

О спикере: Виктор Билык внедряет продукты машинного обучения в промышленную эксплуатацию в Booking.com.
Сначала давайте посмотрим, где Booking.com применяет машинное обучение, в каких продуктах.
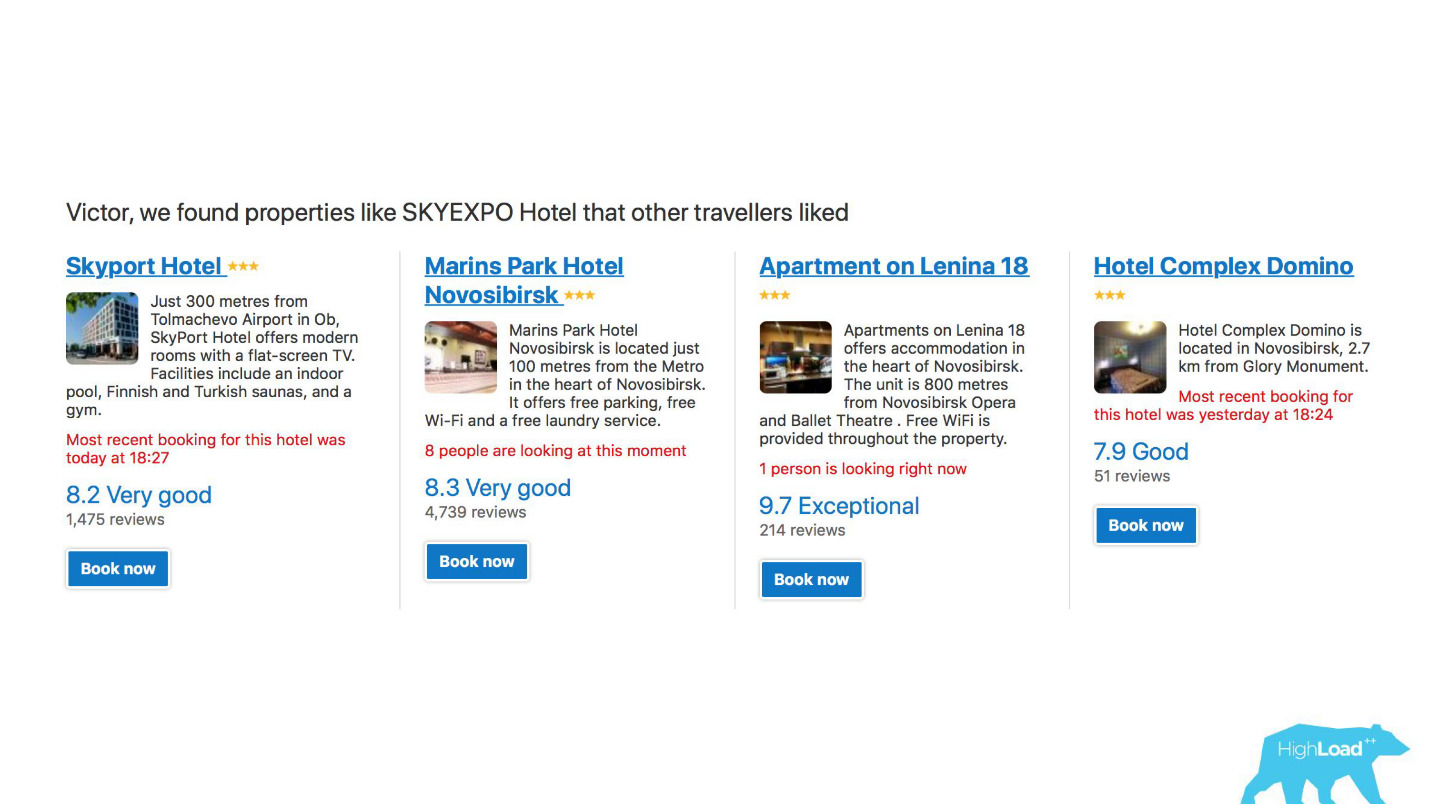
Во-первых, это большое количество рекомендательных систем для отелей, направлений, дат, причем в разных точках воронки продаж и в разных контекстах. Например, мы пытаемся угадать, куда вы поедете, когда вы еще вообще ничего не ввели в поисковую строчку.

Это скриншот в моем аккаунте, и в двух из этих направлений в этом году я обязательно побываю.
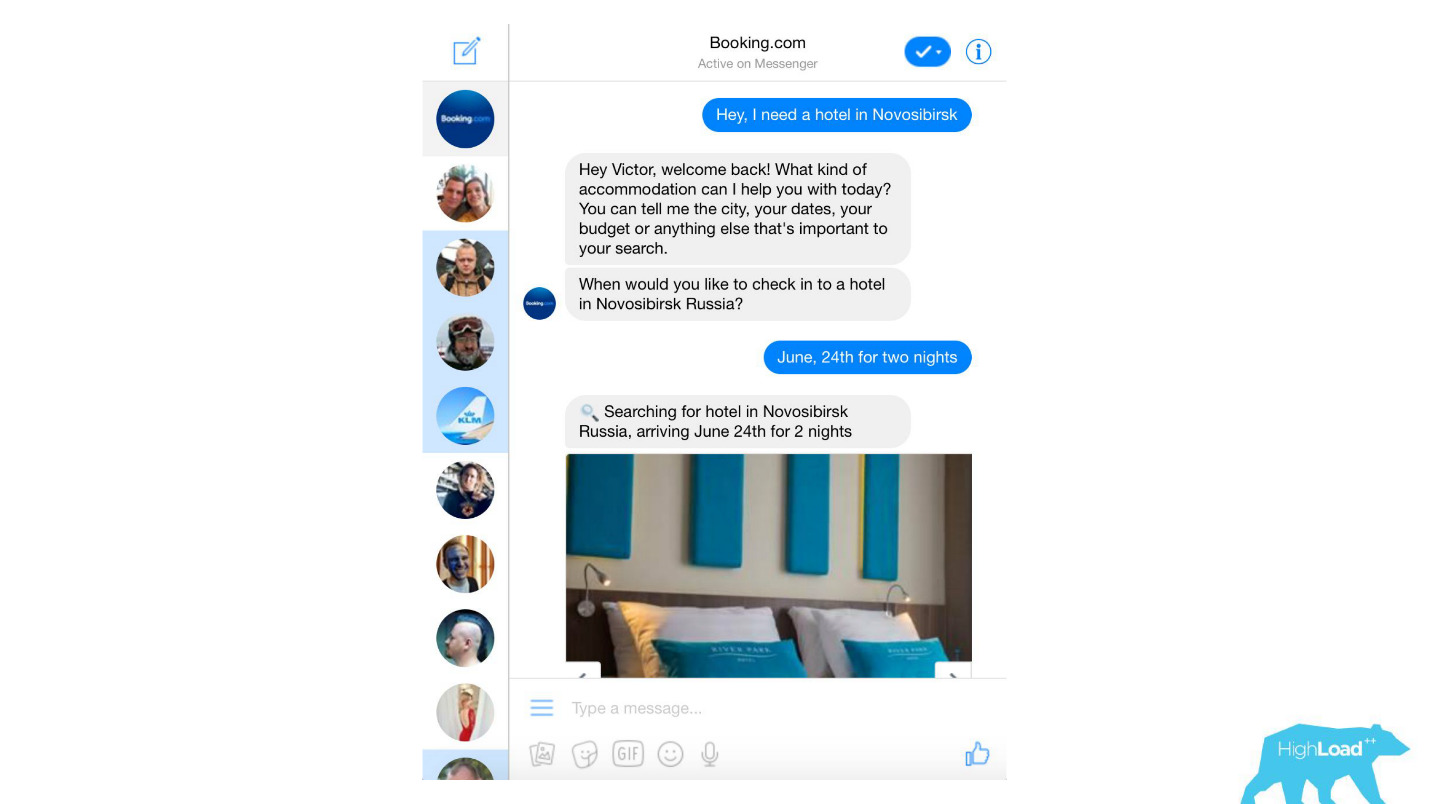
У нас обрабатываются моделями практически любые текстовые сообщения от клиентов, начиная с банальных спам-фильтров, заканчивая такими сложными продуктами, как Assistant и ChatToBook, где используются модели для определения намерений и распознавания сущностей. Кроме того, есть модели, которые не так заметны, например, Fraud Detection.
Мы анализируем отзывы. Модели нам говорят, зачем люди едут, скажем, в Берлин.
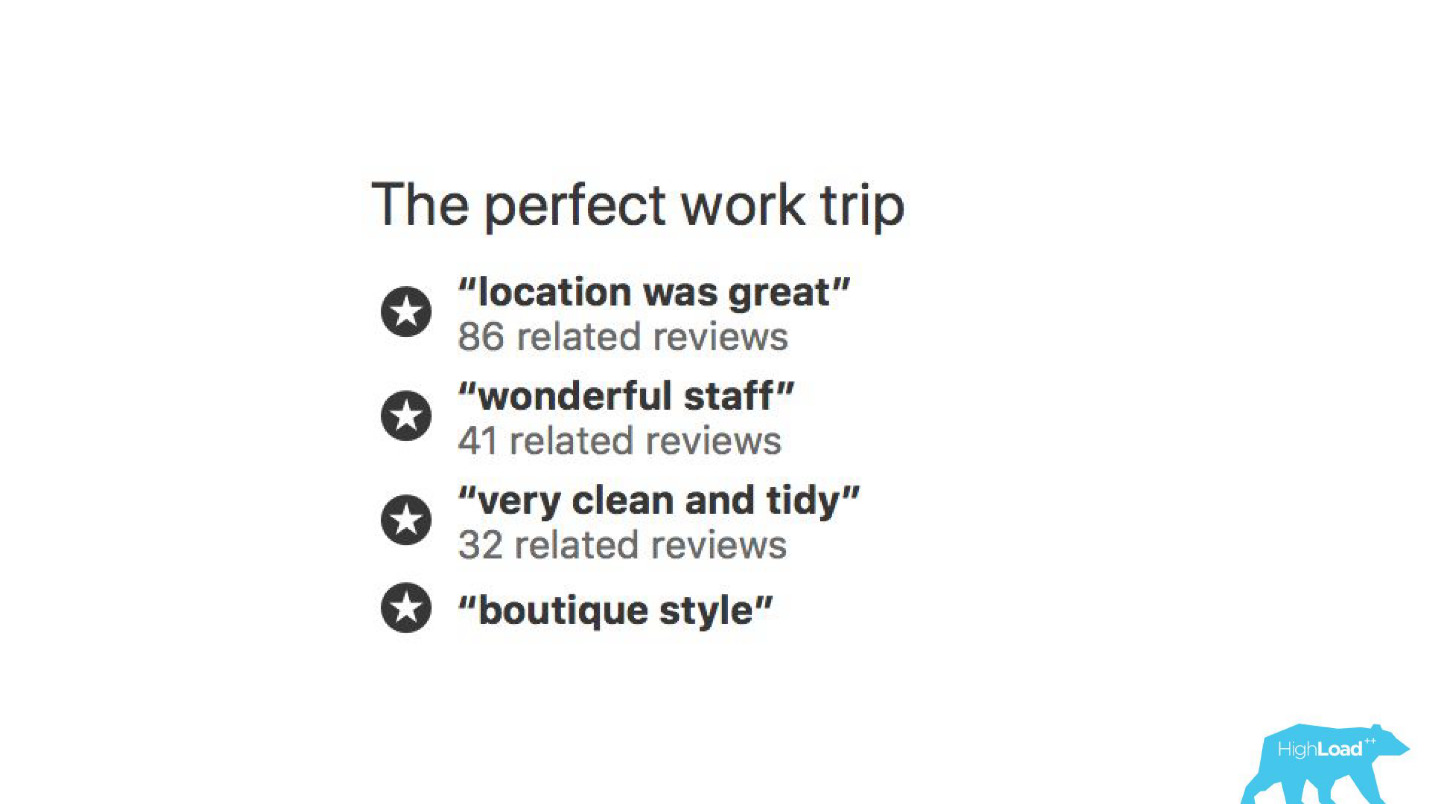
С помощью моделей машинного обучения анализируется, за что хвалят отель, чтобы вам не приходилось читать тысячи отзывов самим.
В некоторых местах нашего интерфейса практически каждый кусочек завязан на предсказаниях каких-то моделей. Например, здесь мы пытаемся предсказать, когда отель будет распродан.
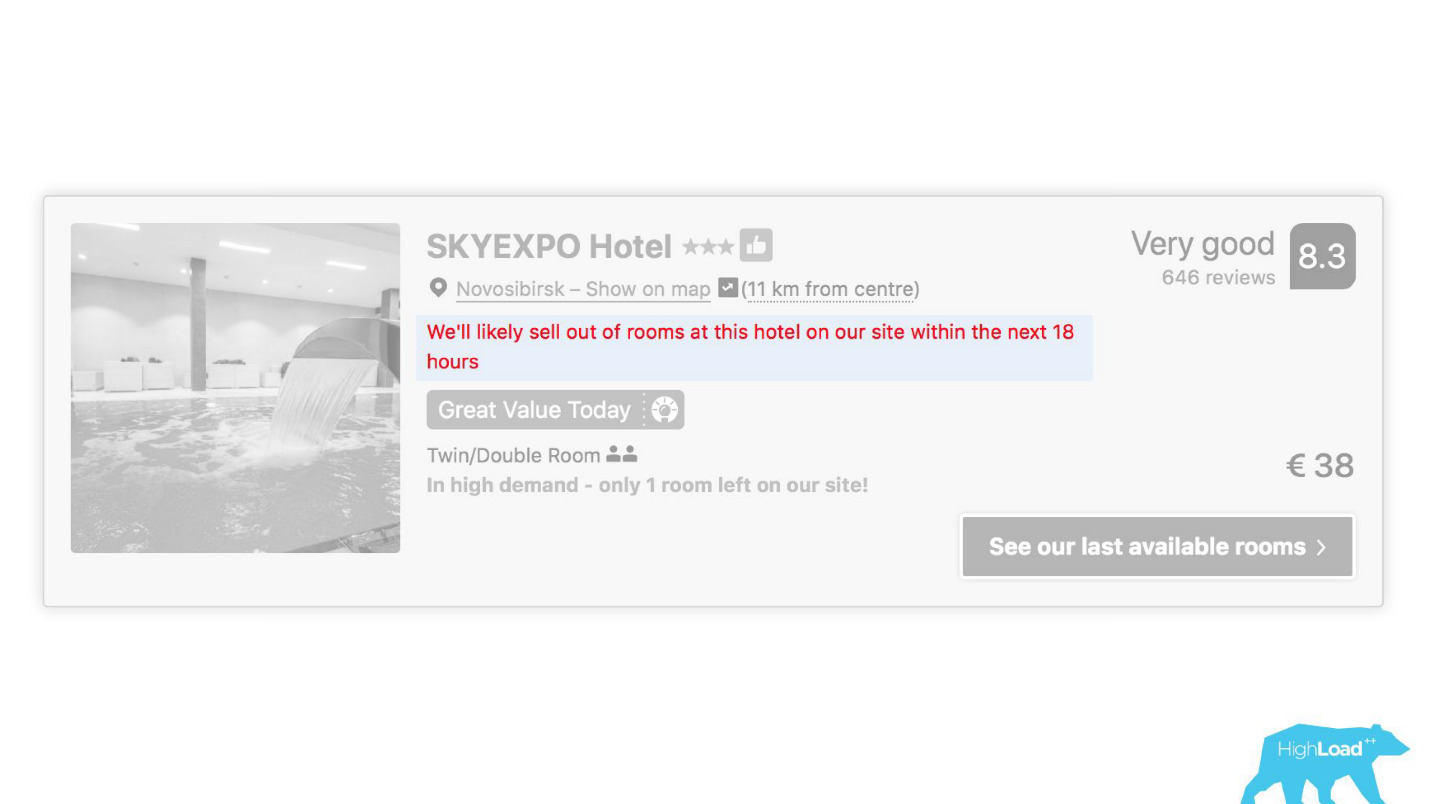
Часто оказываемся правы — через 19 часов последняя комната уже забронирована.
