

Код проекта доступен в репозитории
Введение
Когда я читал описания внешнего вида персонажей в книгах, мне всегда было интересно, как бы они выглядели в жизни. Вполне можно представить себе человека в целом, но описание наиболее заметных деталей – задача сложная, и результаты разнятся от человека к человеку. Много раз у меня не получалось представить себе ничего, кроме весьма размытого лица у персонажа до самого конца произведения. Только когда книгу превращают в фильм, размытое лицо заполняется деталями. К примеру, я никогда не мог представить себе, как именно выглядит лицо Рэйчел из книжки "Девушка в поезде". Но когда вышел фильм, я смог сопоставить лицо Эмили Блант с персонажем Рэйчел. Наверняка у людей, занимающихся подбором актёров, уходит много времени на то, чтобы правильно изобразить персонажей сценария.
Эта проблема вдохновила и мотивировала меня на поиск решения. После этого я начал штудировать литературу по глубинному обучению в поисках чего-то похожего. К счастью, нашлось довольно много исследований по синтезу изображений из текста. Вот некоторые из тех, на которых я основывался:
- arxiv.org/abs/1605.05396 “Generative Adversarial Text to Image Synthesis”
- arxiv.org/abs/1612.03242 “StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks”
- arxiv.org/abs/1710.10916 “StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks”
[в проектах используются генеративно-состязательные сети, ГСС (Generative adversarial network, GAN) / прим. перев.]
Изучив литературу, я выбрал архитектуру, упрощённую по сравнению с StackGAN++, и довольно неплохо справляющуюся с моей проблемой. В следующих разделах я объясню, как решал эту задачу, и поделюсь предварительными результатами. Также опишу некоторые подробности программирования и тренировок, на которые я потратил много времени.
Анализ данных
Несомненно, наиболее важным аспектом работы являются данные, использованные для обучения модели. Как говорил профессор Эндрю Ын в своих курсах deeplearning.ai: «В деле машинного обучения достигает успеха не тот, у кого есть наилучший алгоритм, а тот, у кого есть наилучшие данные». Так начались мои поиски набора данных по лицам с хорошими, богатыми и различными текстовыми описаниями. Я натыкался на разные наборы данных – либо это были просто лица, либо лица с именами, или лица с описанием цвета глаз и формы лица. Но не было таких, которые были нужны мне. Моим последним вариантом было использовать ранний проект – генерация описания структурных данных на естественном языке. Но такой вариант добавил бы лишнего шума в уже достаточно зашумлённый набор данных.
Время шло, и в какой-то момент появился новый проект Face2Text. В нём проходил сбор базы данных подробных текстовых описаний лиц. Благодарю авторов проекта за предоставленный набор данных.
В наборе данных содержались текстовые описания 400 случайным образом выбранных изображений из базы LFW (размеченные лица). Описания были подчищены, чтобы устранить неоднозначные и незначительные характеристики. Некоторые описания содержали не только информацию о лицах, но и какие-то выводы, сделанные на основе изображений – например, «человек на фото, вероятно, преступник». Все эти факторы, а также малый размер набора данных, привели к тому, что мой проект пока только демонстрирует доказательство работоспособности архитектуры. Впоследствии эту модель можно будет масштабировать до более крупного и разнообразного набора данных.
Архитектура
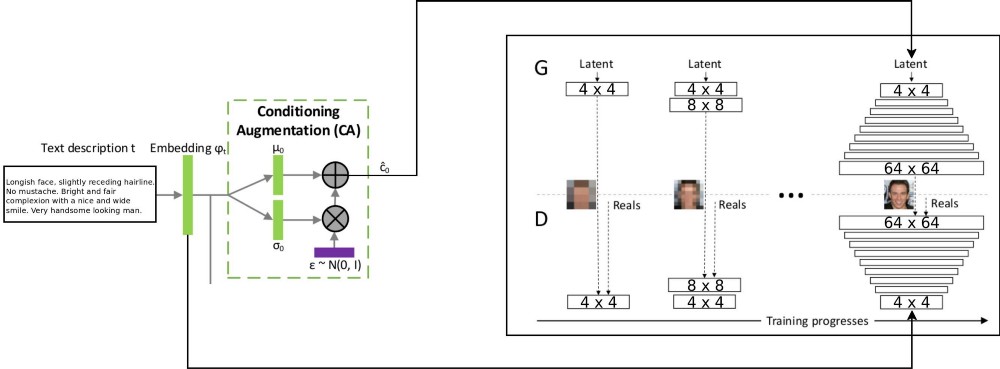
Архитектура проекта T2F комбинирует две архитектуры stackGAN для кодирования текста с условным приращением, и ProGAN (прогрессивный рост ГСС) для синтеза изображений лиц. Оригинальная архитектура stackgan++ использовала несколько ГСС при разных пространственных разрешениях, и я решил, что это слишком серьёзный подход для любой задачи по распределению соответствия. А вот ProGAN использует только одну ГСС, прогрессивно тренируемую на всё более детальных разрешениях. Я решил скомбинировать два этих подхода.
