
Если вы достаточно долго увлекаетесь нейросетевыми технологиями, то наверняка встречались с мнением, кратко заключенным в риторическом вопросе: «Как ты объяснишь человеку, когда нейросеть считает, что у него рак?». И если в лучшем случае такие мысли заставят тебя сомневаться в использовании нейросетей в достаточно ответственных сферах, то в худшем случае ты можешь и потерять весь свой интерес.
Мне попался лучший вариант — я спокойно принимал такую ограниченность и, особо не задумываясь, продолжал применять нейросетевые технологии в сфере компьютерного зрения.
Задача
Недавно на меня выпала задача — максимально быстро создать работоспособный детектор эмоций. Условия были поставлены достаточно четко — фронтально расположенное лицо разрешением 100х100. В поисках готового датасета я потратил пару часов и понял, что мне практически ничего не подходит. Либо же даже в «исследовательских целях» получить доступ к датасету было слишком трудно. Выход был найден быстро — взять десяток художественных фильмов и простым прогоном по ним каскада Хаара выгрузить все лица. За ночь было получено более(!) 30к изображений. Далее полученные изображения были рассортированы по 5 основным эмоциям(happy, sad, neutral, angry, surprised). Конечно, далеко не все изображения подошли и в итоге на каждую категорию пришлось по 400-500 изображений лиц.
Тут то всё и завязалось с темой объяснения результатов работы нейронных сетей. Даже имея достаточно качественную кастомную аугментацию данных, такой набор данных казался явно недостаточным. При обучении сети на основе блоков Resnet получились следующие цифры для метрик:
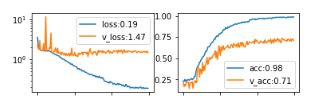
На лицо переобучение на фоне недостаточного числа примеров, но из-за неимения времени необходимо было срочно убедиться, что сеть работает хоть сколько-то удовлетворительно и при определении эмоций не полагается, например, на фон.
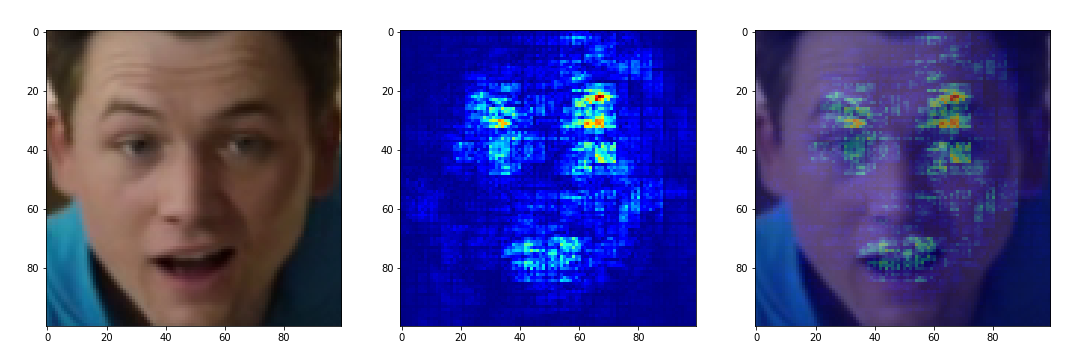
Раньше мне уже приходилось работать с такими инструментами как Lime и Keras-Vis, но именно тут они могли стать философским камнем, превращающим черный ящик в нечто более прозрачное. Суть обоих инструментов примерно одинакова — определить области исходного изображения, несущие наибольший вклад в итоговое решение сети. Для теста я снял видео, на котором имитировал различные эмоции. Выгрузив выражения лица, соответствующие различным эмоциям, я прогнал по ним вышеописанные инструменты
Получились следующие результаты от Lime:

К сожалению, даже меняя различные параметры функций, от Lime не удалось получить достаточно человекопонятного отображения. На принадлежность к классу «angry» почему-то влияет правая половина лица. Единственное, что для «happy» логично выделена область рта и типичных для улыбки ямочек.
