
Эта статья основана на докладе Александра Смирнова на AppsConf 2017 и поможет разобраться, можно ли написать код на Kotlin, который не будет уступать Java по скорости.
О спикере: Александр Смирнов CTO в компании PapaJobs, ведет видеоблог «Android в лицах», а также является одним из организаторов сообщества Mosdroid.
Начнем с ваших ожиданий.
Как вы считаете, Kotlin в runtime работает медленнее, чем Java? Или быстрее? Или, может быть, нет особой разницы? Ведь оба работают на байт-коде, который нам предоставляет виртуальная машина.
Давайте разбираться. Традиционно, когда возникает вопрос сравнения производительности, все хотят видеть бенчмарки и конкретные цифры. К сожалению, для Android нет JMH (Java Microbenchmark Harness), поэтому мы не можем все так же круто замерить, как это можно сделать на Java. Так что же нам остается делать замер, как написано ниже?
fun measure() : Long {
val startTime = System.nanoTime()
work()
return System.nanoTime() - startTime
}
adb shell dumpsys gfxinfo %package_name%
Если вы когда-либо попробуете так замерить свой код, то кто-то из разработчиков JMH будет грустить, плакать и приходить к вам во сне — никогда так не делайте.
На Android можно делать бенчмарки, в частности, Google продемонстрировал это еще на прошлогоднем I/O. Они сказали, что они сильно улучшили виртуальную машину, в данном случае ART, и, если на Android 4.1 одна аллокация объекта занимала примерно 600-700 наносекунд, то в восьмой версии она будет занимать порядка 60 наносекунд. Т.е. они смогли замерить это с такой точностью на виртуальной машине. Почему мы не можем сделать также — у нас нет таких инструментов.
Если мы посмотрим всю документацию, то единственное, что сможем найти, это ту рекомендацию что выше, как измерять UI:
? adb shell dumpsys gfxinfo %package_name%
Собственно, давайте так и сделаем, и посмотрим в конце, что это даст. Но сначала определим, что мы будем замерять и что еще мы можем сделать.
Следующий вопрос. Как вы считаете, где важен performance, когда вы создаете первоклассное приложение?
- Однозначно везде.
- UI Thread.
- Custom view + animations.

Мне больше всего нравится первый вариант, но скорее всего большинство считает, что невозможно сделать так, чтобы весь код отрабатывал очень-очень быстро и важно, чтобы хотя бы не лагал UiThread или custom view. С этим я тоже согласен — это очень-очень важно. То, что у вас в отдельном потоке JSON будет десериализоваться на 10 миллисекунд дольше будет, то этого никто не заметит.
Гештальтпсихология говорит, что, когда мы моргаем, примерно 150-300 милисекунд человеческий глаз находится в расфокусе и не видит, что там, собственно, четко происходит. И тогда эти 10 миллисекунд погоды не делают. Но если мы вернемся к гештальтпсихологии, важно не то, что я реально вижу и что реально происходит, — важно то, что я понимаю как пользователь.
Т.е. если мы сделаем так, чтобы пользователь думал, что у него все очень-очень быстро, а на самом деле это просто будет красиво обыграно, например, с помощью красивой анимации, то он будет доволен, даже если на самом деле это нет.
Мотивы гештальт-психологии в iOS продвигались достаточно давно. Поэтому, если взять два приложения с одинаковым временем обработки, но на разных платформах, и положить их рядышком, будет казаться, что на iOS все быстрее. Анимация в iOS обрабатывает немножко быстрее, раньше начинается показ анимации при загрузке и многих других анимаций, чтобы это было красиво.
Итого, первое правило — думать о пользователе.
А за вторым правилом нужно погрузиться в хардкор.
KOTLIN STYLE
Чтобы честно оценить производительность Kotlin, мы будем сравнивать его с Java. Поэтому, получается, нельзя измерить некоторые вещи, которые есть только в Kotlin, например:
- Сollection Api.
- Method default parameters.
- Data classes.
- Reified types.
- Coroutines.
Сollection АPI, который нам предоставляет Kotlin, очень классный, очень быстрый. В Java, такого попросту нет, есть только разные реализации. Например, библиотека Liteweight Stream API будет медленнее, потому что она делает все то же самое, что и Kotlin, но с одной или двумя дополнительными аллокациями на операцию, поскольку все оборачивается в дополнительный объект.
Если мы возьмем Stream API, из Java 8, то он будет работать медленней, чем Kotlin Сollection АPI, но с одним условием — в Сollection АPI нет такой парализации, как в Java 8. Если мы включаем parallel, на больших объемах данных Stream API в Java обойдет Kotlin Сollection АPI. Поэтому такие вещи мы не можем сравнивать, потому что мы проводим сравнение именно с точки зрения Android.
Вторая вещь, которую, как мне кажется, нельзя сравнивать, это Method default parameters — очень классная фишка, которая, кстати, есть в Dart. Когда вы вызываете какой-то метод, у него могут быть какие-то параметры, которые могут принимать какое-то значение, а могут быть NULL. И поэтому вы не делаете 10 разных методов, а делаете один метод и говорите, что один из параметров может быть NULL, и в дальнейшем используете его без какого-либо параметра. Т.е. он будет смотреть, пришел параметр, либо не пришел. Очень удобно в том плане, что можно писать намного меньше кода, но неудобство заключается в том, что за это приходится платить. Это синтаксический сахар: вы, как разработчик, считаете, что это один метод API, а в реальности под капотом в байт-коде генерируется каждая вариация метода с отсутствующими параметрами. И еще в каждом из этих методов происходит проверка побитово, пришел ли этот параметр. Если он пришел, то ok, если не пришел, то дальше составляем битову маску, и в зависимости от этой битовой маски уже вызывается, собственно, тот изначальный метод, который вы написали. Побитовые операции, все if / else стоят чуть-чуть денег, но очень мало, и это нормально, что удобство вам приходится заплатить. Мне кажется, что это абсолютно нормально.
