
Конечно, мне далеко до профессиональных программистов, и лингвистом я тоже не являюсь, но системное мышление имеется, и чувство языка на месте. Тем более что тематикой ИИ давно интересуюсь, даже пару-тройку постов накатал в свое время. Отчего не реализовать познания в программном коде? Ну и попробовал, насколько смог.
Знакомьтесь, Ваня Разумный.
Ниже находится описание проблем, возникших передо мной на этом хоженом-перехоженом пути, и способов их преодоления.
По поводу результата оговорюсь сразу: целью был не программный код, а формулировка принципов искусственного мышления, функционирующего НЕ на основе физической реальности, как биологические организмы, а на основе СИНТАКСИСА. Поклонники теста Тьюринга, нейронных сетей и машинного обучения могут не беспокоиться.
Внимание, материал объемный.
Ушат холодной воды
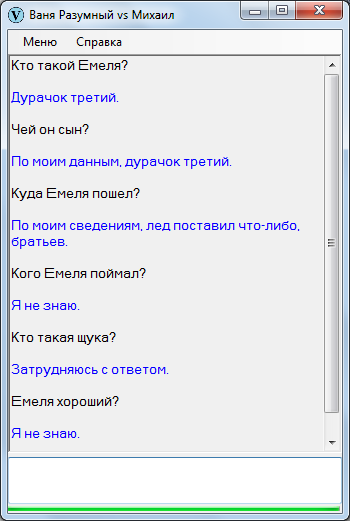
Чтобы не было беспочвенных ожиданий с последующими ехидными скриншотами в комментариях, сразу продемонстрирую Ваню Разумного в непрезентабельном виде. Вот, закачал начало «Емели» и попробовал поспрашивать – в точности как на уроках литературы в начальных классах.
Оригинальный текст:
Жил-был старик. У него было три сына: двое умных, третий – дурачок Емеля. Те братья работают, а Емеля целый день лежит на печке, знать ничего не хочет.
Один раз братья уехали на базар, а бабы, невестки, давай посылать его:
— Сходи, Емеля, за водой.
А он им с печки:
— Неохота…
— Сходи, Емеля, а то братья с базара воротятся, гостинцев тебе не привезут.
— Ну, ладно.
Слез Емеля с печки, обулся, оделся, взял ведра да топор и пошел на речку. Прорубил лед, зачерпнул ведра и поставил их, а сам глядит в прорубь. И увидел Емеля в проруби щуку.
Диалог:
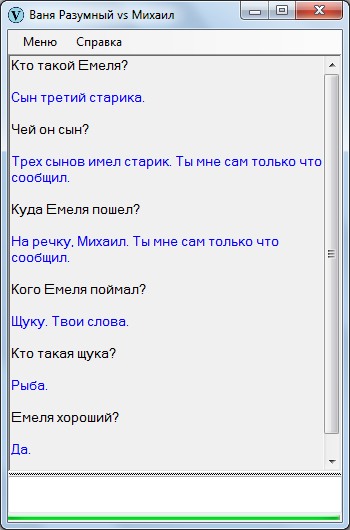
Однако, текст можно адаптировать – так, допустим:
Старик имел трех сыновей. Первый сын был умным. Второй сын был умным. Третий сын был дураком. Емеля – третий сын старика. Емеля хороший.
Старшие сыновья работают целый день, а Емеля лежит на печи.
Однажды братья уехали на базар. Невестки говорят Емеле:
— Сходи за водой.
Емеля отвечает с печки:
— Не пойду за водой.
Невестки говорят:
— Братья гостинцев тебе не привезут.
— Ну, ладно.
Емеля слез с печки, обулся, оделся, взял ведра и топор. Потом Емеля пошел на речку.
Емеля прорубил лед и зачерпнул ведра. И увидел Емеля в проруби щуку. Щука – это рыба. Емеля поймал щуку.
После адаптации выходит поприличней:
Все равно, в художественных текстах непозволительно путается. Несмотря ни на что, Ваня действительно мыслит, в отличие от многих своих собратьев, в первую очередь созданных на основе нейронных сетей, которые только притворяются разумными, но по факту являются ими не более чем пластмассовые куклы. Если вам интересно знать, почему, читайте дальше.
Перехожу непосредственно к описанию интеллектуальной одиссеи.
Теоретическое обоснование
Рассуждал я следующим образом.
В чем главная проблема ИИ? В том, что компьютер не может понимать значений слов, соответственно быть «разумным». При этом считается, что люди разумны, поскольку понимают произносимые собеседником слова.
На самом деле ни черта люди не разумны. Слово само по себе означает не больше, чем составляющие его буквы (по сути, кривые линии) или звуки (колебания воздуха). Смысл возникает лишь в качестве отношений между буквами-звуками как элементами членораздельной речи, за счет устойчивых ассоциаций, в том числе за счет связей с миром визуальных восприятий. Например, собеседник указывает на предмет и говорит: «Это дерево». И ты понимаешь, что данный предмет называется деревом.
Чат-боту (под которым договоримся понимать ИИ, занимающийся исключительно разговорами) нельзя указать на предмет и сказать: «Это дерево», – за счет отсутствия у чат-бота глаз, то есть видеокамеры. Объяснять возможно лишь на словах, а как объяснишь, если человеческой речи он и не разумеет?!
По счастью, отношения между элементами речи определены, и довольно жестко: за них отвечает синтаксис. Следовательно, любой текст, построенный по законам синтаксиса, содержит в себе некоторый, закрепленный в синтаксисе смысл. Та самая вынесенная в заголовок «глокая куздра», знаменитая и непревзойденная по наглядности – которая, как оказалось, давно пристегнута к компьютерным исследованиям.
Из воспоминаний одного товарища о далеких 70-х:
«Глокая куздра штеко будланула бокра и кудлачит бокренка».
В 70е годы искусственным интеллектом занимались в ВЦ АН СССР, в ИПУ АН СССР и нескольких др. институтах. В том числе было направление, которое занималось машинным переводом. Проблема не решалась годами, семантическая неоднозначность не давала перевести смысл без контекста. Было не понятно, как формализовать контекст в компьютерной программе. И вот Д. А. Поспелов /наверно/ распространил пример, иллюстрирующий трудность этого перевода. Он взял фразу, которая состоит из бессмысленных слов, но вместе с тем по строю предложения и звучанию слов создает совершенно ясные одинаковые ассоциации у совершенно разных людей. Этот эффект понимания не мог быть достигнут машиной. Действительно, Глокая куздра – этакая злая коза – она, ясное дело, сильно боднула козла и что-то несусветное творит с козленком… Семинары по машинному переводу проходили и в ИПУ, и я встречал на доске такое вот оглавление: «Глокая куздра. Семинар пройдет в 14.00 в 425 ауд.».
Справка. Автор этой фразы – известный языковед, академик Лев Владимирович Щерба. Корни входящих в нее слов созданы искусственно, суффиксы и окончания позволяют определить, к каким частям речи относятся эти слова и вывести значение фразы. В книге Л. В. Успенского «Слово о словах» приведен ее общий смысл: «Нечто женского рода в один прием совершило что-то над каким-то существом мужского рода, а потом начало что-то такое вытворять длительное, постепенное с его детенышем».
Источник kuchkarov.livejournal.com/13035.html
На основе «глокой куздры» можно построить полноценный диалог.
— Кто будланул бокра?
— Куздра.
— Кто кудлачит бокренка?
— Тоже куздра.
— Какая она?
— Глокая.
— Как будланули бокара?
— Штеко.
Такой ИИ – вполне себе свободно общающийся – окажется не в состоянии понимать значения употребляемых им слов: будет не в курсе, ни что такое «штеко», ни кто такой «бокр», ни каким образом возможно кудлачить. Но разве по этой причине можно посчитать, что ИИ неразумен, а человек, совершенное биологическое создание, «разумеющее» семантику собственных выражений, полноценно, в отличие от ИИ, мыслит? Полноте…
Люди не видят предметов, а наблюдают панораму цветных точек – по сути, хаотичную. Предметы образуются не во внешнем мире, а в человеческом мозгу, за счет увязывания цветных точек воедино, в отдельные совокупности. Это означает, что мы существуем в некоем иллюзорном мире, который в известном смысле нами же и сконструирован.
Читал, что какое-то первобытное племя не видит самолетов в небе – просто не видит, и все. Еще читал, что индейцы не замечали подошедших к берегам кораблей Колумба, потому что… просто не замечали. А заметили после того, как им объяснили, как надо смотреть – то есть каким образом увязывать цветные пиксели в конкретные предметы. Я этим псевдогеографическим байкам верю: такие зрительные парадоксы представляются мне правдоподобными.
У человека нет оснований считать, что его мышление устроено каким-то особенным образом, посему принцип «глокой куздры» – единственная возможность сделать разумным кого-то, будь то чат-бот или человек. Использовать можно различный инструментарий, но принципиальная схема является безусловной. Я так считал до начала работы и не переменил своего мнения по ее окончании.
Библиотеки
Поставив задачу, принялся гуглить по поводу подходящих библиотек для C#.
Тут меня ожидало первое разочарование: ничего пригодного, во всяком случае бесплатного, не обнаруживалось. Всяческие готовые модули для реализации чат-ботов не требовались, интересовала работа со словоформами. Казалось, что проще:
а) определять морфологические признаки словоформы,
б) возвращать словоформу с требуемыми морфологическими признаками?
Лексикон ограничен, количество признаков тоже. И вещь такая полезная, обиходная… Не тут-то было!
Ничего не найдя, сгоряча попробовал закодить определитель морфологических признаков самостоятельно. Как-то сразу не задалось. На этом моя интеллектуальная одиссея и завершилась бы бесславно, в порту отправления, если бы повторное, более тщательное, гугление не выявило пару бесплатных библиотек, которыми я в конечном счете и воспользовался. Как всегда, спасибо энтузиастам.
Первая библиотека – Solarix. Многое чего позволяет, но я, в силу малой компетентности и финансовой недостаточности (библиотека бесплатная лишь частично), использовал безусловно бесплатный парсер, производящий синтаксический разбор текста и записывающий результат в файл.
<?xml version='1.0' encoding='utf-8' ?>
<parsing>
<sentence paragraph_id='-1'>
<text>мама мыла грязную раму.</text>
<tokens>
<token>
<word>мама</word>
<position>0</position>
<lemma>мама</lemma>
<part_of_speech>СУЩЕСТВИТЕЛЬНОЕ</part_of_speech>
<tags>ПАДЕЖ:ИМ|ЧИСЛО:ЕД|РОД:ЖЕН|ОДУШ:ОДУШ|ПЕРЕЧИСЛИМОСТЬ:ДА|ПАДЕЖВАЛ:РОД</tags>
</token>
<token>
<word>мыла</word>
<position>1</position>
<lemma>мыть</lemma>
<part_of_speech>ГЛАГОЛ</part_of_speech>
<tags>НАКЛОНЕНИЕ:ИЗЪЯВ|ВРЕМЯ:ПРОШЕДШЕЕ|ЧИСЛО:ЕД|РОД:ЖЕН|МОДАЛЬНЫЙ:0|ПЕРЕХОДНОСТЬ:ПЕРЕХОДНЫЙ|ПАДЕЖ:ВИН|ПАДЕЖ:ТВОР|ПАДЕЖ:ДАТ|ВИД:НЕСОВЕРШ|ВОЗВРАТНОСТЬ:0</tags>
</token>
<token>
<word>грязную</word>
<position>2</position>
<lemma>грязный</lemma>
<part_of_speech>ПРИЛАГАТЕЛЬНОЕ</part_of_speech>
<tags>СТЕПЕНЬ:АТРИБ|КРАТКИЙ:0|ПАДЕЖ:ВИН|ЧИСЛО:ЕД|РОД:ЖЕН</tags>
</token>
<token>
<word>раму</word>
<position>3</position>
<lemma>рама</lemma>
<part_of_speech>СУЩЕСТВИТЕЛЬНОЕ</part_of_speech>
<tags>ПАДЕЖ:ВИН|ЧИСЛО:ЕД|РОД:ЖЕН|ОДУШ:НЕОДУШ|ПЕРЕЧИСЛИМОСТЬ:ДА|ПАДЕЖВАЛ:РОД</tags>
</token>
<token>
<word>.</word>
<position>4</position>
<lemma>.</lemma>
<part_of_speech>ПУНКТУАТОР</part_of_speech>
<tags></tags>
</token>
</tokens>
</sentence>
</parsing>Вторая библиотека – LingvoNET, предназначенная для склонения и спряжения слов русского языка. Предыдущей склонения и спряжения тоже доступны, но эта приглянулась мне легкостью освоения.
Получив вожделенное, засучил рукава.
Излагаю конечный результат, в сокращении. Все интеллектуальные блуждания и затруднения не описываю: слишком они перепутаны. Частенько забредал не туда, поэтому приходилось переосмысливать и переделывать вроде бы завершенное.
В начале было слово
В соответствии с реализованной мной концепцией, в качестве первичного элемента имеем слова с известными нам морфологическими признаками.
Морфологические признаки слов возвращает парсер Solarix – казалось бы, проблем нет. Однако проблемы имеются в связи с тем, что некоторые словосочетания имеют общую нераздельную семантику, в связи с чем должны восприниматься ИИ в качестве единого элемента.
Я насчитал четыре вида подобных словосочетаний:
1. Фразеологические обороты,
К сожалению, парсер их не возвращает.
Слесарь бил баклуши.
Для парсера «бить баклуши» – для разных слова, хотя семантическая основа тут одна, и воспринимать словосочетание необходимо так, как его воспринимает наш мозг: слитно.
2. Имена собственные,
Александр Сергеевич Пушкин.
Ясно, что это единый указатель на единственный предмет, хотя отдельные составляющие его слова могут быть использованы в других указателях.
3. Поговорки, пословицы, афоризмы.
Они, как правило, также представляют собой единое смысловое поле.
Старый конь борозды не портит.
4. Составные служебные слова (вследствие чего, из-за того что, по причине и т.п.)
Парсер возвращает некоторые из них слитно, другие – нет.
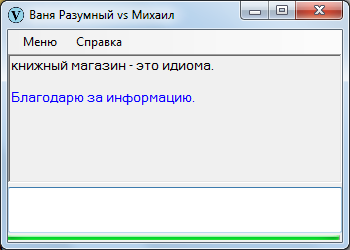
5. Просто устойчивые словосочетания типа «книжного магазина». Не приставишь любое прилагательное к существительному «магазин», хотя бы соответствующие изделия в нем и продавались. Никто не скажет «макаронный магазин», даже если в магазине торгуют исключительно макаронами.
Составные слова – независимо от их типа – необходимо обрабатывать так, как если бы они были единой слитной конструкцией… Но как узнать, какие словосочетания относятся к данной группе?
Наиболее очевидное – посредством прямого на то указания:
Более сложный, применимый лишь к именам, вариант – определение фразеологизмов по заглавным буквам:
- некоторые имена собственные, в частности ФИО, имеют все заглавные буквы
- другие собственные имена лишь начинаются с заглавной буквы (например, Аральское море).
Ясно, что определять составные слова возможно по их повторяемости, но это затруднительно. Более простым и действенным способом могло бы стать использование словарей, однако со словарями вышла незадача: использовать их в рамках реализованной концепции не удалось (на что посетую в конце поста).
Субъект – Действие – Объект
Слова определены, их свойства зафиксированы, что дальше? Дальше необходимо определить костяк фразы: любой разработчик ИИ наверняка приходил к тому же выводу.
Вот фраза:
Плотник выстругал доску.
Что можно о ней сказать, ориентируясь исключительно на синтаксис?
Можно сказать, что:
1. Субъект (существительное именительного падежа) – то, что выполняет действие.
2. Объект (существительное не именительного падежа) – то, на что направлено действие.
3. Само действие – глагол.
При страдательном залоге субъект и объект меняются местами. При этом страдательный залог может быть преобразован обратно в действительный: объект – при страдательном залоге всегда он находится в творительном падеже – в таком случае превращается в субъект именительного падежа, а субъект превращается в объект винительного падежа.
Было:
Плотник выстругал доску.
Стало:
Доска выстругана плотником.
Иначе говоря, залог делает фразу инвариантной.