Далее, всё те же изображения были прогнаны через Keras-Vis и бинго:
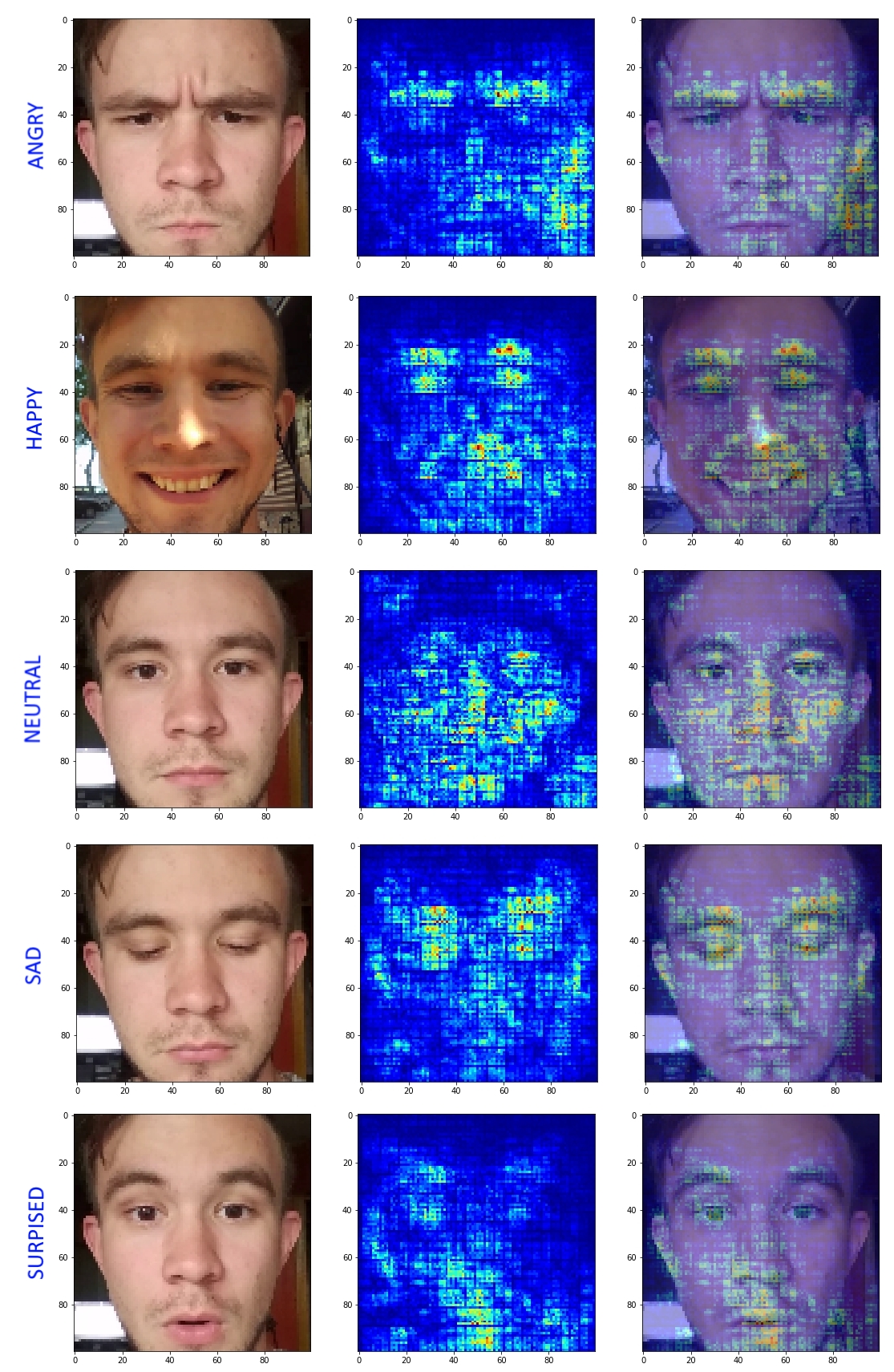
«Happy» ищет расположение глаз и форму рта. «Sad» ориентируется на опущенные брови и веки. «Neutral» старается смотреть на всё лицо в целом и ни в чем невиновные нижние углы изображения. «Angry» логично ориентируется на сдвинутые брови, НО забывает про форму рта и зачем-то ищет фичи в правом нижнем углу. А «Surprised» смотрит на форму рта и левое(!) приподнятое веко — пора бы начать признавать и правое.
