильная сторона F# заключается в том, что в тех случаях когда функциональный подход применять сложно или не выгодно F# позволяет использовать сильные стороны других концепций.
по логике программистов F# отказ от возможностей отладчика по контролю выполнения кода должен дать какие-то преимущества.
Не совсем так. Преимущество заключается в том, что для понимания кода (в том числе и поиска ошибок) отладчик не потребуется.
На практике отладчиком иногда приходится пользоваться и поддержка F# даже в полновесной VS действительно или оставляет желать лучшего или в силу особенностей функциональных конструкций реализация не представляется возможной (оправданной). В таких случаях я переписываю "сложный" участок в более явном виде и тогда никаких проблем нет.
Я бы сказал для типичных простых инструкций, которые в нём пишут, он либо не влияет, либо не критично ухудшает читаемость. Для сложных, которыми любят злоупотреблять новички, читаемость ухудшается значительно, да.
Зависит от форматирования, конечно. Мне приходилось видеть попытки записать все в одну строку. Читать, конечно, было невозможно. Но стоило записать каждый новый вызов с отдельной строки все становится на свои места.
Сложность конструкций также может быть связана с попыткой записать все через Linq даже если в стандартном наборе нет подходящих методов (в F# их намного больше). Вместо того чтобы использовать MoreLinq или написать собственные методы расширения новички стараются похвастаться своими умениям популярной "функциональщины". Давайте им это простим ;)
aikixd
03.07.2018 13:45+3Я много раз пытался объяснить людям положительные стороны функций, но все бестолку. Они ждут что им на пальцах, за пару часов расскажут о целой парадигме. Хотя никто не ожидает что ООП можно объяснить в тот же срок. Люди годами его изучают, придумывают принципы, мнемоники и паттерны. Причем основная масса так никогда его и не осиливает. Но вот функции обязательно надо раскрыть в одной статье. Почти каждый кто стал на них писать не может нарадоваться и всячески толкает и в мир, но для вас это не показатель. Притом что им уже 60 лет. А вот очередное хайповое говно от очередного Гугла учите только так.
пс. не хочу обидеть, но это реально бесит.JobberNet
03.07.2018 13:52-1Они ждут что им на пальцах, за пару часов расскажут о целой парадигме. Хотя никто не ожидает что ООП можно объяснить в тот же срок.
ООП через пару часов уже можно применять хоть с каким-то заметным положительным эффектом.
Мне в своё время, чтобы начать хватило объяснения в одну строку «class это такой struct с функциями внутри». А про то что там ещё бывают private, protected, public и published — об этом я узнал позже, когда уже получил некоторую практику с class.dim2r
03.07.2018 14:18+1Хорошо бы иметь смешанный подход в одном языке. Бывают очень нужны чистые функции для порядка.
pawlo16
03.07.2018 14:41Смешанный подход — это зло. При нём для любой примитивной задачи существует сотня извращённых решений, а код читается весьма тяжело.
Ни кто не запрещает писать вам чистые функции на любом самом что ни на есть императивном языкеdim2r
03.07.2018 15:11есть примеры?
pawlo16
03.07.2018 15:380xd34df00d
03.07.2018 21:04А ничего, что это сильно разные реализации, от функциональности до типобезопасности?
// A heap must be initialized before any of the heap operations // can be used.
Кто это гарантирует и как?pawlo16
04.07.2018 18:04в чём вы там увидели разницу?
в коменте, который вы процитировали, что то есть про гарантии?
pawlo16
03.07.2018 14:36+1Из того, что люди не прониклись вашими объяснениями «положительных сторон функций», вовсе не следует что они глупые или ленивые. Возможно, объяснения ваши не очень или тезисы так себе. Да и грубости на подобие «хайповое говно» не все готовы терпеть.
Типичное передёргивание у вас. Суть моих претензий — отсутствие в материале статьи хоть чего то практически пригодного, а не каких то там глубин Дао.
И ООП здесь совершенно не при чём. Была бы статья в стиле «ООП хорошо потому что шмяк бряк два класса привет мир», к ней бы тоже у меня возникли вопросы. Проблема не в концепциях как таковых (как правило), а в тех, кто их продвигает.
это реально бесит.
примите успокоительное.