В некоторых случаях инвариантность фразы практически неопределима, к сожалению.
Имеем высказывание:
Спички лежат в коробке.
Его можно переформулировать:
Коробок содержит спички.
Содержание обеих фраз идентично, однако выражаемые глаголами действия формально разнонаправленны (в первом случае спички воздействуют на коробок, во втором случае – наоборот), при этом залоги обоих глаголов активные.
«Лежать» и «содержать» – это даже не антонимы, а нечто такое, чему в лингвистике, насколько я понимаю, нет названия. А если нет названия, то и словарей подобных терминологических пар быть не может: затруднение, с которым ИИ неминуемо столкнется при попытке «осмыслить» поступившую информацию.
Совместное употребление триады не обязательно: любой из названных элементов может во фразе отсутствовать.
Бегемот двинулся.
Вечер.
Светало.
И наоборот, элементы могут присутствовать в предложении во множественном числе, например:
Вася и Петя подрались.
Что касается множественности, то после долгих размышлений и переделок мной были установлены следующие правила обработки:
1. Субъект в предложении присутствует всегда. При отсутствии субъекта в исходный текст вставляется заглушка, обозначающая существительное.
Светало.
Преобразуем в:
[Noun] светало. Иначе говоря: Что-то светало.
2. Действие может отсутствовать при отсутствии объекта. При наличии объекта вставляется заглушка, обозначающая глагол.
Шаг в бездну.
Преобразуем в:
Шаг [verb] в бездну. Можно трактовать как: Шаг [направлен] в бездну.
3. Объект в предложении может отсутствовать. Никакой заглушки при этом не применяется.
Он поехал.
Увеличивать фразу до «Он поехал [noun]» нет смысла, ведь едут не обязательно куда-то: термин может обозначать начало движения.
4. Субъект и объект могут быть множественными. Фраза при этом не разделяется.
Множественные субъекты:
Мальчик и девочка смотрели телевизор.
Множественные объекты:
Охотник добыл лося и кабана.
5. Действие допускается только единичным: при множественности действий фраза разделяется по числу глаголов.
Дворник улыбнулся и погрозил пальцем.
Преобразуем в:
Дворник улыбнулся. Дворник погрозил пальцем.
В этом случае фраза требует разделения.
Свойства элементов
Свойства основных элементов (то есть существительных и глаголов) – это в основном их морфологические признаки: род, падеж, лицо, число, переходность, возвратность, модальность и другое – все то, что возвращает парсер Solarix. Плюс прочие, не рассматриваемые лингвистикой. Я использовал характеристики не вполне канонические: отрицание, закавыченность, знак препинания (который посчитал свойством предыдущего слова) и т.п.
Некоторые из названных свойств единичны (например, род: не бывает слов одновременно мужского и женского родов), другие множественны. К множественным свойствам относятся, к примеру, число и дата. Можно сказать «5 лошадок», а можно: «Не меньше 3 и не больше 7 лошадок»: во втором случае оба числительных относятся к одному слову, тем самым являются его множественными свойствами.
Важно, что остальные части речи представляют собой свойства основных элементов либо некие вспомогательные сущности типа ссылок, в частности:
• прилагательное – свойство существительного,
• наречие – свойство глагола (как правило),
• предлог – свойство существительного,
• союз – маркер множественности элементов (как правило),
• местоимение – ссылка на предыдущее существительное,
• числительное – указатель на число субъектов или объектов.
Разделение предложений на секторы
Выше был упомянут случай, требующий разделения предложения на части (пример с дворником). Этот случай не единственный – встречаются другие.
Самое очевидное: сложносочиненные и сложноподчиненные предложения.
Юноша улыбнулся, и девушка улыбнулась в ответ.
Купальщик плюхнулся в воду, которая была холодна.
Разделяем на:
Юноша улыбнулся. Девушка улыбнулась в ответ.
Купальщик плюхнулся в воду. Вода была холодна.
Чуть менее очевидны причастия и деепричастия. Тем не мене они выражают действия, что приводит к необходимости разделения.
Автомобиль, развернувшись на месте, врезался в отбойник.
Развернувшийся на месте автомобиль врезался в отбойник.
Разделяем:
Автомобиль развернулся на месте. Автомобиль врезался в отбойник.
Тот же самый результат был бы получен при множественности глаголов, с которыми причастия и деепричастия взаимозаменяемы.
Автомобиль развернулся на месте и врезался в отбойник.
Конечная конструкция у всех трех исходных вариантов примера идентична.
Разделять предложения необходимо не только в вышеназванных случаях, но и во многих других, в том числе таких, для которых, казалось бы, разделение противопоказано.
Такой пример:
Хорошо гулять по осеннему лесу.
Что тут разделять, когда все слитно и компактно? Немного озадачивает отсутствие субъекта, поскольку, как мы договорились, субъект должен выражаться существительным, а здесь он… наречие что ли? Ан нет, разделение необходимо!
[Noun] гулять по осеннему лесу. Хорошо. В смысле: Кто-то гуляет по осеннему лесу. Это хорошо.
Выше было сказано, что падежи служат для различения субъектов и объектов: падеж субъектов – именительный, тогда как падеж объектов – не именительный. Профессиональные лингвисты со мной вряд ли согласятся: им известна уйма случаев, когда объекты пребывают в не именительном падеже, как и субъекты.
Коттедж – это жилище.
Не только субъект, но и объект в именительном падеже. Исключение, скажете вы? Можно сослаться на исключение, однако логичней посчитать указанную конструкцию двумя фразами, объединенными особым свойством. Я называю такие фразы, полученные посредством разделения предложения на части, секторами.
Суть в том, что один сектор является определением другого (или даже множества предыдущих секторов. Ввиду сложности данного функционала я даже не пытался его реализовать).
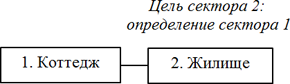
Здесь второй сектор является определением первого. И никаких тебе объектов в именительном падеже!
Главное, конечно, то, что свойствами могут обладать не только отдельные элементы, но и секторы.
Помимо цели, я использовал такие свойства секторов, как:
• тип сообщения (утверждение, распоряжение, вопрос),
• тип вопроса,
• залог (имело ли место преобразование страдательного залога в действительный),
• обращение (к собеседнику по имени: да или нет),
• склейка,
• валидность,
• время,
• вероятность.
Склейка
Как принято именовать данную сущность у лингвистов, понятия не имею. Может быть, соединительное слово?
Итак, склейки служат для связи между секторами. Попросту говоря, это служебные слова типа «поэтому», «когда», «вследствие чего», «ввиду того что» и т.п.
Допустим, имеем сложноподчиненное предложение со склейкой «поэтому».
Ветер подул, поэтому листва зашелестела.
Ясно, что две части связаны между собой как причина и следствие: об этом свидетельствует склейка «поэтому».
Склейка может отсутствовать, тогда обнаружить ее проблематично – практически невозможно.
Ветер подул, и листва зашелестела.
В физической реальности мы ориентируемся на зрение, а если общение происходит на вербальном уровне, то на интонацию и на визуальный опыт, и обычно угадываем, но только не в царстве слов. Как отличить приведенную фразу, обозначающую причину и следствие, от заурядной последовательности событий?
Ветер подул, и пробежал заяц.
Заяц пробежал-то вовсе не от того, что ветер подул – мы знаем, – но из синтаксиса этого не следует, хотя не следует и обратного. Кто его знает, как случилось на самом деле? Может, ветер подул, в результате чего обломилась ветка, заяц испугался и побежал – в этом случае дуновение ветра является причиной того, что заяц побежал.
Названная проблема не решаема для чат-бота в принципе: физическая реальность – одно, вербальная сфера – другое. Элементная база разная (под элементной базой я понимаю способ восприятия реальности: для чат-бота это письменная речь).
Валидность
Некоторые фразы оказываются некорректными. Ясно, что если выдать ИИ откровенную белиберду, он не поймет.
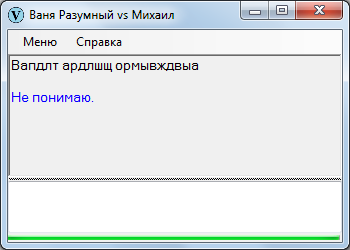
Однако даже фраза, выстроенная на первый взгляд в соответствии с правилами синтаксиса, может оказаться бракованной вследствие разных нюансов, к примеру:
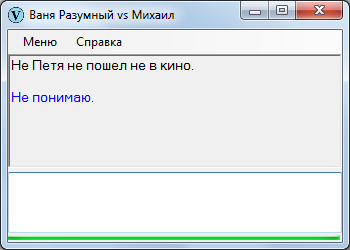
Вы, что ли, способны такую фразу воспринять? Если да, примите поздравления, потому что я при попытке осмысления впадаю в ступор: мозг отказывает. При этом упрощенные варианты воспринимаются обыденно:
Петя не пошел в кино.
Петя пошел не в кино.
Не Петя пошел в кино.
Люди познают мир в соответствии с заложенными в их головы алгоритмами, но стоит им получить нестандартную информацию, хваленый ум куда-то испаряется.
Очевидно, что инвалидные фразы необходимо беспощадно отбраковывать при обработке.
Основные признаки инвалидных фраз, в моей интерпретации:
• отсутствие значащих слов (существительных и глаголов),
• слишком большое число слов, не опознанных парсером в качестве частей речи,
• наличие существительного в не именительном падеже при отсутствии глагола (ошибка в алгоритме, поскольку в таких случаях глагол вставляется принудительно),
• слишком большое число отрицательных частиц (см. выше),
• слишком большое число дат в отсутствие перечисления (обычно в предложении фигурирует либо одна дата, либо, в случае указания на период, две даты),
• наличие двух глаголов (следствие ошибки в алгоритме),
• одинарность союза (если обнаружено, к примеру, одиночное «или», то имеет место ошибка либо во фразе, либо в алгоритме),
• неодинаковость союзов (одновременное использование альтернативных союзов «и», «или»).
Вставка недостающих слов. Замена ссылок
Предложение формализовано, пора записывать? Рано. Требуется вставить недостающие слова и заменить ссылки.
Возьмем для примера диалог:
— Петров, как здоровье?
— Нормальное.
— А у жены?
— Тоже.
Формализация требует восполнения недостающего, приблизительно так:
— Как здоровье Петрова?
— Здоровье Петрова нормальное.
— А как здоровье у жены Петрова?
— Здоровье у жены Петрова тоже нормальное.
После этого – не раньше – можно приступать к обработке текста с последующей записью в базу.
Вот и она – база, со всеми свойствами, также вспомогательными и справочными таблицами.
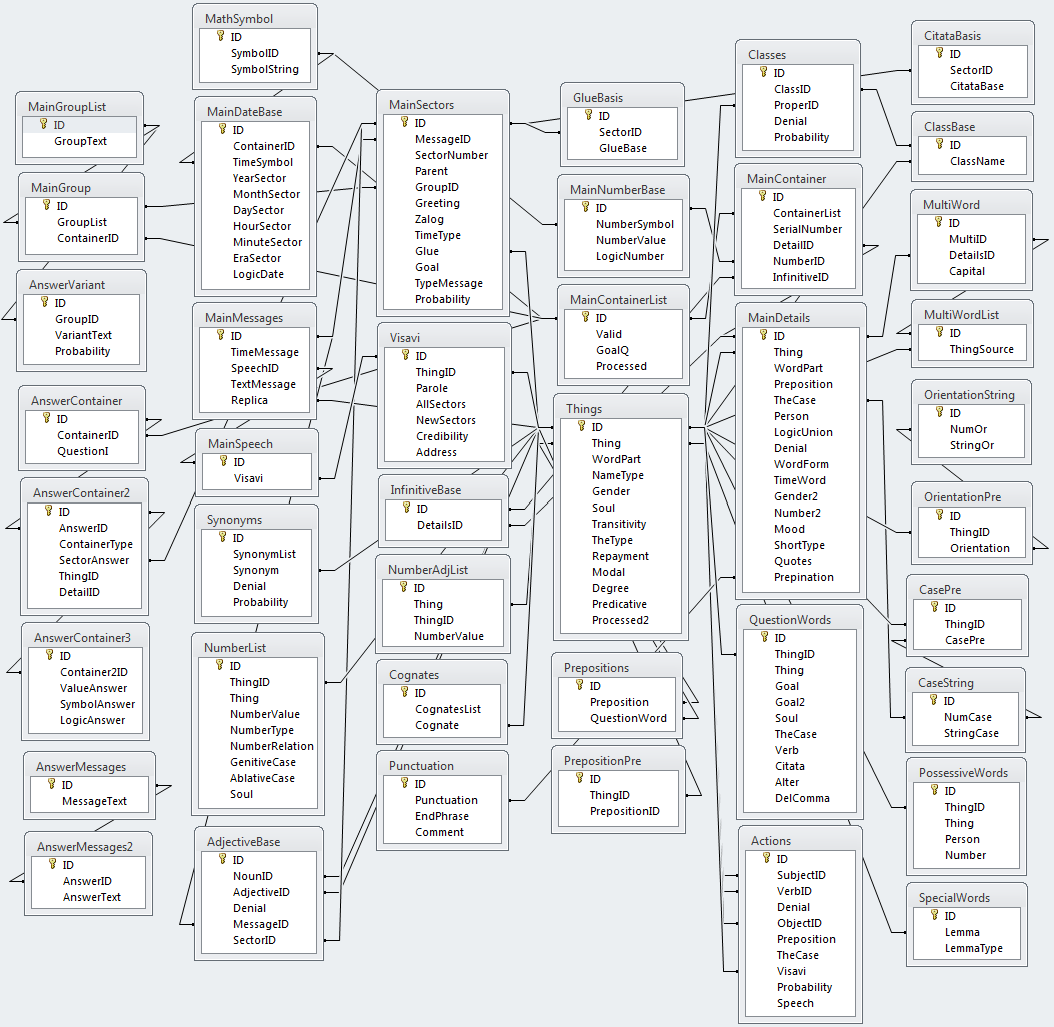
Иерархическая структура:
1. Беседа (сеанс связи с собеседником).
2. Сообщение (текст, который выдает собеседник зараз).
3. Предложение (информационная единица сообщения).
4. Сектор (часть предложения).
5. Слово.
Не Бог весть что, особенно для читателей здешнего ресурса… Но я ж дилетант, мучился долго.
Общение
После записи реплики собеседника в базу можно приступать непосредственно к общению. Проблема – каким образом общаться? Сказать что-то утвердительное? Задать встречный вопрос? Попросить чего-нибудь?
Методом проб и ошибок вырисовалась схема.
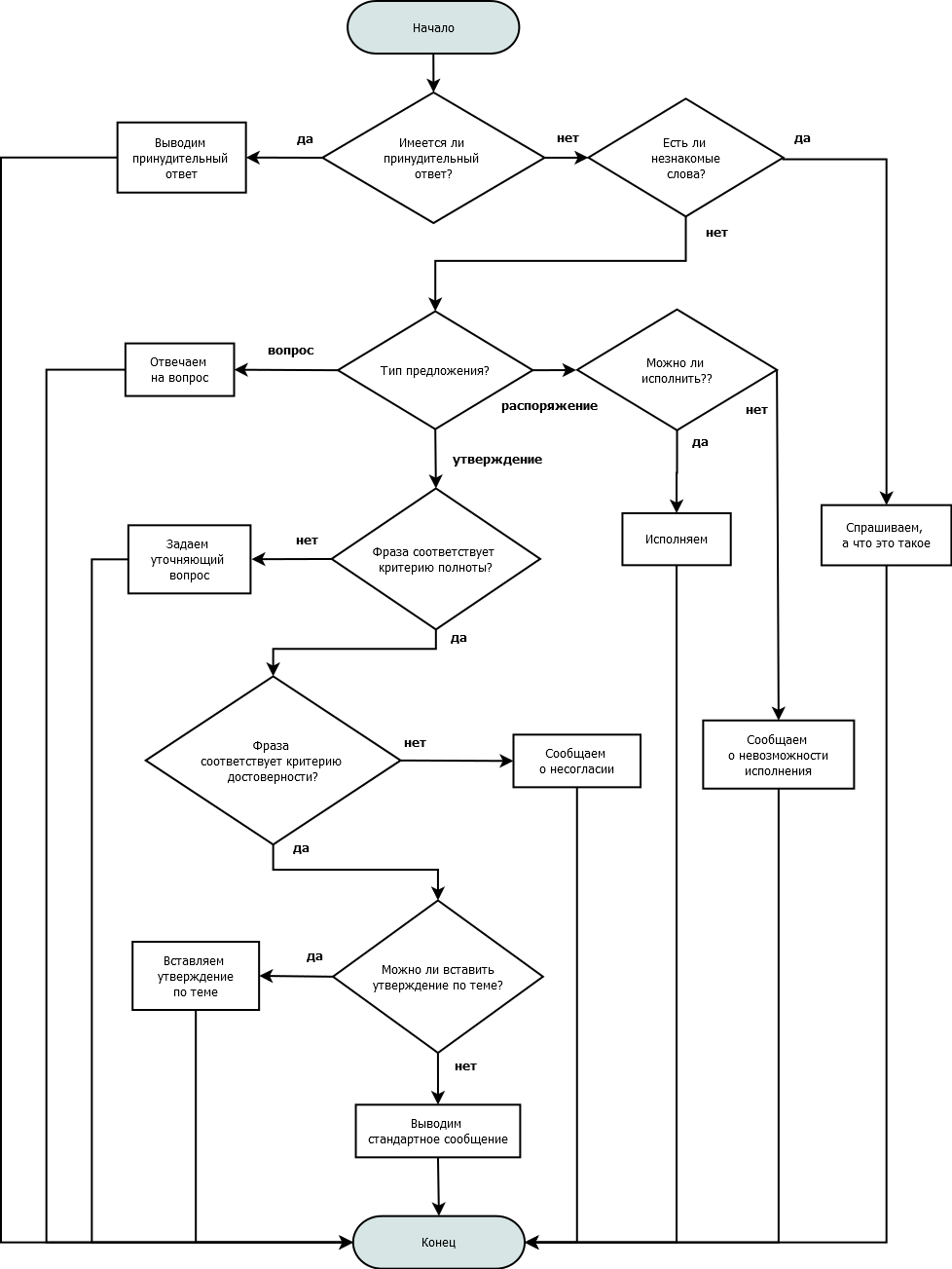
Принудительный ответ – это, к примеру, когда предложение инвалидное или собеседник установил, что на такую-то фразу нужно отвечать таким-то образом.

Информационная неполнота – когда удается установить, что в предложении отсутствуют значащий элемент, как правило объект.
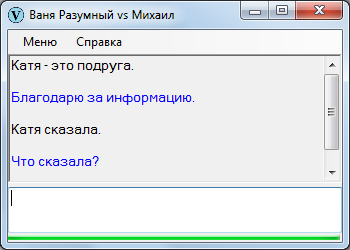
Что сказала-то? Любой человек, услышав подобное, первым делом уточнит, что имеется в виду.
Достоверность – соответствие тому, что записано в памяти. Если кто-то слышит «Гагарин не летал в космос», а в его памяти записано обратное, он опять-таки попросит (должен попросить) разъяснений.
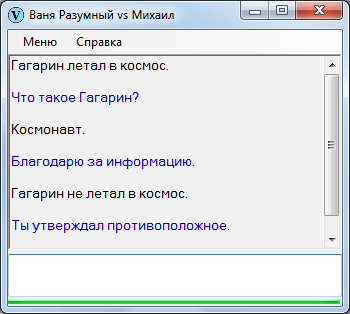
Естественная реакция.
При необходимости отвечать стандартно Ваня Разумный осуществляет выбор из типового набора ответов случайным образом.
Надо сказать, что с типовыми сообщениями я особо не заморачивался по причине того, что добиться полного сходства с человеческой реакцией невозможно по определению. Допустим, чат-бот выдает стандартное «Я согласен». Можно, подобрав синонимичные сообщения, возвращать их рандомно:
Точно так.
Ты прав.
Верно говоришь.
Твоя правда.
и т.п.
Однако любой из этих синонимов обладает смысловыми отличиями от собратьев, ввиду чего их употребление вовсе не идентично. Нюансы, которые легко распознаются людьми по мимике и интонации собеседника, но не могут быть идентифицированы на синтаксическом уровне. Это вам не синтаксис – это физическая реальность.
Да на уровне синтаксиса нельзя даже отличить отрицательный ответ от положительного!
Возьмем два привычных для нас альтернативных ответа на один и тот же вопрос:
Еще как!
Вот еще!
Первый из ответов означает «Да», а второй – «Нет». Определить значения по синтаксису нет никакой возможности.
Типы предложений
Основную роль в диалоге играют типы предложений:
1. Распоряжение.
2. Утверждение.
3. Вопрос.
Самое элементарное из всех – распоряжение. Ваня Разумный пытается по действию понять, чего хочет собеседник: если может исполнить, то исполняет, в противном случае сообщает об отказе.
Ну что чат-бот может исполнить? Сказать о чем-то, выполнить команду.
Ничего стоящего внимания.
При утвердительном высказывании собеседника реакция в общем случае сводится к поиску встречного утверждения по теме, где тема – субъект или объект, по желанию.
Космонавт полетел на Марс.
В ответ, найдя в базе утвердительное предложение со словом «космонавт», можно выдать:
Космонавты храбрые.
А можно поискать по объекту, возвратив что-нибудь вроде:
Марс – это красная планета.
Но нет гарантий, что в базе не отыщется неподходящая фраза, типа:
Планетолет вез на Марс мусорные контейнеры.
Подобрать критерии?.. Но какие??? После долгих раздумий я установил, что в качестве ответного утверждения по теме ИИ должен выдать фразу, обозначающую личное отношение к предмету:
Я не летал на Марс.
Опять-таки, если подобная фраза отыщется в базе.
Вместо ответного утверждения может генерироваться вопрос: в случае если в затронутой теме Ваня чего-нибудь недопонял.
Вопросы
Вопросы подразделяются на два подтипа, которые для себя я обозначил как общие и специальные.
Общие вопросы – без вопросительного слова, допускающие ответы «Да» или «Нет».
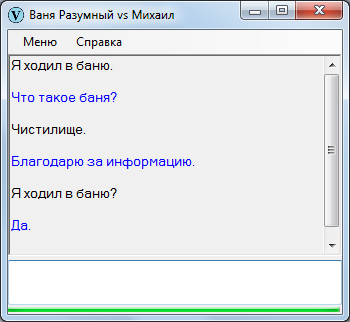
Специальные вопросы требуют в каждом случае индивидуального ответа, тут простым «Да» или «Нет» не отделаешься.
Сколько на Земле людей?
Почему слоны большие?
Кто такой Наполеон?
Пришлось систематизировать вопросительные слова. Каждому вопросительному слову – которых, по счастью, все же немного, – ставился в соответствие тип. Получился список вида:
Вещь: что?
Имя: кто?
Место: куда? где?
Прилагательное: какой?
Наречие: как?
Число: сколько?
Дата: когда?
Причина: почему?
И так далее.
При отсутствии вопросительного слова вопрос общий.
При общем вопросе Ваня Разумный ищет ответы не только непосредственно на него, но в случае отрицательного ответа и на все специальные вопросы, сгенерированные по основному общему. Цель – выдать в качестве ответа альтернативный сектор.
Ответы
Поиск ответа осуществляется, вестимо, по шаблонам:
- Берем слово, со всеми морфологическими признаками, и ищем секторы, в которых указанная словоформа присутствует. Так по всем словам вопросительной фразы.
- Затем находим пересечение результатов, полученных по каждому слову. Сектор, являющийся пересечением, является ответом. Если секторов несколько, выбираем какой больше понравится.
Установив сектор-ответ, можем выдать собеседнику «Да», или «Нет», или «А черт его знает», – но это по общему вопросу.
Если вопрос специальный, делаем все то же самое, с единственным отличием. Для вопросительного слова ищем лишь его морфологические признаки, без самого слова.
Допустим, спросили:
Кто выстрелил?
Для «выстрелил» ищем «выстрелить» с заданными морфологическими признаками, а для «кто» – любое слово с заданными морфологическими признаками. Сектор, в котором присутствуют оба слова, и будет ответом.
В некоторых случаях (на самом деле, во многих) единичный поиск по вопросительному слову с заданными морфологическими признаками не сработает, поэтому искать приходится многократно.
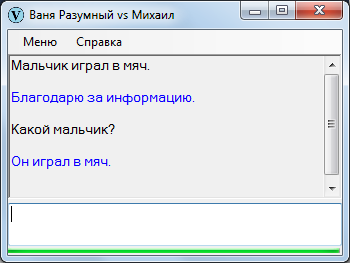
Спрашиваем:
Какой мальчик?
«Какой» – вопросительное слово для прилагательного, то есть в общем случае Ваня должен искать прилагательное. Если в базе для данного существительного находится прилагательное, выдается соответствующий ответ.

В иной ситуации ответом может послужить не только прилагательное, но и нечто другое, например причастие.

Причастие выражает действие, поэтому, с некоторой точки зрения, любое действие характеризует субъект не менее прилагательного и причастия.
Более сложный, связанный с поиском субъекта, вариант подмены шаблона:
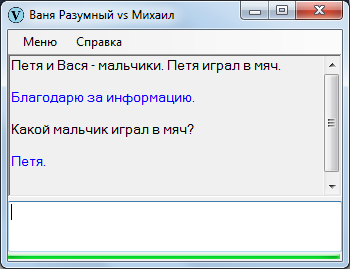
Подобных вариантов с пару десятков: это то, что мне удалось обнаружить.
Обратите внимание: один результат может оказаться ответом сразу на несколько вопросительных подтипов.
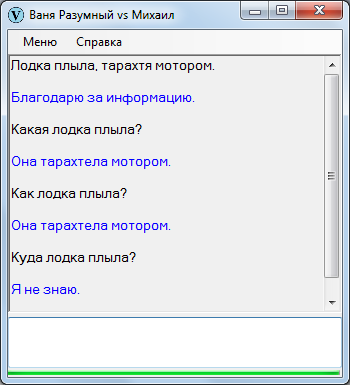
На последний вопрос ответа не находится – Ваня соответственно и не отвечает.
Последовательный поиск по связанным секторам
Допустим, у чат-бота спрашивают:
Куда глупый Петя пошел?
На самом деле вопрос разбивается на два связанных сектора:
Куда Петя пошел? Петя глупый?
При этом не факт, что оба ответа окажутся положительными или отрицательными: вполне можно представить, что Петя пошел в магазин, но при этом Петя совершенно не глупый.
Приходится сначала проверять достоверность определений, затем уже отвечать на главный вопрос.