Следующий пункт, который нельзя сравнивать — это Data classes.
Все плачутся, что в Java есть параметры, для которых есть модельные классы. Т.е. вы берете параметры и делаете еще методы, геттеры и сеттеры для всех этих параметров. Получается, что для класса с десятью параметрами нужна еще целая портянка геттеров, сеттеров и еще кучи всего. Причем, если вы не пользуетесь генераторами, то это приходится писать руками, что вообще ужасно.
Kotlin позволяет от всего этого уйти. Во-первых, так как в Kotlin есть свойства, вам не нужно писать геттеры и сеттеры. У него нет параметров класса, все свойства. Во всяком случае, мы так думаем. Во- вторых, если вы напишете, что это Data classes, сгенерируется целая куча всего остального. Например, equals(), toStrung()/ hasCode() и т.д.
Конечно, у этого есть и недостатки. Например, мне не нужно было, чтобы у меня в equals() сравнивались сразу все 20 параметров моего data classes, нужно было сравнить только 3. Кому-то это все не нравится, потому что на этом теряется производительность, и кроме того, генерируется много служебных функций, и скомпилированный код получается достаточно объемный. То есть, если вы напишете все руками, кода будет меньше, чем если вы используете data classes.
Я не использую data classes по другой причине. Раньше там были ограничения на расширение таких классов и кое-что еще. Сейчас с этим всем лучше, но привычка осталась.
Что очень-очень классно в Kotlin, и на чем он всегда будет быстрее, чем Java? Это Reified types, который тоже, кстати, есть в Dart.
Вы знаете, что когда вы используете generics, то на этапе компиляции происходит стирание типов (type erasure) и в рантайме вы уже не знаете, собственно, какой объект этого дженерика используется.
С Reified types вам не нужно использовать рефлекcию во многих местах, когда в Java вам было бы это нужно, потому что при inline методов именно с Reified остается знание о типе, и поэтому получается, что вы не используете рефлекцию и ваш код работает быстрее. Магия.
И еще есть Coroutines. Они очень классные, они очень мне нравятся, но на момент выступления они входили только в альфа-версию, соответственно проводить с ними корректные сравнения возможности не было.
FIELDS
Поэтому пойдем дальше, перейдем к тому, что мы можем сравнить с Java и том, на что вообще мы можем повлиять.
class Test {
var a = 5
var b = 6
val c = B()
fun work () {
val d = a + b
val e = c.a + c.b
}
}
class B (@JvmField var a: Int = 5,var b: Int = 6)
Как я сказал, у нас нет параметров у класса, у нас есть свойства.
У нас есть var, у нас есть val, у нас есть внешний класс, одно из свойств которого @JvmField, и мы будем смотреть, что, собственно, происходит с функцией work(): мы суммируем значение поля a и поля b собственного класса и значения поля a и поля b внешнего класса, который записан в неизменяемое поле c.
Вопрос заключается в том, что, собственно, будет вызвано в d = a + b. Все мы знаем, что это раз свойство, то будет вызван геттер этого класса для этого параметра.
L0
LINENUMBER 10 L0
ALOAD 0
GETFIELD kotlin/Test.a : I
ALOAD 0
GETFIELD kotlin/Test.b : I
IADD
ISTORE 1
Но если мы посмотрим в байт-код, то увидим, что в реальности происходит обращение getfield. То есть это в байт-коде происходит не вызов InvokeVirtual функции, а напрямую обращение к полю. Нет того, что было обещнао нам изначально, что у нас все свойства, а не поля. Получается, что Kotlin нас обманывает, есть прямое обращение.
Что будет, если мы все-таки посмотрим, какой байт-код генерируется для другой строки: val e = c.a + c.b?
L1
LINENUMBER 11 L1
ALOAD 0
GETFIELD kotlin/Test.c : Lkotlin/B;
GETFIELD kotlin/B.a : I
ALOAD 0
GETFIELD kotlin/Test.c : Lkotlin/B;
INVOKEVIRTUAL kotlin/B.getB ()I
IADD
ISTORE 2
Раньше, если вы обращались к неприватному свойству, то у вас всегда был вызов InvokeVirtual. Если это было приватное свойство, то к нему обращение шло через GetField. GetField намного быстрее, чем InvokeVirtual, в спецификации от Аndroid утверждается, что обращение напрямую к полю в 3–7 раз быстрее. Поэтому рекомендуется всегда обращаться к Field, а не через геттеры либо сеттеры. Сейчас, особенно в восьмой виртуальной машине ART, будут уже другие числа, но, если вы еще поддерживаете 4.1, это будет верно.
Поэтому получается, нам все-таки выгодно, чтобы был GetField, а не InvokeVirtual.
Сейчас, можно добиться GetField, если вы обращаетесь к свойству собственного класса, либо, если это публичное свойство, то необходимо поставить @JvmField. Тогда точно также в байт-коде будет вызов GetField, который в 3–7 раз быстрее.
