
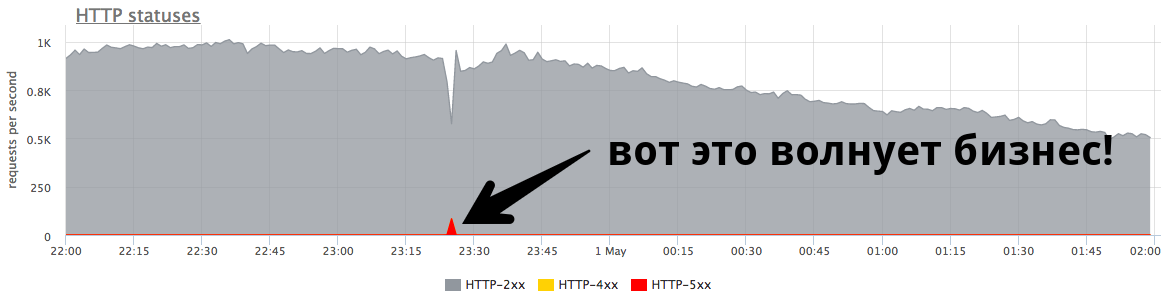
Маленький минутрый пик в 84 RPS «пятисоток» — это пять тысяч ошибок, которые получили реальные пользователи. Это много и это очень важно. Необходимо искать причины, проводить работу над ошибками и стараться впредь не допускать подобных ситуаций.
Николай Сивко (NikolaySivko) в своем докладе на RootConf 2018 рассказал о тонких и пока не очень популярных аспектах балансировки нагрузки:
- когда повторять запрос (retries);
- как выбрать значения для таймаутов;
- как не убить нижележащие серверы в момент аварии/перегрузки;
- нужны ли health checks;
- как обрабатывать «мерцающие» проблемы.
Под катом расшифровка этого доклада.
О спикере: Николай Сивко сооснователь okmeter.io. Работал системным администратором и руководителем группы администраторов. Руководил эксплуатацией в hh.ru. Основал сервис мониторинга okmeter.io. В рамках этого доклада опыт разработки мониторинга является основным источником кейсов.
Про что будем говорить?
В этой статье речь пойдет про веб-проекты. Ниже пример живого продакшена: на графике показаны запросы в секунду на некий веб-сервис.
Когда я рассказываю про балансировку, многие воспринимают это, как «нам надо распределить нагрузку между серверами — чем точнее, тем лучше».
На самом деле это не совсем так. Такая проблема актуальна для очень небольшого числа компаний. Чаще бизнес волнуют ошибки и стабильность работы системы.
Маленький пик на графике — это «пятисотки», которые сервер возвращал в течение минуты, а потом перестал. С точки зрения бизнеса, например интернет-магазина, этот маленький пик в 84 RPS «пятисоток» — это 5040 ошибок реальным пользователям. Одни что-то не нашли в вашем каталоге, другие не смогли положить товар в корзину. И это очень важно. Пусть на графике этот пик выглядит не очень масштабным, но в реальных пользователях это много.
Как правило такие пики есть у всех, и админы не всегда на них реагируют. Очень часто, когда бизнес спрашивает, что это было, ему отвечают:
- «Это кратковременный всплеск!»
- «Это просто релиз катился».
- «Сервер умер, но уже все в порядке».
- «Вася переключал сеть одного из бэкендов».
Нередко люди даже не пытаются понять причины, почему это произошло, и не делают никакую пост-работу, чтобы это не повторилось.
«Тонкая» настройка
Я назвал доклад «Тонкаянастройка» (англ. Fine tuning), потому что я подумал, что не все добираются до этой задачи, а стоило бы. Почему не добираются?
- До этой задачи не все добираются, потому что, когда все работает, она не видна. Это очень важно при проблемах. Факапы случаются не каждый день, а такая маленькая проблемка требует очень серьезных усилий для того, чтобы ее разрешить.
- Нужно много думать. Очень часто админ — тот человек, который настраивает балансировку — не в состоянии самостоятельно решить эту проблемы. Дальше мы посмотрим, почему.
- Цепляет нижележащие уровни. Эта задача очень тесно связана с разработкой, с принятием решений, которые затрагивают ваш продукт и ваших пользователей.
Я утверждаю, что пора заниматься этой задачей по нескольким причинам:
- Мир меняется, становится более динамичным, появляется много релизов. Говорят, что теперь правильно релизиться 100 раз в день, а релиз — это будущий факап с вероятностью 50 на 50 (прямо как вероятность встретить динозавра)
- С точки зрения технологий тоже все очень динамично. Появился Kubernetes и другие оркестраторы. Нет старого доброго deployment, когда один бэкенд на каком-то IP выключается, накатывается обновление, и сервис поднимается. Сейчас в процессе rollout в k8s полностью меняется список IP апстримов.
- Микросервисы: теперь все общаются по сети, а значит, нужно делать это надежно. Балансировка играет немаловажную роль.
Тестовый стенд
Начнем с простых очевидных кейсов. Для наглядности я буду использовать тестовый стенд. Это Golang-приложение, которое отдает http-200, или его можно переключить в режим «отдавай http-503».
Запускаем 3 инстанса:
- 127.0.0.1:20001
- 127.0.0.1:20002
- 127.0.0.1:20003
Подаем 100rps через yandex.tank через nginx.
Nginx из коробки:
upstream backends {
server 127.0.0.1:20001;
server 127.0.0.1:20002;
server 127.0.0.1:20003;
}
server {
listen 127.0.0.1:30000;
location / {
proxy_pass http://backends;
}
}
Примитивный сценарий
В какой-то момент включаем один из бэкендов в режим отдавать 503, и получаем ровно треть ошибок.