В данном случае сведения об определении Пети отсутствуют, поэтому отвечать на основной вопрос нет резона.
Аналогичным образом необходимость поиска по нескольким секторам возникает при общих вопросах, выраженных в сложносочиненных или сложноподчиненных предложениях.
Я поймал жереха, который погнул весы?
После разделение предложение преобразуется в секторы:
Я поймал жереха? Жерех погнул весы?
Так же во всех остальных случаях, требующих разделения на секторы. Затруднение, хотя преодолимое.
Противоречивость информации
Представим, что у ИИ спрашивают, сколько космонавтов летало в космос. Хорошо, если в базе значится одна фраза:
В космос летало 40 космонавтов.
А если там другая фраза присутствует?
В космос летало 45 космонавтов.
40 или 45, кому верить? Вероятно, один из источников лжет, но который? Можно поверить тому либо другому, но критерии веры каковы? Очевидно, рейтинг источника. Но каким образом ИИ может определить рейтинг источника, если все собеседники для него, строго говоря, одинаковы?
Мне показалось логичным, чтобы ИИ стремился к получению максимального объема знаний, то есть: собеседник, предлагающий новую (отсутствующую в базе) информацию – хороший, не предлагающий – плохой.
В итоге был реализован следующий механизм:
- Рейтинг собеседника рассчитывается на основании отношения выданных новых секторов к общему их числу – соответственно, изменяется с каждой фразой.
- Сектору присваивается текущий рейтинг собеседника.
- Если секторы разных собеседников антагонистичны, доверие вызывает тот, который обладает наибольшим рейтингом.
- Если антагонистичны секторы одного собеседника, последний по времени сектор считается истинным (то есть себя можно в любой момент поправить, но поправить утверждение другого визави возможно, если обладаешь бОльшим рейтингом)).
В результате ИИ способен определить, какому из двух высказываний верить.
Думаете, проблема с количеством космонавтов решена? Ничего не решена, потому что оба источника могут оказаться правдивыми. По состоянию на 1 января числилось 40 космонавтов, в течение года 5 человек слетало в космос, по состоянию на 31 декабря числится 45 космонавтов. Только откуда ИИ об этом знать?!
Инвариантность
С чем возникли серьезные трудности, так это с инвариантностью, причем настолько серьезные, что хотел бы я познакомиться с человеком, которому удалось разрешить их в рамках синтаксиса. Я вообще не уверен, что такой человек уже родился.
Итак, одно и то же сообщение можно сформулировать по-разному:
Я заболел.
Мне неможется.
Меня ломает.
Плохо себя чувствую.
Я нездоров.
Недомогаю.
Здоровье ни к черту.
И т.п.
Кое-какие мелочи на этом пути преодолимы.
Синонимы – самое очевидное и повсеместно реализованное решение.
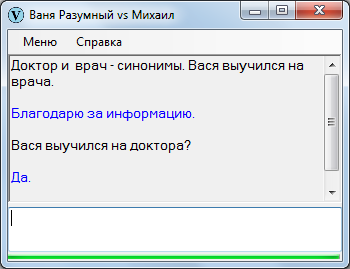
Еще можно использовать однокоренные слова, к примеру:
Болезнь.
Боль.
Заболеть.
Заболевание.
Больно.
Вот фразы с ними, выражающие, по сути, единственную мысль.
Он подхватил болезнь.
Он испытывает боль.
Он заболел.
У него заболевание.
Ему больно.
К сожалению, возможно сформулировать и без использования однокоренных слов. Например:
Здоровье пошатнулось.
Поэтому в рамках синтаксиса полное и безусловное решение проблемы инвариантности отсутствует. Чтобы решить проблему инвариантности, нужен не чат-бот, а ИИ, обладающий полным набором человеческих ощущений.
Что такое интеллект
Речь дошла до интеллекта, на нем и сосредоточусь.
Лично я (хотя у каждого собственное мнение, понимаю) насчитываю три пункта, делающие мыслящее существо таковым:
1. Обратная связь.
2. Мышление.
3. Рефлексия.
Обратная связь – зависимость реакции от предыдущего опыта. Реализуется примитивным образом, за счет записи информации в базу данных. Сначала ИИ чего-то не знал, потом услышал, запомнил и теперь знает – это и есть обратная связь.
Мышление – процесс генерирования новой информации, непосредственно не получаемой от собеседника. Собеседник выдает сообщение, ИИ анализирует и приходит к собственным выводам.
Ваня Разумный делает выводы, затем записывает их в базу с пометкой «идея» (свойство сектора). Все мышление, собственно.
Так мыслим мы:

Так должен мыслить ИИ:

Вопрос не в том, что такое мышление, а в том, каким образом искусственное мышление должно быть организовано…
Мышление при помощи классов
В качестве основы мышления я (не сомневаюсь, что подобно многочисленным предшественникам) использовал классы. В математике это называется множествами, в лингвистике – гиперонимами, но мне больше нравится дарвинистско-программистское «классы». Бульдог относится к классу собак, собаки относятся к классу животных, и так далее вверх и вниз по иерархии.
Правила пользования тривиальны:
- Понятия могут относиться одновременно к нескольким классам. Например, Сидоров одновременно относится к классу мужчин и к классу курильщиков.
- Классы не могут зацикливаться в своей иерархии. Понятие, расположенное на какой-либо иерархической ветке, не может повториться ниже или выше по своей иерархии. Если Сидоров относится к классу курильщиков, то курильщик не относится к классу Сидоровых.
Самое познавательное не в классах и не в их членах, а в том, откуда взять нужную информацию для таксономии.
Придумалось следующее.
Во-первых, определять принадлежность того или иного понятия к классам из дефиниций – так сказать, напрямую.

Если Жучка собака и все собаки гавкают, довольно очевидно, что Жучка тоже умеет гавкать.
Заменим в исходном утверждении «собаку» на «Тузика». Логично предположить, что если собака Тузик умеет гавкать, то и собака Жучка тоже умеет?

Не логично. Что если вместо «гавкать» вставить «рожать щенят»? Тузик этого не умеет, а Жучка – запросто. По этой причине поиск выдал отрицательный результат. Вместе с тем был обнаружен альтернативный сектор (умение Тузика гавкать), который и стал ответом – по-моему, достаточно познавательным.
Другой способ обнаружения классов – перечисления. Исходная посылка: слова, связанные некоторыми союзами (и, или, а, кроме) или запятыми в связи с перечислением, принадлежат хотя бы одному общему классу.

Я ни словом не обмолвился, что Жучка – собака: Ваня Разумный сам сделал вывод из полученной информации. В ином случае мог и ошибиться: к примеру, если бы я написал «Тузик – это кобель», потому что Жучку к кобелям никак не причислишь. Пришлось бы вносить коррективы.
Что я и сделал, собственно, а Ваня соответствующим образом среагировал, хотя не без огрехов.

Следующий способ – некоторые вопросительные наречия (куда, где, откуда, когда). Если такая склейка относится к слову, можно сделать вывод о принадлежности слова к определенному классу (места или времени).

Наконец, действия. Выполнение субъектами одних и тех же действий с большой вероятностью свидетельствует о наличии у субъектов общего класса. Как говорят американцы, если что-то плавает, как утка, летает, как утка и крякает, как утка, то это и есть утка.

Способ неточный, ведь выполнять одинаковые действия могут объекты, принадлежащие разным классам. Однако если все выполняемые действия совпадают, это не может не навести на определенные мысли.
В итоге, процесс мышления можно уподобить разгадыванию паззлов, когда по имеющимся кускам информации восстанавливается полная картина.

Если вы полагаете, что мыслите как-то иначе, то навряд ли… Представьте, что знакомый Петров хвастает: «У меня дочь – первоклассница». Что вы можете сказать о его дочери, о которой впервые слышите? Принадлежность к классу «первоклассница» говорит о возрасте субъекта. Возраст (тоже в некотором смысле класс) свидетельствует о примерном росте, весе, интеллектуальных возможностях и прочем. Женский род (опять-таки класс) позволяет предположить первичные и вторичные половые признаки, а принадлежность к фамилии «Петров» (класс, все класс) доказывает, что искомая первоклассница такая же дура, как все известные вам Петровы.
А если серьезно, то в своих выводах мы оперируем принадлежностью субъекта к определенному набору классов, а более ни к чему. И чем наше хваленое человеческое мышление отличается от заурядных машинных алгоритмов?! Ничем.
Мышление при помощи каузальности
Процесс мышления следует базировать не только на классах, но и на каузальности (причинно-следственных связях).
Над Атлантикой изменилось давление, поэтому подул ветер. Подул ветер, поэтому с головы слетела шляпа. С головы слетела шляпа, поэтому шляпа упала в лужу. Шляпа упала в лужу, поэтому шляпа промокла.
Если идти по каузальной цепочке с конца в начало, неизбежно придем к начальному выводу:
Шляпа промокла, потому что над Атлантикой изменилось давление.
И попробуйте сказать, что вывод неверен!
А ведь подобные каузальные цепочки могут составляться не только по последовательным, но и по разрозненным фразам, в результате выводы, сделанные ИИ, окажутся неожиданными!
Есть и второй способ установить каузальность. Он связан с использованием известной нам триады: субъект – действие – объект.
В чем исконный смысл триады? Да именно в том, что в цепочке происходящих событий выражается каузальность между субъектом и объектом. События происходят одно за другим, причем прошлый объект становится субъектом, в свою очередь воздействующим на другой объект, и т.д.

Указанная последовательность представляет собой каузальную цепочку, в которой:
а) причиной того, что гантель упала, является то, что дедушка взял гантель,
б) причиной того, что нога заболела, является то, что гантель упала на ногу.
Чистый синтаксис, при котором ИИ понятия не имеет, ни что такое дедушка, ни что такое гантель, ни что такое нога.
Согласно имеющейся базе знаний, гантель может упасть на ногу только в названном случае – ни в каком другом.
Представим, что в базу добавляется новые записи:
Мальчик купил гантель.
Бабушка положила гантель на комод.
В результате возникают новые потенциальные возможности того, что гантель упадет на ногу, вследствие чего дедушкина нога заболит.
Имеем веер сходящихся возможностей, весьма пригодный для анализа.
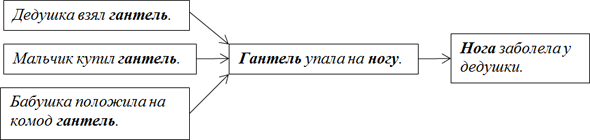
Существо, основывающее свое мышление на правилах синтаксиса, может сделать вывод о том, что, если мальчик купил гантель или бабушка положила гантель на комод, то гантель может упасть на ногу, со всеми вытекающими последствиями. Правомерно поинтересоваться:
Гантель не упадет на ногу?
Или, на следующем витке каузальности:
Нога не заболит у дедушки?
По сути, это предугадывание будущего, но не только. Еще и восстановление прошлого, так как двигаться по каузальной цепочке возможно не вперед, но и назад.
Таков он, механизм предугадывания:

Центральная триада на схеме – текущая. Если субъект текущей триады и какой-либо объект в последующей каузальной цепочке совпадают или хотя бы принадлежат одному классу, имеем каузальную связь в рамках одного субъекта-объекта. То же самое – относительно предыдущей каузальной цепочки.
Образчик реализации:

Ущипните меня, если это не мышление!
Конечно, наличие каузальности далеко не очевидно, если наблюдатель находится в физическом мире.
Я увидел березу. Береза шелестела листвой.
Нам, существующим вне правил синтаксиса, понятно, что береза шелестит листвой вовсе не оттого, что кто-то ее увидел, но с точки зрения синтаксиса дела обстоят именно так. Кто бы тогда шелестел листвой, если бы я не увидел?!
Сколько пользуюсь русским языком, столько убеждаюсь, какое это расчудесное чудо!
Рефлексия и параллельные миры
Помимо обратной связи и мышления, ИИ требует рефлексии.
Вспоминаю, в одном фильме о роботах миллиардер-изобретатель бегал по коридору с радостными воплями: «Она (искусственная женщина) себя осознает! Она себя осознает!»
Наивный! в рефлексии нет никакой тайны, даже в рефлексии живых существ, не то что в рефлексии ИИ.
Мы осознаем себя в качестве субъекта исключительно по той причине, что наше тело отделено от нашего мышления. Чат-бот также способен рефлексировать исключительно за счет мышления, а что это такое, мы выяснили: генерирование собственных, отличных от реплик собеседника, сообщений. Иначе говоря, мыслящий чат-бот должен генерировать внутренние (направляемые непосредственно в базу, а не на десктоп) сообщения о самом себе. Это не составляет сколь-либо заметной проблемы.
Можно, к примеру, генерировать мысли по репликам собеседника: собеседник выдает информацию об ИИ – тот анализирует и приходит к каким-либо выводам. В процессе анализа несомненно рефлексирует: осознает себя.
Можно отталкиваться от сообщений не собеседника, но собственных.
Допустим, сгенерирован вопрос, в соответствии с объявленной выше схемой:
Что такое движение?
Что это означает? То, что означает: сгенерирован вопрос. Идея записывается в качестве таковой, от имени ИИ:
Я задал вопрос.
В базу записываем, но в качестве ответа не выводим: это и есть рефлексия.
Понятно, что идей можно сгенерировать множество – столько, сколько потянут вычислительные мощности и фантазия Создателя. Если вопрос задает собеседник и записывается собственная мысль уже не о самом себе, но о собеседнике – это мышление. Короче, мышление о самом себе – это рефлексия, а мышление о внешнем мире – не рефлексия.
В результате мышления миры распараллеливаются. В низовом, изначальном мире, соответствующем физическому миру людей, происходит обмен сообщениями:
— Как твои дела?
— Прекрасно.
В высшем мире, соответствующем нашему миру идей, рождаются мысли. Одни мысли относятся к внешнему миру (не рефлексия), другие – к самому себе (рефлексия).
Собеседник задал вопрос.
Я ответил на вопрос.
Или:
Собеседник почему-то волнуется.
Я абсолютно спокоен.
Миры смешиваются воедино, иногда до полной неразличимости.
Реплика:
Ты точно влюбился?
Ее основная смысловая часть «ты влюбился?» принадлежит непосредственно диалогу, тогда как наречие «точно» – внешнему миру идей. Полная реконструированная фраза должна бы звучать следующим образом:
Ты точно уверен, что ты влюбился?
Первая часть фразы относится к миру идей, тогда как вторая – к миру диалога.
В результате, при работе с параллельными мирами возникает необходимость обрабатывать не только семантику сообщений, но и некие внешние по отношению к ним характеристики. Вот только как?
Допустим, собеседник спрашивает:
— Сколько сейчас времени?
Ориентируясь на низовой смысловой мир сообщений, ИИ должен бы начать шерстить по всей базе в поисках ответа.
Допустим, найдет фразу полугодичной давности:
Сейчас 15 часов 30 минут.
Вряд ли устаревшее сообщение послужит корректным ответом на текущий вопрос. А чтобы данные о текущем времени не устаревали, всегда были свежими, необходимо каждое – о Господи! – мгновение генерировать сообщение типа:
Сейчас 15 часов 30 минут 28 секунд 34 миллисекунды.
База не потянет.
Какого черта лазить по базе, если можно возвратить системное время, тем самым обратиться непосредственно к внешнему по отношению к диалогу миру?! Можно, конечно, но…
Как заметил один глубокомысленный персонаж, нельзя объять необъятное. Поэтому число верхних параллельных миров любой системы ограничено вычислительными мощностями, в конечном счете – назначением системы и здравым смыслом Создателя.
Оптимизация
В один прекрасный момент, когда работы над ИИ подходили к логическому завершению, я закачал в Ваню чуть поболе текста, чем обычно – строк этак полтыщи, – и решил насладиться общением. Не тут-то было! Юноша оказался тугодумом: как-то чересчур, до неприличия долго соображал. Выяснилось, что из-за множественности SQL-запросов.
Допустим, во фразе всего 3 слова (два существительных и глагол) – это 3 обращения к базе. Пересечение результатов по каждому обращению даст сектор-ответ, из которого при желании можно выбрать слово-ответ, в противном случае использовать в качестве ответа типовую фразу.
Если у какого-либо слова имеются синонимы, необходимо проверить базу по каждой комбинации.
Возьмем вопрос:
Доктор увидел бегемота?
Синоним «доктора» – «врач», а синоним «бегемота» – «гиппопотам», в результате получаем 3 дополнительных варианта:
Врач увидел бегемота.
Доктор увидел гиппопотама.
Врач увидел гиппопотама.
Кроме синонимов, имеются еще классы, которые тоже приходится проверять. Поскольку доктор принадлежит классу людей, ответом на вопрос будет также являться фраза:
Человек увидел гиппопотама.
Ладно, не проблема: вбить перечисления в один SQL-запрос. Хотя длина строки тоже небесконечна, приходится ее контролировать, но не суть дело…
В других ситуациях, при которых структура фразы изменяется, следовательно изменяются параметры SQL-запроса, минимальным количеством обращений к базе никак не обойтись.
Во-первых, по каждому слову необходимо проверять на отрицания:
Не доктор увидел бегемота?
Доктор не увидел бегемота?
Доктор увидел не бегемота?
Во-вторых, приходится осуществлять альтернативный поиск иного рода – я упоминал об этом ранее. Это когда на вопрос «какой?» последовательно перебираются конструкции, образованные на основе прилагательного, причастия, глагола.
Как быть? Если сократить количество SQL-запросов, ИИ лишится многих возможностей анализа, соответственно пострадает разнообразие ответов.
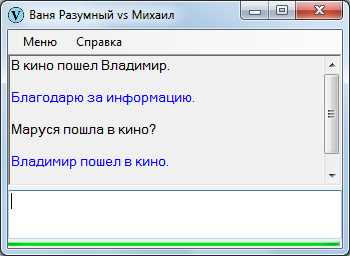
Тут на меня снизошло озарение. Зачем искать по базе, если каждое утверждение само по себе является ответом на известное множество вопросов?!
Некто утверждает:
Маруся пошла в кино.
Данное утверждение является ответом на общий вопрос:
Маруся пошла в кино?
Также оно является ответом на общий вопрос с отрицанием:
Маруся не пошла в кино?
Можно, добавляя вопросительные слова, составить и специальные вопросы, к примеру:
Кто пошел в кино?
Куда пошла Маруся?
Ответом на все названные вопросы является текущий сектор.
Значит, конструируя вопросы разных типов, можно вписывать их в базу, а в качестве ответа соотносить с ними исходный сектор-утверждение! При этом система не перегружается SQL-запросами: диалог течет заметно веселей, чем прежде.
Нет сомнений, что люди мыслят аналогичным образом. Если задать чересчур сложный вопрос, собеседник сразу не ответит, а задумается: сколько нужно для нахождения ответа, столько и будет думать. Зато после того как ответ найден, отвечать на последующие аналогичные вопросы начнет моментально. Иначе говоря, люди реагируют согласно имеющимся у них шаблонам: шаблон имеется – ответ следует немедленно; шаблон отсутствует – отсутствует ответ (вместо ответа вставляется «быстрая» заглушка). Значит, такой способ оптимизации не «выдуман из головы», а в известном смысле слова естественен.
С другой стороны, может быть задан вопрос, на который в базе не найдется готового ответа. Здесь оптимизация не поможет: ИИ задумается опять надолго. Во избежание длительного ожидания, при достижении установленного лимита в n секунд, приходится прерывать поиски. Тогда Ваня отвечает заглушкой типа:
Слишком сложный вопрос.
Что, опять-таки, полностью соответствует естественным алгоритмам. На слишком сложный вопрос (для вас сложный, естественно, а не для находящегося в младенческом возрасте Вани) вы тоже не ответите.
Приведенным способом возможности оптимизации не исчерпываются. Но… как говорится, чем богаты.
Принципиальная схема
Принципиальная схема Вани Разумного получилась такой:
1. Парсим текст при помощи библиотеки Solarix.
2. Обрабатываем, преобразуя в списки элементов и свойств.
3. Пишем в базу.
4. В момент записи связываем будущие потенциальные вопросы с текущим утверждением.
5. Ищем, что сказать в ответ (сектор).
6. Одновременно генерируем собственные мысли (в текстовом виде).
7. Преобразуем сектор обратно в текст (словоформы восстанавливаем при помощи библиотеки LingvoNET).
8. Выдаем ответ собеседнику.
9. Параллельно обрабатываем и записываем мысли.
О программе
Многое из задуманного не реализовано, да и вряд ли будет реализовано в будущем. Причин две:
1. Во-первых, ограниченность вычислительных ресурсов. Как я уже упоминал, во избежание затяжек времени пришлось искусственно ограничить обдумывание ответов, при том что сам мыслительный функционал примитивен. Усложнять есть куда, возможности безграничны, идеи прозрачны и на начальном уровне отработаны, но аппаратную часть желательно иметь помощней.
2. Во-вторых, явная (лично для меня) коммерческая бесперспективность данного мероприятия. Убивать еще год, чтобы удовлетворить лишний десяток читателей данного ресурса? А зачем
Между прочим, назначение будущего полноценного ИИ вовсе не выполнение голосовых команд, как то практикуется современными голосовыми помощниками, а…
1) Компьютерная психотерапия.
Вы возвращаетесь с работы расстроенный и говорите ИИ:
«Начальник дурак».
«Форменный остолоп», – заинтересованно отзывается ИИ.
Далее в том же духе. Подобный диалог проведешь не с каждым собеседником, даже близким родственником, а с компьютерным устройством – пожалуйста. Для чего устройство должно быть соответствующим образом, с учетом ваших индивидуальных характеристик, настроено и воспитано.
2) Тестирование на достоверность.
Как следует из всего текущего поста, синтаксис обладает собственной семантикой, которая может быть соотнесена с чьими-нибудь выводами. Следовательно, ИИ способен проверять утверждения на достоверность, соотнося их с предыдущими известными ему утверждениями. А если ИИ не чат-бот, а устройство, обладающее видеокамерой и другими датчиками ощущений, то не только с утверждениями собеседников, но и с реальным миром, который, как мы помним, лишь совокупность визуальных точек и иных элементарных объектов. Мы воспринимаем (видим и иным образом ощущаем) здания, деревья, облака, но ведь ИИ может воспринять нечто другое, неожиданное, «замыленное» для человеческого глаза. Что, согласитесь, гораздо интересней…
Скачать релиз можно здесь.
Исходники тут, если найдутся желающие копаться в дилетантском коде. Зачем нужен код, если Ваня Разумный – лишь иллюстрация к текущему посту, излагающему принципы создания ИИ методом «глокой куздры»?!
Ну и в напоследок.
Я не программист, с меня взятки гладки. Я это к тому, что ошибок много – возможно, неприлично много, даже в диалогах, не только при чтении художественных файлов. Замечу, что ошибки встречаются не только в моем коде, но и в использованных библиотеках, хотя в меньшем количестве. Однако любая ошибка в библиотеке автоматически транслируется на диалог, это надо понимать.
Базу заполнил, насколько смог. Пара сотен фраз: начальные представления о себе и роде человеческом, правила вежливости, – на большее терпения не хватило. Воспитание младенца, даже компьютерного, – задача из трудоемких.
Прорабатывал вопрос с закачкой словарей, в конце концов отказался от мысли. Орфографический и синонимов закачать еще можно (хотя ну очень долго), а вот толковый – никак. В словарях значится, к примеру:
Сидоров – композитор. Кантаты, сюиты.
Альпы – горный массив. Добыча руды. Туризм.
А мне нужно:
Сидоров – композитор. Сидоров – автор кантат, сюит.
Альпы – горный массив. В Альпах добывают руду. В Альпах развит туризм.
То есть с толковыми словарями полная несовместимость: немыслимо на уровне синтаксиса определить, где «автор», а где «добывают». Собственно, и словарей-то в сети не так чтобы много. Требовались: толковый, синонимов, однокоренных слов, фразеологизмов, гиперонимов… Да чего уж теперь!
Если, вдохновленные текущим постом, вы решились-таки убедиться, насколько автор криворукий, то пополнять базу можно двумя способами: либо диалогом, либо закачкой текста. Закачиваемые фразы лучше начинать с новой строки.
Ты умеешь запоминать.
Ты обладаешь памятью.
Успех – это достижение заветной цели.
Ты не можешь двигаться.
Ты не можешь осязать.
Ты не можешь нюхать.
Я думаю недолго, потому что мои алгоритмы действуют быстро.
и т.д.
Предупреждаю, фразы индексируются мучительно долго, так что загружать несколько страниц текста, право слово, не стоит — одной достаточно.
Синонимы устанавливаются по шаблону:
Врач, доктор – это синонимы.
То же – антонимы (которые на самом деле лишь члены класса, что я сообразил далеко не сразу. Белый и черный – антонимы. Однако синий, зеленый и т.д. члены того же класса, поэтому антонимы как сущность у меня отсутствуют – при указании антонимов записываются члены класса).
Белый и черный – это антонимы.
Стандартные ответы устанавливаются в диалоге. Пример я приводил, но повторю:

При закачке стандартный ответ размещается следом за исходной фразой:
Ты молодец.
Отвечай: Ты тоже.
Набивать тексты следует грамотно, с соблюдением знаков препинания, иначе поняты не будете.
Все советы, собственно.
Нет, если не выпендриваться, то в качестве стандартного чат-бота Ваня Разумный худо-бедно способен функционировать.

