
Автор материала, первую часть перевода которого мы сегодня публикуем, говорит, что он, как независимый консультант по Node.js, каждый год анализирует более 10 проектов. Его клиенты, что вполне оправданно, просят его обратить особое внимание на тестирование. Несколько месяцев назад он начал делать заметки, касающиеся ценных приёмов тестирования и встречающихся ему ошибок. В результате получился материал, содержащий три десятка рекомендаций по тестированию.
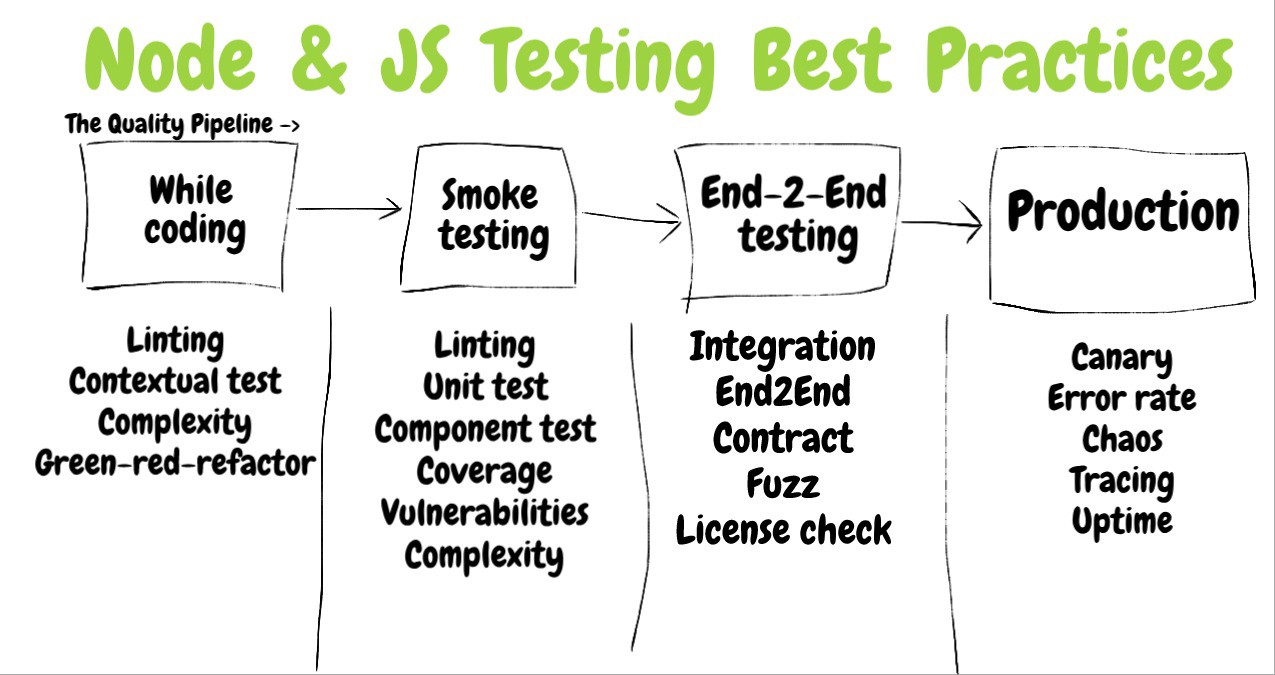
В частности, речь здесь пойдёт о выборе подходящих в конкретной ситуации типов тестов, об их правильном оформлении, об оценке их эффективности, и о том, где именно в CI/CD-цепочках нужно их размещать. Некоторые из приведённых здесь примеров проиллюстрированы с использованием Jest, некоторые — с использованием Mocha. Этот материал, в основном ориентирован не на инструменты, а на методологии тестирования.
> Тестирование Node.js-проектов. Часть 2. Оценка эффективности тестов, непрерывная интеграция и анализ качества кода
Знаете ли вы кого-нибудь — друга, члена семьи, героя фильма, кто всегда заряжен хорошим настроением и всегда готов предложить руку помощи, ничего не требуя взамен? Именно так должны быть спроектированы хорошие тесты. Они должны быть простыми, должны приносить пользу и вызывать положительные эмоции. Этого можно достичь путём тщательного отбора методик, инструментов и целей тестирования. Таких, использование которых оправдывает затраты времени и сил на подготовку и проведение тестов и при этом даёт хорошие результаты. Тестировать нужно только то, что нуждается в проверке, надо стремиться к тому, чтобы тесты были бы простыми и гибкими, а иногда от некоторых тестов можно и отказаться, осмысленно пожертвовав надёжностью проекта ради его простоты и скорости разработки.
Тесты не стоит рассматривать как обычный код приложений. Дело в том, что типичная команда, занимающаяся разработкой некоего проекта, в любом случае, делает всё возможное для поддержки его в рабочем состоянии, то есть стремится к тому, чтобы, скажем, коммерческий продукт работал так, как того ждут его пользователи. В результате такая команда может не очень хорошо отнестись к тому, что ей придётся поддерживать ещё один сложный «проект», представленный набором тестов. Если тесты основного кода разрастаются, оттягивая на себя всё больше внимания и становясь поводом для постоянного беспокойства, то работу над ними либо забросят, либо, пытаясь поддерживать на достойном уровне, отдадут им столько сил и времени, что это замедлит работу над основным проектом.
Поэтому код тестов должен быть как можно более простым, с минимальным количеством зависимостей и уровней абстракции. Тесты должны выглядеть так, чтобы их можно было бы понять с одного взгляда. Большинство рекомендаций, которые мы здесь рассмотрим, произрастают из этого принципа.
Отчёт о тестировании должен сообщать о том, удовлетворяет ли текущая версия приложения требованиям к нему. Делаться это должно в такой форме, которая будет понятна тем, кто не обязательно должен быть знаком с кодом приложения. Это может быть тестировщик, DevOps-специалист, занимающийся развёртыванием проекта, или сам разработчик, взглянувший на проект через некоторое время после написания его кода. Достичь этого можно в том случае, если при написании тестов ориентироваться на требования к продукту. При таком подходе структуру теста можно представить себе состоящей из трёх частей:
Предположим, систему не удалось развернуть и при этом из отчёта о тестировании можно узнать лишь о том, что она не прошла тест, названный
Сведения о тесте состоят из трёх фрагментов информации.
Отчёт о тестировании напоминает документ, содержащий изложение требований к продукту.
Вот как это выглядит на разных уровнях.

Документ с требованиями к продукту, именование тестов, результаты тестирования
Разработка тестов в декларативном стиле позволяет тому, кто с ними работает, мгновенно схватывать их суть. Если тесты пишут, используя императивный подход, они оказываются наполненными условными конструкциями, которые значительно затрудняют их понимание. Следуя этому принципу, ожидания нужно описывать на языке, близком к обычному. В декларативном BDD-стиле используются конструкции
Если не следовать вышеописанным рекомендациям, всё закончится тем, что члены команды разработчиков будут писать меньше тестов и пропускать особо досаждающие им проверки, используя метод
Читателю этого теста придётся полностью просмотреть довольно длинный императивный код только для того, чтобы понять то, что именно проверяется в тесте.
Понять этот тест можно буквально с одного взгляда.
Существует набор плагинов для ESLint, разработанный специально для анализа кода тестов и для нахождения проблем в таком коде. Например, плагин eslint-plugin-mocha выдаёт предупреждения в том случае, если тест написан на глобальном уровне (а не является потомком
Разработчик будет счастлив, видя, что код покрыт тестами на 90% и при этом 100% тестов проходят успешно. Однако в таком состоянии он будет пребывать лишь до тех пор, пока не окажется, что многие тесты, на самом деле, ничего не проверяют, а некоторые тестовые сценарии просто пропускаются. Остаётся лишь надеяться, что никто не станет разворачивать в продакшне проекты, которые «протестированы» подобным образом.
Тестовый сценарий полон ошибок, которые, к счастью, можно выявить с помощью линтера.
Тестирование неких внутренних механизмов кода означает значительное повышение нагрузки на разработчиков и не даёт практически никаких выгод. Если некое API выдаёт правильные результаты, стоит ли тратить несколько часов на тестирование его внутренних механизмов и потом ещё поддерживать эти тесты, которые очень легко «ломаются», в актуальном состоянии? При проверке общедоступных методов их внутренняя реализация, хотя и неявно, но тоже проверяется. Подобный тест выдаст ошибку в том случае, если в системе возникнет некая проблема, выражающаяся в выдаче неправильных данных. Этот подход ещё называют «поведенческим тестированием». С другой стороны, тестируя внутренние механизмы некоего API (то есть — используя методику «белого ящика»), разработчик сосредотачивается на мелких деталях реализации, а не на конечном результате работы кода. Тесты, проверяющие подобные тонкости, могут начать выдавать ошибки, например, после небольшого рефакторинга кода, даже несмотря на то, что система продолжает выдавать верные результаты. В результате такой подход значительно повышает нагрузку на программиста, связанную с поддержкой кода тестов.
Тесты, которыми пытаются охватить внутренние механизмы некоей системы, ведут себя как мальчик-пастух из басни, который сзывал крестьян криками «Помогите! Волк!», когда никакого волка поблизости не было. Люди сбегались на помощь лишь для того, чтобы обнаружить, что их обманули. А когда волк и правда появился, никто уже на помощь не пришёл. Такие тесты выдают ложноположительные результаты, например, в тех случаях, когда меняются имена каких-то внутренних переменных. В результате неудивительно то, что тот, кто проводит эти тесты, скоро начинает игнорировать их «крики», что, в конечном итоге, приводит к тому, что однажды незамеченной может оказаться настоящая серьёзная ошибка.
