

Свою рабочую станцию мне выдалось собирать, будучи студентом. Достаточно логично, что я отдавал предпочтение вычислительным решениям AMD. потому что это дешево выгодно по соотношению цена/качество. Я долго подбирал компоненты, в итоге уложился в 40к с комплектом из FX-8320 и RX-460 2GB. Сначала этот комплект казался идеальным! Мы с соседом по комнате слегка майнили Monero и мой набор показывал 650h/s против 550h/s на наборе из i5-85xx и Nvidia 1050Ti. Правда, от моего набора в комнате бывало слегка жарковато по ночам, но это решилось, когда я приобрел башенный кулер к CPU.
Сказка кончилась
Всё было как в сказке ровно до тех пор, пока я не увлекся машинным обучением в сфере компьютерного зрения. Даже точнее — до тех пор, пока мне не пришлось работать с входными изображениями разрешением больше 100х100px (до этого момента мой 8-ядерный FX резво справлялся). Первой сложностью оказалась задача определения эмоций. 4 слоя ResNet, входное изображение 100х100 и 3000 изображений в обучающей выборке. И вот — 9 часов обучения 150 эпох на CPU.
Конечно, из-за такой задержки страдает итеративный процесс разработки. На работе у нас стояла Nvidia 1060 6GB и обучение похожей структуры(правда, там обучалась регрессия для локализации объектов) на ней пролетало за 15-20 минут — 8 секунд на эпоху из 3.5к изображений. Когда у тебя такой контраст под носом, дышать становится еще труднее.
Что-ж, угадайте мой первый ход после всего этого? Да, я пошёл выторговывать 1050Ti у моего соседа. С аргументами о ненужности CUDA для него, с предложением обмена на мою карту с доплатой. Но всё тщетно. И вот я уже выкладываю свою RX 460 на Авито и рассматриваю заветную 1050Ti на сайтах Ситилинка и Технопоинта. Даже в случае успешной продажи карты мне пришлось бы найти еще 10к(я студент, пусть и работающий).
Гуглю
Окей. Я иду гуглить, как юзать Radeon под Tensorflow. Заведомо зная, что это экзотическая задача, я особо не надеялся найти что-то толковое. Собирать под Ubuntu, заведётся или нет, получить кирпич — фразы, выхваченные с форумов.
И вот я пошел другим путём — я гуглю не "Tensorflow AMD Radeon", а "Keras AMD Radeon". Меня моментально кидает на страничку PlaidML. Я завожу его за 15 минут(правда, пришлось сдаунгрейдить Keras до 2.0.5) и ставлю учиться сеть. Первое наблюдение — эпоха идет 35 сек вместо 200.
Лезу исследовать
Авторы PlaidML — vertex.ai, входящая в группу проектов Intel(!). Цель разработки — максимальная кроссплатформенность. Конечно, это добавляет уверенности в продукте. Их статья рассказывает, что PlaidML конкурентноспособен с Tensorflow 1.3 + cuDNN 6 за счет "тщательной оптимизации".
Однако, продолжим. Следующая статья в какой-то степени раскрывает нам внутреннее устройство библиотеки. Основное отличие от всех других фреймворков — это автоматическая генерация ядер вычислений(в нотации Tensorflow "ядро" — это полный процесс выполнения определенной операции в графе). Для автоматической генерации ядер в PlaidML очень важны точные размеры всех тензоров, константы, шаги, размеры сверток и граничные значения, с которыми далее придется работать. Например, утверждается, что дальнейшее создание эффективных ядер различается для батчсайзов 1 и 32 или для сверток размеров 3х3 и 7х7. Имея эти данные фреймворк сам сгенерирует максимально эффективный способ распараллеливания и исполнения всех операций для конкретного устройства с конкретными характеристиками. Если посмотреть на Tensorflow, то при создании новых операций нам необходимо реализовать и ядро для них — и реализации сильно различаются для однопоточных, многопоточных или CUDA-совместимых ядер. Т.е. в PlaidML явно больше гибкости.
Идем далее. Реализация написана на самописном языке Tile. Данный язык обладает следующими основными преимуществами — близость синтаксиса к математическим нотациям (да с ума же сойти!):
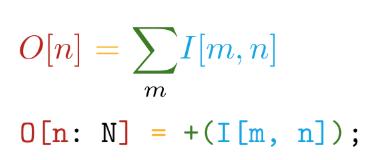
И автоматическая дифференциация всех объявляемых операций. Например, в TensorFlow при создании новой пользовательской операции настоятельно рекомендуется написать функцию для вычисления градиентов. Таким образом, при создании собственных операций на языке Tile нам нужно сказать лишь, ЧТО мы хотим посчитать, не задумываясь о том, КАК это считать в отношении аппаратных устройств.
