
Данное тестирование конечно нельзя назвать полным, ибо задействовано только чтение и то линейное. Но результаты уже заставляют поразмыслить на тему возможного перехода на btrfs в определенных случаях.
Но основная цель — узнать мнение сообщества о том, на сколько это разумно и каких подводных камней может таить в себе подход прозрачного сжатия на уровне файловой системы.
Для тех, кто не хочет тратить время, сразу расскажу про полученные выводы. БД PostgreSQL размещенная на btrfs c опцией compress=lzo, сокращает объем бд в двое (в сравнении с любыми ФС без сжатия) и при использовании многопоточного, последовательного чтения, значительно сокращает нагрузку на дисковую подсистему.
Итак, что в наличии
Физический сервер — 1 шт
- CPU: 2 Сокета по 6 ядер
- RAM: 48 ГБ
- Storage:
- 2x — SAS 10K 300GB в конфигурации RAID 1 + 0 — для ОС и основной бд postgres
- 2x — SAS 10K 300GB в конфигурации RAID 1 + 0 — для тестов
- OS: Ubuntu 14.04.2 — 3.16.0-41
- PG: 9.4.4 x86_64
Методика тестирования
Итак, у нас имеется физическая машина с 2-мя дисками: на первой хранится основная бд postgres(которая после initdb), а второй диск полностью, без создания на нем разметки форматируется в тестируемые ФС(ext4, btrfs lzo/zlib).
На испытуемый диск кладется табличное пространство из резервной копии, которое участвует в тестировании, сделанное с помощью pg_basebackup. Восстанавливается так же и основная бд postgres.
Суть тестирования заключается в последовательном чтении пяти таблиц — клонов в пять потоков.
Скрипт экстремально простой и являет собой обычный «explain analyze».
Каждая таблица имеет размер 13ГБ, общий объем ~ 65ГБ.
Данные для графиков берем из sar с самыми простыми параметрами: «sar 1» — CPU ALL; «sar -d 1» — I/O.
Перед каждым запуском сбрасываем pagecache с помощью команды:
