
В продолжение "разбора полетов" с HighLoad++ 2017 мы подготовили небольшой обзор пяти лучших (по мнению участников конференции) англоязычных докладов.
Наивысших оценок удостоились темы, касающиеся использования ProxySQL (в ТОП-5 попало целых два доклада об этом инструменте), тестирования приложений в публичном облаке Amazon, а также принципы логгирования в масштабах, когда это становится проблемой, и мониторинг Apache Kafka.
Henrik Ingo (архитектор решений MongoDB, а сейчас ведущий инженер по производительности в Mongo DB).
Первый доклад, отмеченный участниками, приводит аргументы в пользу того, что публичное облако действительно можно использовать для тестирования собственных продуктов, в том числе, для нагрузочного тестирования. «Подопытным» в данном случае выступила СУБД MongoDB с открытым исходным кодом, которая тестируется при помощи облака Amazon. В общей сложности в месяц на эту задачу тратится порядка 400 тыс. часов, около 5% этого времени — только тесты на производительность, чья основная задача — даже не обеспечить оптимизацию, а не допустить «проседания» в результате каких-то доработок.
Ключевой вопрос выступления — как в публичном облаке получить воспроизводимые результаты тестирования?
Доклад построен по принципу разбора гипотез. Вначале Henrik Ingo высказывает предположения о том, какие факторы должны влиять на уровень «шума» в тестах (само понятие «шума» в докладе имеет вполне конкретное определение). К примеру, команда тестирования высказывала мысль о том, что на «тяжелых» тестах основной «шум» идет от жесткого диска, или о том, что в облаке при раздаче ресурсов можно «нарваться» на хорошие (полностью выделенные) или плохие (разделенные с кем-то) инстансы, что влияет на результаты тестирования.
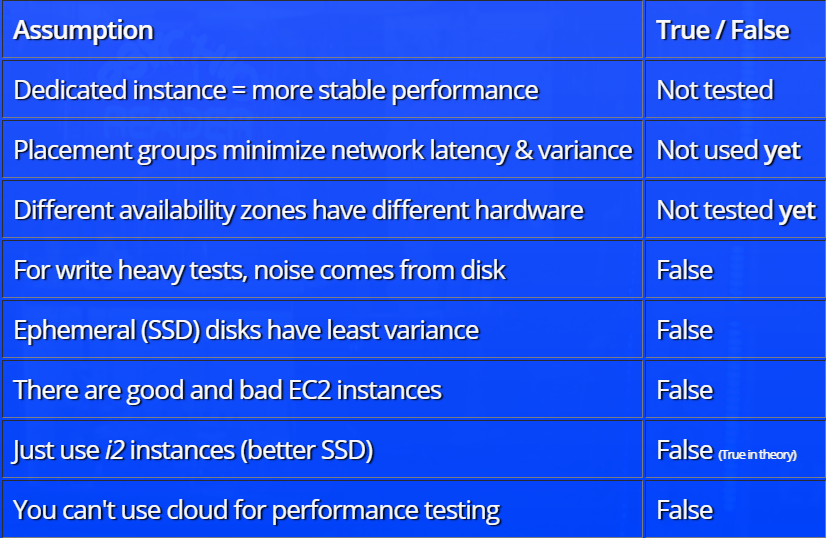
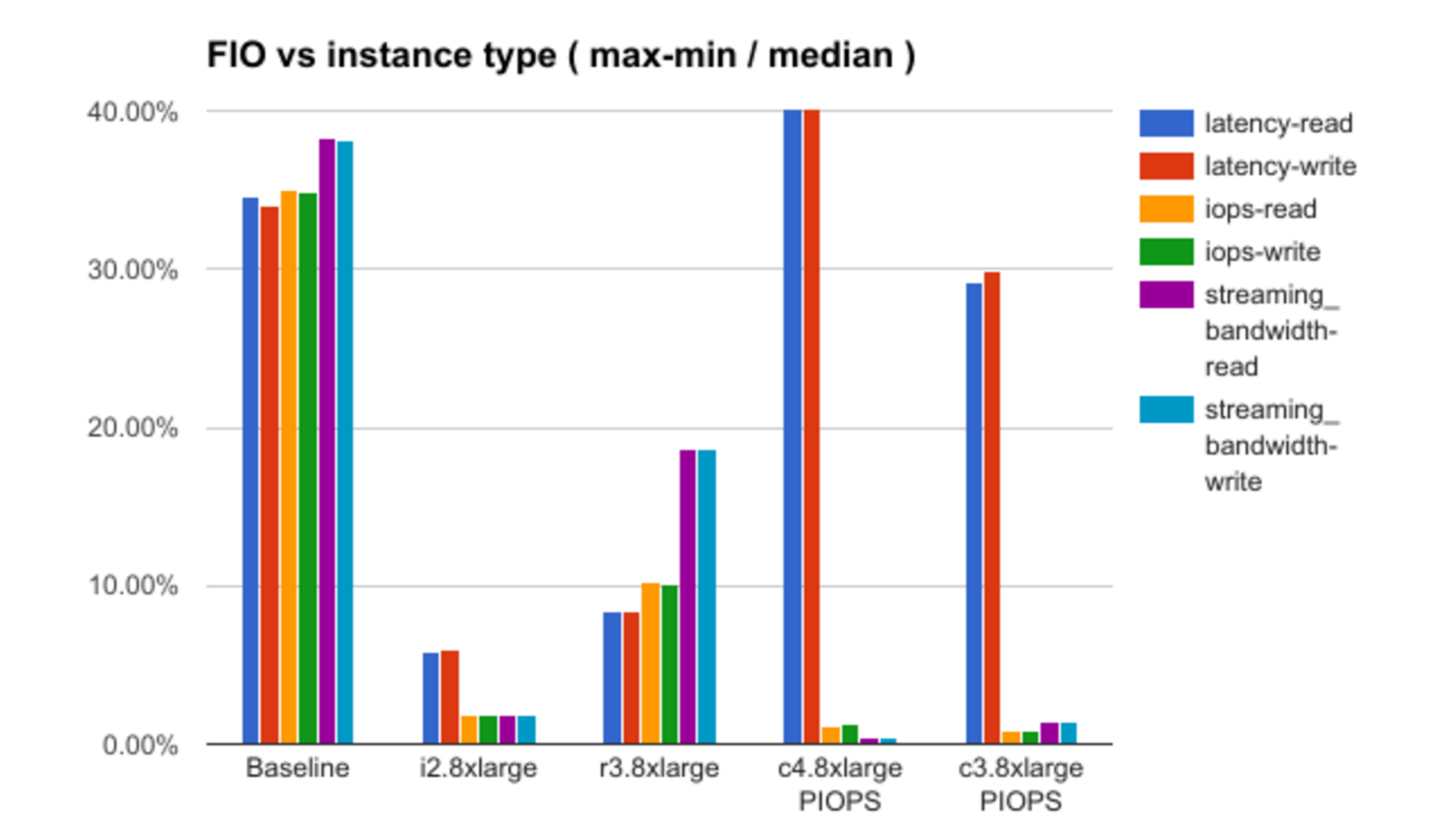
После этого разбираются результаты проверки каждой из теорий с демонстрацией некоторых интересных зависимостей. К примеру, вот график зависимости уровня «шума» (в терминологии доклада) от выбранной конфигурации инстанса:
За неимением информации о деталях инфраструктуры Amazon доклад не дает ответов на все вопросы, в некоторых случаях выдвигая лишь предположения, но и здесь есть над чем подумать.
Vytis Valentinavicius (Lamoda, lead of operations)
Следующий интересный доклад — размышления специалиста крупного интернет-магазина Lamoda о логгировании и о том, каким оно должно быть, чтобы разработчики, с одной стороны, получали необходимые данные в полном объеме, а с другой — не потонули в гигабайтах поступающей информации. И спикер знает, о чем говорит. Проблема, с которой началось выстраивание работы с логами в Lamoda — это потеря 5% отчетов, отправляемых пользователями по UDP (в отдельных случаях эта доля достигала 100%). Это серьезно искажало все метрики, которые удавалось строить на их основе.