Этот тест проверяет внутренние механизмы класса без особой причины для таких проверок.
Использование объектов-дублёров (test doubles) при тестировании — это необходимое зло, так как они связаны с внутренними механизмами приложения. Без некоторых из них прямо-таки невозможно обойтись. Вот полезный материал на эту тему. Однако различные подходы к использованию подобных объектов нельзя назвать равнозначными. Так, некоторые из них — стабы (stub) и шпионы (spy), направлены на тестирование требований к продукту, но, в виде неизбежного побочного эффекта, они вынуждены слегка затрагивать внутренние механизмы этого продукта. Моки же (mock), с другой стороны, нацелены на тестирование внутренних механизмов проекта. Поэтому их использование ведёт к огромной ненужной нагрузке на программистов, о которой мы говорили выше, предлагая придерживаться при написании тестов методики «чёрного ящика».
Прежде чем использовать объекты-дублёры, задайте себе один простой вопрос: «Использую ли я их для проверки функционала, который описан, или мог бы быть описан в технических требованиях к проекту?». Если ответ на этот вопрос отрицателен — это может означать, что вы собираетесь тестировать продукт, используя подход «белого ящика», о недостатках которого мы уже говорили.
Например, если вы хотите узнать, правильно ли ваше приложение работает в ситуации, когда недоступен платёжный сервис, вы можете застабить этот сервис и сделать так, чтобы приложение получило бы нечто, указывающее на отсутствие ответа. Это позволит проверить реакцию системы на подобную ситуацию, узнать, ведёт ли она себя правильно. В ходе подобного испытания проводится проверка поведения, или ответа, или результата работы приложения в определённых условиях. В этой ситуации можно воспользоваться шпионом для проверки того, было ли, при обнаружении падения платёжного сервиса, отправлено некое электронное письмо. Это, опять же, будет проверкой поведения системы в определённой ситуации, что, наверняка, зафиксировано в технических требованиях к ней, скажем, в следующем виде: «Отправить электронное письмо администратору в том случае, если платёж не проходит». С другой стороны, если использовать мок-объект для представления платёжного сервиса и проверить работу при обращении к нему с передачей ему того, что он ожидает, то речь будет идти о тестировании внутренних механизмов, которые не имеют прямого отношения к функционалу приложения, и, вполне возможно, могут часто меняться.
При любом рефакторинге кода придётся искать все моки, подвергая рефакторингу и их код. В результате поддержка тестов превратится в тяжкое бремя, делая их врагами разработчика, а не его друзьями.
В этом примере показан мок-объект, ориентированный на тестирование внутренних механизмов приложения.
Шпионы нацелены на испытание систем на соответствие требований к ним, но, в виде побочного эффекта, неизбежно затрагивают внутренние механизмы систем.
Часто ошибки в продакшне проявляются при весьма специфическом и даже удивительном стечении обстоятельств. А это значит, что чем ближе к реальности входные данные, используемые в ходе тестирования, тем выше вероятность раннего обнаружения ошибок. Используйте, для генерирования данных, напоминающих реальные, специализированные библиотеки, такие, как Faker. Например, такие библиотеки генерируют случайные, но реалистичные номера телефонов, имена пользователей, номера банковских карт, названия компаний и даже тексты в духе «lorem ipsum». Более того, рассмотрите возможность использования в тестах данных, взятых из продакшн-окружения. Если же вы хотите поднять подобные тесты на ещё более высокий уровень — обратитесь к нашей следующей рекомендации, посвящённой тестированию, основанному на проверке свойств.
При тестировании проекта в ходе его разработки все тесты могут оказаться пройденными лишь в том случае, если при их проведении используются нереалистичные данные наподобие строк «foo». А вот в продакшне система даст сбой в ситуации, когда хакер передаст ей что-то вроде
Система успешно проходит эти тесты лишь потому что в них используются нереальные данные.
Здесь используются рандомизированные данные, похожие на настоящие.
Обычно в тестах используют небольшие наборы входных данных. Даже если они и напоминают реальные данные (мы говорили об этом в предыдущем разделе), такие тесты покрывают лишь весьма ограниченное количество возможных комбинаций входов исследуемой сущности. Например, это может выглядеть так:
Разработчик, неосознанно, выбирает такие тестовые данные, которые покрывают лишь те участки кода, которые работают правильно. К сожалению, это снижает эффективность тестирования как средства для обнаружения ошибок.
Тестирование множества вариантов входных данных с использованием библиотеки mocha-testcheck.
Вероятно, сейчас уже очевидно, что я являюсь приверженцем предельно простых тестов. Дело в том, что в противном случае команде разработчиков некоего проекта, фактически, приходится заниматься ещё одним проектом. Для того чтобы понять его код, им приходится тратить ценное время, которого у них не так уж и много. Тут очень хорошо написано об этом явлении: «Качественный продакшн-код — это код хорошо продуманный, а качественный код тестов — это код совершенно понятный… Когда вы пишете тест — думайте о том, кто увидит выведенное им сообщение об ошибке. Этот человек не хотел бы, для того, чтобы понять причины ошибки, читать код всего тестового набора или код дерева наследования утилит, используемых для тестирования».
Для того чтобы читатель мог бы понять тест, не покидая его код, минимизируйте использование утилит, хуков, или любых внешних механизмов при выполнении теста. Если для того, чтобы это сделать, понадобится слишком часто прибегать к операциям копирования и вставки кода, можно остановиться на одном внешнем вспомогательном механизме, использование которого не нарушит понятности теста. Но, если число подобных механизмов будет расти, код теста будет терять понятность.
Вы обнаружили, что в ваших тестах применяется 4 вспомогательных модуля, 2 из которых унаследованы от базовых утилит, много кода для настройки тестовой среды и несколько хуков? Принимайте поздравления! Теперь вам надо будет поддерживать ещё один непростой проект, а если всё и дальше будет продолжаться в том же духе, то вы скоро начнёте писать тесты для тестов.
Взгляните на эту интересную и запутанную структуру. Ясен ли вам смысл происходящего без обращения к коду внешних зависимостей?
Вот пример теста, понять который можно без обращения к стороннему коду.
Если следовать золотому правилу тестирования, изложенному в нулевом пункте этого материала, то каждый тест должен, например, самостоятельно добавлять в базу данных некие записи и пользоваться только ими. Это поможет предотвратить проблему связанности разных тестов и позволит легко анализировать ход выполнения отдельных тестов. В реальности тестировщики часто нарушают это правило, заполняя базы данных информацией до запуска тестов (это ещё называют настройкой тестового окружения) ради улучшения производительности тестирования. Хотя производительность — это важно, проблемы производительности поддаются решению (взгляните на раздел, где речь идёт о компонентном тестировании). А вот вопросы сложности тестов — это уже гораздо серьёзнее, и именно ими и нужно, по большей части, руководствоваться, принимая различные решения. На практике это означает, что нужно сделать так, чтобы каждый тест в явном виде добавлял бы в базу данных необходимые ему записи и работал бы только с ними. Если на первый план выходит производительность — тогда можно найти разумный компромисс, скажем, централизованно готовя данные, с которыми будут работать только те тесты, которые эти данные не меняют (то есть только те, которые, например, выполняют к базам данных лишь запросы на чтение).
Предположим, несколько тестов дало сбой. Развёртывание проекта отменено. Команде нужно будет потратить несколько часов на выяснение причин происходящего. Этими причинами могут быть ошибки в коде. На самом же деле оказывается, что сбои тестов вызваны тем, что некоторые из них меняют одни и те же заранее заданные данные, а другие об этом ничего не знают.
Тесты в этом примере не являются независимыми. Они полагаются на некий глобальный хук, пользуясь общей базой данных.
Мы можем не покидать пределы теста, организовав всё так, чтобы каждый тест работал бы с собственным набором данных.
Если нужно проверить код на предмет выбрасывания им исключений, может показаться, что правильно будет использовать конструкцию
Более изящная альтернатива такому подходу заключается в использовании особого однострочного утверждения Chai, которое выглядит как
Если тесты обрабатывают все исключения, возникающие в коде, одинаково, из отчёта о тестировании может быть очень непросто понять причины неправильного поведения программы.
Вот длинный код теста, в котором сделана попытка проверки выдачи кодом исключений с помощью конструкции
Вот как использование конструкции
Разные тесты должны выполняться в различных ситуациях. Например, минимальный набор тестов для выявления очевидных ошибок (smoke test), не подразумевающий работу с подсистемами ввода-вывода, стоит запускать каждый раз, когда разработчик сохраняет или коммитит файл. А вот полное сквозное тестирование обычно выполняют при отправке нового пулл-запроса в репозиторий. Выбор тестов, которые должны выполняться в том или ином сценарии, можно организовать на основе назначаемых им тегов, представляющих собой ключевые слова наподобие
Если представить себе, что каждый раз, когда разработчики вносят небольшое изменение в код, выполняется куча тестов, в ходе которых производятся десятки запросов к базе данных, то окажется, что проводиться это тестирование будет крайне медленно. В результате разработчики постараются от таких тестов избавиться.
Тег
В этом материале даются рекомендации по тестированию, относящиеся к Node.js-проектам. Здесь же представлены рекомендации, широко известные, но непосредственно к Node.js не относящиеся.
