

Тема этой статьи давным-давно наболела, но было всё как-то лень её писать. Много текста, который я уже раз двадцать повторял разным людям. Но, прочитав очередную пачку треша всё же решил что пора. Буду давать ссылку на эту статью.
Итак. В статье я отвечу на несколько простых вопросов:
- Можно ли распознать вас на улице? И насколько автоматически/достоверно?
- Позавчера писали, что в Московском метро задерживают преступников, а вчера писали что в Лондоне не могут. А ещё в Китае распознают всех-всех на улице. А тут говорят, что 28 конгрессменов США преступники. Или вот, поймали вора.
- Кто сейчас выпускает решения распознавания по лицам в чём разница решений, особенности технологий?
Большая часть ответов будет доказательной, с сылкой на исследования где показаны ключевые параметры алгоритмов + с математикой расчёта. Малая часть будет базироваться на опыте внедрения и эксплуатации различных биометрических систем.
Я не буду вдаваться в подробности того как сейчас реализовано распознавание лиц. На Хабре есть много хороших статей на эту тему: а, б, с (их сильно больше, конечно, это всплывающие в памяти). Но всё же некоторые моменты, которые влияют на разные решения — я буду описывать. Так что прочтение хотя бы одной из статей выше — упростит понимание этой статьи. Начнём!
Введение, базис
Биометрия — точная наука. Тут нет места фразам «работает всегда», и «идеальная». Все очень хорошо считается. А чтобы подсчитать нужно знать всего две величины:
- Ошибки первого рода — ситуация когда человека нет в нашей базе, но мы опознаём его как человека присутствующего в базе (в биометрии FAR (false access rate))
- Ошибки второго рода — ситуации когда человек есть в базе, но мы его пропустили. (В биометрии FRR (false reject rate))
Эти ошибки могут иметь ряд особенностей и критериев применения. О них мы поговорим ниже. А пока я расскажу где их достать.
Характеристики
Первый вариант. Давным-давно ошибки производители сами публиковали. Но тут такое дело: доверять производителю нельзя. В каких условиях и как он измерял эти ошибки — никто не знает. И измерял ли вообще, или отдел маркетинга нарисовал.
Второй вариант. Появились открытые базы. Производители стали указывать ошибки по базам. Алгоритм можно заточить под известные базы, чтобы они показывали офигенное качество по ним. Но в реальности такой алгоритм может и не работать.
Третий вариант — открытые конкурсы с закрытым решением. Организатор проверяет решение. По сути kaggle. Самый известный такой конкурс — MegaFace. Первые места в этом конкурсе когда-то давали большую популярность и известность. Например компании N-Tech и Vocord во многом сделали себе имя именно на MegaFace.
Всё бы хорошо, но скажу честно. Подгонять решение можно и тут. Это куда сложнее, дольше. Но можно вычислять людей, можно вручную размечать базу, и.т.д. И главное — это не будет иметь никакого отношения к тому как система будет работать на реальных данных. Можете посмотреть кто сейчас лидер на MegaFace, а потом поискать решения этих ребят в следующем пункте.
Четвёртый вариант. На сегодняшний день самый честный. Мне не известны способы там жульничать. Хотя я их не исключаю.
Крупный и всемирно известный институт соглашается развернуть у себя независимую систему тестирования решений. От производителей поступает SDK которое подвергается закрытому тестированию, в котором производитель не принимает участия. Тестирование имеет множество параметров, которые потом официально публикуются.
Сейчас такое тестирование производит NIST — американский национальный институт стандартов и технологий. Такое тестирование самое честное и интересное.
Нужно сказать, что NIST производит огромную работу. Они выработали пяток кейсов, выпускают новые апдейты раз в пару месяцев, постоянно совершенствуются и включают новых производителей. Вот тут можно ознакомиться с последним выпуском исследования.
Казалось бы, этот вариант идеален для анализа. Но нет! Основной минус такого подхода — мы не знаем, что в базе. Посмотрите вот на этот график:

Это данные двух компаний по которым проводилось тестирование. По оси x — месяца, y — процент ошибок. Тест я взял «Wild faces» (чуть ниже описание).
Внезапное повышение точности в 10 раз у двух независимых компаний (вообще там у всех взлетело). Откуда?
В логе NIST стоит пометка «база была слишком сложной, мы её упростили». И нет примеров ни старой базы, ни новой. На мой взгляд это серьёзная ошибка. Именно на старой базу была видна разница алгоритмов вендоров. На новой у всех 4-8% пропусков. А на старой было 29-90%. Моё общение с распознаванием лиц на системах видеонаблюдения говорит, что 30% раньше — это и был реальный результат у гроссмейстерских алгоритмов. Сложно распознать по таким фото:

И конечно, по ним не светит точность 4%. Но не видя базу NIST делать таких утверждений на 100% нельзя. Но именно NIST — это главный независимый источник данных.
В статье я описываю ситуацию актуальную на июль 2018 года. При этом опираюсь на точности, по старой базе лиц для тестов связанных с задачей «Faces in the wild».
Вполне возможно что через пол года всё измениться полностью. А может будет стабильным следующие десять лет.