Результаты порадовали и дали возможность увидеть сильные и слабые стороны получившейся сети. Почувствовав слабости в классификации классов «Surprised» и «Angry», я нашел в себе силы слегка увеличить выборку и добавил капельку больше дропаута. На следующей итерации были получены следующие результаты:

Видно, что области активаций в большей степени локализовались. Исчезло внимание сети на фон в случае с «Angry». Конечно, сеть всё ещё имеет свои минусы, забывая про бровь с одной стороны и тд. Но данный подход позволил глубже понять, что и почему делает полученная модель. Данный подход идеален в случаях, когда у нас есть сомнения в правильной сходимости сети.
Выводы
Нейронные сети остаются всего лишь решением сложной задачи оптимизации. Но даже простейшие карты внимания сети вносят долю прозрачности в эти дебри. Данный подход можно использовать наравне с обычным ориентированием на функцию потерь, что позволит получать еще более осознанные сети.
Если вспомнить про риторический вопрос из начала статьи, то можно сказать, что использование карт внимания вместе с итоговым откликом сети уже несет в себе определенное человекопонятное объяснение, которого так не хватало.
Визуализируйте, визуализируйте и еще раз визуализируйте!
Комментарии (46)

ZlodeiBaal
16.08.2018 14:46+2Черный ящик — это вещь где нельзя предсказать какой внутренний процесс приведёт к искомому результату. То что вы тут сделали — это лишь наблюдение за сформировавшимся процессом. Но вы не можете влиять на процесс который есть. Не можете сказать что вот это граница между эмоциями, а вот так эмоции трактуются для азиатов.
Человек может оперировать лишь моделью сети, что почти не влияет на логику принятия решения, а скорее на качество/скорость, либо датасетом, тобишь входом системы.
Да, вход зачастую можно подкорректировать исходя из того что происходит внутри. Иногда можно исходя из внутреннего процесса подкорректировать loss-функцию. Но это не делает происходящего не чёрным ящиком:)San_tit
16.08.2018 15:26Строго говоря, черный ящик — это модель, полностью неопределенная.
В случае с НС — это скорее модель, определенная с точностью до структуры. Т.е. с параметрической неопределенностью.
Другое дело, что очень часто назначение конкретного участка структуры неизвестно из-за того, что назначается она "от балды".
С другой стороны, те же сверточные слои вполне имеют известное назначение и роль.
П.С. по сути, обычная мат. модель с неопределенными параметрами является такого же уровня неопределенности, как и НС. Различие заключается в числе параметров (в мат.модели это обычно не так много, а в НС — это тысячи и десятки тысяч со всеми вытекающими).
phenik
16.08.2018 18:30по сути, обычная мат. модель с неопределенными параметрами является такого же уровня неопределенности, как и НС.
Обычные программы с аналитикой или распознаванием основанные на каких-либо мат. моделях тоже можно считать «нейронными» сетями. Только в них параметры подгоняются разработчиком в ручную, то есть фактически обучение берет на себя разработчик, так как готовой процедуры обучения нет. Так же параметры модели в этом случае могут иметь осмысленные значения.
Интересно удастся для нейросетей проделать такой финт. После обучения, просканировать состояние всех весов, и зная структуру сети, построить оптимальную мат. модель входных данных, максимально сократив число переменных и параметров, в сравнении с нейросетью. Как это делает человек, когда после анализа данных подбирает для них наилучшую мат. модель. На вид модели не накладывается никаких ограничений. Конечно параметры этой модели будут неопределенными, и лишь проанализировав их, возможно некоторым можно будет приписать смысл, то есть интерпретировать их в контексте входных данных. Причем проделать это автоматически, запустив процедуру сканирующую любую нейросеть. Для любых типов данных, а не только изображений, и любой размерности. Если можно, то можно будет утверждать, что эти нейросети не «черные ящики», ну или хотя бы «серые».alexeykuzmin0
16.08.2018 19:32Те задачи, в которых можно сделать более простую и более надежную модель, и решаются с помощью более простых и более надежных моделей. Никто не реализует нейросеть, чтобы сложить два числа. Да, некоторый прогресс в классических алгоритмах и структурах данных есть, с каждым годом мы можем решать все более сложные задачи все быстрее, но не сказать, что этот прогресс быстр. Методы машинного обучения призваны решать то, что мы не можем решить строгими подходами.
