

Академическое проектирование хранилища данных рекомендует держать все в нормализованной форме, со связями между. Тогда накат изменений по реляционной математике даст надежное хранилище с поддержкой транзакций. Atomicity, Consistency, Isolation, Durability — вот это все. Иначе говоря, хранилище специально строится для безопасного обновления данных. Но оно вовсе не оптимально для поиска, особенно широким жестом по таблицам и полям. Нужны индексы, много индексов. Объемы разрастаются, запись замедляется. SQL LIKE не индексируется, а JOIN GROUP BY отправляет медитировать в планировщик запросов.
Возрастающая нагрузка на одну машину вынуждает расширяться, либо вертикально в потолок, либо горизонтально, докупая еще немного узлов. Требования отказоустойчивости заставляет размазывать данные по нескольким узлам. А требование немедленного восстановления после сбоя, без отказа в обслуживании, заставляет настраивать кластер машин так, чтобы в любой момент времени любая из них могла выполнять и запись, и чтение. То есть, уже быть мастером, либо становиться им автоматически и немедленно.
Проблема быстрого поиска решалась установкой рядом второго хранилища, оптимизированного под индексацию. Поиск полнотекстовый, фасетный, со стеммингом и блекджеком. Второе хранилище принимает на вход записи из таблиц первого, анализирует и строит индекс. Таким образом, кластер хранения данных дополнялся еще одним кластером для их поиска. С аналогичной мастер-мастер конфигурацией, чтобы соответствовать общему SLA. Все хорошо, бизнес в восторге, админы спят ночью… пока машин в мастер-мастер кластере не становится больше трех.
Elastic
Движение NoSQL значительно расширило горизонт масштабирования, как для маленьких, так и для больших данных. Узлы NoSQL кластера умеют распределять данные между собой так, чтобы отказ одного или нескольких из них не приводил к отказу в обслуживании всего кластера. Платой за высокую доступность распределенных данных стало невозможность обеспечить их полную согласованность на запись в каждый момент времени. Вместо нее в NoSQL говорят об eventual consistency. То есть, считается, что однажды все данные разойдутся по узлам кластера, и они станут согласованными в конечном счете.
Так реляционная модель дополнилась нереляционной и породила множество движков баз данных, которые с тем или иным успехом решают проблемы треугольника CAP. Разработчики получили в руки модные инструменты для построения своего собственного идеального persistence слоя — на любой вкус, бюджет и профиль нагрузки.
ElasticSearch — это представитель кластерных NoSQL с RESTful JSON API на движке Lucene, с открытым кодом на Java, умеющий не только строить поисковый индекс, но и хранить оригинальный документ. Такой финт помогает переосмыслить роль отдельной СУБД под хранение оригиналов, а то и вовсе от нее отказаться. Конец вступления.
Mapping
Маппинг в ElasticSearch — это что-то вроде схемы (структура таблицы, в терминах SQL), которая говорит как именно нужно индексировать входящие документы (записи, в терминах SQL). Маппинг может быть статическим, динамическим, или отсутствовать. Статический маппинг не разрешает себя менять. Динамический разрешает добавлять новые поля. Если маппинг не указан, ElasticSearch сделает его сам, получив первый документ на запись. Проанализирует структуру полей, сделает некоторые предположения о типах данных в них, пропустит через настройки по-умолчанию и запишет. Такое бессхемное поведение на первый взгляд кажется очень удобным. Но на самом деле подходит больше для экспериментов, чем для сюрпризов в production.
Итак, данные индексируются, и это однонаправленный процесс. Однажды созданный маппинг нельзя изменить динамически как ALTER TABLE в SQL. Потому что таблица SQL хранит оригинальный документ, к которому можно прикрутить поисковый индекс. А в ElasticSearch наоборот. Он сам и есть поисковый индекс, к которому можно прикрутить оригинальный документ. Именно поэтому схема индекса статична. Теоретически, можно было бы либо создать поле в маппинге, либо удалить. А практически, ElasticSearch разрешает только добавлять поля. Попытка удалить поле ни к чему не приводит.
Alias
Псевдоним — эта дополнительное название для индекса ElasticSearch. Псевдонимов может быть несколько для одного индекса. Или один псевдоним для нескольких индексов. Тогда индексы как бы логически объединяются и со стороны выглядят как один. Alias очень удобен для сервисов, которые общаются с индексом на протяжении своей жизни. Например, псевдоним products может прятать за собой как products_v2, так и products_v25, без необходимости менять названия в сервисе. Alias незаменим для миграции данных, когда они уже перекинуты со старой схемы в новую, и нужно переключить приложение на работу с новым индексом. Переключение псевдонима с индекса на индекс — атомарная операция. То есть, выполняется за один шаг без потерь.
