

Общие положения
Как Java, в плане производительности, соотносится с C или C++? Как сравнить C# и Python? Ответы на эти вопросы серьёзно зависят от типа анализируемых исследователем приложений. Не существует идеального бенчмарка, но, изучая производительность программ, написанных на разных языках, неплохой отправной точкой может стать проект The Computer Language Benchmarks Game.
Я ссылаюсь на The Computer Language Benchmarks Game уже больше десяти лет. Python, в сравнении с другими языками, такими, как Java, C#, Go, JavaScript, C++, является одним из самых медленных. Сюда входят языки, в которых используется JIT-компиляция (C#, Java), и AOT-компиляция (C, C++), а также интерпретируемые языки, такие, как JavaScript.
Тут мне хотелось бы отметить, что говоря «Python», я имею в виду эталонную реализацию интерпретатора Python — CPython. В этом материале мы коснёмся и других его реализаций. Собственно говоря, здесь мне хочется найти ответ на вопрос о том, почему Python требуется в 2-10 раз больше времени, чем другим языкам, на решение сопоставимых задач, и о том, можно ли сделать его быстрее.
Вот основные теории, пытающиеся объяснить причины медленной работы Python:
- Причина этого — в GIL (Global Interpreter Lock, глобальная блокировка интерпретатора).
- Причина в том, что Python — это интерпретируемый, а не компилируемый язык.
- Причина — в динамической типизации.
Проанализируем эти идеи и попытаемся найти ответ на вопрос о том, что сильнее всего оказывает влияние на производительность Python-приложений.
GIL
Современные компьютеры обладают многоядерными процессорами, иногда встречаются и многопроцессорные системы. Для того чтобы использовать всю эту вычислительную мощь, операционная система применяет низкоуровневые структуры, называемые потоками, в то время как процессы (например — процесс браузера Chrome) могут запускать множество потоков и соответствующим образом их использовать. В результате, например, если какой-то процесс особенно сильно нуждается в ресурсах процессора, его выполнение может быть разделено между несколькими ядрами, что позволяет большинству приложений быстрее решать встающие перед ними задачи.
Например, у моего браузера Chrome, в тот момент, когда я это пишу, имеется 44 открытых потока. Тут стоит учитывать то, что структура и API системы работы с потоками различается в операционных системах, основанных на Posix (Mac OS, Linux), и в ОС семейства Windows. Операционная система, кроме того, занимается планированием работы потоков.
Если раньше вы не встречались с многопоточным программированием, то сейчас вам нужно познакомиться с так называемыми блокировками (locks). Смысл блокировок заключается в том, что они позволяют обеспечить такое поведение системы, когда, в многопоточной среде, например, при изменении некоей переменной в памяти, доступ к одной и той же области памяти (для чтения или изменения) не могут одновременно получить несколько потоков.
Когда интерпретатор CPython создаёт переменные, он выделяет память, а затем подсчитывает количество существующих ссылок на эти переменные. Эта концепция известна как подсчёт ссылок (reference counting). Если число ссылок равняется нулю, тогда соответствующий участок памяти освобождается. Именно поэтому, например, создание «временных» переменных, скажем, в пределах областей видимости циклов, не приводит к чрезмерному увеличению объёма памяти, потребляемого приложением.
Самое интересное начинается тогда, когда одними и теми же переменными совместно пользуются несколько потоков, а главная проблема тут заключается в том, как именно CPython выполняет подсчёт ссылок. Тут и проявляется действие «глобальной блокировки интерпретатора», которая тщательно контролирует выполнение потоков.
Интерпретатор может выполнять лишь одну операцию за раз, независимо от того, как много потоков имеется в программе.
?Как GIL влияет на производительность Python-приложений?
Если у нас имеется однопоточное приложение, работающее в одном процессе интерпретатора Python, то GIL никак на производительность не влияет. Если, например, избавиться от GIL, никакой разницы в производительности мы не заметим.
Если же, в пределах одного процесса интерпретатора Python, надо реализовать параллельную обработку данных с применением механизмов многопоточности, и используемые потоки будут интенсивно использовать подсистему ввода-вывода (например, если они будут работать с сетью или с диском), тогда можно будет наблюдать последствия того, как GIL управляет потоками. Вот как это выглядит в случае использования двух потоков, интенсивно нагружающих процессов.

Визуализация работы GIL (взято отсюда)
Если у вас имеется веб-приложение (например, основанное на фреймворке Django), и вы используете WSGI, то каждый запрос к веб-приложению будет обслуживаться отдельным процессом интерпретатора Python, то есть, у нас имеется лишь 1 блокировка на запрос. Так как интерпретатор Python запускается медленно, в некоторых реализациях WSGI имеется так называемый «режим демона», при использовании которого процессы интерпретатора поддерживаются в рабочем состоянии, что позволяет системе быстрее обслуживать запросы.
?Как ведут себя другие интерпретаторы Python?
В PyPy есть GIL, он обычно более чем в 3 раза быстрее, чем CPython.
В Jython нет GIL, так как потоки Python в Jython представлены в виде потоков Java. Такие потоки используют возможности по управлению памятью JVM.
?Как управление потоками организовано в JavaScript?
Если говорить о JavaScript, то, в первую очередь, надо отметить, что все JS-движки используют алгоритм сборки мусора mark-and-sweep. Как уже было сказано, основная причина необходимости использования GIL — это алгоритм управления памятью, применяемый в CPython.