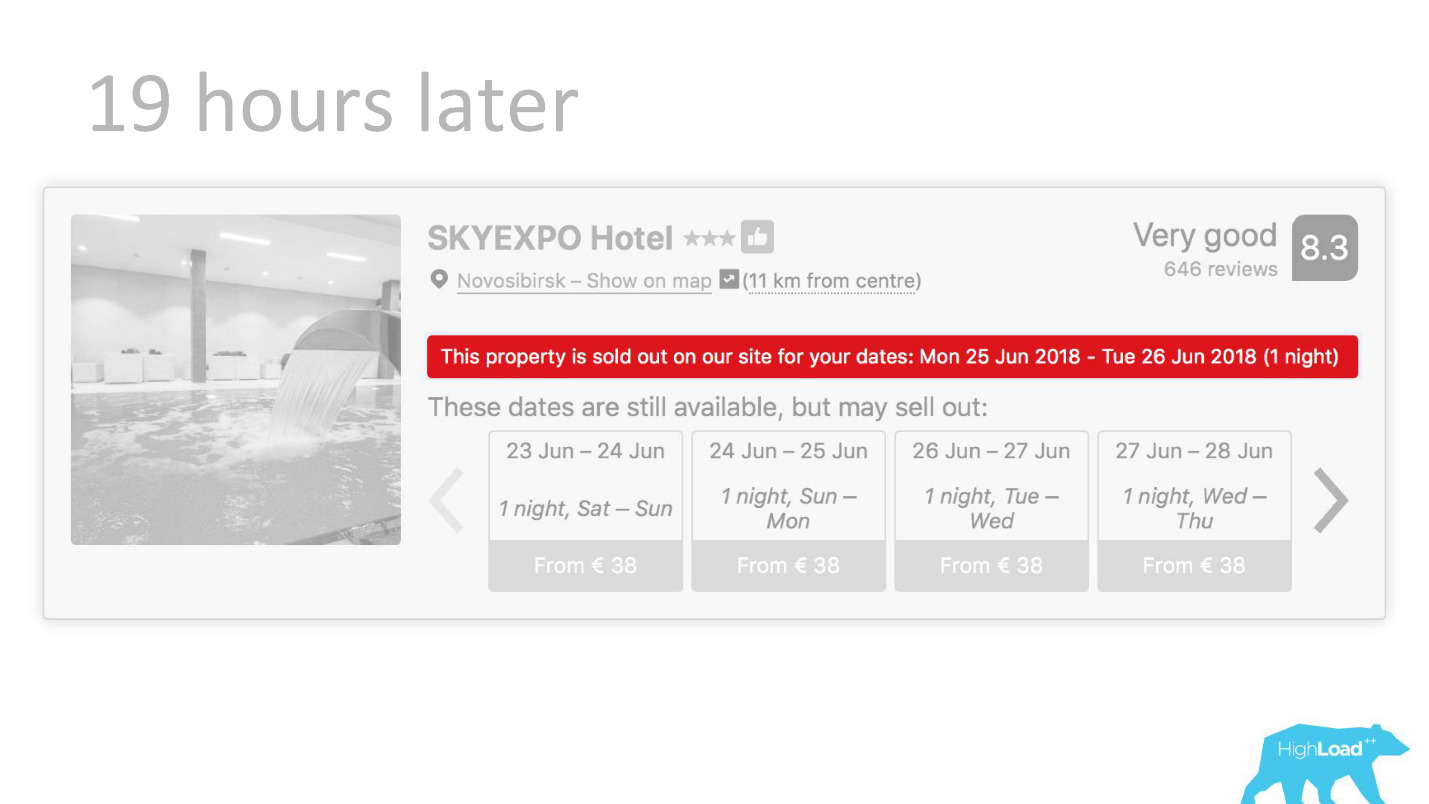
Или, например, — бейдж «Выгодное предложение». Здесь мы пытаемся формализовать субъективное: что вообще такое выгодное предложение. Как понять, что цены, выставленные отелем на эти даты, хороши? Ведь это, кроме цены, зависит от многих факторов, таких как дополнительные услуги, а зачастую вообще от внешних причин, если, например, в этом городе сейчас проходит чемпионат мира по футболу или большая техническая конференция.
Начало внедрения
Давайте отмотаем на несколько лет назад, в 2015 год. Некоторые из продуктов, о которых я говорил, уже существуют. При этом системы, о которой я буду сегодня рассказывать, еще нет. Как же в то время происходило внедрение? Дела были, прямо скажем, не очень. Дело в том, что у нас была огромная проблема, часть которой — техническая, а часть — организационная.
Мы отправляли дейтасайентистов в уже существующие кросс-функциональные команды, которые работают над определенной пользовательской проблемой, и ожидали, что они как-то будут улучшать продукт.
Чаще всего эти кусочки продукта были построены на Perl-стеке. С Perl есть вполне очевидная проблема — он не создан для интенсивных вычислений, и наш бэкенд уже нагружен другими вещами. При этом разработку серьезных систем, которые решали бы эту проблему, приоритезировать внутри команды бы не удалось, потому что фокус команды на решении пользовательской проблемы, а не на решении пользовательской проблемы с помощью машинного обучения. Поэтому Product Owner (PO) был бы весьма против этого.
Давайте разберемся, как это тогда происходило.
Вариантов было всего два — я это знаю точно, потому что в то время я как раз работал в такой команде и помогал дейтасайентистам выводить их первые модели в бой.
Первый вариант — это была материализация предсказаний. Предположим, есть очень простая модель с всего двумя фичами:
- страна, где находится посетитель;
- город, в котором он ищет себе отель.
Нам нужно предсказать вероятность какого-то события. Мы просто взрываем все входные векторы: скажем, 100 000 городов, 200 стран — итого 20 миллионов строчек в MySQL. Звучит, как вполне работоспособный вариант для вывода в продакшен каких-то небольших систем ранжирования или других простеньких моделей.

Другой вариант — это встраивание предсказаний прямо в бэкенд-код. Тут есть большие ограничения — сотни, может быть, тысячи коэффициентов — это все, что мы могли себе позволить.

Очевидно, ни один, ни другой способ не позволяют вывести хоть сколько-нибудь сложную модель в продакшен. Это ограничивало дейтасайентистов и успехи, которые они могли бы достичь улучшая продукты. Очевидно, эту проблему нужно было как-то решать.
Сервис предсказаний
Первое, что мы сделали — сервис предсказаний. Вероятно, эниже самая простая архитектура, когда-либо показанная на Хабре и HighLoad++.
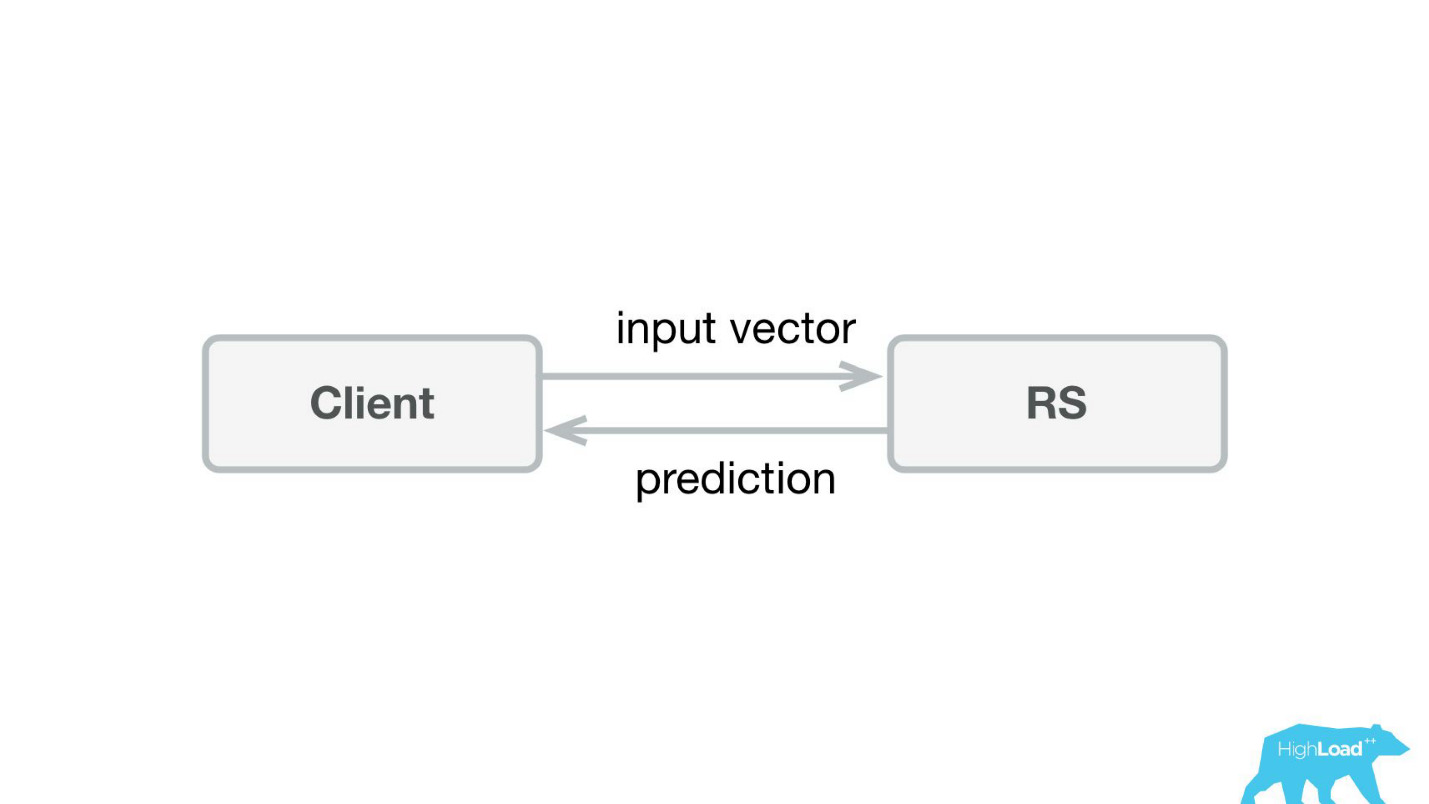
Мы написали небольшое приложение на Scala+Akka+Spray, которое просто принимало входящие векторы и отдавало предсказание обратно. На самом деле, я немножко лукавлю — система была чуть-чуть сложнее, потому что нам нужно было как-то это мониторить и выкатывать. В реальности это все выглядело так:
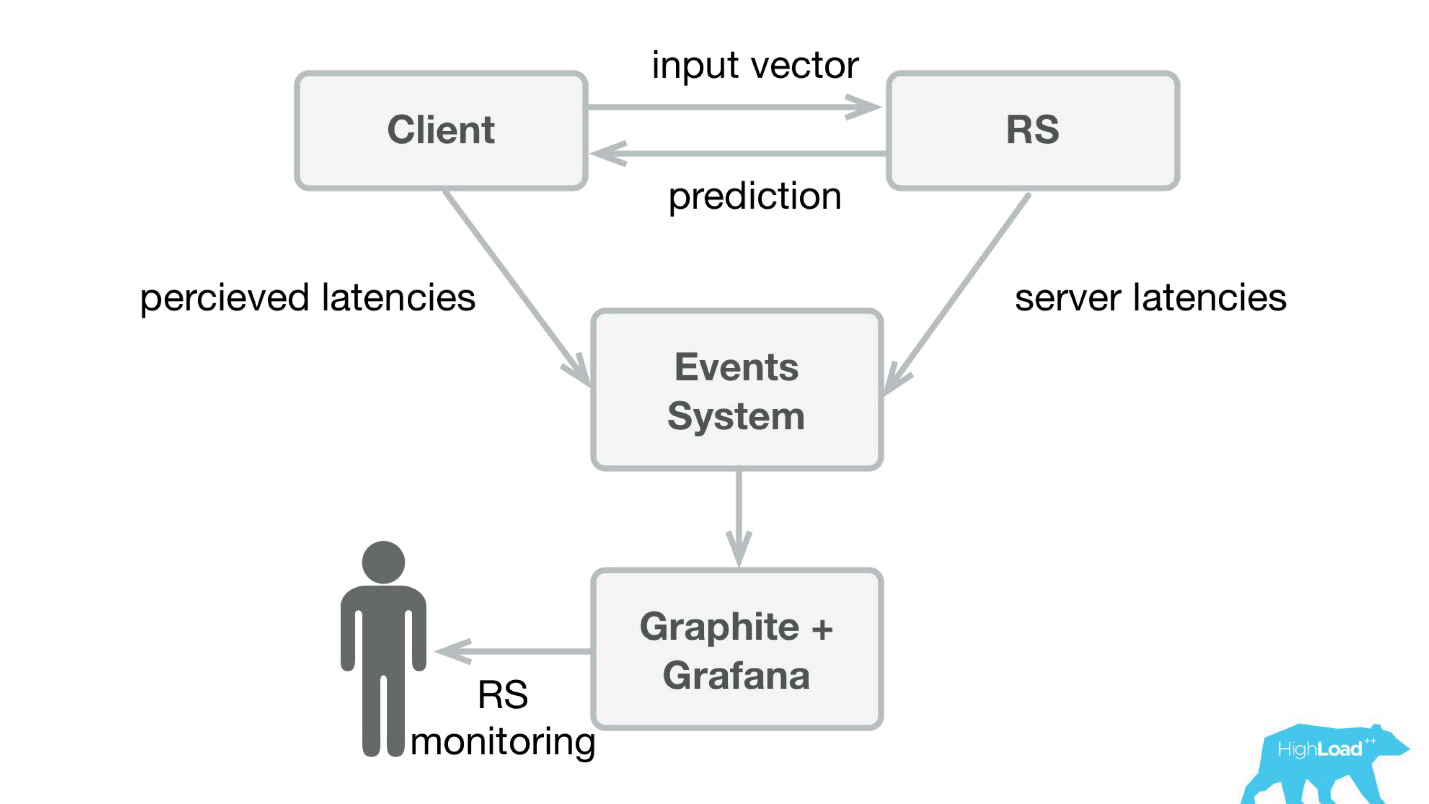
В Booking.com есть система событий — что-то вроде журнала для всех систем. Туда очень просто писать, и этот поток очень просто перенаправлять. На первых порах нам нужно было мы отправляли в Graphite и Grafana клиентскую телеметрию с perceived latencies и подробную информацию с серверной стороны.