Понятно, что здесь мы говорим в наносекундах и, с одной троны это очень-очень мало. Но, с другой стороны, если вы это делаете именно в UI-потоке, например, в методе ondraw обращаетесь к какому-то view, то это скажется на отрисовке каждого кадра, и можно сделать это чуть быстрее.
Если сложить все оптимизации, то в сумме это может что-то и дать.
STATIC!?
А что со статиками? Все мы знаем, что в Kotlin static — это companion object. Раньше вы наверняка добавляли какой-то тэг, например, public static, final static и т.д., если сконвертировать это в код на Kotlin, то вы получите companion object, в котором будет записано примерно следующее:
companion object {
var k = 5
fun work2() : Int = 42
}
Как вы считаете данная запись идентична стандартному из Java объявлению static final? Это вообще static или нет?
Да, действительно, Kotlin заявляет, что вот это вот в Kotlin — static, что object говорит о том, что это static. В реальности это не static.
Если мы посмотрим на сгенерированный байт-код, то увидим следующее:
L2
LINENUMBER 21 L2
GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion;
INVOKEVIRTUAL kotlin/Test$Companion.getK ()I
GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion;
INVOKEVIRTUAL kotlin/Test$Companion.work2 ()I
IADD
ISTORE 3
Генерируется Test.Companion singleton-объект, для которого создается instanсe, этот instanсe записывается в собственное поле. После этого обращение к чему-либо из companion object происходит через этот объект. Он берет getstatic, то есть статический instance этого класса и вызывает у него invokevirtual функцию getK, и точно то же само для функции work2. Таким образом мы получаем, что это не static.
Это имеет значение, по той причине, что на старых JVM invokestatic был примерно на 30 % быстрее, чем invokevirtual. Сейчас, конечно, на HotSpot оптимизированная виртуализация происходит очень круто, и это практически незаметно. Тем не менее, нужно это иметь в виду, тем более, что тут возникает одна лишняя аллокация, а лишняя локация на 4ST1 — это 700 наносекунд, тоже много.
Давайте посмотрим на Java-код, который получится, если обратно развернуть байт-код:
private static int k = 5;
public static final Test.Companion Companion =
new Test.Companion((DefaultConstructorMarker)null);
public static final class Companion {
public final int getK() { return Test.k;}
public final void setK(int var1) {
Test.k = var1;
}
public final int work2() { return 42; }
private Companion() { }
// $FF: synthetic method
public Companion(DefaultConstructorMarker
$constructor_marker) { this(); }
}
Создается статическое поле, static final реализация объекта Companion, создаются геттеры и сеттеры, причем, как вы можете увидеть, обращаясь к статическому полю внутри, появляется дополнительный статический метод. Все достаточно грустно.
Что же мы можем сделать, убедившись, что это не статика? Мы можем попробовать добавить @JvmField и @JvmStatic и посмотреть, что получится.
val i = k + work2()
companion object {
@JvmField
var k = 5
JvmStatic
fun work2() : Int = 42
}
Сразу скажу, что от @JvmStatic вы никак не уйдете, точно так же это буде объект, так как это companion object, будет лишняя аллокация этого объекта и будет лишний вызов.
private static int k = 5;
public static final Test.Companion Companion =
new Test.Companion((DefaultConstructorMarker)null);
public static final class Companion {
@JvmStatic
public final int work2() { return 42; }
private Companion() {}
// $FF: synthetic method
public Companion(DefaultConstructorMarker
$constructor_marker) { this(); }
}
Но вызов изменится только для k, потому что это будет @JvmField, оно будет браться напрямую как getstatic, геттеры и сеттеры уже не будет генерироваться. А для функции work2 ничего не изменится.
L2
LINENUMBER 21 L2
GETSTATIC kotlin/Test.k : I
GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion;
INVOKEVIRTUAL kotlin/Test$Companion.work2 ()I
IADD
ISTORE 3
Второй вариант, как создать static предлагается в документации Kotlin, так сказано, что мы можем просто создать object, и это будет статический код.
object A {
fun test() = 53
}
В реальности это все тоже не так.
L3
LINENUMBER 23 L3
GETSTATIC kotlin/A.INSTANCE : Lkotlin/A;
INVOKEVIRTUAL kotlin/A.test ()I
POP
Получается, что мы делаем вызов getstatic instance от singletone, который создается, и вызываем точно такие же виртуальные методы.
Единственный вариант, как мы можем добиться именно invokestatic, это Higher-Order Functions. Когда мы просто пишем какую-то функцию вне класса, например, fun test2 будет действительно вызвана как статичная.
fun test2() = 99
L4
LINENUMBER 24 L4
INVOKESTATIC kotlin/TestKt.test2 ()I
POP
Причем, что самое интересное, что будет создан класс, объект, в данном случае это testKt, он сам cгенерирует объект у него сам сгенерирует функцию, которую положит в этот объект, и вот ее вызовет как invokestatic.
Почему так было сделано — непонятно. Многие этим недовольны, но есть и те, кто считает такую реализацию вполне нормальной. Поскольку виртуальная машина, в т.ч. Art улучшается, сейчас это уже не настолько критично. В восьмой версии Android, точно так же как на HotSpot, все заоптимизировано, но все же эти мелочи чуть-чуть влияют на общую производительность.
NULLABILITY
fun test(first: String, second: String?) : String {
second ?: return first
return "$first $second"
}
Это следующий интересный пример. Казалось бы, мы отметили, что second может быть nullable, и его надо проверить перед тем, как с ним что-то делать. В данном случае я ожидаю, что у нас есть один if. Когда этот код будет развернут в if second не равен нулю, то я думаю, что выполнение пойдет дальше и выведет только first.