Итак, нам нужна вот эта таблица:
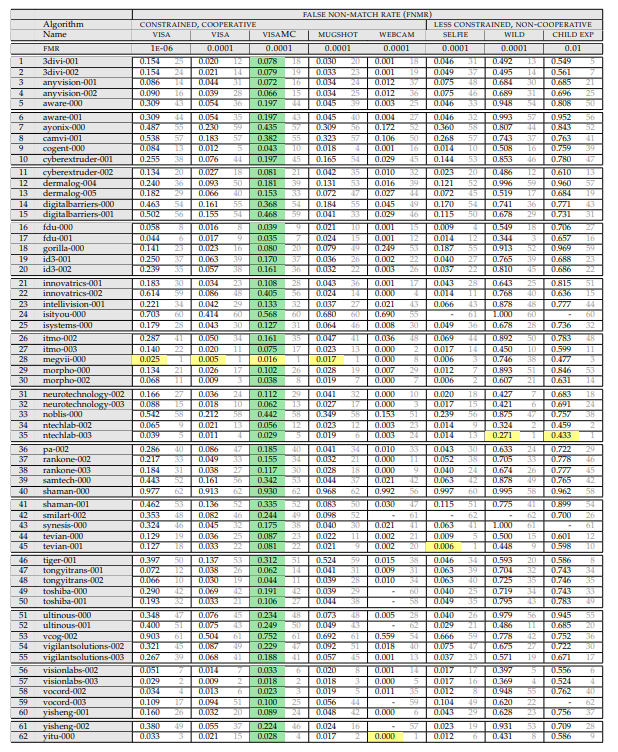
(апрель 2018, т.к. wild тут более адекватный)
Давайте разберём что в ней написано, и как оно измеряется.
Сверху идёт перечисление экспериментов. Эксперимент состоит из:
Того, на каком сете идёт замер. Сеты есть:
- Фотография на паспорт (идеальная, фронтальная). Задний фон белый, идеальные системы съёмки. Такое иногда можно встретить на проходной, но очень редко. Обычно такие задачи — это сравнение человека в аэропорту с базой.

- Фотография хорошей системой, но без топового качества. Есть задние фоны, человек может немного не ровно стоять/смотреть мимо камеры, и.т.д.

- Сэлфи с камеры смартфона/компьютера. Когда пользователь оказывает кооперацию, но плохие условия съёмки. Есть два подмножества, но много фото у них только в «сэлфи»

- «Faces in the wild» — съёмка практически с любой стороны/скрытая съёмка.Максимальные углы поворота лица к камере — 90 градусов. Именно тут NIST ооочень сильно упростил базу.

- Дети. Все алгоритмы работают плохо по детям.
Того при каком уровне ошибок первого рода идёт замер (этот параметр рассматривается только для фотогафий на паспорт):
- 10^-4 — FAR (одно ложное срабатывание первого рода) на 10 тысяч сравнений с базой
- 10^-6 — FAR (одно ложное срабатывание первого рода) на миллион сравнений с базой
Результат эксперимента — величина FRR. Вероятность того что мы пропустили человека который есть в базе.
И уже тут внимательный читатель мог заметить первый интересный момент. «Что значит FAR 10^-4?». И это самый интересный момент!
Главная подстава
Что вообще такая ошибка значит на практике? Это значит, что на базу в 10 000 человек будет одно ошибочное совпадение при проверке по ней любого среднестатистического человека. То есть, если у нас есть база из 1000 преступников, а мы сравниваем с ней 10000 человек в день, то у нас будет в среднем 1000 ложных срабатываний. Разве это кому то нужно?
В реальности всё не так плохо.
Если посмотреть построить график зависимости ошибки первого рода от ошибки второго рода, то получится такая классная картинка (тут сразу для десятка разных фирм, для варианта Wild, это то что будет на станции метро, если камеру поставить где-то чтобы её не видели люди):
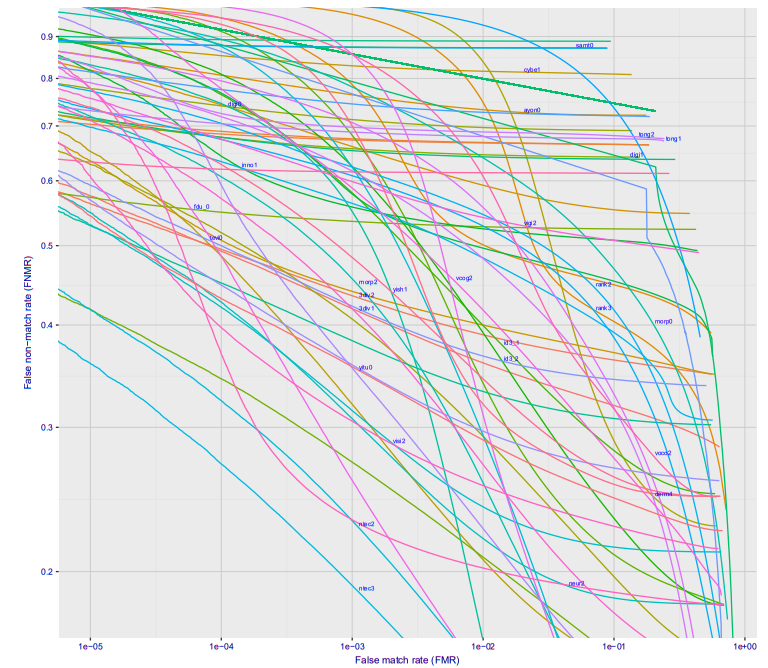
При ошибке 10^-4 27% процентов не распознанных людей. На 10^-5 примерно 40%. Скорее всего на 10^-6 потери составят примерно 50%
Итак, что это значит в реальных цифрах?
Лучше всего идти от парадигмы «сколько ошибок в день можно допустить». У нас на станции идёт поток людей, если каждые 20-30 минут система будет давать ложное срабатывание, то никто не будет её воспринимать всерьёз. Зафиксируем допустимое число ложных срабатываний на станции метро 10 человек в день (по хорошему, чтобы система не была выключена как надоедливая — нужно ещё меньше). Поток одной станции Московского метрополитена 20-120 тысяч пассажиров в сутки. Среднее — 60 тысяч.
Пусть зафиксированное значение FAR — 10^-6 (ниже ставить нельзя, мы и так при оптимистической оценке потеряем 50% преступников). Это значит что допустить 10 ложных тревог мы можем при размере базы в 160 человек.
Много это или мало? Размер базы в федеральном розыске ~ 300 000 человек. Интерпола 35 тысяч. Логично предположить, что где-то 30 тысяч москвичей находятся в розыске.