CheY
03.07.2018 18:38+2И тем не менее:
— Иммутабельность (как и многие другие ФП-штуки) проникает в кучи языков. И прежде всего из-за того, что она позволяет сделать код надёжнее и предупредить ошибки. Их эффективность во многом обусловлена тем, насколько та или иная машина исполнения/компилятор умеет с ними работать.
— Когнитивная нагрузка опять же неоднозначна и на самом деле повторяет lurning curve типичного ФП-языка. Понять, легко читать и применять какие-нибудь «лямбды», «частичное применение», «свёртки и их производные map, filter и прочие», «композиция функций/pipe-оператор» — элементарно. И это, имхо, значительно облагораживает код по сравнению с традиционными альтернативами. Спроcите любого Android-разработчика, что он думает о retrolambda и ФП-фичах Java 8 и Kotlin'а — уверен, он вам скажет, что это глоток свежего воздуха по сравнению с тем boilerplate-ом, который навязывался до этого. Если же переходить на уровень выше, к типичным ФП-абстракциям, типа монад, функторов, стрелок, линз и дальше, то да, нужно потратить время, чтобы научиться распознавать их в типичных задачах программирования. Но это не сложнее, чем научиться распознавать паттерны GoF — просто немного иначе (и прекрасно дополняет друг друга). Более «алгебраично!» чтоли…
— Тут бы более конкретные примеры языков. Ну и не стоит забывать, что чистые функции значительно проще тестировать, а значит и количество ошибок будет меньше. Но да, определённые сложности есть.
Ну, и оглянитесь вокруг. Если даже C++ втягивает в себя концепции ФП, то это что-то но значит. Как минимум посидеть разобраться в этом стоит. Да и проекты, выполненные чисто на ФП-языках и где сработал принцип «наиболее подходящий инструмент под задачу» — есть и их всё больше.pawlo16
03.07.2018 22:58Иммутабельность не является эксклюзивной опцией ФП и наличествует в C#. F# в плане иммутабельности привносит лишь некоторый синтаксический сахар, не более того. Это так же относится к лямбдам. Они есть практически в любом языке, непосредственного отношения к ФП не имеют, а имеют недостатки в виде доп. нагрузки на gc и рисках утечек памяти, закоторыми нужно постоянно следить. Типичному android разработчику лямбд более чем достаточно, остальные фичи котлина воспринимаются в основном как сомнительный синтаксический сахар.
И нет, неизменяемые структуры данных при прочих равных всегда менее эффективны и более сложны в использовании, чем изменяемые — вне зависимости от рантайма.
Нет, кривая обучения здесь совершенно не при чём, поскольку в F# нет «сложных» фич ФП — ни первоклассных модулей ocaml-а, ни тайпклассов. Стандартные комбинаторы языка F# просты, их поймёт школьник даже при желании. И работающий код, в котором они интенсивно применяются, написать довольно просто. А вот читается и дебажится этот код весьма скверно из-за нелокальности символов. По моему опыту написания и ревью боевого C#/F# кода «традиционный» код с циклами for и операторами return break continue значительно проще для понимания и сопровождения.
Вообще разговор о пользе концепций разумно начинать с описания их недостатков и практических примеров, иллюстрирующих их сравнительную полезность. Доп. стат гарантии — это хорошо, но они всегда связаны с усложнением кода и росте mental cost. Это нормально, конпилятор намеренно вставляет программисту палки в колёса чтобы усложнить для него написание кода вообще и плохого кода в частности. Годные фичи усложняют написание плохого кода в большей степени, чем написание хорошего. Мой опыт в промышленной разработке на платформе .net привёл меня к тезису, противоположному тому, который задекларирован в этой статье — F# не относится к языку с таким прагматичным определением годности фич. Поскольку в нормальной дискуссии доказывает тот кто утверждает (автор), а не тот, кто опровергает (я), то хотелось бы видеть пример практического, а не академического или синтетического кода, подтверждающего полезность F#.CheY
03.07.2018 23:19+1В исходном комментарии вы ставили вопрос о пользе ФП и его изъянах, а не конкретно F#. Я на это и ответил.
В комментариях дальше вы пытаетесь подтвердить своё мнение об «общем» своим опытом работы с «частным» — F#. «ФП — плохо, потому что я работал с F# и мне не понравилось». Как-то это не совсем корректно, не находите?