Дополнительно производится оптимизация работы с DRAM и аналогом L1-кэша в GPU. Вспомним схематичное устройство:
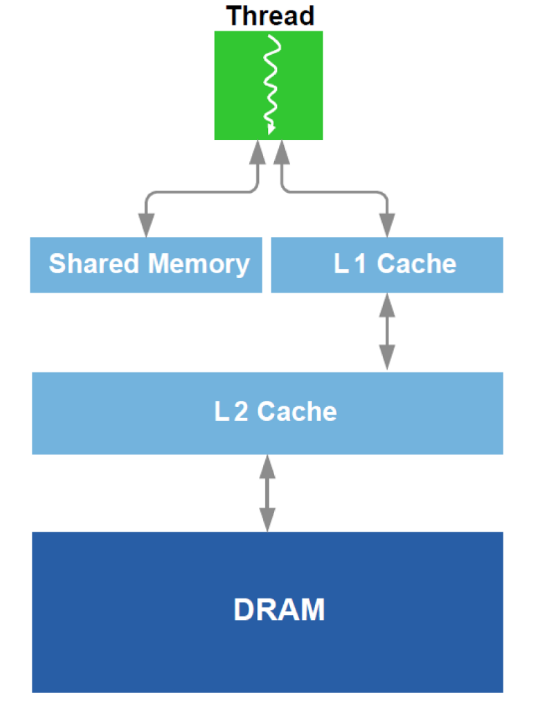
Для оптимизации используются все доступные данные об оборудовании — размер кэша, ширина линии кэша, полоса пропускания DRAM и тд. Основные способы — обеспечение одновременного считывания достаточно больших блоков из DRAM(попытка избежать адресации в разные области) и достижение того, что данные, загруженные в кэш, используются несколько раз(попытка избежать перезагрузок одних и тех же данных несколько раз).
Все оптимизации проходят во время первой эпохи обучения, при этом сильно увеличивая время первого прогона:
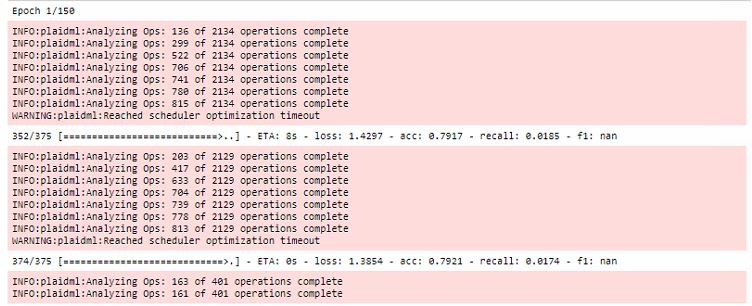
Кроме того, стоит отметить, что данный фреймворк завязан на OpenCL. Главный плюс OpenCL в том, что это стандарт для гетерогенных систем и ничего не мешает Вам запустить kernel на CPU. Да, именно тут кроется один из главных секретов кроссплатформенности PlaidML.
Заключение
Конечно, обучение на RX 460 всё еще идет в 5-6 раз медленнее, чем на 1060, но вы сравните и ценовые категории видеокарт! Потом у меня появилась RX 580 8gb(мне одолжили!) и время прогона эпохи сократилось до 20 сек, что уже почти сопоставимо.