free && sync && echo 3 > /proc/sys/vm/drop_caches && free
Проверяем завершение фоновых процессов:
SELECT sa.pid, sa.state, sa.query
FROM pg_stat_activity sa;
Цифры
Размеры
| ФС | Размер в БД | Размер на диске | Фактор сжатия |
|---|---|---|---|
| btrfs-zlib | 156GB | 35GB | 4.4 |
| btrfs-lzo | 156GB | 67GB | 2.3 |
| ext4 | 156GB | 156GB | 1 |
Последовательное чтение (explain analyze)
| btrfs-zlib | 302000 ms |
| btrfs-lzo | 262000 ms |
| ext4 | 420000 ms |
Графики
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 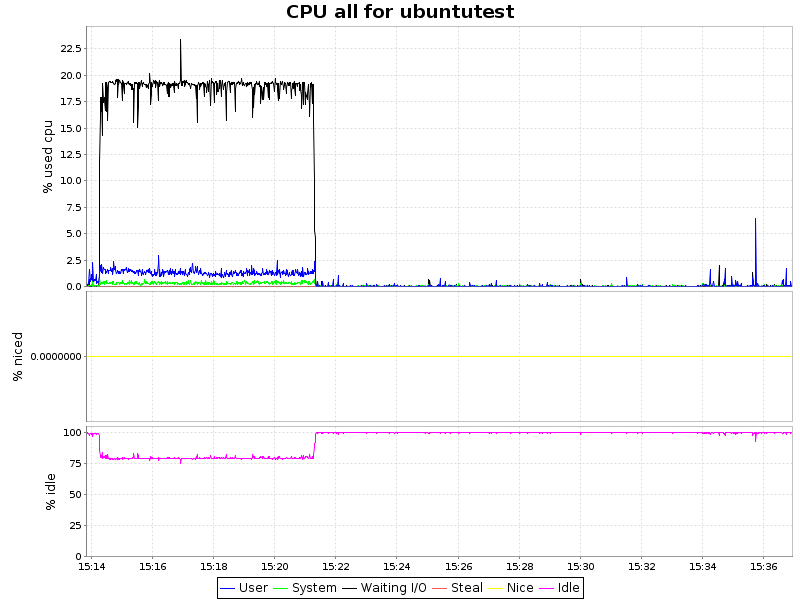 |
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 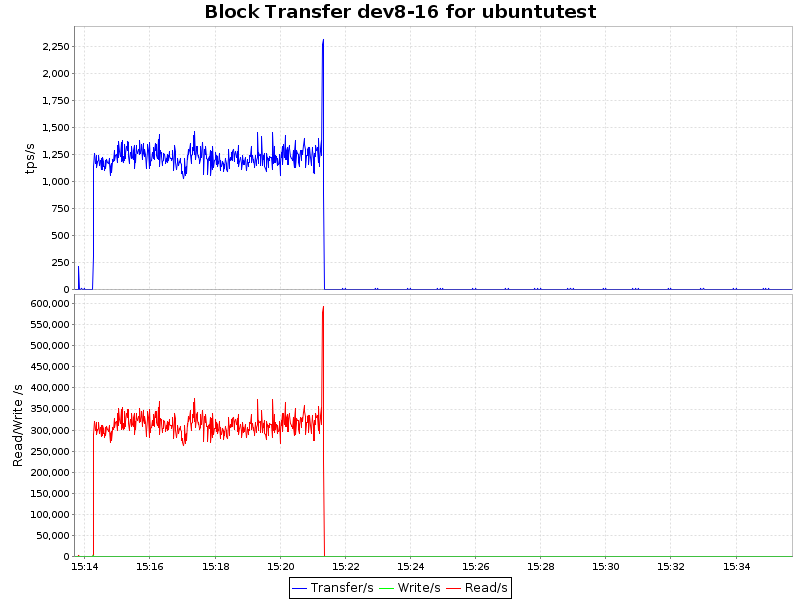 |
| btrfs-zlib | 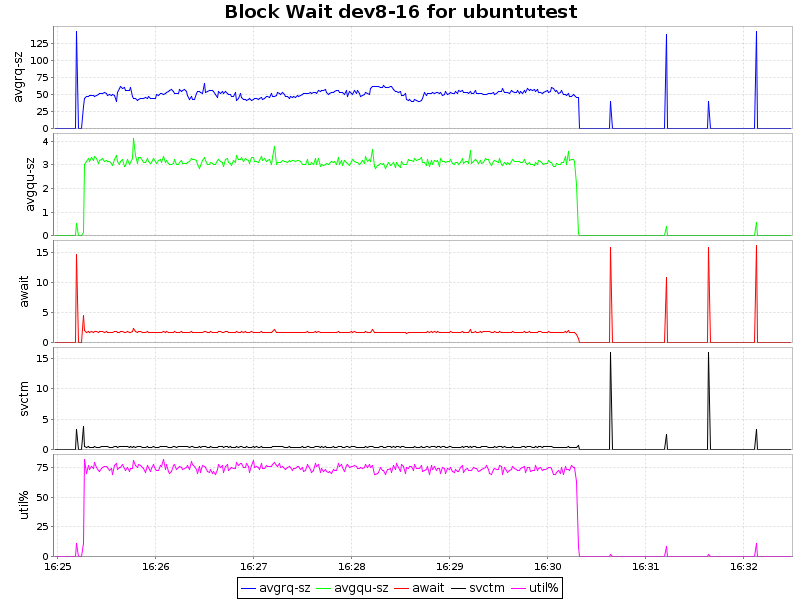 |
| btrfs-lzo | 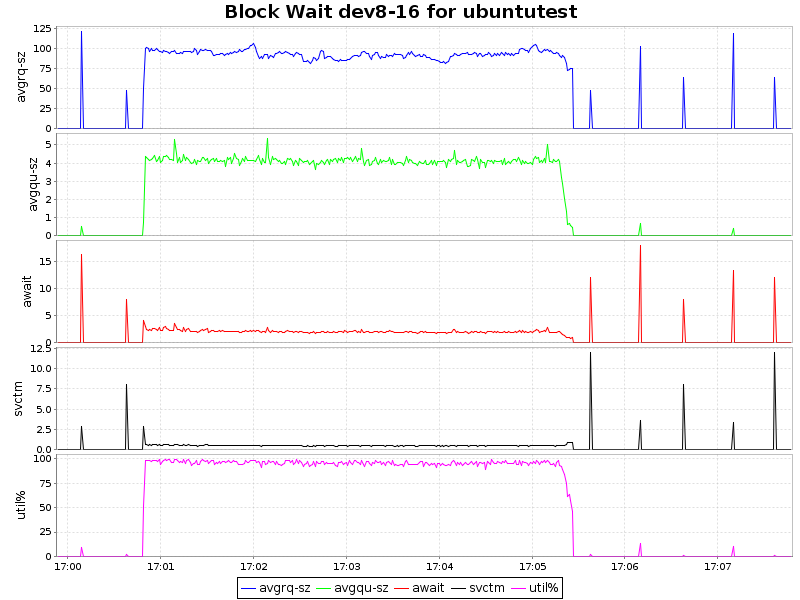 |
| ext4 |  |
Вывод
Как видно из графиков, сжатие с алгоритмом lzo дает лишь незначительную нагрузку на ЦП, что в купе с 2-х кратным уменьшением объемов занимаемого пространства и некоторым ускорением делает такой подход крайней привлекательным. Zlib жмет нашу БД в 4 раза, но при этом нагрузка на процессор возрастает уже ощутимо (~ 7.5% процессорного времени), что для определенных сценариев так же вполне приемлемо. Однако btrfs лишь недавно приобрел статус стабильного (с ядра 3.10) и внедрять в продуктивную среду возможно преждевременно. С другой стороны, наличие синхронной реплики решает и этот вопрос.
P.S.
На сколько мне известно, zlib и, вероятно, lzo используют инструкции из SSE 4.2, что уменьшает загрузку процессоров и вполне возможно, что в некоторых средах виртуализации высокая загрузка процессора не даст воспользоваться преимуществами сжатия.
Если кто подскажет как влиять на это, то я постараюсь перепроверить разницу с аппаратным ускорением и без.
Комментарии (38)

