
Шучу. Главный страх админа при переводе инфраструктуры в облако — это потеря собственной важности. Почти все боятся, что перестанут быть незаменимыми. Это иллюзия. Важно не знание технологий, а знание компании и её устройства. Технологии быстро доучиваются.
Мы часто общаемся с админами наших клиентов. Вот что интересно: «сетевики» совершенно спокойно воспринимают новую инфраструктуру, а те, у кого акцент в работе был на железе, переучиваются долго. Точнее, дольше.
Потому что с момента начала виртуализации надо забыть половину того, что ты знаешь, и начать ботать сеть.
Если вы читали на ночь Олифера «Компьютерные сети» или книгу с таким же названием Таненбаума, то проблем не будет почти точно. Это когда-то было классикой админов в свитерах, а теперь стало классикой админов в галстуках.
Что случается при переезде
К админу приходит CIO или финдиректор (а иногда и учредитель) и говорит: так, дорогой друг, было приятно с тобой работать, но денег на апгрейд железа не дадим. Потому что это капитальные затраты, которые нашему бизнесу совершенно не нужны. Надо сделать так, чтобы деньги тратились по мере потребления ресурсов и в зависимости от количества этого потребления. Чтобы в высокий сезон можно было платить много, а в низкий — мало. Чтобы ничего не простаивало просто так.
Дальше в плохом случае админ прячется и дрожит, потому что масштаб изменений пугает. Во-первых, надо переехать чёрт знает куда и чёрт знает зачем со старой доброй инфраструктуры. Во-вторых, это всё — новые знания, которых часто нет. Всё вокруг непонятно, а в зоне ответственности — вообще работоспособность инфраструктуры.
Понятное дело, чаще случается чуть иначе. Опытные админы уже попробовали какую-то виртуализацию, имеют несколько развёрнутых инстансов в облаках (как правило, разных под разные задачи), но полный перенос делается медленно, поэтапно и с большим тестированием и чтением форумов. Собираются отзывы об облачном провайдере. Проходят переговоры, в ходе которых обе стороны пытаются понять, где подвох.
Потом наступает переезд. С учётом современных реалий, скорее всего, он неизбежен, хотя ряд компаний (например, оборонка) от этого застрахованы.
Что можно забыть
- Совместимость и «зоопарки». IaaS призвана облегчить жизнь админу. Ему не нужно заморачиваться по поводу выбора железа, совместимости. Как у него вот это железо от одного производителя будет работать с железом другого производителя. Не будет проблем. Все эти вопросы решает облако. Оператор облака берёт на себя все вопросы по совместимости. Работать будет оптимально.
- Апгрейд. Не нужно брать инфраструктуру с запасом, не нужно долго согласовывать счета, не надо сильно заранее (за год) думать про устаревание железа. Не нужно дружить старые куски инфраструктуры с новыми.
- Управление серверным железом. Всё это переходит на программный уровень и управляется из консоли. Не надо думать про прошивки сетевых устройств. Не нужна диагностика аппаратных сбоев: проблемы решаются оператором. Обычно админ имеет эникейщика для работы с железом на рабочих станциях, но сам занимается серверным парком. Эникея менять память в сервере пускать крайне опасно. Поддержка облачного провайдера забирает всё это на себя.
- При частичных переездах часто предоставляется услуга «сделайте мне мои сети, только в облаке». Можно сделать так, что часть серверов останется аппаратной, часть виртуальной и они будут в одной сети. Как физически, только не совсем физически.
- Ещё одна масштабная вещь — это обучение. Если у вас не ноунейм, а что-то вроде HP или Dell, то надо либо покупать поддержку, либо обучаться у вендоров. Либо искать спецов, когда приспичит.
- Можно почти забыть про резервное копирование и его особенности в организации. Все виртуальные машины в облаке могут быть скопированы по расписанию, которое задаёт админ. Главное — не забыть создать это расписание. Можно копировать ВМ целиком, можно определённые элементы типа баз данных.
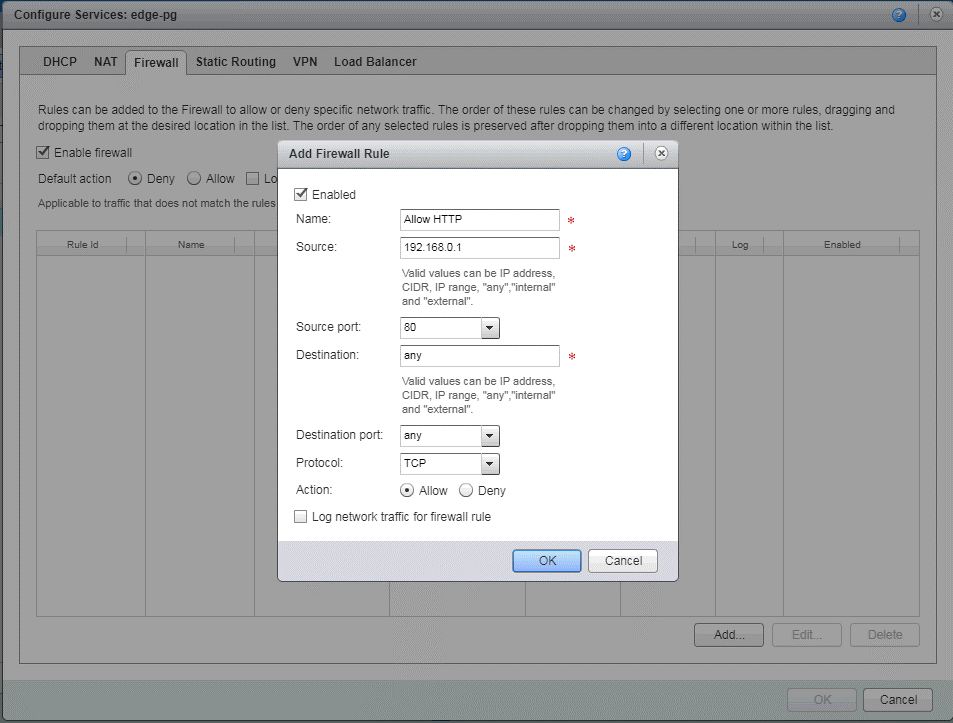
- Нет проблем с аппаратными файрволлами. Появляются программные (у нас — NSX Edge), а они по сложности настройки сравнимы с домашним роутером. При этом, несмотря на низкий порог входа, умеют они много: несколько видов VPN, NSX EDGE может через себя балансировать нагрузку внутри сети. Умеет BGP, OSPF и так далее.
- Не надо гонять в магазин за дисками. От одного из новых клиентов слышали такую историю: когда у них кончалось дисковое пространство, они бегали в магазин с наличкой покупать адаптеры и диски. А это всё делается за неделю, потому что нужно техническое окно на даунтайм в выходные. В IaaS такие задачи решаются без выключения машины за несколько секунд. «Вот этот диск на терабайт больше» — клик, и всё, раздвигаешь партицию.
- Не надо держать запчасти и расходники (для серверного парка).
- Можно забыть о проблемах с коммутацией оборудования. Переключение серверов в стойке в разные сети руками уже не надо.
- Нет проблемы с питанием в здании и его резервированием. Нет проблем с охлаждением. Контролем физического доступа. В общем, все плюшки дата-центров вы и так знаете.
Что придётся учить
- Сеть. Стандартные вещи, в целом сегодня этого достаточно. Просто кто такой IP, зачем нужна маска подсети, как работает маршрутизация в сети, как примерно работает DNS, что есть DHCP… Облако — это сетевой сервис. По опыту, примерно половине переезжающих к нам из среднего бизнеса не хватает основ. Вот книги сверху поста идеально решают задачу. Углубляться не надо: если понять хотя бы 20%, будет уже хорошо для первых шагов. DHCP ставится «одной галочкой». А ещё *nix-админы пару раз попадались на том, что наши политики не позволяют подменять MAC-адреса на виртуальных машинах.