Как на самом деле это все развернется в java код? На самом деле будет проверка.
@NotNull
public final String test(@NotNull String first,@Nullable String second) {
Intrinsics.checkParameterIsNotNull(first, "first");
return second != null ? (first + " " + second) : first;
}
Мы получим Intrinsics изначально. Допустим, то, что я говорю, что вот этот вот
If развернется в тернарный оператор. Но кроме этого, хотя мы даже зафиксировали, что первый параметр не может быть nullable, он все равно будет проверен через Intrinsics.
Intrinsics — это внутренний класс в Kotlin, у которого есть некоторый набор параметров и проверок. И каждый раз, когда вы делаете параметр метода не nullable, он все равно его проверяет. Зачем? Затем, что мы работаем в Interop Java, и может случиться так, что вы то ожидаете, что здесь не будет nullable, но с Java он откуда-нибудь возьмется.
Если вы это проверите, это пойдет дальше по коду, и потом через 10-20 вызовов метода, вы сделаете что-то с параметром, который хоть и не может быть nullable, но почему то им оказался. У вас все упадет, и вы не сможете понять, что, собственно, произошло. Чтобы не возникло такой ситуации, каждый раз, когда у вас происходит передача параметра null, у вас все равно будет его проверка. И если он будет nullable, то будет exception.
Эта проверка тоже чего-то стоит, и если их таких будет много, то будет не очень хорошо.
Но на самом деле, если говорить о HotSpot, то 10 вызовов этих Intrinsics займет порядка четырех наносекунд. Это очень-очень мало, и не стоит по этому поводу переживать, но это интересный фактор.
PRIMITIVES
В Java есть такая вещь, как примитивы. В Kotlin, как все мы знаем, нет примитивов, мы всегда оперируем с объектами. В Java они используются для того, чтобы обеспечить более высокую производительность объектов на каких-либо незначительных вычислениях. Сложить два объекта намного дороже, чем сложить два примитива. Рассмотрим пример.
var a = 5
var b = 6
var bOption : Int? = 6
Есть три числа, для первых двух будет выведен not null тип, а про третье мы сами говорим, что он может быть nullable.
private int a = 5;
private int b = 6;
@Nullable
private Integer bOption = Integer.valueOf(6);
Если посмотреть на байт-код и посмотреть, какой Java-код генерируется, то первые два числа not null, и поэтому они могут быть примитивами. Но примитив не может содержать в себе Null, это может делать только объект, поэтому для третьего числа будет сгенерирован объект.
AUTOBOXING
Когда вы работаете с примитивами, и выполняете операцию с примитивом и непримитивом, то либо надо будет один из них перевести в примитив, либо в объект.
И, казалось бы, неудивительно, что если вы делаете операции с nullable и not nullable в Kotlin, то чуть-чуть теряете в производительности. Причем, если таких операций много, то вы теряете много.
val a: String? = null
var b = a?.isBlank() == true
Видите, где здесь будет Boxing/Unboxing? Я тоже не видел, пока не посмотрел на байт-код.
if (a != null && a.isBlank()) true else false
Собственно, я ожидал, что будет примерно такое сравнение: если строка не null и если она пустая, то установить true, а иначе — установить false. Вроде все просто, но в реальности генерируется следующий код:
String a = (String)null;
boolean b = Intrinsics.areEqual(a != null ?
Boolean.valueOf(StringsKt.isBlank((CharSequence)a)) : null,
Boolean.valueOf(true));
Давайте посмотрим внутрь. Берется переменная a, она кастится в CharSequence, после того, как ее закастили, на что тоже уже потратили сколько-то времени, вызывается другая проверка — StringsKt.isBlank — это как extension функция для CharSequence записана, поэтому она кастится и отправляется. Так как первое выражение может быть nullable, он берет его и делает Boxing, и оборачивает это все в Boolean.valueOf. Поэтому же примитив true тоже становится объектом, и только после этого уже происходит проверка и вызывается Intrinsics.areEqual.
Казалось бы, такая простая операция, а такой неожиданный результат. На самом деле, таких вещей очень мало. Но когда у вас может быть nullable/not nullable, можно нагенерировать подобного достаточно много, причем такого, чего вы никогда бы не ожидали. Поэтому я рекомендую вам как можно раньше уходить от непонятностей. Т.е. как можно раньше приходить к иммутабельности значений и уходить от nullable, чтобы вы как можно быстрее, как можно чаще оперировали not null.
LOOPS
Следующая интересная вещь.
Вы можете использовать обычный for, который есть в Java, но вы точно также можете использовать новый удобный АPI — сразу писать перебор элементов в list. Например, можно в цикле вызывать функцию work, где it будет какой-то элемент этого списка.
list.forEach {
work(it * 2)
}
Будет сгенерирован итератор и будет банальный перебор по итератору. Это нормально, это много где рекомендуется. Но если мы посмотрим, какие советы дает нам Google, то узнаем, с точки зрения производительности конкретно для ArrayList перебор через for работает в 3 раза быстрее, чем через итератор. Во всех остальных случаях итератор будет работать идентично.
