
Использовать архитектуру фон Неймана для приложений с искусственным интеллектом неэффективно. Что придёт ей на смену?
Использовать существующие архитектуры для решения задач машинного обучения (МО) и искусственного интеллекта (ИИ) стало непрактично. Энергия, потребляемая ИИ, значительно выросла, и CPU вместе с GPU всё больше кажутся неподходящими инструментами для этой работы.
Участники нескольких симпозиумов согласились с тем, что наилучшие возможности для значительных перемен возникают при отсутствии унаследованных особенностей, которые приходится тащить за собой. Большая часть систем со временем развивалась постепенно – и, пускай это обеспечивает безопасное продвижение вперёд, такая схема не даёт оптимальных решений. Когда появляется что-то новое, возникает возможность взглянуть на вещи свежим взглядом и выбрать лучшее направление, чем то, что предложат общепринятые технологии. Именно это обсуждали на недавней конференции, где изучался вопрос, является ли комплементарная структура металл-оксид-полупроводник (CMOS) наилучшей базовой технологией, на которой стоит строить ИИ-приложения.
Ан Чен, назначенный компанией IBM исполнительным директором исследовательской инициативы в области наноэлектроники (NRI), сформулировал рамки дискуссии. «Много лет мы ведём исследования новых, современных технологий, включая и поиски альтернативы CMOS, особенно из-за её проблем, связанных с энергопотреблением и масштабированием. После всех этих лет выработалось мнение о том, что мы так и не нашли ничего лучшего в качестве основы для создания логических схем. Сегодня многие исследователи концентрируются на ИИ, и он действительно предлагает новые способы мышления и новые схемы, и у них появляются новые технологические продукты. Появится ли у новых устройств для ИИ возможности заменить CMOS?»
ИИ сегодня
Большая часть приложений для МО и ИИ используют архитектуру фон Неймана. «В ней память используется для хранения массивов данных, а CPU выполняет все вычисления», — объясняет Марвин Чен, профессор департамента электротехники Национального университета Синьхуа. «По шине перемещаются большие объёмы данных. Сегодня также часто для глубинного обучения используются GPU, включая и свёрточные [нейронные сети]. Одна из основных проблем – появление промежуточных данных, необходимых для составления вывода. Перемещение данных, особенно за пределы чипа, приводит к потерям энергии и задержкам. Это узкое место технологии».

Архитектуры, используемые для ИИ
Что сегодня нужно, так это совместить обработку данных и память. «Концепция вычислений в памяти предлагалась специалистами по компьютерной архитектуре много лет, — говорит Чен. – Есть несколько схем для SRAM и энергонезависимой памяти, с помощью которых пытались использовать и внедрять такую концепцию. В идеале, если это получится, можно будет сэкономить огромное количество энергии, устранив перемещение данных между CPU и памятью. Но это в идеале».
Но на сегодня у нас нет вычислений в памяти. «У нас до сих пор ИИ 1.0, использующий архитектуру фон Неймана, потому что так и не появилось кремниевых устройств, реализующих обработку в памяти, — жалуется. Чен. – Единственный способ хоть как-то задействовать 3D TSV – использовать высокоскоростную память вместе с GPU, чтобы решать проблему пропускной способности. Но это всё равно остаётся узким местом для энергии и времени».
Достаточно ли будет обработки данных в памяти для того, чтобы решить проблему потерь энергии? «В человеческом мозге содержится сто миллиардов нейронов и 1015 синапсов, — говорит Шон Ли, помощник директора из Taiwan Semiconductor Manufacturing Company. „А теперь посмотрите на IBM TrueNorth“. TrueNorth – многоядерный процессор, разработанный компанией IBM в 2014. У него 4096 ядер, и у каждого по 256 программируемых искусственных нейронов. „Допустим, мы хотим масштабировать его и воспроизвести размер мозга. Разница составляет 5 порядков. Но если мы просто напрямую будем увеличивать числа и множить TrueNorth, потребляющий 65 мВт, тогда у нас получится машина с потреблением 65 кВт против мозга человека, потребляющего 25 Вт. Потребление надо уменьшать на несколько порядков“.
