
Я в это время занимался задачей составления оптимальных расписаний, и подумал — а что, если применить оптимизационные алгоритмы для повышения утилизации серверов в ДЦ? Отсюда и родился проект, про который я хочу написать.
Для продвинутых сразу скажу, что в этой статье речь пойдет про bin packing, а остальным, кто хочет узнать, как с помощью относительно несложных расчетов сэкономить до 30% серверных ресурсов, добро пожаловать под кат.
Итак, у нас есть ДЦ с примерно 100 серверами, на которых размещены примерно 7 000 виртуальных машин. Что внутри виртуальных машин — мы не знаем и знать не должны. Нужно разместить виртуальные машины по серверам так, чтобы выполнить SLA и при этом использовать минимальное количество серверов.
Мы знаем:
- список серверов
- количество ресурсов на каждом сервере (CPU time, CPU cores, RAM, disk, disk io, network io).
- список виртуальных машин (VM)
- количество ресурсов, потребляемых каждой виртуальной машиной (CPU time, CPU cores, RAM, disk, disk io, network io).
- потребление ресурсов хост-системой на серверах.
Нам нужно распределить виртуальные машины по серверам так, чтобы по каждому из ресурсов на каждом сервере не превысить доступное количество ресурса, и при этом задействовать минимальное количество серверов.
Данная задача в научной литературе называется bin packing problem (как это будет по-русски?). По простому, это задача о том, как распихать маленькие коробочки произвольных размеров по большим коробкам, и при этом использовать минимальное количество больших коробок. Задача в математике известная, NP-полная, точно решается только полным перебором, стоимость которого комбинаторно растет.
Картинка ниже иллюстрирует суть алгоритма bin packing для одномерного случая:

Рис. 1. Иллюстрация bin packing problem, неоптимальное размещение
На первом рисунке айтемы как-то распределены по корзинам и для их размещения используется 3 корзины.

Рис. 2. Иллюстрация bin packing problem, оптимальное размещение
На второй картинке нарисовано оптимальное распределение, для которого нужно всего 2 корзины.
Стандартная формулировка bin packing алгоритма также предполагает, что все корзины одинаковы. У нас же сервера не одинаковы, так как закупались в разное время и их конфигурация отличается — разное количество ядер процессора, памяти, диска, разная мощность процессоров.
Субоптимальное решение можно получить, используя эвристики, генетические алгоритмы, monte-carlo tree search и глубокие нейронные сети. Мы остановились на эвристическом алгоритме BestFit, который сходится к решению не более чем 1.7 раз хуже оптимального, а также на некоторой вариации генетического алгоритма. Ниже я приведу результаты их применения.
Но сначала обсудим, что делать с метриками, изменяющимися во времени, такими как CPU usage, disk io, network io. Самый простой способ — заменить переменную метрику константой. Но как выбрать значение этой константы? Мы взяли максимальное значение метрики за какой-то характерный период (предварительно сгладив выбросы значений). Характерным периодом в нашем случае оказалась неделя, так как основная сезонность в нагрузке была связана с рабочими и выходными днями.
В этой модели каждой виртуальной машине выделяется полоса ресурса размером с максимально потребляемое значение ресурса, и каждая VM описывается константами max CPU usage, RAM, disk, max disk io, max network io.
Далее применяем алгоритм расчета оптимальной упаковки и получаем карту размещения VM по физическим серверам.
Практика показывает, что если не оставить некоторый запас по каждому из ресурсов на сервере, то при плотном размещении VM сервер становится перегружен. Поэтому по CPU usage мы оставляем запас 30%, по RAM 20%, по disk io — 20%, по network io — 20%, эти лимиты подобраны опытным путем.
Также у нас есть несколько типов дисков (быстрые SSD и медленные дешевые HDD), по каждому из типов дисков мы снимаем метрики disk и disk io отдельно, так что итоговая модель становится несколько сложнее и имеет больше измерений.
Результат оптимизации размещения VM показан на диаграмме:
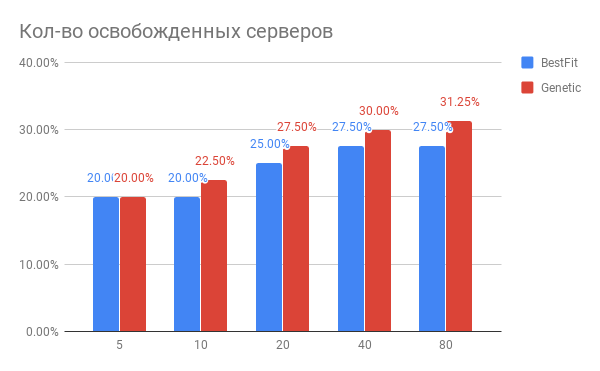
Рис. 3. Результат оптимизации размещения VM по серверам
По горизонтали — количество серверов, которое оптимизировали, по вертикали — количество освобожденных серверов для эвристики BestFit и для генетического алгоритма.
Какие выводы можно сделать из диаграммы?
- Для выполнения текущих задач можно использовать на 20-30% серверов меньше.
- Чем больше серверов за раз оптимизируете, тем больше вы выигрываете в %, при количестве серверов 40 и выше происходит насыщение.
- Генетический алгоритм несколько превосходит эвристический BestFit. Если мы захотим еще улучшить наши результаты, то будем копать в эту сторону.
Какие еще проблемы всплыли на практике?
- Если вы захотите перетрясти около 100 серверов с 7 000 виртуальных машин, то объем миграций окажется весьма значительным, таким, что вся затея окажется нереализуемой. Но если вы будете работать с группами по 20-40 серверов последовательно, то эффект вы получите практически такой же, но количество миграций будет многократно меньше. И вы сможете оптимизировать свой ДЦ по частям.
- Если вы обязательно должны делать live-миграции, то вы можете столкнутся с ситуацией, когда миграция не может закончиться. Это значит, что внутри VM происходит интенсивная запись на диск и/или изменяется состояние памяти, и состояния VM между старой и новой репликами не успевают синхронизироваться до изменения состояния старой реплики. В этом случае нужно заранее определять такие VM машины и помечать их как неперемещаемые. В свою очередь, это требует модификации алгоритмов оптимизации. Что радует, так это то, что общий выигрыш практически не зависит от количества таких машин, если их не более 10-15% от всего числа VM.
Как изменяется нагрузка на сервера после оптимизация размещения VM?
Ок, мы оптимизировали размещение VM. Может быть, получившееся новое состояния весьма хрупкое относительно увеличения нагрузки? Может быть, сервера работают на пределе и любой рост нагрузки их убъет?
Мы сравнили утилизацию ресурсов серверов до оптимизации и после за период в 1 неделю. То, что получилось, нарисовано на рисунке 2:

Рис. 4. Изменение нагрузки на CPU после оптимизации размещения VM
По CPU usage: средний CPU usage вырос с 10% до всего лишь 18%. Т.е. у нас есть трехкратный запас производительности по CPU, при этом сервера будут оставаться в так называемой «зеленой» зоне.
Как это было сделано в софте?
Мы собираем нужные нам метрики в Yandex.ClickHouse (пробовали InfluxDB, но на наших объемах данных запросы с агрегацией в ней выполняются слишком медленно) с периодичностью в 30 сек. Оттуда задача на расчет оптимального состояния читает метрики, рассчитывает по ним максимумы потребления и формирует задание на расчет, которое ставится в очередь. Как только задание на расчет выполняется, запускаются тесты, проверяющие, что результат не выходит за пределы заданных ограничений.
А кто-то это уже сделал?
Из известного нам, аналогичные алгоритмы есть внутри VMware vSphere и Nutanix и появляются внутри OpenStack (проект OpenStack Watcher).
Можно ли сделать еще лучше?
Да, можно. В следующей статье я расскажу, как можно еще плотнее упаковать виртуальные машины без нарушения SLA, и зачем для этого нужны нейронки.
Комментарии (16)

mclouds
06.07.2018 18:07VMware DRS у нас уже все это делает, причем очень эффективно. Учитываются как тренды, так и аптайм конкретного хоста, средняя нагрузка, учитывается очень много параметров, включая объем памяти на хосте, отношение к ядрам. И работает это очень эффективно для производительности конкретных машин. Если надо чтоб какая-то виртуалка не уезжала на другой хост, а была только на каком-то конкретном или ездила только между какими-то хостами, а не по всему кластеру — тоже легко делается.