Поэтому если вы уверены, что у вас ArrayList, логично сделать другую вещь — написать свой foreach.
inline fun <reified T> List<T>.foreach(crossinline action: (T)
-> Unit): Unit {
val size = size
var i = 0
while (i < size) {
action(get(i))
i++
}
}
list.foreach { }
Это тоже будет API, но который будет генерировать чуть-чуть другой код. Здесь мы используем всю мощь, которую дает нам Kotlin: мы сделаем extension функцию, которая будет «инлайниться», которая будет типа reified, т.е. мы ничего не сотрем, и еще сделаем так, что передадим лямбду, для которой выполним crossinline. Поэтому все везде станет очень хорошо, даже идеально, счет работает очень быстро. В 3 раза быстрее, как и рекомендует нам спецификация Android от Google.
RANGES
Это же мы могли сделать с помощью Ranges.
inline fun <reified T> List<T>.foreach(crossinline action: (T)
-> Unit): Unit {
val size = size
for(i in 0..size) {
work(i * 2)
}
}
Предыдущий пример и этот с: Unit будут идентично отработаны в байт-коде. Но если вы попробуете сделать здесь либо ?1, либо until добавить, либо другой шаг, то обратно будут итераторы. И кроме этого, будет аллокация для объекта, который будет генерировать ranges. Т.е. вы аллоцируете объект, в который записывается начальная точка. Каждую следующую итерацию будет вызван этот метод со следующим значением step. Про это стоит помнить.
INTRINSICS
Вернёмся-ка к Intrinsics, и рассмотрим еще один интересный пример:
class Test {
fun concat(first: String, second: String) = "$first $second"
}
В этом случае Intrinsics вызывается два раза — и для second, и для first.
public final class Test {
@NotNull
public final String concat(@NotNull String first, @NotNull String second) {
Intrinsics.checkParameterIsNotNull(first, "first");
Intrinsics.checkParameterIsNotNull(second, "second");
return first + " " + second;
}
}
Их можно выключить, но их нельзя выключить в gradle. Если вы выделите, что у вас очень-очень важно вплоть до этих 4 наносекунд, то вы можете там их отключить. Вы можете сделать модуль Kotlin с UI, где вы точно уверены, что туда не может ничего попасть nullable, и передать напрямую Kotlin компилятору:
? kotlinc -Xno-call-assertions -Xno-param-assertions Test.kt
Это вырубит Intrinsics, как проверяющий входные параметры, так и результат.
На самом деле, я не видел ни разу, чтобы вторая часть была особо полезна. Но параметр — Xno-param-assertions — вырубает эти два Intrinsics, и все работает очень хорошо.
Если это сделать везде, то получится не очень хорошо, потому что приводит к тому, что я уже говорил, что программа может упасть там, где вы не ожидаете. А в тех местах, где вы действительно уверены, что дополнительная проверка не нужна, вы можете так сделать.
REDEX
Многие считают, что геттеры и сеттеры, как написано в документации, инлайнятся в Proguard. Но я бы сказал, что в 99% случаев метод, который состоит из одной функции, не будет заинлайнен. В Android 8.0 это оптимизировали, и там уже инвайнится. Остается лишь ждать, когда мы все будем на нем.
Другой вариант, это использовать кроме Proguard, инструмент от Facebook, который называется Redex. В нем также используются оптимизации байт-кода, но точно так же он не инлайнит все, и точно также не инлайнит геттеры и сеттеры. Получается, что Jvm Fields на данный момент единственный вариант, как уйти от геттера и сеттера для простых свойств.
Кроме этого, в Redex включены другие оптимизации. В частности, я создал примитивное приложение, где абсолютно не писал никакого кода, добавил для него Proguard, котрый вырезал все, что только можно было. После этого я провернул это приложение еще и через Redex и получил минус 7% к весу APK. Мне кажется, это достаточно хорошо.
BENCHMARKS
Перейдем к бенчмаркам. Я взял достаточно интересное приложение, у которого много фреймов и много анимаций, чтобы было удобно его мерить. Это приложение написал Ярослав Мыткалык, а я замерил бэнчмарки на четырех разных телефонах. Собственно, я сделал dumpsys gfxinfo и тысячи раз собирал данные, которые после этого свел в итоговое значение. В моем github профиле github.com/smred вы сможете найти исходники и результаты.
Итак, на достаточно слабеньком устройстве Huawei.