В JavaScript нет GIL, однако, JS — это однопоточный язык, поэтому в нём подобный механизм и не нужен. Вместо параллельного выполнения кода в JavaScript применяются методики асинхронного программирования, основанные на цикле событий, промисах и коллбэках. В Python есть нечто подобное, представленное модулем
asyncio.Python — интерпретируемый язык
Мне часто приходилось слышать о том, что низкая производительность Python является следствием того, что это — интерпретируемый язык. Подобные утверждения основаны на грубом упрощении того, как, на самом деле, работает CPython. Если, в терминале, ввести команду вроде
python myscript.py, тогда CPython начнёт длительную последовательность действий, которая заключается в чтении, лексическом анализе, парсинге, компиляции, интерпретации и выполнении кода скрипта. Если вас интересуют подробности — взгляните на этот материал.Для нас, при рассмотрении этого процесса, особенно важным является тот факт, что здесь, на стадии компиляции, создаётся
.pyc-файл, и последовательность байт-кодов пишется в файл в директории __pycache__/, которая используется и в Python 3, и в Python 2.Подобное применяется не только к написанным нами скриптам, но и к импортированному коду, включая сторонние модули.
В результате, большую часть времени (если только вы не пишете код, который запускается лишь один раз) Python занимается выполнением готового байт-кода. Если сравнить это с тем, что происходит в Java и в C#, окажется, что код на Java компилируется в «Intermediate Language», и виртуальная машина Java читает байт-код и выполняет его JIT-компиляцию в машинный код. «Промежуточный язык» .NET CIL (это то же самое, что .NET Common-Language-Runtime, CLR), использует JIT-компиляцию для перехода к машинному коду.
В результате, и в Java и в C# используется некий «промежуточный язык» и присутствуют похожие механизмы. Почему же тогда Python показывает в бенчмарках гораздо худшие результаты, чем Java и C#, если все эти языки используют виртуальные машины и какие-то разновидности байт-кода? В первую очередь — из-за того, что в .NET и в Java используется JIT-компиляция.
JIT-компиляция (Just In Time compilation, компиляция «на лету» или «точно в срок») требует наличия промежуточного языка для того, чтобы позволить осуществлять разбиение кода на фрагменты (кадры). Системы AOT-компиляции (Ahead Of Time compilation, компиляция перед исполнением) спроектированы так, чтобы обеспечить полную работоспособность кода до того, как начнётся взаимодействие этого кода с системой.
Само по себе использование JIT не ускоряет выполнение кода, так как на выполнение поступают, как и в Python, некие фрагменты байт-кода. Однако JIT позволяет выполнять оптимизации кода в процессе его выполнения. Хороший JIT-оптимизатор способен выявить наиболее нагруженные части приложения (такую часть приложения называют «hot spot») и оптимизировать соответствующие фрагменты кода, заменив их оптимизированными и более производительными вариантами, чем те, что использовались ранее.
Это означает, что когда некое приложение снова и снова выполняет некие действия, подобная оптимизация способна значительно ускорить выполнение таких действий. Кроме того, не забывайте о том, что Java и C# — это языки со строгой типизацией, поэтому оптимизатор может делать о коде больше предположений, способствующих улучшению производительности программ.
JIT-компилятор есть в PyPy, и, как уже было сказано, эта реализация интерпретатора Python гораздо быстрее, чем CPython. Сведения, касающиеся сравнения разных интерпретаторов Python, можно найти в этом материале.
?Почему в CPython не используется JIT-компилятор?
У JIT-компиляторов есть и недостатки. Один из них — время запуска. CPython и так запускается сравнительно медленно, а PyPy в 2-3 раза медленнее, чем CPython. Длительное время запуска JVM — это тоже известный факт. CLR .NET обходит эту проблему, запускаясь в ходе загрузки системы, но тут надо отметить, что и CLR, и та операционная система, в которой запускается CLR, разрабатываются одной и той же компанией.
Если у вас имеется один процесс Python, который работает длительное время, при этом в таком процессе имеется код, который может быть оптимизирован, так как он содержит интенсивно используемые участки, тогда вам стоит серьёзно взглянуть на интерпретатор, имеющий JIT-компилятор.
Однако, CPython — это реализация интерпретатора Python общего назначения. Поэтому, если вы разрабатываете, с использованием Python, приложения командной строки, то необходимость длительного ожидания запуска JIT-компилятора при каждом запуске этого приложения сильно замедлит работу.
CPython пытается обеспечить поддержку как можно большего количества вариантов использования Python. Например, существует возможности подключения JIT-компилятора к Python, правда, проект, в рамках которого реализуется эта идея, развивается не особенно активно.
В результате можно сказать, что если вы, с помощью Python, пишете программу, производительность которой может улучшиться при использовании JIT-компилятора — используйте интерпретатор PyPy.
Python — динамически типизированный язык
В статически типизированных языках, при объявлении переменных, необходимо указывать их типы. Среди таких языков можно отметить C, C++, Java, C#, Go.
В динамически типизированных языках понятие типа данных имеет тот же смысл, но тип переменной является динамическим.
a = 1
a = "foo"В этом простейшем примере Python сначала создаёт первую переменную
a, потом — вторую с тем же именем, имеющую тип str, и освобождает память, которая была выделена первой переменной a.Может показаться, что писать на языках с динамической типизацией удобнее и проще, чем на языках со статической типизацией, однако, такие языки созданы не по чьей-то прихоти. При их разработке учтены особенности работы компьютерных систем. Всё, что написано в тексте программы, в итоге, сводится к инструкциям процессора. Это означает, что данные, используемые программой, например, в виде объектов или других типов данных, тоже преобразуются к низкоуровневым структурам.