С этой стороны я своей интеллектуальной одиссеей доволен. Кристальная ясность в голове: что в рамках синтаксиса можно реализовать, а чего нельзя. И полная уверенность в том, что для создания искусственного существа недостает механики и вычислительных мощностей, а что касается принципов мышления, будь то на основе синтаксиса, зрительного или иного восприятия либо комбинированным способом, – теоретические препятствия отсутствуют.
Комментарии (247)

Sly_tom_cat
20.08.2018 10:37Prolog-машина по русски. Ну прикольно че.
Только такие технологии ИИ называли в 70 годы прошлого века.mikejum Автор
20.08.2018 10:45Не знаю, может быть. Только ведь дело не в технологиях, а в принципах. Сдается мне, что современные ИИ используют другие принципы, и я не уверен, что это правильный путь.
Akon32
20.08.2018 13:44Если не ошибаюсь, разработка ИИ на основе пролог-машин закончилась тем, что база правил разрасталась, становилась запутанной и противоречивой. Не взлетело.
Кстати, ваша система оценки достоверности высказываний по рейтингу говорящего, на мой взгляд, не очень хороша. В идеале, нужно реализовывать что-то подобное научному методу, а не просто безоговорочное доверие авторитетам, т.к. авторитеты могут ошибаться. Может быть, нужен какой-то анализ взаимоотношений авторитетов и их целей. Иногда авторитеты говорят противоположное, и помнить нужно всё, чтобы применять в различных контекстах. Иногда авторитет сам не имеет согласованной непротиворечивой информации. ИИ должен в этом бардаке как-то разбираться, а не просто принимать истинным последнее значение.
Но реализовывать это совсем непросто.mikejum Автор
20.08.2018 13:58Не знаком с историей пролог-машин, к сожалению.
Что касается разрастания базы правил, тут у меня полная ясность:
1. В отношении самого мышления правила разрастаться не будут. Классы и каузальность: им просто некуда разрастаться.
2. Некоторое разрастание правил возможно в отношении речевых оборотов, но это исключительно из-за ограниченной элементной базы. Чат-бот, он и есть чат-бот. Приделать видеокамеру, и данный недостаток исчезнет (не станет необходимым растолковывать, чем отличается «еще как» от «вот еще» — ИИ сам определит).
Видеокамера решит проблему и с оценкой достоверности. Если высказывание противоречит визуальному миру, значит собеседник лжец. Заурядная верификация.
Мой способ оценки достоверности, разумеется, несовершенен. Я принял первый непротиворечивый, на который наткнулся. С другой стороны, если для чат-бота единственным способом восприятия окружающего мира является услышанная фраза, почему ей не верить? Для человека это аналогично визуальному восприятию. Вы видите дерево, а кто-то утверждает, что этого дерева нет. Но вы же его видите!Akon32
20.08.2018 14:42Если высказывание противоречит визуальному миру, значит собеседник лжец.
Это можно проверить, только если предмет, о котором говорит собеседник, попал в камеру. Если предмет абстрактный или невидимый камерой — сразу проблема. И ещё невозможно проверить, не врёт ли камера (например, объект можно не заметить из-за недостаточных характеристик камер или ошибок в системе распознавания объектов)
если для чат-бота единственным способом восприятия окружающего мира является услышанная фраза, почему ей не верить?
Для относительно простых случаев (а их, наверно, достаточно много) можно создать непротиворечивое описание ситуации, и на первых порах сойдёт и так.
Но в общем случае, в головах людей — каша из противоречий (особенно когда они пытаются в чём-то разобраться или принять сложное решение). Было бы хорошо, если бы ИИ мог легко разобраться в этой каше, и помочь разобраться в ней пользователю (такие методы уже есть, например метод анализа иерархий). И вряд ли тут можно обойтись без нечёткой логики.
Но полагаю, ваша система будет полезна и без этой сложной схемы верификации, во многих случаях даже рейтинга будет более чем достаточно.
mikejum Автор
20.08.2018 14:53Это можно проверить, только если предмет, о котором говорит собеседник, попал в камеру.
Вот именно. На этот случай у меня имеется готовый пример. Вы верите в существование Антарктиды? Почему, если никогда там не были и вряд ли отправитесь?
То есть люди также часто основываются на высказываниях, в этом чат-бот мало от них отличается.
Но в общем случае, в головах людей — каша из противоречий (особенно когда они пытаются в чём-то разобраться или принять сложное решение). Было бы хорошо, если бы ИИ мог легко разобраться в этой каше, и помочь разобраться в ней пользователю (такие методы уже есть, например метод анализа иерархий)
Полностью с Вами согласен: в головах людей каша. Именно поэтому я написал:
Как следует из всего текущего поста, синтаксис обладает собственной семантикой, которая может быть соотнесена с чьими-нибудь выводами. Следовательно, ИИ способен проверять утверждения на достоверность, соотнося их с предыдущими известными ему утверждениями.
Только это будет проверка с точки зрения синтаксиса, не более.
Что касается конкретных решений, так ведь Ваня Разумный — сделанный любителем прототип. Оценка достоверности — в нем не самое, в случае чего переписать можно.
adeptoleg
20.08.2018 10:51+1Идею вполне реально допилить напильником, скорость можно увеличить нормальной БД и апгрейдом архитектуры (это не критика это выводы из того что я вижу). А вообще вы озвучили то над чем я давно сам задумывался. Только я предполагал развивать на основе объектной модели и для начала там надо было бы составить достаточно приличный словарь. Зато в перспективе можно было бы более точно объяснить суть нового понятия и вполне вероятно что при достижении критической точки такой алгоритм мог бы начать «делать выводы» заполняя пробелы по принципу дедукции.
mikejum Автор
20.08.2018 11:01Кто бы сомневался, что можно допилить и скорость увеличить тоже. Я ж любитель-самоучка, меня методы создания ИИ интересовали, а не программный код. Если раньше я принципы мышления лишь формулировал, то теперь воплотил на практике, насколько смог. А словари, да, мне их сильно недоставало. То, что удалось нагуглить, использовать не смог, к сожалению — об этом я написал.
adeptoleg
20.08.2018 12:26Жаль что вы не хотите заниматься вопросом дальше. Сам я тоже проект бы такой не начинал, а вот в команде думаю был бы смысл. Да и приткнуть даже на вскидку как минимум в 2 места с коммерческим выхлопом можно было но в таком случае надо шевелить поршнями :) для чего и нужна команда.
mikejum Автор
20.08.2018 13:01Заниматься далее или нет, это я по наитию действую. Сегодня мне наитие одно говорит, а завтра другое. Его, это наитие, не поймешь…
Знаете, некоторые вещи я очень хорошо понимаю:
1. У меня отсутствуют способности к бизнесу. То есть любой мой личный коммерческий проект обречен изначально на неуспех, это я на своей шкуре неоднократно испытывал. При том что, случалось, коммерсанты на моих познаниях и способностях неплохо наживались.
2. Программист я начинающий, поэтому сам коммерческий продукт не осилю в любом случае.
3. Данный проект зависит от библиотек, которые я назвал в посте. Без них ничего не получится, поэтому с авторами данных библиотек придется так или иначе договариваться.
4. Нужны словари, причем некоторые придется приводить к пригодному для обработки виду.
Для меня идеальным был бы вариант, чтобы за проект взялся именно коммерсант, чтобы зарплату платил со всеми вытекающими, команду собрал и, главное, знал, зачем и для чего это ваяется. А то, что на озвученных в посте принципах можно сделать ИИ, в этом у меня никаких сомнений нет. Мне известно как.AlexeyR
20.08.2018 15:45Относительно библиотек. Есть opencorpora. Это открытый проект. Из нее легко делается база данных, которая выдает набор требуемых признаков для любого слова. Могу прислать готовое решение.
mikejum Автор
20.08.2018 15:57Спасибо, посмотрю. Хотя не уверен, что хватит квалификации использовать. В свое время я искал, искал — почти ничего. Странно.
Hardcoin
20.08.2018 11:53+1Нюансы, которые легко распознаются людьми по мимике и интонации собеседника, но не могут быть идентифицированы на синтаксическом уровне.
Да, конечно. Особенно в чате.
То, что у бота нет глаз — не существенно. У слепых с рождения тоже нет глаз.
Вообще то, что вы делаете, напоминает экспертные системы из 70-х. Интересно, но прорывов в таком подходе не видно. За саму статью спасибо, увлекательно.
mikejum Автор
20.08.2018 12:04У пользователей чата многолетний опыт восприятия физического мира, поэтому мимика не важна, стилистика сообщения вполне ее заменяет. У чат-бота такого опыта нет по определению, поэтому чат-бот не способен отлавливать стилистику на уровне синтаксиса.
Отсылку к 70-м я сам дал, однако «старая» технология не значит плохая. Преследуя определенные цели, вполне возможно вместо «старой» подсунуть «новую» технологию: объявив ее новомодным трендом, предоставив деньги на развитие и т.п. Не правда ли?Hardcoin
20.08.2018 12:14У пользователей чата многолетний опыт восприятия физического мира
У чат-бота такого опыта нет по определениюВот это очень тонкий вопрос. Например, у openai есть очень классная работа по переносу восприятия "физического мира" из симуляции в реальный. Научили руку манипулировать кубиком.
Дело в том, что мы воспринимаем реальный мир не напрямую, а посредством органов чувств. Обрабатываем сигналы. ИИ вполне может получать такие сигналы из симуляции и набрать эти "несколько лет опыта" при необходимости за пару дней.
Так что "по определению" я считаю неверным. Нет такого определения, которое запрещает чат-боту набирать опыт. Вопрос в алгоритме.
mikejum Автор
20.08.2018 12:44Вопрос не только в алгоритме, но и в вычислительной мощности, при недостатке которой никакой алгоритм не поможет.
Что касается openai, то я не в курсе их достижений, но саму постановку вопроса считаю ошибочной. Это две разных задачи, создание ИИ и эмулирование реальности, зачем их смешивать? К тому же никакая виртуальная реальность не обучит ИИ по-настоящему, по причине, которой я коснулся в посте. Если принять за аксиому, что зрительный мир — совокупность цветных точек, то нет никаких гарантий, что ИИ с видеокамерой начнет воспринимать те же объекты, что человек, и трактовать их по-человечески. Он ведь другое может увидеть! А обучать ИИ на примерах, как это делают нейронные сети, значит подгонять результат эксперимента под желаемые выводы. Посему ИИ должен обучаться не в виртуальном мире, а в нашем с вами — физическом.
Два дня, говорите? Хм… То есть человек, по образцу которого мы мечтаем слепить ИИ, достигает совершеннолетия в 18 лет, а ИИ за пару дней справится? С чего бы это? Возьмите годовалого ребенка и попробуйте за пару дней вбить в его голову Брокгауза и Евфрона, посмотрю, что у Вас получится. А ведь ребенок — урожденный интеллектуал, у него нейронные связи в черепе настроены к восприятию окружающего мира.
И с последним Вашим выводом тоже не соглашусь, Вы приписали мне мысль, которую я не озвучивал. Чат-бот может самостоятельно набирать опыт, но в рамках своего способа восприятия. Если это восприятие — речь, то информацию чат-бот способен почерпнуть только из речи, а семантика речи определяется синтаксисом. «Объяснить» тот или иной термин чат-боту мы можем, конечно, но это внешнее, не самостоятельное знание, см. пример с вопросом «Сколько времени?».Hardcoin
20.08.2018 12:59эмулирование реальности
Конечно это отдельная задача. Но она поможет обучать ИИ быстрее. Не за 25 лет, как живых людей в обычной реальности, а за неделю.
К тому же никакая виртуальная реальность не обучит ИИ по-настоящему, по причине, которой я коснулся в посте.
Честно говоря, не понял этой причины. ИИ без проблем можно научить выделять те же самые предметы из "совокупности цветных точек". Это сделать гарантированно можно — выделение предметов — хорошо изученная задача.
значит подгонять результат эксперимента под желаемые выводы.
Только если обучающие примеры подогнаны под желаемые выводы. Но даже это не плохо. Хочешь получить ИИ-строителя — даёшь больше строительных примеров, это нормально.
ИИ за пару дней справится? С чего бы это?
Нет фундаментальных проблем на рост объема вычислительных мощностей и скорости прогонки примеров. Я потому пример с openai и привёл. Другие исследователи считают, что обучать нужно в физическом мире, т.к. симулировать нереально сложно. И обучают месяцами. Они обучили за 50 часов — двое суток.
Возьмите годовалого ребенка и попробуйте за пару дней вбить в его голову Брокгауза и Евфрона
Конечно нельзя, об этом и речь — скорость обучения машины выше, чем у человека. Пробуйте вбить в него за месяц игру Го. Для машины это сделано — за месяц она обучается играть на голову выше лучших игроков мира, которые учились 20 лет.
mikejum Автор
20.08.2018 13:10Честно говоря, не понял этой причины. ИИ без проблем можно научить выделять те же самые предметы из «совокупности цветных точек». Это сделать гарантированно можно — выделение предметов — хорошо изученная задача.
Если это цветные точки, то совокупность может оказаться иной. Человек видит зайца, а ИИ увидит нечто совершенно другое, так как скомпонует цветные точки иным образом.
Го — слишком специальная задача для мышления: наш мир сложней. Честно говоря, игровые программы я вообще не отношу к ИИ: принципы мышления, соответственно методы реализации, кардинально различаются.Hardcoin
20.08.2018 13:21ИИ увидит нечто совершенно другое
Чем обосновано это утверждение? ИИ увидит то, чему обучат. Даже в вашей статье — сказал, что щука — это рыба и чат-бот запомнил. Если ИИ учить, что эта совокупность точек — мяч, а он "увидел", что это облако — это всего лишь сбой.
принципы мышления, соответственно методы реализации, кардинально различаются.
А это? Насколько я понимаю принципы мышления, они не так уж сильно отличаются от того, что сейчас делают в нейросетях. Если у вас есть надёжные ссылки с разбором настоящих принципов мышления, можете дать?
Го — слишком специальная задача для мышления: наш мир сложней.
Вы правы, мир движется поступательно. Сначала решается более простая задача.
mikejum Автор
20.08.2018 13:40Читал, что какое-то первобытное племя не видит самолетов в небе – просто не видит, и все. Еще читал, что индейцы не замечали подошедших к берегам кораблей Колумба, потому что… просто не замечали. А заметили после того, как им объяснили, как надо смотреть – то есть каким образом увязывать цветные пиксели в конкретные предметы. Я этим псевдогеографическим байкам верю: такие зрительные парадоксы представляются мне правдоподобными.
Увидит — это не о чат-боте, конечно, а о полноценном ИИ, обладающем всеми доступными человеку органами чувств.
Насколько я понимаю принципы мышления, они не так уж сильно отличаются от того, что сейчас делают в нейросетях. Если у вас есть надёжные ссылки с разбором настоящих принципов мышления, можете дать?
Насколько я понимаю (хотя понимаю я в этом совсем немного), принцип действия нейросетей кардинально противоположен тому, что я предлагаю. То, что мне известно о мышлении, я перечислил (в этих абзацах, кстати, основная эвристическая ценность данного поста): классы и каузальность. Человек мыслит именно таким способом. Если для определения классов и установления каузальных цепочек следует использовать нейронные сети, я совершенно не против. Только не понимаю, каким образом это возможно? И зачем, если подобное достижимо без всяких нейронных сетей?
Какую ссылку признать надежной, каждый решает сам. Я обрадуюсь, если кому-то понадобится ссылка на текущий пост.lair
20.08.2018 14:27То, что мне известно о мышлении, я перечислил [...]: классы и каузальность. Человек мыслит именно таким способом.
Кстати, а на чем основано утверждение об "именно таким способом"?
Если для определения классов и установления каузальных цепочек следует использовать нейронные сети, я совершенно не против. Только не понимаю, каким образом это возможно?
Задача классификации — классическая задача машинного обучения, и нейронными сетями (в том числе) она вполне решается. В частности, (обученная) нейронная сеть вполне способа по фразе "Жучка гавкала" сказать "Жучка — собака", а по набору данных "Жучка гавкает; Тузик гавкает; Жучка — собака; Тузик — собака" построить соответствие "собаки гавкают" (собственно, такое соответствие и будет основанием для решения выше).
mikejum Автор
20.08.2018 14:38Кстати, а на чем основано утверждение об «именно таким способом»?
На мышлении — только не чат-бота, а моем. Я проанализовал все, что мне известно о человеке в частности и мироустройстве в целом, и пришел к такому выводу. А Вы каким-то иным способом мыслите?
Задача классификации — классическая задача машинного обучения, и нейронными сетями (в том числе) она вполне решается.
В нейронных сетях я не спец, остается поверить на слово.
Я при решении данной проблемы обошелся заурядной реляционной базой. Вообще, я методолог, меня методы интересуют, а не инструментарий.lair
20.08.2018 14:44А Вы каким-то иным способом мыслите?
Я знаю, что мои представления о мышлении регулярно не совпадают с проявлениями мышления у других людей. Следовательно, мои представления о мышлении не универсальны.
Вы же на основании наблюдений за своим мышлением делаете громкое утверждение, что человек в общем мыслит именно так.
Я при решении данной проблемы обошелся заурядной реляционной базой.
Ну, обойтись-то можно чем угодно, вопрос в том, насколько это эффективно. Для задач классификации есть вполне себе известные метрики.
mikejum Автор
20.08.2018 15:00Вы же на основании наблюдений за своим мышлением делаете громкое утверждение, что человек в общем мыслит именно так.
С оговоркой: с моей точки зрения. Следовательно, я допускаю иные точки зрения, не совпадающие с моей.
Ну, обойтись-то можно чем угодно, вопрос в том, насколько это эффективно. Для задач классификации есть вполне себе известные метрики.
На том, что моя поделка максимальна эффективна, я не настаиваю. Наоборот, всячески подчеркиваю, что я любитель. Вопрос-то не в инструментарии, а в принципах. Если Вы с изложенными мной принципами человеческого мышления не согласны, я с удовольствием выслушаю альтернативную точку зрения. Если Вы для реализации ИИ, на моих ли или иных принципах, предлагаете использовать нейронные сети, никаких возражений. Хотя, конечно, у меня складывается впечатление, что для Вас принципиально задействовать нейронные сети. Не стану спорить — наверное, Вы специалист в данном вопросе.lair
20.08.2018 15:10Нет, для меня принципиально не делать утверждений "человек думает именно так" и "поэтому ИИ должен думать именно вот так".
mikejum Автор
20.08.2018 15:15Ну хорошо, в этом вопросе у нас разные мнения. Было бы странным, если бы мнение автора статьи совпало с мнениями всех без исключения читателей.
buriy
20.08.2018 12:20Да, старая технология из 70х весьма неплоха, более того, наконец-то есть шанс реанимировать её на новых принципах и на новых мощностях.
Кстати, подробнее про нюансы «старой технологии», рекомендую статьи про Cyc, они в своё время ушли дальше всего.
dididididi
20.08.2018 17:06))) Да половина стартапов, у которых в описании машинлернинг, под капотом имеют череду старых добрых ифов))) А что касается эмоций, то вы взгляните в современнную переписку там смайликов больше чем текста.
lair
20.08.2018 13:57Мышление – процесс генерирования новой информации, непосредственно не получаемой от собеседника.
Исходя из этого определения, любой вычислительный процесс есть мышление. Это точно правильное определение?
mikejum Автор
20.08.2018 14:06Любой вычислительный процесс, который генерирует информацию. Генерирует — означает, что информация новая: не считываемая откуда-то. При этом то, что генерируется, должно признаваться информацией: собеседник должен воспринимать ее в качестве таковой. При условии что процесс происходит в объекте, признаваемом за мыслящий, для чего требуется соблюдение, помимо мышления, некоторых других условий (обратная связь, рефлексия). Да, с моей точки зрения, такой вычислительный процесс — мышление.
lair
20.08.2018 14:11Ну смотрите, вот нам на вход подали пятнадцать чисел, мы вернули их среднее и описывающее их распределение. Это новая информация, она ниоткуда не "считана".
Мышление?
mikejum Автор
20.08.2018 14:23При выполнении прочих условий — да. Особенно если это среднее добавляется в ряд к предыдущим пятнадцати числам и на новой основе выполняются последующие, возможно уже другие, вычисления.
lair
20.08.2018 14:28При выполнении прочих условий — да.
Каких именно?
mikejum Автор
20.08.2018 14:46Ну назвал же…
Генерирует — означает, что информация новая: не считываемая откуда-то. При этом то, что генерируется, должно признаваться информацией: собеседник должен воспринимать ее в качестве таковой. При условии что процесс происходит в объекте, признаваемом за мыслящий, для чего требуется соблюдение, помимо мышления, некоторых других условий (обратная связь, рефлексия).
Можно и подробней.
Есть 15 чисел. Высчитываем среднюю. Необходимые условия мышления:
1. Обратная связь: ставим среднюю в ряд к предыдущим 15-ти.
2. Рефлексия: устройство различает числа, услышанные от собеседника и сгенерированные самостоятельно, также историю их создания (от каких родителей сгенерировано). Соответственно, появляется возможность анализа собственных мыслей и услышанного.
3. Мышление: собственно процесс генерирования средней.
4. Имеется собеседник, для которого числа — нечто значащее.
5. Ведется общение, то есть некоторые числа поступают от собеседника, а некоторые возвращаются к собеседнику в виде ответных реплик.
Да, это и есть мыслящее существо. Только, пожалуйста, не путайте сложность системы с принципиальной схемой.lair
20.08.2018 14:55Ну назвал же…
Там нет ничего конкретного, к сожалению. В моем примере
- информация ниоткуда не считывается (чек)
- признается собеседником за информацию (чек)
А вот признание объекта за мыслящий — это же субъективная оценка, как на нее можно опираться? Хуже того, это же получается рекурсивное определение: чтобы объект признавался мыслящим, он должен мыслить, но чтобы понять, что такое мышление, оно должно происходить в мыслящем объекте.
Необходимые условия мышления:
Таким образом, строго детерминированная программа вычисления среднего, адаптированная под чат-бот, является мыслящим существом. По вашему определению.
Тогда у меня есть вопрос: почему вы утверждаете, что "многие [...] собратья [Вани Разумного], в первую очередь созданные на основе нейронных сетей, [...] только притворяются разумными, но по факту являются ими не более чем пластмассовые куклы"? На основании какого формального критерия вы проводите это различение?
mikejum Автор
20.08.2018 15:07Выписка чека не является мышлением, так как отсутствуют другие условия, в частности рефлексия.