Мы сделали простые клиентские библиотеки для Perl — спрятали весь RPC в локальный вызов, поместили туда несколько моделей и сервис начал взлетать. Продать такой продукт было достаточно просто, потому что мы получили возможность внедрять более сложные модели и тратить при этом гораздо меньше времени.
Дейтасайентисты начали работать с гораздо меньшими ограничениями, а работа бэкендеров в некоторых случаях сводилась к однострочнику.
Предсказания в продукте
Но давайте ненадолго вернемся к тому, как мы пользовались этими предсказаниями в продукте.
Есть модель, которая на основе известных фактов делает предсказание. Базируясь на этом предсказании, мы как-то меняем пользовательский интерфейс. Это, конечно, не единственный сценарий использования машинного обучения у нас в компании, но достаточно распространенный.
В чем же проблема запуска таких фич? Все дело в том, что это две вещи в одном флаконе: модель и изменение пользовательского интерфейса. Очень сложно разделить эффекты от того и от другого.
Представьте, запускаем бейдж «Выгодное предложение» в рамках AB-эксперимента. Если он не взлетает — нет никакого статистически значимого изменения целевых метрик — неизвестно, в чем проблема: непонятный, маленький, незаметный бейдж или плохая модель.
К тому же модели могут деградировать, и причин для этого может быть очень много. То, что работало вчера, необязательно работает сегодня. К тому же мы постоянно находимся в режиме cold-старта, постоянно подключаем новые города и отели, люди из новых городов приходят к нам. Нам нужно как-то понимать, что модель все еще хорошо обобщает и в этих кусочках входящего пространства.

Самым, наверное, известным в последнее время случаем деградации модели была история с Алексой. Скорее всего, в результате переобучения она начала понимать случайные шумы, как просьбу посмеяться, и начинала заходиться хохотом по ночам, пугая владельцев.
Мониторинг предсказаний
Для того чтобы мониторить предсказания, мы немного доработали нашу систему (схема ниже). Точно также из event-системы перенаправили поток в Hadoop и начали сохранять, помимо всего, что мы сохраняли раньше, еще и все входные векторы, и все предсказания, которые сделала наша система. Потом с помощью Oozie мы их агрегировали в MySQL и оттуда показывали небольшим веб-приложением тем, кто заинтересован в каких-то качественных характеристиках моделей.
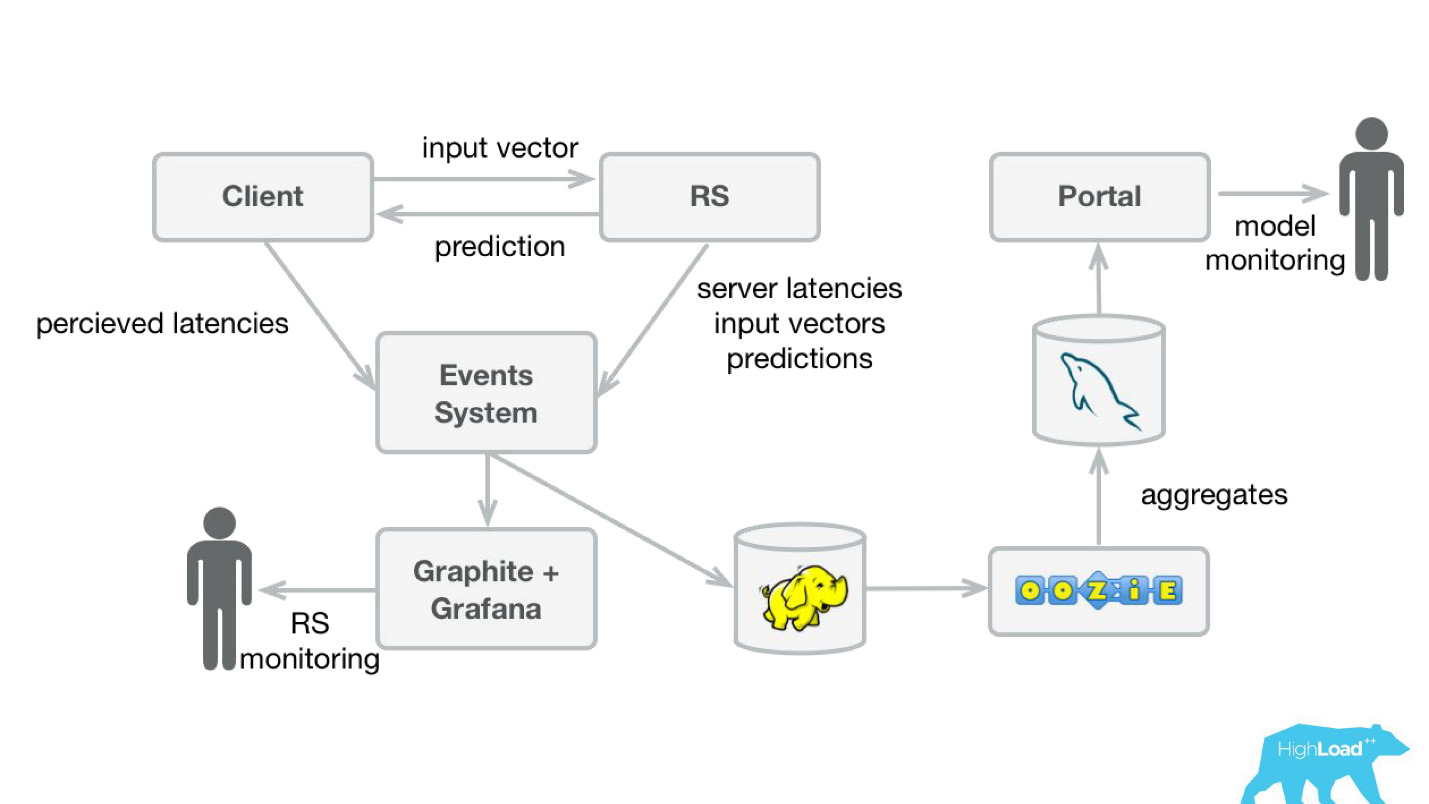
Однако, важно разобраться, что там показывать. Все дело в том, что посчитать обычные метрики, использующиеся при обучении моделей, в нашем случае очень тяжело, потому что зачастую у нас гигантская задержка лейблов.
Рассмотрим это на примере. Мы хотим предсказать, едет ли пользователь в отпуск один или с семьей. Это предсказание нам нужно, когда человек выбирает отель, но правду мы сможем узнать только через год. Только уже съездив в отпуск, пользователь получит приглашение оставить отзыв, где среди прочего будет вопрос, был ли он там один или с семьей.
То есть нужно где-то хранить все предсказания, сделанные за год, да еще и так, чтобы можно было быстро найти соответствия с входящими лейблами. Это звучало, как очень серьезная, может быть, даже неподъемная инвестиция. Поэтому пока мы не справились с этой проблемой, мы решили сделать что-нибудь попроще.
Этим «попроще» оказалась просто гистограмма предсказаний, сделанных моделью.
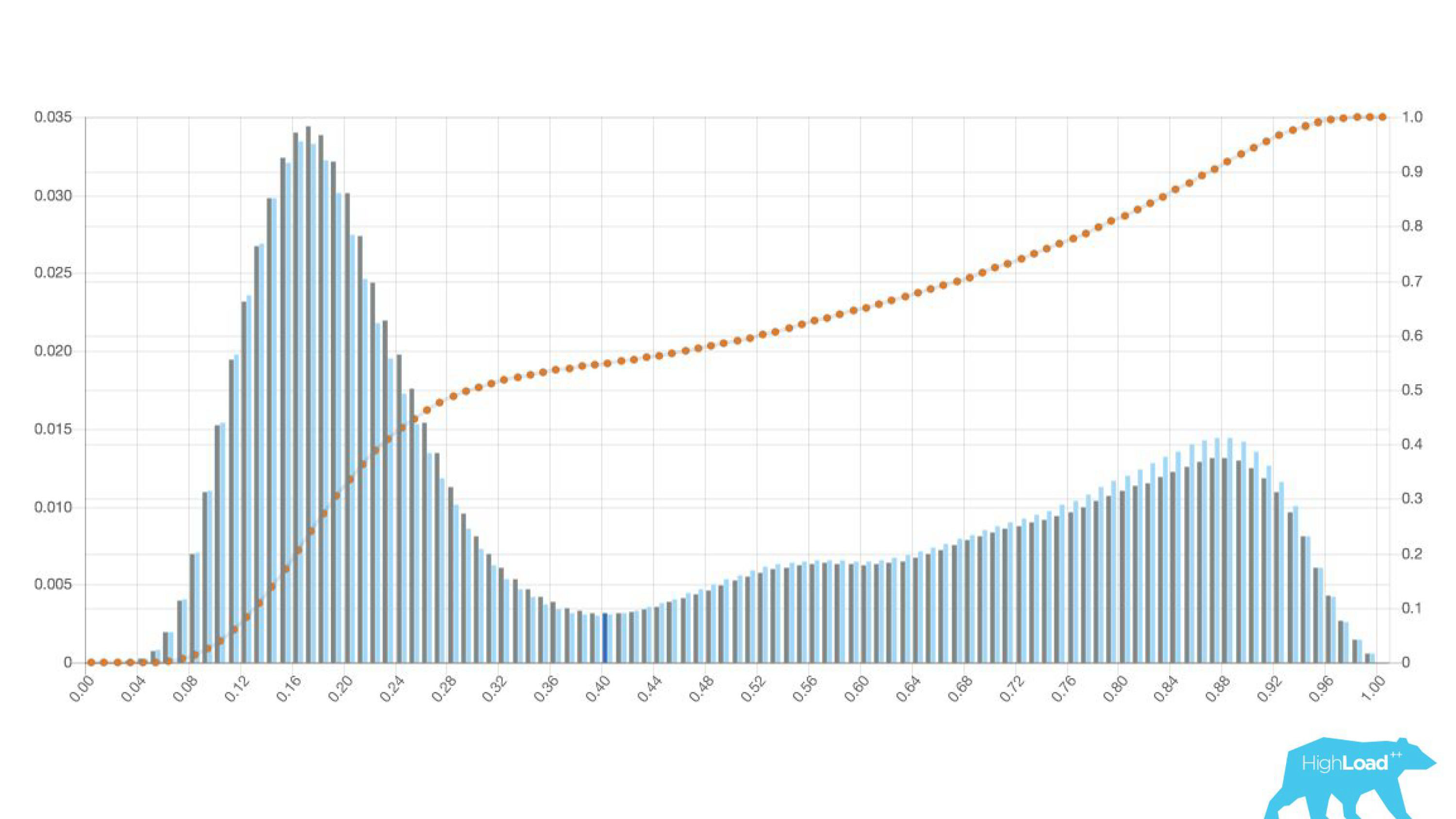
Выше на графике логистическая регрессия, которая предсказывает, поменяет пользователь дату своего путешествия или нет. Видно, что она неплохо разделяет пользователей на два класса: слева холм — это те, кто не сделают этого; справа холм — те, кто это сделает.