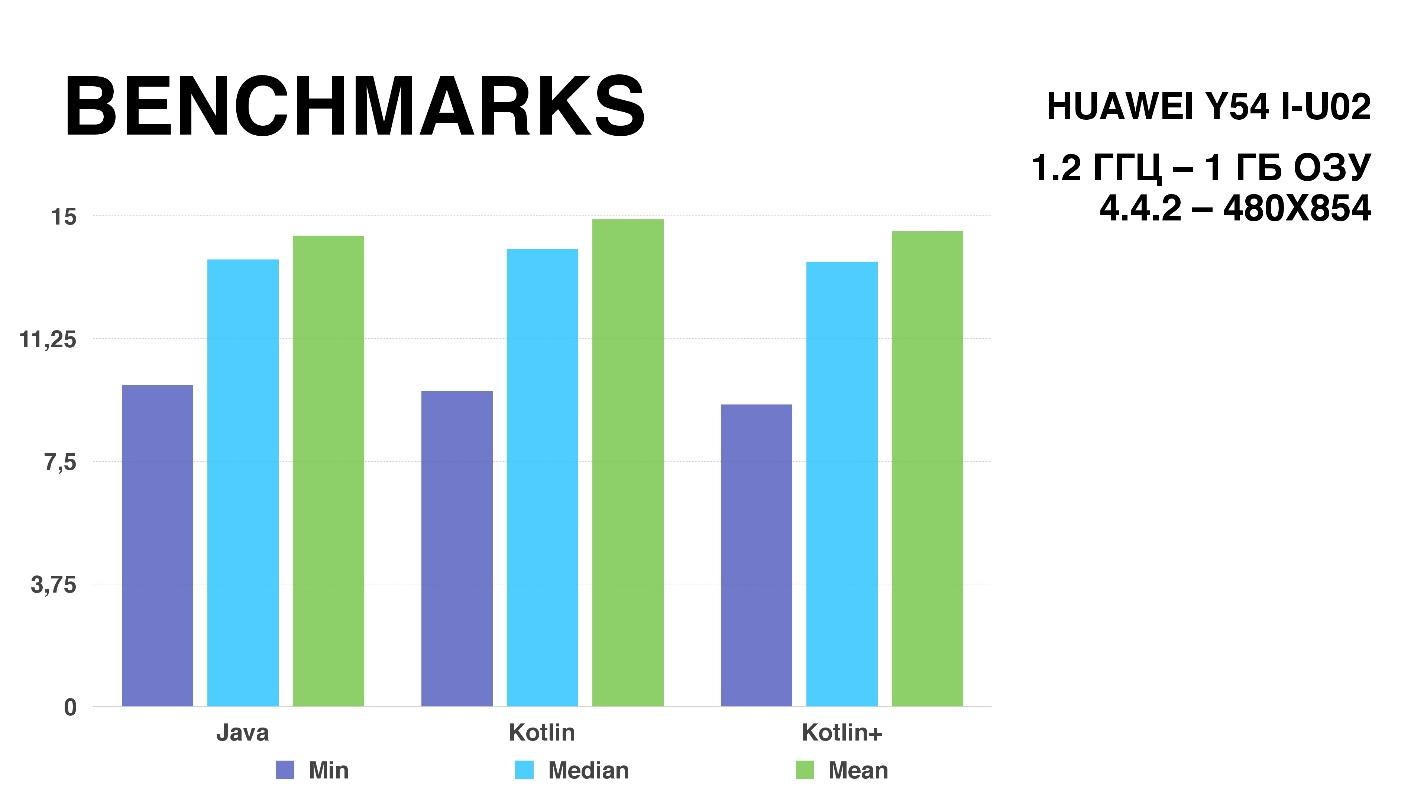
Фиолетовый столбец показывает минимальный вариант одного кадра. Зеленый — максимальный, на разных расчетах всегда прыгал. Голубой столбец отражает медианное значение, которое было довольно стабильным, погрешность была порядка 0,04 миллисекунды. Но, к сожалению, по графику результат бэнчмарка довольно трудно понять — все очень близко, поэтому посмотрим на время отрисовки одного кадра в миллисекундах.
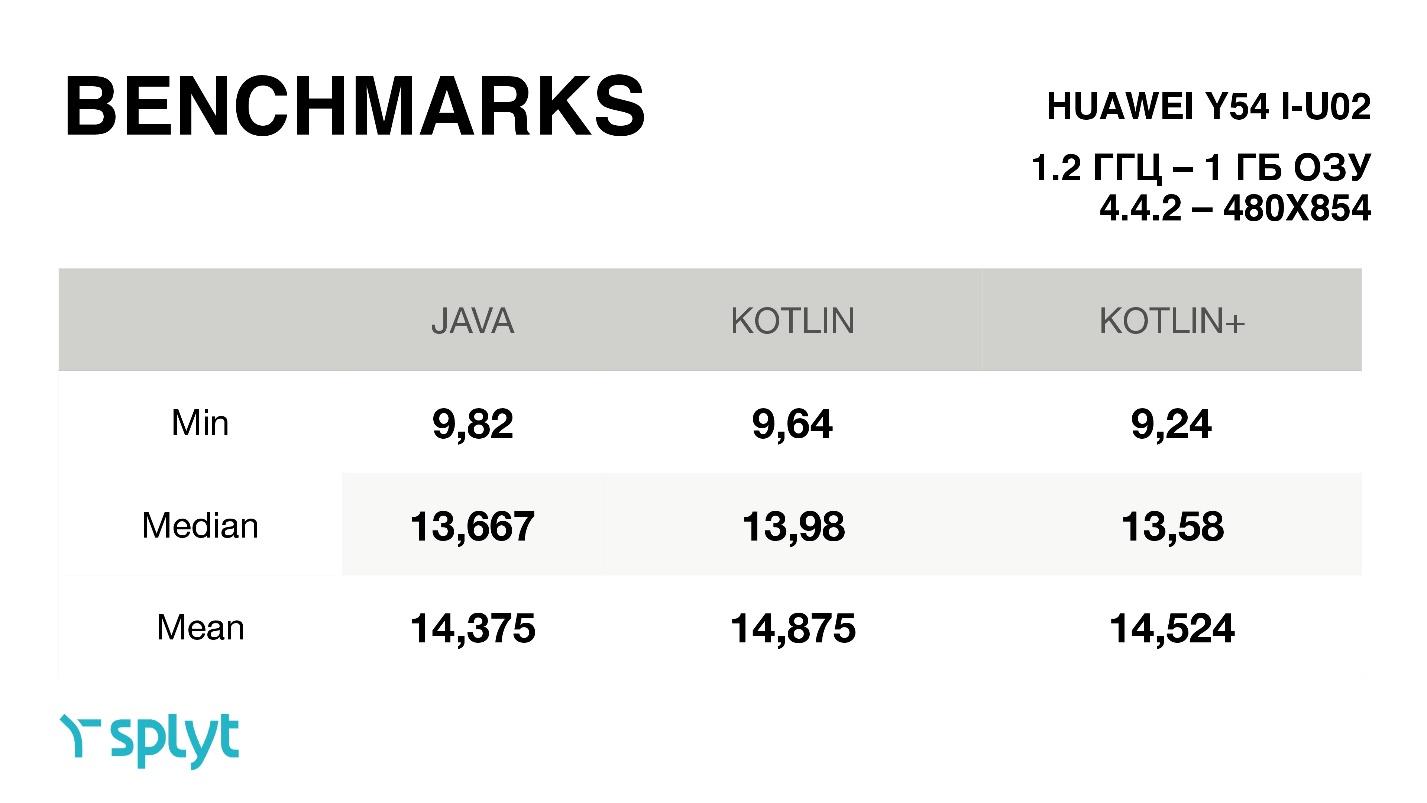
Когда мы просто перешли на Kotlin, получили немножечко больше времени на кадр. После того, как произведены все оптимизации, отличия почти в рамках погрешности. Но почему-то получилось, что медиана в оптимизированном Kotlin даже больше, чем у Java. Но если посмотреть среднее, то, конечно, результаты всегда чуть лучше было, чем в просто автосгенерированном котлиновском коде. На четырех устройствах получилась примерно похожая схема.