nazarpc
06.07.2015 20:58Однако btrfs лишь недавно приобрел статус стабильного (с ядра 3.10)
Вообще-то текущая версия уже 4.1 и вышел 4.2 RC1, как не считай, не так и недавно.
achekalin
07.07.2015 12:46+1Это текущая версия ядра. «Текущие» же версии ядер в разных дистрибутивах крайне разнятся, и тут уж не до 4.*, тут бы хотя бы 3.10+ встретить. Тем более что за счет бекпортов и патчей от авторов того или иного дистирибутива версия как набор цифр иногда и не сильно важна, важно, что конкретное ядро конкретного дистрибутива может/делает.
А ставить на сервер с БД специально 4.1… Не все рискнут )


PastorGL
06.07.2015 21:26+6Не надо слонов кормить маслом, они от этого могут впасть в маст и всех вокруг поубивать.
К хранению БД на ФС со сжатием это тоже относится. Кажется, что неплохая идея, но как только встречается сценарий с большим количеством мелких рандомных запросов (или кучей апдейтов по одной записи за один раз), сжатие очень сильно убивает производительность дискового IO. Традиционные БД с дисковым пространством работают постранично (и PostgreSQL в том числе — если мне не изменяет склероз, 8192 байта у него размер страницы по умолчанию) в режиме прочитал страницу целиком — обновил нужную часть — записал целиком, и сжатие тут только мешается.
Так что выигрыш в реальной жизни будет только для сценариев пакетной вставки или full-scan чтений.
shapa
06.07.2015 23:01+1Это далеко не так, точнее — не надо обобщать.
В случае NDFS мы наоборот видим значительное ускорение даже на тяжелых базах — виртуальное увеличение емкости флеша в пару раз дает существенно больший выигрыш чем минимальные потери от компрессии (тот-же snappy чрезвычайно быстр).
Тобишь в подавляющем большинстве случаев — базы ускоряются существенно. Но в случае отсутствия тиринга — да, сжатие на лету теряет смысл, но никто не мешает использовать отложенное (если ФС умеет).
Вот пример эффективности сжатия:
sqlsos.wordpress.com/2015/01/17/nutanix-journey-part-3
«But, finally on January 13th, we began moving “real” VM’s over to the Nutanix environment. So far we have 32 VM’s in the cluster, 15 being large SQL server between 0.5 and 1.7 TB in size. Most of them with all databases PAGE compressed, the highest level of compression in SQL server, and we still have reached 1.8: 1 in compression ration in Nutanix.
»

gotozero Автор
07.07.2015 00:33+1Ну, в реальной жизни сие может быть весьма полезным.
Например, если у нас 40ТБ архивных данных, которые никогда не меняются, а храним мы их на медленных дисках, ибо на дорогих у нас активная БД, ситуация меняется в корне.
Мы сходу можем получить 10 ТБ, которые можно уместить и на быстрых дисках тем самым ускорив некоторую аналитику.
Я общем-то и написал что оно не применимо ко всему подряд, ибо я даже не проверял пока.
Данное тестирование конечно нельзя назвать полным, ибо задействовано только чтение и то линейное.
И это не считая его нестабильности о чем пишут ниже.gotozero Автор
07.07.2015 00:41+1Поправлюсь,10 из 40 это конечно теория, но когда речь идет о терабайтах, даже лишние 10ТБ могут выглядеть аппетитно.