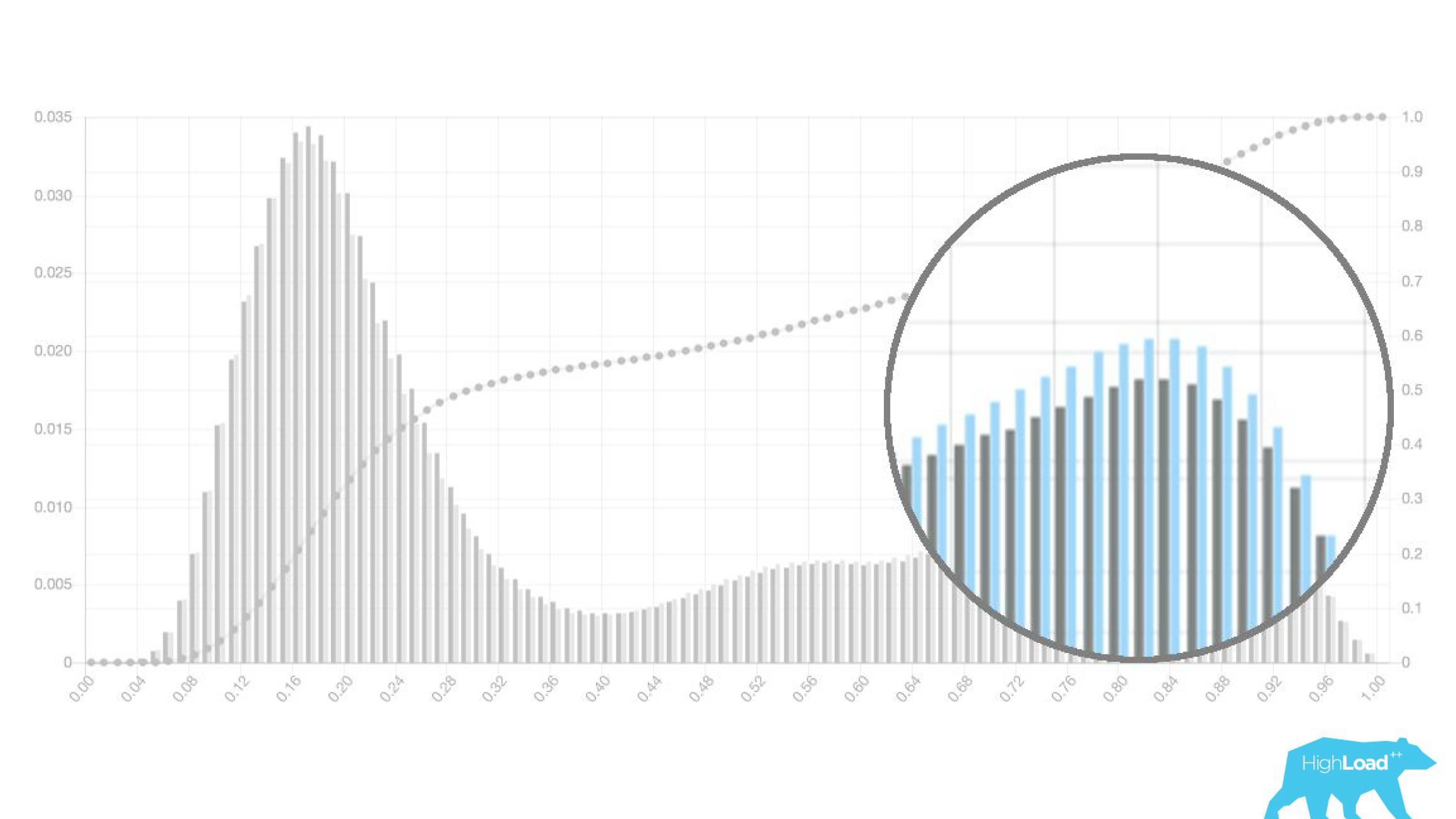
На самом деле мы показываем даже два графика: один за текущий период, а другой за предыдущий. Хорошо видно, что на этой неделе (это недельный график) модель предсказывает смену дат немножко чаще. Трудно точно сказать, сезонность это, или та самая деградация со временем.
Это привело к изменению процесса работы дейтасайентистов, которые перестали вовлекать других людей и начали быстрее итерировать свои модели. Они отправляли модели в продакшен в dry-run вместе с бэкенд-инженерами. То есть векторы собирались, модель делала предсказание, но эти предсказания никак не использовались.
В случае бейджа мы просто ничего не показывали, как и раньше, а собирали статистику. Это позволило нам не тратить время на заранее провальные проекты. Мы освободили время фронтэндеров и дизайнеров для других экспериментов. Пока дейтасайентист не уверен в том, что модель работает так, как он хочет, он просто не вовлекает в этот процесс других.
Интересно посмотреть, как графики меняются в различных разрезах.
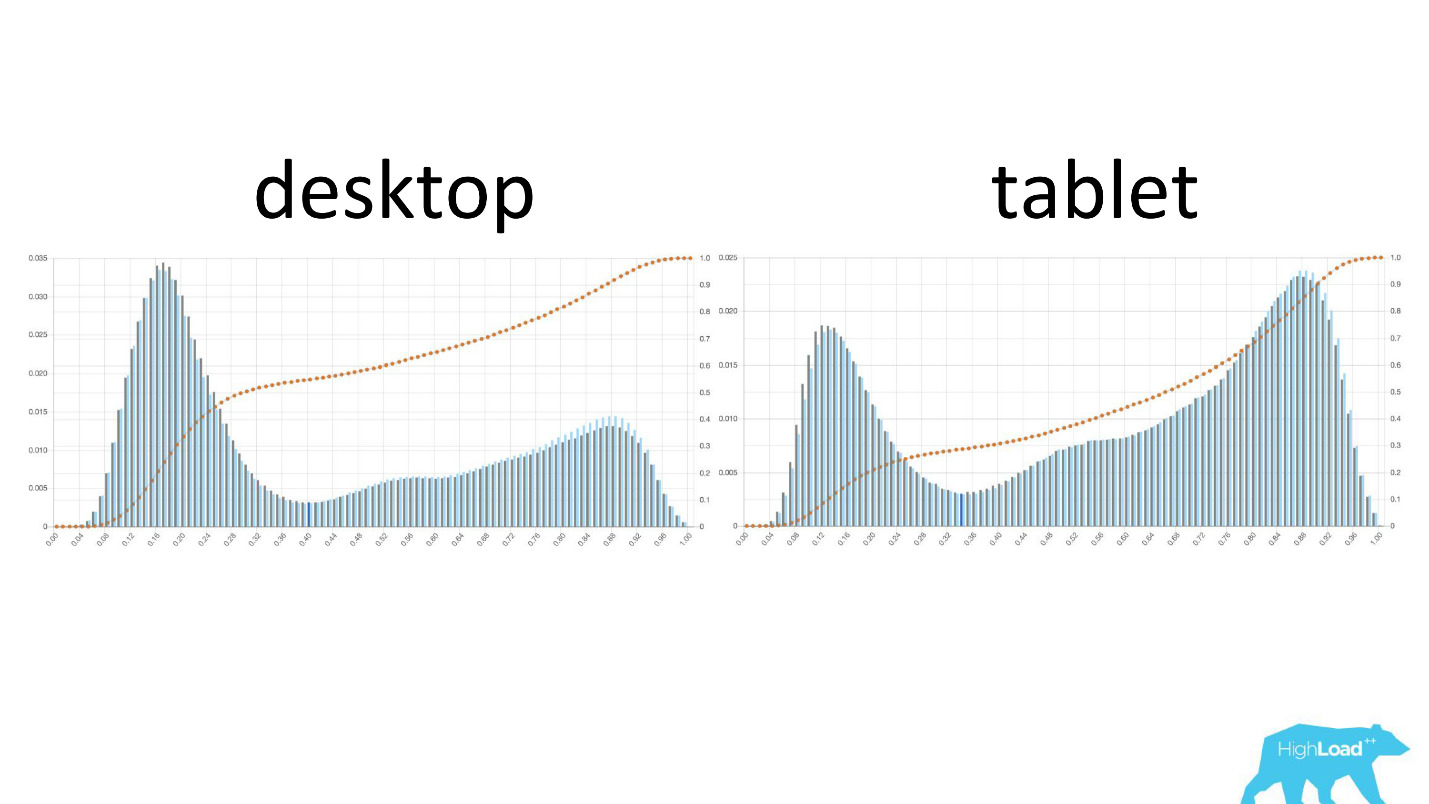
Слева — вероятность смены дат на десктопе, справа — на планшетах. Хорошо видно, что на планшетах модель предсказывает более вероятную смену дат. Это, скорее всего, связано с тем, что планшет часто используют для планирования путешествия и реже для бронирования.
Еще интересно смотреть, как эти графики меняются по мере движения пользователей по воронке продаж.
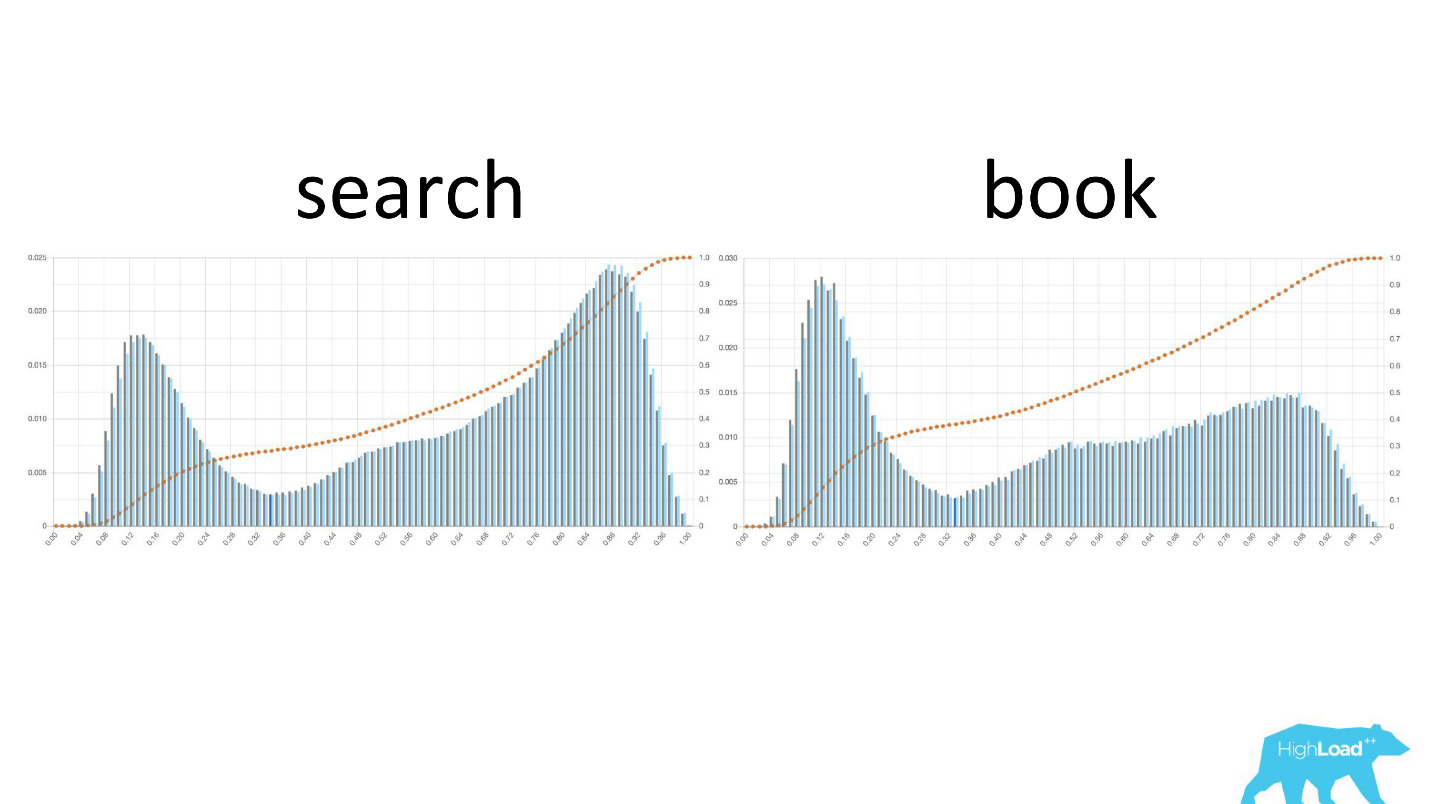
Слева вероятность смены дат на страничке поиска, справа — на первой страничке бронирования. Видно, что до странички бронирования добирается гораздо большее количество людей, которые уже определились со своими датами.
Но это были хорошие графики. Как выглядят плохие? Очень по-разному. Иногда это просто шум, иногда огромный холм, что означает, что модель не может эффективно разделить какие-то два класса предсказаний.

Иногда это огромные пики.
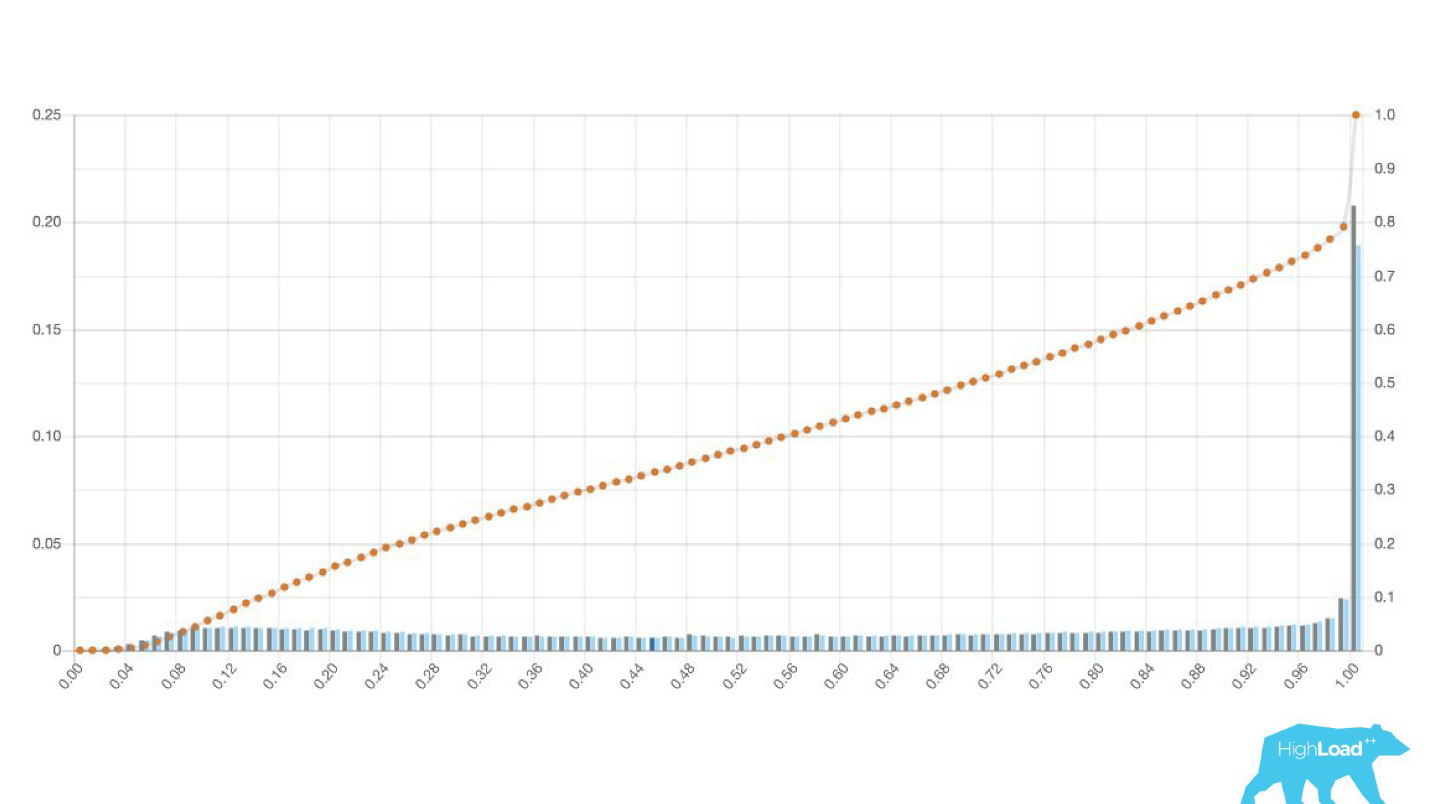
Это тоже логистическая регрессия, и до какого-то момента она показывала красивую картинку с двумя холмами, но одним утром она стала такой.