Получается, оптимизации, о которых я говорил, действительно помогали и приводили к тому, что Kotlin навскидку практически всегда работает так же как код на Java. Да, из-за некоторых особенностей и отличий, например, в абстракциях, есть немного дополнительной нагрузки, но если вы захотите, вы всегда сможете добиться практически идентичной скорости работы.
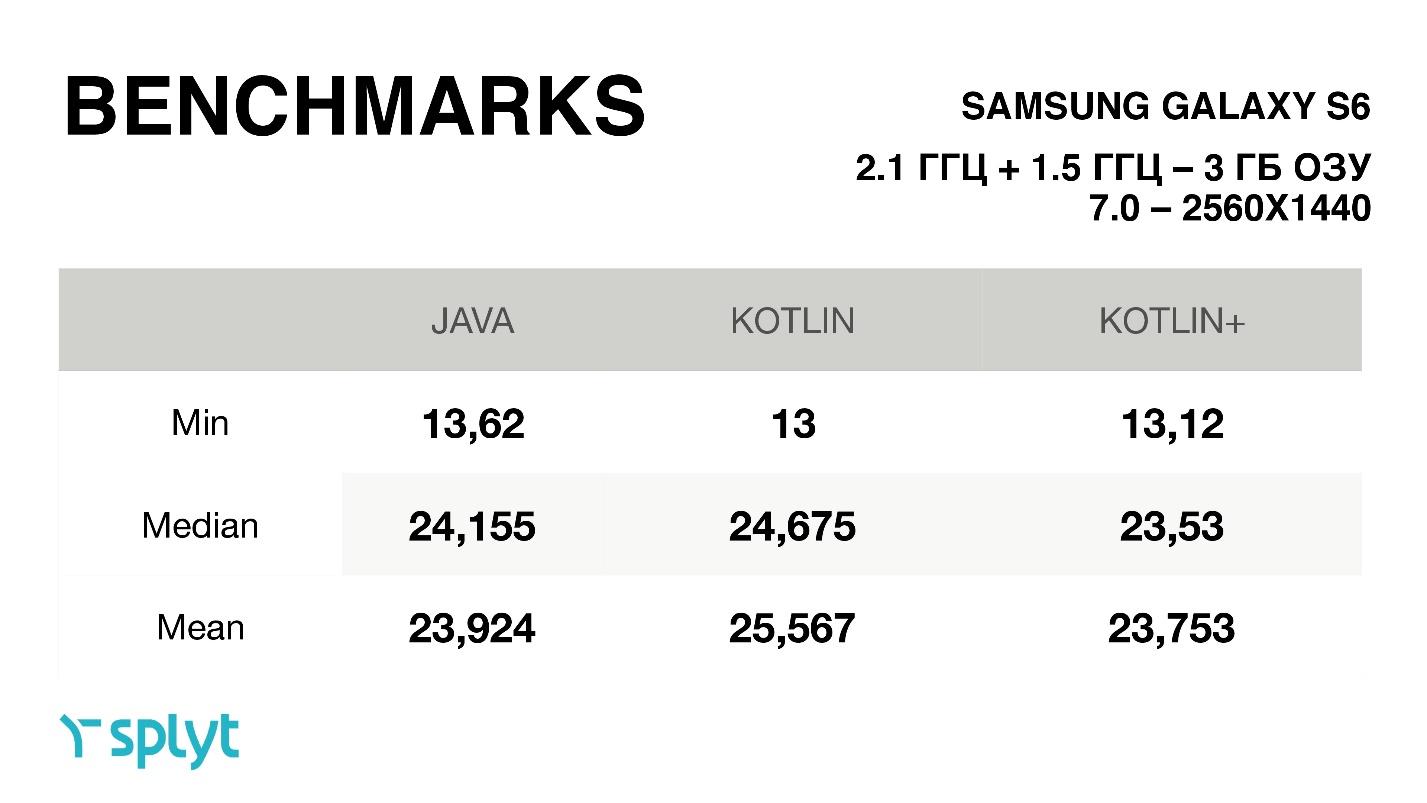
Кстати, еще одна особенность: почему-то в этих бэнчмарках всегда для Kotlin минимальное время на отрисовку одного кадра уменьшалось, т.е. становилось даже лучше. В среднем же получался либо небольшой рост, либо точно такое же время. На удивление у какого-то китайского телефона с маленьким разрешением получается времени на отрисовку одного кадра уходило намного-намного меньше — практически в 2 раза меньше, чем у крутого Galaxy S6, с очень большим разрешением экрана.