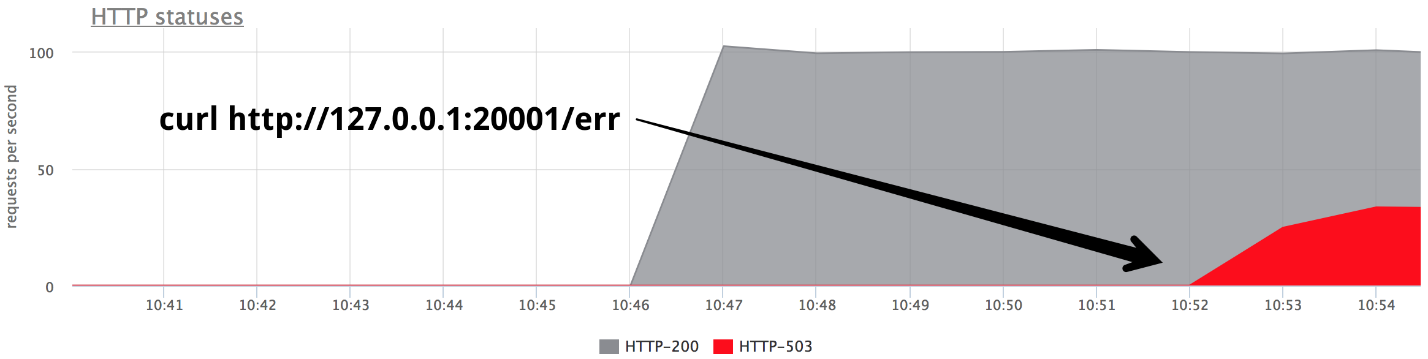
Понятно, что из коробки ничего не работает: nginx из коробки не делает retry, если получили с сервера любой ответ.
Nginx default: proxy_next_upstream error timeout;
На самом деле это довольно логично со стороны разработчиков nginx: nginx не вправе за вас решать, что вы хотите ретраить, а что нет.
Соответственно, нам нужны retries — повторные попытки, и мы начинаем о них говорить.
Retries
Нужно найти компромисс между:
- Пользовательский запрос — святое, расшибись, но ответь. Мы хотим любой ценой ответить пользователю, пользователь — самое важное.
- Лучше ответить ошибкой, чем перегруз серверов.
- Целостность данных (при неидемпотентных запросах), то есть нельзя повторять определенные типы запросов.
Истина, как обычно, где-то между — мы вынуждены балансировать между этими тремя пунктами. Попытаемся понять, что и как.
Я разделил неудачные попытки на 3 категории:
? 1. Transport error
Для HTTP транспортом являются TCP, и, как правило, здесь мы говорим об ошибках установки соединения и о таймаутах установки соединения. В своем докладе я буду упоминать 3 распространенных балансировщика (про Envoy поговорим чуть дальше):
- nginx: errors + timeout (proxy_connect_timeout);
- HAProxy: timeout connect;
- Envoy: connect-failure + refused-stream.
У nginx есть возможность сказать, что неудачная попытка — это ошибка соединения и таймаут соединения; у HAProxy есть таймаут соединения, у Envoy тоже — все стандартно и нормально.
? 2. Request timeout:
Допустим, что мы отправили запрос на сервер, успешно с ним соединились, но ответ нам не приходит, мы его подождали и понимаем, что дальше ждать уже нет никакого смысла. Это называется request timeout:
- У nginx есть: timeout (prox_send_timeout* + proxy_read_timeout*);
- У HAProxy — OOPS :( — его в принципе нет. Многие не знают, что HAProxy, если успешно установил соединение, никогда не будет пробовать повторно послать запрос.
- Envoy все умеет: timeout || per_try_timeout.
? 3. HTTP status
Все балансировщики, кроме HAProxy, умеют обрабатывать, если все-таки бэкенд вам ответил, но каким-то ошибочным кодом.
- nginx: http_*
- HAProxy: OOPS :(
- Envoy: 5xx, gateway-error (502, 503, 504), retriable-4xx (409)
Таймауты
Поговорим теперь подробно про таймауты, мне кажется, что стоит уделить этому внимание. Дальше не будет rocket science — это просто структурированная информация про то, что вообще бывает, и как к этому относится.
Connect timeout
Connect timeout — это время на установку соединения. Это характеристика вашей сети и вашего конкретного сервера, и не зависит от запроса. Обычно, значение по умолчанию для сonnect timeout устанавливает небольшим. Во всех прокси дефолтовое значение достаточно велико, и это неправильно — должно быть единицы, иногда десятки миллисекунд (если мы говорим о сети в пределах одного ДЦ).
Если вы хотите проблемные сервера определять чуть быстрее, чем эти единицы-десятки миллисекунд, вы можете регулировать нагрузку на бэкенд путем установки небольшого backlog на прием TCP-соединений. В таком случае вы можете, когда backlog приложения заполнится, сказать Linux, чтобы он сделал reset на переполнение backlog. Тогда вы будете иметь возможность отстрелить «плохой» перегруженный бэкенд чуть раньше, чем connect timeout:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflowRequest timeout
Request timeout — это характеристика не сети, а характеристика группы запросов (handler). Есть разные запросы — они разные по тяжести, у них внутри совершенно разная логика, им нужно обращаться к совершенно разным хранилищам.
У nginx, как такового, нет таймаута на весь запрос. У него есть:
- proxy_send_timeout: время между двумя успешными операциями записи write();
- proxy_read_timeout: время между двумя успешными операциями чтения read().
То есть если у вас бэкенд медленно, по одному байту раз, в таймаут что-то отдает, то все нормально. Как такового request_timeout у nginx нет. Но речь идет об апстримах. В нашем датацентре они подконтрольны нам, поэтому с допущением, что в сети нет slow loris, то, в принципе, read_timeout можно использовать в качестве request_timeout.