Python выполняет подобные преобразования автоматически, программист этих процессов не видит, и заботиться о подобных преобразованиях ему не нужно.
Отсутствие необходимости указывать тип переменной при её объявлении — это не та особенность языка, которая делает Python медленным. Архитектура языка позволяет сделать динамическим практически всё, что угодно. Например, во время выполнения программы можно заменять методы объектов. Опять же, во время выполнения программы можно использовать технику «обезьяньих патчей» в применении к низкоуровневым системным вызовам. В Python возможно практически всё.
Именно архитектура Python чрезвычайно усложняет оптимизацию.
Для того чтобы проиллюстрировать эту идею, я собираюсь воспользоваться инструментом для трассировки системных вызовов в MacOS, который называется DTrace.
В готовом дистрибутиве CPython нет механизмов поддержки DTrace, поэтому CPython нужно будет перекомпилировать с соответствующими настройками. Тут используется версия 3.6.6. Итак, воспользуемся следующей последовательностью действий:
wget https://github.com/python/cpython/archive/v3.6.6.zip
unzip v3.6.6.zip
cd v3.6.6
./configure --with-dtrace
makeТеперь, пользуясь
python.exe, можно применять DTRace для трассировки кода. Об использовании DTrace с Python можно почитать здесь. А вот тут можно найти скрипты для измерения с помощью DTrace различных показателей работы Python-программ. Среди них — параметры вызова функций, время выполнения программ, время