Доклад рассказывает, не как распутывать подобную ситуацию, а как ее в принципе не допускать, учитывая, что многие очевидные решения имеют свои подводные камни.
Vytis Valentinavicius акцентирует внимание на том, что лог должен иметь структуру. Но при этом ее нельзя раздувать. Для сбора и хранения каждого поля должна быть своя цель, поскольку любые собираемые данные — это деньги. Пример Lamoda — это 25 тыс. сообщений debug log-а в секунду (32 ТБ информации в неделю, одно только хранилище для которых обходится в 12 тыс. долларов).
Кроме того, важно отслеживать не конкретные ошибки, а события. Их надо агрегировать, выявлять метрики, а на основе их анализа строить более сложные события для будущей агрегации.
Помимо теоретических размышлений, доклад содержит описание некоторых трюков, которые Lamoda использовали в продакшене для налаживания работы с логами.
Gwen Shapira (Confluent, product manager)
Следующий доклад — о мониторинге Apache Kafka, а точнее о том, какие метрики стоит выбрать из обилия доступных для анализа параметров, чтобы понимать состояние брокера сообщений в любой момент времени.
Свой рассказ спикер начала с шутки, в которой, как говорится, присутствует лишь доля шутки: «Даже если вы не сможете запомнить содержание всего доклада, запомните одно: если Kafka используется в продакшене, его надо мониторить» (благо, для этого предусмотрен соответствующий API).
Нужно ли при этом мониторить все? Зависит от поставленной задачи. От них-то и отталкивается Gwen Shapira, разбирая рекомендуемые метрики. Спикер описывает стандартные эксплуатационные кейсы и рекомендует параметры, которые надо добавить на dashboard, чтобы вовремя среагировать на происходящее, и как при этом не усугубить ситуацию. В частности, она лишний раз напоминает, что не стоит при первом изменении метрик перезапускать брокер, т.к. это требует много времени и иногда (из-за известных багов) может привести к более тяжелым последствиям. В конечном счете, метрики — это лишь начальные данные. А чтобы принимать решения, надо иметь гипотезы, основанные на этих данных.

Благодаря огромному опыту Gwen Shapira в статусе консультанта, все выступление сопровождается наглядными примерами из жизни.
Alkin Tezuysal (Percona, Global DBA team)
Сразу два доклада, попавших по оценкам участников в ТОП-5, касаются ProxySQL — средства проксирования SQL-запросов к MySQL (а с недавнего времени и ClickHouse).
Первый доклад — в целом о сценариях использования этого инструмента.
ProxySQL — решение с открытым исходным кодом, поэтому до сих пор нам на глаза не попадалась такая квинтэссенция опыта. Да, это решение скачивают многие компании, но даже сам производитель не всегда понимает, кто и в каком масштабе его будет использовать. Собранные в этом докладе сценарии были выявлены в результате общения с пользователями ProxySQL и разбора их кейсов.
В целом ProxySQL позволяет решать огромное количество задач, от балансировки нагрузки и перезаписи запросов (о которой речь пойдет в следующем докладе из нашего списка), до очереди запросов и подогрева кэша, которого нет в MySQL. Каждый из вариантов Alkin Tezuysal разбирает подробно, упоминая преимущества и недостатки решения, а также частные случаи, в которых оно может быть полезно.
Здесь упомянем лишь два примера, касающихся оптимизации работы БД.