Это даст уже нереальное число ложных тревог.
Тут стоит отметить, что 160 человек может быть и достаточной базой, если система работает on-line. Если искать тех кто совершил преступление в последние сутки — это уже вполне рабочий объём. При этом, нося чёрные очки/кепки, и.т.д., замаскироваться можно. Но много ли их носит в метро?
Второй важный момент. Несложно сделать в метро систему дающее фото более высокого качества. Например поставить на рамки турникетов камеры. Тут уже будет не 50% потерь на 10^-6, а всего 2-3%. А на 10^-7 5-10%. Тут точности из графика на Visa, всё будет конечно сильно хуже на реальных камерах, но думаю на 10^-6 можно оставить сего 10% потерь:

Опять же, базу в 30 тысяч система не потянет, но всё что происходит в реальном времени детектировать позволит.
Первые вопросы
Похоже время ответить на первую часть вопросов:
Ликсутов заявил что выявили 22 находящихся в розыске человека. Правда ли это?
Тут основной вопрос — что эти люди совершили, сколько было проверено не находящихся в розыске, насколько в задержании этих 22 людей помогло распознавание лиц.
Скорее всего, если это люди которых искали планом «перехват» — это действительно задержанные. И это неплохой результат. Но мои скромные предположения позволяют сказать, что для достижения этого результата было проверено минимум 2-3 тысячи людей, а скорее около десятка тысяч.
Это очень хорошо бьётся с цифрами которые называли в Лондоне. Только там эти числа честно публикуют, так как люди протестуют. А у нас замалчивают…
Вчера на Хабре была статья на счёт ложняков по распознаванию лиц. Но это пример манипуляций в обратную сторону. У Амазона никогда не было хорошей системы распознавания лиц. Плюс вопрос того как настроить пороги. Я могу хоть 100% ложняков сделать, подкрутив настройки;)
Про Китайцев, которые распознают всех на улице — очевидный фэйк. Хотя, если они сделали грамотный трекинг, то там можно сделать какой-то более адекватный анализ. Но, если честно, я не верю что пока это достижимо. Скорее набор затычек.
А что с моей безопасностью? На улице, на митинге?
Поехали дальше. Давайте оценим другой момент. Поиск человека с хорошо известной биографией и хорошим профилем в соцсетях.
NIST проверяет распознавание лица к лицу. Берётся два лица одного/разных людей и сравнивается насколько они близки друг к другу. Если близость больше порога, тогда это один человек. Если дальше — разные. Но есть другой подход.
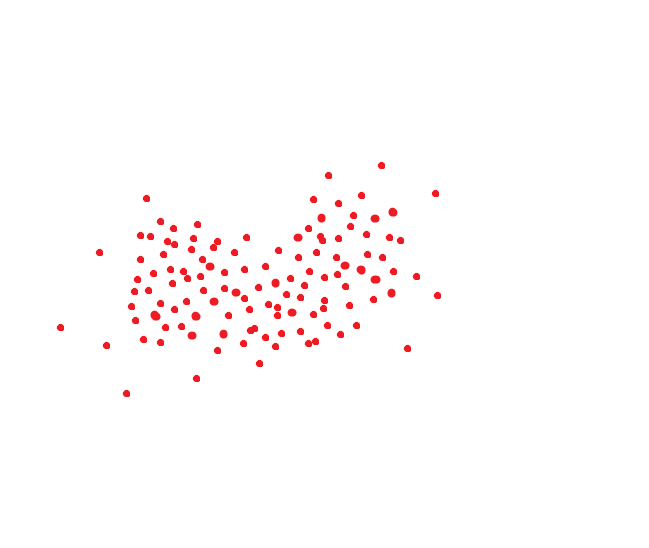
Если вы почитали статьи, которые я советовал в начале — то знаете, что при распознавании лица формируется хэш-код лица, отображающий его положение в N-мерном пространстве. Обычно это 256/512 мерное пространство, хотя у всех систем по разному.
Идеальная система распознавания лиц переводит одно и то же лицо в один и тот же код. Но идеальных систем нет. Одно и то же лицо обычно занимает какую-то область пространства. Ну, например, если бы код был двумерным, то это могло бы быть как-то так:
Если мы руководствуемся методом который принимается в NIST, то вот это расстояние было бы целевым порогом, чтобы мы могли распознать человека как одного и того же индивида с вероятностью под 95%:
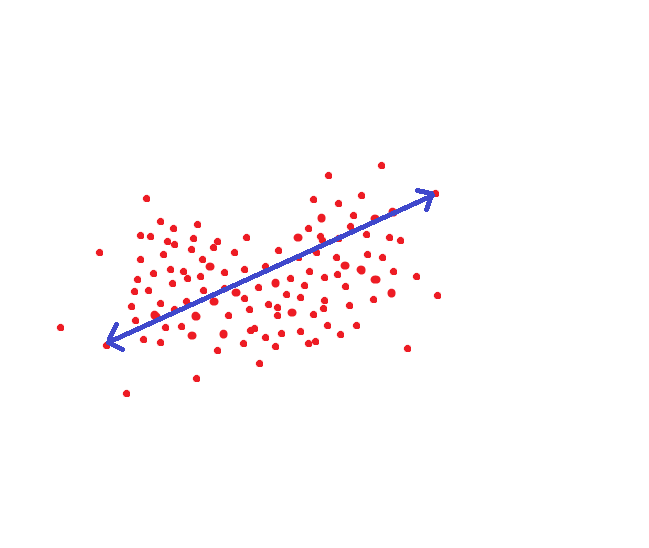
Но ведь можно поступить по другому. Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины:

Тогда пороговое расстояние при сохранении точности уменьшится в несколько раз.
Только нам нужно очень много фотографий на каждого человека.
