
Каждый день пользователи совершают миллионы действий в интернете. Проекту FACETz DMP необходимо структурировать эти данные и проводить сегментацию для выявления предпочтений пользователей. В материале мы расскажем о том, как команда сегментировала аудиторию в 600 миллионов человек, обрабатывала 5 миллиардов событий ежедневно и работала со статистикой, используя Kafka и HBase.
В основе материала — расшифровка доклада Артема Маринова, специалиста по большим данным в компании Directual, c конференции SmartData 2017.
Меня зовут Артём Маринов, я хочу рассказать о том, как мы перерабатывали архитектуру проекта FACETz DMP, когда я работал в компании Data Centric Alliance. Почему мы это делали, к чему это привело, по какому пути мы шли и с какими проблемами столкнулись.
DMP (Data Management Platform) – платформа по сбору, обработке и агрегации пользовательских данных. Данные – это очень много разных вещей. Платформа насчитывает порядка 600 миллионов пользователей. Это миллионы cookie, которые ходят по интернету и совершают различные события. В целом, день в среднем выглядит примерно вот так: мы видим порядка 5,5 млрд событий в сутки, они как-то размазаны по дню, а в пике достигают порядка 100 тысяч событий в секунду. События – это различные пользовательские сигналы. К примеру, визит на сайт: мы видим, с какого браузера ходит пользователь, его useragent и всё, что мы можем извлечь. Иногда мы видим, как и по каким поисковым запросам он пришел на сайт. Это также могут быть различные данные из офлайн-мира, например, что он оплачивает скидочными купонами и так далее.
События – это различные пользовательские сигналы. К примеру, визит на сайт: мы видим, с какого браузера ходит пользователь, его useragent и всё, что мы можем извлечь. Иногда мы видим, как и по каким поисковым запросам он пришел на сайт. Это также могут быть различные данные из офлайн-мира, например, что он оплачивает скидочными купонами и так далее.
Нам эти данные надо сохранить и разметить пользователя в так называемые группы аудиторных сегментов. Например, сегментами могут быть «женщина», которая «любит котиков» и ищет «автосервис», у нее «есть автомобиль старше трех лет».
Зачем сегментировать пользователя? Применений этому множество, например, реклама. Различные рекламные сети могут оптимизировать алгоритмы показа рекламы. Если вы рекламируете свой автосервис, то сможете настроить кампанию таким образом, чтобы показывать информацию только людям, у которых есть старый автомобиль, исключив владельцев новых. Вы можете динамически менять контент сайта, можете использовать данные для скоринга – применений множество.
Данные получаются из множества абсолютно разных мест. Это могут быть прямые установки пикселя – это в том случае, если клиент хочет анализировать свою аудиторию, он ставит пиксель на сайт, невидимую картинку, которая подгружается с нашего сервера. Суть в том, что мы видим визит пользователя на этот сайт: его можно сохранить, начать анализировать и понять портрет пользователя, вся эта информация доступна нашему клиенту.

Данные могут быть получены от различных партнеров, которые видят много данных и хотят их монетизировать различными способами. Партнеры могут поставлять данные как в реальном времени, так и делать периодические выгрузки в виде файлов.
Ключевые требования:
Одно из ключевых требований системы – горизонтальная масштабируемость. Тут есть такой момент, что когда вы разрабатываете портал или интернет-магазин, то можете оценить количество ваших пользователей (как оно будет расти, как будет меняться) и примерно понять, сколько нужно ресурсов, и как магазин будет жить и развиваться со временем.
Когда вы разрабатываете платформу, подобную DMP, нужно быть готовыми к тому, что любой крупный сайт – условный Amazon, — может поставить к себе ваш пиксель, и вы должны будете работать с трафиком всего этого сайта, при этом вы не должны падать, и показатели системы не должны от этого как-то меняться.
Также довольно важно уметь понимать объем определенной аудитории, чтобы потенциальный рекламодатель или кто-то иной мог проработать медиаплан. К примеру, к вам приходит человек и просит узнать, сколько беременных женщин из Новосибирска ищут ипотеку, чтобы оценить, есть смысл на них таргетироваться или нет.
С точки зрения разработки надо уметь классно мониторить все, что у вас происходит в системе, отлаживать какую-то часть реального трафика и так далее.
Одно из самых важных требований к системе – хорошая скорость реакции на события. Чем быстрее системы реагируют на события, тем лучше, это очевидно. Если вы ищете билеты в театр, то, если вы увидите какую-то скидочную акцию спустя день, два дня или даже час – это может быть уже неактуально, так как вы могли уже купить билеты или сходить на спектакль. Когда вы ищете дрель – вы ее ищете, находите, покупаете, вешаете полку, а через пару дней начинается бомбардировка: «Купи дрель!».
Статья в целом про переработку архитектуры. Хотелось бы рассказать, что было нашей отправной точкой, как все работало до изменений.