У Envoy все есть: timeout || per_try_timeout.
Выбираем request timeout
Теперь самое важное, на мой взгляд — какой поставить request_timeout. Мы исходим из того, сколько допустимо ждать пользователю — это некий максимум. Понятно, что пользователь не будет ждать дольше 10 с, поэтому надо ответить ему быстрее.
- Если мы хотим обработать отказ одного единственного сервера, то таймаут должен быть меньше максимального допустимого времени ожидания: request_timeout < max.
- Если вы хотите иметь 2 гарантированные попытки отправки запроса на два разных бэкенда, то таймаут на одну попытку равен половине этого допустимого интервала: per_try_timeout = 0.5 * max.
- Есть также промежуточный вариант — 2 оптимистичные попытки на случай если первый бэкенд «притупил», но второй при этом ответит быстро: per_try_timeout = k * max (где k > 0.5).
Есть разные подходы, но в целом выбрать таймаут — это сложно. Всегда найдутся граничные случаи, например, один и тот же handler в 99% случаев обрабатывается за 10 мс, но есть 1% случаев, когда мы ждем 500 мс, и это нормально. Это придется разруливать.
С этим 1% нужно что-то сделать, потому что вся группа запросов должна, например, соответствовать SLA и укладываться в 100 мс. Очень часто в эти моменты перерабатывается приложение:
- Появляется paging в тех местах, где невозможно за timeout отдать все данные целикомю.
- Админка/отчеты отделяются в отдельную группу урлов для того, чтобы поднять для них timeout, а да пользовательских запросов, наоборот понизить.
- Чиним/оптимизируем те запросы, которые не укладываются в наш таймаут.
Тут же нам нужно принять не очень простое с психологической точки зрения решение о том, что если мы не успеваем ответить пользователю за отведенное время, отдаем ошибку (это как в древней китайской поговорке: «Если кобыла сдохла, слезь!»).
После этого упрощается процесс мониторинга вашего сервиса с точки зрения пользователя:
- Если есть ошибки, все плохо, это нужно чинить.
- Если ошибок нет, мы укладываемся в нужное время ответа, значит все хорошо.
Speculative retries #нифигасечобывает
Мы убедились, что выбрать значение таймаута достаточно сложно. Как известно, чтобы что-то упростить, нужно что-то усложнить:)
Спекулятивный ретрай — повторный запрос на другой сервер, который запускается по какому-то условию, но первый запрос при этом не прерывается. Ответ мы берем от того сервера, который ответил быстрее.
Я не видел этой фичи в известных мне балансерах, но есть отличный пример с Cassandra (rapid read protection):
?? speculative_retry = N ms | Mth percentile
Таким образом вам не надо зажимать таймаут. Вы можете оставить его на приемлемом уровне и в любом случае имеете вторую попытку получить ответ на запрос.
В Cassandra есть интересная возможность, задать статический speculative_retry или динамический, тогда вторая попытка будет сделана через перцентиль времени ответа. Cassandra накапливает статистику по временам ответов предыдущих запросов и адаптирует конкретное значение таймаута. Это достаточно хорошо работает.
В этом подходе все держится на балансе между надежностью и паразитной нагрузкой не серверы Вы обеспечиваете надежность, но иногда получаете лишние запросы на сервер. Если вы где-то поторопились и отправили второй запрос, а первый все-таки ответил — сервер получил чуть больше нагрузки. В единичном случае это небольшая проблема.

Согласованность таймаутов — еще один важный аспект. Про request cancellation мы еще поговорим, но в целом, если таймаут на весь пользовательский запрос 100 мс, то нет смысла ставить таймаут на запрос в базу 1 с. Есть системы, которые позволяют это делать динамически: сервис к сервису передает остаток времени, который вы будете ждать ответа на этот запрос. Это сложновато, но, если вам вдруг это понадобится, вы легко найдете, как в том же Envoy это сделать.
Что еще надо знать про retry?
Точка невозврата (V1)
Здесь V1 — это не версия 1. В авиации есть такое понятие — скорость V1. Это скорость, после достижении которой на разгоне по взлетной полосе тормозить нельзя. Надо обязательно взлетать, и потом уже принимать решение о том, что делать дальше.
Такая же точка невозврата есть в балансировщиках нагрузки: когда вы 1 байт ответа передали своему клиенту, никакие ошибки исправить уже нельзя. Если в этот момент бэкенд умирает, никакие retries не помогут. Можно только уменьшить вероятность срабатывания такого сценария, сделать graceful shutdown, то есть сказать своему приложению: «Ты сейчас новые запросы не принимаешь, но старые дорабатывай!», и только потом его гасить.
Если вы контролируете клиент, это какой-нибудь хитрый Ajax или мобильное приложение, оно может попробовать повторить запрос, и тогда вы можете выйти из этой ситуации.
Точка невозврата [Envoy]
В Envoy была такая странная фишка. Есть per_try_timeout — он ограничивает сколько может занимать каждая попытка получить ответ на запрос. Если этот таймаут срабатывал, но бэкенд уже начал отвечать клиенту, то все прерывалось, клиент получал ошибку.
Мой коллега Павел Труханов (tru_pablo) сделал патч, который уже в master Envoy и будет в 1.7. Теперь это работает так, как надо: если ответ начали передавать, сработает только global timeout.
Retries: нужно ограничивать
Retries — это хорошо, но бывают так называемые запросы-убийцы: тяжелые запросы, которые выполняют очень сложную логику, много обращается к базе данных и часто не укладывается в per_try_timeout. Если мы снова и снова посылаем retry, то этим мы убиваем нашу базу. Потому, что в большинстве (99.9%) сервисов баз данных нет request cancellation.