Reindex API
Схема данных, маппинг, склонен меняться время от времени. Добавляются новые поля, удаляются ненужные. Если ElasticSearch играет роль единственного хранилища, то нужен некий инструмент смены маппинга на лету. Для этого имеется специальная команда переброса данных с одного индекса в другой, так называемый _reindex API. Работает он с готовым или пустым маппингом индекса-получателя, на стороне сервера, быстро индексируя пачками по 1000 документов за раз.
Переиндексация умеет делать простое преобразование типа поля. Например long в text и назад в long, или boolean в text и назад в boolean. Но -9.99 в boolean уже не умеет, это вам не PHP. С другой стороны, конвертация типа — штука небезопасная. Сервис, написанный на языке с динамической типизацией такой грех, может, и простит. Но если reindex не сможет сконвертировать тип, то документ просто не будет записан. В общем случае, миграция данных должна проходить в 3 этапа: добавляем новое поле, релизим с ним сервис, подчищаем старое.
Добавляется поле так. Берется схема индекса-источника, вписывается новое свойство, создается пустой индекс. Затем запускается переиндексация:
{
"source": {
"index": "test"
},
"dest": {
"index": "test_clone"
}
}Удаляется поле похожим образом. Берется схема индекса-источника, убирается поле, создается пустой индекс. Затем запускается переиндексация со списком копируемых полей:
{
"source": {
"index": "test",
"_source": ["field1", "field3"]
},
"dest": {
"index": "test_clone"
}
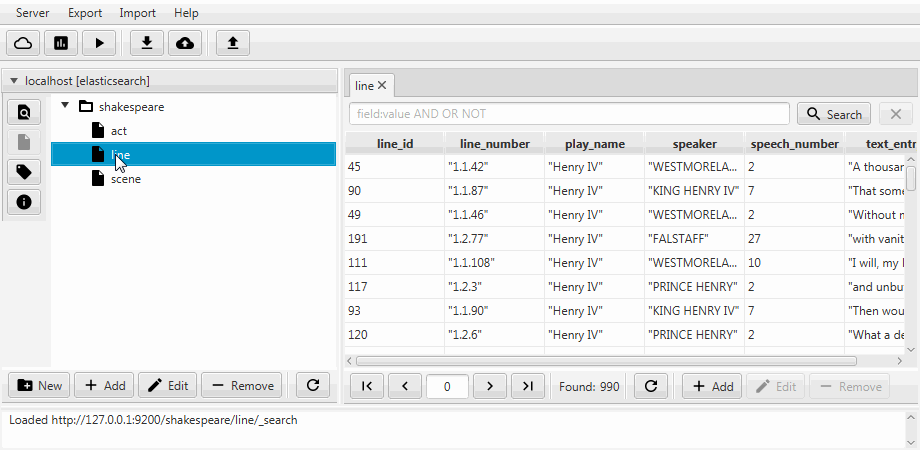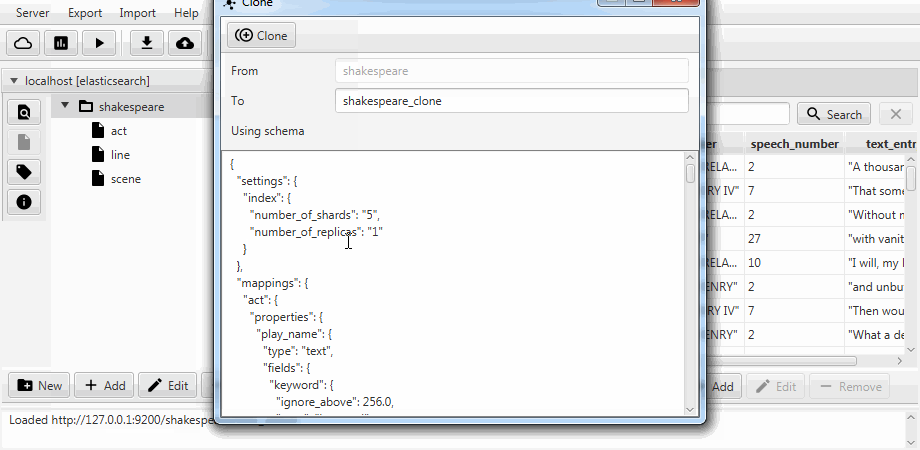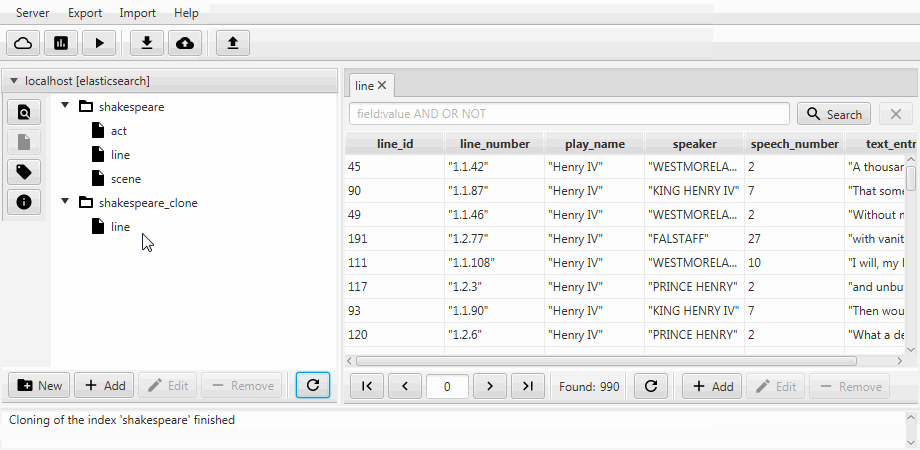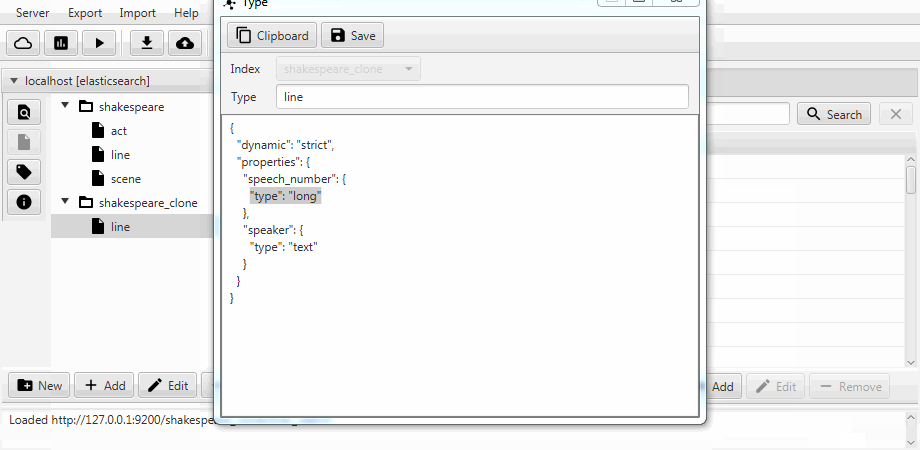
}Для удобства обa случая объединены в функцию клонирования в Kaizen, десктопном клиенте для ElasticSearch. Клонирование умеет подстраиваться под маппинг индекса-получателя. Пример ниже демонстрирует как из индекса с тремя коллекциями (типами, в терминах ElasticSearch) act, line, scene делается частичный клон. В нем остается только line с двумя полями, включается статический маппинг, а поле speech_number из text становится long.