- Безопасность. Здесь наболевшее — просто мало кто выделяет DMZ для серверов. Часто бывают косо настроены файрволлы, мы проводим регулярные ликбезы. Если админ знает стек TCP/IP, проблемы нет.
- Интерфейс облака. Придётся с ним подружиться. Проблемы реже возникают у хардкорных *nix-админов, чаще — у тех, кто живёт в стеке Windows. Нет, тот же EDGE, конечно, Linux. Но он там теперь по-настоящему user frienly.
It's just picky about who its friends are.Сегодня выглядит так: создаёшь виртуальную машину, подключаешь сети, назначаешь адреса, пишешь правила сетевого экрана для доступа виртуальной машины наружу и для доступа извне к виртуальной машине. Всё. - Очень много придётся учить СХД. И не физическое обслуживание, а именно логическое. До этого чаще всего у админа был опыт по полкам с RAID-массивами. Возможно, был какой-то SAN, но это вообще отдельный мир. Не зря стораджисты уходят в отдельную ветку прокачки: в крупных организациях почти всегда есть отдельный стораджист. Называется «администратор систем хранения данных» — он админит сеть и сами системы хранения. В среднем и малом бизнесе часто приходит человек, который настроил у себя NetApp, HP 3Par или вообще гордый бренд Noname. Что досталось, то и изучили: это вторичный рынок железок после апгрейдов из больших компаний. А каждая СХД — это свой интерфейс, свои системы управления, свой мониторинг. Админы заранее сильно думают, куда и что размещать: какие данные на SSD, какие на медленные диски. В случае, если он сразу запланировал неверно, потом будет плохо. Миграция данных с одного типа носителей на другой — это настоящая боль. В физике — это всегда остановка связи. А в облаке — перевод данных с одного типа носителя на другой в три клика. В момент копирования сервис предоставляется. Занимает процесс чуть больше, чем время на само копирование.
В целом в облачном хранении всё происходит относительно элементарно. Всё, что админ знал на уровне дисков и ОС, остаётся. Как в организации используют диски внутри ОС, так и будут. А аппаратная часть — представление дисков внутрь ВМ — задача провайдера.

С другими устройствами хранения в облаке тоже обычно нет проблем. Часто беспокоятся про подключение флешек с USB-ключами, USB-хаб обеспечивает проброс ключей до ВМ. Машина может быть на любом узле, и ключ будет направлен к ней.
- Нужно очень хорошо понимать, как работают объектные хранилища, например S3. Хорошо знать про распределённые файловые системы. Потренироваться на кошках — можем дать тест у нас, можно учиться на Амазоне, но S3 — это уже промышленный стандарт, и почти все его поддерживают.
- Надо немного разобраться с гипервизором. Глубоко лезть не надо. Современные версии накладывают оверхед около 1% на производительность: и софт виртуализации эти годы менялся, и ОС, и железо под требования облачности. Результат — прослойка гипервизора почти не чувствуется. Какой именно гипервизор используется, по большому счёту важно только провайдеру.
- Подучить лицензирование. При переезде надо учитывать особенности лицензий прикладного ПО.
- Подучить способы переезда. Чаще всего мы помогаем, но разбираться не помешает. Оптимальная ситуация — мы забираем всё через сеть, у нас каналы широкие. Реже случается — если у клиента проблемы, — что надо везти на дисках в офис или ЦОД, мы обеспечим доступность в облаке.
- Мониторинг — акцент не на инфраструктуре, а на доступности приложений. Как правило, первый достаточный уровень — это просто перезапуск ВМ при проблемах с приложением, дальше уже собственный опыт.
Ещё особенности
Нас часто спрашивают про резерв по мощностям, нужно ли это делать. В нашем видении мира это полностью задача облачного провайдера. Например, мы никогда не загружаем серверы больше определённого процента, иначе при потере серверов не сможем гарантировать перезапуск ВМ на оставшихся. Мы можем вывести из эксплуатации не меньше двух серверов в каждом кластере. И при этом сохраним полную отказоустойчивость.
Второй частый вопрос — про переезд легаси. Win95 можно запустить, даже, скорее всего, софт заработает. Хотя она не поддерживается MS. И Win98 не поддерживается MS. И WinXP не поддерживается. Но в теории запускается, правда, есть особенности со специфическим ПО — вначале надо всегда тестировать. Менее популярные ОС, такие как FreeBSD и Solaris, через гипервизор работают. У нас даже получалось запуститься, причём часто проще, чем с несвежими дистрибутивами Linux. Кстати, возможно, админу надо будет почитать и подумать про другой вопрос: операционка может вносить в среде виртуализации задержки, если она старая и не оптимизированная для виртуализации. Был проект, который с Дебиана старого переехал на Убунту новую, заработало. Физические машины на популярных ОС можно отконвертировать в виртуальные машины при помощи конвертера.
Что ещё прочитать
Моё личное мнение — стоит посмотреть:
- Эндрю Таненбаум, Дэвид Уэзеролл. Компьютерные сети.
- Виктор Олифер, Наталия Олифер. Компьютерные сети. Принципы, технологии, протоколы.
- Михаил Михеев. Администрирование VMware vSphere 5.
- vCloud Director User's Guide.
Плюс вот это: про тех, кому вообще не надо переезжать в облако, про типичные ошибки переезда, ну и про ликбезы.
Комментарии (98)

0xf0a00
12.07.2018 10:43+2Хорошо, красиво расписано, но дремать в каморке под шум собственных серверов как то по приятнее, ламповее что ли. :)
Retifff
12.07.2018 10:47Дремать в офисе в нескольких десятках километрах от собственного цода тоже ничего, в общем-то.
sevikl
12.07.2018 11:14арендовать пачку vds и не знать про беды цода, как и про драмы в облаке тоже хорошо.
Alexsandr_SE
12.07.2018 12:15+1Пока там не случилось что-то, связи нет, данных нет, на телефоны не отвечают. Даже представить время простоя не получается.
sevikl
12.07.2018 13:51админ забухал и сменил все пароли. или внезапный камаз переехал того админа. или метеорит — если уж быть фаталистом.
Alexsandr_SE
12.07.2018 14:21И позвав людей через некоторое время выбудете знать срок простоя и что можно сделать по быстрому. Все равно точек отказа меньше.
И это не фатализм. Это жизнь. Экскаваторщик вон пару лет назад оптику перерубил магистральную. И все. Сколько ждать никто не знает. Позже кто-то додумался в люк накидать листья осенью и поджечь, опять кабеля накрыло. Капитально при чем....
Buggy777
12.07.2018 11:11Объясните мне одну вещь: что будет с сетью при использовании облака? Вот есть файлопомойка со сканами. В случае сервера в офисе у меня гигабит и распечатать гигабайт сканов не проблема. А как быть с файлопомойкой в облаке? А если еще и почту и все остальное положить в облако, то даже 100 мбит инета становится очень мало.
Anastasia_K
12.07.2018 11:22Вы ещё спросите про потери бизнеса при любых проблемах с каналом.
0xf0a00
12.07.2018 11:49Тут красиво умолчали о том что в случае покупки нового железа старое находит вторую, а то и третью жизнь. А в облаке мы платим только за здесь и сейчас, и вдруг случись что то — все, приехали.
На прошлой работе была не очень хорошая линия к АТС, все грозились поменять на оптоволокно, но для организации выходило дорого. И как то после сильных дождей с ветром залило кабельную шахту, да так что связи не было больше 3 рабочих дней. Почта и бухгалтерия через 3G модем сидела.
appsforlife
12.07.2018 11:23Сейчас маркетологи Вам объяснят, что Вам это не надо. Например на базе заботы об экологии. А еще расскажут, что есть облачное решения для просмотра, редактирования и подписи документов. Кстати, недорого.
behek Автор
12.07.2018 12:01В первую очередь нужно понять, как бегает ваш трафик до файловой помойки. Если из офиса со стационарных рабочих мест, то видимо не стоит переносить. А если в офисе тонкие клиенты на рабочих местах и вы работаете через терминальный сервер, который тоже в облаке, то как раз стоит. И почту тоже. В облаке стандартный интерфейс у виртуальной машины 10Гбит/с. Плюсы, которые дает работа через терминальный сервер, я расписывать не буду.
onlinehead
12.07.2018 12:38+1В облаке стандартный интерфейс у виртуальной машины 10Гбит/с.