Request cancellation означает, что клиент отцепился, нужно прекратить всю работу прямо сейчас. В Golang сейчас активно пропагандируется этот подход, но, к сожалению, он заканчивается бэкендом, и многие хранилища баз данных это не поддерживают.
Соответственно, retries нужно ограничивать, что позволяют практически все балансировщики (HAProxy мы с данного момента рассматривать перестаем).
Nginx:
- proxy_next_upstream_timeout (global)
- proxt_read_timeout** в качестве per_try_timeout
- proxy_next_upstream_tries
Envoy:
- timeout (global)
- per_try_timeout
- num_retries
В Nginx можно сказать, что мы пытаемся делать retries на протяжении окна X, то есть в заданный интервал времени, например, 500 мс мы делаем столько retries, сколько поместится. Либо есть настройка, которая ограничивает количество повторных проб. В Envoy так же — количество или timeout (global).
Retries: применяем [nginx]
Рассмотрим пример: задаем в nginx 2 попытки retry — соответственно, получив HTTP 503, пробуем послать запрос на сервер еще раз. Потом выключаем два бэкенда.
upstream backends {
server 127.0.0.1:20001;
server 127.0.0.1:20002;
server 127.0.0.1:20003;
}
server {
listen 127.0.0.1:30000;
proxy_next_upstream error timeout http_503;
proxy_next_upstream_tries 2;
location / {
proxy_pass http://backends;
}
}
Ниже графики нашего тестового стенда. На верхнем графике ошибок не видно, потому что их очень мало. Если оставить только ошибки, видно, что они есть.
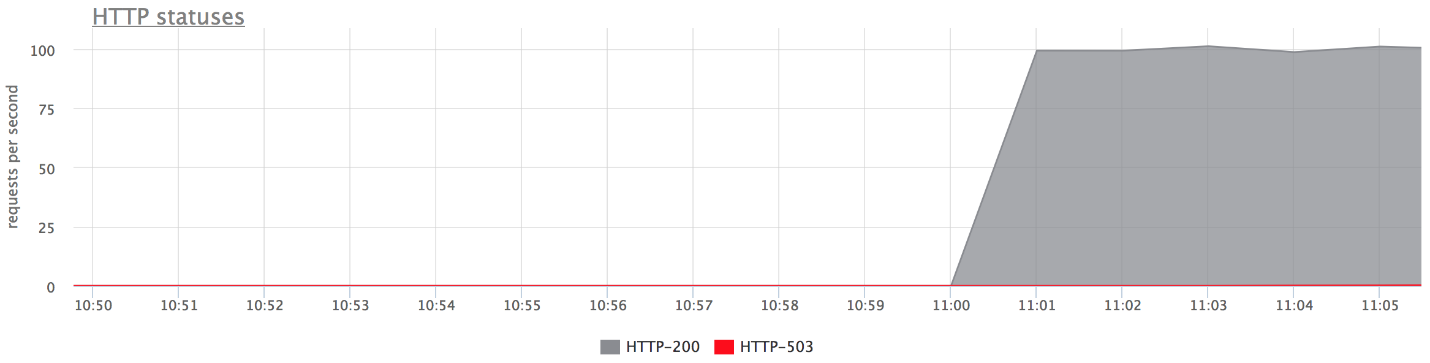

Что произошло?
- proxy_next_upstream_tries = 2.
- В случае, когда вы первую попытку делаете на «мертвый» сервер, и вторую — на другой «мертвый», то получаете HTTP-503 в случае обеих попыток на «плохие» серверы.
- Ошибок мало, так как nginx «банит» плохой сервер. То есть если в nginx от бэкенда вернулось сколько-то ошибок, он перестает делать следующие попытки отправить на него запрос. Это регулируется переменной fail_timeout.
Но ошибки есть, и нас это не устраивает.
Что с этим делать?
Мы можем либо увеличить количество повторных попыток (но тогда возвращаемся к проблеме «запросов-убийц»), либо мы можем уменьшить вероятность попадания запроса на «мертвые» бэкенды. Это можно делать с помощью health checks.
Health checks
Я предлагаю рассматривать health checks как оптимизацию процесса выбора «живого» сервера. Это ни в коем случае не дает никаких гарантий. Соответственно, в ходе выполнения пользовательского запроса мы с большей вероятностью будем попадать только на «живые» серверы. Балансировщик регулярно обращается по определенному URL, сервер ему отвечает: «Я жив и готов».
Health checks: с точки зрения бэкенда
С точки зрения бэкенда можно сделать интересные вещи:
- Проверить готовность к работе всех нижележащих подсистем, от которых зависит работа бэкенда: установлено нужное количество соединений с базой данных, в пуле есть свободные коннекты и т.д., и т.п.
- На Health checks URL можно повесить свою логику, если используемый балансировщик не особо интеллектуальный (допустим, вы берете Load Balancer у хостера). Сервер может запоминать, что «за последнюю минуту я отдал столько-то ошибок — наверное, я какой-нибудь „неправильный“ сервер, и последующие 2 минуты я буду отвечать „пятисоткой“ на Health checks. Таким образом сам себя забаню!» Это иногда очень спасает, когда у вас неконтролируемый Load Balancer.
- Как правило, интервал проверки около секунды, и нужно, чтобы Health check handler не убил ваш сервер. Он должен быть легким.
Health checks: имплементации
Как правило, здесь все у всех всё примерно одинаково:
- Request;
- Timeout на него;
- Interval, через который мы делаем проверки. У навороченных прокси есть jitter, то есть некая рандомизация для того, чтобы все Health checks не приходили на бэкенд одномоментно, и не убивали его.
- Unhealthy threshold — порог, сколько должно пройти неудачных Health checks, чтобы сервис пометить, как Unhealthy.