Полезно изучить и опробовать принципы TDD — они весьма ценны во многих ситуациях, хотя вполне может оказаться так, что в ваш стиль работы над проектами они не вписываются. Это не должно вас расстраивать, так как подходят они далеко не всем. Рассмотрите возможность написания тестов до написания кода, для которого они предназначены, работая в стиле Red-Green-Refactor. Следите за тем, чтобы один тест проверял лишь что-то одно, а если вы обнаруживаете в программе ошибку, то, перед её исправлением, напишите тест для её выявления, что позволит находить такие же ошибки и в будущем. Следуйте правилу, в соответствии с которым рабочий код не пишут без неудачно завершившегося теста. Избегайте зависимостей тестов от среды выполнения программ (это — пути к файлам, операционная система, и так далее).
Разработка через тестирование — это техника разработки ПО, которая вобрала в себя многие годы опыта. Неразумно полностью от всего этого отказываться.
Пирамида тестов, выделяющая три типа тестирования, хотя этой модели уже около 10 лет, всё ещё не потеряла актуальности. Она влияет на стратегии тестирования, применяемые большинством разработчиков. В то же время, в тени этой пирамиды скрывается немало современных методик тестирования. Учитывая серьёзнейшие изменения, произошедшие в мире разработки ПО за последнее десятилетие (микросервисы, облачные и бессерверные технологии), возможно ли, чтобы одна модель тестирования, уже довольно старая, подходила бы для всех приложений? Может быть миру тестирования стоит присмотреться к чему-то новому?
Пожалуйста, не поймите меня неправильно. Сегодня, в 2019 году, пирамида тестов, TDD, модульные тесты — это всё такие же мощные методики тестирования как и раньше, идеально подходящие для множества приложений. Только, как и в случае с любыми другими моделями, несмотря на их полезность, иногда некоторые модели тестирования не подходят для решения определённых задач. Например, представьте себе IoT-приложение, которое, через шину сообщений, реализуемую с помощью чего-то вроде Kafka или RabbitMQ, получает множество сообщений о неких событиях. Затем эти данные попадают в какое-то хранилище, и, в итоге, оказываются в пользовательском интерфейсе для анализа данных. Нужно ли тратить половину бюджета, выделенного на тестирование, на написание модульных тестов для приложения, ядром которого являются задачи интеграции, и которое практически не содержит программной логики? С ростом разнообразия приложений (боты, работа с блокчейном, приложения для голосового помощника Alexa) растут и шансы того, что появятся сценарии, в которых пирамида тестов окажется не лучшим выбором.
Пришло время присмотреться к новым методикам тестирования, познакомиться с новыми типами тестов (о них мы поговорим ниже). При этом не стоит, конечно, забывать о пирамиде тестов и о других классических подходах к тестированию, но, подбирая подходящие тесты, нужно учитывать то, что происходит в реальном мире. Скажем, если оказалось, что что-то не так с API некоего проекта — можно взглянуть на шаблон Consumer-Driven Contracts и написать соответствующие тесты. Тесты стоит диверсифицировать, взяв пример с разумного инвестора, который, проанализировав риски, строит диверсифицированный инвестиционный портфель. Изучив проект, можно понять, в каких его частях могут возникнуть проблемы, выявить которые, используя некую методику тестирования, будет непросто. Найдя подобные участки проекта, можно подстраховаться, написав для них особые тесты.
Обратите внимание на то, что вокруг методологии TDD в мире разработки ПО идут постоянные разговоры. Одни говорят, что TDD нужно использовать всегда и везде, другие придерживаются прямо противоположной точки зрения. По поводу этих крайностей можно сказать лишь о том, что идеи, делящие мир исключительно на белое и чёрное, всегда ошибочны.
Если разработчик не будет присматриваться к современным методикам тестирования — он может пропустить нечто весьма эффективное (вроде фаззинга), почти мгновенно оправдывающее усилия на его внедрение.
Здесь мы предложим вам пару полезных публикаций. Вот материал о тестировании микросервисов. Вот видео о том, что, в сфере Node.js, можно увидеть за границами модульных тестов.
Каждый модульный тест проверяет лишь небольшую часть приложения. Полное покрытие кода такими тестами — дорогое удовольствие. В то же время, сквозное тестирование легко покрывает большие объёмы кода, но оно не так надёжно и медленнее выполняется. Почему бы, выбирая подход к тестированию проекта, не остановиться на чём-то сбалансированном, и писать тесты, которые находятся где-то между модульными и сквозными? Найти такой подход можно, задействовав компонентные тесты. Они недооценены в современной разработке ПО, но они дают программисту лучшее из двух подходов к тестированию: высокую производительность с возможностью применения шаблонов TDD, а также — реалистичное и очень хорошее покрытие тестами кода.
Компонентные тесты направлены на микросервисный «модуль». Они работают с API, не создавая мок-объектов для чего бы то ни было, принадлежащего самому микросервису (например, речь идёт о работе с реальной базой данных, или, по крайней мере, с её копией, хранящейся в оперативной памяти). Они, вместо этого, создают стабы для всего, что находится за пределами модуля (скажем, сюда относятся обращения к другим микросервисам). Поступая так, мы тестируем именно то, что мы разворачиваем, всесторонне исследуем приложение и, в приемлемое время, получаем результаты, которым можно доверять.
Пользуясь исключительно модульными тестами, можно, потратив долгие дни на их написание, обнаружить, что код покрыт тестами лишь процентов на 20.
Вот библиотека supertest, которая позволяет тестировать API, созданные с использованием Express, делая это быстро и покрывая тестами множество уровней абстракции.

Тестирование API, разработанных средствами Express
Предположим, с вашими микросервисами работает множество клиентов, и вы, из соображений совместимости, поддерживаете в рабочем состоянии несколько разных версий сервиса. Затем вы, в коде микросервиса, меняете какое-то поле, и некий важный клиент, который этим полем пользуется, оказывается из-за этого в глубокой печали. Это «уловка-22» мира интеграции: серверу очень сложно учесть ожидания множества клиентов. С другой стороны, клиент ничего протестировать не может, так как порядок релиза продукта контролируется сервером. Для того чтобы революционным образом преобразовать этот процесс, появился шаблон Consumer-Driven Contracts и фреймворк PACT.
Теперь не сервер определяет план собственного тестирования. Вместо этого тесты для сервера определяет клиент. Фреймворк PACT может записывать ожидания клиентов и помещать их туда, где они доступны серверу (отдавая их «брокеру»). Сервер может эти данные взять и проверять с их помощью код, при каждой сборке, с использованием библиотеки PACT, на предмет нарушенных контрактов, то есть ситуаций, в которых не выполняются ожидания клиента. В результате несовпадения между ожиданиями клиента и тем, что реально предоставляет сервер, выявляются очень рано, в ходе сборки проекта, что позволяет разработчику сэкономить время и нервы.
Альтернативами вышеописанного подхода являются изнурительное ручное тестирование или страх развёртывания новой версии сервера.
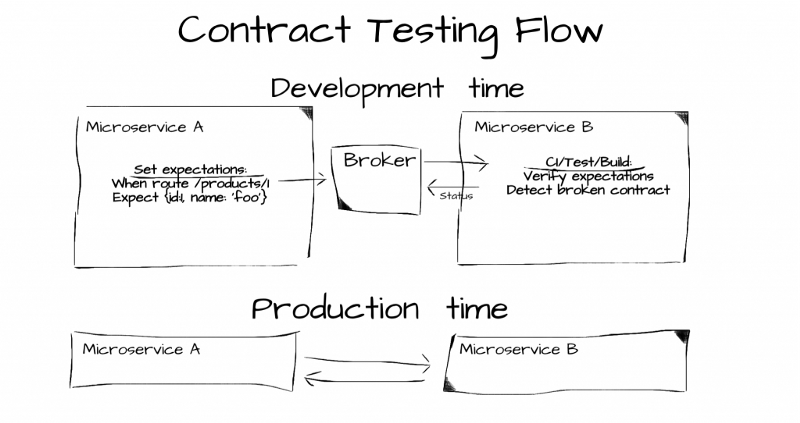
Шаблон Consumer-Driven Contracts
На этапе разработки микросервис А, через брокера, сообщает микросервису B о том, чего он от него ждёт. Микросервис B это учитывает и система без проблем работает в продакшне.
Многие избегают тестировать промежуточное программное обеспечение (middleware) из-за того, что оно представляет собой лишь небольшую часть системы, и из-за того, что для этого нужен рабочий Express-сервер. И та и другая причины не выдерживают критики. Программы промежуточного слоя, хотя и выглядят скромно, влияют на все запросы или на большую их часть. Их можно легко протестировать, представив в виде чистых функций, которые принимают JS-объекты вида
Ошибка в промежуточном программном обеспечении Express означает неправильную обработку всех или большинства запросов.
Вот пример тестирования промежуточного ПО в изоляции без выполнения реальных сетевых вызовов и без задействования всего Express-сервера.
Использование статических инструментов анализа кода полезно в том плане, что это позволяет получить объективные показатели качества кода, понять, в каком направлении его нужно улучшать, и, в результате, усовершенствовать код. Подобные инструменты можно настроить так, чтобы сборка проекта прерывалась бы в том случае, если они обнаруживают в нём что-то нехорошее. Главные преимущества таких инструментов, в сравнении с обычными линтерами, заключаются в том, что они могут исследовать качество кода в масштабах множества файлов (то есть, например, находить дублирующийся код), а также в том, что они умеют выполнять продвинутый анализ кода (например — анализировать его сложность) и учитывать историю работы над ошибками. Вот пара инструментов для статического анализа кода, которые вы можете испытать: SonarQube (более 2600 звёзд на GitHub) и Code Climate (более 1500 звёзд).