Пример 1 — использование ProxySQL для сокращения количества запросов на установку соединения приложения с БД. Идею наглядно отражает график, приведенный в докладе:
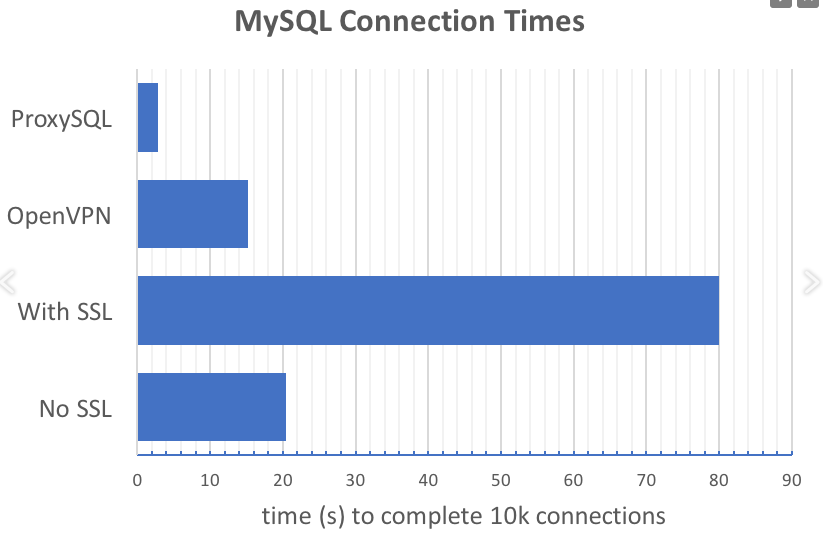
ProxySQL радикально снижает количество запросов на установку соединений, особенно в случае использования SSL.
Пример 2 — фильтрация бесполезных запросов (вроде SELECT 1, проявляющихся в масштабных приложениях), которые замедляют работу базы. Здесь результат также лучше всего оценить графически:

Rene Cannao (основатель и product owner ProxySQL)
Второй англоязычный доклад о ProxySQL, попавший в ТОП-5, посвящен решению вполне конкретной задачи — маскированию данных.
После краткого введения в ProxySQL для тех, кто не видел первый доклад, спикер погружается в возможности инструмента применительно к решению конкретной задачи — сокрытию (замене звездочками) части имени или замене реальной суммы дохода на фейковую.
Как отмечает спикер, эту задачу можно решить собственными средствами того же MySQL или сторонними продуктами. Среди сторонних ProxySQL — далеко не единственный инструмент. Однако пока на рынке нет идеального решения, а ProxySQL — не хуже многих, позволяющих разработчикам получить для тестов валидные данные, не содержащие реальную персональную информацию. При этом он имеет открытый исходный код.
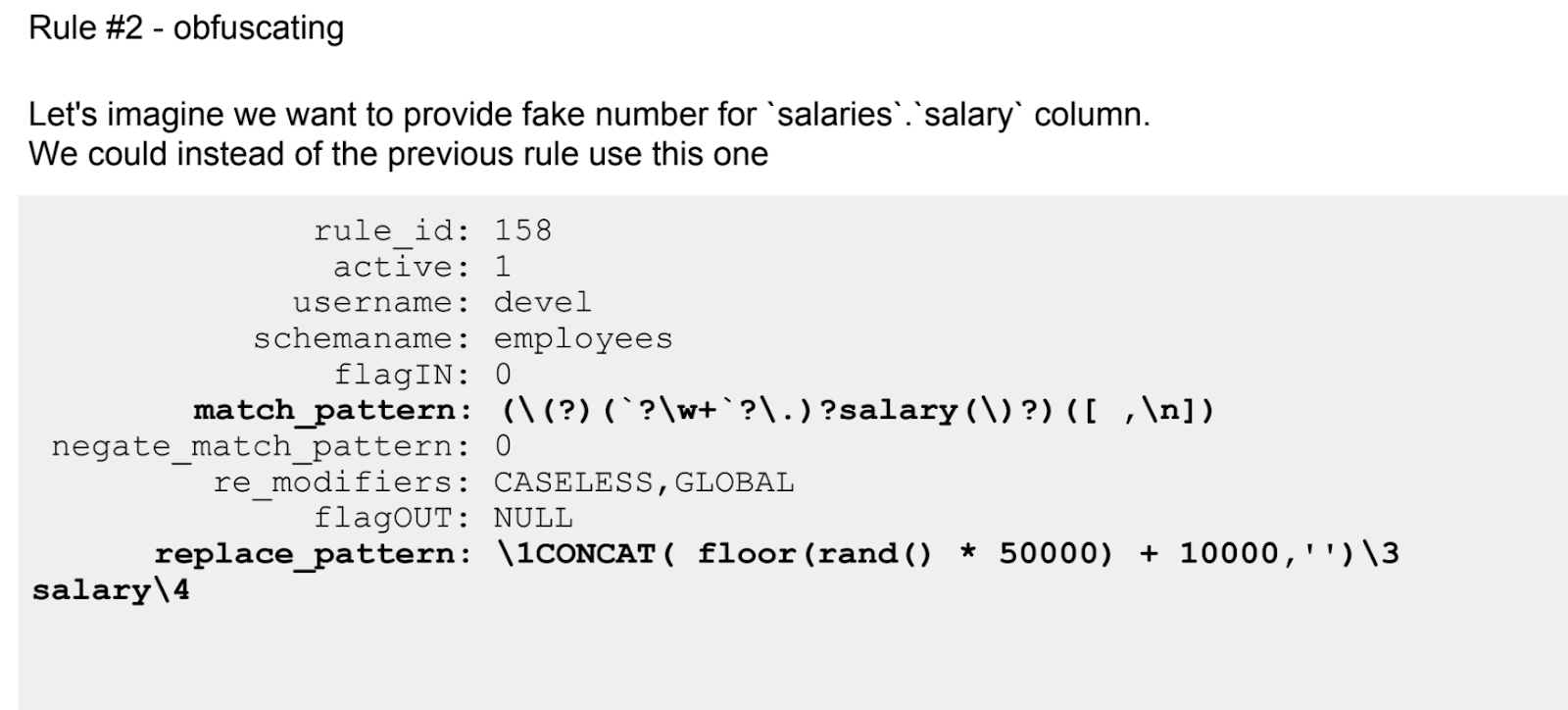
Если первый рассказ о ProxySQL был больше теоретическим, то здесь — сплошная практика. Приведены даже настроенные при помощи регулярных выражений правила.

Как и любой инструмент ProxySQL имеет свои ограничения. Об этом тоже пойдет речь. В частности, это не самый лучший подход для сложных трансформаций.