Ли предлагает ещё один способ представить себе эту возможность. „Самый эффективный суперкомпьютер на сегодня — Green500 из Японии, выдающий по 17 Гфлопс на Ватт, или 1 флопс на 59 пДж“. На сайте Green500 написано, что система ZettaScaler-2.2, установленная в Передовом центре вычислений и коммуникаций (RIKEN) в Японии, измерила достижение 18,4 Гфлопс/Вт во время тестового запуска Linpack, требовавшего 858 Тфлопс. „Сравните это с принципом Ландауэра, по которому при комнатной температуре минимальная энергия переключения транзистора составляет порядка 2,75 зДж [10-21 Дж]. Опять получается разница на несколько порядков. 59 пДж – это примерно 10-11 против теоретического минимума примерно в 10-21. У нас есть огромное поле для исследований“.
А честно ли сравнивать такие компьютеры с мозгом? „Изучив последние успехи глубинного обучения, мы увидим, что в большинстве случаев при соревновании человека и машин последние выигрывают уже семь лет подряд“, — говорит Каушик Рой, почётный профессор электротехники и информатики Университета Пердью. „В 1997 Deep Blue победила Каспарова, в 2011 IBM Watson победила в игру Jeopardy!, и в 2016 Alpha Go победила Ли Седоля. Это величайшие достижения. Но какой ценой? Эти машины потребляли от 200 до 300 кВт. Человеческий мозг потребляет около 20 Вт. Огромный разрыв. Откуда возьмутся инновации?
В основе большинства приложений МО и ИИ находятся простейшие вычисления, выполняемые на огромном масштабе. “Если взять простейшую нейросеть, то она выполняет взвешенное суммирование, за которым идёт пороговая операция, — объясняет Рой. – Это можно сделать в матрицах различных типов. Это может быть устройство из спинтроники или резистивной памяти. В этом случае входное напряжение и итоговая проводимость будут связаны с каждой точкой пересечения. На выходе вы получаете сумму напряжений, перемноженную с проводимостью. Это ток. Затем можно взять похожие устройства, выполняющие пороговую операцию. Архитектуру можно представить себе, как кучу этих узлов, связанных вместе так, чтобы проводить вычисления».
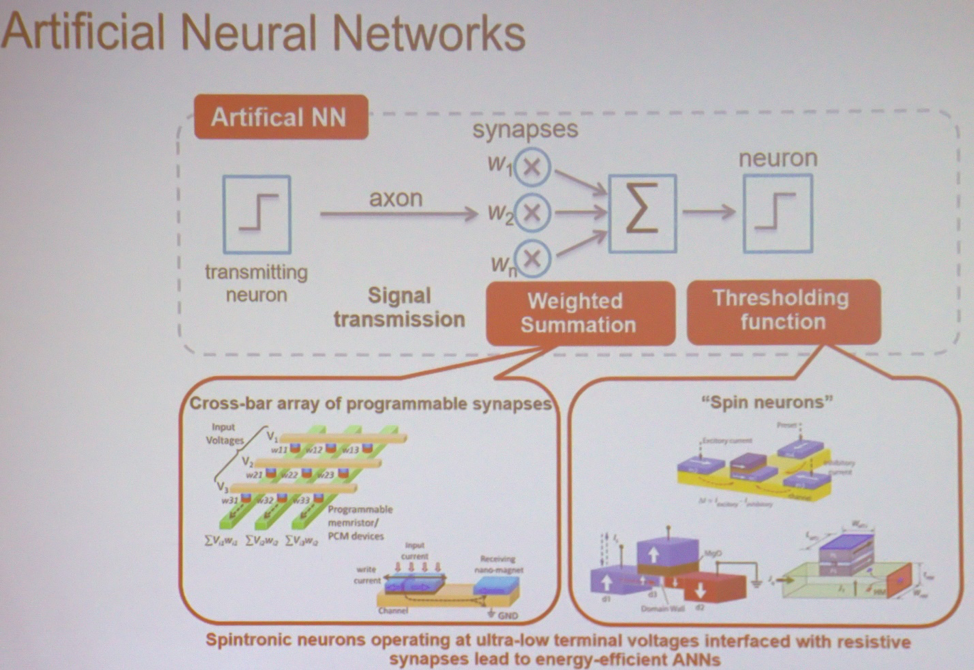
Основные компоненты нейросети
Новые виды памяти
Большинство потенциальных архитектур связаны с появляющимися типами энергонезависимой памяти. «Каковы наиболее важные характеристики?» – спрашивает Джеффри Барр, исследователь из IBM Research. «Я бы поставил на энергонезависимую аналоговую резистивную память, такую, как память с изменением фазового состояния, мемристоры, и так далее. Идея в том, что эти устройства способны делать все перемножения для полностью связанных слоёв нейросетей за один такт. На наборе процессоров это может занять миллион тактов, а в аналоговом устройстве это можно сделать при помощи физики, работающей в месте расположения данных. Тут достаточно очень интересных аспектов в плане времени и энергии, чтобы эта идея развилась во что-то большее».