В продуктах, код которых отличается низким качеством, всегда есть ошибки. Такой код может отличаться низкой производительностью. Эти проблемы не исправить ни за счёт использования новейших библиотек, ни за счёт наличия у таких продуктов уникальных возможностей.
Вот как выглядит работа с коммерческим анализатором кода Code Climate.
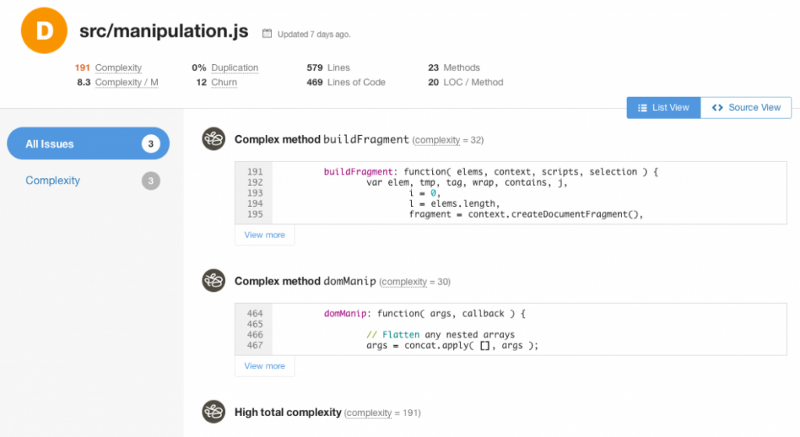
Работа с Code Climate
Тестирование большинства программ заключается в проверке их логики, и того, как они работают с данными. Это может показаться странным, если учесть, что самые серьёзные проблемы, которых по-настоящему сложно избежать, связаны с инфраструктурой. Например, тестировали ли вы когда-нибудь ваше приложение на предмет выяснения того, что случится, если память, доступная процессу, окажется переполненной? А знаете, что произойдёт, если процесс неожиданно завершится? А как быть, если скорость некоего API снизится в два раза?
Для проверки работоспособности систем в случаях возникновения подобных неприятностей в Netflix были разработаны принципы хаос-инженерии. Они нацелены на то, чтобы повысить уровень информированности сообщества разработчиков о проблемах, возникающих в условиях хаоса, на то, чтобы дать программистам фреймворки и инструменты для тестирования приложений на устойчивость к подобным проблемам. Например, вот один из известных инструментов хаос-инженерии — Chaos Monkey. Он случайным образом отключает серверы, что позволяет проверить устойчивость системы к таким сбоям, её способность нормально работать в подобных условиях, и её независимость от отдельно взятого сервера. Есть и похожий инструмент для Kubernetes — kube-monkey. Все эти средства работают на уровне хостинга или платформы, но что если вы хотите проверить ваш проект на устойчивость к хаотическим ошибкам в среде Node.js? Скажем, это могут быть необработанные исключения и неудачно завершённые промисы, а также ситуации, в которых достигается ограничение V8 в виде 1.7 Гб памяти. Сюда же относятся проверки пользовательского интерфейса в случаях частой блокировки цикла событий. Для выполнения подобных испытаний можете взглянуть на мой проект node-chaos, который пока пребывает в альфа-версии.
От хаотических ошибок никто не застрахован, поэтому, не учитывая возможность их возникновения, вы рискуете столкнуться с ними в самый неожиданный момент.
Вот страница npm-пакета chaos-monkey, который позволяет проверять приложения на устойчивость к самым разным странностям среды Node.js.

Пакет chaos-monkey
Сегодня мы привели вашему вниманию почти два десятка советов, касающихся тестирования Node.js-проектов. В частности, мы поговорили об анатомии тестов и о типах тестов. В следующий раз поговорим об оценке эффективности тестов и об анализе качества кода.
Уважаемые читатели! Используете ли вы принципы хаос-инженерии при тестировании своих проектов?

В частности, речь здесь пойдёт о выборе подходящих в конкретной ситуации типов тестов, об их правильном оформлении, об оценке их эффективности, и о том, где именно в CI/CD-цепочках нужно их размещать. Некоторые из приведённых здесь примеров проиллюстрированы с использованием Jest, некоторые — с использованием Mocha. Этот материал, в основном ориентирован не на инструменты, а на методологии тестирования.
> Тестирование Node.js-проектов. Часть 2. Оценка эффективности тестов, непрерывная интеграция и анализ качества кода
?0. Золотое правило: тесты должны быть очень простыми и понятными
Знаете ли вы кого-нибудь — друга, члена семьи, героя фильма, кто всегда заряжен хорошим настроением и всегда готов предложить руку помощи, ничего не требуя взамен? Именно так должны быть спроектированы хорошие тесты. Они должны быть простыми, должны приносить пользу и вызывать положительные эмоции. Этого можно достичь путём тщательного отбора методик, инструментов и целей тестирования. Таких, использование которых оправдывает затраты времени и сил на подготовку и проведение тестов и при этом даёт хорошие результаты. Тестировать нужно только то, что нуждается в проверке, надо стремиться к тому, чтобы тесты были бы простыми и гибкими, а иногда от некоторых тестов можно и отказаться, осмысленно пожертвовав надёжностью проекта ради его простоты и скорости разработки.
Тесты не стоит рассматривать как обычный код приложений. Дело в том, что типичная команда, занимающаяся разработкой некоего проекта, в любом случае, делает всё возможное для поддержки его в рабочем состоянии, то есть стремится к тому, чтобы, скажем, коммерческий продукт работал так, как того ждут его пользователи. В результате такая команда может не очень хорошо отнестись к тому, что ей придётся поддерживать ещё один сложный «проект», представленный набором тестов. Если тесты основного кода разрастаются, оттягивая на себя всё больше внимания и становясь поводом для постоянного беспокойства, то работу над ними либо забросят, либо, пытаясь поддерживать на достойном уровне, отдадут им столько сил и времени, что это замедлит работу над основным проектом.
Поэтому код тестов должен быть как можно более простым, с минимальным количеством зависимостей и уровней абстракции. Тесты должны выглядеть так, чтобы их можно было бы понять с одного взгляда. Большинство рекомендаций, которые мы здесь рассмотрим, произрастают из этого принципа.
Раздел 1. Анатомия тестов
?1. Проектируйте тесты так, чтобы отчёт сообщал бы о том, что тестируется, по какому сценарию, и о том, чего ждут от тестов
Рекомендации
Отчёт о тестировании должен сообщать о том, удовлетворяет ли текущая версия приложения требованиям к нему. Делаться это должно в такой форме, которая будет понятна тем, кто не обязательно должен быть знаком с кодом приложения. Это может быть тестировщик, DevOps-специалист, занимающийся развёртыванием проекта, или сам разработчик, взглянувший на проект через некоторое время после написания его кода. Достичь этого можно в том случае, если при написании тестов ориентироваться на требования к продукту. При таком подходе структуру теста можно представить себе состоящей из трёх частей:
- Что именно тестируется? Например — метод
ProductsService.addNewProduct. - По какому сценарию и в каких обстоятельствах проводится тест? Например, проверяется реакция системы в ситуации, когда методу не передали цену товара.
- Каковы ожидаемые результаты тестирования? Например, в подобной ситуации система отказывается подтверждать добавление в неё нового товара.
Последствия отступления от рекомендаций
Предположим, систему не удалось развернуть и при этом из отчёта о тестировании можно узнать лишь о том, что она не прошла тест, названный
Add product, проверяющий добавление в неё некоего товара. Даст ли это сведения о том, что именно пошло не так?Правильный подход
Сведения о тесте состоят из трёх фрагментов информации.
//1. тестируемый модуль
describe('Products Service', function() {
//2. сценарий
describe('Add new product', function() {
// 3. то, чего ждут от теста
it('When no price is specified, then the product status is pending approval', ()=> {
const newProduct = new ProductService().add(...);
expect(newProduct.status).to.equal('pendingApproval');
});
});
});Правильный подход
Отчёт о тестировании напоминает документ, содержащий изложение требований к продукту.
Вот как это выглядит на разных уровнях.
Документ с требованиями к продукту, именование тестов, результаты тестирования
- Документ с требованиями к продукту может представлять собой либо, собственно, специальный документ, либо может существовать в виде чего-то вроде электронного письма.
- Именуя тесты, описывая цель тестирования, его сценарий и ожидаемые результаты, нужно придерживаться того языка, который применяется при формулировании требований к продукту. Это поможет сопоставлять код тестов и требования к продукту.
- Результаты тестирования должны быть понятны даже тем, кто с кодом приложения не знаком или основательно его забыл. Это — тестировщики, DevOps-специалисты, разработчики, возвращающиеся к работе с кодом через несколько месяцев после его написания.