Если у человека есть профиль в социальных сетях / база его снимков разного возраста, то точность распознавания можно повысить очень сильно. Точной оценки того как вырастает FAR|FRR я не знаю. Да и оценивать уже некорректно такие величины. У кого-то в такой базе 2 фото, у кого-то 100. Очень много обёрточной логики. Мне кажется, что максимальная оценка — один/полтора порядка. Что позволяет дострелить до ошибок 10^-7 при вероятности не распознавания 20-30%. Но это умозрительно и оптимистично.
Вообще, конечно, с менеджментом данного пространства проблем не мало (возрастные фишки, фишки редакторов изображений, фишки шумов, фишки резкости), но как я понимаю большая часть уже успешно решена у крупных фирм кому было нужно решение.
К чему это я. К тому, что использование профилей позволяет в несколько раз поднять точность алгоритмов распознавания. Но она далека от абсолютной. С профилями требуется много ручной работы. Похожих людей много. Но если начинать задавать ограничения по возрасту, местонахождению, и.т.д., то этот метод позволяет получить хорошее решение. На пример того как нашли человека по принципу «найти профиль по фото»->«использовать профиль для поиска человека» я давал ссылку в начале.
Но, на мой взгляд, это сложно масштабируемый процесс. И, опять же, людей с большим числом фоток в профиле дай бог 40-50% в нашей стране. Да и многие из них дети, по которым всё плохо работает.
Но, опять же — это оценка.
Так вот. Про вашу безопасность. Чем меньше у вас фото в профиле — тем лучше. Чем более многочисленный митинг куда вы идёте — тем лучше. Никто не будет разбирать 20 тысяч фотографий в ручную. Тем кто заботиться о своей безопасности и приватности — я бы советовал не делать профилей со своими картинками.
На митинге в городе с 100 тысячным населением вас легко найдут, просмотря 1-2 совпадения. В Москве — задолбаются. Где-то пол года назад Vasyutka, с которым мы работаем вместе, давал рассказывал на эту тему:
Кстати, про соцсети
Тут я позволю себе сделать небольшой экскурс в сторону. Качество обучения алгоритма распознавания лиц зависит от трёх факторов:
- Качество выделения лица.
- Используемая метрика близости лиц при обучения Triplet Loss, Center Loss, spherical loss, и.т.д.
- Размер базы
По п.2 вроде как сейчас достигнут предел. В принципе, математика развивается по таким вещам очень быстро. Да и после triplet loss остальные функции потерь не давали драматического прироста, лишь плавное улучшение и понижение размера базы.
Выделение лица — это сложно, если надо найти лица под всеми углами, потеряв доли процента. Но создание такого алгоритма — это достаточно предсказуемый и хорошо управляемый процесс. Чем более всё синее, тем лучше, большие углы корректно обрабатываются:

А полгода назад было так:

Видно, что потихоньку всё больше и больше компаний проходят этот путь, алгоритмы начинают распознавать всё более и более повёрнутые лица.
А вот с размером базы — всё интереснее. Открытые базы — маленькие. Хорошие базы максимум на пару десятков тысяч человек. Те что большие — странно структурированы / плохие (megaface, MS-Celeb-1M).
Как вы думаете, откуда создатели алгоритмов взяли эти базы?
Маленькая подсказка. Первый продукт NTech, который они сейчас сворачивают — Find Face, поиск людей по вконтакту. Думаю пояснения не нужны. Конечно, вконтакт борется с ботами, которые выкачивают все открытые профили. Но, насколько я слышал, народ до сих пор качает. И одноклассников. И инстаграмм.
Вроде как с Facebook — там всё сложнее. Но почти уверен, что что-то тоже придумали.
Так что да, если ваш профиль открыт — то можете гордиться, он использовался для обучения алгоритмов;)
Про решения и про компании
Тут можно гордиться. Из 5 компаний-лидеров в мире сейчас два — Российские. Это N-Tech и VisionLabs. Пол года назад лидерами был NTech и Vocord, первые сильно лучше работали по повёрнутым лицам, вторые по фронтальным.
Сейчас остальные лидеры — 1-2 китайских компании и 1 американская, Vocord что-то сдал в рейтингах.
Еще российские в рейтинге itmo, 3divi, intellivision. Synesis — белорусская компания, хотя часть когда-то была в Москве, года 3 назад у них был блог на Хабре. Ещё про несколько решений знаю, что они принадлежат зарубежным компаниям, но офисы разработки тоже в России. Ещё есть несколько российских компаний которых нет в конкурсе, но у которых вроде неплохие решения. Например есть у ЦРТ. Очевидно, что у Одноклассников и Вконтакте тоже есть свои хорошие, но они для внутреннего пользования.
Короче да, на лицах сдвинуты в основном мы и китайцы.
NTech вообще первым в миру показал хорошие параметры нового уровня. Где-то в конце 2015 года. VisionLabs догнал NTech только только. В 2015 году они были лидерами рынка. Но их решение было прошлого поколения, а пробовать догнать NTech они стали лишь в конце 2016 года.
Если честно, то мне не нравятся обе этих компании. Очень агрессивный маркетинг. Я видел людей которым было впарено явно неподходящее решение, которое не решало их проблем.
С этой стороны Vocord мне нравился сильно больше. Консультировал как-то ребят кому Вокорд очень честно сказал «у вас проект не получится с такими камерами и точками установки». NTech и VisionLabs радостно попробовали продать. Но что-то Вокорд в последнее время пропал.
Выводы
В выводах хочется сказать следующее. Распознавание лиц это очень хороший и сильный инструмент. Он реально позволяет находить преступников сегодня. Но его внедрение требует очень точного анализа всех параметров. Есть применения где достаточно OpenSource решения. Есть применения (распознавание на стадионах в толпе), где надо ставить только VisionLabs|Ntech, а ещё держать команду обслуживания, анализа и принятия решения. И OpenSource вам тут не поможет.