Все данные, что у нас были, будь это прямой поток данных или логи, складывались на HDFS – распределенное файловое хранилище. Далее был некий процесс, который периодически запускался, брал все необработанные файлы из HDFS и преобразовывал их в запросы на обогащение данных в HBase («PUT запросы»).
Это колоночная Time Series база данных. У нее есть понятие Row Key — это ключ, под которым вы храните свои данные. Мы в качестве ключа используем идентификатор пользователя, user id, который мы генерируем, когда видим юзера в первый раз. Внутри каждого ключа данные разбиты на Column Family – сущности, на уровне которых вы можете управлять мета-информацией ваших данных. Например, вы можете для Column Family «data» хранить тысячу версий записей и хранить их два месяца, а для Column Family «raw»– год, как вариант.
В рамках Column Family существует множество Column Qualifier (далее column). Мы в качестве column используем различные атрибуты пользователя. Это может быть URL, на который он ходил, IP-адрес, поисковый запрос. А самое важное, что внутри каждого column хранится много информации. Внутри column URL может быть указано, что юзер ходил на smartdataconf.ru, затем еще на какие-то сайты. И в качестве версии используется timestamp – вы видите упорядоченную историю визитов пользователя. В нашем случае мы можем определить, что пользователь пришел на сайт smartdataconf по ключевому слову «конференция», потому что timestamp у них совпадает.
Есть несколько вариантов работы с HBase. Это могут быть PUT запросы (запрос на изменение данных), GET-запрос («дай мне все данные по пользователю Вася» и так далее). Вы можете запускать SCAN запросы — многопоточное последовательное сканирование всех данных в HBase. Это мы и использовали раньше для разметки в аудиторные сегменты.
Была задача, которая называлась Analytics Engine, она запускалась раз в день и сканировала HBase в несколько потоков. Для каждого пользователя, она поднимала из HBase всю историю и прогоняла через набор аналитических скриптов.

Что такое аналитический скрипт? Это некоторый черный ящик (java class), который на вход принимает все данные пользователя, а на выход отдает набор сегментов, которые считает подходящими. Мы отдаем скрипту всё, что видим – IP, визиты, UserAgent и пр., а на выходе скрипты выдают: «это женщина, любит котиков, не любит собак».
Эти данные отдавались партнерам, считалась статистика. Нам было важно понимать, сколько вообще женщин, сколько мужчин, сколько людей любит кошек, сколько имеет или не имеет автомобиль и так далее.
Статистику мы хранили в MongoDB и писали путем инкремента определенного счетчика сегмента за каждый день. У нас был график объема каждого сегмента за каждый день.
Эта система была хороша для своего времени. Она позволила горизонтально масштабироваться, расти, позволяла оценивать объем аудитории, но в ней был ряд недостатков.
Не всегда можно было понять, что происходит в системе, посмотреть логи. Пока мы находились у предыдущего хостера, задача довольно часто по разным причинам падала. Там был Hadoop-кластер из 20+ серверов, раз в день стабильно один из серверов вылетал. Это приводило к тому, что задача могла частично упасть и не досчитать данные. Нужно было успеть ее перезапустить, а, учитывая, что она работала несколько часов, был ряд определенных нюансов.
Самое основное, что не выполняла существующая архитектура – было слишком большое время реакции на событие. Есть даже история на эту тему. Была компания, которая выдавала микрокредиты населению в регионах, мы с ними запартнерились. Их клиент приходит на сайт, заполняет заявку на микрокредит, компании необходимо за 15 минут дать ответ: готовы выдать кредит или нет. Если готовы – сразу переводили деньги на карточку.
Все работало вроде как хорошо. Клиент решил проверить, как оно вообще происходит: взяли отдельный ноутбук, установили чистую систему, посетили множество страниц в интернете и зашли на свой сайт. Видят, что идет запрос, а мы в ответ говорим, что данных еще нет. Клиент спрашивает: «А почему нет данных?»
Мы объясняем: есть некий лаг перед тем, как пользователь совершит действие. Данные отправляются в HBase, обрабатываются, и только потом клиент получает результат. Казалось бы, если юзер не увидел рекламу – все в порядке, ничего страшного не случится. Но в этой ситуации пользователю из-за лага могли не дать кредит.
Это не единичный случай, и нужно было переходить на realtime-систему. Что мы от нее хотим?

Мы хотим писать данные в HBase сразу же, как видим их. Увидели визит, обогатили всем, что знаем, и отправили в Storage. Как только данные в Storage изменились – нужно сразу запускать весь набор аналитических скриптов, что у нас есть. Хотим удобства мониторинга и разработки, возможность писать новые скрипты, отлаживать их на части реального трафика. Хотим понимать чем прямо сейчас занята система.
Первое, с чего мы начали – это с решения второй задачи: сегментировать пользователя сразу же после изменения данных о нем в HBase. Изначально у нас worker-ноды (на них запускались map-reduce задачи) находились там же, где HBase. В ряде случаев это было очень даже хорошо – вычисления производятся рядом с данными, задачи работают достаточно быстро, мало трафика идет по сети. Понятно, что задача потребляет какие-то ресурсы, потому что она выполняет сложные аналитические скрипты.