amarao
06.07.2015 21:43+12Стабильный статус btrfs — ложь. До сих пор корраптит fs в неудачных случаях. Баг заслан, апстриму пофигу, бубунтовцам исправить кишка тонка (3.13).
gotozero Автор
07.07.2015 00:35+1Ок, а что со сценарием, когда у нас терабайты архивных данных «только на чтение»?
Или он настолько крив, что даже в таком случае может посыпаться?amarao
07.07.2015 13:51Не знаю. Я сказал про обычное применение (без снапшотов, компресии и т.д., даже с отключенным cow).

shapa
06.07.2015 22:57+10btrfs? стабильно? :))) хорошая шутка юмора. они тулзы-то для исправления ФС доделать не могут до сих пор, да и потери данных частенько бывают — сам пару месяцев назад на SLES словил.

ploop
06.07.2015 23:00+2Вообще интересный тест. Для реальных применений вряд ли пригодится, но чисто в познавательных целях годно. Даже не могу представить себе такую «рыхлую» БД, где количество обращений минимально, а объёмы большие.
gotozero Автор
07.07.2015 00:24Не совсем так, количество обращений может быть большим, вопрос только в том какого характера.
Линейные чтения, то бишь всякая аналитика и прочий dwh сильно ускоряются.
Если смотреть iostat(и если он правильно считает в данном случае), количество мегабайт в секунду сокращается пропорционально фактору сжатия. А это сниженная нагрузка на СХД.
Надо провести тесты на случайную запись.
Хотя, в любом случае надо ждат пока ФС станет стабильным, иначе страшно его использовать так.


DLag
07.07.2015 11:45Если есть возможность проверьте пожалуйста на ZoL.
Понимаю что коммент очевиден, но действительно интересны тесты на LZ4.gotozero Автор
07.07.2015 12:32Вот что пишут на btrfs.wiki.kernel.org:
David Sterba — no patches yet — Not in kernel yet
Started with simply adding more compression algorithms, like LZ4, that itself does not bring a significant improvement without other changes.
Там комплекс необходимых улучшений, которые должны дать некоторое улучшение.
Сейчас, даже такое сжатие выглядит вполне приемлемым по описанному сценарию.
Думаю стоит все же немного подождать до LZ4.
Сейчас гораздо перспективнее на мой взгляд исследовать случайный доступ, а именно UPDATE(SELECT-DELETE-INSERT), в случайном порядке размазанных по таблице данных.
Имитируя тем самым некий OLTP. Это покажет возможную перспективу использования, ко времени, когда он станет действительно стабильной.amarao
07.07.2015 13:54Я думаю, на фоне cow, всё остальное будет ерундой. Использовать cow под базой данных — это надо быть очень, очень смелым, и не очень умным.
gotozero Автор
07.07.2015 15:29Не уловил, а при чем тут cow?
И про какой cow идет речь.
У нас есть несколько вариантов:
fs(cow) — lvm — bldev
fs — lvm(cow) — bldev
fs — lvm — bldev(cow)
Любой из этих вариантов для сколь-либо важной бд неприемлем разумеется, ибо ни какой из этих уровней про внутреннюю структуру БД ничего не знает, а значит логическую целостность мы не гарантируем.
Но есть сценарии, когда в тестовой-девелоперской среде, для создания снэпшотов оно может быть использовано с пользой для дела. Хотя для этого хватает cow на других уровнях.
И раз зашел разговор про это, имели ли вы положительный опыт использования встроенного lvm в какой-либо фс, например zfs?amarao
07.07.2015 15:59Все эти варианты — плохо. Если мы говорим про OLAP нагрузку, то это всё — просто ужасно с точки зрения производительности. И дело даже не в логической целостности, а в том, что любой cow — это внезапные тормоза на ровном месте когда этого никто не ожидает.
Нет, у меня нет ни одной success story в продакшене ни с одной из «фичастых» файловых систем. Это не мешает использовать btrfs для снапшота стимовых игрушек, но не более.
Более того, я и у lvm видел неприятные истории, приводившие к ручному разгребанию кольцевого буфера в первой PV'шке.