?2. Описывайте то, чего ожидают от тестов, на языке продукта: используйте утверждения в стиле BDD
Рекомендации
Разработка тестов в декларативном стиле позволяет тому, кто с ними работает, мгновенно схватывать их суть. Если тесты пишут, используя императивный подход, они оказываются наполненными условными конструкциями, которые значительно затрудняют их понимание. Следуя этому принципу, ожидания нужно описывать на языке, близком к обычному. В декларативном BDD-стиле используются конструкции
expect или should, а не некий особый код собственной разработки. Если в Chai или Jest нет необходимых утверждений, и при этом оказывается, что необходимость в подобных утверждениях возникает часто, рассмотрите возможность добавления новых «проверок» в Jest или написания собственных плагинов для Chai.Последствия отступления от рекомендаций
Если не следовать вышеописанным рекомендациям, всё закончится тем, что члены команды разработчиков будут писать меньше тестов и пропускать особо досаждающие им проверки, используя метод
.skip().Неправильный подход
Читателю этого теста придётся полностью просмотреть довольно длинный императивный код только для того, чтобы понять то, что именно проверяется в тесте.
it("When asking for an admin, ensure only ordered admins in results" , ()={
//предположим, что мы добавили тут двух администраторов — "admin1" и "admin2", и пользователя "user1"
const allAdmins = getUsers({adminOnly:true});
const admin1Found, adming2Found = false;
allAdmins.forEach(aSingleUser => {
if(aSingleUser === "user1"){
assert.notEqual(aSingleUser, "user1", "A user was found and not admin");
}
if(aSingleUser==="admin1"){
admin1Found = true;
}
if(aSingleUser==="admin2"){
admin2Found = true;
}
});
if(!admin1Found || !admin2Found ){
throw new Error("Not all admins were returned");
}
});Правильный подход
Понять этот тест можно буквально с одного взгляда.
it("When asking for an admin, ensure only ordered admins in results" , ()={
//предполагается, что тут добавлены два администратора
const allAdmins = getUsers({adminOnly:true});
expect(allAdmins).to.include.ordered.members(["admin1" , "admin2"])
.but.not.include.ordered.members(["user1"]);
});?3. Выполняйте линтинг кода тестов с помощью специальных плагинов
Рекомендации
Существует набор плагинов для ESLint, разработанный специально для анализа кода тестов и для нахождения проблем в таком коде. Например, плагин eslint-plugin-mocha выдаёт предупреждения в том случае, если тест написан на глобальном уровне (а не является потомком
describe()), или если тесты оказываются пропущенными, что может дать ложные надежды на то, что все тесты оказываются пройденными. Плагин eslint-plugin-jest работает похожим образом, например, предупреждая о тестах, у которых нет утверждений, то есть о таких, которые ничего не проверяют.Последствия отступления от рекомендаций
Разработчик будет счастлив, видя, что код покрыт тестами на 90% и при этом 100% тестов проходят успешно. Однако в таком состоянии он будет пребывать лишь до тех пор, пока не окажется, что многие тесты, на самом деле, ничего не проверяют, а некоторые тестовые сценарии просто пропускаются. Остаётся лишь надеяться, что никто не станет разворачивать в продакшне проекты, которые «протестированы» подобным образом.
Неправильный подход
Тестовый сценарий полон ошибок, которые, к счастью, можно выявить с помощью линтера.
describe("Too short description", () => {
const userToken = userService.getDefaultToken() // *error:no-setup-in-describe, use hooks (sparingly) instead
it("Some description", () => {});//* error: valid-test-description. Must include the word "Should" + at least 5 words
});
it.skip("Test name", () => {// *error:no-skipped-tests, error:error:no-global-tests. Put tests only under describe or suite
expect("somevalue"); // error:no-assert
});
it("Test name", () => {*//error:no-identical-title. Assign unique titles to tests
});?4. Придерживайтесь метода «чёрного ящика» — тестируйте только общедоступные методы
Рекомендации
Тестирование неких внутренних механизмов кода означает значительное повышение нагрузки на разработчиков и не даёт практически никаких выгод. Если некое API выдаёт правильные результаты, стоит ли тратить несколько часов на тестирование его внутренних механизмов и потом ещё поддерживать эти тесты, которые очень легко «ломаются», в актуальном состоянии? При проверке общедоступных методов их внутренняя реализация, хотя и неявно, но тоже проверяется. Подобный тест выдаст ошибку в том случае, если в системе возникнет некая проблема, выражающаяся в выдаче неправильных данных. Этот подход ещё называют «поведенческим тестированием». С другой стороны, тестируя внутренние механизмы некоего API (то есть — используя методику «белого ящика»), разработчик сосредотачивается на мелких деталях реализации, а не на конечном результате работы кода. Тесты, проверяющие подобные тонкости, могут начать выдавать ошибки, например, после небольшого рефакторинга кода, даже несмотря на то, что система продолжает выдавать верные результаты. В результате такой подход значительно повышает нагрузку на программиста, связанную с поддержкой кода тестов.
Последствия отступления от рекомендаций
Тесты, которыми пытаются охватить внутренние механизмы некоей системы, ведут себя как мальчик-пастух из басни, который сзывал крестьян криками «Помогите! Волк!», когда никакого волка поблизости не было. Люди сбегались на помощь лишь для того, чтобы обнаружить, что их обманули. А когда волк и правда появился, никто уже на помощь не пришёл. Такие тесты выдают ложноположительные результаты, например, в тех случаях, когда меняются имена каких-то внутренних переменных. В результате неудивительно то, что тот, кто проводит эти тесты, скоро начинает игнорировать их «крики», что, в конечном итоге, приводит к тому, что однажды незамеченной может оказаться настоящая серьёзная ошибка.
Неправильный подход
Этот тест проверяет внутренние механизмы класса без особой причины для таких проверок.
class ProductService{
//Этот метод используется лишь внутри класса
//Изменение его имени приведёт к тому, что тест сообщит об ошибке
calculateVAT(priceWithoutVAT){
return {finalPrice: priceWithoutVAT * 1.2};
//Изменение формата результата или имени свойства объекта приведут к отказу теста
}
//Общедоступный метод
getPrice(productId){
const desiredProduct= DB.getProduct(productId);
finalPrice = this.calculateVATAdd(desiredProduct.price).finalPrice;
}
}
it("White-box test: When the internal methods get 0 vat, it return 0 response", async () => {
//Система не должна позволять пользователям рассчитывать показатель VAT, она лишь должна выводить итоговую стоимость. Но мы, несмотря на это, тестируем тут внутренние механизмы класса
expect(new ProductService().calculateVATAdd(0).finalPrice).to.equal(0);
});?5. Выбирайте подходящие объекты-дублёры: избегайте моков, отдавая предпочтение стабам и шпионам
Рекомендации
Использование объектов-дублёров (test doubles) при тестировании — это необходимое зло, так как они связаны с внутренними механизмами приложения. Без некоторых из них прямо-таки невозможно обойтись. Вот полезный материал на эту тему. Однако различные подходы к использованию подобных объектов нельзя назвать равнозначными. Так, некоторые из них — стабы (stub) и шпионы (spy), направлены на тестирование требований к продукту, но, в виде неизбежного побочного эффекта, они вынуждены слегка затрагивать внутренние механизмы этого продукта. Моки же (mock), с другой стороны, нацелены на тестирование внутренних механизмов проекта. Поэтому их использование ведёт к огромной ненужной нагрузке на программистов, о которой мы говорили выше, предлагая придерживаться при написании тестов методики «чёрного ящика».
Прежде чем использовать объекты-дублёры, задайте себе один простой вопрос: «Использую ли я их для проверки функционала, который описан, или мог бы быть описан в технических требованиях к проекту?». Если ответ на этот вопрос отрицателен — это может означать, что вы собираетесь тестировать продукт, используя подход «белого ящика», о недостатках которого мы уже говорили.
Например, если вы хотите узнать, правильно ли ваше приложение работает в ситуации, когда недоступен платёжный сервис, вы можете застабить этот сервис и сделать так, чтобы приложение получило бы нечто, указывающее на отсутствие ответа. Это позволит проверить реакцию системы на подобную ситуацию, узнать, ведёт ли она себя правильно. В ходе подобного испытания проводится проверка поведения, или ответа, или результата работы приложения в определённых условиях. В этой ситуации можно воспользоваться шпионом для проверки того, было ли, при обнаружении падения платёжного сервиса, отправлено некое электронное письмо. Это, опять же, будет проверкой поведения системы в определённой ситуации, что, наверняка, зафиксировано в технических требованиях к ней, скажем, в следующем виде: «Отправить электронное письмо администратору в том случае, если платёж не проходит». С другой стороны, если использовать мок-объект для представления платёжного сервиса и проверить работу при обращении к нему с передачей ему того, что он ожидает, то речь будет идти о тестировании внутренних механизмов, которые не имеют прямого отношения к функционалу приложения, и, вполне возможно, могут часто меняться.
Последствия отступления от рекомендаций
При любом рефакторинге кода придётся искать все моки, подвергая рефакторингу и их код. В результате поддержка тестов превратится в тяжкое бремя, делая их врагами разработчика, а не его друзьями.
Неправильный подход
В этом примере показан мок-объект, ориентированный на тестирование внутренних механизмов приложения.
it("When a valid product is about to be deleted, ensure data access DAL was called once, with the right product and right config", async () => {
//Предположим, что мы уже добавили товар
const dataAccessMock = sinon.mock(DAL);
//Это плохо, так как мы тут тестируем внутренние механизмы системы
dataAccessMock.expects("deleteProduct").once().withArgs(DBConfig, theProductWeJustAdded, true, false);
new ProductService().deletePrice(theProductWeJustAdded);
mock.verify();
});Правильный подход
Шпионы нацелены на испытание систем на соответствие требований к ним, но, в виде побочного эффекта, неизбежно затрагивают внутренние механизмы систем.
it("When a valid product is about to be deleted, ensure an email is sent", async () => {
//Предположим, что мы уже добавили товар
const spy = sinon.spy(Emailer.prototype, "sendEmail");
new ProductService().deletePrice(theProductWeJustAdded);
//Это нормальный подход. Мы имеем дело с внутренними механизмами системы? Да, но лишь в виде побочного эффекта испытания системы на соответствие техническим требованиям к ней (отправка электронного письма)
});?6. В ходе тестирования используйте реалистичные входные данные, не ограничиваясь чем-то вроде «foo»
Рекомендации
Часто ошибки в продакшне проявляются при весьма специфическом и даже удивительном стечении обстоятельств. А это значит, что чем ближе к реальности входные данные, используемые в ходе тестирования, тем выше вероятность раннего обнаружения ошибок. Используйте, для генерирования данных, напоминающих реальные, специализированные библиотеки, такие, как Faker. Например, такие библиотеки генерируют случайные, но реалистичные номера телефонов, имена пользователей, номера банковских карт, названия компаний и даже тексты в духе «lorem ipsum». Более того, рассмотрите возможность использования в тестах данных, взятых из продакшн-окружения. Если же вы хотите поднять подобные тесты на ещё более высокий уровень — обратитесь к нашей следующей рекомендации, посвящённой тестированию, основанному на проверке свойств.