Это, мягко говоря, не совсем правда. Зависит от того, что за облако и что за тип инстанса. Далеко не всегда нужен m5.12xlarge (с которого начинается 10 Гбит/с) с ценой в районе $2.304 в час без прекоммита (итого ~ 1700 долларов в месяц только за вычислительную мощность).
К тому же, никто не отменял требования к обратному каналу с терминального сервера до принтера в офисе, там тоже магии не происходит и на принтер приедет вероятно больше 1 ГБ данных при респечатке 1 Гб сканов, т.к. принтер все таки другими протоколами пользуется.
В таких случая разумно оставлять файлопомойку в офисе и делать к ней синхронизацию во облачный сторадж (S3 + Glacier, допустим), чтобы обеспечить сохранность.behek Автор
12.07.2018 16:14Это, мягко говоря, не совсем правда. Зависит от того, что за облако и что за тип инстанса. Далеко не всегда нужен m5.12xlarge (с которого начинается 10 Гбит/с) с ценой в районе $2.304 в час без прекоммита (итого ~ 1700 долларов в месяц только за вычислительную мощность).
В нашем облаке это правда. Даже самый маленький инстанс может иметь интерфейс в 10Гбит/с без ограничения трафика внутри сети и дополнительных плат.
К тому же, никто не отменял требования к обратному каналу с терминального сервера до принтера в офисе, там тоже магии не происходит и на принтер приедет вероятно больше 1 ГБ данных при респечатке 1 Гб сканов, т.к. принтер все таки другими протоколами пользуется.
В таких случая разумно оставлять файлопомойку в офисе и делать к ней синхронизацию во облачный сторадж (S3 + Glacier, допустим), чтобы обеспечить сохранность.
Полностью согласен. Большой объём сканов действительно удобно хранить в S3. И с S3 приятней работать чем с кучей каталогов.onlinehead
12.07.2018 16:26В нашем облаке это правда. Даже самый маленький инстанс может иметь интерфейс в 10Гбит/с без ограничения трафика внутри сети и дополнительных плат.
А зачем это маленькому инстансу, он же умрет просто на обработке сети.
Что будет, если туда подселить 10 подобных инстансов (по остальным ресурсам они, допустим, поместятся)?
Это же явный оверкоммит, еще и в таких объемах. Попасть на соседа, который кушает почти весь канал своей небольшой машинкой — так себе удовольствие.
Да и я что-то не нашел у вас на сайте про это. Есть «частное облако», которое выглядит как блейд с райзером, но стоимость у него ухх. Да и там тоже что-то ничего про 10 Гбит наружу нет, там в целом то всего 2х10 Гбит, как я вижу в конфигурации.
Полностью согласен. Большой объём сканов действительно удобно хранить в S3. И с S3 приятней работать чем с кучей каталогов.
А с чем вы согласны то? Я же сказал ровно обратное — гигабайты сканов в S3, которые часто надо печатать на локальном принтере — не самый лучше выбор, если только S3 бэкап и не более (как и любое другое облачное хранилище).behek Автор
12.07.2018 16:43А зачем это маленькому инстансу, он же умрет просто на обработке сети.
Что будет, если туда подселить 10 подобных инстансов (по остальным ресурсам они, допустим, поместятся)?
Это же явный оверкоммит, еще и в таких объемах.
Трафик больше 1 Гбит/с уже хочет интерфейс 10Гбит/с
Попасть на соседа, который кушает почти весь канал своей небольшой машинкой — так себе удовольствие.
Это забота облачного оператора, чтоб клиенты не почувствовали.
Да и я что-то не нашел у вас на сайте про это. Есть «частное облако», которое выглядит как блейд с райзером, но стоимость у него ухх. Да и там тоже что-то ничего про 10 Гбит наружу нет, там в целом то всего 2х10 Гбит, как я вижу в конфигурации.
Мы используем порты 10 и 25 Гбит/с на наших серверах.
А с чем вы согласны то? Я же сказал ровно обратное — гигабайты сканов в S3, которые часто надо печатать на локальном принтере — не самый лучше выбор, если только S3 бэкап и не более (как и любое другое облачное хранилище).
Согласен я с вашем мнением, по поводу сетевого взаимодействия с принтером. И с тем, что предпочтительней не гонять тяжёлый трафик через внешний канал.
Tufed
13.07.2018 11:13Становится очень грустно. А если перейти еще и на виртуальные рабочие столы/приложения/RDP и тому подобное, да впихнуть это в все в VPN канал на весь офис… скорость порежется до нескольких мегабит, пинг увеличится с увеличением расстояния до ЦОДа… И тут становится не очень комфортно…
TaHKucT
13.07.2018 13:16+1Решается как обычно: «консультантов облака» нужно слушать, а решения принимать самостоятельно, а не «делать все как они рассказывают». В облако есть смысл уносить службы, к которым клиенты через интернет ходят (сайт компании, сервер видеонаблюдения, на котором хранятся видео из филиалов и т.д.). Не стоит переносить в облако ресурсы, если в данный момент основная масса клиентов этого ресурса сидит рядом с сервером, особенно если есть проблема с шириной канала.
Но при этом облако все равно можно использовать для оптимизации вышеуказанных служб.
Например в ваших примерах: основная файлопомойка в офисе, но синхронизируется с облаком в обе стороны. Пока все хорошо, офисные работники работают через быструю локалку с офиснойной копией. Удаленные сотрудники через VPN'ы работают с облачной копией (потому что в облаке интернет шире, чем в офисе). Если в офисе с сервером вдруг что-то случится, то офисные работники перенаправляются в облако, пока все не починят. Да, на время аварии деградирует производительность(из за узкого канала), но уж лучше так, чем «ничего не работает».
С почтой примерно так же поступаем: входящая почта валиться на сервер в облаке, там фильтруется спам, проверяется антивирусом, применяются нужные политики и т.п., а на офисный маилсервер синхронизируются только нужные письма.
Инфраструктура конечно получается сложнее, чем простое «один сервер выполняет одну роль и по ночам бэкапится», в зависимости от конкретного стека и требований возможно что придется пойти на некоторые компромиссы, но обычно оно того стоит если сервисы действительно критичные для компании.
ybalt
12.07.2018 11:41+1Это зависит от сферы применения. Если вам надо печатать гигабайт сканов в минуту с внутреннего хранилища для собственных нужд, то облако вам не нужно.
А вот если вам нужно обеспечить доступ к этим сканам пользователям по всему миру, да еще и отказоустойчиво, да еще и быстро, то облако поможет вам сэкономить время, нервы и деньги, которые вы непременно потратите на осуществление необходимого в собственном ДЦ.0xf0a00
12.07.2018 11:52+1Дааа, собственный VPN сервер это нынче крайне дорого и затратно. А главное специалистов по настройке днем с огнем не сыщешь. :)
ybalt
12.07.2018 11:58Прошу прощения, а причем тут VPN? Я что-то пропустил?
sevikl
12.07.2018 12:02[sarcasm] vpn это теперь про отказоустойчивость[/sarcasm]
Alexsandr_SE
12.07.2018 12:21Несколько каналов иметь не проблема по нынешним временам, остается только вопрос железа по отказоустойчивости.
0xf0a00
12.07.2018 12:06Стоит задача: организовать доступ сотруднику к удаленным документам. Как проще всего решить? Через VPN сервер. Просто, надежно, дешево, что клиентов, что серверов разве что под кофеварку нет. Зачем облако городить? Что бы дяде посреднику, между мной и моими данными, денежку отдавать?
ybalt
12.07.2018 13:19Просто-то просто, но что вы будете делать, если:
— у вашего провайдера проблемы и внешнего доступа к вашему ДЦ нет?