Когда мы переходим на работу в реальном времени, меняется характер нагрузки на HBase. Мы переходим к случайным чтениям вместо последовательных. Важно, чтобы нагрузка на HBase была ожидаемой – мы не можем позволить, чтобы кто-то запустил задачу на Hadoop кластере и испортил этим производительность HBase.
Первое, что мы сделали – вынесли HBase на отдельные сервера. Также подкрутили BlockCache и BloomFilter. Потом хорошо поработали над тем, как храним данные в HBase. Довольно сильно переработали систему, о которой рассказывал вначале, и пожали сами данные.

Из очевидного: мы хранили IP в виде строки, а стали в long числа. Какие-то данные классифицировали, вынесли словарные вещи и так далее. Суть в том, что из-за этого мы смогли пожать HBase примерно в два раза – с 10 ТБ до 5 ТБ. У HBase есть механизм, схожий с триггерами в обычной базе данных. Это механизм coprocessor. Мы написали такой coprocessor, который при изменении пользователя в HBase отправляет идентификатор этого пользователя в Kafka.
Идентификатор пользователя попадает в Kafka. Далее есть некий сервис «сегментатор». Он читает поток пользовательских идентификаторов и прогоняет на них всё те же скрипты, которые были до этого, запрашивая данные из HBase. Процесс запустили на 10% трафика, посмотрели, как оно работает. Все было довольно неплохо.

Далее мы стали увеличивать нагрузку и увидели ряд проблем. Первое, что мы увидели – сервис работает, сегментирует, а затем отваливается от Kafka, подключается и снова начинает работать. Сервисов несколько – они помогают друг другу. Затем отваливается следующий, еще один и так по кругу. При этом очередь пользователей на сегментацию почти не разгребается.
Это было связано с особенностью работы механизма heartbeat в Kafka, тогда это еще была версия 0.8. Heartbeat это когда консьюмеры сообщают брокеру, живые они или нет, в нашем случае сообщает сегментатор. Происходило следующее: мы получали довольно большую пачку данных, отправляли ее на обработку. Какое-то время оно работало, пока работало – heartbeat не отправлялись. Брокеры считали, что консьюмер умер, и выключали его.
Консьюмер дорабатывал до конца, тратя драгоценные CPU, пытался сказать, что пачка данных отработана и можно взять следующую, а ему отказывали, потому что другой забрал то, с чем он работал. Мы это починили сделав свои фоновые heatbeat, потом правда вышла более новая версия Kafka где эту проблему исправили.
Дальше появился вопрос: на какое железо устанавливать наши сегментаторы. Сегментация – это ресурсоемкий процесс (CPU bound). Важно, что сервис не только потребляет много CPU, но еще и нагружает сеть. Сейчас трафик достигает 5 Gbit/sec. Стоял вопрос: куда поставить сервисы, на много маленьких серверов или немного больших.
В тот момент мы уже переехали в servers.com на bare metal. Пообщались с ребятами из servers, они помогли нам, дали возможность протестировать работу нашего решения как на небольшом количестве дорогих серверов, так и на множестве недорогих с мощными CPU. Выбрали подходящий вариант, посчитав удельную стоимость обработки одного события в секунду. К слову, выбор пал на достаточно мощные и при этом крайне приятные по цене Dell R230, запустили – все заработало.
Важно, что после того, как сегментатор разметил пользователя в сегменты, результат его анализа попадает обратно в Kafka, в некий топик Segmentation Result.
Далее мы можем независимо подключиться к этим данным разными потребителями которые не будут друг другу мешать. Это позволяет нам отдавать данные независимо каждому партнеру, будь это какие-то внешние партнеры, внутренние DSP, Google, статистика.
Со статистикой тоже интересный момент: раньше мы могли увеличивать значение счетчиков в MongoDB, сколько пользователей было в определенном сегменте за определенный день. Теперь же этого сделать не получится потому, что каждого пользователя мы теперь анализируем после совершения им события, т.е. несколько раз в день.
Поэтому нам пришлось решать задачу подсчета уникального количества пользователей в потоке. Для этого мы использовали структуру данных HyperLogLog и ее реализацию в Redis. Структура данных – вероятностная. Это значит, что вы можете туда добавлять идентификаторы пользователя, сами идентификаторы храниться не будут, поэтому можно крайне компактно в HyperLogLog хранить миллионы уникальных идентификаторов, и это будет занимать по одному ключу до 12 килобайт.
Вы не сможете получить сами идентификаторы, но сможете узнать размер этого множества. Так как структура данных вероятностная, существует некоторая погрешность. Например, если у вас есть сегмент «любит котиков», делая запрос за размером этого сегмента за определенный день, вы получите 99.2 млн и это будет значить что-то типа «от 99 млн до 100 млн».