Dr_Wut
06.07.2018 21:50у меня только один вопрос — что сделают с этим «оптимизатором» когда произойдет поломка оборудования и у него будет жесткий недостаток ресурсов?
Как правило всегда оставляют некий запас оборудования на случай выход аварий/обслуживанияactorai Автор
07.07.2018 09:20Не понимаю проблемы. На кластере даже в несколько десятков серверов выход одного сервера из строя не приведет росту нагрузки на остальные сервера в разы, а только на проценты, а с этим кластер справится.
Chupaka
07.07.2018 09:13Данная задача в научной литературе называется bin packing problem (как это будет по-русски?)
Да примерно так же и будет: задача упаковки в контейнеры. Вариация — задача об укладке ранца (задача о ранце), когда в один заданный надо положить как можно больше всего.
AngryMonk
07.07.2018 09:17Вот дочитал и автор выше(Dr_Wut) как раз задал мой вопрос, о котором я как раз подумал. Первое интересует, это обслуживание, второе это выход диска/сервера.
ildarz
Вроде бы все приличные системы управления виртуализацией умеют оптимизировать нагрузку, причем динамически, поэтому я не очень понимаю область практической применимости решения. Самописный скрипт для кучи неуправляемых серверов?
actorai Автор
Давайте сначала перечислим все приличные системы управления виртуализацией, которые реально часто встречаются в продакшн. Мой опыт ограничивается 3 продуктами: VMware vSphere, Mircosoft SCOM и Openstack. Плюс самописные системы, такое тоже встречается.
VMware vSphere умеет оптимизировать размещение VM, но делает это, насколько я разобрался, на основе краткосрочных трендов (анализирует нагрузку за несколько минут) + порог, по которому она будет перемещать VM на другой сервер, администратор устанавливает сам. В продакшне это чревато тем, что VM может уехать на сервер, на котором уйдет в своп и оттуда её нужно будет доставать руками. И при оптимизации не учитываются долгосрочные тренды, а как раз их учет дает возможность построить глобально оптимальное размещение VM.
Microsoft SCOM не имеет встроенного оптимизатора ресурсов, аналогичного тому что мы делаем.
Чтобы получить такую функциональность в Openstack, вы должны будете развернуть Openstack Watcher. Мы неделю на это убили, но Watcher так и не запустили, всегда что-то, от чего он зависел, не работало или работало не так, как надо. И я пока не смог найти среди эксплуатантов Openstack кого-то, кто использует Watcher, хотя он больше всего похож на то, что мы делаем, и в части функционала ушел вперед.
В целом же то, что мы делаем, укладывается в мировой тренд cloud management automation, и не надо думать, что в этой области все задачи решены и решены идеально.
actorai Автор
Небольшое уточнение к предыдущему комментарию. У Microsoft есть продукт SCVMM, который, судя по документации, по стратегиям оптимизации размещения VM аналогичен vSphere — основываясь на краткосрочных трендах, перемещает VM с перегруженных серверов на ненагруженные. Глобальной оптимизацией кластера он тоже не занимается.
ildarz
Я приведу простой пример. Вот у вас есть куча камней, вам нужно уложить их как можно более плотно в емкость. Вы можете просчитать идеальное расположение каждого камня и сложить их (глобальная оптимизация), а можете просто высыпать кучей, а потом ее потрясти (динамическая оптимизация). И вот тут сразу возникает два вопроса:
Иными словами — нужна ли тут на самом деле глобальная оптимизация, или же достаточно локальных динамических оптимизаций, которые сойдутся к тому же (если не лучшему, с учетом динамического потребления ресурсов), результату?
Disclaimer. Это вопрос, на который я тоже не знаю ответа, а не попытка как-то умалить вашу работу. :)
actorai Автор
Есть предположение, что никто не знает ответа на этот вопрос )))
У меня есть некоторое объяснение, которое ни к коем случае не претендует на какую-либо строгость в математическом смысле или общность, скорее это наблюдение. Мы некоторое время уже занимаемся оптимизационными задачами, и для их решения используем 2 подхода — линейное программирование или эвристики на основе его и генетические алгоритмы. Производительность у них примерно равная, если запускать их с одного начального неоптимального состояния. Но если сначала применить метод, основанный на линейном программировании, а получившееся решение подать на вход генетического алгоритма, то генетический алгоритм добавит еще 10%.
Можно провести грубую аналогию между генетическим алгоритмом (потрясти камешки) и динамической оптимизацией, то вроде как получается, что имеет смысл получить глобально оптимальное состояние, и от него делать уже локальные динамические оптимизации.
Причиной того, что так можно делать, мне кажется, является тот факт, что все алгоритмы находят субоптимальные состояния, а до настоящего глобального оптимума все равно достаточно далеко, и в этом случае начальная точка имеет значение.
actorai Автор
Про камни, меняющие форму — следующая статья )
ildarz
Это уж слишком сжатое описание мануалов на сотни страниц. :) VMWare может делать в том числе ровно то же, что и вы (задать фиксированный резерв для каждой машины и раскидать по имеющимся нодам), плюс много-много чего ещё.
Ну, наверное, специально такого можно добиться (особенно на кластере с оверкоммитом), но это вопрос выстрела себе в ногу, а не возможностей системы.
Даже голый Hyper-V 2016 имеет примитивный оптимизатор, а System Сenter — уже много лет как. Не знаю, что вы понимаете под "аналогичным". Если алгоритм — наверное, не имеет. Если конечный результат — вполне себе.
Я потому и спрашиваю — область применимости вашего решения какая? :) Что вы можете делать лучше, чем другие, и как вас с этими другими сравнить? :)
actorai Автор
Мы гораздо лучше учитываем совместимость VM в рамках одной ноды в долгосрочной перспективе, и про то, как мы это делаем, будет следующая статья.
И да, это все про оверкоммит, потому что если не делать его, то задача давно решенная.
Мы решаем следующий вопрос: как делать максимально возможный при данных нагрузках оверкоммит так, чтобы он не ухудшал работу VM в кластере.