Доклад завершился полноценной секцией вопросов-ответов, из которой можно также почерпнуть много всего полезного и интересного.
Разумеется, эта англоязычная пятерка — лишь вершина того айсберга, что был на HighLoad++ 2017. Поэтому напомним, что мы только что выложили видеозаписи всех докладов конференции, которые можно найти вот в этом плей-листе.
Наивысших оценок удостоились темы, касающиеся использования ProxySQL (в ТОП-5 попало целых два доклада об этом инструменте), тестирования приложений в публичном облаке Amazon, а также принципы логгирования в масштабах, когда это становится проблемой, и мониторинг Apache Kafka.
Видеозаписи всех докладов HighLoad++ 2017 мы только что выложили в свободный доступ. Полный список из 150 докладов на нашем YouTube-канале в этом плей-листе.
Кроме этого плейлиста в канале несколько сотен видео по базам данных, архитектурам, масштабированию, очередям, машинному обучению и другим highload-премудростям :)
Measuring performance variabillity of EC2
Henrik Ingo (архитектор решений MongoDB, а сейчас ведущий инженер по производительности в Mongo DB).
Первый доклад, отмеченный участниками, приводит аргументы в пользу того, что публичное облако действительно можно использовать для тестирования собственных продуктов, в том числе, для нагрузочного тестирования. «Подопытным» в данном случае выступила СУБД MongoDB с открытым исходным кодом, которая тестируется при помощи облака Amazon. В общей сложности в месяц на эту задачу тратится порядка 400 тыс. часов, около 5% этого времени — только тесты на производительность, чья основная задача — даже не обеспечить оптимизацию, а не допустить «проседания» в результате каких-то доработок.