Пояснение по потоку данных через есть: текстовые описания кодируются в итоговый вектор при помощи встраивание в сеть LSTM (Embedding) (psy_t) (см. диаграмму). Потом встраивание передаётся через блок условного дополнения (Conditioning Augmentation) (один линейный слой) чтобы получить текстовую часть собственного вектора (используется техника репараметризации VAE) для ГСС в качестве входа. Вторая часть собственного вектора – случайный гауссовый шум. Полученный собственный вектор скармливается генератору ГСС, а встраивание подаётся на последний слой дискриминатора для условного распределения соответствия. Тренировка процессов ГСС идёт точно так же, как в статье о ProGAN – по слоям, с увеличением пространственного разрешения. Новый слой вводится при помощи техники fade-in, чтобы избежать уничтожения предыдущих результатов обучения.
Реализация и другие детали
Приложение было написано на python при помощи фреймворка PyTorch. Раньше я уже работал с пакетами tensorflow и keras, а теперь мне захотелось попробовать PyTorch. Мне понравилось использовать строенный дебаггер python для работы с архитектурой Network – всё благодаря стратегию раннего выполнения. В tensorflow недавно тоже включили режим eager execution. Однако, я не хочу судить, какой фреймворк лучше, я просто хочу подчеркнуть, что для этого проекта код был написан при помощи PyTorch.
Довольно много частей проекта кажутся мне пригодными для повторного использования, особенно ProGAN. Поэтому я написал для них отдельный код в виде расширения модуля PyTorch, и его можно использовать и на других наборах данных. Нужно только указать глубину и размер особенностей ГСС. ГСС можно тренировать прогрессивно для любого набора данных.
Детали тренировки
Я натренировал довольно много версий сети, используя разные гиперпараметры. Детали работы следующие:
- У дискриминатора нет операций batch-norm или layer-norm, поэтому потеря WGAN-GP может расти взрывообразно. Я использовал drift penalty с лямбдой равной 0.001.
- Для контроля собственного многообразия, полученного из закодированного текста, необходимо использовать расстояние Кульбака — Лейблера в потерях Генератора.
- Чтобы получившиеся изображения лучше соответствовали входящему текстовому распределению, лучше использовать вариант WGAN соответствующего (Matching-Aware) дискриминатора.
- Время fade-in для верхних уровень должно превышать время fade-in для нижних. Я использовал 85% в качестве значения fade-in при тренировке.
- Я обнаружил, что у примеров в более высоком разрешении (32 x 32 и 64 x 64) получается больше фонового шума, чем у примеров меньшего разрешения. Думаю, это происходит из-за недостатках данных.
- Во время прогрессивной тренировки лучше потратить больше времени на меньши разрешения, и уменьшить время работы с большими разрешениями.
На видео показан таймлапс Генератора. Видео собрано из изображений с различным пространственным разрешением, полученных во время тренировки ГСС.
Заключение
По предварительным результатам можно судить, что проект T2F работоспособен, и обладает интересными вариантами применения. Допустим, его можно применять для составления фотороботов. Или для случаев, когда необходимо подстегнуть воображение. Я буду дальше работать над масштабированием этого проекта на таких наборах данных, как Flicker8K, Coco captions и так далее.
Прогрессивный рост ГСС – феноменальная технология для более быстрой и стабильной тренировки ГСС. Её можно совмещать с различными современными технологиями, упомянутыми в других статьях. ГСС можно использовать в разных областях МО.
Комментарии (4)

JTG
22.08.2018 17:59Ну, всяко лучше, чем AttnGAN

(больше по ссылке aiweirdness.com/post/177091486527/this-ai-is-bad-at-drawing-but-will-try-anyways)
Wolframium13
23.08.2018 08:48результаты разнятся от человека к человеку
Поэтому и существует эффект «в книге было лучше».
codecity
Если сделают качественное преобразование txt -> mp4 — то фильмы даже снимать перестанут. Просто перетаскиваешь файл со сценарием в прогу и смотришь готовый фильм, причем каждый раз немножко разный вариант.