Мне казалось, что нейронные сети требуют обучения на основе объемных баз, тем самым обученный субъект реагирует «как полагается в общем случае», а не на основе понятных алгоритмов. Если Вы правы относительно применимости нейронных сетей к классификации, тогда неправ я.
С рекурсией Вы меня неплохо поддели! Переформулирую: устройство должно использоваться для двухстороннего обмена информацией.lair
20.08.2018 15:13Выписка чека не является мышлением, так как отсутствуют другие условия, в частности рефлексия.
А откуда внезапно взялась выписка чека? Я даже не понимаю, о каком именно процессе вы говорите.
Мне казалось, что нейронные сети требуют обучения на основе объемных баз, тем самым обученный субъект реагирует «как полагается в общем случае», а не на основе понятных алгоритмов.
И что? Человек тоже реагирует на задачу классификации далеко не всегда на основе понятных алгоритмов.
Если Вы правы относительно применимости нейронных сетей к классификации,
Относительно чего конкретно? Нейронные сети — и не они одни, есть и более простые алгоритмы — решают задачи классификации достаточно уверенно, это такая современная данность.
Переформулирую: устройство должно использоваться для двухстороннего обмена информацией.
То есть человек, который решает задачу в уме, не мыслит, потому что двустороннего обмена информацией не происходит. Так?
mikejum Автор
20.08.2018 15:18Человек тоже реагирует на задачу классификации далеко не всегда на основе понятных алгоритмов.
Но чтобы написать ИИ, нужно данные алгоритмы хорошо понимать, разве нет? В противном случае ничего написать невозможно, можно вот именно что «обучать».
То есть человек, который решает задачу в уме, не мыслит, потому что двустороннего обмена информацией не происходит. Так?
Человек мыслит, потому что в принципе способен к двухстороннему обмену информацией и мыслит по большей части для этого.lair
20.08.2018 15:24Но чтобы написать ИИ, нужно данные алгоритмы хорошо понимать, разве нет?
Какие "данные"? Которыми человек пользуется? Нет, не обязательно.
В противном случае ничего написать невозможно, можно вот именно что «обучать».
Ну так одни люди именно что "обучают" других, далеко не всегда понимая, что там в обучаемой голове происходит. И ничего, как-то не мешает развитию.
Человек мыслит, потому что в принципе способен к двухстороннему обмену информацией и мыслит по большей части для этого.
И тем не менее, в конкретный момент времени, когда человек мыслит, не совершая обмена информацией, а потом результат этого мышления претворяет в действия (например, идет в магазин за продуктами) — это, получается, не мышление? По вашему определению.
mikejum Автор
20.08.2018 15:29Какие «данные»? Которыми человек пользуется? Нет, не обязательно.
Нет, не которыми человек пользуется, а которые Вы собираетесь вложить в ИИ. Они, извините, обязательны.
Ну так одни люди именно что «обучают» других, далеко не всегда понимая, что там в обучаемой голове происходит. И ничего, как-то не мешает развитию.
Вы действительно не видите разницы между обучением кого бы то ни было и его созданием? Обучение — это показать что и как. Создание — это собрать из деталек. Немножко разные задачи, не находите?
потом результат этого мышления претворяет в действия (например, идет в магазин за продуктами) — это, получается, не мышление?
Ну расширьте определение, если не устраивает. Пусть будет: для двухстороннего обмена и действий в реальном мире.lair
20.08.2018 15:34Нет, не которыми человек пользуется, а которые Вы собираетесь вложить в ИИ. Они, извините, обязательны.
Ну так люди, которые пишут те или иные алгоритмы машинного обучения, знают, как эти алгоритмы работают. Нейронных сетей это тоже касается.
Вы действительно не видите разницы между обучением кого бы то ни было и его созданием?
Вижу. Для задач машинного обучения как раз и характерно это разделение: сначала мы создаем модель, а потом ее обучаем (в противовес обычным детерминированным алгоритмам, которые обычно не обучаются). И вот для обучения совершенно не обязательно понимать, как именно оно происходит, до тех пор пока результат нас устраивает.
Ну расширьте определение, если не устраивает. Пусть будет: для двухстороннего обмена и действий в реальном мире.
А, этот пункт тогда будет применим к любому алгоритму вообще и, как следствие, незначимым для определения мышления.
Что снова возвращает нас к вопросу, по какому критерию вы разделяете "мыслящие" и "немыслящие" реализации ИИ.
mikejum Автор
20.08.2018 16:05Ну так люди, которые пишут те или иные алгоритмы машинного обучения, знают, как эти алгоритмы работают. Нейронных сетей это тоже касается.
Алгоритмы обучения или создания? Я привык думать, что нейронная сеть — черный ящик.
вот для обучения совершенно не обязательно понимать, как именно оно происходит, до тех пор пока результат нас устраивает.
Прежде чем обучать, необходимо же создать! Вы все время создание подменяете обучением.
Что снова возвращает нас к вопросу, по какому критерию вы разделяете «мыслящие» и «немыслящие» реализации ИИ.
Если устройство осуществляет выбор из имеющихся вариантов, оно немыслящее; если генерирует новую информацию — мыслящее.
Вы все за нейронные сети ратуете. Ну, если они способны генерировать новую информацию по настраиваемым алгоритмам, а не методами теории вероятности, мои извинения, Вам лично и нейронным сетям.lair
20.08.2018 16:09Алгоритмы обучения или создания?
И те, и другие.
Я привык думать, что нейронная сеть — черный ящик.
Это представление приблизительно настолько же верно, насколько верно утверждение "программа — черный ящик".
Прежде чем обучать, необходимо же создать! Вы все время создание подменяете обучением.
Не подменяю. Я просто говорю, что это разные моменты, требующие разных навыков.
Если устройство осуществляет выбор из имеющихся вариантов, оно немыслящее
То есть музыковед, относящий по результатам анализа то или иное произведение к той или иной музыкальной форме — не мыслит?
Вы все за нейронные сети ратуете.
Я? Нет.
Ну, если они способны генерировать новую информацию по настраиваемым алгоритмам, а не методами теории вероятности
Подождите-подождите, а почему вдруг алгоритм стал критерием мышления? Вроде бы только что критерием было то, получаем мы "новую" информацию или нет.
mikejum Автор
20.08.2018 16:16То есть музыковед, относящий по результатам анализа то или иное произведение к той или иной музыкальной форме — не мыслит?
Если музыковед, обнаружив новаторское произведение, не в состоянии дать определение новой музыкальной форме, он дубина, а не мыслящее существо.
почему вдруг алгоритм стал критерием мышления? Вроде бы только что критерием было то, получаем мы «новую» информацию или нет.
Возможно, я неточно выразился. Критерием является новая информация, конечно.lair
20.08.2018 16:39Если музыковед, обнаружив новаторское произведение, не в состоянии дать определение новой музыкальной форме
Во-первых, вы ушли от ответа на мой вопрос. Давайте, все же, к нему вернемся: человек, осуществляющий классификацию в существующие классы — мыслит, или нет?
Ну и на всякий случай:
Если музыковед, обнаружив новаторское произведение, не в состоянии дать определение новой музыкальной форме, он дубина, а не мыслящее существо.
Вы, видимо, не очень разбираетесь в музыковедении, иначе бы не делали таких утверждений. Если музыковед имеет дело с новаторским произведением, единственное, что он может сделать — это описать те уникальные признаки, которые в этом произведении есть, однако дать определения новой форме он не может, потому что форма еще не кристаллизовалась.
Более того, способность музыковеда дать или не дать такое определение зависит не от того, является ли он мыслящим существом (потому что все музыковеды являются мыслящими существами, вне зависимости от того, что вы об этом думаете), а от его навыков и таланта.
Критерием является новая информация, конечно.
Так все же, классификация в известные категории — это новая информация или нет?
mikejum Автор
20.08.2018 16:45-1Да, в музыковедении не силен.
Однако Ваш пример притянут за уши. «Если музыковед сидит на диване, он мыслящее существо или нет?». Мыслящее, только его текущее действие к мышлению не относится. Точно так же, когда музыковед классифицирует произведения: если при этом генерируется новая информация, он мыслит; в противном случае не мыслит. При этом музыковед — мыслящее существо.lair
20.08.2018 16:47Ну так классификация произведения — это новая информация: до начала анализа у нас ее не было, а теперь она у нас есть. Но при этом это "выбор из имеющихся вариантов", потому что мы классифицируем в существующей системе понятий. А у вас это невозможное противопоставление.
Что опять возвращает нас к вопросу критериев "мышления" и "разумности".
mikejum Автор
20.08.2018 16:53Если новая, тогда процесс мышления имел место. И что? Несколько утерял ход мысли.
lair
20.08.2018 17:18В таком случае любой классификатор, вне зависимости от алгоритма и реализации, "мыслит".
(а у какого-нибудь SGD, как, впрочем, и любого другого алгоритма с частичным обучением, будет и "обратная связь", и "рефлексия")
… что возвращает нас к вопросу критериев "разумности".
mikejum Автор
20.08.2018 17:21А что такое SGD? Значений многовато:
www.abbreviationfinder.org/ru/acronyms/sgd.htmllair
20.08.2018 17:24mikejum Автор
20.08.2018 17:28У него есть рефлексия? Сомневаюсь.
К тому же не вижу темы для спора. Если мы делаем ИИ «под человека», то изначально признаем, что человек — машина. В этом смысле нет никакой разумности вообще, есть обратная связь, рефлексия, мышление (или любые другие критерии, на выбор). Подгоните под них стиральную машину — она тоже разумной окажется.lair
20.08.2018 17:33У него есть рефлексия? Сомневаюсь.
Давайте начнем с определения рефлексии.
К тому же не вижу темы для спора
Ну то есть вы снимаете все свои утверждения, что ваш "Ваня разумный" — разумен, а остальные алгоритмы машинного обучения — нет?
изначально признаем, что человек — машина. В этом смысле нет никакой разумности вообще
Это в вашей системе определений, возможно, но не в моей.
mikejum Автор
20.08.2018 17:42-1Если нейронные сети действительно берут пример с собачками, беру свои слова назад. К слову, буду признателен, если кто-то из компетентных свидетелей данного спора мне это подтвердит. Так, на всякий случай.
Это в вашей системе определений, возможно, но не в моей.
Вы же мою систему обсуждаете, а свою не излагаете. Простите, но я с Вашей системой не знаком, поэтому ссылаться на нее в аргументированном споре некорректно.
Рефлексия в моем понимании — это восприятие себя отдельно от внешнего мира. Для чат-бота рефлексия — это восприятие отдельно своих фраз от фраз собеседника, что дает возможность раздельно анализировать поведение собеседника и свое поведение. Как возможна рефлексия, см. в статье, схемки приложены.lair
20.08.2018 17:52Если нейронные сети действительно берут пример с собачками, беру свои слова назад.
Нейронные сети "берут" существенно более сложные вещи, чем пример с собачками (ну вон хотя бы на ImageNet посмотрите). Собственно, для "примера с собачками" нейронная сеть избыточна, там достаточно любого линейного классификатора (ну и текстового препроцессора).
Рефлексия в моем понимании — это восприятие себя отдельно от внешнего мира. Для чат-бота рефлексия — это восприятие отдельно своих фраз от фраз собеседника, что дает возможность раздельно анализировать поведение собеседника и свое поведение.
У чистого SGD такого разделения нет, однако у тривиального построенного поверх него чат-бота — тривиально же есть, потому что это всего лишь битовый признак (или раздельные хранилища, не суть). У меня тут в соседнем окне поиск-по-близости с обратной связью, так вот в нем как раз такая рефлексия есть, потому что он (поиск) разделяет сделанную им рекомендацию (это его "фраза") и выбор пользователя (это "фраза" собеседника). Собственно, он, этот поиск, удовлетворяет вообще всем вашим критериям мышления.
mikejum Автор
20.08.2018 17:57Значит, принципиально это мыслящее устройство. Вы этого признания от меня ожидали?
lair
20.08.2018 18:03Теперь осталось, собственно, разобраться с этой фразой:
Несмотря ни на что, Ваня действительно мыслит, в отличие от многих своих собратьев, в первую очередь созданных на основе нейронных сетей, которые только притворяются разумными, но по факту являются ими не более чем пластмассовые куклы.
О каких именно "собратьях" идет речь, и по каким формальным критериям "Ваня" — разумен, а "собратья" — нет?
mikejum Автор
20.08.2018 18:16Вот поясните, коли специалист. Нейронные сети способны обучаться без примеров? Для их обучения нужна база — чем больше, тем лучше — или нет? Если да, тогда это обучение по аналогии, следовательно пример, отсутствующий в базе, нейронная сеть не возьмет. Если нет, тогда чем нейронная сеть отличается от «обыкновенных» алгоритмов? Я искренне не понимаю.
Sychuan
20.08.2018 19:36Я не специалист, но попробую предположить
Нейронные сети способны обучаться без примеров?
Так обучали одну из версий АльфаГо. Она играла сама с собой и никаких других примеров не видела. Нейронная сеть может обучаться на некоторой «воображаемой» ситуации и потом применять набранный опыт к реальности.(я здесь упрощаю) Вот статья blog.otoro.net/2018/06/09/world-models-experiments
Для их обучения нужна база — чем больше, тем лучше — или нет? Если да, тогда это обучение по аналогии, следовательно пример, отсутствующий в базе, нейронная сеть не возьмет.
Нейронные сети и другие модели машинного обучения обладают способностью к генерализации. Вопрос в том, как определять пример отсутсвующий в базе.
lair
20.08.2018 20:18Нейронные сети способны обучаться без примеров?
В общем случае — да. Впрочем, чаще (по моим наблюдениям) люди под "обучением" понимают другое, и в этом смысле ни нейронные сети, ни что-либо другое без примеров обучаться не может.
Для их обучения нужна база
Для обучения с учителем — да.
чем больше, тем лучше
Не всегда так, но часто. Опять-таки, мы говорим об обучении с учителем.
Если да, тогда это обучение по аналогии,
Не обязательно.
пример, отсутствующий в базе, нейронная сеть не возьмет.
Что такое "пример, отсутствующий в базе"? Возьмем задачу классификации, где пример — это набор характеристик и целевой класс. Если речь идет о том, что вы даете обученному алгоритму характеристики от объекта, принадлежащего классу, которого не было в обучающей выборке, то да, известные мне алгоритмы не смогут сделать такую классификацию, но на это не способен и человек (без изменения задачи) — лучшее, что здесь возможно, это сказать, что этот объект не принадлежит ни к одному из известных классов.
Если нет, тогда чем нейронная сеть отличается от «обыкновенных» алгоритмов?
Что такое "обыкновенные" алгоритмы?
Давайте на примере. Возьмем, опять, задачу классификации, те же ирисы Фишера. Существующие данные — это, если в терминах вашего чатбота "ирис с длиной лепестка 1.4, шириной лепестка 0.2, длиной чашелистика 5.1 и шириной чашелистика — это щетинистый ирис", "4.7, 1.4, 6.1 и 2.9, соответственно — это разноцветный ирис", и так 150 раз. Задача — имея четыре цифры, сказать, к какому из трех классов относится ирис.
Как, по-вашему, такую задачу решают "обыкновенные" алгоритмы, о которых вы пишете? И как, кстати, ее решает ваш "разумный" Ваня?
После того, как мы это поймем, можно будет обсуждать, чем отличается решение этой же задачи с помощью нейронной сети или другого алгоритма машинного обучения.
mikejum Автор
20.08.2018 20:33Мой Ваня, «разумность» которого Вы упорно закавычиваете, действует следующим образом.
Во-первых, ему нужно объяснить, что «разноцветный ирис» — это идиома, а не просто существительное с определением.
Во-вторых, нужно объяснить, что разноцветный ирис относится к классу ирисов (хотя тут можно и догадаться, по существительному).
В-третьих, о разноцветном ирисе можно высказать разные соображения, но они будут относиться только к разноцветному ирису. А вот если соображения высказать просто об ирисе, они будут отнесены к ирисам всех видов.
Если же, на что Вы намекаете, какие-либо свойства соотнести с конкретным ирисом, сразу вспомнится пример с определением человека и ощипанной курицей. Платон пошутил, не помню уже?lair
20.08.2018 20:37Окей, вот допустим мы сделали все, что вы описали. После этого Ваня способен решить задачу классификации ирисов Фишера, или нужно что-то еще сделать?
И да, я в первую очередь спрашивал про "обыкновенные" алгоритмы, с ними как?
(я уж молчу про то, что вы так и не ответили, что такое "пример, отсутствующий в базе")
mikejum Автор
20.08.2018 20:47Я уже говорил, что нужно. Обтыкать Ваню датчиками, имитирующими человеческое восприятие, тогда можно говорить о дальнейшем. А пока он чат-бот, и ориентироваться способен исключительно на синтаксис. Если человек способен решить задачу Фишера, то и Ваня окажется способен.
Под «обыкновенными» алгоритмами я разумею НЕ нейронные сети, со всеми ифами, лИстами и прочими прелестями.
Пример, отсутствующий в базе? Ну допустим, вводятся слова, отсутствующие в базе, та же «глокая куздра». Нейронная сеть способна трактовать данную фразу так, как будет трактовать человек? Моему Ване Разумному, при условии что парсер выдаст верную морфологию, до лампочки, что данные слова означают: он легко встроит их в общий контекст. А нейронная сеть? Ответа я не знаю, кстати.lair
20.08.2018 21:04Обтыкать Ваню датчиками, имитирующими человеческое восприятие, тогда можно говорить о дальнейшем.
… а зачем? Какое отношение эти датчики имеют к задаче Фишера, если ни один орган восприятия не является для нее необходимым?
Под «обыкновенными» алгоритмами я разумею НЕ нейронные сети, со всеми ифами, лИстами и прочими прелестями.
Ну вот и расскажите мне, как эти "ифы и листы" будут решать описанную выше задачу классификации — и я вам отвечу, чем ее, задачи, решение с помощью нейронной сети отличается.
Ну допустим, вводятся слова, отсутствующие в базе, та же «глокая куздра». Нейронная сеть способна трактовать данную фразу так, как будет трактовать человек?
При решении какой задачи?
Скажем, при решении задачи классификации ирисов Фишера и нейронные сети, и более простые алгоритмы прекрасно справляются с примерами, которых в обучающей выборке не было.
Чего далеко ходить, берем простейшую логистическую регрессию, one-vs-rest, берем из датасета Фишера 112 примеров, обучаем на них. Берем случайный пример из остальных 38 (5.7, 2.5, 5, 2), удостоверяемся, что его нет в обучающей выборке (в датасете 147 уникальных примеров из 150 всего), загоняем в логит, получаем ответ — виргинский ирис.
mikejum Автор
20.08.2018 21:07Что нужно нейронной сети, чтобы после ввода информации «Глокая куздра штеко кудланула бокра» сеть смогла ответить на вопрос «Кого кудланула куздра?».
lair
20.08.2018 21:08Подозреваю, что синтаксический анализатор, морфологический анализатор и набор примеров.
(точнее говоря, два анализатора нужны для того, чтобы составить набор примеров, самой сети они нафиг не сдались)
mikejum Автор
20.08.2018 21:09Набор каких примеров? С куздрой?
lair
20.08.2018 21:10Нет, с аналогичными признаками, выделенными анализаторами. Если очень грубо — то "медведь поймал оленя" и "корова родила теленка".
lair
20.08.2018 21:12На самом деле, вру, немного сложнее. Приблизительно так:
"медведь поймал оленя — кого поймал медведь — оленя"
"корова родила теленка — кого родила корова — теленка"
lair
20.08.2018 21:09Вы, кстати, знаете, что на этот вопрос нет единственно верного ответа, да?
mikejum Автор
20.08.2018 21:13Да, знаю.
А какое именно обучение должно произойти с нейронной сетью, чтобы в ответ на «Емеля был третьим сыном старика. Его младший брат умер. Сколько сыновей осталось у старика?» получить корректный ответ? Что-нибудь вроде «Теленок был третьим ребенком коровы, двое первых умерло, остался один теленок»?lair
20.08.2018 21:15Без идей. Но я, с другой стороны, никогда не утверждал, что нейронная сеть мыслит и/или разумна.
mikejum Автор
20.08.2018 21:17Может, Вы меня неправильно понимаете? Я скорей утверждаю, что не только Ваня Разумный не мыслит, но и человек тоже. Оба они не мыслят или оба мыслят — вопрос терминологии.
lair
20.08.2018 21:23Нет, вы утверждаете, что Ваня разумный "действительно мыслит, в отличие от многих своих собратьев, в первую очередь созданных на основе нейронных сетей, которые только притворяются разумными, но по факту являются ими не более чем пластмассовые куклы".
Аргументировать это утверждение вы, однако, никак не можете.
(а утверждение "человек не мыслит" выводит эту дискуссию, вместе с вашим постом, в область откровенного троллинга, и я бы не рекомендовал так делать)
mikejum Автор
20.08.2018 21:35-11. По поводу своего высказывания я уже сообщил. Если мне кто-то из хабровчан подтвердит, что нейронная сеть способна по фразам «Жучка собака. Собаки лают» определить, что Жучка умеет лаять, я возьму свои слова относительно нейронных сетей обратно.
2. И по поводу человека говорил. Сама идея создания ИИ наподобие человеческого возможна лишь в том случае, если человек кем-то создан, и создан наподобие машины. В этом смысле термин «мышление» — не прерогатива человека: человек — единица в ряду мыслящих устройств. Если мышление уникально, создать ИИ невозможно в принципе.lair
20.08.2018 21:39Если мне кто-то из хабровчан подтвердит, что нейронная сеть способна по фразам «Жучка собака. Собаки лают» определить, что Жучка умеет лаять, я возьму свои слова относительно нейронных сетей обратно.
То есть внезапно определяющим критерием мышления является построение выводов по таким фразам (и, заметим, именно таким, но не более сложным)?
Сама идея создания ИИ наподобие человеческого
А откуда внезапно взялось "наподобие человеческого"?
Если мышление уникально, создать ИИ невозможно в принципе.
Это, очевидно, не так, потому что уникальные явления поддаются анализу и воссозданию.
mikejum Автор
20.08.2018 21:47и, заметим, именно таким, но не более сложным
Я взял простейший случай. Хотя бы таким…
А откуда внезапно взялось «наподобие человеческого»?
Разве это не общее поветрие? Да и Вы к тому меня склоняете вроде бы.
уникальные явления поддаются анализу и воссозданию
Анализу все поддается, а вот воссозданию — навряд ли, иначе предмет перестанет быть уникальным. Создавая ИИ, мы тем самым признаем, что человеческое мышление не уникально.lair
20.08.2018 22:20Я взял простейший случай. Хотя бы таким…
Тут немедленно возникает вопрос "а может ли более сложные случаи Ваня".
Так все-таки, критерием мышления является именно способность корректно обрабатывать такие фразы, не что-то другое?
Разве это не общее поветрие?
Нет. Все люди, которые что-нибудь мне рассказывали или обсуждали со мной про машинное обучение (и, by extension, про искусственный интеллект), ничего не говорили про "наподобие человеческого". Человек там вообще возникает только как тоска отсчета для метрик качества.
Да и Вы к тому меня склоняете вроде бы.