Ключевой вопрос выступления — как в публичном облаке получить воспроизводимые результаты тестирования?
Доклад построен по принципу разбора гипотез. Вначале Henrik Ingo высказывает предположения о том, какие факторы должны влиять на уровень «шума» в тестах (само понятие «шума» в докладе имеет вполне конкретное определение). К примеру, команда тестирования высказывала мысль о том, что на «тяжелых» тестах основной «шум» идет от жесткого диска, или о том, что в облаке при раздаче ресурсов можно «нарваться» на хорошие (полностью выделенные) или плохие (разделенные с кем-то) инстансы, что влияет на результаты тестирования.
После этого разбираются результаты проверки каждой из теорий с демонстрацией некоторых интересных зависимостей. К примеру, вот график зависимости уровня «шума» (в терминологии доклада) от выбранной конфигурации инстанса:
За неимением информации о деталях инфраструктуры Amazon доклад не дает ответов на все вопросы, в некоторых случаях выдвигая лишь предположения, но и здесь есть над чем подумать.
Logging and ranting
Vytis Valentinavicius (Lamoda, lead of operations)
Следующий интересный доклад — размышления специалиста крупного интернет-магазина Lamoda о логгировании и о том, каким оно должно быть, чтобы разработчики, с одной стороны, получали необходимые данные в полном объеме, а с другой — не потонули в гигабайтах поступающей информации. И спикер знает, о чем говорит. Проблема, с которой началось выстраивание работы с логами в Lamoda — это потеря 5% отчетов, отправляемых пользователями по UDP (в отдельных случаях эта доля достигала 100%). Это серьезно искажало все метрики, которые удавалось строить на их основе.
Доклад рассказывает, не как распутывать подобную ситуацию, а как ее в принципе не допускать, учитывая, что многие очевидные решения имеют свои подводные камни.
Vytis Valentinavicius акцентирует внимание на том, что лог должен иметь структуру. Но при этом ее нельзя раздувать. Для сбора и хранения каждого поля должна быть своя цель, поскольку любые собираемые данные — это деньги. Пример Lamoda — это 25 тыс. сообщений debug log-а в секунду (32 ТБ информации в неделю, одно только хранилище для которых обходится в 12 тыс. долларов).
Кроме того, важно отслеживать не конкретные ошибки, а события. Их надо агрегировать, выявлять метрики, а на основе их анализа строить более сложные события для будущей агрегации.
Помимо теоретических размышлений, доклад содержит описание некоторых трюков, которые Lamoda использовали в продакшене для налаживания работы с логами.
Metrics are Not Enough: Monitoring Apache Kafka
Gwen Shapira (Confluent, product manager)
Следующий доклад — о мониторинге Apache Kafka, а точнее о том, какие метрики стоит выбрать из обилия доступных для анализа параметров, чтобы понимать состояние брокера сообщений в любой момент времени.
Свой рассказ спикер начала с шутки, в которой, как говорится, присутствует лишь доля шутки: «Даже если вы не сможете запомнить содержание всего доклада, запомните одно: если Kafka используется в продакшене, его надо мониторить» (благо, для этого предусмотрен соответствующий API).
Нужно ли при этом мониторить все? Зависит от поставленной задачи. От них-то и отталкивается Gwen Shapira, разбирая рекомендуемые метрики. Спикер описывает стандартные эксплуатационные кейсы и рекомендует параметры, которые надо добавить на dashboard, чтобы вовремя среагировать на происходящее, и как при этом не усугубить ситуацию. В частности, она лишний раз напоминает, что не стоит при первом изменении метрик перезапускать брокер, т.к. это требует много времени и иногда (из-за известных багов) может привести к более тяжелым последствиям. В конечном счете, метрики — это лишь начальные данные. А чтобы принимать решения, надо иметь гипотезы, основанные на этих данных.