Для того, чтобы понять, что произошло внутри, нужно понимать, как вычисляется логистическая регрессия.
Краткая справка
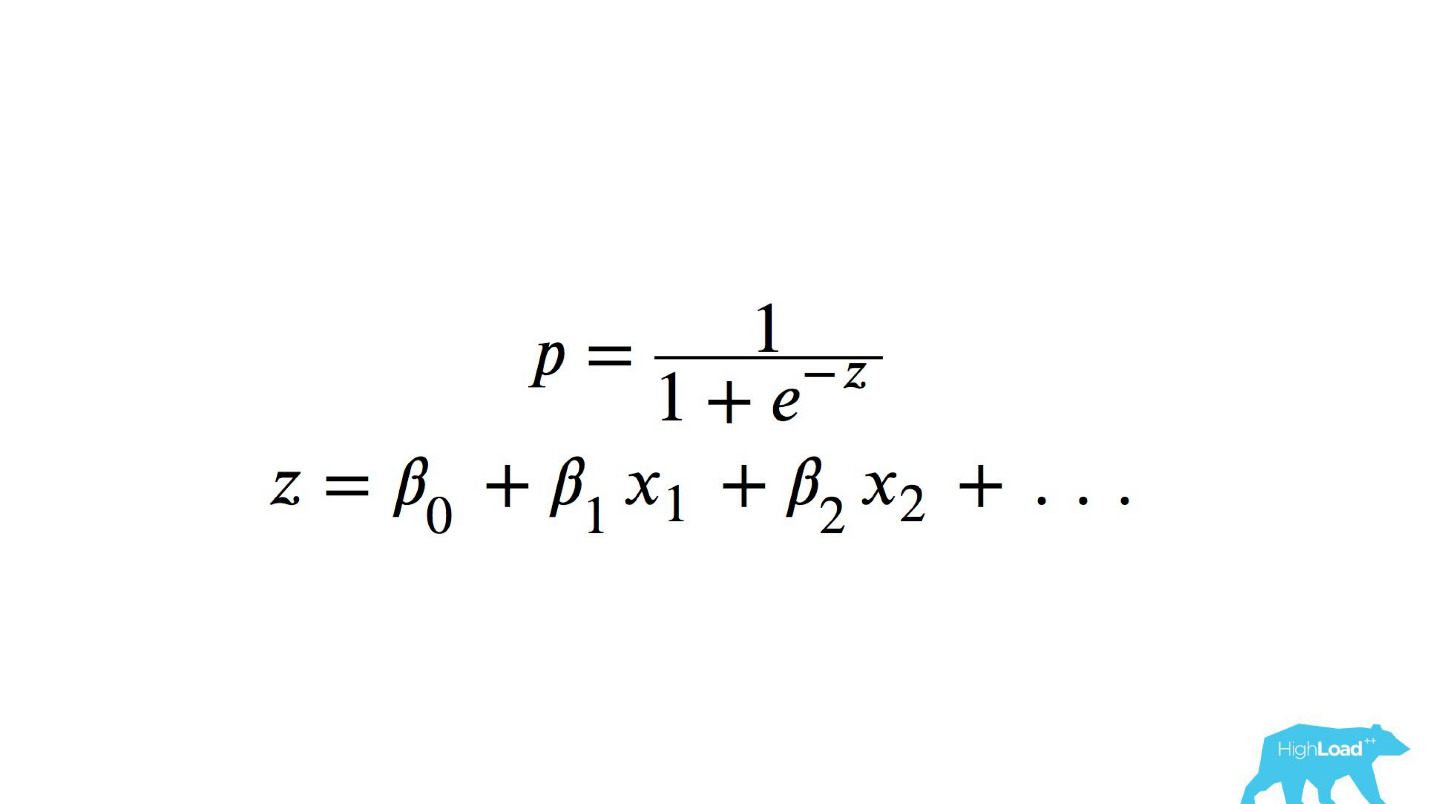
Это логистическая функция от скалярного произведения, где xn — это какие-то фичи. Одной из этих фич была цена ночи в отеле (в евро).
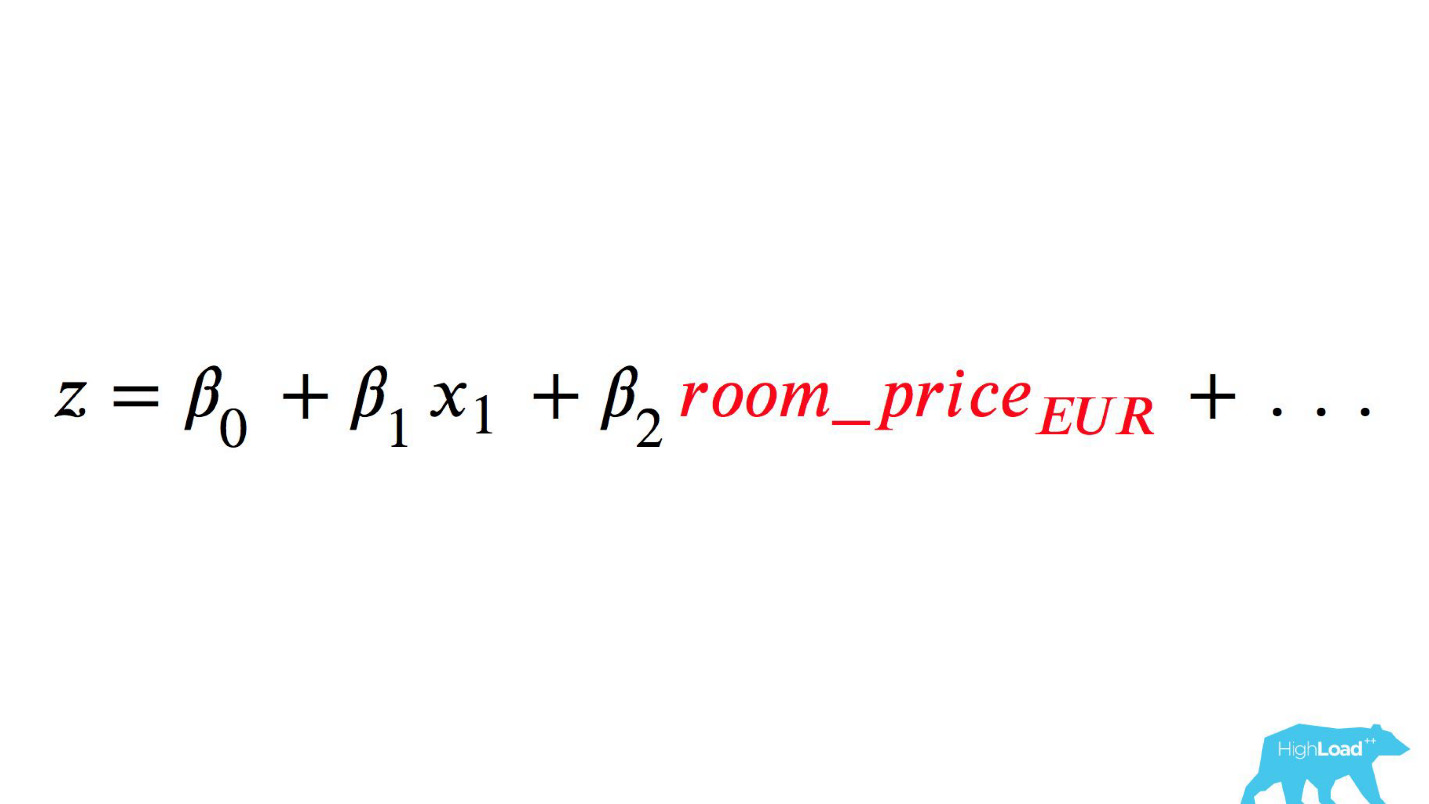
Вызывать эту модель стоило бы как-нибудь так:
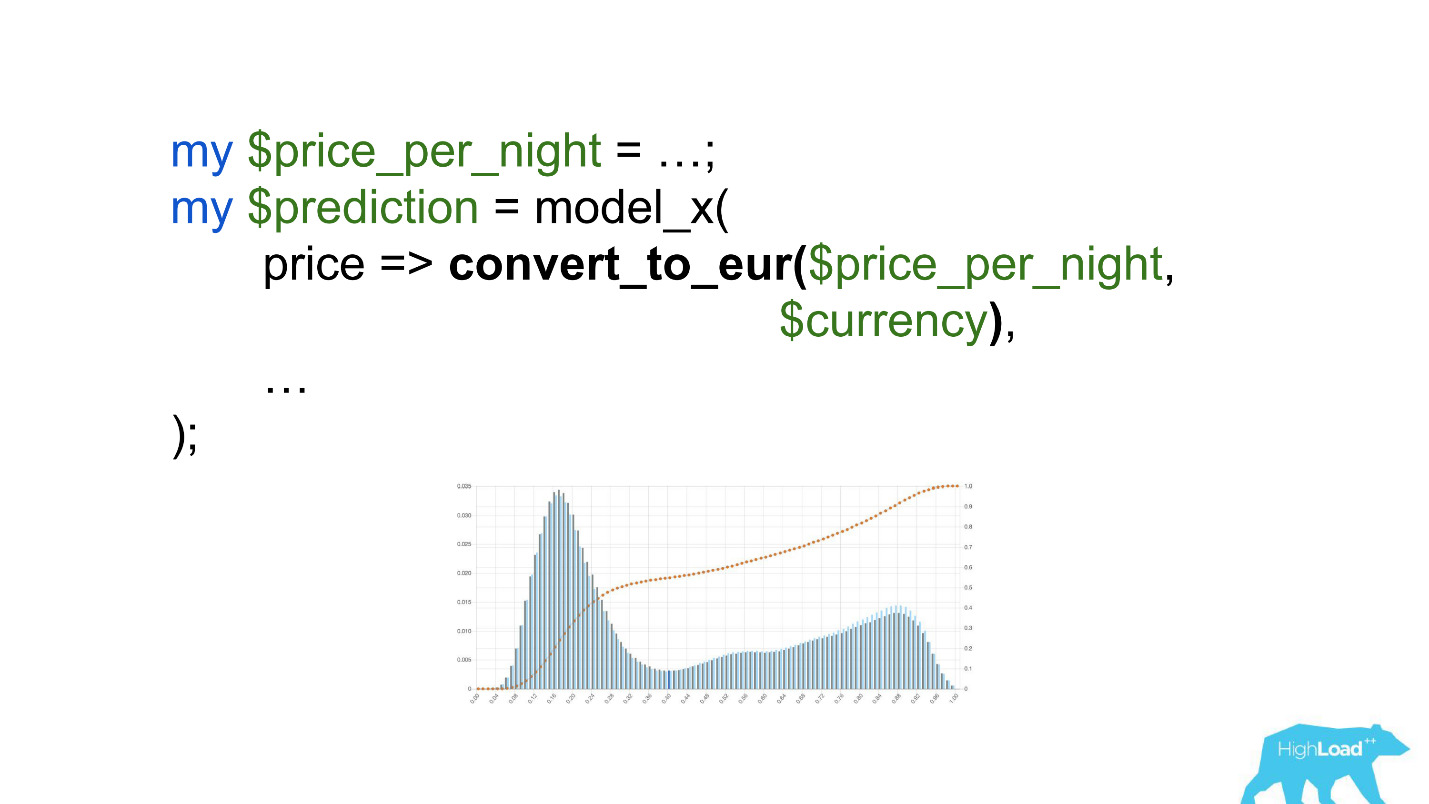
Обратите внимание на выделение. Нужно было сконвертировать цену в евро, но разработчик забыл это сделать.
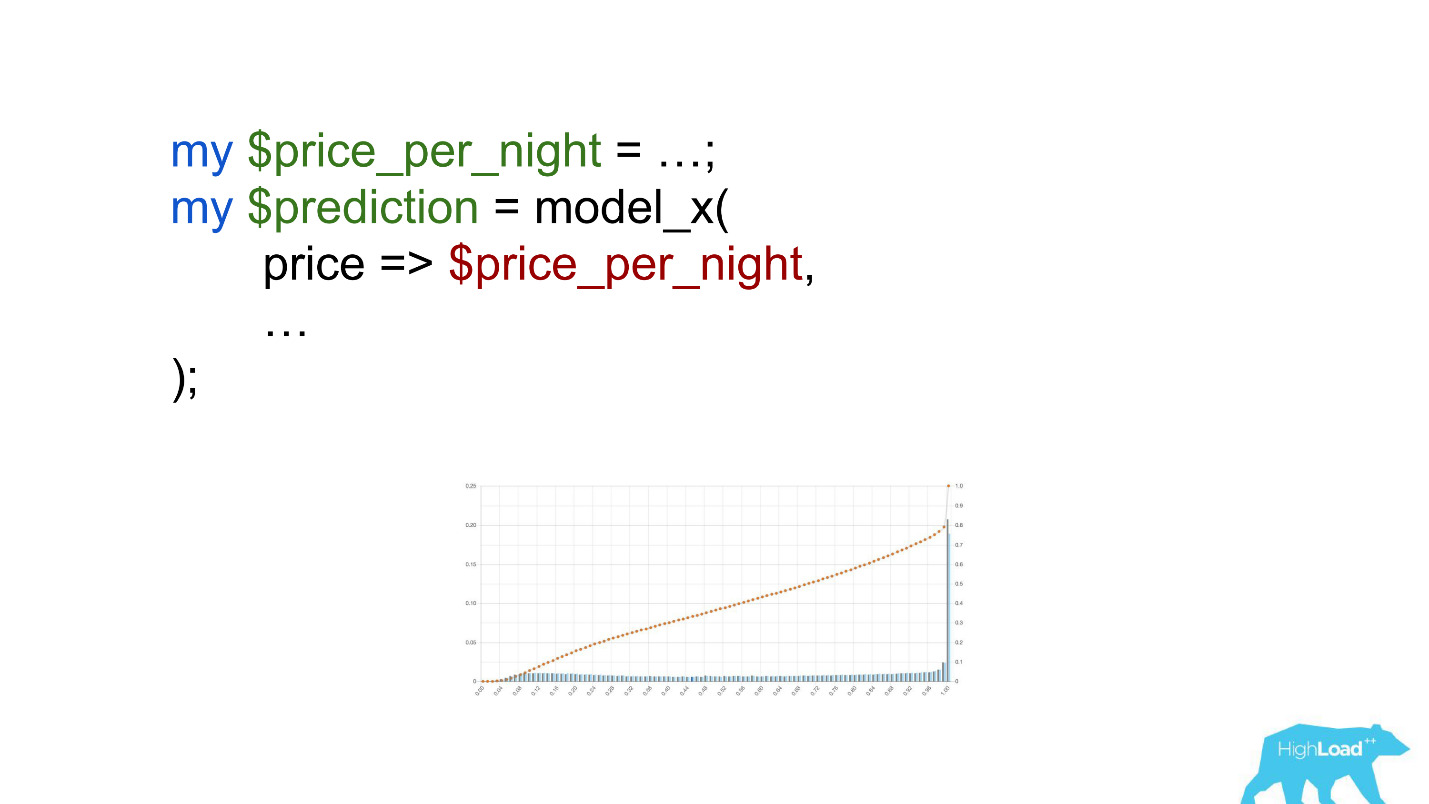
Валюты вроде рупий или рублей многократно увеличили скалярное произведение, и, значит, заставили эту модель выдавать значение, близкое к единице, гораздо чаще, что мы и видим на графике.