phenik
17.08.2018 04:26Мой посыл был другим. Можно ли из обученной нейросети получить мат. модель, для изначально не формализованных данных, как это и делает человек. Понятно, что есть данные, для которых это невозможно, и для них будет иметься только нейросетевая аппроксимация. А значит от представления о нейросетях, как «черных ящиках» в общем случае не уйти. Человек, кстати, тоже не все данные может формализовать, так что ситуация аналогичная. Мозг еще долго будет останется «черным ящиком», ну может «сереть» понемногу, по мере прояснения его функций)
fireSparrow
17.08.2018 10:38Никто не реализует нейросеть, чтобы сложить два числа.
Не факт. FizzBuzz на TensorFlow вот решают: habr.com/post/301536
Так что может кто-то и числа нейросетью складывает.
n1ger
17.08.2018 23:23А я думал только меня всю статью не покидает ощущение, что тема — чистый кликбейт.
WinPooh73
16.08.2018 14:54В результате разобраться в логике нейронной сети и найти какие-то закономерности смогла только ещё одна нейронная сеть, естественная.
Dark_Daiver
16.08.2018 15:33Нейронные сети остаются всего лишь решением сложной задачи оптимизации.
Достаточно спорное утверждение. Нейронная сеть это модель, оптимизация всего лишь один из способов задать ее параметры.
pagin Автор
16.08.2018 15:50Да. Тут вместо термина «нейронная сеть» было бы правильнее сказать «машинное обучение». Не сделал я этого лишь оттого, что в моём сознании нейронные сети и оптимизация уже неразрывно связаны (думаю, как и в сознании большинства разработчиков нашего направления)
Vinchi
16.08.2018 16:38Можно наверно точнее сформулировать — МО для бизнеса дает оптимизацию бизнес процессов — сокращение издержек, увеличение прибыли за счет новых возможностей.
А с точки зрения математики, там конечно не только оптимизация. Конечно если в каждой можели мы видим функцию потерь, ее частные производные для движения к оптимуму модели легко назвать это оптимизацией, но это ответ на вопрос «как», а не «зачем».
Да и еще — что значит более ососзнанные сети? :) Скорее визуализация — возможность человеку осознать как устроена сеть и увидеть как можно ее оптимизировать.pagin Автор
16.08.2018 18:24Увидев, как её можно оптимизировать, мы оптимизируем и делаем её более осознанной.
Возможно, сбивает с толку само слово "осознанность" в отношение сети — доля хуманизации :)
AlexVist
16.08.2018 15:51"Нейронные сети остаются всего лишь решением сложной задачи оптимизации. Но даже простейшие карты внимания сети вносят долю прозрачности в эти дебри. Данный подход можно использовать наравне с обычным ориентированием на функцию потерь, что позволит получать еще более осознанные сети.
Если вспомнить про риторический вопрос из начала статьи, то можно сказать, что использование карт внимания вместе с итоговым откликом сети уже несет в себе определенное человекопонятное объяснение, которого так не хватало."
Вот тут уж точно не "человекопонятное", а узкоспециализированно понятное.
pagin Автор
16.08.2018 15:56Кажется, это не выяснить, пока нет конкретного пользовательского опыта. Нужно брать фокус-группу и смотреть, как быстро получилось бы обучить их взаимодействию с выводом сети и картами внимания.
AlexVist
16.08.2018 16:31Это не то чтобы критика. Но все же. Замечание касается того, что затронутая тема, да и включенная цитата… Все это для узкого круга специалистов работающих с нейронными сетями, а не для всех человеков. ))
Vinchi
16.08.2018 16:34Бустинг — вот уж точно черный ящик. Нейросети уже кое-как можно рассмотреть паттерны.
А вы не могли бы раз уж на хабре — написать код, как-то рассказать про keras-vis, а то выглядит несерьезно.pagin Автор
16.08.2018 18:12Я долго думал, добавлять ли в статью технические моменты. Решил, что для первой статьи пусть будет попроще =)
Думаю, что в следующих статьях рассмотрю их подробнее!