На сегодняшний день нельзя верить всем сказкам о том, что можно ловить всех преступников, или наблюдать всех в городе. Но важно помнить, что такие вещи могут помогать ловить преступников. Например чтобы в метро останавливать не всех подряд, а только тех кого система считает похожими. Ставить камеры так, чтобы лица лучше распознавались и создавать под это соответствующую инфраструктуру. Хотя, например я — против такого. Ибо цена ошибки если вас распознает как кого-то другого может быть слишком велика.
Комментарии (54)

denis-19
30.07.2018 05:21Распознать это еще полбеды, а аналитику снять с мимики и прочих радостей и эмоций на лице — вроде VisionLabs и этим тоже занимается еще, например.

mephistopheies
30.07.2018 09:07пост годный, афтор пеши исчо, но есть но: можно плес вставлять пустую строку между всеми абзацами, реально глаза болят читать при таком форматировании
пс: ссылаться на ализара это конечно тоже зашквар :trollface:ZlodeiBaal Автор
30.07.2018 12:05+1Спасибо!
Вроде на Ализара я ссылался только в местах где контекст «журналисты говорят». Там как-бы подразумевается, что всё написанное несусветная противоречивая чушь:)
Но, возможно, я сделал это чересчур серьёзно…
ValdikSS
31.07.2018 15:11можно плес вставлять пустую строку между всеми абзацами, реально глаза болят читать при таком форматировании
Автор, не делайте так, пожалуйста, а то глаза начинают болеть у меня.ZlodeiBaal Автор
31.07.2018 15:14Прилетело НЛО и навставляло… Я обычно стараюсь чтобы пустой строкой были разделены какие то глобальные темы, а абзацы шли энтерами. Но знаю что многим это не нравиться.
ValdikSS
31.07.2018 15:17+1Аналогично, и модераторам это очень не нравится. Я в свои статьи вставляю следующий скрытый текст:
Но они все равно часто правят, приходится сохранять исходник в виде файла и периодически возвращать обратно, но когда они это замечают, они блокируют мои статьи на редактирование. Как можно читать текст с отступами на каждое предложение — не знаю, у меня не получается, приходится использовать юзерскрипты, вырезающие переносы.<!-- Пожалуйста, не правьте форматирование. Я не могу читать статьи с пустой строкой на каждое предложение, у меня просто от такого форматирования разбегаются глаза. Если вы внесете правки, я верну все назад. -->ElegantBoomerang
01.08.2018 02:00А как вы форматируете обычно? Новый абзац без пустой строки начинаете с отступа?
ValdikSS
01.08.2018 02:06Я вставляю пустую строку только для логически нового абзаца, чтобы отделить не связанный между собой текст. Не вставляю дополнительный перенос после заголовка (там и так есть отступ), не вставляю перенос перед блоком кода или цитаты.
Посмотрите пример: habr.com/post/335436
Bel_Riose
30.07.2018 11:59«Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины» — о, любопытное приложение математики. Простите, можно вопрос: область считается выпуклой?(выпуклой комбинацией доступных точек?) Если не выпуклой, как на картинке, то каким методом считают расстояние до множества?
ZlodeiBaal Автор
30.07.2018 12:01Обычно используют алгоритмы кластеризации достаточно простые DBSCAN там, k-mean. В статье на которую я давал ссылку в начале это немного освещается.
odin_v_pole
30.07.2018 12:21FAR, FRR… А как же ситуация когда человек есть в базе, но мы его опознаем как другого человека из базы?
ZlodeiBaal Автор
30.07.2018 12:23Это считается событием FAR обычно, исходя из наиболее распространённой методологии вычисления ошибок.
babylon
30.07.2018 14:47На Хабре есть много хороших статей на эту тему: а, б, с
На Хабре не было ни одной хорошей статьи на эту тему. Продолжайте я внимательно слушаю вас и… читаю.
ASTAPP
30.07.2018 15:08Но ведь можно поступить по другому. Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины
В NIST FRVT сравниваются между собой не «лица», а «персоны». т.е. дескриптор строится именно на наборе фотографий одного человека и вендор имеет возможность параметризовать в дескрипторе область распределения данного лица.ZlodeiBaal Автор
30.07.2018 15:36Вроде как тут вот «5.2 Test design» написано всё же, что «The number of images used to make 1 template is 1». Поправьте если не прав.
С дескриптором персоны методология должна усложниться ощутимо.
ta6aku
30.07.2018 15:24Статья очень интересная, весьма содержательная.
Единственная странность — нет ни единого упоминания известной фруктовой компании.ZlodeiBaal Автор
30.07.2018 15:32А зачем? Они решают другую задачу.
ta6aku
30.07.2018 16:11задача вроде та же — сравнение с образцом, только по железной части возможностей побольше
и интерес китайцев к распознаванию лиц, я уверен, во многом связан с появлением «разблокировки по лицу» в большинстве последних китайских смартфоновZlodeiBaal Автор
30.07.2018 16:19Есть задача идентификации, есть задачи верификации. Это две разных задачи. Для них по разному выбираются пороги, по разному происходить оптимизация. Apple не надо иметь хороших алгоритмов, в том числе из-за их железа. Там и детектор лица на порядок проще, и поиск ключевых точек.
По сравнению с тем, что у Ntech и VisonLabs — у них детский сад.
У них есть своё решение по 2д + используется 3Д. Но оно очень нишевое под их задачу. По сравнению с конкурентами именно по 3д лицу — там всё слабо. Единственный их плюс, но плюс существенный — это то что их математика оптимизирована для распознавания пользователя смартфона. Её достаточно сложно обмануть. Гопники из из соседнего подъезда не откроют(хотя для любого профессионала сложности нет). При этом оно куда удобнее в эксплуатации того же Самсунга с радужкой. И всё. Всё остальное — весьма слабо и не имеет отношения к тему статьи.