— в вашем ДЦ появились проблемы с электропитанием?
— у вашего ДЦ внезапно проблемы с железом, например у фаервола или центрального коммутатора?Furriest
13.07.2018 05:23Это управляемые риски. Можно посчитать их вероятность, стоимость их компенсации и решить, нужно их закрывать или нет.
А вот когда ровно те же проблемы появляются у провайдера облака — это не управляемые клиентом риски. Провайдер облака решил построить решение вот так, потому что ему кажется, что так будет правильно. Но при падении — я не знаю провайдеров облачных решений, которые готовы полностью оплачивать ущерб бизнесу из-за отсутствия сервиса. Поэтому и гарантии с облаком — в размере абонплаты.TaHKucT
13.07.2018 14:28Но при падении — я не знаю провайдеров облачных решений, которые готовы полностью оплачивать ущерб бизнесу из-за отсутствия сервиса. Поэтому и гарантии с облаком — в размере абонплаты.
Так это стандартная практика во всем мире во всех отраслях. Производители серверов сломавшийся сервер вам поменяют, но оплачивать убытки из-за его простоя не будут. Автопроизводители починят сломавшийся автомобиль, но если не будут вам оплачивать упущенную прибыль сорвавшейся сделки, даже если она сорвалась из-за поломки автомобиля и так почти везде.
Если хотите застраховаться от подобных проблем, но стоит обращаться в профильные организации, то есть в страховые компании. Причем если верить гуглу, то даже в России есть облачные провайдеры, которые сотрудничают со страховыми компаниями и вполне могут предоставить подобные услуги. Но нужно понимать что страховая сумма будет всегда ограниченна сверху и напрямую привязана к страховым взносам.kuftachev
14.07.2018 13:31+1Согласен. Я бы даже сказал по другому, что инфраструктура — это ответственность компании, а не провайдера.
Нужно самим думать, что лучше, заплатить за дублирующую функциональность (полную или неполную), или какое-то время не работать и решать по ходу возникновения проблемы.
romxx
12.07.2018 12:43+1Сидящих на Хабре сисадминов предсказуемо бомбит ;)
quwy
13.07.2018 01:55+4Я вот не сисадмин, но меня тоже бомбит. Однажды я изучил цену вопроса переноса в облако интернет-проекта на 5 серверов, и с тех пор любую статью, где говориться о выгодности облаков, воспринимаю как абсолютный, стопроцентный звиздежь.
romxx
13.07.2018 10:06-3Значит вы будущий сисадмин ;)
1. Цена — не единственный параметр при выборе перехода в облако.
2. Цена — вопрос сложный, конечно, можно считать цены по листпрайсу, и удивляться, почему дорого. Но это скорее говорит о компетентности считающего, чем о реальной цене облака.kaichou
13.07.2018 10:38+4> 1. Цена — не единственный параметр
На самом деле, облако — это дорого.
> 2. Цена — вопрос сложный
На самом деле, облако — это очень дорого.
Всё, что вам нужно знать про облака.
quwy
13.07.2018 15:38Значит вы будущий сисадмин ;)
Поздновато мне уже.
Цена — не единственный параметр при выборе перехода в облако.
Если речь про бизнес, а не хобби, то все (абсолютно все) критерии в конечном счете превращаются в стоимость. Как любая энергия в конце концов переходит в тепло, так и любая характеристика выбираемого продукта/услуги всегда упирается в деньги. Это нерушимый законтермодинамикибизнеса.
можно считать цены по листпрайсу, и удивляться, почему дорого
Простите, а как еще принято считать? Забухать с владельцем сервиса и договориться о специальной цене, что ли? Стоимость услуги публикуется как раз для того, чтобы покупатели видели, во сколько эта услуга им обойдется.
это скорее говорит о компетентности считающего, чем о реальной цене облака
Есть цена услуги, она включает в себя все то, что и так у меня уже есть, плюс навар владельца, плюс все его налоги. Это может быть дешевле только если у меня или совсем какой-то пустяк типа «хомяка», или большой резерв на случай неожиданного наплыва. Если же у меня 5 нагруженных под завязку серверов и нужно принять решение, брать шестой или переходить в облако, то тут вообще вариантов нет, облако дороже в разы.romxx
14.07.2018 00:53> Простите, а как еще принято считать?
По крайней мере владея всеми возможными средствами оптимизации цены.
Тем более, что обычно для этого достаточно хотя бы погуглить.
aws.amazon.com/ru/blogs/rus/cost-optimization-capabilities
habr.com/post/331566
habr.com/company/bitrix/blog/174181
Так называемые «спотовые» и «контрактные» цены, например, позволяют снизить стоимость владения иногда в десятки раз. И это только единственный способ. А их еще с десяток.
Разумеется, если переносить имеющуюся инфраструктуру «один-в-один» то получится как вы и считали, это как минимум глупо. Глупо натягивать сову на глобус, оставьте подход «свой датацентр, как мне привычно» в своем датацентре. На то оно и облако.
Но тем не менее сисадмины занимаются этим снова и снова. Вне зависимости от возраста.
kuftachev
14.07.2018 14:06"Простите, а как еще принято считать? Забухать с владельцем сервиса и договориться о специальной цене, что ли? "
Зачёт!!!
У меня такое впечатление, что там нужно отдельно заканчивать университет облачный факультет, и там должны быть кафедры на выбор Амазон, Гугл и МикроСофт, чтобы иметь хоть приблизительное представление о том, сколько в конечном счёте будут стоить услуги.
khanid
12.07.2018 13:05Слишком много упрощений и допущений.
Опытные админы уже попробовали какую-то виртуализацию
Ныне это уже эдакий entry-level. Если при найме на работу у будущего админа нет понимания, что есть виртуализация — ему, пожалуй, рано в админы. Напроситься помощником разве что. Опыт тут даже не при чём. Виртуализация сейчас везде и всюду. Там где её нет — это, как правило, специфика или отсутствие необходимости в какой-либо весомой инфраструктуре. И даже в таком случае плюсы виртуализации весомее минусов и оверхеда.
Потому что это капитальные затраты, которые нашему бизнесу совершенно не нужны.
Решается просто сравнением предложения IaaS вендора со строимостью оборудования + стоимостью его владения.
Простой пример из недавнего. Пришло предложение на хранение данных. Вроде дело хорошее. Запросили цены на объёмы 50-100 Тб данных. И выходит 70-120 т.р. в месяц. При таких ценах уже через полтора года затраты превысят затраты на полноценную СХД. Уже невыгодно при закладывамом минимальном сроке эксплуатации в 3 года (в реальности же — 5-6 лет со сменой дисков). Можно включить затраты на содержание СХД, но тогда надо включать и затраты на доступ к облаку. До этого, честно скажу, даже не дошло, поскольку IaaS провайдер не смотря на наличие собственной сетевой инфраструктуры как ISP, вопрос доступа обошёл стороной, но дав понять, что халявного подключения через них не будет. И при таких объёмах не 100 Мбит надо. Всё описанное — это только на хранение. На полноценную IaaS затраты выходят больше. Как на доступность, так и на оплату мощностей. Даже копеечные БД по 20-50 Гб будут загибаться по производительности на дешёвых конфигах.
Как у него вот это железо от одного производителя будет работать с железом другого производителя
Обычно это проблем не доставляет, поскольку заранее подбирается совместимое оборудование. Никто в здравом уме не берёт железо наугад в разнобой.
Не нужна диагностика аппаратных сбоев: проблемы решаются оператором
Вот только сроки решения. Конечно, есть всякие SLA, но, как показывает история последних 10 лет, IaaS уходит в отказ и сделать что либо становится затруднительным. Даже у таких гигантов как Amazon бывают факапы. Достаточно вспомнить безвозвратное удаление кучи EC2 (кажется) инстансов, когда у них возникло подозрение на возможность попадания данных не владельцу, например.