Пороговые значения
Еще одним полезным свойством этих гистограмм оказалась возможность осознанного и оптимального выбора пороговых значений.
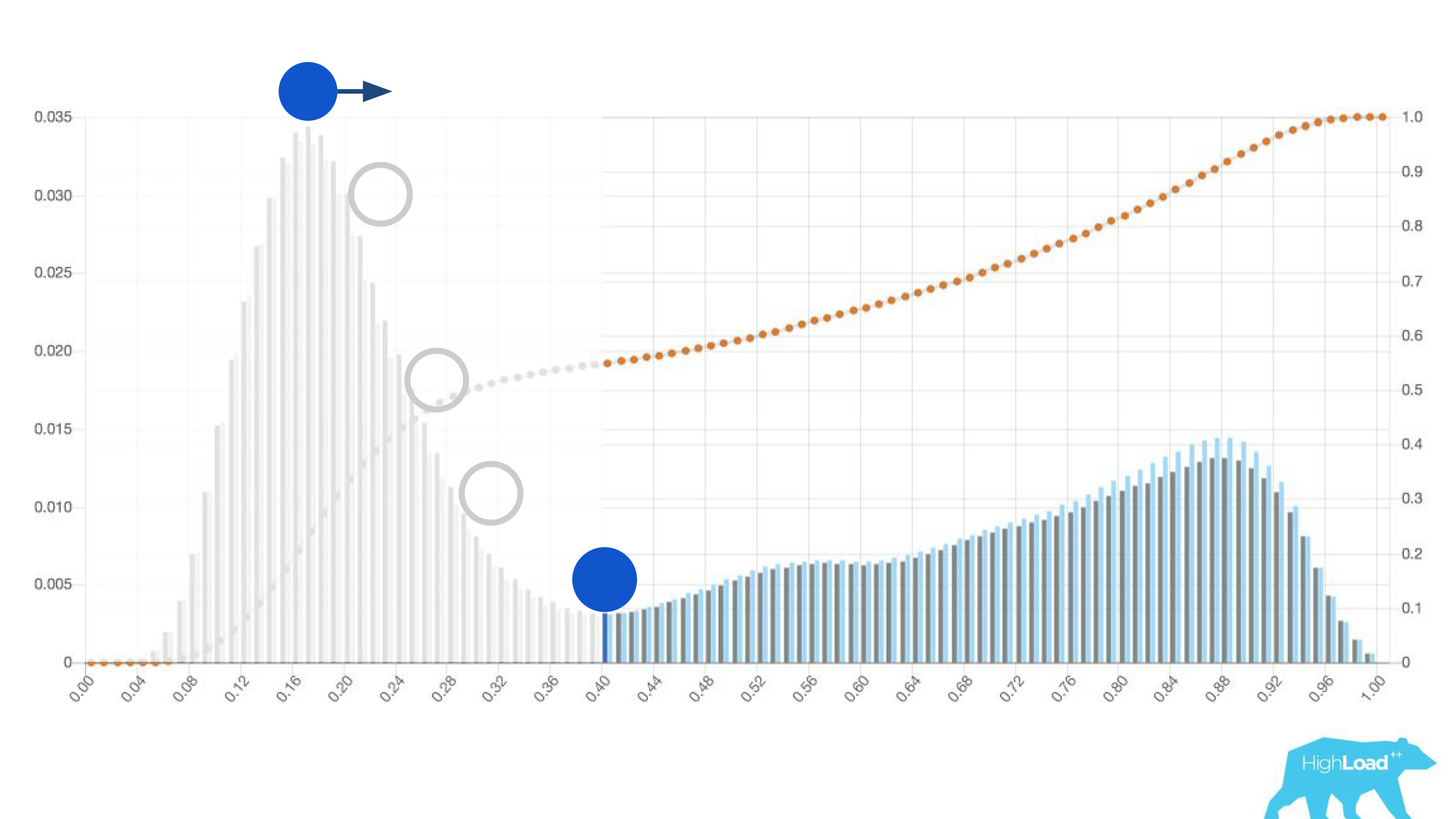
Если поместить шар на самый высокий холм на этой гистограмме, столкнуть его и представить, где он остановится, это и будет точка, оптимальная для разделения классов. Все, что справа — один класс, все, что слева — другой.
Однако если начать двигать эту точку, можно добиться весьма интересных эффектов. Предположим, мы хотим запустить эксперимент, который в случае, если модель говорит «да», как-то меняет пользовательский интерфейс. Если пододвинуть эту точку вправо, сокращается аудитория нашего эксперимента. Ведь количество людей, которые получили это предсказание, — это площадь под кривой. Однако на практике точность предсказаний (precision) гораздо выше. Точно также если не хватает статмощности, можно увеличить аудиторию своего эксперимента, но понизив точность предсказаний.
Кроме самих предсказаний мы начали мониторить входящие значения в векторах.
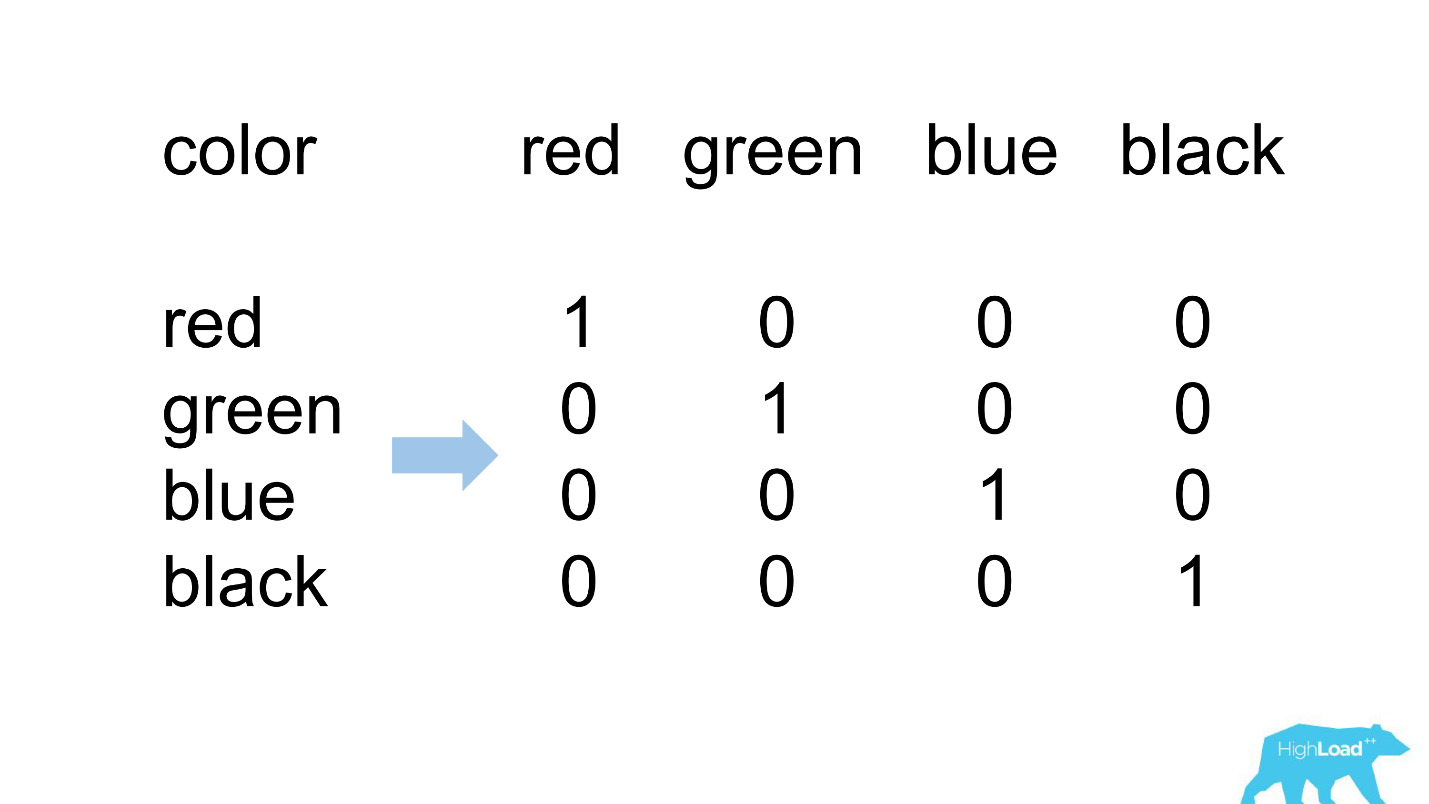
One Hot Encoding
Большинство фич в наших самых простых моделях категориальные. Это значит, что это не числа, а некие категории: город, из которого пользователь, или город, в котором он ищет отель. Мы пользуемся One Hot Encoding и превращаем каждое из возможных значений в единицу в бинарном векторе. Поскольку вначале мы пользовались только нашим собственным вычислительным ядром, было легко определить ситуации, когда для входящей категории нет места во входящем векторе, то есть модель не видела этих данных во время обучения.
Так это обычно выглядит.

destination_id — город, в котором пользователь ищет отель. Вполне естественно, что модель не видела примерно 5% значений, так как мы постоянно подключаем новые города. visitor_cty_id =23,32%, потому что дейтасайентисты иногда сознательно опускают малораспространенные города.
В плохом случае это может выглядеть так:

Сразу 3 свойства, 100% значений которых модель никогда не видела. Чаще всего это возникает из-за использования форматов, отличных от тех, что использовались при обучении, или просто банальных опечаток.
Сейчас с помощью дэшбордов мы обнаруживаем и исправляем такие ситуации очень быстро.
Витрина машинного обучения
Давайте поговорим о других проблемах, которые мы решили. После того, как мы сделали клиентские библиотеки и мониторинг, сервис начал очень быстро набирать обороты. Нас буквально завалило заявками из разных частей компании: «Давайте подключим еще эту модель! Давайте обновим старую!» Мы просто зашивались, фактически любая новая разработка остановилась.
Мы вышли из ситуации, сделав киоск самообслуживания для дейтасайентистов. Теперь можно просто зайти на наш портал, тот самый, который мы использовали сначала только для мониторинга, и буквально нажав кнопку загрузить модель в продакшен. Через несколько минут она будет работать и давать предсказания.
Оставалась еще одна проблема.
Booking.com — это примерно 200 IT-команд. Как дать знать команде в какой-то совершенно другой части компании, что есть модель, которая могла бы им помочь? Вы можете просто не знать, что такая команда даже существует. Как узнать, какие вообще есть модели и как ими пользоваться? Традиционно внешними коммуникациями у нас в командах занимаются PO (Product Owner). Это не значит, что у нас нет никаких других горизонтальных связей, просто PO занимается этим больше других. Но очевидно, что в таких масштабах коммуникация «один на один» не масштабируется. Нужно что-то с этим делать.
Как можно облегчить коммуникацию?
Мы вдруг поняли, что тот портал, который мы делали исключительно для мониторинга, постепенно начинает превращаться в витрину машинного обучения у нас внутри компании.
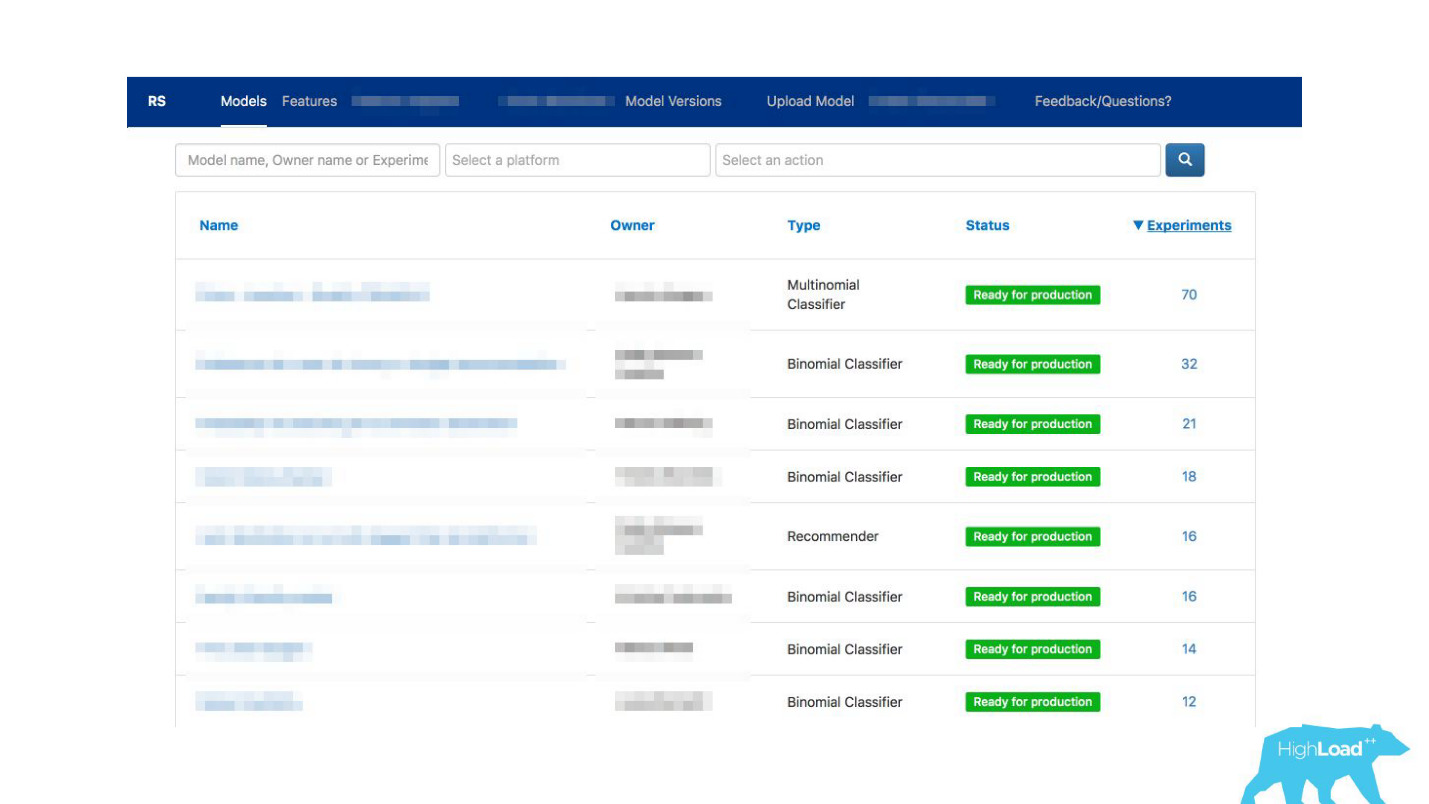
Мы дали возможность дейтасайентистам подробно описывать свои модели. Когда моделей стало много, мы добавили метки тем и областей применимости для удобной группировки.