Также в HyperLogLog можно получать размер объединения нескольких множеств. Допустим у вас есть два сегмента «любит котиков» и «любит собак». Допустим, первых 100 млн, вторых 1 млн. Можно спросить: «сколько вообще любят животных?» и получите ответ «около 101 млн» с погрешностью в 1%. Было бы интересно посчитать, сколько одновременно любят и котиков, и собак, но сделать это довольно сложно.

С одной стороны, вы можете узнать размер каждого множества, узнать размер объединения, сложить, вычесть одно из другого и получить пересечение. Но из-за того, что размер погрешности может быть больше размера итогового пересечения, итоговый результат может быть вида «от -50 до 50 тысяч».

Мы довольно много поработали над тем, как увеличить производительность при записи данных в Redis. Изначально мы достигли 200 тыс. операций в секунду. Но когда на каждого пользователя приходится более 50 сегментов – запись информации о каждом пользователе – 50 операций. Получается что мы довольно ограничены в пропускной способности и на данном примере не можем писать информацию более чем о 4 тыс. пользователей в секунду, это в разы меньше необходимого нам.
Мы сделали отдельную «хранимую процедуру» в Redis через Lua, загрузили ее туда и стали передавать в нее строку со всем списком сегментов одного пользователя. Процедура внутри нарежет переданную строку на необходимые обновления HyperLogLog-ов и сохранит данные, так мы достигли примерно 1 млн обновлений в секунду.
Немного хардкора: Redis является однопоточным, можно запинить его на одно ядро процессора, а сетевую карту на другое и добиться еще 15% производительности, экономя на переключениях контекста. Помимо этого, важным моментом является также то, что вы не можете просто кластерризировать структуру данных, потому что операции получения мощности объединений множеств некластеризируемы
Вы видите, что Kafka является у нас основным инструментом транспорта в системе.
В ней есть сущность «топик». Это то, куда вы пишете данные, а по сути – очередь. В нашем случае есть несколько очередей. Одна из них – идентификаторы пользователей, которых необходимо сегментировать. Вторая – результаты сегментации.
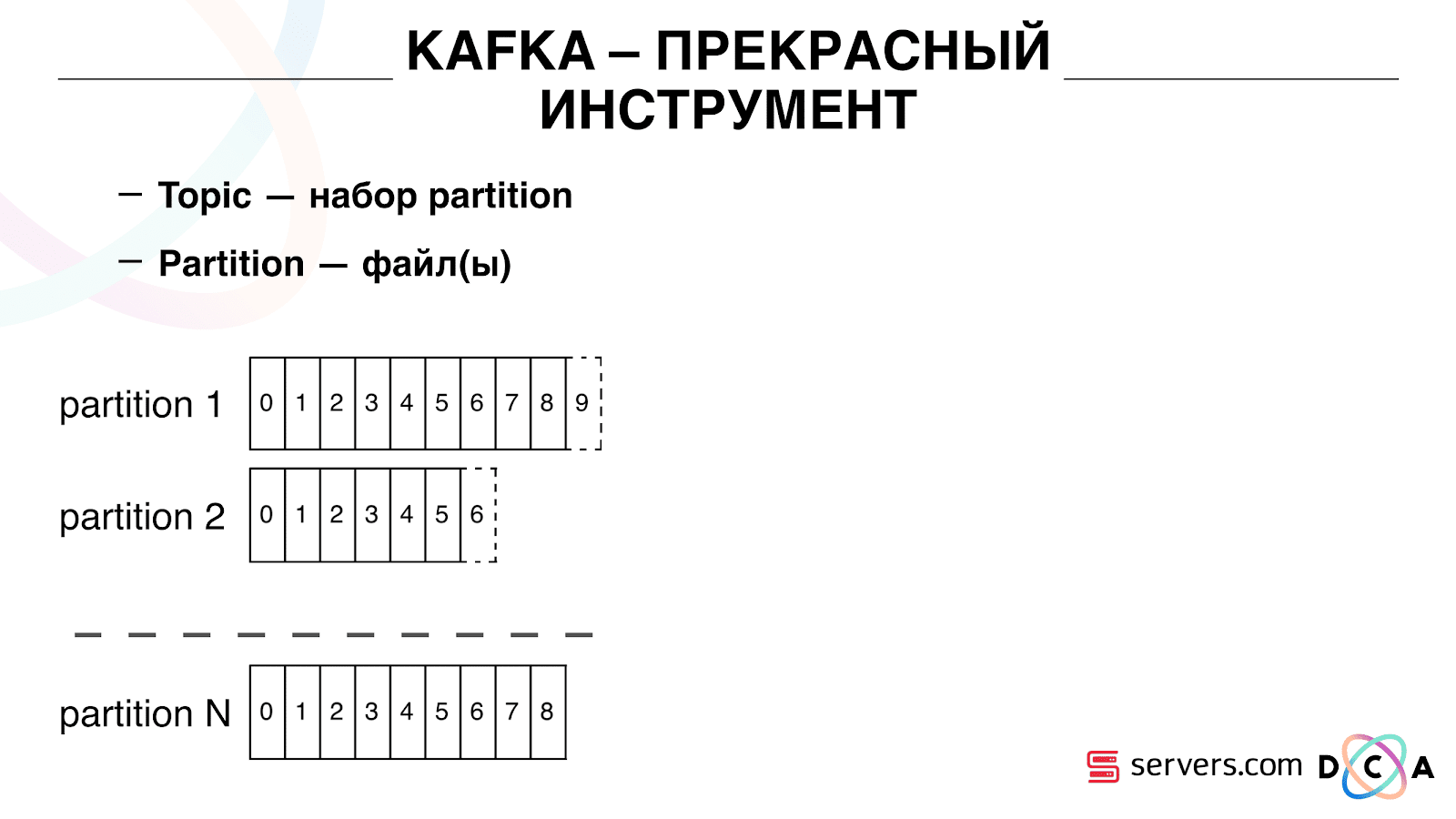
Топик – это набор partition-ов. Он разделен на некоторые кусочки. Каждый partition – файл на жестком диске. Когда ваши продюсеры пишут данные – они пишут кусочки текста в конец partition. Когда ваши консьюмеры читают данные – они просто читают из этих partition.