- Healthy threshold — наоборот, сколько удачных попыток должно пройти, чтобы сервер вернуть в строй.
- Дополнительная логика. Вы можете разбирать Check status + body и пр.
Nginx реализует функции Health check только в платной версии nginx+.
Отмечу особенность Envoy, у него есть Health check panic mode. Когда мы забанили, как «нездоровые», больше, чем N% хостов (допустим, 70%), он считает, что все наши Health checks врут, и все хосты на самом деле живы. В совсем плохом случае это поможет вам не нарваться на ситуацию, когда вы сами себе прострелили ногу, и забанили все серверы. Это способ еще раз подстраховаться.
Собираем все воедино
Обычно для Health checks ставят:
- Либо nginx+;
- Либо nginx+что-то еще:)
В нашей стране есть тенденция ставить nginx+HAProxy, потому что в бесплатной версии nginx нет health checks, и до 1.11.5 не было ограничения на количество соединений с бэкендом. Но это вариант плох тем, что HAProxy не умеет ретраиться после установки соединения. Многие считают, что если HAProxy вернет ошибку на nginx, а nginx сделает retry, то все будет хорошо. На самом деле нет. Вы можете попасть на другой HAProxy и на тот же бэкенд, потому что пулы бэкендов одни и те же. Так вы вводите для себя еще один уровень абстракции, что снижает точность вашей балансировки и, соответственно, доступность сервиса.
У нас nginx + Envoy, но, если заморочиться, можно ограничиться только Envoy.
Какой-такой Envoy?
Envoy — это модный молодежный балансировщик нагрузки, изначально разрабатывался в Lyft, написан на С++. Из коробки умеет кучу плюшек по нашей сегодняшней теме. Вы, наверное, видели его, как Service Mesh для Kubernetes. Как правило, Envoy выступает в роли data plane, то есть непосредственно балансирует трафик, а еще есть control plane, который предоставляет информацию о том, между чем надо распределять нагрузку (service discovery и пр.).
Расскажу пару слов о его плюшках.
Чтобы увеличить вероятность успешного ответа при retry при следующей попытке, можно немного поспать и подождать, пока бэкенды придут в себя. Таким образом мы обработаем короткие проблемы на базе данных. У Envoy есть backoff for retries — паузы между повторными попытками. Причем интервал задержки между попытками экспоненциально возрастает. Первый retry происходит через 0-24 ms, второй — через 0-74 ms, и далее для каждой следующей попытки интервал увеличивается, а конкретная задержка выбирается рандомно из этого интервала.
Второй подход — не специфичная для Envoy штука, а паттерн, который называется Circuit breaking (букв. разрыв цепи или предохранитель). Когда у нас бэкенд притупливает, на самом деле мы его каждый раз пытаемся добить. Это происходит потому, что пользователи в любой непонятной ситуации нажимают refresh-ат страницу, посылая вам все новые и новые запросы. Ваши балансировщики нервничают, отправляют retries, увеличивается количество запросов — нагрузка все растет, и в этой ситуации хорошо бы запросы не посылать.
Circuit breaker как раз позволяет определить, что мы в таком состоянии, быстро отстрелить ошибку и дать бэкендам «отдышаться».
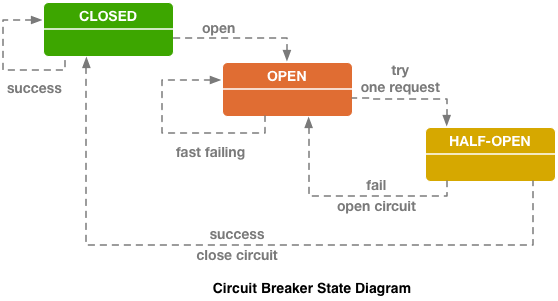
????????Circuit breaker (hystrix like libs), оригинал в блоге ebay.
Выше схема Circuit breaker от Hystrix. Hystrix — это Java-библиотека от Netflix, которая призвана реализовывать паттерны отказоустойчивости.
- «Предохранитель» может находиться в состоянии «закрыто», когда все запросы отправляются на бэкенд и нет никаких ошибок.
- Когда срабатывает некий fail-порог, то есть произошло сколько-то ошибок, circuit breaker переходит в состояние «Open». Он быстро возвращает ошибку клиенту, и на бэкенд запросы не попадают.
- Раз в некоторый промежуток времени, все-таки маленькую часть запросов отправляется на бэкенд. Если срабатывает ошибка, то состояние остается «Open». Если все начинает хорошо работать и отвечать, «предохранитель» закрывается, и работа продолжается.
В Envoy, как такового, этого всего нет. Есть верхнеуровневые лимиты на то, что не может быть больше N запросов на конкретную группу upstream. Если больше, что-то здесь не так — возвращаем ошибку. Не может быть больше N активных retries (то есть retries, которые происходят прямо сейчас).
У вас не было retries, что-то взорвалось — пошли retries. Envoy понимает, что больше, чем N — это ненормально, и все запросы надо отстреливать ошибкой.
Circuit breaking [Envoy]
- Cluster (upstream group) max connections
- Cluster max pending requests
- Cluster max requests
- Cluster max active retries
Эта простая штука хорошо работает, понятно конфигурируется, не надо придумывать особые параметры, и настройки по умолчанию достаточно неплохие.
Circuit breaker: наш опыт
Раньше у нас был HTTP-коллектор метрик, то есть агенты, установленные на серверах наших клиентов, отправляли метрики в наше облако по HTTP. Если у нас случаются какие-то проблемы в инфраструктуре, агент записывает метрики на свой диск и потом пытается их нам дослать.
А агенты постоянно делают попытки отправить нам данные, они не расстраиваются от того, что мы как-то не так отвечаем, и не уходят.