Sahai
31.07.2018 00:42Может, не совсем в тему, но мне кажется, что преступников ловят не по фото.Система для распознавания лиц- это часть большой системы по сбору аналитической информации, с целью сделать управление этими людьми более удобным.Если раньше были бесполезные люди, то сейчас любой приносит пользу системе, своими реакциями и мнениями.
kbaa
31.07.2018 05:07Общался с ребятами из Vocord несколько лет назад на одной из выставок MIPS, насколько я помню, у них система была ориентирована на всякие мероприятия, и состояла из 2 стоек с камерами, которые располагаются по краям прохода (вход на стадион, в зал и т.п.), в таких условиях и само лицо все время будет где то в заданной области, и ракурс хороший, обещали высокую вероятность правильного срабатывания. Ценник только кусачий был все равно, потенциальных заказчиков в нашем регионе вряд ли было бы больше десятка, поэтому сильно вопрос не изучал
ZlodeiBaal Автор
31.07.2018 10:47Это старое 3д распознавание. Тут я писал про 2д. 3д — совсем про другое. Оно достаточно дорого и очень мало применений. Плюс оно работает только на проходных.
AlexShvili
31.07.2018 11:12Это вы говорите про систему 3D распознавания лиц. Мы ее делали в еще до дипленинговую эпоху, когда использовались старые алгоритмы очень нестабильные при изменении ракурса лица. Там для распознавания можно использовать и форму поверхности лица и фронтализированную текстуру. Сейчас с точки зрения точности эта система не дает практически ни какого выигрыша в сравнении с нашей 2D системой, она имеет смысл если вам нужно детектировать liveness на лету.
AlexShvili
31.07.2018 10:46+1Статья качественная. Спасибо за добрые слова о Vocord :).
Очень близко к тому, что мы пытаемся донести нашим заказчикам, но как только они узнают что ошибок оказывается две, да они еще и лежат на какой то кривой, то глаза их становятся печальны они начинают искать кого то кто им просто скажет что у них распознается 99% :) Касательно практического применения есть 2 замечания:
1. Если говорить про задачу типа «распознавания в метро» то «старый» wild не очень адекватен. В реальности при правильном подборе камер и правильной их установке снимки получаются лучше и соответственно результаты лучше.
2. Если говорить про задачу распознавания лиц в целом, то это не только алгоритм распознавания, но и способ получения изображения для распознавания. Если ориентироваться на результаты того же NIST FRVT, то там видно что прирост точности который получается за счет улучшения качества изображения намного выше чем разница в точности алгоритмов входящих в топ10. Говоря по простому камеры решают все :). Именно поэтому мы делаем не только свой алгоритм, но и свои камеры. Но их протестировать можно только в полевых испытаниях, а это намного сложней и затратней чем тестировать алгоритмы :(
Ну и ради высшей справедливости замечу, что если взять последние отчет NIST за 21.06.2018, то там видно что Vocord вернулся в топ4 :). В предыдущем алгоритме была ошибка поэтому результаты были такими грустными. Так что жив еще курилка!KuzMax
31.07.2018 16:44Скажите, а видимый спектр остаётся и для машинного распознавания самым интересным? Расширение диапазона не добавляет ли к результату?
Alexeyslav
31.07.2018 17:03ИК и УФ камеры пока диковинка, очень дорогая диковинка. А системам распознавания и без этого есть куда стремиться — достичь хотябы способностей обычного человека.
AlexShvili
31.07.2018 17:08Камеры чувствительные в ближнем ИК это совсем не диковинка. Практически все сенсоры используемые в камерах и мобильных телефонах чувствительны в ближнем ИК, причем для цветных сенсоров это отдельная проблема т.к. чувствительность в ближнем ИК приводит к искажениям цветного изображения и приходится ставить дополнительные фильтры которые отрезают ближний ИК
AlexShvili
31.07.2018 17:04Расширение диапазона в сторону ближнего ИК в принципе интересно т.к. в этом случае можно использовать невидимую глазу ИК подсветку и таким образом решать проблему низкой освещенности при получении изображения. Во всех системах распознавания автомобильных номеров (в том числе и в нашей :)) это прекрасно работает, а вот с лицам все хуже.
В лицах расширение спектра добавит к результату в двух случаях: либо будет достаточна богатая обучающая выборка в расширенном спектральном диапазоне, либо научиться интерполировать картинки из видимого диапазона в «расширенный». Мы этим начинали заниматься, но ничего прорывного сходу не получилось поэтому отложили до лучших времен.
sarbash
01.08.2018 09:18Американцы после 11 сентября в это направление инвестировали огромные деньги и через пару лет поняли что задача не решается в принципе, только некоторая вероятность. Китай с Россией еще не поняли наверно… хотя они запросто могут запретить бороды, бейсболки, пользоваться смартфонами в общественных местах и т.п. чтобы поднять немного вероятность.
Хотя процент можно поднять достаточно высоко, если правильно все сделать, т.е. должен быть предварительный отбор с низким FAR и высоким FRR, после этого сразу трекинг роботизированными камерами с оптикой хорошей чтобы получить качественные кадры с разных углов, и затем уже с высоким FAR прогон по нескольким алгоритмам.
tersuren
Я дико извиняюсь, но мне кажется что в статье упущен очень важный фрагмент работы реальных систем: возможность массового сравнения многих фотографий. Статистика приведена по одиночному упражнению сравнения. Но в метро телепортации нет и одна и также фигура проходит много контрольных точек и попадает на много камер. Я сам не знаком с конкретным применением всего этого, но чисто интуитивно мне кажется, что во-первых отслеживание движения очень хорошо дополняет распознавание лиц тут, а во-вторых элементарная арифметика. Если человек заходит в вестибюль метро (два кадра к примеру), потом спускается по эскалатору (ещё три кадра) и проходит к платформе (пусть ещё кадр), то мы вполне можем «ловить» его на совпадение с, к примеру, паспортной фотографией разыскиваемого статистически. Не? То есть я понимаю что близнецы вызовут именно таки 6 ложно-положительных срабатываний — ибо с ними проблема не в несовершенстве алгоритма распознавания, а в реальной похожести. Но неужели с ложноположительными срабатываниями вызванными несовершенством алгоритма нельзя бороться простой мыслью: «если на станции есть Джон До, то он не может быть опознан только одной камерой»?