использования процессора, сведения о системных вызовах и так далее. Вот как пользоваться командой dtrace:sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe script.py’А вот как средство трассировки
py_callflow показывает вызовы функций в приложении.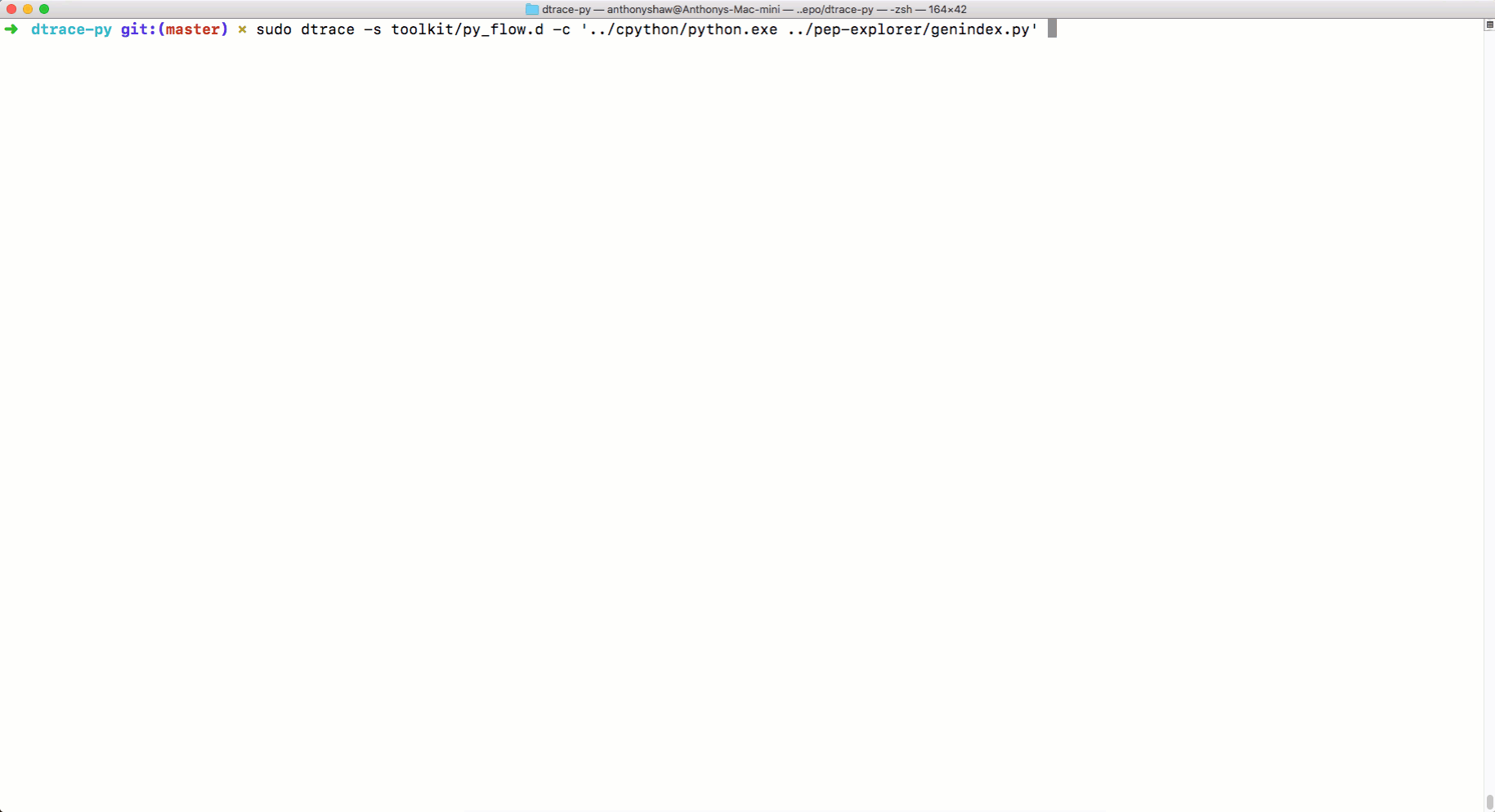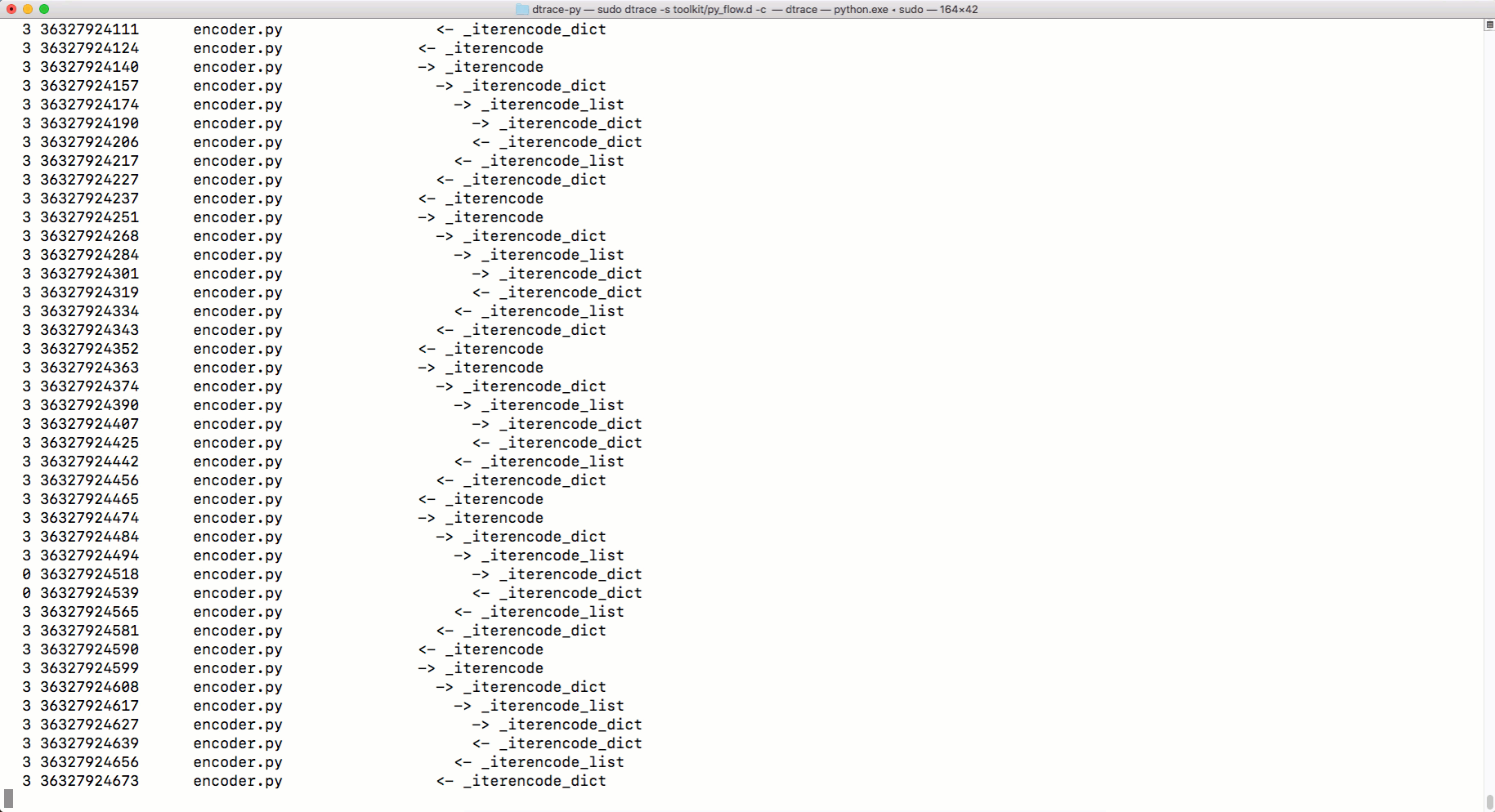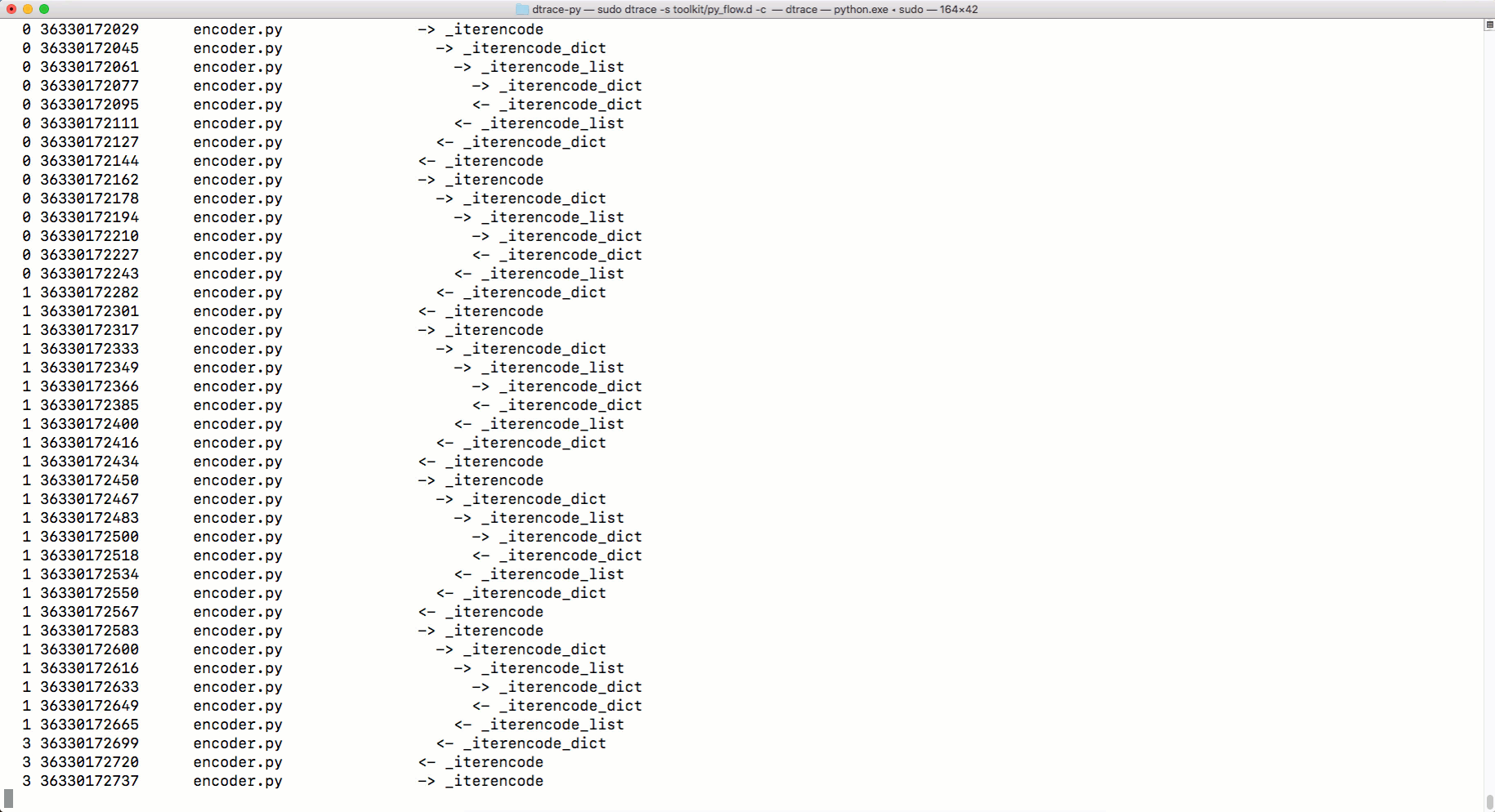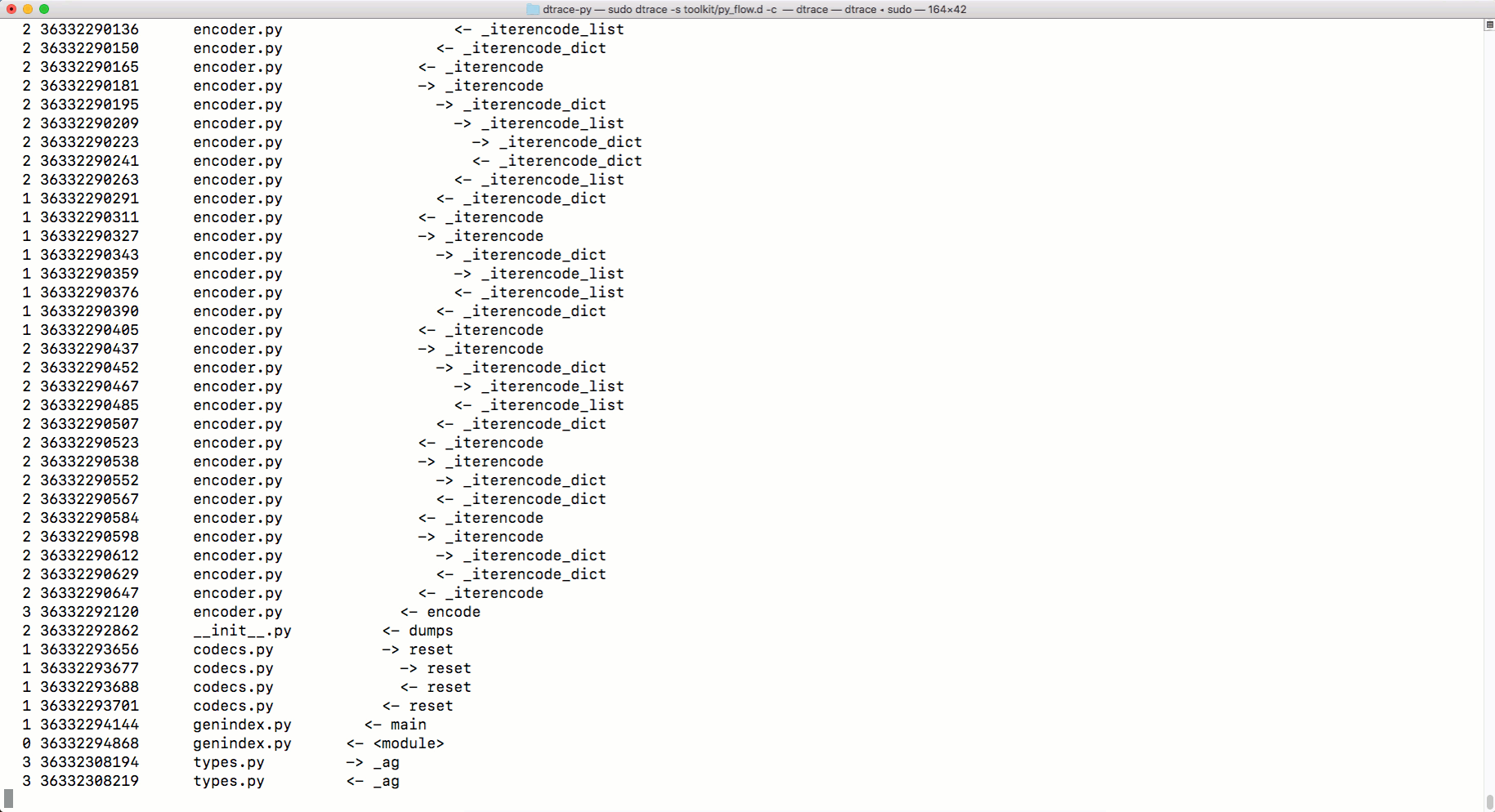
Трассировка с использованием DTrace
Теперь ответим на вопрос о том, влияет ли динамическая типизация на производительность Python. Вот некоторые соображения по этому поводу:
- Проверка и конверсия типов — операции тяжёлые. Каждый раз, когда выполняется обращение к переменной, её чтение или запись, производится проверка типа.