potan
07.07.2015 12:49+1А поиск по индексу в такой ситуации не тормозит?
По моему базы данных на очень умных файловых системах работают хуже, так как пытаются оптимизировать работу независимо.gotozero Автор
07.07.2015 16:21Вы можете указывать конкретно что сжимать, а что нет.
Если вы монтируете фс с опцией сжатия, то сжимается по умолчанию все.
Но можно на существующей ФС сжать уже имеющиеся данные на лету например вместе с дефрагментацией.
Конкретную папку или конкретный файл.
Возможности достаточно гибкие.
Стабильной надежности и цены бы не было.potan
07.07.2015 16:50А как указать, что сжимать только отдельные записи, что бы при извлечении одной не приходилось разжимать несколько?
С точностью до файла для эффективной работы БД не достаточно.gotozero Автор
07.07.2015 19:48Нет, это невозможно по определению. ФС и БД не взаимодействуют на таком уровне.
БД просто отдает кусок данных и его же запрашивает, что дальше с ним делает ФС она не знает.
Не заработает это еще по одной причине:
Все БД так работают, что минимальный объект доступа это некоторый блок(8192 в данном случае).
В блоке хранится несколько строк и в любом случае, самая дорогая операция — чтение/запись с/на диск происходит полным куском.
И даже если вам нужно всего лишь изменить в одном гипотетическом поле цифру 1 на цифру 0, то вы сначала прочитаете 8192 байта с диска(если этого блока нет в кэше БД, либо в кэше ОС, если последняя не использует directIO), сделаете необходимые изменения и обратно запишите 8192 байта.
На этом фоне, процессорным временем по разархивированию этих 8192 байт зачастую можно пренебречь.
Диски в подавляющем большинстве случаев выступают бутылочным горлышком, а при наличии аппаратного ускорения, операции компрессии и декомпрессии тем паче не являются критической нагрузкой на ЦП.potan
07.07.2015 20:47Дело в том, что что бы разархивировать блок, возможно, придется считать предыдущий. При непоследовательном доступе нагрузка на диск может даже возрасти.
gotozero Автор
08.07.2015 10:29Не возможно, а точно возрастет. Он действительно жмет некоторыми кусками(chunk). Но я точно не знаю перечитывает ли он полностью эти чанки или нет и в каких случаях. Поэтому не понятно на сколько возрастет.
Тут еще имеет влияние в каком месте чанка лежит блок и тому подобные параметры.
Именно поэтому данный тест я проводил с линейным последовательным чтением.
Интерес к данному подходу может быть в первую очередь у баз направленности DSS, DHW, OLAP и еже с ними.
ploop
08.07.2015 07:44Не забывайте, что все современные СУБД (PostgreSQL не исключение) активно кешируют данные в памяти, а с дисками работают по фону, если позволяют объёмы. И как тут корректно протестировать скорости со сжатием/без — не очень понятно, так как часть данных может реально читаться с диска, а часть относиться к кешу. А время будет суммарное.
gotozero Автор
08.07.2015 10:22Вы имеете ввиду кэш ОС или так называемый buffer cache постгреса?
Если первое, то я написал как исключить его влияние:
Перед каждым запуском сбрасываем pagecache с помощью команды:
free && sync && echo 3 > /proc/sys/vm/drop_caches && free
Эта команда сбрасывает линуксовый кэш, да если этого не сделать, все последующие запросы ускоряются на порядки, ибо все лежит в RAM, а его у нас 48ГБ.
На счет второго все еще проще, его размер по умолчанию чрезвычайно мал(128МБ) чтобы вносить хоть какие-либо погрешности.
Его я специально оставил нетронутым.
К тому же, я каждый раз перед запуском теста перезапускал инстанс, ибо заново восстанавливал всю БД.
Кстати в новых версиях постгреса планируют внедрить directIO как у oracle, чтобы 2 раза не кэшировать одни и те же данные, плюс сделать процесс кэширования более оптимальным.ploop
08.07.2015 10:53Я имел ввиду кеш постгреса.
На счет второго все еще проще, его размер по умолчанию чрезвычайно мал(128МБ) чтобы вносить хоть какие-либо погрешности. Его я специально оставил нетронутым.
Ясно, то есть вы учли этот момент. А то его первым делом увеличивают при настройке сервера, и потом это забывается.

netracer
09.07.2015 14:19Пробовал не так давно btrfs на Linux-хранилище бэкапов с ядром 3.18, 4-ядерным серверным Atom-ом и самым быстрым режимом сжатия. Софтовый RAID-5 был из 6 дисков.
Как только Veeam начал туда сливать бэкапы (хватило 1-го сервера в 2 потока), посыпались ошибки I/O. Итог — под ext4 все до сих пор работает прекрасно даже при большой нагрузке, к btrfs веры после этого нет.

u_story
14.07.2015 20:18А никто ZFS и XFS не использует в продакшен для подобных задач? По описанию они выглядят привлекательно.
varnav
А в PostgreSQL нет сжатого формата для баз данных? В современных версиях MySQL есть, InnoDB row format = compressed.