Все виртуальные машины в облаке могут быть скопированы по расписанию, которое задаёт админ. Главное — не забыть создать это расписание. Можно копировать ВМ целиком, можно определённые элементы типа баз данных.
Принципиальной разницы же просто нет в сравнении со своей инфраструктурой.
Нет проблем с аппаратными файрволлами
Здесь идёт какое-то непонятное упрощение. Принципиальной разницы же нет, кроме наличия железа в стойке.
Переключение серверов в стойке в разные сети руками уже не надо.
Это, скорее, из разряда чего-то еординарного. При той же виртуализации коммутация — эдакая software-defined составляющая, если говорить о подключении серверов к сети.
В среднем и малом бизнесе часто приходит человек, который настроил у себя NetApp, HP 3Par или вообще гордый бренд Noname. Что досталось, то и изучили: это вторичный рынок железок после апгрейдов из больших компаний. А каждая СХД — это свой интерфейс, свои системы управления, свой мониторинг. Админы заранее сильно думают, куда и что размещать: какие данные на SSD, какие на медленные диски. В случае, если он сразу запланировал неверно, потом будет плохо. Миграция данных с одного типа носителей на другой — это настоящая боль. В физике — это всегда остановка связи. А в облаке — перевод данных с одного типа носителя на другой в три клика. В момент копирования сервис предоставляется. Занимает процесс чуть больше, чем время на само копирование.
3PAR — это уже не малый бизнес. Там все плюхи кровавого энтерпрайза. И, что характерно, принципиальной разницы же нет при понимании сути. Достаточная изученность какой-нибудь MSA, вполне себе может быть нормальной платформой для безболезненного перехода на что-то иное или более серьёзное. Что же касается планирования — оно и в облаке никуда не девается. Определённый уровень IOPS никто не отменял. В части своей же инфраструктуры это тоже не вызовет проблем. На более серьёзном оборудовании data-tiering вполне себе существует. А на более простом переезд конфигурации и данных с одного хранилища в друге не представляет сколь либо большой проблемы. В том же win 2012 HA-cluster это тупо несколько кликов по контекстным меню, где просто выбирается другое хранилище/раздел под конфиг/диски ВМ. Ну и дальше идёт безостановочный (а это важно, поскольку вся аргументация на этом) процесс переезда. Побочные эффекты — ну разве что снижение производительности на время переезда. Но это и делается не в пик нагрузки обычно.
Прямая попытка противопоставления облако vs своя инфраструктура — не очень. Очень тяжело сказать, что вот это в таком решении безальтернативно лучше, а вот это — безальтернативно хуже. Оно, скорее, просто другое.
onlinehead
12.07.2018 14:15Немного ошибся веткой, отвечал khanid
Во многом вы правы, но расчеты на счет стораджа меня несколько смутили.
Запросили цены на объёмы 50-100 Тб данных. И выходит 70-120 т.р. в месяц. При таких ценах уже через полтора года затраты превысят затраты на полноценную СХД. Уже невыгодно при закладывамом минимальном сроке эксплуатации в 3 года (в реальности же — 5-6 лет со сменой дисков).
СХД в практически минимальной комплектации с 12х8000 Гб чистого объема (а мы хотим отказоустойчивость, поэтому смело делем на 2) стоит 1.5 рублей единоразово по минимуму. Теперь берем к нему еще полку на столько же — 600 т.р, чтобы добить объем. Это все в примерных ценах условного DEPO, полки какого-нибудь HP будут еще дороже.
Чтобы обеспечить сопоставимую в облаком отказоустойчивость, нам поидее надо два таких и канал между ними. Просто по железу это будет уже 4.2 миллиона + канал, который мы не знаем сколько стоит, но явно не бесплатный. Ну и конечно за железо в такой конфигурации тоже придется доплатить.
Итого, имеет 4.2 миллиона (а на самом деле больше) за железо с порога + специалисты, которым тоже надо платить, которые болеют, увольняются и обижаются + еще определенное количество расходов, которые мы тут не учли.
Вам же предложили 70-120 т.р в месяц, считаем.
4200/120 (берем максимальную стоимость) = 35 месяцев без учета накладных расходов по обоим решениям.
Но что-то мне кажется из моего опыта, что отказоустойчивый канал до провайдера будет дешевле, чем отказоустойчивая схема обеспечения сотрудниками, которые знают что делать с этой полкой. Вариант совмещения конечно хорошо (админ же не только для полки), но искать его будет уже чуточку сложнее.
В общем, стоимость получается +- такая же если брать сразу весь объем, но сторадж как сервис однозначно дешевле если брать поэтапно или надо будет расширяться больше чем на эти 100 ТБ, так как придется опять капитальные затраты будут большими, а использоваться они будут неэффективно.onlinehead
12.07.2018 14:24Добавлю еще что с RAID6 стоимость упадет, поэтому что можно обойтись без внешней полки и получить 90 Тб на одной, а значит получается 3000/120 = 25 месяцев. +- конечно, т.к. объем разный, но для оценки пойдет.
amarao
12.07.2018 14:31Нифига. Внедрение software defined networks вызывает совершенную passive-agressive реакцию сетевого отдела, даже если они сдерживаются. Если же речь идёт про SDN уровня дата-центра (bgp, dynamic egress ballancing), или про оверлейную сеть на сетевом оборудовании (не путать про оверлейные сети на хостах), то реакция становится просто сардонической. Потому что понять что происходит на сетевом оборудовании можно только через инструментарий управляющего ПО — если посмотреть на конфиги оборудования, то там тысячи vlan/vxlan, динамически появляющиеся/исчезающие vrf'ы, и даже нельзя (без заглядывания в управляющее ПО) понять с кем из свичей устанавливается BGP-сессия.
Автоматизация приходит к автоматизаторам, и не все из неё выйдут в статусе гуру.
gsl23
12.07.2018 14:41Вендоры хотят кушать и хотят кушать всегда. Вдруг компания будет сидеть n лет на 1них серверах, и не захочет i7 менять на новый i7+, старое ПО на новое ПО+, где они затратились на новые свистелки. На облаках вы то денюжки им постоянно несете.
Облака иногда полезны, но надо уметь считать, и считать хорошо, чтобы понять, где вам будет выгоднее переезд на другие железки у дяди, которые делает тоже самое что и вы, но еще свою маржу будет с вас иметь.
ruslanmatrix
12.07.2018 15:02+3Последние годы перевожу компании из облаков на свои сервера. Ибо оказывается, что аренда ЦОД, свои сервера и СХД плюс самый быстрый сервис от вендора, софт виртализауии с самой быстрой поддержкой от вендора, ОС, аутсорсинг админов поддержки стоит в 3-5 раз дешевле облаков при расчете на 3/4/5 лет.
Поймите простую истину. Облачные провайдеры типа Amazon, Azure используют кастомные (не серийные) сервера. И если бы облака реально были бы дешевле своих серверов, то производители серверов, систем хранения данных, сетевого оборудования для ЦОД стали бы банкротами. Однако крупнейшие мировые производители отчитываются о росте продаж и росте всего рынка!
Уже не раз при проведении тендера на закупку оборудования, лицензирования, поддержки продавцы меня спрашивали зачем все это, купите у нас облака. Я говорил посчитайте и получалось ещё дороже.
Облака — новый способ получить дополнительную прибыль, создав дополнительную ценность для узкого круга клиентов.
Облака выгодно использовать в определённых случаях:
стандартизированные услуги типа хостинг, почта, телефония, портальные решения и т.п.
катастрофоустойчивость — реплики серверов, баз данных, бэкапов.
не постоянные нагрузки — повышенный спрос, сезон, сдача отчётности, пилотный проект, тестирование, сборка приложений
когда скорость запуска/изменений дороже денег на разницу стоимости облаков/своего ИТ
дорогие специалисты по определенной технологии в стране/регионе
нет специалистов по новым технологиям
ваучер для стартапов
и реально большие, транснациональные даже не компании а корпорации с публичными сервисами для десятков тысяч/миллионов клиентов.
onlinehead
12.07.2018 16:07+1Последние годы перевожу компании из облаков на свои сервера.