Если после восстановления мы пустим полный поток запросов (к тому же нагрузка будет даже больше обычной, так как нам доливают накопившиеся метрики) на серверы, скорее всего все снова ляжет, так как некоторые компоненты окажутся с холодным кэшем или типа того.
Чтобы справиться с такой проблемой мы зажимали входящий поток записи через nginx limit req. То есть мы говорим, что сейчас мы обрабатываем, допустим, 200 RPS. Когда это все приходило в нормальный режим, мы убирали ограничение, потому что в нормальной ситуации коллектор способен записывать гораздо больше, чем кризисный limit req.
Потом по некоторой причине мы перешли на свой протокол поверх TCP и потеряли плюшки проксирования HTTP (возможность использовать nginx limit req). Да и в любом случае надо было этот участок привести в порядок. Нам больше не хотелось менять limit req руками.
У нас достаточно удобный случай, потому что мы контролируем и клиента, и сервер. Поэтому мы в агенте закодии Circuit breaker, который понимал, что если он получил N ошибок подряд, ему надо поспать, и через какое-то время, причем экспоненциально возрастающее, пытаться заново. Когда все нормализуется, он все метрики доливает, так как у него есть spool на диске.
На сервере мы добавили Circuit breaker код всех обращений во все подсистемы + request cancellation (где возможно). Тем самым, если мы получили N ошибок от Cassandra, N ошибок от Elastic, от базы, от соседнего сервиса — от чего угодно, мы отдаем быстро ошибку и не выполняем дальнейшую логику. Просто отстреливаем ошибку и все — ждем, пока это нормализуется.
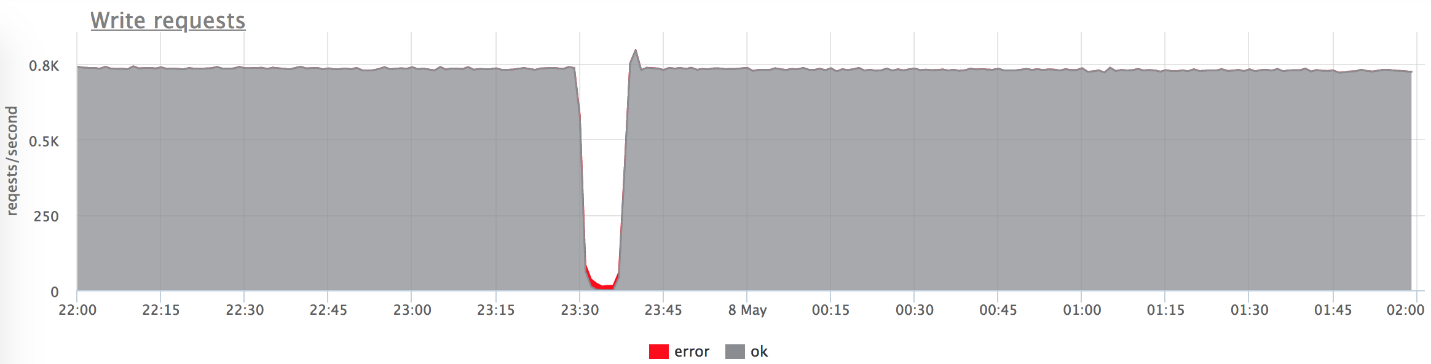
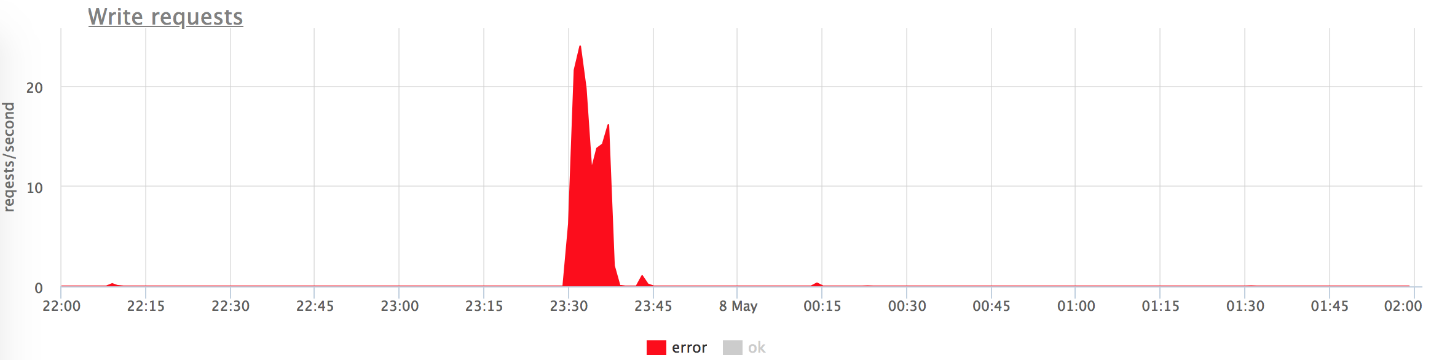
На графиках выше видно, что мы не получаем всплеск ошибок при проблемах (условно: серое — это «двухсотки», красное — «пятисотки»). Видно, что в момент проблем из 800 RPS на бэкенд долетело 20-30. Это позволило нашему бэкенду «отдышаться», подняться, и дальше хорошо работать.
Самые сложные ошибки
Самые сложные ошибки — это те, которые неоднозначны.
Если у вас сервер просто выключился и не включается, или вы поняли, что он мертвый и сами его добили — это на самом деле подарок судьбы. Такой вариант хорошо формализуется.
Намного хуже, когда один серверов начинает вести себя непредсказуемо, например, сервер на все запросы отвечает ошибками, а на Health checks — HTTP 200.
Приведу пример из жизни.