И насчёт отслеживания движения: ну возьмём тот же эскалатор как самый яркий пример. Последовательность появления на нем довольно легко предсказывается, отслеживать можно просто по комбинации цветов одежды как-то. Скорость потока пешеходов в переходе отслеживать по характерным лицам — сто пудово там будет пик средних значений показывающий скорость потока.
Неужели это все прямо совсем не применяется?
ZlodeiBaal Автор
В идеале, на полупустой улице это теоретически возможно. Но в метро/любом прочем транспорте где толпа и всё загружено — это нереально. Алгоритмы сильно не идеальные. Тут сразу две задачи, одна это «Tracking», вторая — «Reindentification». Можете погуглить. Первая решается хоть как-то, но при толпе всё плохо. Вторая решается откровенно плохо. Либо надо просто сплошное поле камер, вертикально ориентированных, перекрывающееся на потолке вешать, где трекать по головам. Но это нереально по стоимости. Да и не понятны цели. Плюс такую систему никто не будет давать гарантий что она работает.
Сильно проще поставить шлюзы с хорошим освещением и хорошими камерами на вход в метро. Точность значительно выше будет, чем от всяких таких ухищрений. Но даже так — не достаточно, я это тоже писал. Ложняков будет много, даже если и пропуски сильно упадут.
А по головам считать… Мосгостранс вроде уже 3-4 год ищет хоть у кого-то решение, чтобы поставить в автобусы и считать людей по головам с достаточной точностью. Так никто же не предлагает...;)
tersuren
Видимо я плохо выразился. Необязательно именно тракать людей идеально то. Смотрите, цифры такие: у нас на станции одновременно находится не более 3000 человек. Больше не влезет физически. В среднем человек проводит на станции скажем 5 минут. Нам не надо точно тракать положение человека в толпе то и его траекторию. Нам достаточно знать что с момента обнаружения подозреваемого в вестибюле входа у нас есть окно в скажем 10 минут и перед ним ещё 5 камер. Если сработало распознание на эскалаторе — 8 и 4 камеры, а шестая осталась сзади и не распознала. И так далее. И дальше мы просто тупо смотрим: а сколько ещё камер опознают его? Сколько пропустит?
То есть если можно ещё и тракать с какой-то точностью, то оно лучше, конечно. Но и без тракинга при 3000 лиц в кадрах и базе подозреваемых скажем в 300,000 — имхо статистика таки поможет. Типа если у вас на 4х из 6 камер опознался разыскиваемый — можно ментам на платформе давать команду брать клиента под руки. Если на 1ой, то можно не суетить.
И там ещё как-то хитрить трезво понимая что Джон До то он один. И если у нас есть срабатывание на него в вестибюле, то потом в потоке можно искать не только сравнивая с паспортной фотографией Джона, но и стой, которая опозналась. Учитывая что похмелье на лице потенциального Джона за две минут между верхом и низом эскалатора вряд ли прошло — может оказаться проще выцепить его и сравнить с эталонным изображением настоящего Джона после.
Alexeyslav
Камеры сами по себе не распознают. Распознаёт алгоритм, который работает на серверах по изображениям с камер. Ошибка не будет зависеть от камеры а только от ракурса и условий съемки.
tersuren
Это понятно. Ракурс то и условия будут каждый раз разными, очевидно.
ZlodeiBaal Автор
Смотрите. Я в статье писал про математику, про FAR и FRR. И проще оценивать через них.
FARы таким подходом мы не сильно сократим если люди похожи, похожи причёски, и.т.д. а большая часть FARов именно на таких данных. FRR — мы таким подходом можем немного сократить, там с 40% в лучшем случае до 20-30.
Но даже если мы выиграем порядок — ситуация сильно не поменяется. Как вы видите по остальным цифрам — для полного решении задачи там ещё много порядоков точности надо. А для минимальной помощи сотрудникам — да, можно уже сейчас делать, я это тоже показывал. Можно чуть-чуть уменьшить количество ошибок.
Если же камеры с хорошим освещением поставить на входе — то можно выиграть сильно дешевле, без непонятной математики два порядка. Всё равно для полноценной системы не хватит. Но уже лучше.
MaksV
Системы нахождения похожих лиц не смотрят на прически. Было бы странно, чтобы компьютер обращал на это внимание. :) Даже овал лица некоторые алгоритмы не учитывают, так как под разными ракурсами одно и то же лицо будет иметь совершенно разные профили. Как-то так. matthewearl.github.io/assets/switching-eds/landmarks.jpg
ZlodeiBaal Автор
В начале приведено три статьи о том как сейчас работают системы распознавания. Я бы рекомендовал сперва с ними ознакомится…
MaksV
Видимо я Ваш предыдущий коментарий неправильно понял. Если там речь шла только о вариантах как трэчить и делать многократное сопоставление, то вопросов нет. Если же пытаться использовать прически при сопоставлении лиц, то эти попытки приведут к обратному результату (увеличению ошибок). В широко известном заменителе лиц FaceSwap много усилий сделано на то чтобы отделить лицо от посторонних предметов перекрывающих лицо, таких как прическа, руки, самый тяжелый алгоритм GAN128 направлен именно на это разделение.
ZlodeiBaal Автор
Ещё раз. Советую посмотреть как сейчас делается обучение embeding'а через triple loss, center loss и.т.д… Что там подаётся на вход.