Благодаря огромному опыту Gwen Shapira в статусе консультанта, все выступление сопровождается наглядными примерами из жизни.
ProxySQL Use Case Scenarios
Alkin Tezuysal (Percona, Global DBA team)
Сразу два доклада, попавших по оценкам участников в ТОП-5, касаются ProxySQL — средства проксирования SQL-запросов к MySQL (а с недавнего времени и ClickHouse).
Первый доклад — в целом о сценариях использования этого инструмента.
ProxySQL — решение с открытым исходным кодом, поэтому до сих пор нам на глаза не попадалась такая квинтэссенция опыта. Да, это решение скачивают многие компании, но даже сам производитель не всегда понимает, кто и в каком масштабе его будет использовать. Собранные в этом докладе сценарии были выявлены в результате общения с пользователями ProxySQL и разбора их кейсов.
В целом ProxySQL позволяет решать огромное количество задач, от балансировки нагрузки и перезаписи запросов (о которой речь пойдет в следующем докладе из нашего списка), до очереди запросов и подогрева кэша, которого нет в MySQL. Каждый из вариантов Alkin Tezuysal разбирает подробно, упоминая преимущества и недостатки решения, а также частные случаи, в которых оно может быть полезно.
Здесь упомянем лишь два примера, касающихся оптимизации работы БД.
Пример 1 — использование ProxySQL для сокращения количества запросов на установку соединения приложения с БД. Идею наглядно отражает график, приведенный в докладе:
ProxySQL радикально снижает количество запросов на установку соединений, особенно в случае использования SSL.
Пример 2 — фильтрация бесполезных запросов (вроде SELECT 1, проявляющихся в масштабных приложениях), которые замедляют работу базы. Здесь результат также лучше всего оценить графически:
Inexpensive Datamasking for MySQL with ProxySQL — Data Anonymization for Developers
Rene Cannao (основатель и product owner ProxySQL)
Второй англоязычный доклад о ProxySQL, попавший в ТОП-5, посвящен решению вполне конкретной задачи — маскированию данных.
После краткого введения в ProxySQL для тех, кто не видел первый доклад, спикер погружается в возможности инструмента применительно к решению конкретной задачи — сокрытию (замене звездочками) части имени или замене реальной суммы дохода на фейковую.
Как отмечает спикер, эту задачу можно решить собственными средствами того же MySQL или сторонними продуктами. Среди сторонних ProxySQL — далеко не единственный инструмент. Однако пока на рынке нет идеального решения, а ProxySQL — не хуже многих, позволяющих разработчикам получить для тестов валидные данные, не содержащие реальную персональную информацию. При этом он имеет открытый исходный код.
Если первый рассказ о ProxySQL был больше теоретическим, то здесь — сплошная практика. Приведены даже настроенные при помощи регулярных выражений правила.
Как и любой инструмент ProxySQL имеет свои ограничения. Об этом тоже пойдет речь. В частности, это не самый лучший подход для сложных трансформаций.
Доклад завершился полноценной секцией вопросов-ответов, из которой можно также почерпнуть много всего полезного и интересного.
Разумеется, эта англоязычная пятерка — лишь вершина того айсберга, что был на HighLoad++ 2017. Поэтому напомним, что мы только что выложили видеозаписи всех докладов конференции, которые можно найти вот в этом плей-листе.
HighLoad++ 2018 состоится 8 и 9 ноября в Москве, в Сколково. Работа над программой уже идет, но подать доклад можно до 1 сентября.
jazzl0ver
Запилил пару нагиос-скриптов для проверки разделов Кафки:
check_kafka_unavailparts.sh: gist.github.com/jazzl0ver/144b8880ddcaee7f3f0095a448cbd5ed
check_kafka_urp.sh: gist.github.com/jazzl0ver/856cf99ac7183e22f5b5cdfce09e4cb3
Вдруг кому надо…
(Для запуска, необходим docker)