Beshere
16.08.2018 17:39Ну это вам просто повезло с предметной областью. А так нейро-сети ждут своих пионеров, но это будут не программисты, которые будут смотреть на картинки, а математики.
pagin Автор
16.08.2018 18:13Соглашусь, что вышеописанное применимо исключительно к области компьютерного зрения =)
dzzirtuoz
16.08.2018 19:21А «Surprised» смотрит на форму рта и левое(!) приподнятое веко — пора бы начать признавать и правое.
А что если сети дополнительно отдавать на проверку зеркальные варианты всех изображений? Интересно, какой у сети окажется процент противоречий самой себе.
Возможно ли заставить сеть смотреть на обе брови, если датасет увеличить вдвое через добавление зеркальных дубликатов?pagin Автор
16.08.2018 19:24Забавно, что в функции аугментации конечно же было зеркальное отображение изображений с вероятностью 0.5. Вероятно, из-за малого числа изображений в обучающей выборке, выравнивания активаций относительно вертикальной оси не произошло.
Ведь при малом числе измерений вероятность 0.5 — это далеко не 0.5 =)dimm_ddr
17.08.2018 18:51Это не совсем интуитивно, но может быть сеть права и нужно смотреть только на одну сторону? Для меня, например, совсем не очевидно что в естественных условиях будут встречаться оба варианта с хотя бы примерно одинаковой частотой. Или может быть левое веко все равно отличается. Было бы интересно посмотреть на процент ошибок разных родов с незеркальными относительно центральной оси признаками.
maxood
17.08.2018 01:23Скармливать необходимо не только зеркальные, но «jittered» изображения. Кстати, веко, упомянутое автором — правое, а не левое…

vibrant
16.08.2018 19:27+2Так и не понял, почему нужно перестать называть НС черным ящиком(
К сожалению, даже меняя различные параметры функций, от Lime не удалось получить достаточно человекопонятного отображения. На принадлежность к классу «angry» почему-то влияет правая половина лица.
В двух предложениях — описание черного ящика. Визуализация зависит от правильного подбора параметров этой самой визуализации, я знаю тысячу способов построить карту активации и везде мы получим разные картинки. Дальше, интерпретация вот этого всего — это проблема, «почему-то влияет правая половина лица» — на «самом деле» может это левая бровь внесла больший вклад в результат или просто цвет лица или вообще фон картинки, и таких интерпретаций = бесконечность.
pagin Автор
16.08.2018 19:31Хорошее замечание!
Думаю написать в ближайшем будущем статью про выбор способа построения карты активации и параметров. Чем больше активаций с одними параметрами мы построим, тем больше сократим число возможных интерпретаций! Если, конечно, сеть хоть как-то сошлась.
Если же на большом числе полученных карт не будет виден тренд, то у нас плохая сеть =)vibrant
16.08.2018 21:30По теме визуализации и интерпретации куча работ. Вывод везде один — это как смотреть на облачка и пытаться там увидеть что-то знакомое. Иногда это «работает» — и в самом деле иногда можно увидеть силуэты из реального мира.
Чем больше карт вы построите, тем больше простора для воображения, но это никак не приблизит к одному единственному правильному объяснению, которое выглядит как-нибудь банально: 14-й, 88-й, и 146-й пиксель сделали весь праздник, а мы тут ищем высокоуровневые признаки, о которых знаем только мы — «пол лица», бровь, нос.
Попробуйте one pixel attack и увидите, как всего один пиксель в нужном месте сломает вам и нейронку, и все интерпретации. arxiv.org/abs/1710.08864
Обожаю визуализацию данных, но считаю с НС это путь в никуда, единственно верный вариант здесь — ну очень тонко понимать математику. Наверное такие люди есть, зато нет ни одного такого, кто бы смог объяснить, что и как эта нейронка делает.pagin Автор
16.08.2018 21:40Я наслышан про OnePixAttack.
Повторюсь, что учитывая связь данной темы с биологией, есть смысл в том, чтобы считать идеалом совпадение собственного и нейросетевого восприятий. Можно посмотреть, например, на визуализацию слоёв VGG и увидеть, что высокоуровневые признаки — это реальная, практически объективная сущность.
«14-й, 88-й, и 146-й пиксель сделали весь праздник» — кажется, мы именно противоположному и учим сеть, создавая большие датасеты и добавляя аугментацию
YetAnotherSlava
17.08.2018 10:56Лiл
>14-й, 88-й, и 146-й пиксель
Эта фраза является хорошим примером малозаметного, но очень важного признака, который однако же не все поймут.