Последствия отступления от рекомендаций
При тестировании проекта в ходе его разработки все тесты могут оказаться пройденными лишь в том случае, если при их проведении используются нереалистичные данные наподобие строк «foo». А вот в продакшне система даст сбой в ситуации, когда хакер передаст ей что-то вроде
@3e2ddsf . ##’ 1 fdsfds . fds432 AAAA.Неправильный подход
Система успешно проходит эти тесты лишь потому что в них используются нереальные данные.
const addProduct = (name, price) =>{
const productNameRegexNoSpace = /^\S*$/;//пробелы запрещены
if(!productNameRegexNoSpace.test(name))
return false;//Сюда мы, из-за нереалистичных входных данных, не доберёмся.
//Тут будет какой-то код
return true;
};
it("Wrong: When adding new product with valid properties, get successful confirmation", async () => {
//Строка "Foo", используемая во всех тестах, не позволит проверить ситуацию, в которой возвращается false
const addProductResult = addProduct("Foo", 5);
expect(addProductResult).to.be.true;
//Ненадёжный результат: операция завершается успешно лишь из-за того, что мы
//не использовали в тесте длинные имена товаров с пробелами
});Правильный подход
Здесь используются рандомизированные данные, похожие на настоящие.
it("Better: When adding new valid product, get successful confirmation", async () => {
const addProductResult = addProduct(faker.commerce.productName(), faker.random.number());
//Сгенерированы следующие входные данные: {'Sleek Cotton Computer', 85481}
expect(addProductResult).to.be.true;
//Тест не пройден, так как наши входные данные привели к срабатыванию механизма, нарушающего нормальную работу системы.
//Мы нашли ошибку на этапе разработки, а не в продакшне!
});?7. Испытывайте системы с использованием множества комбинаций входных данных, применяя тестирование, основанное на проверке свойств
Рекомендации
Обычно в тестах используют небольшие наборы входных данных. Даже если они и напоминают реальные данные (мы говорили об этом в предыдущем разделе), такие тесты покрывают лишь весьма ограниченное количество возможных комбинаций входов исследуемой сущности. Например, это может выглядеть так:
(method(‘’, true, 1), method("string" , false" , 0)). Проблема заключается в том, что в продакшне API, которое вызывается с пятью параметрами, может получить на вход тысячи различных вариантов их сочетаний, один из которых способен привести к сбою (тут уместно будет вспомнить о фаззинге). Что если вы могли бы написать единственный тест, который автоматически проверяет некий метод на 1000 комбинаций его входов и выясняет, на какие из них этот метод реагирует неправильно? Тестирование, основанное на проверке свойств — это именно то, что нам в подобной ситуации пригодится. А именно, в ходе такого тестирования модуль проверяют, вызывая его со всеми возможными комбинациями входных данных, что увеличивает вероятность нахождения в нём ошибки. Предположим, у нас имеется метод addNewProduct(id, name, isDiscount), и библиотека, выполняющая тестирование, вызывает его с множеством комбинаций параметров числового, строкового и логического типа, например — (1, "iPhone", false), (2, "Galaxy", true). Проводить тестирование, основанное на проверке свойств, можно используя обычную среду для выполнения тестов (Mocha, Jest, и так далее) и применяя вместе с ней специализированные библиотеки вроде js-verify или testcheck (у этой библиотеки имеется очень хорошая документация).Последствия отступления от рекомендаций
Разработчик, неосознанно, выбирает такие тестовые данные, которые покрывают лишь те участки кода, которые работают правильно. К сожалению, это снижает эффективность тестирования как средства для обнаружения ошибок.
Правильный подход
Тестирование множества вариантов входных данных с использованием библиотеки mocha-testcheck.
require('mocha-testcheck').install();
const {expect} = require('chai');
const faker = require('faker');
describe('Product service', () => {
describe('Adding new', () => {
//это выполнится 100 раз с использованием различных случайных свойств
check.it('Add new product with random yet valid properties, always successful',
gen.int, gen.string, (id, name) => {
expect(addNewProduct(id, name).status).to.equal('approved');
});
})
});?8. Стремитесь к тому, чтобы код теста был бы самодостаточным, минимизируя внешние вспомогательные средства и абстракции
Рекомендации
Вероятно, сейчас уже очевидно, что я являюсь приверженцем предельно простых тестов. Дело в том, что в противном случае команде разработчиков некоего проекта, фактически, приходится заниматься ещё одним проектом. Для того чтобы понять его код, им приходится тратить ценное время, которого у них не так уж и много. Тут очень хорошо написано об этом явлении: «Качественный продакшн-код — это код хорошо продуманный, а качественный код тестов — это код совершенно понятный… Когда вы пишете тест — думайте о том, кто увидит выведенное им сообщение об ошибке. Этот человек не хотел бы, для того, чтобы понять причины ошибки, читать код всего тестового набора или код дерева наследования утилит, используемых для тестирования».
Для того чтобы читатель мог бы понять тест, не покидая его код, минимизируйте использование утилит, хуков, или любых внешних механизмов при выполнении теста. Если для того, чтобы это сделать, понадобится слишком часто прибегать к операциям копирования и вставки кода, можно остановиться на одном внешнем вспомогательном механизме, использование которого не нарушит понятности теста. Но, если число подобных механизмов будет расти, код теста будет терять понятность.
Последствия отступления от рекомендаций
Вы обнаружили, что в ваших тестах применяется 4 вспомогательных модуля, 2 из которых унаследованы от базовых утилит, много кода для настройки тестовой среды и несколько хуков? Принимайте поздравления! Теперь вам надо будет поддерживать ещё один непростой проект, а если всё и дальше будет продолжаться в том же духе, то вы скоро начнёте писать тесты для тестов.
Неправильный подход
Взгляните на эту интересную и запутанную структуру. Ясен ли вам смысл происходящего без обращения к коду внешних зависимостей?
test("When getting orders report, get the existing orders", () => {
const queryObject = QueryHelpers.getQueryObject(config.DBInstanceURL);
const reportConfiguration = ReportHelpers.getReportConfig();//Что это за конфигурация? Из кода теста это неясно
userHelpers.prepareQueryPermissions(reportConfiguration);//Что здесь происходит? Без внешних источников этого не понять
const result = queryObject.query(reportConfiguration);
assertThatReportIsValid();//Снова неясный момент, опять придётся уходить из кода теста и читать об этом где-то ещё
expect(result).to.be.an('array').that.does.include({id:1, productd:2, orderStatus:"approved"});
//откуда мы знаем о существовании этого заказа? придётся покинуть код теста и это выяснить
})Правильный подход
Вот пример теста, понять который можно без обращения к стороннему коду.
it("When getting orders report, get the existing orders", () => {
//Хочется надеяться, что код этого текста понятен сам по себе
const orderWeJustAdded = ordersTestHelpers.addRandomNewOrder();
const queryObject = newQueryObject(config.DBInstanceURL, queryOptions.deep, useCache:false);
const result = queryObject.query(config.adminUserToken, reports.orders, pageSize:200);
expect(result).to.be.an('array').that.does.include(orderWeJustAdded);
})?9. Избегайте использования глобальных настроек и заранее подготовленных данных: пусть каждый тест пользуется собственными данными
Рекомендации
Если следовать золотому правилу тестирования, изложенному в нулевом пункте этого материала, то каждый тест должен, например, самостоятельно добавлять в базу данных некие записи и пользоваться только ими. Это поможет предотвратить проблему связанности разных тестов и позволит легко анализировать ход выполнения отдельных тестов. В реальности тестировщики часто нарушают это правило, заполняя базы данных информацией до запуска тестов (это ещё называют настройкой тестового окружения) ради улучшения производительности тестирования. Хотя производительность — это важно, проблемы производительности поддаются решению (взгляните на раздел, где речь идёт о компонентном тестировании). А вот вопросы сложности тестов — это уже гораздо серьёзнее, и именно ими и нужно, по большей части, руководствоваться, принимая различные решения. На практике это означает, что нужно сделать так, чтобы каждый тест в явном виде добавлял бы в базу данных необходимые ему записи и работал бы только с ними. Если на первый план выходит производительность — тогда можно найти разумный компромисс, скажем, централизованно готовя данные, с которыми будут работать только те тесты, которые эти данные не меняют (то есть только те, которые, например, выполняют к базам данных лишь запросы на чтение).