- Язык, обладающей подобной гибкостью, сложно оптимизировать. Причина, по которой другие языки настолько быстрее Python, заключается в том, что они идут на те или иные компромиссы, выбирая между гибкостью и производительностью.
- Проект Cython объединяет Python и статическую типизацию, что, например, как показано в этом материале, приводит к 84-кратному росту производительности в сравнении с применением обычного Python. Обратите внимание на этот проект, если вам нужна скорость.
Итоги
Причиной невысокой производительности Python является его динамическая природа и универсальность. Его можно использовать как инструмент для решения разнообразнейших задач. Для достижения тех же целей можно попытаться поискать более производительные, лучше оптимизированные инструменты. Возможно, найти их удастся, возможно — нет.
Приложения, написанные на Python, можно оптимизировать, используя возможности по асинхронному выполнению кода, инструменты профилирования, и — правильно подбирая интерпретатор. Так, для оптимизации скорости работы приложений, время запуска которых неважно, а производительность которых может выиграть от использования JIT-компилятора, рассмотрите возможность использования PyPy. Если вам нужна максимальная производительность и вы готовы к ограничениям статической типизации — взгляните на Cython.
Уважаемые читатели! Как вы решаете проблемы невысокой производительности Python?

Комментарии (47)

Javian
01.08.2018 13:20+7Как вы решаете проблемы невысокой производительности Python?
Для особой задачи существуют особый инструмент. Проблема производительности не должна волновать, если выбран Python. Если же этот вопрос стоит, то вы ошиблись в первоначальном выборе инструмента для решения задачи. В общем случае в сравнении C, C++ и JAVA, программный код на языке Python проще писать, отлаживать и сопровождать.
А так пробовать CPython, Jython, IronPython.artskep
01.08.2018 15:47+2В общем случае в сравнении C, C++ и JAVA, программный код на языке Python проще писать, отлаживать и сопровождать
Я бы добавил "в определенных задачах". С и плюсы, как компилируемые, конечно, имеют вынужденные сложности с разработкой, но java и прочие интерпретируемые строго типизированные языки при определеном размере кода могут быть проще в написании (IDE, как правило, проще работать с языками "построже"), и в сопровождении (проверки на уровне компиляции это хорошо — в слишком гибких языках regression можно отслеживать только тестами. Не, TDD это неплохо, но когда тест надо писать на любой чих, чтобы ничего не свалилось, то это сомнительное свойство языка)
Femistoklov
02.08.2018 08:29Именно так. У кроваво-энтерпрайзных языков есть свои преимущества. Не представляю, как тонну легаси говнокода на плохо типизированном языке можно сопровождать, проще наверно застрелиться. А в Java и C# такое — сплошь и рядом.
nikitasius
02.08.2018 12:50Не надо кидаться в Java и равнть к другим. Легаси код понятие растяжимое: ему 1 год, 3 или 10 лет?
Тем более не забываем об анализаторах, которые умеют подсказывать (если уж не сам писал проект), где, что и как поменялось и что более не юзается в выбранной версии языка для проекта.
Далее, если речь идет о чистой Java (конечно с внешними либами, но без совсем уж жирных, которые именуют себя фреймворками), то там все просто и понятно, под свою задачу, есессно.
evgenyk
01.08.2018 14:06+3Я давно работаю на питоне и с «проблемами невысокой производительности» пока не сталкивался.
Но, например, если бы мне нужно было бы обсчитать массив чисел, и производительности бы не хватало, сегодня я попробовал бы связку Python+Numpy+Ctypes и поробовал бы написать работу с массивом чисел на Си и дергать ее из питона.
Ну или Cython, но не факт, что получиться написать быстрее, чем на Python+C. Я имею в виду скорость разработки.artskep
01.08.2018 19:24Насколько я понимаю, описанная в статье проблема имеет влияние только когда есть много потоков, конкурирующих за процессор.