… ничто не выдавало в нем русского разведчика: ни рация за спиной, ни волочащийся сзади парашютvibrant
17.08.2018 14:39Лiл
вы перепутали сайт со своим свинарникомYetAnotherSlava
17.08.2018 17:42Не ругайтесь. Я это выражение употреблял задолго до, как им многие другие. И к 404 никакого отношения не имею. Мне просто приятно видеть знакомую символику на ресурсе, который яростно старается выхолостить весь контент и убрать всё, что имеет отношение к политике. Стараться-то старается, но не получается.
demimurych
16.08.2018 21:15+1Простите если я что-то не понял,
но разве подгонка результата под то, каким образом эксперементатор воспринимает проблему, является достаточным основанием для того, чтобы раскрыть проблему черного ящика?
Почему визуализация, а точнее ее восприятие экспериментатором является достаточным основанием для того чтобы влиять на сеть? Не кажется ли Вам что в данном случае вы создаете сеть, которая, в некотором роде, является копией вашего восприятия, а не понимаете почему именно такие решения для нее (сети) являются правильными?pagin Автор
16.08.2018 21:31Мой эксперимент следует из априорного предположения о том, что нейронные связи в нашем мозгу — это идеальный вариант нейросети. Соответственно, достижение близости её восприятия к собственному является целью.
demimurych
16.08.2018 21:39+1Еще раз простите, если я опять скажу какую-нибудь глупость но
в результате, вы получаете сеть, которая распознает то, каким образом лично Вы имитируете эмоций. Подчеркиваю, не распознает эмоции, а узнает ваши имитации.
И вы не столько раскрываете черный ящик, сколько создаете условия при которых открыв его, вы увидите там то что хотите увидеть.
Иными словами, то что вы положили внутрь ящика яблоко, не дает вам оснований утверждать что вы понимаете почему это именно яблоко, и почему лично вы это считаете это яблоком.
Вам это даете только право утверждать, что с высокой долей вероятности, ваша сеть скажем вам то, что вы и так знали — вы положили туда яблоко. Но вы так и не поймете почему сеть поняла что это именно яблоко и что оно лежит именно там.
pagin Автор
16.08.2018 21:47А, я понял, в чем столкновение.
«Вы получаете сеть, которая распознает то, каким образом лично Вы имитируете эмоций» — конечно же, предполагается, что активации нужно смотреть на максимально широком пространстве(т.е. не только на моих фотографиях). И только тогда можно будет говорить о какой-то объективности результатов.
Один из вариантов — создать отдельную валидационную выборку, подсчитать на каждом изображении в ней активации и затем отобразить средние значения
dim2r
17.08.2018 13:33Интересно, как Keras-Vis определяет области? Наверное как-то анализирует, какие наибольшие веса подходят к разным областям.
Насколько я понимаю, можно еще делать «от обратного». Закрываешь разные части картинки черными квадратами и смотришь, — какие части начинают влиять на выбор класса.alexeykuzmin0
17.08.2018 15:00Метод обратного распространения ошибки считает градиент функционала качества по весам каждого нейрона каждого слоя. Те пиксели, соответствующие которым нейроны входного слоя имеют большой по модулю градиент, являются важными.
Это чисто по логике, ни разу не использовал Keras-Vis.
GAG
17.08.2018 18:12Пропустив про "художественные фильмы", но обратив внимание на то, что "за ночь было получено более 30 тысяч изображений", ожидал увидеть на следующей картинке эмоции Саши Грей. Пятница, что ж.

Hardcoin
Потому что это были не лица, не фронтальные или неподходящие эмоции? Я так понял, что из 30к изображений осталось 2.5к, совсем мало.
pagin Автор
Да, не фронтальные изображения лиц, мусор и лица с непонятными эмоциями
Hardcoin
Вот по поводу последнего есть вопрос. В продакшене тоже будет много лиц "с непонятными эмоциями". Выкидывая их из датасета не получим ли мы низкое качество определения (условно, случайную эмоцию) именно на таких сложных случаях?
pagin Автор
Задача была не для продакшена. Целью было, скорее, показать возможности работы архитектуры сети на блоках ResNet, а также получить примерную оценку по скорости работы. Однако, всё это переросло в данное исследование =)