Какого рода компании? Каковы требования по устойчивости? Можно все поставить в одну стойку и жить спокойно, или надо придумывать disaster recovery планы и есть критичные сервисы? Какой SLA вообще? Что со стоимостью лицензий, с первоначальными вложениями?
Очень много вопросов у меня вызвал это пункт, расскажите если не трудно.
И если бы облака реально были бы дешевле своих серверов, то производители серверов, систем хранения данных, сетевого оборудования для ЦОД стали бы банкротами.
Для облачных компаний сервера делают по контракту те же компании производители железа. Плюс есть другие крупные потребители, которые не могут уходить от своего железа по административным причинам.
Я говорил посчитайте и получалось ещё дороже.
А точно все считали? Какие масштабы?
Пока я могу представить только одну ситуацию, когда свое и правда будет выгоднее безальтернативно — это какая то среднемелкая компания, которой в целом все равно на простой, а надо подешевле и «ну вы сделайте сейчас, оно же точно не упадет, а там решим».
amarao
12.07.2018 16:12Подтверждаю тренд. Чем крупнее компания, тем выгоднее для неё baremetal (арендованный или свой).
Идеальный клиент для облаков, получающий от них фантастическую экономию — пользователь одинокого инстанса минимального размера, который почти ничего не делает, и вообще, появляется на свет иногда.
Вот в этом режиме никто не сможет побить клаудный рейт в 1?/час (100 часов в месяц — евро!).
А вот как только появляется постоянная нагрузка, то перенос постоянной нагрузки на свои мощности начинает давать экономию пропорционально масштабу.
Т.е. при IT-бюджете в 200 баксов в месяц — облака и только облака.
При бюджете в 200к баксов в месяц — на облака можно выносить только волатильную часть инфрастурктуры (всякие CI, ephimerial staging и т.д.).
При бюджете в 2kk баксов в месяц, можно и их in house держать — дешевле будет.onlinehead
12.07.2018 16:47Рассуждения в целом верные, но есть момент — является ли IT профильным бизнесом для компании или хотя бы частью ее профиля.
При бюджете 2кк в месяц на IT это или крупная компания, которая производит IT услугу и так или иначе имеет штат специалистов или, к примеру, крупная торговая сеть, для которой это непрофильная деятельности и вот ей дешевле будет купить все это как услугу с минимальным штатом на своей стороне.
При этом, в первом случае облака тоже могут быть дешевле, но тут важны конкретные примеры.amarao
13.07.2018 10:58+1А 200к?
Кстати, если бюджет IT 2кк, то купить услугу не будет дешевле. На таких суммах затраты на специалистов уже несущественные и они примерно o(log n), а затраты на оборудование — o(n), при этом поставщик клауда закладывает маржу как константу от цены услуги (утрируя, цены оборудования), да ещё и помноженную на время. Т.е. получаем переплату в размере o(n*t), что совсем неприлично. Для маленьких контор тут есть фактор «больше на зарплаты потратим», но для большого бюджета — это во-первых не существенно, а во-вторых волшебное поле трушной оптимизации и автоматизации.
Соответственно, чем меньше контора, тем выгоднее ей облака. Можно сказать и наоборот, по мере роста компании ей надо уходить с облаков на self-hosted. А из этого вырастает ещё интереснейшая штука: архитектуру надо с самого начала закладывать такую, которая может жить как и cloud native, так и на self-hosted. Это означает, что смысл имеет использовать только те сервисы, которые могут быть воссозданы in house (что на практике означает «имеют удобные opensource варианты»).
TaHKucT
13.07.2018 14:42+1Последние годы перевожу компании из облаков на свои сервера. Ибо оказывается, что аренда ЦОД, свои сервера и СХД плюс самый быстрый сервис от вендора, софт виртализауии с самой быстрой поддержкой от вендора, ОС, аутсорсинг админов поддержки стоит в 3-5 раз дешевле облаков при расчете на 3/4/5 лет.
Действую подобным образом вы имеете все шансы стать новым облачным провайдером для своих клиентов.
ALexhha
12.07.2018 15:40+1Ещё одна масштабная вещь — это обучение. Если у вас не ноунейм, а что-то вроде HP или Dell, то надо либо покупать поддержку, либо обучаться у вендоров. Либо искать спецов, когда приспичит.
а что в облаке этот пункт чудесным образом исчезает? Или вы хотите сказать, что с тем же aws разберется любой сисадмин?
Можно почти забыть про резервное копирование и его особенности в организации.
до первого факапа со стороны провайдера. Aws например вообще не гарантирует сохранность ec2/ebs например. И в любой момент ваша виртуалка может уйти на покой. Ну и у каждого провайдера куча тонкостей и граблей с бекапом для каждого сервиса, так что не все так радужно, как вы описываете
Можно забыть о проблемах с коммутацией оборудования.
но зато вспомнить о проблемах коммутации между зонами
Нет проблемы с питанием в здании и его резервированием.
очень сильно зависит от уровня провайдера. Даже у топовых, таких как амазон случаются форсмажоры, самый яркий — удар молнии в их дц
Очень много придётся учить СХД.
не понял, а зачем мне учить схд при использовании того же aws/gcp?onlinehead
12.07.2018 16:10+1до первого факапа со стороны провайдера. Aws например вообще не гарантирует сохранность ec2/ebs например.
Забывать конечно нельзя, но вероятность смерти данных в своем ДЦ все таки выше, чем в облаке крупного вендора. Просто по причине заложенной надежности решений и их стоимости.
но зато вспомнить о проблемах коммутации между зонами
Ровно те же проблемы (и даже больше) будет и при своем оборудовании, если начать делать подобные отказоустойчивые решения.
Даже у топовых, таких как амазон случаются форсмажоры, самый яркий — удар молнии в их дц
Конечно бывает, а ДЦ, в который стоит свое оборудование в собственности заговоренные что-ли?:)amarao
12.07.2018 16:15Факапы со своей стороны часто могут быть предсказаны, а в режиме разбора полётов — устранены в дальнейшем. Факап амазона звучит как письмо и покерфейс (у нас SLA выполняется — свободы), с нулевыми перспективами участвовать в разборе полётов.
ALexhha
12.07.2018 16:31с нулевыми перспективами участвовать в разборе полётов.
ну только если вы ОЧЕНЬ «жирный» клиент, то может вас и пригласят послушать :) Вроде помню была статья на хабре, когда человека начал аффектить баг ebs, если не ошибаюсь, в результате чего он потерял несколько виртуалок. Так вот там он вроде с личным менеджером амазон общался с ведущим разработчиком. Так что шансы есть :)amarao
12.07.2018 16:41Это не разбор полётов. Разбор полётов включает не только выяснение технической причины, но и обсуждение административных изменений. Добавление тестов, мониторинга, назначение обязанностей на персонал, пересмотр административной структуры и т.д. Провайдер может побеседовать с клиентом и дать репорт, но реальные изменения в workflow будут делаться в рамках интересов бизнеса amazon (например, если amazon устраивает текущий рейт отказов, то дальше будет sales dance, даже если он выполняется с участием ведущего разработчика).
Кто сотрудников зарплатит, тот их и строит.onlinehead
12.07.2018 16:48Провайдер может побеседовать с клиентом и дать репорт, но реальные изменения в workflow будут делаться в рамках интересов бизнеса amazon
Вот только обеспечение того же уровня у себя будет с высокой вероятностью дороже, или вы считаете что свои специалисты могут сделать лучше и одновременно дешевле, чем специалисты условного Amazon и Google?amarao
13.07.2018 10:59Конечно. Потому что специалисты хотят себе только зарплату и кофе в офис, а Amazon с Google хотят ещё и profit per share. А shares у них мнооого…
ALexhha
12.07.2018 16:38Конечно бывает, а ДЦ, в который стоит свое оборудование в собственности заговоренные что-ли?:)
об этом и речь, поэтому я и не понял, почему вы ставите это плюсом облачных провайдеров.