В блоге vertex.ai есть честные графики (больше — лучше):
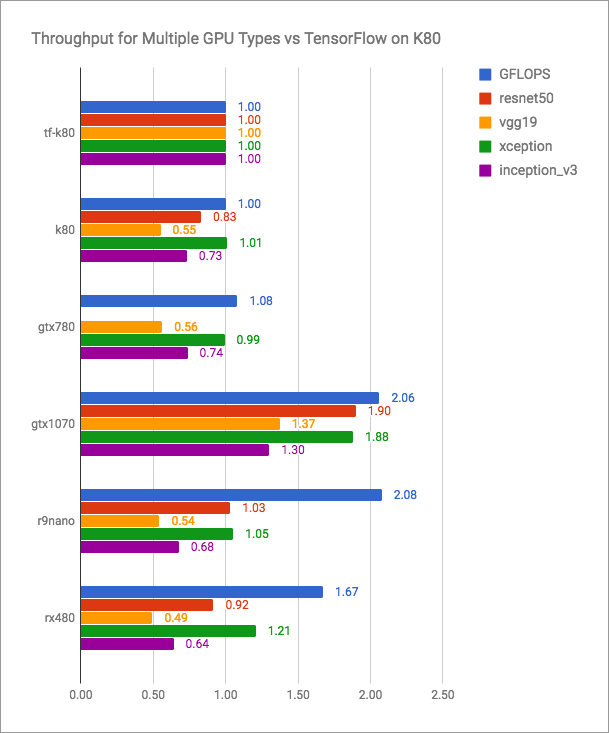
Видно, что PlaidML конкурентноспособен по отношению к Tensorflow+CUDA, но точно не быстрее для актуальных версий. Но в такую открытую схватку разработчики PlaidML, вероятно, и не планируют вступать. Их цель — универсальность, кроссплатформенность.
Оставлю здесь и не совсем сравнительную таблицу со своими замерами производительности:
| Вычислительное устройство | Время прогона эпохи (батч — 16), с |
|---|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB plaid | 35 |
| RX 580 8 GB plaid | 20 |
| 1060 6GB tf | 8 |
| 1060 6GB plaid | 10 |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 plaid | 240 |
| GT 640 plaid | 46 |
Последняя статья в блоге vertex.ai и последние правки в репозитории датированы маем 2018 года. Кажется, если разработчики данного инструмента не перестанут релизить новые версии и всё больше людей, обиженных Nvidia, будут ознакомлены с PlaidML, то про vertex.ai скоро будут говорить намного чаще.
Расчехляйте свои Radeon'ы!
Комментарии (27)

djinninia
24.08.2018 11:28У меня тоже amd видео карта. Хотела протренироваться с нейронными сетями. Были мысли арендовать удалённую машину с nvidia. Спасибо, что просветили.
ZlodeiBaal
24.08.2018 13:16То что keras запускается — это уже хорошо:)
Но, скажу по своему опыту — как только появятся лишние деньги — переходите на NVIDIA.
Ловля маловразумительных багов, которые обусловлены opencl/сборкой энтузиастов — будет стоить дороже. Я тоже начинал прогать на gpu-шках с opencl. На хабре первую статью на эту тему писал даже. Но весь продакшн код был на куде:)
У вас будет минимальная скорость поддержки новых слоёв/решений. Не получиться запустить чужие семплы достаточно сложные, и.т.д. Так что бегите;)
pagin Автор
24.08.2018 14:26Полностью согласен насчёт продакшена.
Считаю, данный подход в большинстве своём актуален в рамках прототипирования на Керасе и вывода моделей на нетипичные вычислительные устройства.
evocatus
24.08.2018 14:52Грустно. Отрасль только-только взлетела и уже превращается в монокультуру семимильными шагами.
buzzroll
24.08.2018 15:28чего грустного, обычный эволюционный процесс. Вот так и люди.
evocatus
24.08.2018 16:21Да, эволюционный процесс, но не чисто технический, т.е. в данном случае побеждает не более совершенная технология, а та, которую насильно продвигают. Вливая деньги, заработанные на других направлениях, в PR и всякую бесплатную «обучающую» заманиловку.
San_tit
24.08.2018 16:59+1Тут несколько сложнее: по сути на момент массового появления ML академическая среда уже плотно сидела на CUDA (Теслы разного рода) для совершенно других задач. Когда математикам же приспичило считать огромные нейросети, очевидным решением было писать под CUDA, ну и дальшее написание огромного массива кода. А т.к. платформа по сути закрыта, то переход на альтернативу практически невозможен.
buzzroll
24.08.2018 17:32Отчего же? Не просто так ведь сложилась ситуация, когда DL == CUDA. nVidia раньше и успешнее стали этим заниматься, и результат налицо. Красные всегда были на позиции если не конкретно отстающих, то лишь догоняющих.