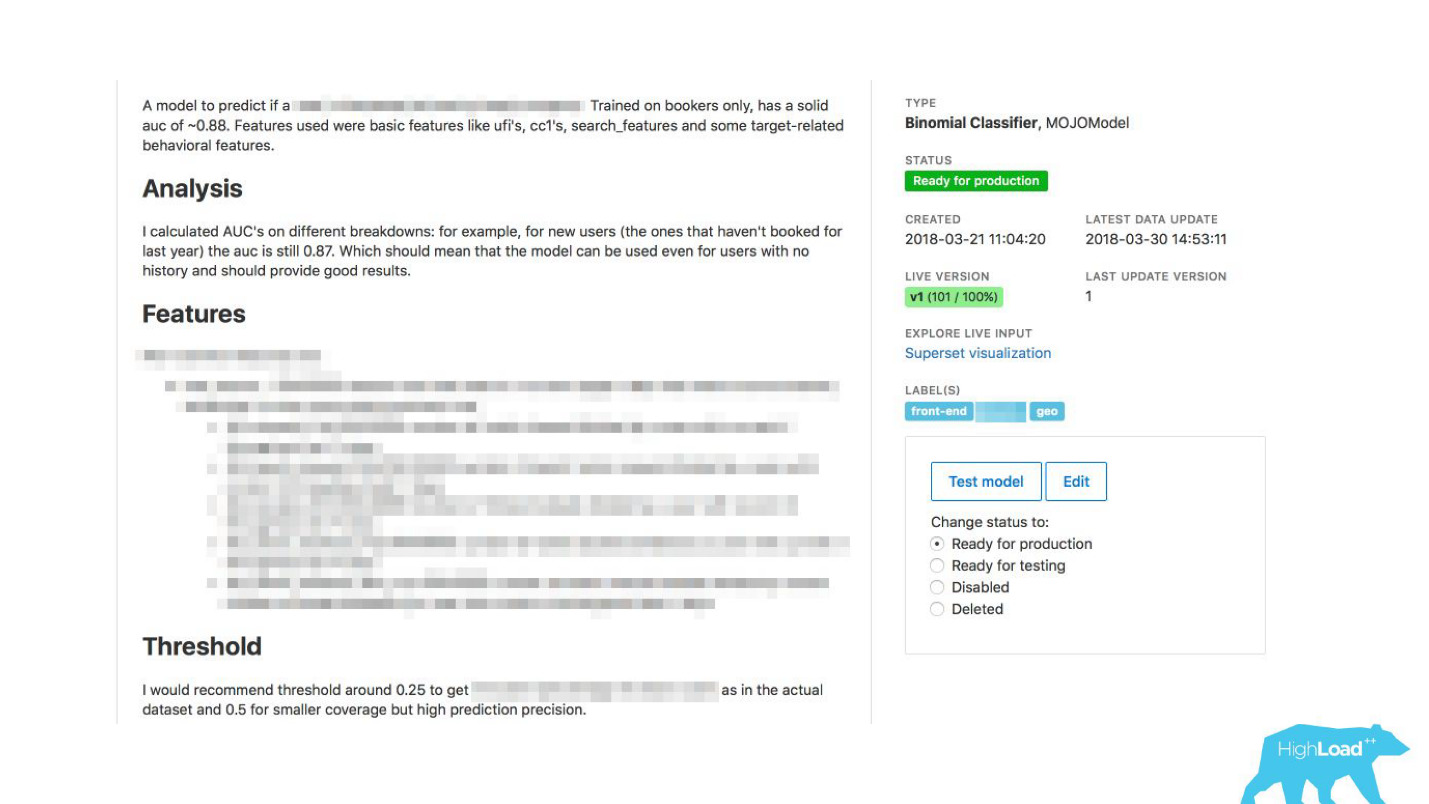
Мы связали наш инструмент с ExperimentTool. Это продукт внутри нашей компании, который обеспечивает проведение A/B-экспериментов и хранит в себе всю историю экспериментирования.

Теперь вместе с описанием модели можно еще и посмотреть, что делали другие команды с этой моделью раньше и насколько успешно. Это изменило всё.
Серьезно, это изменило то, как работает IT, потому что даже в ситуациях, когда нет дейтасайентиста в команде, можно пользоваться машинным обучением.
Например, многие команды используют это во время мозговых штурмов. Когда они придумывают какие-то новые продуктовые идеи, они просто подбирают подходящие им модели и пользуются ими. Для этого не нужно ничего сложного.
Во что это вылилось для нас? Прямо сейчас в пике мы доставляем около 200 тысяч предсказаний в секунду, при этом с latency меньше 20-30 мс, причем включая HTTP round trip, и размещение больше 200 моделей.
Может показаться, что это была такая легкая прогулка в парке: мы все замечательно сделали, все работает, все рады!
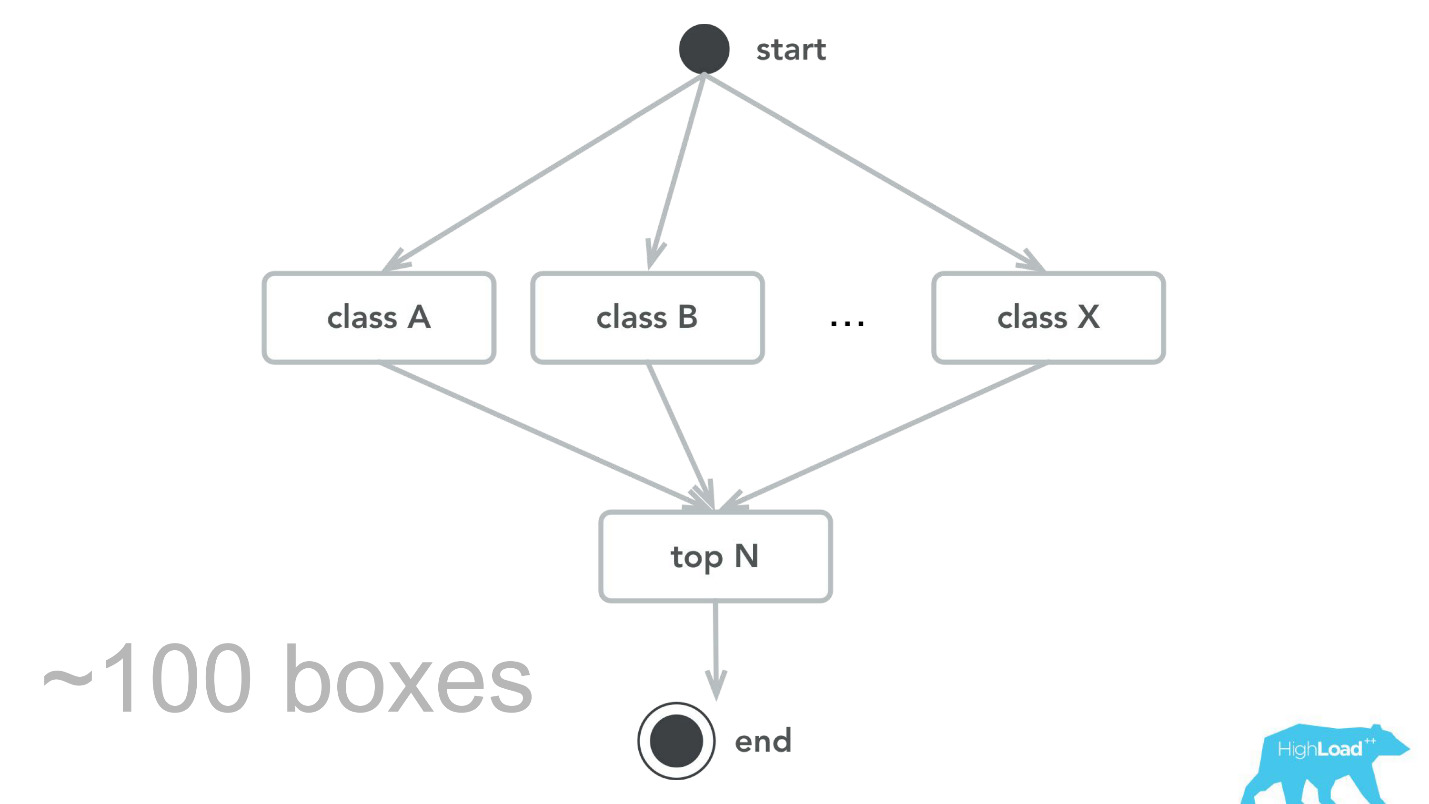
Такого, конечно, не бывает. Были и ошибки. В самом начале, например, мы заложили небольшую бомбу замедленного действия. Мы почему-то предполагали, что большинство наших моделей будут рекомендательные системы с тяжелыми входными векторами, и стек Scala+Akka был выбран именно потому, что с его помощью очень легко организовать параллельные вычисления. Но в реальности накладные расходы на всю эту параллелизацию, на сбор вместе оказался выше, чем возможный выигрыш. В какой-то момент мы наши 100 машин обрабатывали всего 100 000 RPS, и отказы случались с вполне характерными симптомами: утилизация CPU низкая, но получаются таймауты.
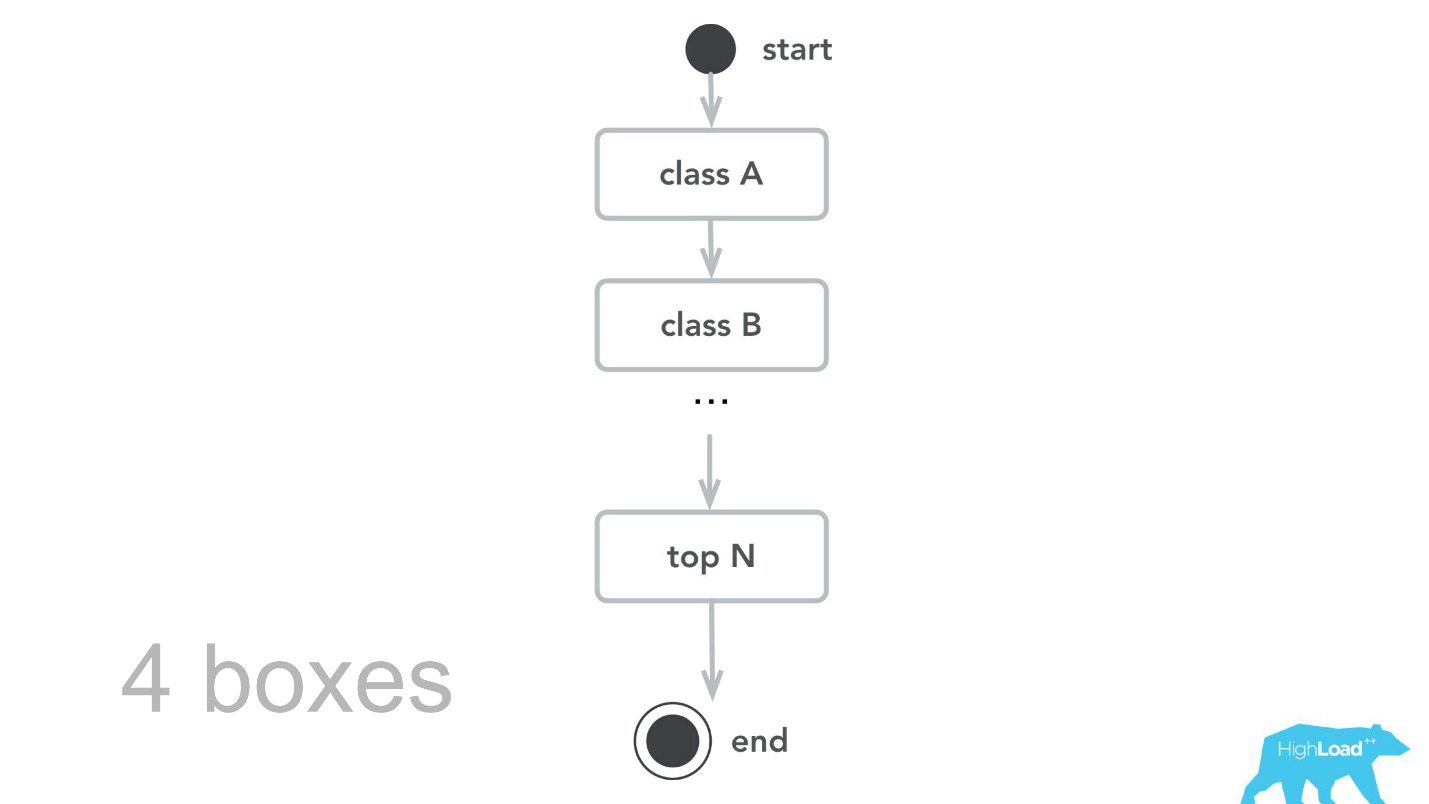
Тогда мы вернулись к нашему вычислительному ядру, пересмотрели, сделали бейнчмарки и в результате capacity-тестирования узнали, что для того же самого трафика нам нужно всего 4 машины. Конечно, мы так не делаем, потому что у нас несколько дата-центров, нам нужна избыточность вычислений и всё остальное, но, тем не менее, теоретически мы можем обслуживать больше 100 000 RPS всего 4 машинами.