Последние пару лет я работаю исключительно с aws/gcp и самый большой плюс для меня — это возможность сконцентрироваться на решение конкретной задачи, а не ковыряться и выяснять причины, почему данный рейд контроллер не работает и/или глючит с данным ядром. Или почему СХД начала тормозить и т.п. Своих багов/костылей тоже хватает, но вот возможность практически полностью абстрагироваться от аппаратного уровня — это большой плюс. Ну и конечно плюсом будет приятные плюшки в виде terraform и т.п. вещей.onlinehead
12.07.2018 16:50об этом и речь, поэтому я и не понял, почему вы ставите это плюсом облачных провайдеров.
Как то внезапно я записался в адвокаты облачных решений, но ладно:)
Плюс в том, что там предусмотрены удобюные инструменты, которые позволят минимизировать риски, а во многих случаях вообще без дополнительных телодвижений пережить падение ДЦ. Если самому делать подобные штуки — будет очень дорого и на порядок менее удобно.
behek Автор
12.07.2018 16:23Коллега onlinehead меня опередил.
Добавлю про обучение.
а что в облаке этот пункт чудесным образом исчезает? Или вы хотите сказать, что с тем же aws разберется любой сисадмин?
Речь шла о железе. А с интерфейсом облака придётся дружить, я об этом писал, здесь я согласен.
playnet
12.07.2018 16:41Для РФ выпадает очень вкусный западный пункт — переход на новые процессоры и платформы раз в N лет (3-5) для экономии электроэнергии. Там на тех же вычислительных мощностях это может заметно сказываться. У нас по меркам европы электричество дешёвое.
Gwinbleidd
12.07.2018 16:50Единственное, что меня напрягает во всех этих переездах в облако в стороннем ДЦ — это безопасность. Кто сможет гарантировать, что ваши данные не утекут из самого ДЦ или где-то по дороге от вас к ним?
AlexGertsyk
12.07.2018 17:23Никто. Максимум — договор, в которой оговорены все нюансы. Но это уже к юристам.
behek Автор
12.07.2018 20:30Облака бывают разные, в том числе и закрытые, с различными уровнями защищённости и аттестованные для размещения государственных информационных систем, информационных систем обработки персональных данных и для работы с платёжными системами. У нас есть и такие. Вот тут можно детали посмотреть ts-cloud.ru/service/virtualnyi-data-centr-VDC, а еще вот пост моего коллеги про мифы при переезде habr.com/company/technoserv/blog/348982.
kt97679
12.07.2018 21:28В посте, ссылку на который вы приводите, хватает аргументированной критики, которая показывает, что не все так радужно с переездом в облако.
kt97679
12.07.2018 18:30Я недавно комментировал похожий пост: habr.com/company/activecloudru/blog/415483/#comment_18832225
Отдельно хотелось бы отметить, что с переездом в облако вы теряете контроль над сетью. В своем датацентре вы можете сделать любую конфигурацию, удовлетворяющую вашим условиям и в случае, к примеру, увеличения latency понять где узкое место и исправить ситуацию. В облаке вы можете только пожаловаться поддержке. Когда ситуация будет исправлена (и будет ли исправлена вообще) — вопрос отдельный.
Также остро встает вопрос траффика между регионами. Если у вас свой датацентр вы можете арендовать свой канал и траффик между датацентрами будет ходить по нему. При этом вы сами контролируете ширину канала, а траффик не идет через интернет. В облаке в общем случае это не так.behek Автор
12.07.2018 20:33Построить свой ЦОД очень дорого. Далеко не каждая крупная компания себе может это позволить.
kt97679
12.07.2018 21:25Построить свой цод с нуля — дорого. Арендовать место в готовом цод — гораздо дешевле.
behek Автор
12.07.2018 21:36Вы можете арендовать каналы связи между разными облаками и своими офисами, это не отличается от аренды каналов в ЦОДах. Например, некоторые клиенты объединяют свои ресурсы в нашем облаке с облаком Амазона. С российскими операторами ещё проще и дешевле. Я писал об этом в своей статье, это реально работает и не стоит космических денег.
kt97679
12.07.2018 22:43К сожалению все не так просто. Я сейчас общаюсь с сетевиками, которые участвуют в планировании нашего переезда в амазон. Возможности арендовать выделенный канал между регионами нет, надо гонять данные через интернет. Это, к слову, еще значительно увеличит стоимость траффика.
onlinehead
13.07.2018 09:14Что то у вас с архитектурой не так, раз такие проблемы возникают.
Для межрегионального трафика существует VPC Peering, который как раз объединяет разные VPC в разных регионах в единое сетевое пространство. Трафик пойдет по каналам амазона.

slavait
12.07.2018 22:05При переходе на облако можно забыть о безопасности. Вам ни один поставщик услуг не даст гарантий защиты ваших данных. Не страхуют и не возмещают потери связанные с утечкой ваших данных в руки админов или других лиц имеющим доступ к железу на котором находится облако!
onlinehead
13.07.2018 09:16А разве с крупными облаками был хоть один подобный случай?
В обычном ДЦ, если он не полностью свой, риски еще выше. Там как минимум сразу понятно из какой стойки оборудование ваше вынимать.0xf0a00
13.07.2018 09:34А разве с крупными облаками был хоть один подобный случай?
Вы гарантируете что не было? То что не было огласки не значит что все замечательно.onlinehead
13.07.2018 10:19Нет, не гарантирую конечно, но известных случаев не было.
Если и были, то все получили прекрасную компенсацию и замяли это дело, потому что потеря доверия для такого бизнеса подобна смерти.
Плюс к этому, архитектурно из облака, даже имея доступ во внутренние сети, сложно что-то воровать. Ключи шифрования и данные лежат на разных слоях и доступны разным людям, куча слоев абстракции и т.п.
Да, наверно сотрудник может при острой необходимости и с разрешения службы безопасности попасть на машину, но контролируется это хорошо и уверен что лучше, чем в обычном собственном ДЦ, в котором к слову и так правила весьма и весьма строгие.slavait
13.07.2018 15:16Вы рассматриваете в узком круге интересов. А что если бизнес целиком и полностью зависит от софта в «облаке». В России компенсации, да не шутите. Сколько крупных предприятий за прошлый год отжали? А вы о каких-то данных в облаке. Владелец/директор просто исчезает, падает с окна или убегает за границу оставив все и нет никому дела. Когда крупные куски уже разобраны, то и мелкие идут в расход, кстати пенсионная реформа, повышение налогов, тотальный контроль переписки, контроль платежей, автоматическое взимание денег с зарплат и т.д. — похоже показатель, что мелким не так долго осталось.
Вы же понимаете, что пенсионку за один день не реформируют, а тут сразу после выборов, т.е. в тайне прошли все подготовки и согласования. А люди — это расходник его ставят в известность по мере расхода материала.
Я не за и не против этой власти, я не вижу положительных сдвигов для населения этой страны. А отрицательных полно. Но ничего менять не будут.
Поэтому на облако надейся, а сам не плошай.
И по части компенсации, сколько заплатили торрент-трекеру после уничтожения?onlinehead
13.07.2018 17:23Вы зачем в политику то ударились?
Я вам все это пишу с общей точки зрения, а не с точки зрения рисков определенной страны.
Это конечно преимущественно русскоязычный ресурс, но это не значит что все тут живут и работают на ex-СССР пространстве.
slavait
13.07.2018 15:03А с чего Вы решили, что по ТВ или где либо скажут о подобном случае. Мы же говорим о бизнесе. А в России ни на кого надеяться нельзя и тем более, если это связано с денежными потоками. У всех разное понимание зачем облако, а если там все исходные тексты, а как правило скрипты и или базы данных всегда с исходниками.