Во многих реальных задачах потоки ждут i/o операции большую часть времени, так что это может быть незаметно. На 100%cpu нечасто приходится работать. А в devops или нехитрой оптимизации (где питон часто используется и, на мой взгляд, особенно хорош) вообще ни о чемevgenyk
01.08.2018 19:32Можно вместо потоков использовать процессы. И тогда GIL неактуален. Но, питон и сам по себе не очень шустрый. Но в 90 процентов случаев скорости вполне хватает.
artskep
01.08.2018 20:47+2Ну да — в этом сама суть.
Питон "человеческий" язык со своей областью применения.
Натягивание совы на глобус, чтобы быть "лучшим" языком… возможно, а оно надо?
Хайп вокруг питона последнее время меня смущает: никто не говорит, что скрипты на bash для автоматизации чего-то сложнее ls|grep|wc выглядят, как порождение марсиан, но, как только в питоне изменился синтакс print или ввели новые операторы — все дружно обсуждают кризис языка
AlexPancho
01.08.2018 15:54JobberNet
02.08.2018 09:47Уроки по Кристалу для Хабры не напишите?
И есть ли там поддержка OpenGL/OpenCL/OpenAL/OpenML?
Сборщик мусора у него отключаемый?
ArsenAbakarov
01.08.2018 16:33Работаю с python, io можно ускорить асинхронщиной (asyncio, curio, trio и тд. и тп.)
Для тяжелых вычислений с числами можно брать numpy, там почти все на C
Да и вообще сперва код, потом оптимизация, узкие места можно на C реализовать
Прекрасно понимаю что язык не универсален, в геймдеве, например, только для скриптинга…
В своей работе тоже не сталкивался с проблемой низкой производительности, но от синтаксиса и идеологии в восторге, правда вот последние изменения настораживают…Neikist
01.08.2018 16:46А что за изменения? А то подумываю перейти на него.
ArsenAbakarov
01.08.2018 17:31например :=, уход Гвидо
AhJong
01.08.2018 19:19Так Гвидо был прав с := и те, кто не понимал, зачем предлагается такая конструкция просто его задолбали.
Sly_tom_cat
01.08.2018 18:49:= и «самоснятие короны» — в новостях все было и было бы трудно пропустить если вы интересуетесь Python-ом.
Neikist
01.08.2018 20:26Обе видел, но я лично не вижу ничего плохого ни в том ни в том, боялся увидеть в ответ что то вроде изменения лицензионной политики, уход в конкретную прикладную область самого языка (веб, анализ данных, т.п.), раскол на несколько разных веток и подобное. А тут всего лишь небольшие изменения синтаксиса и уход важной фигуры немного в сторону.
Zanak
01.08.2018 19:35С уходом Гвидо, для широкой публики возникло определенное недопонимание, как будут приниматься решения о развитии языка. Не факт, что и раньше много людей знало, как это происходило, но была легенда, что Гвидо ван Россум — это тот человек, за которым остается последнее слово, и он не допустит необоснованных нововедений.
Пример деградации проекта, из за непродуманных действий — это ситуация с perl. Сколько лет уже пилят 6 версию, но стандартом она так и не стала. Сам язык есть, но это все еще 5 версия, которая осталась в своей нише, но это совсем не то, что было во времена рассвета.
chupasaurus
02.08.2018 15:35в геймдеве, например, только для скриптинга…
Маленькая инди-игра EVE Online всё ещё на Stackless Python в клиенте и серверах, производительность затыкалась вставками C/C++.
0xd34df00d
01.08.2018 17:24+1В статически типизированных языках, при объявлении переменных, необходимо указывать их типы.
Нет. Не следует путать статическую типизацию и обязательные аннотации типов.
Python выполняет подобные преобразования автоматически, программист этих процессов не видит, и заботиться о подобных преобразованиях ему не нужно.
А в каком-то из высокоуровневых статически типизированных языков программисту нужно об этом заботиться?
mapron
01.08.2018 18:31Причиной невысокой производительности Python является его динамическая природа и универсальность.
Что-то статья как-то резко оборвалась. В начале рассматривалось сравнение с Javascript — там же почти все тоже самое, нет? Неужели при обращении к переменной ее тип не проверяется, в чем принципиальная разница?inv2004
01.08.2018 19:23Не могу сказать по составляющей, но у меня был одинаковый код на python и nodejs (описал комментом ниже). nodejs была заметно быстрее питона, но, к сожалению, у меня она не прижилась, так как питоновские биндинги типа numpy естественно выиграли у нативных JS-решений, не говоря уж о ML.
inv2004
01.08.2018 19:20Расскажу свой случай:
Написал некий подбор параметров для вычисления. сначала сделал это на Rust, заняло довольно много времени, так как это был первый подход к расту, без каких-то особенных оптимизаций получилось вполне примлемо: ~4млн данных подбирало 7 параметров (где-то 12млн комбинаций) на домашнем i5-7500 около 5 часов.
Потом захотелось добавить ML, естественным выбором для этого был питон. ML подсчитал всё что надо, но я подумал, что питон такой модный и молодёжный, что почему бы не попробовать его применить глубже.
сначала с pandas — скорость была такая, что он и 1k данным считал больше минуты — это ни в какие ворота. Переписал всё исключтельно на numpy — скорость стала вполне приличной.
Но всё не верторизируешь, и одним numpy сыт не будешь — добавил перебор параметров как было раньше — и с каждым лишним if программа проседала на порядки, в итоге ETA подсчёта того что я описал в первом обзаце, показал что оно будет считаться несколько месяцев, что очень резко охладило желание использовать питон где-то за пределами ML.fireSparrow
01.08.2018 22:08сначала с pandas — скорость была такая, что он и 1k данным считал больше минуты — это ни в какие ворота. Переписал всё исключтельно на numpy — скорость стала вполне приличной.