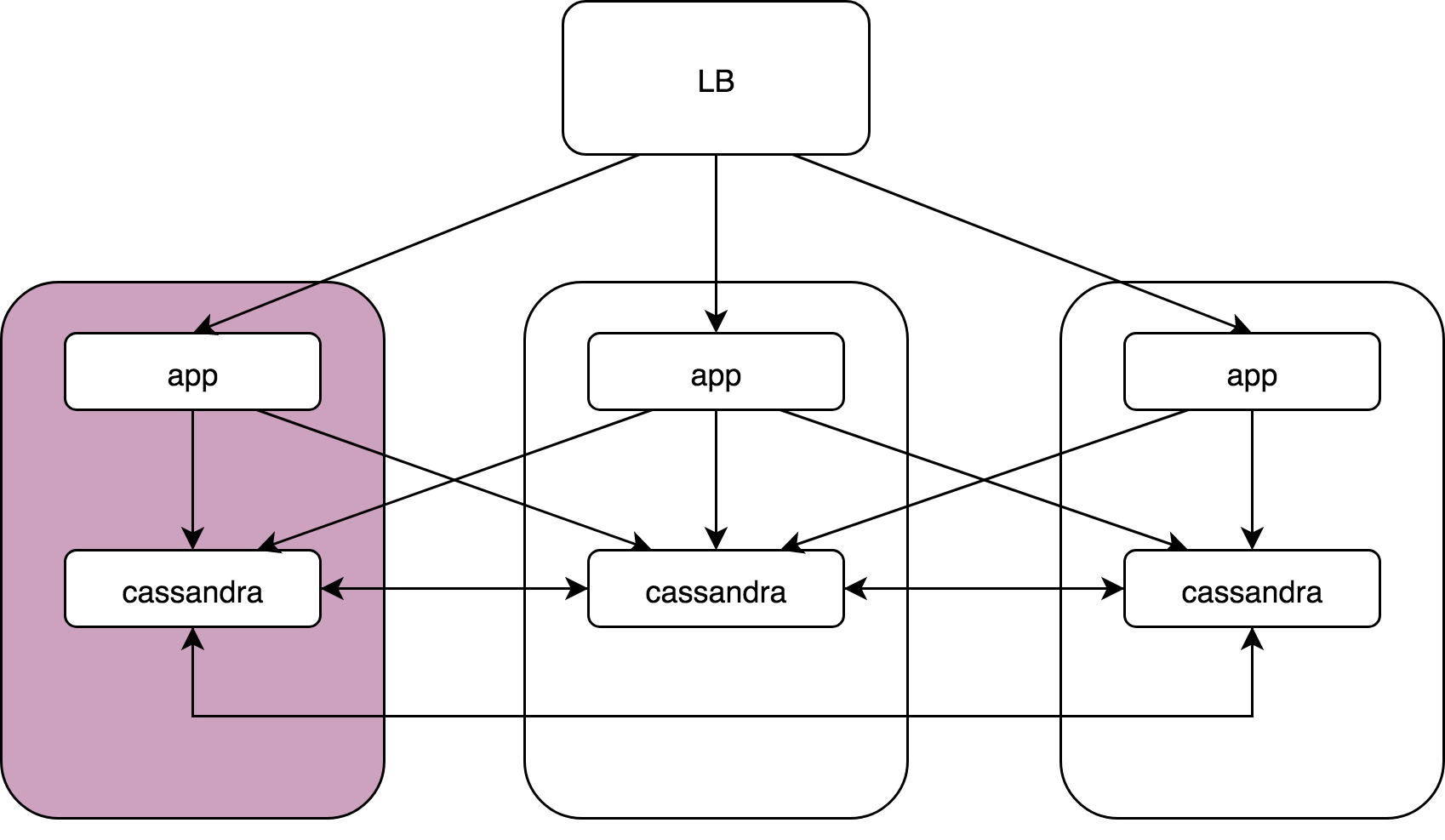
У нас есть некий Load Balancer, 3 узла, на каждом из которых приложение и под ним Cassandra. Приложения обращаются ко всем экземплярам Cassandra, и все Cassandra взаимодействуют с соседними, потому что у Cassandra двухуровневая модель координатор и data noda.
Сервер Шредингера — один из них целиком: kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.
Там произошло следующее: в сетевом драйвере баг (в интеловских драйверах они случаются), и одна из 64 очередей передачи просто перестала отправляться. Соответственно, 1/64 всего трафика теряется. Это может происходить до reboot, это никак не лечится.
Меня, как админа, волнует в этой ситуации, не почему в драйвере такие баги. Меня волнует, почему, когда вы строите систему без единой точки отказа, проблемы на одном сервере в итоге таки приводят к отказу всего продакшена. Мне было интересно, как это можно разрулить, причем на автомате. Я не хочу ночью просыпаться, чтобы выключить сервер.
Cassandra: coordinator -> nodes
У Cassandra, есть те самые спекулятивные ретраи (speculative retries), и эта ситуация отрабатывается очень легко. Есть небольшое повышение latency на 99 перцентиле, но это не фатально и в целом все работает.
App -> cassandra coordinator
Из коробки ничего не работает. Когда приложение стучится в Cassandra и попадает на координатор на «мертвом» сервере, никак это не отрабатывает, получаются ошибки, рост latency и т.д.
На самом деле мы используем gocql — достаточно навороченный cassandra client. Мы просто не использовали все его возможности. Там есть HostSelectionPolicy, в который мы можем подсунуть библиотеку bitly/go-hostpool. Она использует алгоритмы Epsilon greedy для того, чтобы найти и удалить выбросы из списка.
Попытаюсь в двух словах объяснить, как работает алгоритм Epsilon-greedy.