Миграция
У reindex API есть одна неприятная особенность — он не умеет следить за изменениями в индексе-источнике. Если после старта переиндексации там что-то меняется, то изменения не отражаются в индексе-получателе. Для решения этой проблемы был разработан ElasticSearch FollowUp Plugin, который добавляет команды журналирования. Плагин умеет следить за индексом, возвращая в формате JSON действия, производимые над документами в хронологическом порядке. Запоминается индекс, тип, идентификатор документа и операция над ним — INDEX или DELETE. FollowUp Plugin опубликован в GitHub и скомпилирован почти под все версии ElasticSearch.
Итак, для миграция данных без потерь понадобится FollowUp, установленный на узле, на котором будет запускаться переиндексация. Предполагается, что alias у индекса уже имеется, и все приложения работают через него. Непосредственно перед переиндексацией плагин включается. Когда переиндексация завершена, плагин выключается, а alias перебрасывается на новый индекс. Затем записанные действия воспроизводятся на индексе-получателе, догоняя его состояние. Не смотря на высокую скорость переиндексации, во время воспроизведения могут возникнуть два типа коллизий:
- в новом индексе больше нет документа с таким _id. Документ успели удалить после переключения псевдонима на новый индекс.
- в новом индексе есть документ с таким _id, но с номером версии выше чем в индексе-источнике. Документ успели обновить после переключения псевдонима на новый индекс.
В этих случаях действие не должно быть воспроизведено в индексе-получателе. Остальные изменения воспроизводятся.
Happy coding!
kemsky
Решил посмотреть на Kaizen, но на windows он можно сказать еле работает, что-то очень сырой.
olku Автор
Пришлите, пожалуйста, в личку конфигурацию машины, версию JVM, версию ОС и описание места в каком тормозит. Kaizen это JavaFX приложение, сам UI не рендерит. Долгий ответ от сервера ElasticSearch тоже может приводить в ощущению «залипания».