Важно то, что вы можете подключить независимо несколько групп консьюмеров (consumer group), они будут потреблять данные не мешая друг другу. Это определяется по имени consumer group и достигается следующим образом.
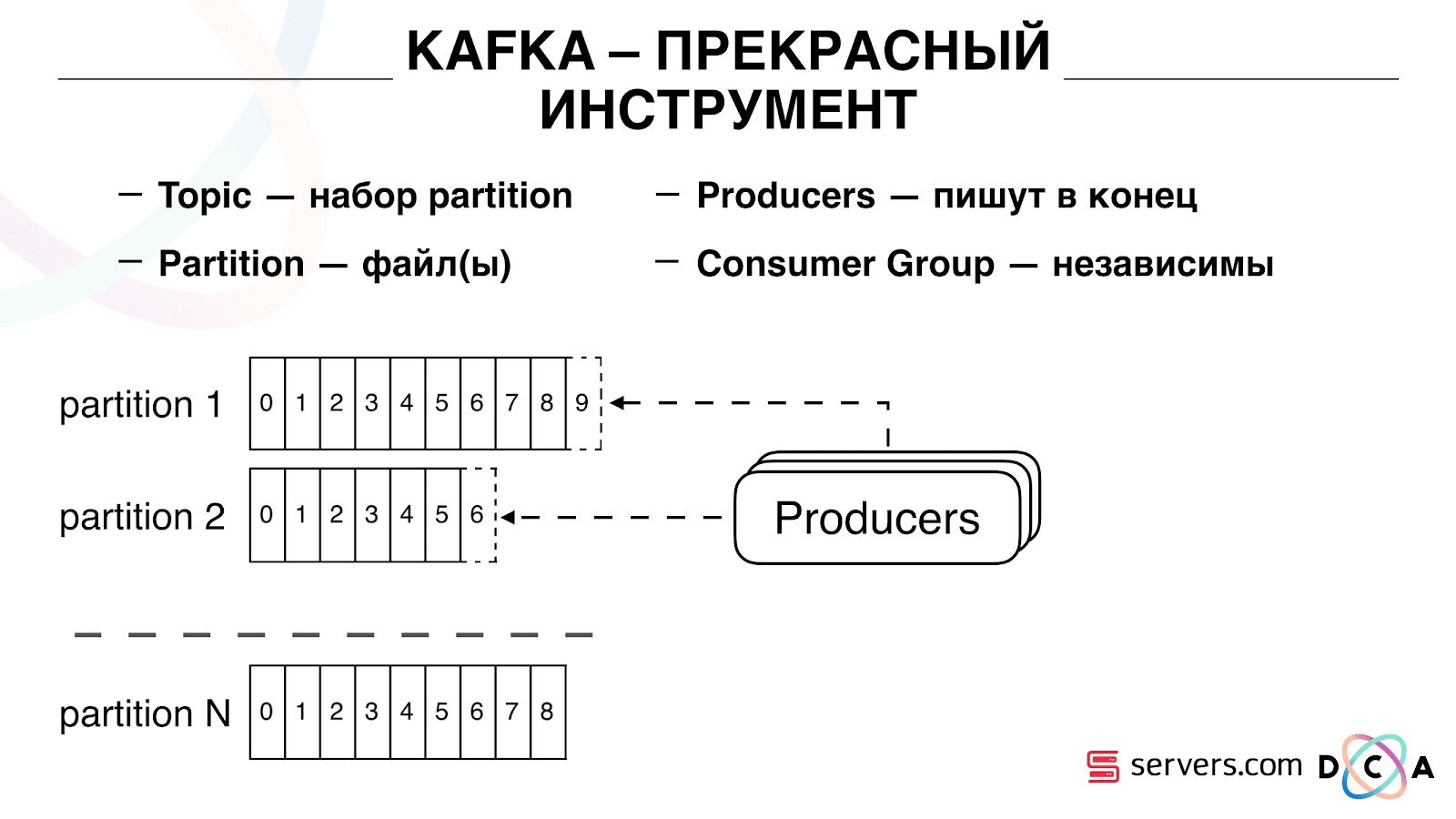
Есть такая вещь, как offset, позиция, где сейчас находятся consumer group на каждом partition. Например, группа А потребляет из partition1 седьмое сообщение, а из partition2 — пятое. Группа Б, независимая от А, имеет другие offset.