Последствия отступления от рекомендаций
Предположим, несколько тестов дало сбой. Развёртывание проекта отменено. Команде нужно будет потратить несколько часов на выяснение причин происходящего. Этими причинами могут быть ошибки в коде. На самом же деле оказывается, что сбои тестов вызваны тем, что некоторые из них меняют одни и те же заранее заданные данные, а другие об этом ничего не знают.
Неправильный подход
Тесты в этом примере не являются независимыми. Они полагаются на некий глобальный хук, пользуясь общей базой данных.
before(() => {
//добавляем сведения об объектах и администраторах в БД. Где находятся данные? Где-то снаружи, например - в некоем json-файле.
await DB.AddSeedDataFromJson('seed.json');
});
it("When updating site name, get successful confirmation", async () => {
//Мне известно, что объект, называемый "Portal", существует, так как я видел его в файле с начальными данными
const siteToUpdate = await SiteService.getSiteByName("Portal");
const updateNameResult = await SiteService.changeName(siteToUpdate, "newName");
expect(updateNameResult).to.be(true);
});
it("When querying by site name, get the right site", async () => {
//Мне известно, что объект, называемый "Portal", существует, так как я видел его в файле с начальными данными
const siteToCheck = await SiteService.getSiteByName("Portal");
expect(siteToCheck.name).to.be.equal("Portal"); //Сбой! Предыдущий тест поменял название объекта :[
});Правильный подход
Мы можем не покидать пределы теста, организовав всё так, чтобы каждый тест работал бы с собственным набором данных.
it("When updating site name, get successful confirmation", async () => {
//тест добавляет в базу новые записи и работает только с ними
const siteUnderTest = await SiteService.addSite({
name: "siteForUpdateTest"
});
const updateNameResult = await SiteService.changeName(siteUnderTest, "newName");
expect(updateNameResult).to.be(true);
});?10. Не перехватывайте в тесте исключения, возникающие в коде. Обрабатывайте их с помощью конструкции expect
Рекомендации
Если нужно проверить код на предмет выбрасывания им исключений, может показаться, что правильно будет использовать конструкцию
try-catch-finally и проверить некое утверждение при входе в блок catch. Результат такого подхода, показанный ниже, выражается в виде неуклюжего и слишком длинного кода теста, читая который непросто понять цель теста и ожидаемый результат.Более изящная альтернатива такому подходу заключается в использовании особого однострочного утверждения Chai, которое выглядит как
expect(method).to.throw. Подобное есть и в Jest: expect(method).toThrow(). Используя подобные конструкции совершенно необходимо проверить свойство объекта ошибки, указывающее на её тип. В противном случае, если тип ошибок не проверять, тест просто покажет сообщение об ошибке без разъяснения его смысла.Последствия отступления от рекомендаций
Если тесты обрабатывают все исключения, возникающие в коде, одинаково, из отчёта о тестировании может быть очень непросто понять причины неправильного поведения программы.
Неправильный подход
Вот длинный код теста, в котором сделана попытка проверки выдачи кодом исключений с помощью конструкции
try-catch.it("When no product name, it throws error 400", async() => {
let errorWeExceptFor = null;
try {
const result = await addNewProduct({name:'nest'});}
catch (error) {
expect(error.code).to.equal('InvalidInput');
errorWeExceptFor = error;
}
expect(errorWeExceptFor).not.to.be.null;
//Если это утверждение не выполнится, то в отчёте о проведении теста будет сказано
//лишь о том, что некое значение равняется null, и ни слова о выброшенном исключении
});Правильный подход
Вот как использование конструкции
expect позволяет написать тест, отчёт которого будет понятен даже специалисту, далёкому от работы с кодом приложения.it.only("When no product name, it throws error 400", async() => {
expect(addNewProduct)).to.eventually.throw(AppError).with.property('code', "InvalidInput");
});?11. Назначайте тестам теги, указывающие на их особенности
Рекомендации
Разные тесты должны выполняться в различных ситуациях. Например, минимальный набор тестов для выявления очевидных ошибок (smoke test), не подразумевающий работу с подсистемами ввода-вывода, стоит запускать каждый раз, когда разработчик сохраняет или коммитит файл. А вот полное сквозное тестирование обычно выполняют при отправке нового пулл-запроса в репозиторий. Выбор тестов, которые должны выполняться в том или ином сценарии, можно организовать на основе назначаемых им тегов, представляющих собой ключевые слова наподобие
#cold, #api, #sanity. В результате можно будет отбирать нужные тесты средствами используемой системы автоматического запуска тестов и выполнять в определённых ситуациях только их. Например, в Mocha для отбора тестов можно воспользоваться флагом -g (--grep).Последствия отступления от рекомендаций
Если представить себе, что каждый раз, когда разработчики вносят небольшое изменение в код, выполняется куча тестов, в ходе которых производятся десятки запросов к базе данных, то окажется, что проводиться это тестирование будет крайне медленно. В результате разработчики постараются от таких тестов избавиться.
Правильный подход
Тег
#cold-test позволяет системе запуска тестов отобрать только те из них, на выполнение которых много времени не требуется. В данном случае такой тег указывает на то, что тест работает быстро и не пользуется подсистемой ввода-вывода, а значит, вызывать его можно очень часто — буквально в процессе ввода кода разработчиком.//этот тест очень быстр (в частности, не взаимодействует с БД), поэтому мы назначаем ему
//соответствующий тег, что позволяет пользователю или системе выполнения тестов
//вызывать его часто
describe('Order service', function() {
describe('Add new order #cold-test #sanity', function() {
it('Scenario - no currency was supplied. Expectation - Use the default currency #sanity', function() {
//какой-то код
});
});
});?12. Не забывайте о других правилах подготовки качественных тестов
Рекомендации
В этом материале даются рекомендации по тестированию, относящиеся к Node.js-проектам. Здесь же представлены рекомендации, широко известные, но непосредственно к Node.js не относящиеся.
Полезно изучить и опробовать принципы TDD — они весьма ценны во многих ситуациях, хотя вполне может оказаться так, что в ваш стиль работы над проектами они не вписываются. Это не должно вас расстраивать, так как подходят они далеко не всем. Рассмотрите возможность написания тестов до написания кода, для которого они предназначены, работая в стиле Red-Green-Refactor. Следите за тем, чтобы один тест проверял лишь что-то одно, а если вы обнаруживаете в программе ошибку, то, перед её исправлением, напишите тест для её выявления, что позволит находить такие же ошибки и в будущем. Следуйте правилу, в соответствии с которым рабочий код не пишут без неудачно завершившегося теста. Избегайте зависимостей тестов от среды выполнения программ (это — пути к файлам, операционная система, и так далее).
Последствия отступления от рекомендаций
Разработка через тестирование — это техника разработки ПО, которая вобрала в себя многие годы опыта. Неразумно полностью от всего этого отказываться.
Раздел 2. Типы тестов
?13. Расширьте набор используемых вами методик тестирования, выйдя за пределы модульных тестов и пирамиды тестов
Рекомендации
Пирамида тестов, выделяющая три типа тестирования, хотя этой модели уже около 10 лет, всё ещё не потеряла актуальности. Она влияет на стратегии тестирования, применяемые большинством разработчиков. В то же время, в тени этой пирамиды скрывается немало современных методик тестирования. Учитывая серьёзнейшие изменения, произошедшие в мире разработки ПО за последнее десятилетие (микросервисы, облачные и бессерверные технологии), возможно ли, чтобы одна модель тестирования, уже довольно старая, подходила бы для всех приложений? Может быть миру тестирования стоит присмотреться к чему-то новому?
Пожалуйста, не поймите меня неправильно. Сегодня, в 2019 году, пирамида тестов, TDD, модульные тесты — это всё такие же мощные методики тестирования как и раньше, идеально подходящие для множества приложений. Только, как и в случае с любыми другими моделями, несмотря на их полезность, иногда некоторые модели тестирования не подходят для решения определённых задач. Например, представьте себе IoT-приложение, которое, через шину сообщений, реализуемую с помощью чего-то вроде Kafka или RabbitMQ, получает множество сообщений о неких событиях. Затем эти данные попадают в какое-то хранилище, и, в итоге, оказываются в пользовательском интерфейсе для анализа данных. Нужно ли тратить половину бюджета, выделенного на тестирование, на написание модульных тестов для приложения, ядром которого являются задачи интеграции, и которое практически не содержит программной логики? С ростом разнообразия приложений (боты, работа с блокчейном, приложения для голосового помощника Alexa) растут и шансы того, что появятся сценарии, в которых пирамида тестов окажется не лучшим выбором.
Пришло время присмотреться к новым методикам тестирования, познакомиться с новыми типами тестов (о них мы поговорим ниже). При этом не стоит, конечно, забывать о пирамиде тестов и о других классических подходах к тестированию, но, подбирая подходящие тесты, нужно учитывать то, что происходит в реальном мире. Скажем, если оказалось, что что-то не так с API некоего проекта — можно взглянуть на шаблон Consumer-Driven Contracts и написать соответствующие тесты. Тесты стоит диверсифицировать, взяв пример с разумного инвестора, который, проанализировав риски, строит диверсифицированный инвестиционный портфель. Изучив проект, можно понять, в каких его частях могут возникнуть проблемы, выявить которые, используя некую методику тестирования, будет непросто. Найдя подобные участки проекта, можно подстраховаться, написав для них особые тесты.
Обратите внимание на то, что вокруг методологии TDD в мире разработки ПО идут постоянные разговоры. Одни говорят, что TDD нужно использовать всегда и везде, другие придерживаются прямо противоположной точки зрения. По поводу этих крайностей можно сказать лишь о том, что идеи, делящие мир исключительно на белое и чёрное, всегда ошибочны.