Да, у итогового решения есть зависимость от растительности на лице, от линии причёски, от цвета волос, и.т.д. и это нормально, так как при обучении достигается максимальная разделяющая статистика.
Приведённая вами картинка dlib-овской разметки не имеет ничего общего с тем как сейчас делается распознавание лиц…
babylon
Макс, овал лица думаю распознают, но в конечном счете не учитывают, т.к. внутри лица много других овалов:))) Это всего лишь один из признаков.
Desavian
Ну и сделать цепочку, отслеживающую перемещение по комплексу характеристик. В метро то не проблема, люди телепортироваться пока не научились. Первая съемка — на входе на станцию. Вторая — проход рамки как на ВДНХ например сразу у входа. Третья — опциональная — аппараты по продаже билетов+касса(дает дополнительную аналитику). Четвертая — турникет.
На основании этих 3-4 блоков анализа делается, хм, «слепок», который ведется пятым уровнем камер, стоящих на входе и выходе на каждую станцию.
Реидентификация, отсев ошибок и повторный подхват личностей производится камерами в самих поездах, так как там в большинстве случаев люди стоят неподвижно и камеры в крыше вагонов будут максимально эффективными.
ZlodeiBaal Автор
Сделайте;)
Опять же. Вы говорите про очень-очень сложную систему. Которая съест огромное число человекочасов, стоимость внедрения которой будет астрономической. Но зачем, если можно делать проще, лучше, надежнее, поставив её на входе?
При этом эти стоимости — никак не будут окупаться. Система будет стоить миллиарды. Общественный резонанс — ужасный. Что от самой идеи, что от стоимости. Финансовая прибыль — нулевая. Все задачи можно решить проще и дешевле.
А то что такая система будет хоть как-то работать, у меня есть очень большие сомнения. Выше я писал почему (все алгоритмы всех уровней сырые, дают плохие точности). Камеры ужасные.
То что сейчас есть — уже позволяет работать в ручном режиме, если надо кого-то найти поймать. Это как сделать и разработать робота который будет вам наливать в бокал коктейль. Сделать можно, из любви к искусству. Но стоимость создания и эксплуатации в жизни не окупиться.
Desavian
Будет поставлена задача — сделаю, вопрос, как вы правильно ответили, только в финансовой составляющей. Кривые алгоритмы чинятся привлечением больших вычислительных мощностей, хреновые камеры — повышением их числа и расположения, так что вопрос только в финансовой эффективности. Как только потребуется решение вопроса из серии «пофиг на деньги, надо сделать» — оно будет реализовано достаточно быстро.
ZlodeiBaal Автор
Не все задачи решены, ещё раз. Есть математические и физические ограничения сегодняшнего развития: их никто не отменял.
Я знаю, что сейчас алгоритмов трекинга/реиндентификации не хватает для этой задачи. Можно ли их допилить? Возможно да, возможно нет. Они явно не допиливаются госконторой в рамках госзаказа -> не хватит компетенций и энтузиазма.
Да, если вбухать туда денег как в олимпиаду — наверное можно через десять. А может получиться как с тем ишаком говорящим.
В любом случае, любые задачи которые на сегодняшний день существуют — можно решить проще, дешевле и быстрее. Хотя да, местами нужны будут административные вмешательства.
pashasak
А как работает «магазин без касс и очередей» Amazon Go, в котором, не только людей «трекают», но то, что они положили в корзину?
Loki3000
Они там при входе идентифицируют себя, насколько я помню. Так что надо смотреть по базе из нескольких десятков человек.
TimsTims
unclejocker
А там как раз сплошное поле камер (около 2000 на не самый большой магазин), и им не надо узнавать конкретного человека, а только трекать человекоподобную фигуру от входа до выхода — это просто другая задача.
Welran
Весь магазин утыкан камерами по самое нехочу. Никто в метро столько камер ставить не будет.
dimka11
Интересно зачем они использовали камеры, когда каждому человеку можно дать метку и идентифицировать его по ней.
Ndochp
Мск, новая станция «Ховрино» я себя реально как в каком- нибудь ДеусЭксе чуствовал, или ещё каком стелс шутере. И ловил себя на размышлениях, а с какой камеры надо начать их отстреливать, чтобы ни разу не попасть в кадр. Но кажется это в том камерном поле невозможно.
InterceptorTSK
Алгоритмы не то что неидеальные, они как будто «вражинами» писаны.
Объяснюсь.
Делали приложение для инстаграмчика. Проще некуда, продажа книжек, все банально.
Дизайнер сделала изумительно хороший «шаблон» дизайна любой «книжки». На это написалось простенькое ПО.
На пальцах: кладется закрытая книжка на светлосерую крышку от системного блока, фотается специальной приспособой, открывается книжка, фотается страницы 3-5 и т.д. Если прицепить тел с которого это фотается, запущенная служба стаскивает сама все фотки, банально сортирует по времени и по краям изображений книжки закрытой/открытой создает красивый коллаж. И автоматом зашвыривает на трубу или на эмулятор уже готовые файлы.
Фокус: все это залетело в бан, ибо инстаграм на вопросы зачем и почему вбан написал следующее: вы подписываете фотки как книги, инфа о книгах, авторы книг, а они «системой» определяются как иллюстрации.
Только конченый дебил тут не понимает сразу же, что искусственный интеллект подходит только для быдлы. Как только появляется что-то новое, чего абсолютно нет в премилом обученном быдлой ии — вы сразу улетите в бан, ну вот потому что ии считает, что вы его обманываете.
И так на каждом шагу. Что бы ни контролировалось искусственным интеллектом — нужно быть как все. Иначе фейл.
В гробу я видал этот ваш искусственный интеллект.
JobberNet
Вспомнилась антиутопия «Этот идеальный день», где ИИ помимо прочего определял быть ли человеку художником, и можно ли ему использовать принадлежности для рисования.