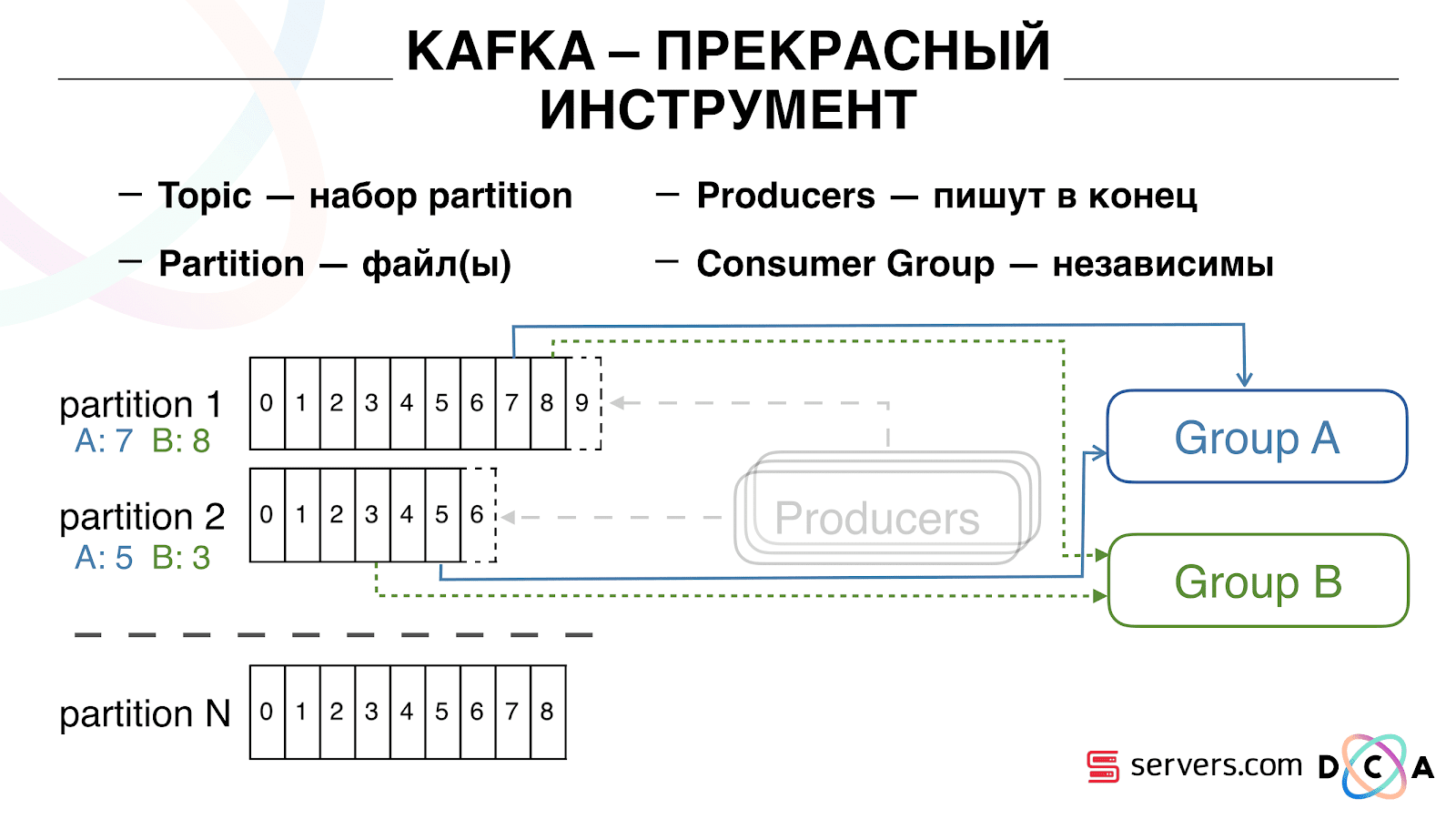
Вы можете горизонтально масштабировать ваши consumer group, добавить еще один процесс или сервер. Произойдет partition reassignment (Kafka broker назначит каждому потребителю список partition на потребление) Это означает, что первая consumer group начнет потреблять только partition 1, а вторая — только partition 2. Если какой то из потребителей умирает (например не приходят hearthbeat) – происходит новый reassignment, каждый потребитель получает актуальный список partition на обработку.