Последствия отступления от рекомендаций
Если разработчик не будет присматриваться к современным методикам тестирования — он может пропустить нечто весьма эффективное (вроде фаззинга), почти мгновенно оправдывающее усилия на его внедрение.
Правильный подход
Здесь мы предложим вам пару полезных публикаций. Вот материал о тестировании микросервисов. Вот видео о том, что, в сфере Node.js, можно увидеть за границами модульных тестов.
?14. Возможно, вам стоит обратить внимание на компонентное тестирование
Рекомендации
Каждый модульный тест проверяет лишь небольшую часть приложения. Полное покрытие кода такими тестами — дорогое удовольствие. В то же время, сквозное тестирование легко покрывает большие объёмы кода, но оно не так надёжно и медленнее выполняется. Почему бы, выбирая подход к тестированию проекта, не остановиться на чём-то сбалансированном, и писать тесты, которые находятся где-то между модульными и сквозными? Найти такой подход можно, задействовав компонентные тесты. Они недооценены в современной разработке ПО, но они дают программисту лучшее из двух подходов к тестированию: высокую производительность с возможностью применения шаблонов TDD, а также — реалистичное и очень хорошее покрытие тестами кода.
Компонентные тесты направлены на микросервисный «модуль». Они работают с API, не создавая мок-объектов для чего бы то ни было, принадлежащего самому микросервису (например, речь идёт о работе с реальной базой данных, или, по крайней мере, с её копией, хранящейся в оперативной памяти). Они, вместо этого, создают стабы для всего, что находится за пределами модуля (скажем, сюда относятся обращения к другим микросервисам). Поступая так, мы тестируем именно то, что мы разворачиваем, всесторонне исследуем приложение и, в приемлемое время, получаем результаты, которым можно доверять.
Последствия отступления от рекомендаций
Пользуясь исключительно модульными тестами, можно, потратив долгие дни на их написание, обнаружить, что код покрыт тестами лишь процентов на 20.
Правильный подход
Вот библиотека supertest, которая позволяет тестировать API, созданные с использованием Express, делая это быстро и покрывая тестами множество уровней абстракции.
Тестирование API, разработанных средствами Express
?15. Для того чтобы быть уверенным в том, что новые релизы проекта не нарушают работу API, используйте шаблон Consumer-Driven Contracts
Рекомендации
Предположим, с вашими микросервисами работает множество клиентов, и вы, из соображений совместимости, поддерживаете в рабочем состоянии несколько разных версий сервиса. Затем вы, в коде микросервиса, меняете какое-то поле, и некий важный клиент, который этим полем пользуется, оказывается из-за этого в глубокой печали. Это «уловка-22» мира интеграции: серверу очень сложно учесть ожидания множества клиентов. С другой стороны, клиент ничего протестировать не может, так как порядок релиза продукта контролируется сервером. Для того чтобы революционным образом преобразовать этот процесс, появился шаблон Consumer-Driven Contracts и фреймворк PACT.
Теперь не сервер определяет план собственного тестирования. Вместо этого тесты для сервера определяет клиент. Фреймворк PACT может записывать ожидания клиентов и помещать их туда, где они доступны серверу (отдавая их «брокеру»). Сервер может эти данные взять и проверять с их помощью код, при каждой сборке, с использованием библиотеки PACT, на предмет нарушенных контрактов, то есть ситуаций, в которых не выполняются ожидания клиента. В результате несовпадения между ожиданиями клиента и тем, что реально предоставляет сервер, выявляются очень рано, в ходе сборки проекта, что позволяет разработчику сэкономить время и нервы.
Последствия отступления от рекомендаций
Альтернативами вышеописанного подхода являются изнурительное ручное тестирование или страх развёртывания новой версии сервера.
Правильный подход
Шаблон Consumer-Driven Contracts
На этапе разработки микросервис А, через брокера, сообщает микросервису B о том, чего он от него ждёт. Микросервис B это учитывает и система без проблем работает в продакшне.
?16. Тестируйте промежуточное ПО в изоляции
Рекомендации
Многие избегают тестировать промежуточное программное обеспечение (middleware) из-за того, что оно представляет собой лишь небольшую часть системы, и из-за того, что для этого нужен рабочий Express-сервер. И та и другая причины не выдерживают критики. Программы промежуточного слоя, хотя и выглядят скромно, влияют на все запросы или на большую их часть. Их можно легко протестировать, представив в виде чистых функций, которые принимают JS-объекты вида
{req,res}. Для того чтобы протестировать подобную функцию, её нужно лишь вызвать и «пошпионить» (например, используя Sinon) за тем, что она делает с объектами {req,res}. Сделав это, можно убедиться в том, что она работает правильно, или найти ошибки. Библиотека node-mock-http идёт ещё дальше, и, вместе с наблюдением за поведением функций, ещё и позволяет работать с объектами запроса и ответа. Например, с её помощью можно проверить, соответствует ли ожиданиям HTTP-статус, установленный у объекта-ответа.Последствия отступления от рекомендаций
Ошибка в промежуточном программном обеспечении Express означает неправильную обработку всех или большинства запросов.
Правильный подход
Вот пример тестирования промежуточного ПО в изоляции без выполнения реальных сетевых вызовов и без задействования всего Express-сервера.
//Промежуточное ПО, которое мы хотим протестировать
const unitUnderTest = require('./middleware')
const httpMocks = require('node-mocks-http');
//Тут используется Jest, то же самое в Mocha реализуется с помощью describe() и it()
test('A request without authentication header, should return http status 403', () => {
const request = httpMocks.createRequest({
method: 'GET',
url: '/user/42',
headers: {
authentication: ''
}
});
const response = httpMocks.createResponse();
unitUnderTest(request, response);
expect(response.statusCode).toBe(403);
});?17. Исследуйте код и выполняйте рефакторинг с использованием статических анализаторов
Рекомендации
Использование статических инструментов анализа кода полезно в том плане, что это позволяет получить объективные показатели качества кода, понять, в каком направлении его нужно улучшать, и, в результате, усовершенствовать код. Подобные инструменты можно настроить так, чтобы сборка проекта прерывалась бы в том случае, если они обнаруживают в нём что-то нехорошее. Главные преимущества таких инструментов, в сравнении с обычными линтерами, заключаются в том, что они могут исследовать качество кода в масштабах множества файлов (то есть, например, находить дублирующийся код), а также в том, что они умеют выполнять продвинутый анализ кода (например — анализировать его сложность) и учитывать историю работы над ошибками. Вот пара инструментов для статического анализа кода, которые вы можете испытать: SonarQube (более 2600 звёзд на GitHub) и Code Climate (более 1500 звёзд).
Последствия отступления от рекомендаций
В продуктах, код которых отличается низким качеством, всегда есть ошибки. Такой код может отличаться низкой производительностью. Эти проблемы не исправить ни за счёт использования новейших библиотек, ни за счёт наличия у таких продуктов уникальных возможностей.
Правильный подход
Вот как выглядит работа с коммерческим анализатором кода Code Climate.
Работа с Code Climate
?18. Проверьте готовность проекта к хаосу, который может царить в среде Node.js
Рекомендации
Тестирование большинства программ заключается в проверке их логики, и того, как они работают с данными. Это может показаться странным, если учесть, что самые серьёзные проблемы, которых по-настоящему сложно избежать, связаны с инфраструктурой. Например, тестировали ли вы когда-нибудь ваше приложение на предмет выяснения того, что случится, если память, доступная процессу, окажется переполненной? А знаете, что произойдёт, если процесс неожиданно завершится? А как быть, если скорость некоего API снизится в два раза?
Для проверки работоспособности систем в случаях возникновения подобных неприятностей в Netflix были разработаны принципы хаос-инженерии. Они нацелены на то, чтобы повысить уровень информированности сообщества разработчиков о проблемах, возникающих в условиях хаоса, на то, чтобы дать программистам фреймворки и инструменты для тестирования приложений на устойчивость к подобным проблемам. Например, вот один из известных инструментов хаос-инженерии — Chaos Monkey. Он случайным образом отключает серверы, что позволяет проверить устойчивость системы к таким сбоям, её способность нормально работать в подобных условиях, и её независимость от отдельно взятого сервера. Есть и похожий инструмент для Kubernetes — kube-monkey. Все эти средства работают на уровне хостинга или платформы, но что если вы хотите проверить ваш проект на устойчивость к хаотическим ошибкам в среде Node.js? Скажем, это могут быть необработанные исключения и неудачно завершённые промисы, а также ситуации, в которых достигается ограничение V8 в виде 1.7 Гб памяти. Сюда же относятся проверки пользовательского интерфейса в случаях частой блокировки цикла событий. Для выполнения подобных испытаний можете взглянуть на мой проект node-chaos, который пока пребывает в альфа-версии.
Последствия отступления от рекомендаций
От хаотических ошибок никто не застрахован, поэтому, не учитывая возможность их возникновения, вы рискуете столкнуться с ними в самый неожиданный момент.
Правильный подход
Вот страница npm-пакета chaos-monkey, который позволяет проверять приложения на устойчивость к самым разным странностям среды Node.js.
Пакет chaos-monkey
Итоги
Сегодня мы привели вашему вниманию почти два десятка советов, касающихся тестирования Node.js-проектов. В частности, мы поговорили об анатомии тестов и о типах тестов. В следующий раз поговорим об оценке эффективности тестов и об анализе качества кода.
Уважаемые читатели! Используете ли вы принципы хаос-инженерии при тестировании своих проектов?