Но ведь у pandas под капотом как раз numpy крутится, не может у них быть какого-то значимого различия в скорости. Возможно, вы в первом случае просто что-то сделали не так.inv2004
01.08.2018 22:18там код довольно простой: вначале было переписано 1 в 1 и прирост был сразу. потом ещё уже на numpy оптимизировал.
Arseny_Info
02.08.2018 00:47pandas довольно медленный (особенно если его неправильно готовить, например, итерировать по строкам). Даже в простых случаях накладные расходы сильно тормозят:
In [38]: arr = np.random.rand(1000, 10000) In [39]: df = pd.DataFrame(arr) In [40]: %timeit arr.mean(axis=1) 4.62 ms ± 114 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) In [41]: %timeit df.apply(np.mean, axis=1) 109 ms ± 1.43 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [42]: np.all(arr.mean(axis=1) == df.apply(np.mean, axis=1)) Out[42]: True
Slasher111
01.08.2018 19:21Удивительно, что в статье не упомянули numba. На мой взгляд, это самый простой, но при этом очень мощный способ увеличения производительности при минимальных изменениях в исходном коде.
Akafe
01.08.2018 19:21Все это уже давно известно, ничего нового, никакого углубления в суть. Вот если бы автор, например, взял пример какой-нибудь функции на python и проанализировал ее байт-код, замерил бы скорость его компиляции и интерпретации и по регистрам проанализировал получившийся в итоге нативный код, сравнив его с аналогичным результатом на c# или c++, тогда я б поклонился. Была бы видна незаурядная работа, а так просто перечень общеизвестных истин. Кстати, что cpython делает с байт-кодом в pyc файлах? Он его просто интерпретирует, не компилируя в нативный, или каждый раз перекомпилирует? — из статьи так это и не ясно
saaivs
01.08.2018 20:27Oracle не так давно достаточно интересно подошла к рантайму для различных языков программирования, включая Python, и предварительные результаты для динамических языков выглядят вполне неплохо youtu.be/mMmOntDWSgw?t=678. С учетом того, что GraalVM позволяет генерировать в том числе и нативный код, то в теории увеличивается не только общая производительность, но и время старта программ.
alexeygrigorev
01.08.2018 21:14Стоит добавить про numba — в некоторых случаях очень хорошо ускоряет код
alec_kalinin
01.08.2018 22:59Ключевые слова: процессы, asyncio, numpy, cupy, numba, cython решают все проблемы с производительностью.
lorc
01.08.2018 23:08+1Питон — это не числодробилка. 99% времени программа на Питоне чего-нибудь ждет: ответа от БД, чтения данных с диска, прихода пакета по сети, пользовательского ввода.
Если мне нужна числодробилка, я напишу программу на С (может даже с OpenCL). Если мне нужна программа, которая вычитывает из последовательного порта данные, пакует их в XML и пуляет на удаленный сервер по HTTPS с авторизацией по сертификатам — я напишу ее на Python. Потому что так проще, удобнее и быстрее.
korizza_spb
02.08.2018 07:29ну так есть же форки процессов в питоне, и ими активно пользуются для распараллеливания выполнения задач.
Elrond16
02.08.2018 10:35+1Как вы решаете проблемы невысокой производительности Python?
Поскольку Python все более и более популярен в научной среде, эта проблема решается использованием библиотек с высокой производительностью. Для многих вычислительных задач и обработки данных хватает производительности numpy, scipy, numba, pandas. Для чего-то более хитрого можно написать основную часть на C/C++/Cython, а Python использовать как высокоуровневую обертку. Еще есть Dask, который для определенных задач обещает довольно простой параллелизм, масштабируемый до суперкомпьютеров, но я им пока не пробовал пользоваться.
nafikovr
02.08.2018 10:41скорость выполнения может и не очень, но скорость разработки сервисных утилит просто решает.
PS: PyQt отлично помогает избавиться от проблем производительности в GUI.
lega
02.08.2018 11:03и используемые потоки будут интенсивно использовать подсистему ввода-вывода (например, если они будут работать с сетью или с диском), тогда можно будет наблюдать последствия того, как GIL управляет потоками. Вот как это выглядит в случае использования двух потоков, интенсивно нагружающих процессов.
«Смешались люди-кони», как раз IO работа параллелится замечательно, а вот для CPU нагрузки* потоки не помогут.
Но это опять же зависит от задачи, если вы будете делать задачу сжатия данных (архиватор), то решение по скорости будет сопоставимо с С/С++.
Питон надо рассматривать как «мастер»-язык (код который управляет другим кодом), поэтому хорошо знать не просто питон а связку Python-C++ или Python-Cython, тогда вопросы скорости отпадут.
0serg
02.08.2018 12:56Питон в целом плохо подходит для высокопроизводительных задач. Это не его ниша. На нем удобно всякие инструменты создавать да прототипы.
Но если все же надо его то numpy (при правильном применении) или какая-нибудь другая domain-specific библиотека дает прекрасную однопоточную производительность сочетая скорость C с удобством Python.
Чисто питоновские решения следует запускать на PyPy — это дает ускорение на порядок а то и на два.
SirEdvin
Больше десяти лет ссылаться на такой бесполезный источник. Этим можно гордится?