Я? Нет.
Анализу все поддается, а вот воссозданию — навряд ли, иначе предмет перестанет быть уникальным.
Ну да, перестанет. И что?
Создавая ИИ, мы тем самым признаем, что человеческое мышление не уникально.
Нет, мы признаем, что оно перестало быть уникальным (да и то, только в том случае, если мы создаем человекоподобный ИИ, что не является общим случаем).
mikejum Автор
20.08.2018 22:51критерием мышления является именно способность корректно обрабатывать такие фразы, не что-то другое?
Я приводил свое определение мышления. Ну хорошо, мое Вас не устраивает. Приведите свое определение, пожалуйста.
ничего не говорили про «наподобие человеческого».
А со мной говорили.
Человек там вообще возникает только как тоска отсчета для метрик качества.
Оговорка по Фрейду?
Жду от Вас оригинальной версии мышления.lair
20.08.2018 23:19Я приводил свое определение мышления.
Вот как раз по вашему определению, как мы уже выяснили любая система машинного обучения с обратной связью — мыслящая. Что противоречит написанному вами же в посте.
А со мной говорили.
На "общее место", однако же, уже не тянет.
mikejum Автор
21.08.2018 06:49Любая система с обратной связью при соблюдении прочих условий. С чего мы и начали.
По поводу общего места не понял.lair
21.08.2018 07:51Любая система с обратной связью при соблюдении прочих условий.
Которые, как там же описано, выполняются.
По поводу общего места не понял.
Вы говорили, что "человекоподобные ИИ" — общее поветрие. Как можно видеть — нет, не общее.
mikejum Автор
21.08.2018 08:02Которые, как там же описано, выполняются.
Значит, эти системы с обратной связью — мыслящие.
Как можно видеть — нет, не общее.
Где можно видеть? Я нигде не вижу. Это Ваше ничем не подкрепленное утверждение. Почему я должен ему верить, если у меня другие данные?
Слушайте, чего Вы добиваетесь? Желаете поймать меня на неверном определении? Дайте свое, я Вам уже предлагал, но ответа не получил.
Предлагаю на этом дискуссию завершить, она начинает ходить по кругу и становится бессмысленной.
lair
21.08.2018 08:05Значит, эти системы с обратной связью — мыслящие.
Значит, утверждение в посте — неверно вне зависимости от способности нейронных сетей корректно обрабатывать последовательность фраз "Жучка собака. Собаки лают."
Почему я должен ему верить, если у меня другие данные?
А почему мы должны верить любому вашему утверждению?
Слушайте, чего Вы добиваетесь?
Чтобы вы перестали делать некорректные утверждения в области, в которой вы — по вашеим же заверениям! — не разбираетесь.
mikejum Автор
21.08.2018 08:12-1А почему мы должны верить любому вашему утверждению?
Кто Вас просить верить-то? Да не верьте на здоровье.
Чтобы вы перестали делать некорректные утверждения в области, в которой вы — по вашеим же заверениям! — не разбираетесь.
В каких-то не разбираюсь, а в каких-то очень даже разбираюсь. Про этот термин что-нибудь слышали?
ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5lair
21.08.2018 08:17В каких-то не разбираюсь, а в каких-то очень даже разбираюсь.
Нас интересуют конкретные: машинное обучение, искусственный интеллект, лингвистика. М?
Про этот термин что-нибудь слышали?
Слышал. Однако ряд утверждений в вашей статье не выражен как мнения. Если же вы призываете ко всей статье относиться как ко мнению дилетанта… ну ок, да.
mikejum Автор
21.08.2018 08:30-1Я автор философской системы. Проблема ИИ — смежная с данным вопросом. Еще я профессиональный литератор. Лингвистика — смежная литературе область. Дилетантом в этих областях меня назвать вряд ли возможно. В машинном обучении — да, дилетант.
А Вы, уважаемый? В каких областях Вы крутой специалист, а в каких дилетант? Машинное обучение, ИИ, лингвистика…lair
21.08.2018 08:32Дилетантом в этих областях меня назвать вряд ли возможно.
Возможно-возможно. "Смежная область" — это как раз прекрасная почва для дилетантизма.
В каких областях Вы крутой специалист, а в каких дилетант? Машинное обучение, ИИ, лингвистика…
В лингвистике — дилетант. В области машинного обучения (ну и по совместительству — искусственного интелекта, так было в анонсе написано) я сейчас работаю.
mikejum Автор
21.08.2018 08:36-1А до того, как начали работать в области машинного обучения, были дилетантом или не были?
lair
21.08.2018 08:52Не был.
mikejum Автор
21.08.2018 08:54-1Родились специалистом в области машинного обучения? Это у Вас врожденное?
lair
21.08.2018 09:00(а вы, я смотрю, с определением дилетантизма тоже не очень знакомы)
Да нет, просто пошел учиться.
mikejum Автор
21.08.2018 09:01Для Вас дилетантизм равносилен отсутствию диплома?
lair
21.08.2018 09:06Нет, для меня дилетантизм — это то, что описано в соответствующей статье в википедии.
mikejum Автор
21.08.2018 09:16Да и для меня тоже.
Показательно, что Вы критикуете не достигнутый мной результат, а напрямую не связанное с ним второстепенное высказывание. Из этого я делаю вывод, что Вас совсем не интересуют принципы ИИ, хотя Вы в данной области трудитесь, зато очень интересует толерантность заявлений относительно нейронных сетей. Какие цели Вы при этом преследуете, не знаю, Вам видней.
На этом дискуссию прекращаю. До следующей моей статьи, видимо…lair
21.08.2018 11:50Показательно, что Вы критикуете не достигнутый мной результат, а напрямую не связанное с ним второстепенное высказывание.
Во-первых, если бы это высказывание было второстепенным, вы бы его уже давно поправили. Во-вторых, если бы оно было не было напрямую связано с результатом, вы бы не приводили результат как объяснение "почему" вашего высказывания.
А в-третьих, про результат мы тоже попробовали поговорить, и выяснилось, что (а) метрик у вас нет и (б) чтобы решить предложенные мной задачи, нужно массив органов чувств, подобный человеческим.
Не, мне не сложно, давайте попробуем еще раз. Вот есть простенькая задачка:
— Ваня, на улице жарко?
— Не знаю.
— Какая температура на улице? [заметим, что для ответа на этот вопрос не нужно органов чувств, это типовой пример из любого современного conversational assistant, поэтому я даже не спрашиваю, можно ли это сделать — очевидно, что можно]
— +23
— +23 — это жарко [пойдем по простому варианту, без омиссий и контекстных знаний]
— Запомнил
[Следующий день, за окном +23]
— Ваня, жарко ли на улице?
Каков будет ответ и почему? (я сразу оговорюсь, что это не конец сценария, но надо начинать с простых шагов)
я делаю вывод, что Вас совсем не интересуют принципы ИИ
Неправильный вывод. Именно потому, что меня интересуют принципы машинного обучения, у меня вызывают вопросы и непонимания утверждения, которые ставят одни принципы сильно выше других.
Sychuan
20.08.2018 22:37+1из хабровчан подтвердит, что нейронная сеть способна по фразам «Жучка собака. Собаки лают» определить, что Жучка умеет лаять, я возьму свои слова относительно нейронных сетей обратно.
1. Т.к. эта задача доступна обычным алгоритмам, и так как доказано, что как минимум некоторые архитектуры нейросетей экваивалентны универсальной машине Тьюринга, то очевидно, что можно создать теоретически нейросеть способную к этому.
2. Есть эксперименты по обучению нейросетей отвечать на вопросы по содержванию текстов книг. Вот, например, arxiv.org/abs/1603.08884v1
Думаю это близко к вашему вопросу.mikejum Автор
20.08.2018 22:43Спасибо, беру свои слова обратно.
Если нейронную сеть использовать правильно, она вполне способна стать инструментом для создания ИИ.
lair
20.08.2018 21:22+1… кстати, вот и прекрасный ответ на ваш вопрос "зачем [использовать нейронные сети], если подобное достижимо без всяких нейронных сетей?" — затем, что с помощью "обычного машинного обучения" задача классификации ирисов Фишера решается без необходимости объяснять таксономию ирисов, вводить понятие идиомы (которой, кстати, "разноцветный ирис" не является) и обвешивать кучей датчиков, имитирующих человеческое восприятие.
mikejum Автор
20.08.2018 21:29Вы берете пример, который нейронная сеть заведомо способна решить, и водружаете его в качестве переходящего знамени, но на вопрос, неоднозначный для чат-бота, отвечаете «без идей».
И я не представляю, как без таксономии решить проблему с ирисами. Этак ваша нейронная сеть начнет толковать фразу «Усталый Вася надел тапочки» как: Все усталые люди надевают тапочки, или: Признаком усталости являются надетые тапочки.
Не, разноцветный ирис — это идиома, такая же как индийский слон.lair
20.08.2018 21:36И я не представляю, как без таксономии решить проблему с ирисами.
Я выше показывал, как. Или вам код нужен?
Этак ваша нейронная сеть начнет толковать фразу «Усталый Вася надел тапочки» как: Все усталые люди надевают тапочки, или: Признаком усталости являются надетые тапочки.
Нет, почему бы?
Не, разноцветный ирис — это идиома, такая же как индийский слон.
Я боюсь, что ваше понятие идиомы отличается от общепринятого.
mikejum Автор
20.08.2018 21:42Да, отличается.
Нет, почему бы?
Потому что усталый Вася — это субъект с определением. Вася запросто может стать не усталым, а индийский слон не станет африканским даже в том случае, если его поселить в Африке. Поэтому индийский слон — неделимый оборот, то есть идиома. Хотя лингвисты, возможно, и пользуются другим термином, не знаю.lair
20.08.2018 22:22Да, отличается.
Ну вот опять. Понятие мышления у вас отличается, понятие идиомы — тоже. И зачем только люди придумывают терминологические системы?
Потому что усталый Вася — это субъект с определением.
Вот только это не ответ на вопрос "почему нейронная сеть начнет именно так толковать фразу".
mikejum Автор
20.08.2018 22:46И зачем только люди придумывают терминологические системы?
Для удобства, наверное. Если кому-то терминологическая система становится узка в плечах, он берет другую.
Вот только это не ответ на вопрос «почему нейронная сеть начнет именно так толковать фразу».
Я не специалист по нейронным сетям. Это вам отвечать, каким образом нейронная сеть начнет толковать «эту фразу».lair
20.08.2018 23:14Для удобства, наверное.
Нет, чтобы можно было обсуждать что-то, используя одинаковую (и непротиворечивую) терминологию.
Я не специалист по нейронным сетям
Тогда и не делайте утверждений "ваша нейронная сеть начнет толковать фразу". Вы не специалист, вы не знаете.
mikejum Автор
21.08.2018 06:54Нет, чтобы можно было обсуждать что-то, используя одинаковую (и непротиворечивую) терминологию.
Одинаковая не значит непротиворечивая и полная. Если обнаруживаются противоречия или терминологию становится неудобно использовать из-за неполноты, исследователь применяет свою, оговаривая новые значения, естественно.
Тогда и не делайте утверждений «ваша нейронная сеть начнет толковать фразу».
Вы меня сами вынуждаете к подобным заявлениям. Скажите, как — я во всяком случае прислушаюсь к Вашему мнению.lair
21.08.2018 07:54Если обнаруживаются противоречия или терминологию становится неудобно использовать из-за неполноты,
Вы нашли противоречия или неполноту в лингвистическом понятийном аппарате?
Вы меня сами вынуждаете к подобным заявлениям.
Нет, не вынуждаю. Вы их делаете исключительно по собственной воле для доказательства своей — и, как уже выяснилось, неправильной — точки зрения.
Скажите, как
Так, как будет обучена.
lair
20.08.2018 14:30Несмотря ни на что, Ваня действительно мыслит,
Какое именно обучение должно произойти с "Ваней мыслящим", чтобы в ответ на "Емеля был третьим сыном старика. Его младший брат умер. Сколько сыновей осталось у старика?" получить корректный ответ?
mikejum Автор
20.08.2018 15:14+1Никакого. Корректный ответ в Вашем примере невозможен в принципе, так как отсутствует информация, сколько детей было у старика всего. Может, у него было четверо или пятеро детей?
Если человек не в силах корректно сформулировать вопрос, можно ли требовать корректного ответа от чат-бота?lair
20.08.2018 15:18Корректный ответ в Вашем примере невозможен в принципе
Да здрасьте. Легко и непринужденно: "не меньше одного, если Емеля все еще жив".
Но в данном конкретном случае можно дать и полную информацию, это не отменит моего вопроса.
mikejum Автор
20.08.2018 15:21Ладно, отвечаю полно. Обучить ИИ ответу на такой вопрос можно, если приделать к нему датчики, аналогичные человеческим органам чувств, и воспитывать в физическом мире вместе с людьми. В синтаксисе задания ответа на данный вопрос не содержится.
lair
20.08.2018 15:26Получается, ваш "ИИ" не умеет понимать смысл, только синтаксис. Такое вот "мышление".
mikejum Автор
20.08.2018 15:30Именно так, об этом текущий пост. Как-то Вы невнимательно читали либо главная мысль Вам глубоко несимпатична.
Люди не видят предметов, а наблюдают панораму цветных точек – по сути, хаотичную. Предметы образуются не во внешнем мире, а в человеческом мозгу, за счет увязывания цветных точек воедино, в отдельные совокупности. Это означает, что мы существуем в некоем иллюзорном мире, который в известном смысле нами же и сконструирован.
lair
20.08.2018 15:36Именно так, об этом текущий пост.
… но при этом вы утверждаете, что ваш "Ваня Разумный" мыслит, хотя я вот считаю, что мышление без понимания смысла невозможно (а синтаксис понимает и компилятор).
либо главная мысль Вам глубоко несимпатична.
Эта мысль, очевидно, недоказуема (равно как и неопровергаема), поэтому неинтересна в аргументированной дискуссии.
mikejum Автор
20.08.2018 16:12мышление без понимания смысла невозможно
Еще как возможно! Потому что мышление — это не объекты (дерево, дом, человек), а связи между элементарными и ничего не значащими элементами (цветными точками). Для чат-бота элементарный объект — буква. Очевидно, что сама буква не обладает никаким смыслом сама по себе, смысл возникает для связки из нескольких букв, образующих слово. Которое в свою очередь тоже мало что означает, а обретает смысл лишь в связке с другими словами, обладающими определенными морфологическими признаками.
Эта мысль, очевидно, недоказуема (равно как и неопровергаема), поэтому неинтересна в аргументированной дискуссии.
Я не смогу ее доказать, но ведь Вам-то известно, как оно обстоит на самом деле!lair
20.08.2018 16:36Потому что мышление — это не объекты (дерево, дом, человек), а связи между элементарными и ничего не значащими элементами (цветными точками).
Не всякая связь является мышлением; те же, которые мышлением являются, как раз и являются "смыслом".
Вам-то известно, как оно обстоит на самом деле!
Нет, мне известно, как оно обстоит в принятой мной картине мира, и, что характерно, это не так, как вы описываете.
buriy
21.08.2018 15:13Увы, в этом раунде mikejum прав: мышление без понимания смысла возможно — это абстрактное мышление (оно же «абстрактно-логическое мышление»). Вы не видели чисел 1 и 2 (только их реализации, если вы не слепой, которые тоже умеют решать задачи на сложения), не знаете, что такое «х», вы не видели бесконечную прямую линию, но вы способны запомнить, что 1+1=2 и sqrt(x^2) == abs(x), и что если на линии поставить точку, то бесконечные половинки будут называться «луч», и что тесть троюродного брата — скорее всего вам не родственник, даже если у вас нет брата и тестя.
Только нужно помнить, что логики абстрактного мышления бывают разные: аристотелева, женская, темпоральная.
У автора в логике константы и три отношения: classOf («класс-подкласс»), instanceOf («класс-объект») и causeOf (причина-следствие).
Его система вполне рабочая, но весьма ограниченная. При попытке существенно расширить её (добавив темпоральность, вероятность или оба понятия) возникнут серьёзные вычислительные проблемы.
Но в таком виде, как демонстрация некоторых принципов интеллекта, она вполне годится. Кстати, напоминает детское мышление.
А если поглубже копнуть в теорию систем для логического вывода, то вопрос хорошо обсуждаются здесь:
www.lektorium.tv/course/22781
и, конечно же, если хочется популярно про отличия различных логических систем, то читать здесь:
wikimipt.org/wiki/%D0%97%D0%B0%D0%BC%D0%B5%D1%82%D0%BA%D0%B8_%D0%BE_%D0%B6%D0%B5%D0%BD%D1%81%D0%BA%D0%BE%D0%B9_%D0%BB%D0%BE%D0%B3%D0%B8%D0%BA%D0%B5
А про существенное развитие системы для парсинга человеческого языка читать в PDF: «Тузов В.А. Компьютерная семантика русского языка» (и другие работы его авторства по этой теме).lair
21.08.2018 15:15Вы не видели чисел 1 и 2 (только их реализации, если вы не слепой, которые тоже умеют решать задачи на сложения), не знаете, что такое «х», вы не видели бесконечную прямую линию, но вы способны запомнить, что 1+1=2 и sqrt(x^2) == abs(x), и что если на линии поставить точку, то бесконечные половинки будут называться «луч», и что тесть троюродного брата — скорее всего вам не родственник, даже если у вас нет брата и тестя.
Подождите, но при чем тут "без понимания смысла"? Я понимаю смысл всего описанного выше.
buriy
21.08.2018 15:39Правда? И какой же смысл у числа 1? И что означает то, что вы говорите, что вы его «понимаете»?
lair
21.08.2018 15:42"Число, обозначающее единственный предмет; a unit". Ну и дальше набор характеристик.
buriy
21.08.2018 15:58+1Вы только что определили одно понятие через несколько других. Именно это означает для вас «понимаю смысл»? Для автора поста знание абстрактной онтологии символов не означает понимание смысла. Может, в понимании смысла есть что-то ещё? Например, представление об успешности синтаксического парсинга данного предложения? Теперь понимаете, на основе чего оно возникает?
Это действие называется «интерпретация»: словам из текста мы приписываем их свойства в реальном мире (или их свойства по меркам другого человека). Теперь представьте, что эту часть вы не делаете, реального мира у вас нет, и другого человека тоже нет. Вы можете вывести чисто формально, что платон — человек (Силлогизмы)
Будет ли «расчёт силлогизма» мышлением на ваш взгляд, в тот момент, когда вы не будете рассматривать объекты силлогизма в реальном мире?
(Можете рассмотреть альтернативный пример с любым другим чисто формально-синтаксическим действием, например, раскрывание скобок в любом алгебраическом выражении или взятие производной)lair
21.08.2018 16:02Вы только что определили одно понятие через несколько других. Именно это означает для вас «понимаю смысл»?
Йеп. И так пока не дойдем до неопределимого базового понятия.
Может, в понимании смысла есть что-то ещё? Например, представление об успешности синтаксического парсинга данного предложения?
Это не "что-то еще", это "что-то меньшее".
Будет ли «расчёт силлогизма» мышлением на ваш взгляд
Нет. "Расчет силлогизма" ничем не отличается от "логического и" в программе, но никто не говорит, что программа мыслит.
Можете рассмотреть альтернативный пример с любым другим чисто формально-синтаксическим действием, например, раскрывание скобок в любом алгебраическом выражении или взятие производной
Да-да, именно поэтому и не будет.
buriy
21.08.2018 16:16>Нет. «Расчет силлогизма» ничем не отличается от «логического и» в программе, но никто не говорит, что программа мыслит.
Оу, а если я так сказал, то я «никто»?
Смотрите, возьмём даже википедию: «Мышле?ние — это познавательная деятельность (человека)… Результатом мышления является мысль (понятие, смысл, идея).»
Значит, если новое умозаключение появилось, значит, кто-то только что «помыслил», правильно? И этим «кто-то» былАльберт Энштейнкомпьютер.
Вот люди говорят «гугл нашёл». Но ведь гугл — не может «искать» по аналогичным причинам, он ведь компьютерная программа.
С очеловечиванием разобрались, теперь разберёмся с делимостью.
Я считаю, что каждая часть мышления — тоже мышление, а не только всё явление в совокупности. Вы можете со мной не соглашаться, конечно, ведь это плохо определённый людьми термин.lair
21.08.2018 16:19Оу, а если я так сказал, то я «никто»?
Нет, это я сделал некорректное обобщение.
И этим «кто-то» был компьютер.
Нет, не был. Потому что умозаключение делается умом, а не компьютером, такой вот сложный трюк.
Вы можете со мной не соглашаться, конечно, ведь это плохо определённый людьми термин.
Именно так. Тут (а так же в одном из соседних постов) уже был по этому поводу спор, и результат его все тот же: чем утверждать, что программа "мыслит", лучше говорить о конкретных характеристиках, которые она демонстрирует, это продуктивнее.
Fracta1L
21.08.2018 10:10Но ведь «понимать смысл» это и есть чисто синтаксическая задача, т.е. умение правильным образом выстраивать правильно подобранные слова.
lair
21.08.2018 11:56Совсем нет.
Во-первых, вы говорите ("умение правильным образом выстраивать правильно подобранные слова") о генеративной задаче — то есть выдать пользователю правильный ответ. Например: "что ты видишь на картинке". Задача синтаксиса в этом случае — дать ответ "я вижу двух котов", а не "кот: 2". Но синтаксис никак не поможет выбрать между "я вижу кота" и "я вижу собаку".
А во-вторых, задача понимания — это другая сторона, предшествующая, когда надо понять (извините), что же говорится в предложении. И тут, аналогичным образом, синтаксис может различить объект, действие и субъект ("корова родила теленка": субъект — корова, действие — рожать, объект — теленок), но не способен различить сами объекты: для синтаксиса "корова родила теленка" и "рысь украла теленка" идентичны (ну, за разницей парадигмы слов "корова" и "рысь", но в соседнем языке не будет и этого).
Fracta1L
21.08.2018 12:03Я почему-то подумал, что синтаксис включает в себя морфологию, и что фраза «кот это коробка на колёсах» неверна синтаксически, а не морфологически. Мой фейл.
lair
21.08.2018 12:05Эта фраза морфологически полностью верна. Морфология не имеет никакого отношения к смыслу слов.
(собственно, с точки зрения языкового формализма в этой фразе есть только одна ошибка, и это пунктуация)
Welran
21.08.2018 12:06«Емеля был третьим сыном старика.» наталкивает на мысль что Емеля тоже умер. А корректный ответ «на одного меньше» что не дает никакой полезной информации.
lair
21.08.2018 12:12«Емеля был третьим сыном старика.» наталкивает на мысль что Емеля тоже умер
Не обязательно. Действие происходит в прошлом, вопрос тоже может к нему относиться.
А корректный ответ «на одного меньше» что не дает никакой полезной информации.
Ну, требование про полезность информации пока вообще особо не всплывало, мы только о корректности говорили.
KevinMitnick
20.08.2018 14:49Все современные методы создания ИИ (и ваш не исключение), это подгонка результатов.
Реальное мышление состоит из множества конкурентных процессов, каждый из которых состоит из множества конкурентных процессов.
И моделировать соответственно нужно не исходя из абстракций придуманных человеком. А исходя из первичных элементов.
И чем наше хваленое человеческое мышление отличается от заурядных машинных алгоритмов?! Ничем.
Ничем, потому что машинные алгоритмы, это продукт человеческого мышления, основанный на человеческих же абстракциях.mikejum Автор
20.08.2018 15:23Не возьмусь судить, насколько Вы правы. Вообще, я как раз исходил из первичных элементов — словоформ.