Есть задача о многоруком бандите (multi-armed bandit): вы находитесь в комнате с игровыми автоматами, у вас есть несколько монет, и вы должны за N попыток выиграть как можно больше.
Алгоритм включает две стадии:
- Фаза «explore» — когда вы исследуете: 10 монеток тратите на то, чтобы определить, какой автомат лучше.
- Фаза «exploit» — остальные монетки опускаются в лучший автомат.
Соответственно, маленькое количество запросов (10 — 30%) отправляются в round-robin просто на все хосты, считаем отказы, время ответа, выбираем лучшие. Потом 70 — 90% запросов посылаем на лучшие и обновляем свою статистику.
Host-pool каждый сервер оценивает по количеству успешных ответов и времени ответа. То есть он берет самый быстрый сервер в итоге. Время ответа он вычисляет как взвешенное среднее (свежие замеры более значимые — то, что было прямо сейчас, гораздо весомее). Поэтому мы периодически сбрасываем старые замеры. Так с неплохой вероятностью наш сервер, который возвращает ошибки или тупит, уходит, и на него практически перестают поступать запросы.
Промежуточный итог
Мы добавили «бронебойности» (отказоустойчивости) на уровне приложение—Cassandra и Cassandra coordinator-data. Но если наш балансировщик (nginx, Envoy — какой угодно) шлет запросы на «плохой» Application, который обращаясь к любой Cassandra будет тупить, потому что у него самого сетка нерабочая, мы в любом случае получим проблемы.
В Envoy из коробки есть Outlier detection по:
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
По последовательным «пятисоткам» можно понять, что с сервером что-то не так, и забанить его. Но не навсегда, а на интервал времени. Потом туда начинает поступать небольшое количество запросов — если он опять тупит, мы его баним, но уже на больший интервал. Таким образом, все сводится к тому, что практически никакие запросы не попадают на этот проблемный сервер.
С другой стороны, чтобы защититься от неконтролируемого взрыва этой «умности», мы имеем max_ejection_percent. Это максимальное количество хостов, которое мы можем посчитать за outlier, в процентах от всех доступных. То есть, если мы забанили 70% хостов —это не считается, всех разбаниваем — короче, амнистия!
Это очень крутая штука отлично работает, при этом она простая и понятная — советую!
ИТОГО
Надеюсь, я убедил вас в том, что надо бороться с подобными кейсами. Я считаю, что бороться с выбросами ошибок и latency определенно стоит для того, чтобы:
- Делать автодеплойменты, релизиться нужное количество раз в день и т.д.
- Спать спокойно по ночам, не вскакивать лишний раз по СМС-кам, а проблемные серверы чинить в рабочее время.
Очевидно, что из коробки ничего не работает, примите этот факт. Это нормально, потому что есть очень много решений, которые вам надо принять самим, и софт не может это сделать за вас — он ждет, пока вы его сконфигурируете.
Не нужно гнаться за самым навороченным балансировщиком. Для 99% проблем хватает стандартных возможностей nginx/
Дело не в конкретном proxy (если это не HAProxy:)), а в том, как вы его настроили.
На DevOpsConf Russia Николай расскажет об опыте внедрения Kubernetes с учетом сохранения отказоустойчивости и необходимостью экономить человеческие ресурсы. Что еще нас ждет на конференции можно посмотреть в Программе.
Хотите получать обновления программы, новые расшифровки и важные новости конференций — подпишитесь на тематическую рассылку Онтико по DevOps.
Больше любите смотреть доклады, чем читать статьи, заходите на YouTube-канале — там собраны все видео по эксплуатации за последние годы и список все время пополняется.
Комментарии (5)

neanton
14.09.2018 12:46Все балансировщики, кроме HAProxy, умеют обрабатывать, если все-таки бэкенд вам ответил, но каким-то ошибочным кодом.
Как насчет опцииobserve layer7доступной как минимум с версии 1.4? cbonte.github.io/haproxy-dconv/1.9/configuration.html#5.2-observeNikolaySivko
14.09.2018 13:14Хорошая опция, но это не про повторную попытку, она лишь может пометить данный сервер "мертвым" не дожидаясь результатов health check или спровоцировать health check. Я же говорил именно про ретрай.
aml
14.09.2018 14:18Даже если сервис полностью лежит одну минуту в день (ситуация хуже, чем на первом графике), он все равно находится в зоне трёх девяток по надёжности. В то же время, надёжность, скажем, мобильной связи — 2 девятки. Это значит, что из 10 проблем с загрузкой, когда пользователю приходится ругаться и перезагружать страничку, всего 1 приходится на серверную аварию.
В то же время, чем ближе сервис приближается к абсолютной надёжности, тем дороже становится каждое последующее улучшение. Где-то надо остановиться. Так вот, если надо потратить кучу денег, чтобы снизить серверные ошибки вдвое, но у юзеров всего на 5% снизится число видимых отказов, то оно может того и не стоить.
Все зависит от сервиса, конечно. Это может быть система управления полетами или биржевая система — там другие требования по надёжности. Но во многих случаях я бы согласился с бизнесом — причины проблемы понятны (Вася кабель переключил), повторяться она часто не должна (мы кабели трогаем раз в месяц), на юзеров оно влияет ниже уровня шума — соответственно можно не фиксить и потратить время инженеров более эффективно.
Мораль такая — бугорок на графике ошибок — еще не достаточная причина, чтобы чинить проблему, особенно если цена этого — усложнение системы.
NikolaySivko
14.09.2018 16:00Спору нет, если редко, но у многих 5 раз в день деплой с таким бугорком.
KerLaeda
Отличная статья, очень полезно, глубокий анализ проблемы и сразу методы решения.
Удивлен тем, что универсальный nginx позволяет балансировку настраивать тоньше специализированного haproxy.