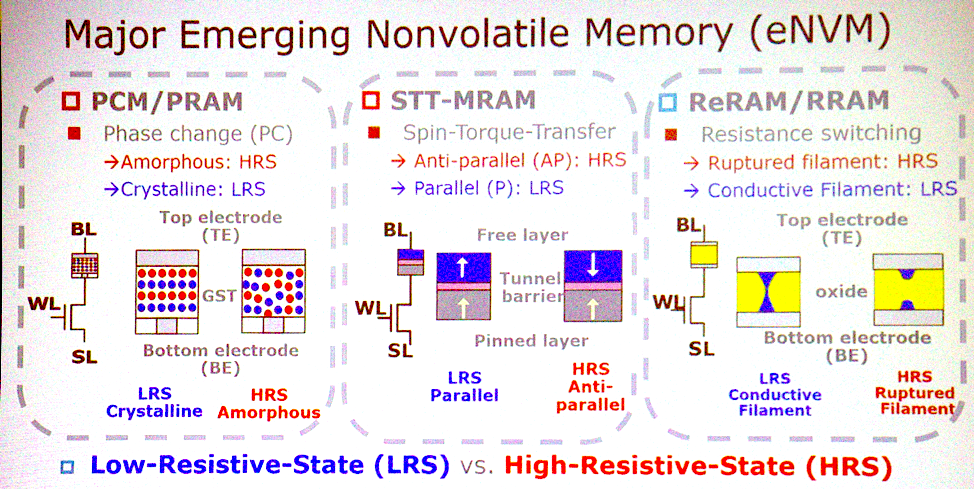
Новые технологии памяти
Чен соглашается с этим. «У PCM, STT серьёзные заявки на победу. Три этих типа памяти – хорошие кандидаты на реализацию вычислений в памяти. Они способны на базовые логические операции. У некоторых видов есть проблемы с надёжностью, и их нельзя использовать для тренировки, но можно для получения вывода».
Но может оказаться, что на эту память не обязательно переходить. «Люди говорят по поводу использования SRAM ровно для тех же целей, — добавляет Ли. – Они занимаются аналоговыми вычислениями при помощи SRAM. Единственный минус в том, что SRAM великовата – 6 или 8 транзисторов на бит. Поэтому не факт, что мы будем использовать эти новые технологии в аналоговых вычислениях».
Переход на аналоговые вычисления также подразумевает, что точность вычислений перестанет быть предметом первой необходимости. «ИИ занимается специализацией, классификацией и предсказаниями, — говорит он. – Он принимает решения, которые могут быть грубыми. С точки зрения точности мы можем чем-то поступиться. Нам нужно определить, какие вычисления устойчивы к ошибкам. Потом какие-то технологии можно будет применять для уменьшения энергопотребления или ускорения вычислений. Над вероятностными CMOS работают с 2003 года. Сюда входит и понижение напряжения вплоть до появления нескольких ошибок, количество которых остаётся терпимым. Сегодня люди уже используют приблизительные техники вычисления, например, квантизацию. Вместо 32-битного числа с плавающей запятой у вас будут 8-битные целые. Аналоговые компьютеры – ещё одна уже упомянутая возможность».
Выбраться из лаборатории
Перемещение технологии из лаборатории в общее пользование может оказаться сложной задачей. «Иногда приходится искать альтернативы, — говорит Барр. – Когда двумерная флэш-память не взлетела, трёхмерная флэш-память стала казаться уже не такой сложной задачей. Если мы будем продолжать улучшать существующие технологии, получая удвоение характеристик тут, удвоение там, тогда аналоговые вычисления внутри памяти окажутся заброшенными. Но если следующие улучшения окажутся незначительными, аналоговая память будет выглядеть более привлекательно. Мы, как исследователи, должны быть готовы к появлению новых возможностей».
Экономика часто тормозит развитие, особенно в области памяти, но Барр говорит, что в данном случае такого не случится. «Одно из наших преимуществ в том, что этот продукт не будет относиться к памяти. Это не будет что-то с небольшими улучшениями. Это не потребительский продукт. Это вещь, конкурирующая с GPU. Их продают по цене, в 70 раз превышающей стоимость размещённой на них DRAM, так что это явно продукт, не связанный с памятью. А стоимость продукта будет не сильно отличаться от памяти. Звучит неплохо, но когда вы принимаете решения, стоящие миллиарды долларов, то все стоимости и план развития продукта должны быть кристально ясны. Чтобы преодолеть этот барьер, нам надо выдать впечатляющие прототипы».