Это бэнчмарк на Google Pixel. Для него разница очень небольшая, всё в пределах 0,1 милисекунды.
ВЫВОДЫ
Для того, чтобы подвести итог, я бы хотел сказать, что
- Быстродействие важно только на UI потоке или custom view.
- Очень критично в onmeasure-onlayout-ondraw. Старайтесь избежать там всех autoboxing, not null параметров и т.д.
- Практически всегда можно написать код на Kotlin, который будет работать с идентичной Java скоростью, а в некоторых местах даже может получиться быстрее.
- Преждевременная оптимизация — зло.
Все то, что я сделал, могло затратить у вас очень много времени. Есть разработчики, которые считают, что некоторые современные средства, например, Kotlin, плохи с точки зрения производительности. Но у меня получилось представить доказательства того, что Kotlin никак на это не влияет и можно без проблем его использовать в продакшене.
Не тратьте время там, где могли бы его не тратить.
Александр Смирнов входит в Программный комитет нашей brand new AppsConf, в том числе благодаря его работе секция Android будет такой сильной. Хотя, и вся целиком программа будет крутой. Бронируйте билеты, и увидимся 8 и 9 октября на масштабнейшей конференции по моблиьной тематике.
Комментарии (7)

KivApple
15.08.2018 21:00Не понял, почему подстановка значений аргументов по умолчанию происходит не на этапе компиляции, а в рантайме с помощью каких-то битовых масок и т. д.
h0tkey
16.08.2018 16:35Это нужно, чтобы значения по умолчанию не «оседали» в бинарниках, скомпилированных напротив библиотеки с функцией, у которой есть дефолтные значения. Такой подход позволяет заменить версию библиотеки и без перекомпиляции вызывающего кода получить её новые значения по умолчанию.
rraderio
16.08.2018 17:53Это синтаксический сахар: вы, как разработчик, считаете, что это один метод API, а в реальности под капотом в байт-коде генерируется каждая вариация метода с отсутствующими параметрами. И еще в каждом из этих методов происходит проверка побитово, пришел ли этот параметр.
fun foo(bar: Int, baz: Int = 10) { }
void foo(int bar, int baz) {} void foo(int bar) { foo(bar, 5); }
Не ясно для чего делать проверки побитовоh0tkey
16.08.2018 18:28под капотом в байт-коде генерируется каждая вариация метода с отсутствующими параметрами
На самом деле в этом месте в статье неточность, по умолчанию в байт-коде вообще не генерируются перегрузки без отдельных аргументов, а есть только два метода: один с настоящей сигнатурой функции (такой, как же, как в коде) и ещё один синтетический с добавленной битовой маской. Для вызовов из Котлина этого всегда хватает.
Если перегрузки без аргументов Вам всё-таки нужны (для Java-интеропа), то включить генерацию дополнительных методов можно с помощью аннотации
@JvmOverloads. Но! Даже с ней перегрузок методов будет сгенерировано не 2^n (где n — число параметров со значениями по умолчанию), а всего n — это будут методы с отброшенными с конца параметрами.
В идиоматичном коде на Котлине часто встречаются и функции с большим числом дефолтных параметров. При сколько-нибудь существенном числе дефолтных параметров (даже уже на четырёх) генерировать 2^n перегрузок было бы очень накладно в смысле числа методов (актуально для Android) и размера класс-файлов. Для того, чтобы этого избежать, и нужен синтетический метод с битовой маской. С вызывающей стороны в битовой маске передаётся информация о том, для каких параметров аргументы переданы, а для каких должны быть использованы дефолтные. Синтетический метод проверяет битовую маску и на её основе вычисляет только нужные дефолтные значения, после чего передаёт всё вместе "настоящему методу".
То есть битовая маска нужна, чтобы не страдать от экспоненциального роста числа комбинаций отсутствующих аргументов.
KivApple
16.08.2018 18:28Спорное решение. С одной стороны, конечно, можно изменить значение по умолчанию в библиотеке без перекомпиляции всего приложения, с другой стороны, разве приложение не опирается на значение по умолчанию, которое было в момент разработки? То есть фактически частично изменяется контракт метода и, быть может, было бы лучше сохранить исходное значение по умолчанию. Как нужно — 50/50 зависит от ситуации. Значит было бы логично выбрать более производительное решение.
h0tkey
16.08.2018 18:47Для вызывающего кода отсутствие аргумента для дефолтного параметра может также иметь семантику «я не хочу ничего решать, сделайте там сами что-нибудь разумное», в таком случае код не опирается на значения по умолчанию.
Более того, значения по умолчанию — это произвольные выражения, которые могут ссылаться на детали реализации библиотеки. «Осевшие» в вызывающем коде выражения дефолтных аргументов могли бы оказаться даже бинарно несоместимыми с новой версией библиотеки, поэтому их тоже можно считать деталями реализации.
FirsofMaxim
Спасибо, а есть возможность у видео поднять громкость?