Россия не правовое государство(любой юрист или адвокат понабравшись опыта сожалеют о том, что пошли работать по данной профессии). И в этом государстве никому ничего не докажете, а заносить бабло нет никакого интереса, проще строиться учитывая эту специфику. И да антисоциальное государство долго ли протянет? Где потом это облако искать.
onyxmaster
12.07.2018 23:37Главное никогда не забывать что оператор отвечает исключительно SLA. Компенсацию больше месячного платежа обычно никто не даёт. Вы отвечаете своим бизнесом, а провайдер — ежемесячным платежом.
Про «местные» облака лучше вообще даже не начинать. Складывается ощущение, что люди купили железо, поставили лицензированный софт (гипервизоры, SDN, SDS) и никаких проблем самостоятельно решать не научились. Хотя вот с Селектелом и Мэйлом мы ещё не пробовали работать, надо посмотреть.IT_pilot
13.07.2018 13:14При выборе провайдера не помешает посмотреть его вакансии. Зачем? А чтобы посмотреть кто будет обслуживать твою инфраструктуру. Вернее сколько им собираются платить. Ведь в большинстве случаев уровень оплаты прямо пропорционален уровню квалификации. Низкие з/п сразу отпугивают от провайдера. Формулировка «з/п не указана» заставляет задуматься. А высокие з/п хоть и не гарантируют, но все же повышают доверие к команде инженеров провайдера.
gecube
13.07.2018 22:42Селектел — рекомендую.
Мейл — пробуйте.
Еще яндекс скоро запустится — cloud.yandex.ru
ybonar
13.07.2018 12:18Мне интересно а те кто пишут что уходя в облако можете забить о безопасности готовы как то бизнесу/собственникам гарантировать ту самую безопасность в своем лице. Не на уровне понятий а как говорится голову на отсечение дать?
Облачный провайдер не несет никаких гарантий сохранности данных. А админ в офисе почки продаст если убьет базу или потерят данные в процессе каких-то манипуляций? Да для собственнника бизнеса наемный сотрудник несет такие же риски что и любой аутсорс.
IT_pilot
13.07.2018 12:56Да, облако это очень дорого, — утверждает кто-то.
А если ему задать вопрос: сколько стоит час простоя бизнеса, что он ответит?
«Не знаю, я не финансист!».achekalin
13.07.2018 13:13+1А сколько стоит час простоя бизнеса, который заплатил (дорого) за облако, а оно (опа!) заработало не так, как ожидали?
Причем при массовой аварии облака достучаться до живого человека с вопросом «где мои данные» невозможно, потому что пытаются сделать хорошо всем клиентам, так что копировать и восстанавливать там сильно больше, чем было у себя в офисе.
Облако хорошо, когда у тебя новый софт, написанный под него. И, да, идеально, когда потребление ресурсов меряется по фактическому значению. А варианты «сервер в облаке с 64 Гб ОЗУ и 200 Гб места диска», который обходится в приличные N денег, даже если на нем вообще никакой нагрузки нет — какой тогда смысл? Да, в таком случае можно добавлять виртуалки по ходу роста нагрузки, но это не так выгодно для клиента, а приложение должно правильно масштабироваться на много нод…
romxx
13.07.2018 13:30Да ладно «час простоя», я, обычно, даже ответа на вопрос «сколько у вас активное оборудование датацентра потребляет электричества в сутки» не могу добиться.
До следующего вопроса «А сколько днем/ночью, минимум/максимум» и «сколько электричества потребляют кондиционеры» даже не доходило ни разу, на первом срезаются :)
onyxmaster
13.07.2018 14:17Я точно знаю сколько стоит час простоя — 42 часа простоя это стоимость облачного хостинга для нас в месяц. Можно округлить до 2 суток.
IT_pilot
13.07.2018 14:35В таком случае вашей конторе облако не нужно.
Просто у некоторых час простоя может стоить как оплата за несколько лет хостинга…
Это образно, а по цифрам: В среднем каждое крупное предприятие (более 500 работников) теряет от простоя своей инфраструктуры 100 тысяч долларов в час или примерно 1666 долларов в минуту.onyxmaster
13.07.2018 14:39О да, с тем что нашей конторе облако не нужно я абсолютно согласен =) Ну может быть для офисных нужд — да, а для производственных — совершенно точно нет. На трафике разоримся =))
IT_pilot
13.07.2018 13:17+1сервер в облаке с 64 Гб ОЗУ и 200 Гб места диска», который обходится в приличные N денег, даже если на нем вообще никакой нагрузки нет. Это не облако — это колокейшн.
kt97679
14.07.2018 09:49+1Я заметил 2 интересных современных тренда.
1. Энтузиазм по поводу миграции в облако прямо пропорционален высоте положения и обратно пропорционален практическому техническому опыту. В облака толкают директора и архитекторы. Разработчики, сетевики и опсы стараются аккуратно взывать к здравому смыслу, но получается не всегда.
2. Активировались представители облачных провайдеров, которые глубоко не вдаваясь в технические подробности красочно расписывают, как миграция в облако решит кучу проблем.
Убойная смесь.
kuftachev
14.07.2018 14:37Мне кажется, что такие статьи больше портят облачным компаниям, так как появляются много грамотных людей в комментариях и говорят правду, а так, продажники смогут напарить кому-то из руководителей, а технорей заставят исполнять, сочтя их протесты за лень.
kaichou
> так, дорогой друг, было приятно с тобой работать, но денег на апгрейд железа не дадим
А потом, пару лет спустя, выясняется, что на облако в год тратится столько денег, сколько стоил весь собственный серверный парк…
И админ оказывается крайним со словами «что же ты нам не рассказал, что это НАСТОЛЬКО дорого».
merced2001
К счатью появляется другой финансовый гений, который предлагает зааутсорсить вообще всё ИТ т.к. инфраструктура уже в облаке, а кадры — это те же капексы.
После полного краха и смены руководства приходит понимание ценности старого доброго лампового инсорса, и всё начинается по-новой )
Tufed
Это при условии, что после полного краха что-то остаётся чтобы выкарабкаться. Обычно процесс деградации имеет малозаметный, но накопительный эффект. Разваливается на глазах начинает уже тогда, когда бизнес процессы уже необратимы и тянут на дно.
ky0
… но про это нам в статье не расскажут, разумется :)
ybalt
А все потому, что несмотря на переезд в облако, подход остался таким же, как и в собственном ДЦ — накупить кучу мощных серверов с «запасом», просто один-в-один с железным ДЦ и потом удивляться куда утекают деньги.
По итогу nginx крутится на t2.4xlarge просто потому, что в ДЦ так было, а оптимизация это страшно и не нужно никому.
ALexhha
Ну если делать без ума и под сайт с посещаемостью 100 уников в день выбирать какой нибудь m5.4xlarge (типа с запасом на будущее) — то да, можно влететь в копеечку. Но с таким же успехом админ может закупать ынтерпрайз железо и в офис, бить в себя в грудь, при этом доказывая, что им просто необходима вот эта вот циска за 100500$, потому что стильно/модно/молодежно. Очень многое зависит от руководства, имхо
kuftachev
Вот концептуально облака — это очень правильно!
Но за те деньги, которые нужно будет платить в месяцы без нагрузки, можно арендовать физическое железо и в случае резкого роста нагрузки… просто не заметить, что она выросла :-D
При этом, ещё всякие v-CPU и прочие радости, когда по сути, провайдеры не гарантируют никакой производительности.
Но если всё-таки говорить о концептуальной основе, то я бы аппелировал к другой книжке Таненбаума, а именно "Распределенные системы". Ведь действительно, облака (распределенные системы) позволяют виртуально получить компьютер, который физически сделать очень дорого.
Ну и кстати, отсюда, микросервисы — очень не эффективный способ построения систем, если смотреть со стороны железа, а не говнокодеров, которые все испортят, если там будет больше определенного количества строчек кода...