Мы постоянно ищем какие-то новые мониторы, которые могут нам помочь найти и исправить ошибки, но не всегда делаем шаги в правильном направлении. В какой-то момент у нас собралось небольшое количество моделей, которые применялись буквально по всей воронке, начиная со странички индекса, заканчивая подтверждением о бронировании.
Мы решили — давайте посмотрим на то, как модели меняют свои предсказания для одного и того же пользователя. Посчитали дисперсию, сгруппировав все по ID пользователя, никаких серьезных проблем не обнаружилось. Предсказания моделей были стабильны, дисперсия в районе 0.
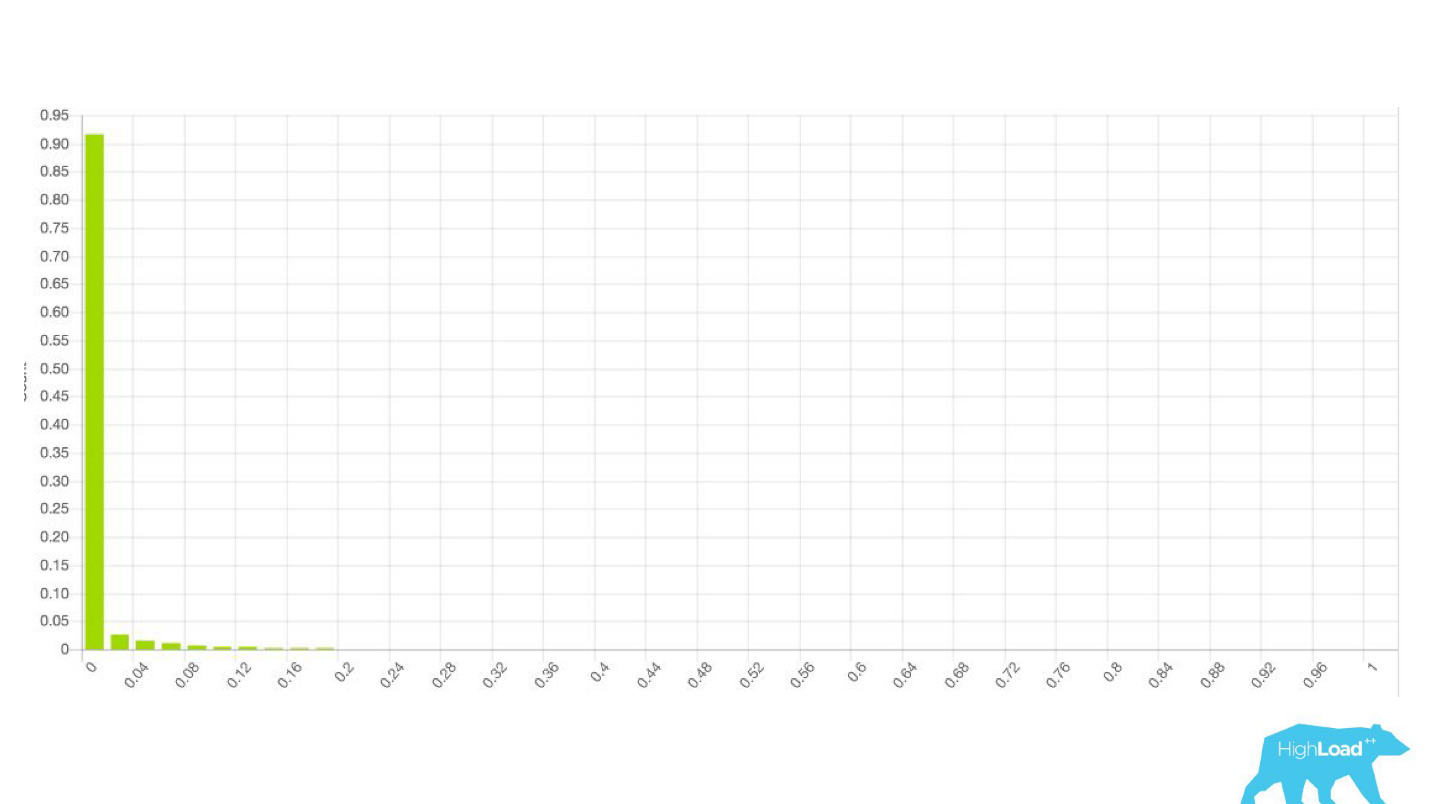
Другая ошибка — опять же и техническая, и организационная — мы начали упираться в память.
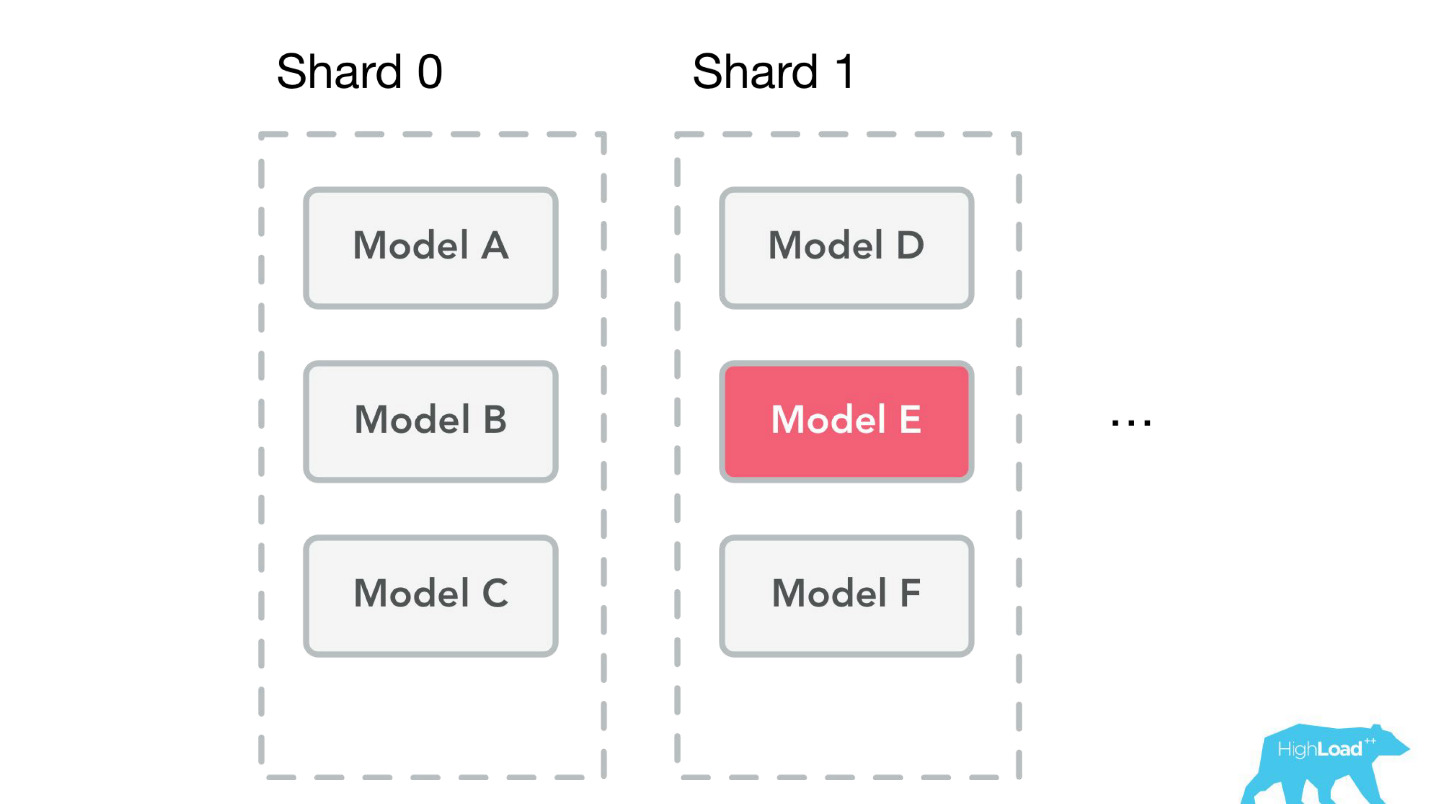
Дело в том, что мы храним все модели на всех машинах. Мы начали упираться в память и подумали, что пора делать шарды. Но проблема в том, что одновременно в разработке находились и батчи — это возможность предсказаний для одной модели, но много раз. Представьте себе, например, страничку поиска, и для каждого отеля там нужно что-то предсказать.
Когда мы начинали делать шардинг, мы посмотрели на живые данные и шардить собирались очень просто — по ID модели. Нагрузка и объемы модели распределялись примерно равномерно — 49-51%. Но когда мы закончили заниматься шардингом, батч уже использовался в продакшене. У нас были горячие модели, которые использовались гораздо больше других, и дисбаланс был большой. Окончательно мы решим эту проблему, когда наконец уедем в контейнеры.
Планы на будущее
- Label based metrics
В первую очередь мы все-таки хотим дать дейтасайентистам возможность наблюдать в динамике те же самые метрики, которые они используют при обучении. Мы хотим Label based metrics, и наблюдать precision и recall в реальном времени.
- More tools & integrations
В компании еще остались внутренние инструменты и продукты, с которыми мы плохо интегрированы. В основном это высоконагруженные проекты, потому что для всего остального мы сделали пару клиентских библиотек для Perl и Java, и все, кому нужно, могут этим пользоваться. У аналитиков есть удобная интеграция со Spark, они могут для своих целей использовать наши модели.
- Reusable training pipelines
Мы хотим иметь возможность вместе с моделями деплоить кастомный код.
Например, представьте себе спам-классификатор. Все процедуры, которые происходят до получения входящего вектора весов, например, разбиение текста на предложения, на слова, steaming — вы должны в продакшен-окружении повторить еще раз, желательно тем же самым образом для того, чтобы избежать ошибок.
Мы хотим избавиться от этой проблемы. Мы хотим деплоить кусочек pipeline, разработанный для тренировки модели, вместе с моделью. Тогда вы сможете отправлять просто письма нам, а мы будем говорить, спам или не спам.
- Async models
Мы хотим сделать асинхронное предсказание. Сложность наших моделей растет, а все, что медленнее 50 мс, мы считаем очень медленным. Представьте себе модель, которая делает предсказания исключительно на основании истории посещённых страниц на нашем сайте. Тогда мы можем запускать эти предсказания в момент рендера странички, а забирать и использовать их тогда, когда нам надо.
Start small
Самое важное, что я узнал, пока работал над внедрением моделей в продакшен в Booking.com, и что я хочу, чтобы вы запомнили, унесли домой и пользовались — начинайте с малого!
Мы своих первых успехов с машинным обучением достигли, смешно сказать, взрывая предсказания в MySQL. Возможно, у вас тоже есть первые шаги, которые вы можете сделать уже сейчас. Вам не нужны какие-то сложные инструменты для этого. B у меня тот же совет дейтасайентистам. Если вы не работаете с видео, с голосом и с изображением, если ваша задача как-то связана с транзакционными данными — не берите слишком сложные модели сразу.
Зачем вам нейронная сеть, пока вы не попробовали логистическую регрессию?
Monitor
Мониторьте все на свете — вы же мониторите свое программное обеспечение, веб-серверы, железо. Модель — это такое же программное обеспечение. Единственная разница — это программное обеспечение, которое написали не вы. Его написала другая программа, которую, в свою очередь, написал дейтасайентист. В остальном всё то же самое: входные аргументы, возвращаемые значения. Знайте, что у вас происходит в реальности, насколько модель хорошо справляется со своей работой, все ли идет штатным путем — мониторьте!
Organization footprint
Думайте о том, как устроена ваша организация. Практически любые ваши шаги в этом направлении изменят то, как люди работают вокруг вас. Думайте, как им можно помочь устранить их проблемы и как вы вместе можете прийти к большим успехам.
(Don’t) Follow our steps
Я поделился какими-то успехами, неудачами, проблемами, с которыми мы столкнулись. Надеюсь, кому-то это поможет обойти те мели, на которые мы сели. Делайте как мы, но не повторяйте наших ошибок. Или повторяйте — кто в конце концов сказал, что ваша ситуация точно такая же, как наша? Кто сказал, что то, что не заработало у нас, не заработает у вас?
Пробуйте, ошибайтесь, делитесь своими ошибками!
На HighLoad++ 2018, который состоится 8 и 9 ноября в СКОЛКОВО, будет 135 спикеров, уже готовых поделиться результатами своих экспериментов. Дополнительно в расписании 9 треков мастер-классов и митапов. Темы найдутся для каждого, и билеты еще можно успеть забронировать.
Комментарии (6)

servekon
26.10.2018 09:32Используете ли вы машинное обучение для выявления недобросовестных отельеров?
К примеру, отельер сам же у себя бронирует номер, выплачивает комиссию и пишет положительный отзыв. Возможно это отследить хотя бы по IP или cookies?molec
26.10.2018 13:13В ту же степь — отели на нашем черноморском берегу. Регулярно принимают бронирование, но в итоге номера нет, пристраивают куда придется. Нормальная для нашего юга ситуация — подтверждать бронирование только по звонку клиента. Нет звонка — нет подтверждения.
Это очень напрягает, по видимому, санкций от букинга они не боятся.
sergeyns
26.10.2018 12:56+1Да настройте выдачу отелей так как это я указываю в фильтрах, а не как вам хочется.
undisclosed
26.10.2018 15:15С развитием ML и Ai, выбрать действительно выгодный отель становится все сложнее и сложнее.
QtRoS
26.10.2018 20:23Расскажете, что физически из себя представляет модель? С чем к вам на сайт приходят датасаентисты, чтобы 'в один клик грузить модель'? Как храните эти модели?
Далее, интересно какого рода входы есть у витрины? Как ей пользуются, программно или 'глазами'?
pipyakin
Чем бы смузихлебы не тешились.