Замена CMOS
Обработка данных в памяти может дать впечатляющие преимущества, но для реализации технологии требуется больше. Может ли помочь в этом какой-то другой материал, кроме CMOS? «Рассматривая переход от CMOS низкого потребления к туннельным FET, мы говорим об уменьшении потребления на 1-2 порядка, — говорит Ли. – Ещё одна возможность – это трёхмерные интегральные схемы. Они уменьшают длину проводки, используя TSV. Это уменьшает и энергопотребление, и задержки. Посмотрите на дата-центры, все они убирают металлическую проводку и подключают оптическую».
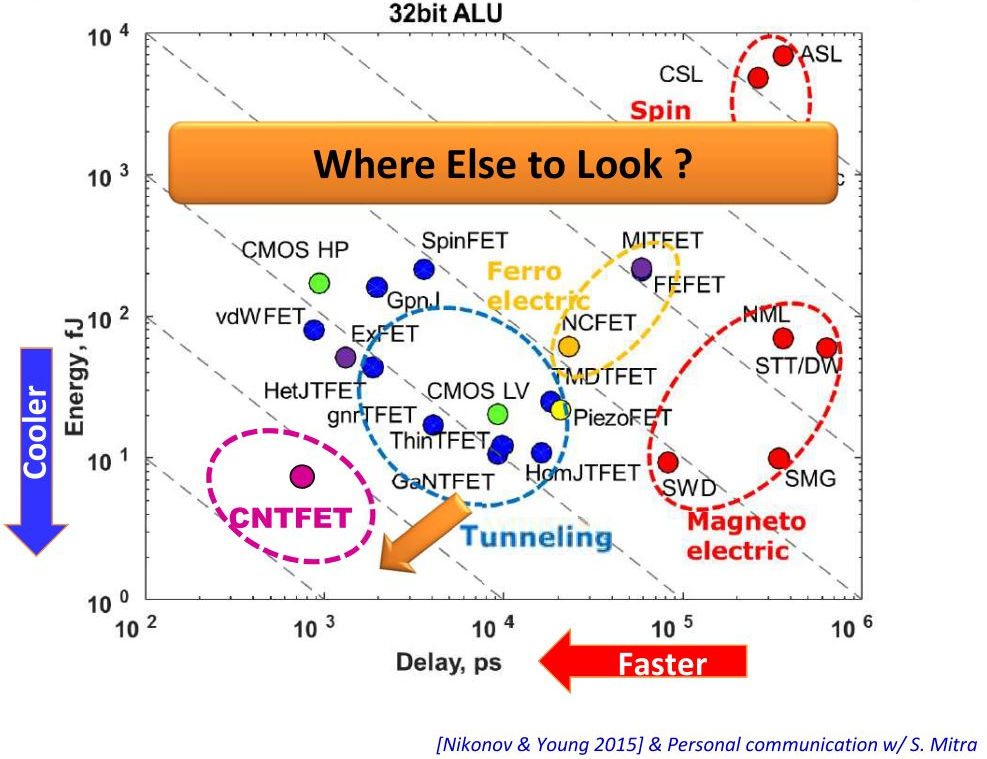
По вертикали – энергопотребление, по горизонтали – задержки в работе устройств
Хотя при переходе к иной технологии можно достичь неких преимуществ, они могут того и не стоить. «Будет очень сложно заменить CMOS, но некоторые из обсуждаемых устройств могут дополнить CMOS-технологию так, чтобы она проводила вычисления в памяти, — говорит Рой. – CMOS может поддерживать вычисления в памяти в аналоговом виде, возможно, в ячейке 8T. Возможно ли создать архитектуру с явным преимуществом перед CMOS? Если всё сделать правильно, то и CMOS даст мне увеличения энергоэффективности в тысячи раз. Но на это нужно время».
Ясно, что CMOS не заменят. «Новые технологии не отвергнут старые, и не будут сделаны на каких-то других подложках, кроме CMOS», — заключает Барр.
Комментарии (19)

artemev
23.08.2018 17:05+2Если провести аналогию с программированием, то все о чем говорится в статье похоже на чрезмерную оптимизацию на начальной стадии разработки (этап прототипа).