Давайте я приведу такой же частный пример с Erlang/Elixir'ом, который очень даже фп, и на котором написаны и пишутся тонны софта с высочайшими требованиями как к производительности, так и к надёжности. Но я не говорю, что этот пример доказывает величие и непогрешимость ФП.pawlo16
03.07.2018 23:30Я специально не уточнял, да, но речь шла конечно же об ФП на F#. Я счёл это очевидным в контексте обсуждения статьи. Прошу прощения, если не вольно ввёл в заблуждение. Мои рассуждения частично можно отнести к HAskell, но про Erlang/Elixir дискутировать не готов, поскольку знаю о них на уровне проекта Эйлера. И у меня сложилось впечатление, что эти языки берут не только и не столько опциями ФП, сколько моделью многопоточности и лиспообразным REPL-ом
Borjomy
04.07.2018 10:03Скажите пожалуйста, какие конкретно типичные задачи вы пытаетесь решить с помощью retrolambda или boilerplate?
0xd34df00d
03.07.2018 21:00+1Я хаскелирую, а не F#-ирую, поэтому буду говорить в контексте хаскеля, но это ничего, ведь там всё ещё
хужестроже.
проблемы эффективности функциональных и неизменяемых структур данных
Когда это действительно становится проблемой, к вашим услугам монада ST. Которая, кстати, даёт очень много хороших гарантий на тему локализации вашего мутабельного кода, невидимости мутабельных эффектов извне монады, и так далее.
неоправданный рост когнитивной нагрузки на чтение и понимание кода
Не более, чем привычка. Тем более, смотря с чем сравнивать — абстрактная фабрика фасадов синглтонов не сильно проще, на мой взгляд, да и читать и понимать сколь угодно нетривиальный императивный код с большим состоянием и многопоточностью — так себе удовольствие.
функциональный код невозможно нормально отлаживать, дебагер не может перейти внутрь однострочного лямбда выражения, из которых состоит типичный ФП код
А это не нужно. Ну, почти не нужно. Мне за всю практику нужно было что-то там именно отлаживать дебаггером, наверное, раза два, и оба раза это был сторонний немножко кривой код, не обрабатывающий все паттерны, поэтому мне надо было понять, откуда кидается экзепшн. В ghc с тер пор завезли возможность легко узнавать трейсы, откуда кидаются экзепшоны, а в более строгих языках с тоталити чекером всё ещё проще.
Ну и кроме того, дешевизна создания функций и их композиции, а также все эти чистоты, иммутабельности и прочее означают, что вы даже достаточно сложный алгоритм можете побить на мелкие одно-двухстрочные функции и счастливо их протестировать по отдельности. Ну, тестами обложить. Включая очень клёвый и удобный property-based testing.
dima_mendeleev
03.07.2018 13:19Очевидно, что невозможно иметь по case-у на каждое возможное число
Для приведенного примера (т.е. для типаint) очень даже возможно.
geher
03.07.2018 19:15Как видно из диаграмм, для математической функции всегда существует только один вход и только один выход.
Что-то не понял.
В ФП под математической функцией понимается что-то другое более узкое, чем в математике, или вектор из нескольких аргументов просто обзывается одним входом?
Если первое, то зачем называть это математической функцией. Если второе, то зачем заострять внимание на том, что вход единственный?Neftedollar
03.07.2018 21:21+1В фп нет понятия математической функции. Разработчики ФП языков ориентируются на математические ф-ции.
Если фунция принимает вектор, то да, это один объект. На самомделе можно решить что в математических ф-циях такого нет, но вот вам пример: Корень из 4 возвращает пару (-2,+2) т.е. это обычное дело возвращать множество. Смысл в том, что сопоставление всегда одно и другого быть не может.
Borjomy
04.07.2018 09:54-2Нда… Под Labview я просто устанавливаю флажок в свойствах любой функции (VI) флажок «Preallocated clone reentrant execution» и получаю такой-же эффект с распределениями по процессам, изоляцией и прочим. Только это было реализовано еще 20 лет назад.
DrownHound
«Map» в математическом смысле традиционно переводится на русский как отображение. Многими принято считать, что отображение — наиболее общий вариант, не накладывающий ограничений на входное и выходное множества, а область значений функции является одномерной (или R).
shwars Автор
Спасибо, исправили!