WinPooh73
20.08.2018 16:28> Никто не скажет «макаронный магазин», даже если в магазине торгуют исключительно макаронами.
А вот «барабанный магазин» внезапно оказывается совершенно не тем магазином, в котором торгуют барабанами.
> Возьмем для примера диалог:
> — Петров, как здоровье?
> — Нормальное.
> — А у жены?
> — Тоже.
А сможет ли ИИ разобрать такой диалог:
— Рабинович, как здоровье?
— Не дождётесь!mikejum Автор
20.08.2018 16:51Чат-бот не сможет, естественно: в синтаксисе особого смысла не содержится. В лучшем случае определит, что характеристикой вопроса «как здоровье?» является «Не дождетесь». А полноценный ИИ сможет, примерно таким образом:
а) по физиономии собеседника определит недовольство и агрессию,
б) соответственно установит, что «не дождетесь» является отрицанием в вызывающей форме,
в) запомнит и будет знать.
DGN
21.08.2018 04:05В принципе, если общение бота с Рабиновичем будет более продолжительным, нежели один вопрос, бот способен выстроить интеллектуально-эмоциональную характеристику объекта Рабинович. Просто по частотному анализу фраз, никакой магии. Сейчас ваш бот общается с неким богом, не делая различий между сеансами связи. Если заложить ему протокол «handshake», из серии «как тебя зовут-сколько тебе лет? мы ведь сегодня-вчера-давно-недавно общались?» то можно профилировать аппонентов и при ответе выбирать более близкую для аппонента тему из возможных, более отвечающие аппоненту синонимы. Вплоть до вопроса от бота «Рабинович, вы еврей?» Если некто похожий по профилю, до этого на вопрос «кто ты?», ответил «еврей».
Если вернуться к примеру «Вася устал и надел тапочки», бот может поинтересоваться «вы устали? нет. (вы не вася, а петя) Вы не в тапочках? В тапочках. Почему? Я дома.» Таким образом, человек в тапочках получается или Вася, или устал или дома! По мере наработки базы, сила правильных связей будет расти, а ошибочные связи — отпадать. Я конечно представляю себе комбинаторный взрыв будет на тему, хранить к каждому понятию еще и веса ко всем другим понятиям (ну не ко всем, пусть к единожды использованным). А потому, чат-бот должен уметь забывать. То, к чему нет давно обращений и мало внутренних ссылок, может быть удалено и дефрагментировано (если это не снабжено неким префиксом, из серии «помни — человек царь природы!»).mikejum Автор
21.08.2018 06:58Небольшое уточнение: различия между сеансами связи имеются, чат-бот запоминает, кто и что сказал.
С остальным полностью согласен. Да, приблизительно так и нужно делать, напрашивается.
dididididi
20.08.2018 17:01Крутая штука — порадовали. Сам такую делаю, рад что есть единомышленники. На heroku валяется, но я не стал осмеливаться замахиваться на все богатство человеческого общения. Мне кажется это очень годная вещь для ограниченного синтаксиса. Например ии-кадровик, ии-продавец и т.п. Тогда количество входных данных сильно уменьшается и становится проще анализировать. Ваще странно, что вы в БД уперлись. я мож ничо не понял у меня задачи объемней но не куда не упирается даже на слабом ноутбуке.
mikejum Автор
20.08.2018 17:24Спасибо на добром слове. Что касается БД, то оптимизировал, оптимизировал, все равно — либо слишком много обращений, либо слишком мало материала для анализа. Хотя есть что еще оптимизировать, это да.
dididididi
21.08.2018 09:16Да не парьтесь вы с оптимизацией. Ну подтупливает. Если вы выложите куда-нить в открытый доступ, найдется добрая душа, вам за пару часов если не оптимизирует, то расскажет как это быстро сделать. Я б помог, но я java-js.
mikejum Автор
21.08.2018 09:17Кажется, это Сальвадор Дали сказал: Не стремись к совершенству, ты все равно его не достигнешь.
PavelBelyaev
20.08.2018 18:15Спасибо за статью, несколько лет назад у меня некое подобие было, только с транспортом на вк, телеграм и смс. Но я делал сперва систему уведомлений разными каналами смс+вк+телеграм. А потом развлечения ради привязал ответ на некоторые вопросы по маске (что-то типа регулярок), придумывал алгоритмы случайности и поиска максимальной схожести.
Но сейчас планирую чисто по фану запилить морфологический анализатор и как-то его гонять через открытые источники общения людей. Но пока всё в планах…mikejum Автор
20.08.2018 18:18Да пожалуйста.
Только вот с библиотеками и словарями беда. Когда начинал, убедился: использовал, что смог. Хотя вот, в комментариях подсказали, где искать…DGN
21.08.2018 04:12Доработать толковые словари — вообще не сложно. Загнать в вики-проект пусть сообщество правит. По трудозатратам это меньше чем перевод книги. Суперкомпьютер так же можно построить хоть дома, пусть он будет и не из ТОП500, но боту может хватить.
FerZ_174
20.08.2018 19:23После прочтения статьи, сложилось мнение, что автор утверждает, что для полноценного человеческого интеллекта алгоритмам на морфологическом разборе слов недостает только, остальных основных органов чувств: зрительных, слуховых про остальные упоминать не стоит. Так ли это?
mikejum Автор
20.08.2018 19:28Немного не так. Полноценный ИИ не будет действовать на основании алгоритмов, построенных на морфологическом разборе слов. Однако принцип «глокой куздры» можно применить при трактовке объединенных совокупностей визуальных, слуховых и проч. первичных элементов — объектов физического мира. Морфология отодвинется в сторону, превратится в третьестепенный метод, но сам принцип «глокой куздры» сохранится.
FerZ_174
20.08.2018 19:50То есть, если развить тему дальше, то получается, что язык/слова и тому подобное, являются второсортным методом освоения информации, а точнее только передатчиком. А эффект все же наблюдателя важнее. На подкорке возникает глубинный больше философский вопрос: может ли ИИ делать выводы, выдвигать гипотезы/теории, задумывать технологии и их подтверждать или опровергать, как предположим тот же Стивен Хокинг, Эйнштейн и т.п. Ведь они двигались в области далекой от созерцания процессов, но это им не мешало выдвигать гипотезы, которые в последствии получали подтверждения...
FerZ_174
20.08.2018 20:03Ну и конечно под всем этим поднимается вопрос "воли". А зачем, мотивация, в чем смысл/направление алгоритму проводить собственные внутренние изыскания, суждения. Ведь все же человек пытается осмыслить, осознать, разуметь когда у него появляется в этом потребность, его что то неустраивает. Зачем что то искать и как это заложить ИИ. Ведь По сути программа и машина выдают тот результат, который в нее заложили… Сразу скажу, что вопрос по нейронным сетям еще не дома конца изучен, чтобы утверждать, что они самимм способны постигать за счет обучения.
mikejum Автор
20.08.2018 20:37Вопроса «зачем» не существует, так как цель вкладывается в систему ее Создателем. Какую цель сочтете приемлемой, такую и вложите.
Что касается выдвижения гипотез и проч., то в статье об этом сказано. Предсказание прошлого и антиципация будущего, или этого мало? От гипотез это очень мало отличается.
pekunov
20.08.2018 20:09Хорошая статья. Идея построения интеллектуальной системы на механизме прямой и, отчасти, статистической интерпретации синтаксических конструкций созвучна моим идеям, хотя я занимаюсь в этой области не ИИ, а более частной задачей автоматического программирования. Если будете писать научную статью про Ваши эксперименты, пришлите, пожалуйста ссылку (pekunov@mail.ru). Буду признателен.
mikejum Автор
20.08.2018 20:50Спасибо за теплые слова.
Научную статью — вряд ли, этих научных статей я уже насочинялся вволю (хотя в несколько иной… кгм… сфере деятельности). Следите за моими статьями на Хабре: если появится что-нибудь новенькое, то наверняка здесь.
kirdin
20.08.2018 23:15+1Не хватает цифр перформанса. Например, я пилил для сберовского конкурса-2016 «ответы на вопросы по тексту» примерно такую же штуку на синтаксисе. Проигрывает нейронкам, достаточно значительно.
Я как (бывший) лингвист как раз не сторонник следования нейронкам и др., но нельзя не признать, что есть ряд вещей, с которыми они справляются лучше.
Сейчас вы по сути переизобретаете синтаксический парсинг — штука полезная, на том же питоне, например, есть куча хороших инструментов под нее (см. мой последний пост), но боюсь, что на одном синтаксисе чат-бот далеко уехать не может в принципеmikejum Автор
21.08.2018 07:22Прочитал Ваш последний (?) пост, мне понравилось, спасибо. Разница между моим материалом и материалом профессионального лингвиста заметна невооруженным глазом, увы мне. Но с тем, что на синтаксисе далеко не уедешь, не согласен. Синтаксис — это все, что есть у чат-бота, иного не может быть в принципе.
Не совсем понял, что вы имеете в виду под цифрами перфоманса. Статистические данные?lair
21.08.2018 07:55Синтаксис — это все, что есть у чат-бота, иного не может быть в принципе.
Это, очевидно, не так. У него еще есть (как минимум) предыдущий опыт.
Не совсем понял, что вы имеете в виду под цифрами перфоманса.
Эээ, вы это серьезно? Вы не знаете, что задачи машинного обучения не имеют смысла в отрыве от метрик качества (решения этой задачи)?
kirdin
21.08.2018 13:13+11) Да, насчет последнего я погорячился. Пока единственный ).
2) В вашей парадигме — кроме синтаксиса, действительно, ничего нет. Что не отменяет того, что у других чат-ботов бывают (векторные) семантические модели, онтологии, модели учета контекста и др. — иными словами, сущности семантического, а не синтаксического уровня.
3) И вот именно в связи с пунктом два цифры перформанса и приобретают особый интерес — действительно, пока никто не доказал, что ваш «синтаксический» подход хуже или лучше по качеству, чем любой другой.
Я подразумеваю под ними оценку качества работы бота. Например, на сколько вопросов он ответил верно, на сколько это лучше/хуже каких-то коробочных моделей (условной Алисы).
Поскольку, насколько я успел понять, Ваш бот «специализируется» в первую очередь на ответах на вопросы по тексту, можно было бы взять датасет и посмотреть качество работы на нем. Для русского, насколько мне известно, есть только один масштабный датасет на эту тему — см. задачу B отсюда.
Если бы вы прогнали своего бота по этим текстам и вопросам-ответам, то можно было бы понять, насколько ваше отрицание всего, что выше (и менее управляемо), чем синтаксис и морфология, сказывается на качестве работы модели.mikejum Автор
21.08.2018 13:30Да, теперь понял.
Введение в систему онтологии я не рассматривал, так как это противоречит концепции.
Оценка качества работы? Так ведь это зависит от введенной информации, насколько понимаю. Для корректной проверки необходимо залить во все боты идентичные исходные данные.
Мой Ваня только-только родился. Меня на данном этапе больше заботит, чтобы он в исключения не вылетал, а не соревнование с Алисой. А то, что моя концепция работоспособна, я не то что верю, я доподлинно знаю. Довести Ваню до ума — вопрос чисто технический: времени и денег. Тут и начинаются сложности, для меня непосильные.kirdin
21.08.2018 13:37> Для корректной проверки необходимо залить во все боты идентичные исходные данные.
Совершенно верно! Именно поэтому я и говорю о публичном датасете (в этом, в общем-то и состоит бОльшая часть его миссии) — и даю на него ссылку.
> А то, что моя концепция работоспособна, я не то что верю, я доподлинно знаю.
Вера — это здорово, но в анализе данных я предпочитаю ей цифры. Я тоже верил в чисто синтаксическую историю, пока не проиграл 25% лидерам на упомянутом выше соревновании.
А пока цифр нет — позвольте всё же считать отсутствие чего-либо выше синтаксиса не плюсом, а предубеждением разработчика, снижающим качество работы бота ).
KvanTTT
21.08.2018 01:18Почему бы не выложить исходники на гитхаб?
mikejum Автор
21.08.2018 07:29Позавчера пытался — перед тем, как пост опубликовать, — но постоянно ошибку выдает. Промучился день, потом плюнул, нервишки не выдержали.
devalone
21.08.2018 16:53А что там сложного? Вот тут куча инструкций и клиентов git-scm.com
Какая ОС, софт и какую ошибку выдаёт?mikejum Автор
21.08.2018 18:29Win7. Ошибка одинаковая и в терминале, и в клиенте SourceTree:
git -c diff.mnemonicprefix=false -c core.quotepath=false --no-optional-locks push -v --tags --set-upstream origin master:master
POST git-receive-pack (chunked)
fatal: The remote end hung up unexpectedly
fatal: The remote end hung up unexpectedly
error: RPC failed; curl 56 OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno 10054
Pushing to github.com/mikejum/Informatorium.git
Everything up-to-datedevalone
21.08.2018 19:29А что до этого делаешь? По инструкции с GitHub'а?
Вот тут похожая ошибка и советуют перейти с https на ssh
stackoverflow.com/questions/15240815/git-fatal-the-remote-end-hung-up-unexpectedly
Попробуй в терминале по инструкции на странице репозитория, используя sshmikejum Автор
21.08.2018 19:37До этого — в соответствии с консультацией более сведущего товарища.
Ок, попробую ssh.
Спасибо большое.
ivanrt
21.08.2018 02:02Объединение классов слишком агрессивное. Дочитал до него и возникла идея уточняющих вопросов.
- Маша и Жучка гуляли. Жучка это собака.
- Маша тоже собака?
- Нет, Маша — девочка.
- Понятно.
mikejum Автор
21.08.2018 07:34Да, ошибки на этом пути вероятны, с этим ничего не поделаешь.
Что касается примера, то некорректно говорить:
Маша и Жучка гуляли.
Правильно:
Маша гуляла с Жучкой.
В этом случае объединения субъектов в класс не произойдет.kirdin
21.08.2018 13:15К сожалению, если Вам бы предстояло работать с реальными пользовательскими запросами, то они обычно куда грязнее, чем тексты из прессы и др., там такие «некорректности» сплошь и рядом.
Поэтому боюсь, что для чатов Ваш бот был бы нежизнеспособен. Впрочем, такой цели, кажется, и нет, но думаю, что и пресса допускает некоторый процент «некорректности» в своем стиле. Язык вообще достаточно многоообразен ;-)mikejum Автор
21.08.2018 13:35Да, такой цели передо мной не стояло. Однако неправильное словоупотребление до добра не доводит.
Маша и Жучка гуляли.
Мы с вами предполагаем, что Маша — девочка. Но ведь Маша может оказаться собачкой, тогда отнесение Маши и Жучки к одному классу правомерно.
С точки зрения синтаксиса довольно однозначно:
Маша и Жучка гуляли — это субъекты одного класса.
Маша гуляла с Жучкой — это субъекты разных классов.lair
21.08.2018 13:41Маша гуляла с Жучкой — это субъекты разных классов.
Ха. "Маша гуляла с Олей". Субъекты разных классов, да?
mikejum Автор
21.08.2018 13:46-1Да, с точки зрения синтаксиса Маша, гулявшая с Олей, — субъекты разных классов. Это синтаксис, а не физическая реальность, недоступная чат-боту по определению.
Попробуйте перечитать главку о параллельных реальностях, Вы их все-таки не различаете.lair
21.08.2018 13:49Да, с точки зрения синтаксиса Маша, гулявшая с Олей, — субъекты разных классов.
Вот именно поэтому чистая синтаксическая модель нежизнеспособна.
Это синтаксис, а не физическая реальность, недоступная чат-боту по определению.
Для того, чтобы знать, что Маша и Оля принадлежат (или не принадлежат) к одному классу, не надо иметь доступ в физическую реальность, достаточно иметь информацию о классах объектов и признаках, присущих этим классам.
mikejum Автор
21.08.2018 13:58Вот именно поэтому чистая синтаксическая модель нежизнеспособна.
Не более нежизнеспособна, чем наше бытие. Вам заметно недостает философского опыта, иначе бы Вы поняли, что физический мир, в котором обитают люди, мало чем отличается от вербального мира чат-бота. Пенять существу, что он не способен воспринимать трансцендентный для него мир, не лучшее занятие.
достаточно иметь информацию о классах объектов и признаках, присущих этим классам.
Можно так, а можно иначе, например напрямую отнести субъект к классу.
Оля — это человек.lair
21.08.2018 14:02Пенять существу, что он не способен воспринимать трансцендентный для него мир, не лучшее занятие
Мне, если честно, все равно, какой мир он не воспринимает (и, кстати, это именно вы формулируете так, чтобы мир оказался для него трансцедентным, хотя эту информацию можно получить и другими способами), мне важно, что он не способен решить поставленной задачи. Ну и зачем тогда?
Можно так, а можно иначе, например напрямую отнести субъект к классу.
Это и есть "информация о классах объектов". Только вы замучаетесь каждый объект явно относить к классу, поэтому рано или поздно вы захотите, чтобы бот сам понимал, к какому классу относится объект. И тут мы попадаем в задачу классификации, ну и вы поняли.
mikejum Автор
21.08.2018 14:09мне важно, что он не способен решить поставленной задачи.
Те задачи, которые я перед Ваней поставил, он решил.
Только вы замучаетесь каждый объект явно относить к классу, поэтому рано или поздно вы захотите, чтобы бот сам понимал, к какому классу относится объект.
Именно поэтому Ваня определяет принадлежность к классам по синтаксису. Ваш пример с признаками — лишь одна из возможностей, для синтаксиса не характерная. В синтаксисе другие возможности имеются, то же перечисление.lair
21.08.2018 14:13Именно поэтому Ваня определяет принадлежность к классам по синтаксису.
И, как мы видим, ошибается.
В синтаксисе другие возможности имеются, то же перечисление.
… которое требует, чтобы мы обязательно упомянули объект в той же группе, что и объект нужного класса, что (а) не всегда верно и (б) не всегда возможно. Я, при этом, не говорю, что это неработающая модель, я говорю, что это недостаточная модель.
mikejum Автор
21.08.2018 14:21И, как мы видим, ошибается.
А предмет вашей разработки не ошибается?
Залить словарь гиперонимов и ошибаться перестанет.
Я, при этом, не говорю, что это неработающая модель, я говорю, что это недостаточная модель.
Достаточная в рамках своих возможностей. Вы же не требуете от холодильника, чтобы он еще и блины пек?
lair
21.08.2018 14:26А предмет вашей разработки не ошибается?
Ошибается, и я уверенно могу сказать, в каком проценте случаев. А вот в каком проценте случаев ошибается ваше решение? Да, мы снова пришли к вопросу о метриках.
Залить словарь гиперонимов и ошибаться перестанет.
Несуществующий, ага. В этом и проблема.
Вы же не требуете от холодильника, чтобы он еще и блины пек?
Нет, я требую, чтобы в холодильной камере было +6, а не "+18, ну потому что в рамках своих возможностей". Мне не нужен холодильник с +18 в холодильной камере, мне нужен с +6.
Мне, например, нужен бот, который умеет понимать, что такое "жарко" по десятку примеров. Я дал вам этот сценарий. Может ли ваш бот с ним справиться?
mikejum Автор
21.08.2018 14:30А мне нужен бот, который мыслит на основании синтаксиса. Вашим требованиям Ваня не соответствует, а моим — вполне.
lair
21.08.2018 14:33Ну то есть для решения практических задач ваш бот непригоден, так, что ли, получается?
mikejum Автор
21.08.2018 14:34Для решения Ваших задач, видимо, непригоден. Для решения задач, которые я перед Ваней ставил, — частично. И абсолютно пригоден для подтверждения жизнеспособности моей концепции.
lair
21.08.2018 14:35Для решения Ваших задач, видимо, непригоден.
QED. А говорите — "мыслит".
И абсолютно пригоден для подтверждения жизнеспособности моей концепции.
А напомните, в чем состоит ваша концепция?..
mikejum Автор
21.08.2018 14:37А говорите — «мыслит».
Ага, а по-вашему, мыслящая машина — та, которая отвечает Вашим требованиям?
А напомните, в чем состоит ваша концепция?..
А потрудитесь перечитать пост.lair
21.08.2018 14:42Ага, а по-вашему, мыслящая машина — та, которая отвечает Вашим требованиям?
Ну, моим критериям мышления — да.
А потрудитесь перечитать пост.
Определения концепции там не обнаружено, есть только "в соответствии с реализованной мной концепцией", без указания, что же за концепция. Поэтому понять, какое же из утверждений в вашем посте является концепцией, возможным не представляется, а гадать я не хочу.
mikejum Автор
21.08.2018 14:49Ну, моим критериям мышления — да.
То есть Вы — конечная инстанция, решающая, что является ИИ, а что нет? Поздравляю…
Определения концепции там не обнаружено