ИМХО, сначала нужно создать более-менее полноценный ИИ, а уже потом думать об увеличении его эффективности и уменьшении энергопотребления.
P. S. Прочитав заголовок, думал будет о том, что текущая архитектура принципиально не подходит для создания ИИ
Akon32
23.08.2018 17:36Стадия разработки уже не начальная, попыткам сделать ИИ десятки лет. И сейчас ясно, что для нейросетевого подхода классический CPU с double precision арифметикой не очень-то хорош, а GPU — получше. Почему бы не сделать ещё лучшее "железо" для нейросетей?
Конечно, нет уверенности, что сильный ИИ будет реализован именно на тех нейронных сетях, которые популярны сейчас, но сегодняшние нейронные сети тоже приносят пользу, и их работу есть куда оптимизировать.
Кроме того, эти разработки идейно приближаются к структуре "железа" единственного известного интеллекта (высокий параллелизм, распределённая память), и я не вижу причин, почему этот путь неправильный. Возможно, к разработке ИИ есть и другие пути, но они так же туманны.
P.S.: По моему опыту, без "преждевременной" оптимизации сложные системы просто неспособны работать. Неуспевающая система — это тоже фэйл.
artemev
23.08.2018 18:38+3На мой взгляд тут просто проблема в терминологии. Сейчас любую простейшую нейросеть гордо именуют Искусственным Интеллектом.
А так, если какая-то условная нейросеть хорошо справляется со своей задачей, но при этом работает медленно и жрет много энергии, то создать для нее некий специализированный чип, который сделает ее быстрой и энергоэффективной вполне оправданно.

Tamul
23.08.2018 18:27Выйдет забавно, если лет через 5 разработают алгоритм сильного ИИ, способный в реальном времени работать на Arduino с парой подключённых гигабайтных DDR1 и SD-карточкой, не говоря уж о малинке и нетбуках.
Sdima1357
24.08.2018 02:31Не разработают. Мозг — довольно мощный прибор хотя бы на обработке изображений. Вы не можете сделать никакого распознавания быстрее чем n^2 log n где n сторона картинки порядка 2000. И это минимальная оценка, и делать нужно не менее 10 раз в секунду. Реально все намного хуже. То есть ардуино тут никаким боком
Tamul
24.08.2018 14:13Не факт, что способность распознавать изображения хоть как-то коррелирует с абстрактным мышлением и интеллектом. В том же тесте Тьюринга объём входных данных и выборки для обучения на порядки меньше, а он до сих пор не пройден
gleb_l
23.08.2018 18:53Забавно, что история вычислительной техники тоже развивается по спирали. Аналоговые вычислительные модули снова становятся перспективными. Для применения в качестве нейронов — самое то — цифровая точность в ячейке принятия решения не нужна, и даже вредна, а тепловой шум — естественный фактор, увеличивающий обобщающие способности аналогового ИИ
Khort
24.08.2018 08:12Перебирание давно известных фактов. Понятно, что для нейрона использовать процессор — как из пушки по воробьям. Понятно, что на КМОП нейрон не сделать, а если и сделать (подпороговое питание) то слишком медленно и неточно (при низком питании шум того же порядка что и сигнал). Поэтому аналоговые КМОП нейроны почти не делают. Понятно, что мемристоры могли бы подойти, несмотря на недоизученность. Все это известно уже лет 20.
fivehouse
24.08.2018 19:05+1Аффтары могли бы смело писать статью о том, сколько чертей поместится на кончике иглы производства Siemens. Было бы более предметно и содержательно, чем этот словоблудный опус.
Hardcoin
Они реально видят в этом проблему? Если полноценный ИИ влезет в 65 кВт, дайте два.
pomme
Конечно, видят.
Если полноценный ИИ влезет в 65 Вт вместо 65 кВт, представляете, что влезет в 65 кВт?
Hardcoin
Пока не представляю.
Я имел ввиду, что сложно его сделать с любым потреблением. Пусть хоть 65 МВт. Хотя само по себе исследование, которое даст снижение энергопотребления на порядок или два, конечно, очень важно. И не только для ИИ.
P.S. мощность фермы для бота open ai для доты — 1-2 мегаватта. Так что 65 кВт — вообще ни о чем.
saboteur_kiev
Если полноценный ИИ влезет в 65 кВт, то он сам изобретет ИИ-2, который влезет в 65Вт.
С другой стороны, нужно ли нам полноценный ИИ, или нужен похожий на полноценный, но полностью контролируемый?