Alcor
24.08.2018 18:11+3Честно говоря, не всё так просто. Начинал заниматься вычислениями на gpu ещё до cuda/opencl и волей-неволей следил за началом этой истории. Появились они на рынке практически одновременно, но nvidia пришла сразу с хорошей ide, профайлером, примерами и рекламой, а красные ..., красные сделали ставку на opensource и проиграли, решили, что сообщество (на тот момент ещё не сформировавшееся) за них всё само сделает, хотя железо изначально было примерно одинаковое, да и более популярны были радеоны в начале.
mistergrim
27.08.2018 05:44Эволюция — это когда побеждает не более совершенный, а более приспособленный. Что в данном случае и наблюдаем.
inferrna
24.08.2018 18:09+1Некоторые мысли по сабжу:
1. OpenCL, это не только radeon, но и intel, телефоны, FPGA, утюги.
2. OpenCL отстаёт в развитии от куды, из-за необходимости учитывать в API особенности работы на устройствах разного типа.
3. В противовес п.2: когда нужно выбрать наиболее производительное решение на доллар и/или на ватт — пишут майнер на OpenCL, так когда же выбирают CUDA? Не хочется думать про гранты с откатами.
4. Этот самый PlaidML не обновлялся 4 месяца — можно считать, что проект практически мёртв.
5. TF тихой сапой портируют на OpenCL, правда пока только при помощи проприетарного SYCL от computecpp tensorflow/issues/22Alcor
24.08.2018 18:22+1Проблема в том, что если написать и оптимизировать ядро на Cuda, то оно работать будет одинаково быстро на всех картах линейки, причем если производительности будет не хватать, всегда можно взять карту получше/на кластер переползти. А с opencl всё сложнее — да, оно, может быть, запустится на абстрактном утюге, но для того, чтобы оно на нем заработало эффективно, его нужно будет переписать под архитектуру этого утюга, а это деньги, а если при этом утюг мало распространён, то кто будет этим заниматься?
inferrna
24.08.2018 18:32У майнеров же как-то получается майнить. Кстати, не знаю, как там на куде, но OpenCL изначально заточен на параллельную работу на нескольких устройствах.
pagin Автор
24.08.2018 18:41Кстати, это чувствуется при обучении. Если стоят одновременно и карта, и процессор от AMD, то оба оказываются загружены где-то на 50-60%.
Я не смог разобраться точно, в чем дело.
Но вероятно, что из-за этой фичи OPENCL часть ядер создаётся для CPUinferrna
24.08.2018 19:01Загруз 50% — отсюда в 2 раза более слабый результат 580 vs 1060. Возможно кстати, дело действительно в том, что разработчики фреймворка пытаются задействовать сразу все доступные устройства, из-за чего и возникают тормоза (процессор не успевает ни свои данные обработать, ни видеокарте подвезти).
pagin Автор
24.08.2018 19:49Возможно, это наоборот улучшает результат.
У них же так разгружаются линии RAM и кэша.
Плюс оптимальная производительность достигается явно не при 100% загрузки.
Dark_Daiver
24.08.2018 18:44+1Применительно к DL все еще веселей. Основные вычисления в фреймворках, как я помню, происходят не за счет CUDA а за счет cuDNN которая не написана на CUDA а использует что-то типа местного ассемблера, который простым смертным недоступен.
arquolo
24.08.2018 21:06+3А как же ROCm? Там уже есть поддержка TensorFlow 1.8. Даже бенчмарки есть, правда для TF1.3. Т.е. связку из Keras+TensorFlow можно использовать в том числе и на видеокартах от AMD.
pagin Автор
24.08.2018 21:07О, спасибо за ссылку! Обязательно попробую на досуге.
Возможно, когда-то напишу сравнительную статью про разные другие бэкенды
JerleShannara
24.08.2018 23:24О, спасибо за наводку. Попробую запустить это дело на FPGA. Если что — набор входных данных и параметров (1 в 1 какие вы и использовали) можно будет получить.
Vlad_IT
Так система охлаждения же не убивает тепло, она его рассеивает быстрее, и тепловая энергия испускаемая процессором в комнату не уменьшилась. Возможно, вентилятор побольше рассеивал тепло равномерно по комнате.
springimport
Тоже резануло, но автор все же не ошибся. Читал что чем горячее цп тем еще сильнее он потребляет энергию и еще больше разогревается.
Так что в этом может быть смысл.
Vlad_IT
А как же троттлинг? По достижению процессором определенной температуры, он сбрасывает частоты, а значит тепловыделение и потребление.
springimport
Сбрасывает, но как это отменяет то что при работе на предельной температуре тепловыделение растет.