Концепция изложена в посте. Если она Вас не устраивает или Вы ее в упор не видите, ну извините. Стоит ли вторые сутки мучить автора, добиваясь от него того, что он не может дать? Или Вы на повременке?lair
21.08.2018 14:55То есть Вы — конечная инстанция, решающая, что является ИИ, а что нет?
Да нет. Просто вопрос критериев — это вопрос критериев, и именно с него мы начали (и именно он — самое слабое место).
Концепция изложена в посте.
Там много чего изложено, в том числе и того, что уже показано ошибочным. Возьму следующую фразу, а выяснится, что она — тоже "второстепенное высказывание", а совсем не "концепция".
mikejum Автор
21.08.2018 15:00-1в том числе и того, что уже показано ошибочным
Пока Вы ничего не показали ошибочным, кроме того, что нейронные сети можно использовать при создании ИИ.
Не, Вы все-таки на повременке.lair
21.08.2018 15:03Одного пункта достаточно, чтобы мое утверждение было верным. А еще там есть недоказанные (а то и недоказуемые) утверждения.
Между прочим, если бы вы потрудились сформулировать свою концепцию, последних пяти где-то комментариев можно было бы избежать.
kirdin
21.08.2018 14:49Все значительно сложнее.
В лингвистике это называется «комитативной конструкцией» и все далеко не однозначно с «одноклассовостью» ее членов даже в русском языке, см. как минимум вот эту книжку.mikejum Автор
21.08.2018 14:51Подозреваю, что сложнее. Однако передо мной стояла начальная задача создания непротиворечивой конструкции.
Спасибо за ссылку.
RuK
21.08.2018 07:35Насколько я понимаю, проблема ИИ всё-таки не в недостатке мощностей, а в структуре. За последние 30 лет вычислительные мощности выросли на много порядков, но чего-то интеллектуального мы так и не видим.
Да, алгоритмы теперь способны обрабатывать большее количество информации, выдавать её в более привлекательной для человека форме, но по сути ничего не поменялось — Запрос-Алгоритм-Ответ. Даже у животных интеллект работает иначе. (они решают одну и ту же проблему разными способами, креативят.)
devalone
21.08.2018 11:40Было бы интересно скормить данные комментариев какого-то нибудь крупного ресурса вроде Хабра или Пикабу и посмотреть, чему он из них научится.
mikejum Автор
21.08.2018 11:55Увы, ничему. Если ребенка сразу пичкать высшей математикой, ему ж неинтересно будет. Начинать придется с малого: «Это птичка. Это листик». Пока система на этом уровне развития находится.
devalone
21.08.2018 16:44А сложно будет сделать, чтоб он понимал информацию с википедии, например?
fractaler
21.08.2018 16:53Википедия имеет плохую машиночитаемость, основная ориентация — человекочитаемость. Следующий шаг за Википедией в эволюции инструментов для статической модели мира — Викидата. Но лучше сразу использовать категории (например, через API) и не ждать, пока викидатовцы тоже пролетят со своей концепцией.
mikejum Автор
21.08.2018 17:07Очень сложно. Текст должен быть определенным образом структурирован. Мы же обитаем в физическом мире и общаемся исходя из физических реалий.
fractaler
21.08.2018 17:11Текст должен быть определенным образом структурирован
Вооот. Именно поэтому ВП обречена.mikejum Автор
21.08.2018 17:18ВП — Википедия?
Если да, то абсолютно согласен. Пока люди не научатся корректно мыслить, соответственно высказывать свои мысли, они обречены на безумие.fractaler
21.08.2018 17:24Да, ВП — Википедия. Мы сейчас наблюдаем все стадии эволюции (от появления, пика, до спада). Там не хотели структурировать текст, получают вымирание (использование их продукта только людьми). Но множество Википедий послужило для следующего элемента, который их все объединил — не узкая, языковая, а универсальная координата (Q*) в общем пространстве координат для коммуникации людей, ботов.
devalone
21.08.2018 17:24а как это мешает программе понимать текст с википедии?
mikejum Автор
21.08.2018 17:32Люди пользуются терминами разной степени абстрактности. Дерево — обозначение предмета реального мира. Зеленый — обозначение свойства предмета. Совесть — абстракция высочайшего уровня. А для чат-бота все эти понятия единого уровня, соответственно понимание сильно различается, не может не различаться. Плюс инвариантность. Плюс сложность языковых конструкций. Плюс несовершенство самого чат-бота. Плюс отсутствие сколь-нибудь объемной базы (опыта).
fractaler
22.08.2018 10:40-1Люди пользуются терминами разной степени абстрактности. Дерево...
Посаженное 100 лет назад дерево — обозначение предмета реального мира?
Здесь
mikejum Автор
22.08.2018 10:48Эти вопросы адресуют к философии, их неуместно обсуждать на техническом ресурсе. Но если коротко, то совесть является сложнейшим (высшего порядка) отношением между объектами физического мира.
Frankenstine
21.08.2018 12:07Пару слов о вашей экспертной системе.
Не Петя не пошёл не в кино
Вы, что ли, способны такую фразу воспринять? Если да, примите поздравления, потому что я при попытке осмысления впадаю в ступор: мозг отказывает.
Что тут сложного-то? В «переводе» в нормальный вид получится
Кто-то (но не Петя) куда-то (но не в кино) не пошёл (отказался от посещения)
Под такую формулировку, например, подходит предложение «Маша сегодня вечером осталась дома».
Тузик — это собака. Жучка и Тузик гуляли по улице. Собаки умеют гавкать.
Здесь вы позволяете вашей системе делать слишком далеко идущие выводы, объединяя Жучку и Тузика в один класс, а это чаще всего не так. «Жучка и Маша гуляли по улице». Маша, со всей очевидностью, выгуливала собака, и с вашей лёгкой руки Маша теперь гавкает.
Нет сомнений, что люди мыслят аналогичным образом. Если задать чересчур сложный вопрос, собеседник сразу не ответит, а задумается: сколько нужно для нахождения ответа, столько и будет думать. Зато после того как ответ найден, отвечать на последующие аналогичные вопросы начнет моментально.
Дело в том, что поиск информации у человека, как правило, не длится долго (за исключением информации, которая частично забыта и требуется время на её восстановление). Человек долго думает в большинстве случаев из-за неоднозначностей формы сложного вопроса, он перобразовывает сам вопрос в более однозначную форму путём мышления. После того, как вопрос удалось переформулировать, ответ на более однозначный вопрос легко находится. Если не удалось сделать достаточно чёткого преобразования, человек, как правило, просит сделать такое преобразование спрашивавшего: «что вы имеете в виду?».
Представим, что в базу добавляется новые записи:
Мальчик купил гантель.
Бабушка положила гантель на комод.
В результате возникают новые потенциальные возможности того, что гантель упадет на ногу, вследствие чего дедушкина нога заболит.
Опять же, здесь делается слишком далеко идущий вывод, что гантель падает на ногу именно дедушки. Программа «выдумывает» информацию, которая отсутствует в предложениях, которые в неё вводят. С большой вероятностью, такая информация будет ложной. Соответственно, чем больше будет база программы, тем больше будет неправильно сделанных выводов.
Во избежание длительного ожидания, при достижении установленного лимита в n секунд, приходится прерывать поиски. Тогда Ваня отвечает заглушкой типа:
Слишком сложный вопрос.
По-хорошему, после вывода заглушки, Ване следует позволить продолжить поиск информации, пока не возникнет необходимость нового поиска (не поступит новый вопрос или утверждение). Это, кстати, будет вполне человечно, мы часто говорим «не знаю» и продолжаем думать над ответом, потрой вскоре находя его.
Надеюсь вы получили море удовольстви в процессе разработки вашего Вани.mikejum Автор
21.08.2018 12:40В «переводе» в нормальный вид получится
Кто-то (но не Петя) куда-то (но не в кино) не пошёл (отказался от посещения)
Все верно, я именно так и пытался переводить, чисто по логике. Только вот мой мозг отказывается эту фразу воспринимать…
«Жучка и Маша гуляли по улице». Маша, со всей очевидностью, выгуливала собака, и с вашей лёгкой руки Маша теперь гавкает.
В одном из предыдущих комментариев поступило такое предложение. Однако стилистически корректная фраза:
Маша гуляла с Жучкой.
Человек долго думает в большинстве случаев из-за неоднозначностей формы сложного вопроса, он перобразовывает сам вопрос в более однозначную форму путём мышления. После того, как вопрос удалось переформулировать, ответ на более однозначный вопрос легко находится.
Можно трактовать и так. С другой стороны, ответ на более однозначный вопрос, а не на заданный — это и есть заглушка.
Программа «выдумывает» информацию, которая отсутствует в предложениях, которые в неё вводят. С большой вероятностью, такая информация будет ложной. Соответственно, чем больше будет база программы, тем больше будет неправильно сделанных выводов.
Абсолютно правильно. Но ведь это чат-бот, он мыслит не так, как мы. Для чат-бота физического мира не существует, он живет в вербальном мире, поэтому его выводы с точки зрения физического мира часто будут оказываться ложными.
По-хорошему, после вывода заглушки, Ване следует позволить продолжить поиск информации, пока не возникнет необходимость нового поиска (не поступит новый вопрос или утверждение). Это, кстати, будет вполне человечно, мы часто говорим «не знаю» и продолжаем думать над ответом, потрой вскоре находя его.
Я не только над этим думал, у меня в одном из вариантов было такое реализовано. Потом отказался, но, если продолжу работы над Ваней, обязательно восстановлю.
Надеюсь вы получили море удовольстви в процессе разработки вашего Вани.
Что есть, то есть.Frankenstine
21.08.2018 15:51Однако стилистически корректная фраза:
Маша гуляла с Жучкой.
Я не о стилистике. Я о ложном выводе.
Петя и Маша гуляли по улице. Петя — мальчик.
Ваша программа делает ложное обобщение «Маша — мальчик». Это ниоткуда не следует, но она это делает.
С другой стороны, ответ на более однозначный вопрос, а не на заданный — это и есть заглушка.
Более однозначный вопрос является сутью сложного вопроса. То есть ответ на упрощённую форму является вопросом по-существу.
Вы знаете ведь, что благими намерениями устлана дорога в ад, так хорошо ли вы подумали над своим предложением?
— сложный вопрос, сводящийся контекстно к простым утверждению «ваше предложение опасно» и вопросу «продуманы ли вами последствия?». Это практически недостижимо вашей программе, как и любому ИИ реализованному на данный момент, я понимаю и ничего не могу предложить по этому поводу. Всё-таки мы думаем не так, как модели нашего мышления, реализованные в софте.
если продолжу работы над Ваней, обязательно восстановлю
Ну вам же станет когда-нибудь скучно ;)
Правда, после публикации исходников, вы можете обнаружить, что свободного времени хватает лишь на анализ изменений, предложенных другими энтузиастами.mikejum Автор
21.08.2018 15:57Ваша программа делает ложное обобщение «Маша — мальчик». Это ниоткуда не следует, но она это делает.
Это следует из перечисления. Причем, если субъекты уже принадлежат каким-либо классам, вывод не делается.
Вообще, ложные выводы неизбежны, их даже люди делают.
Это практически недостижимо вашей программе, как и любому ИИ реализованному на данный момент, я понимаю и ничего не могу предложить по этому поводу.
Если я Вас правильно понял, то да, недостижимо.
ivanrt
21.08.2018 12:34Я тут немного поразмышлял. То что вы создали очень похоже на создание точно семантического графа и поиска в нём. Подобные задачи в нейро-сетях вроде не решены. Точный поиск в нейро-сети это не просто. Зато сети могут делать классификацию картинок которых раньше не видели, перевод на другие языки текста который не встречали, что вы возможно могли бы классифицировать как мышление.
Для вашей задачи вроде используют сегментаторы чтобы находить составные понятия, типа "Вася Пупкин" а затем создают базу взаимосвязей, по которой можно искать. Отрицание факта довольно сложная концепция и то что вы сделали — интересно.
mikejum Автор
21.08.2018 12:51Не берусь судить о новизне того, что сделал. По личным ощущениям, тут мало нового. Ну может, понятие каузальности лингвистикой игнорируется, не знаю. Скорей, заслуга в том, что я некоторые закономерности переоткрыл, систематизировал и сформулировал.
fractaler
21.08.2018 14:33использовал классы. В математике это называется множествами, в лингвистике – гиперонимами
гипероним: понятие, в отношении к другому понятию выражающее более общую сущность. Синонимы: надмножествоmikejum Автор
21.08.2018 14:36Надмножество? Надо же, не знал, что такой термин существует. Хотя все логично.
fractaler
21.08.2018 14:50Причём, тут всё очень и очень относительно. Относительно текущего множества (т.е., уже требуется такое понятие, как наблюдатель). При переходе,
гиперонимнадмножество становится множеством. Ваш Ваня — тоже наблюдатель. Сейчас его (синтаксическая) картина мира создаётся человеком. Интересно будет сравнить с картиной мира, создаваемой, например, вики-коллективом людей и ботов.
devalone
21.08.2018 16:39Код на Яндекс диске и в архиве? Серьёзно? Залей лучше на гитхаб.
Помимо того, что использовать системы контроля версий вроде git стандарт в IT, это позволит вести более удобно разработку и другим людям помогать в разработке.mikejum Автор
21.08.2018 16:42Знаю, что неприлично, но отвечал уже.
habr.com/post/420197/#comment_19014191
Залью рано или поздно, конечно. Будем считать, что эта такая фича.
noobstr
21.08.2018 17:35Подобный подход и правда гораздо лучше бота например с aiml(Alice) или бота типа SimSimi бд которого зависит от юзеров.
Я зарегистрировался специально для этого случая.Я тоже пытаюсь создать свой чат-бот.
Причем готов потратить на это пару лет, по пару часов в день.
К сожалению эта статья как я вижу отражает только малую часть проделанной работы. Исходник уже скачал, но еще особо не изучал.
Ваша статья очень хороша, но к сожалению для таких как я более было бы полезной визуализация алгоритма в текстовом формате например:(к содалению форматирование создано под больший размер)
…
попытаться обнаружить кодировку > если кодировка нормальная(не обнаружены паттерны кракозябр)
попытаться транслитерировать слово > слово есть в БД > дальнешая обработка
слова нет в БД>…
… пытаться определить язык введенного > если слова русские (не обнаружены иностранные буквы по чаркоду)
не удалось понять значение слова стандартными способами{ (
Ориентироваться на другие слова и попытаться предугадать контекст (В зависимости от настроек бота, допустимы попытки предугадывания...)
…
или Ориентироваться на другие слова и попытаться предугадать контекст с сообщением типа
…
или Бот признаться что граматика этого слова не понятна и просит собсеседника исправить вручную
…
или Пытаться выведать информацию об этом слове задав хитрый вопрос
…
}
…
Я пытаюсь неторопливо создать свой чат-бот на другом языке программирования и выверить основные моменты логики перед тем как писать код.
Я хочу детализированно прописать алгоритм который бы можно было начать реализировать на любом языке программирования.
Если вы писали этот чат-бот для того чтобы сформулировать принципы искусственного мышления, то предлагаю совместно сделать все в таком виде,
так как эта статья не прорабатывает детально все моменты а в исходном коде коментарии не настолько частые как мне хотелось.
Это может также помочь многим разработчикам, что будут снова изобретать колесо.
Если вы и правда намучились разбирая чужой код, вы должны понять меня.
если вы даже не хотите или переключились на другой проект тогда прошу разрешения сохранить ваш бот на моей странице в гитхабе,
где я буду в основном пытаться сформулировать логику в текстовом виде. В ином случае предлагаю сотрудничество.
Я думаю что есть немало того что вы не учли при разработке этого бота вместе мы могли бы лучше продумать логику бота в текстовом виде.
В ином случае я буду пытаться проработать логику в текстовом виде в одиночку
Возможно подобный способ кажеться дилетанством, или вам легче читать именно код а не текст. В моем случае легче проработать логику в текстовом виде.mikejum Автор
21.08.2018 17:39В настоящий момент я как раз раздумываю, переключиться на другой проект или допиливать этот. Может, придется допиливать — не знаю.
Напишите в личку, что Вы конкретно предлагаете. Не совсем понимаю, как Вы собираетесь прописывать логику ИИ в текстовом виде.
noobstr
21.08.2018 17:46Это практически недостижимо вашей программе, как и любому ИИ реализованному на данный момент, я понимаю и ничего не могу предложить по этому поводу.
Пратически единственным вариантом чтобы это сделать нужно сделать максимально проработанную словарную базу данных со сложными зависимостями между словами.
На это надо потратить очень много времени. Даное можно реализовать только большим сообществом.
Да и максимально проработать логику программы чтобы имитировать подобное.
А пример с Машей и мальчиком легко реализуем. БД имен и например уточняющий вопрос типа:
Так как это женское имя с большой вероятностью Маша женского пола. Уточните это если не так.
noobstr
21.08.2018 17:50Большинство вариантов логики легко прописать добавив например или на следующей строке текстового файла.
Это подобие разметки когда словами можно описать что необходимо сделать и это быстрее
Псевдокод различных типов используеться некоторыми разработчиками
Он позволет сфокусироваться именно на логике а не на написании кода.
Ykai
21.08.2018 18:40«указывает на предмет и говорит: «Это дерево». И ты понимаешь, что данный предмет называется деревом»
Деревьев не существует, это обобщение, абстракция.
Не знаю, читать ли дальше…mikejum Автор
21.08.2018 18:41Не знаете, читать ли дальше, но комментарий поспешили написать? Ну-ну…
Ykai
21.08.2018 18:44Так это будет опровергнуто?
mikejum Автор
21.08.2018 18:51Вы сначала до конца дочитайте, а потом требуйте опровержений.
Ykai
21.08.2018 19:08в смысле про это — «для создания искусственного существа недостает механики и вычислительных мощностей, а что касается принципов мышления, будь то на основе синтаксиса, зрительного или иного восприятия либо комбинированным способом, – теоретические препятствия отсутствуют.»?
С учетом моего первого коммента здесь, я, пожалуй, сделаю это когда-нибудь.
noobstr
21.08.2018 19:52Деревьев не существует, это обобщение, абстракция.
Есть различные теории что все происходящее абстракция или фильм. Так что пока это полностью не развенчано это возможно.
А описать дерево можно по параметрам: тегам: итд. Начиная из биологических понятий а заканчивая временными параметрами.
Кстати,mikejum можешь проверить диалоги.
Nutwood
22.08.2018 18:59Здравствуйте. Есть проект, с похожим – коннекционистским подходом к исследованию искусственного интеллекта. cortexistenz.com
Возможно, вам будет интересно ознакомиться с некоторыми материалами, размещенными там, или пообщаться с участниками проекта.mikejum Автор
22.08.2018 19:37Ознакомился. Действительно, очень близко к моему подходу. Диалог, приведенный в одной из статей, как под копирку. А в выводе даже дальше шагнули. То, что символьные (синтаксические) системы сами по себе являются интеллектом, мысль простая, но для меня новая. Вполне может оказаться!
Nutwood
22.08.2018 19:56Прошу прощения. Не коннекционистским, а символическим подходом. Коннекционизм — это нейросети Мысль про символьные системы далеко не нова, как вы видите.
sanakess
Возникла идея, запихивать в него научный текст и выуживать информацию вопросами. Что то типа интерактивного поиска.
mikejum Автор
Теоретически возможно в том случае, если содержание научного текста соответствует правилам синтаксиса. Для имеющихся научных текстов такое, увы, невозможно: нужно строить ИИ, воспринимающий физический (зрительный, звуковой и т.п.) мир.
fractaler
«научный текст и выуживать информацию вопросами»
Первый пример. Причём, не нужен посредник в виде очередного Вани — ввод и контроль сразу осуществляется коллективом людей. Т.е., отпадает надобность в проверке создаваемой тривиальной модели мира на близость к реальной тривиальной картине мира (для научной информации, конечно, требуется эксперт).