Это довольно удобно. Во-первых, вы можете манипулировать offset для каждой consumer group. Представьте, что есть партнер, которому вы передаете данные из этого топика с результатами сегментации. Он пишет, что случайно в результате бага потерял последний день данных. И вы для consumer group этого клиента просто откатываетесь на день назад и переливаете ему день данных целиком. Также мы можем иметь свою consumer group, подключаться к продакшн-трафику смотреть, что происходит, заниматься отладкой на реальных данных.
Итак, мы добились того, что начали сегментировать пользователей при изменении, мы можем независимо подключать новых consumer-ов, мы пишем статистику и можем ее смотреть. Теперь надо добиться записи данных в HBase сразу же после того, как они к нам пришли.
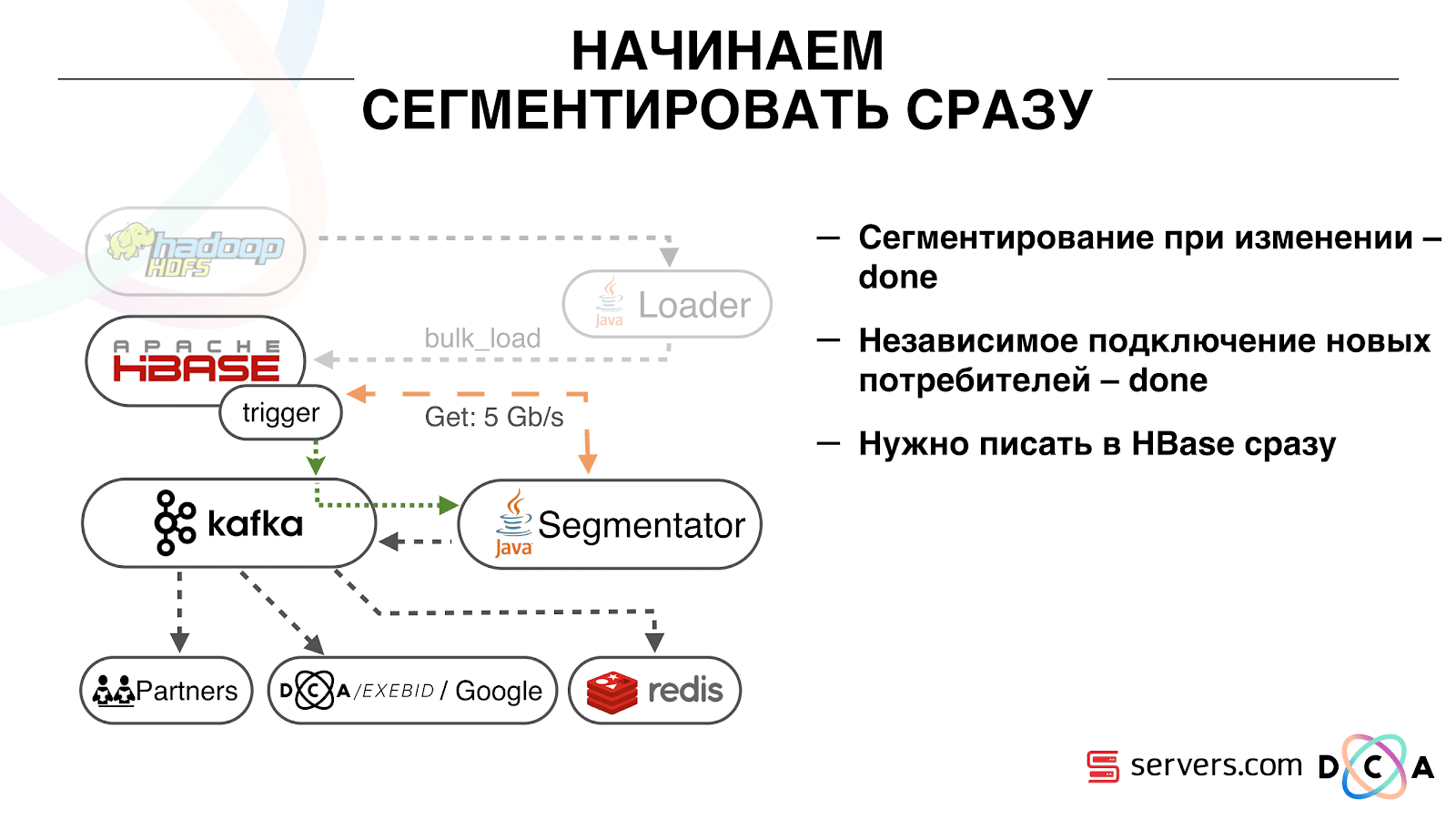
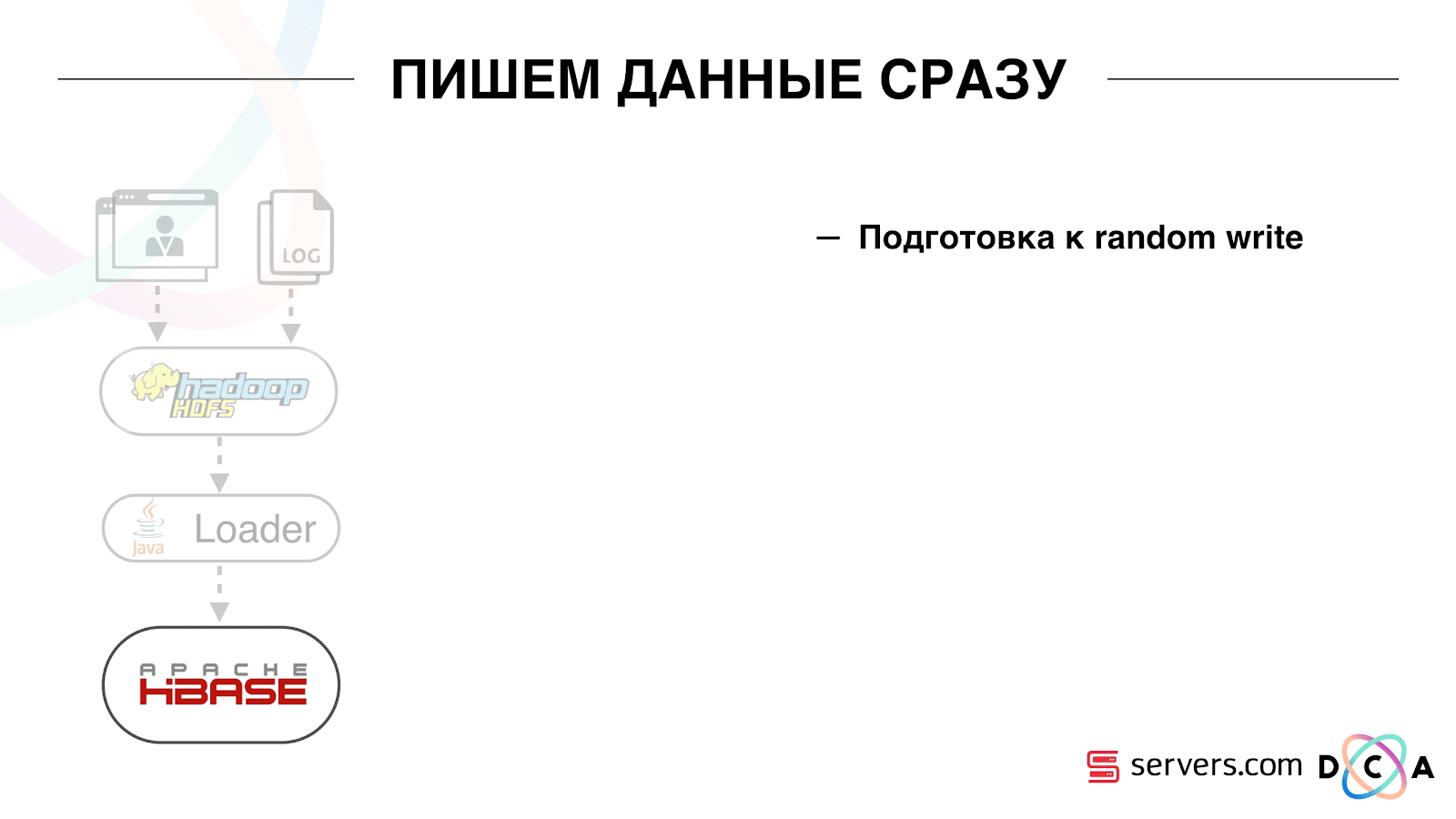
Как мы это делали. Раньше была пакетная загрузка данных. Был Batch Loader, он обрабатывал файлы логов пользовательской активности: если пользователь совершил 10 визитов, приходил batch на 10 событий, его записывали в HBase одной операцией. Приходило лишь одно событие на сегментацию. Теперь мы хотим каждое отдельное событие писать в хранилище. У нас сильно вырастет поток на запись и поток на чтение. Количество событий на сегментацию также увеличится.
Первое, что мы сделали – перенесли HBase на SSD. Стандартными средствами это не особо делается. Это делалось средствами HDFS. Вы можете сказать, что определенная директория на HDFS должна находиться на такой-то группе дисков. Была прикольная проблема с тем, что, когда мы взяли и втупую запинили HBase на SSD, туда же попали и все snapshot-ы, и наши SSD довольно быстро закончились.
Это тоже решается, мы стали периодически экспортировать snapshot-ы в файл, писать в другую директорию HDFS и удалять всю метаинформацией о snapshot-е. Если надо восстановить – берем сохраненный файл, импортируем и восстанавливаемся. Эта операция очень нечастая, к счастью.
Также на SSD вынесли Write Ahead Log, подкрутили MemStore, включили опцию cache block on write. Она позволяет при записи данных сразу класть их и в block cache. Это очень удобно т.к. в нашем случае если мы записали данные, то они с высокой вероятностью будут сразу прочитаны. Это тоже дало некоторые плюсы.
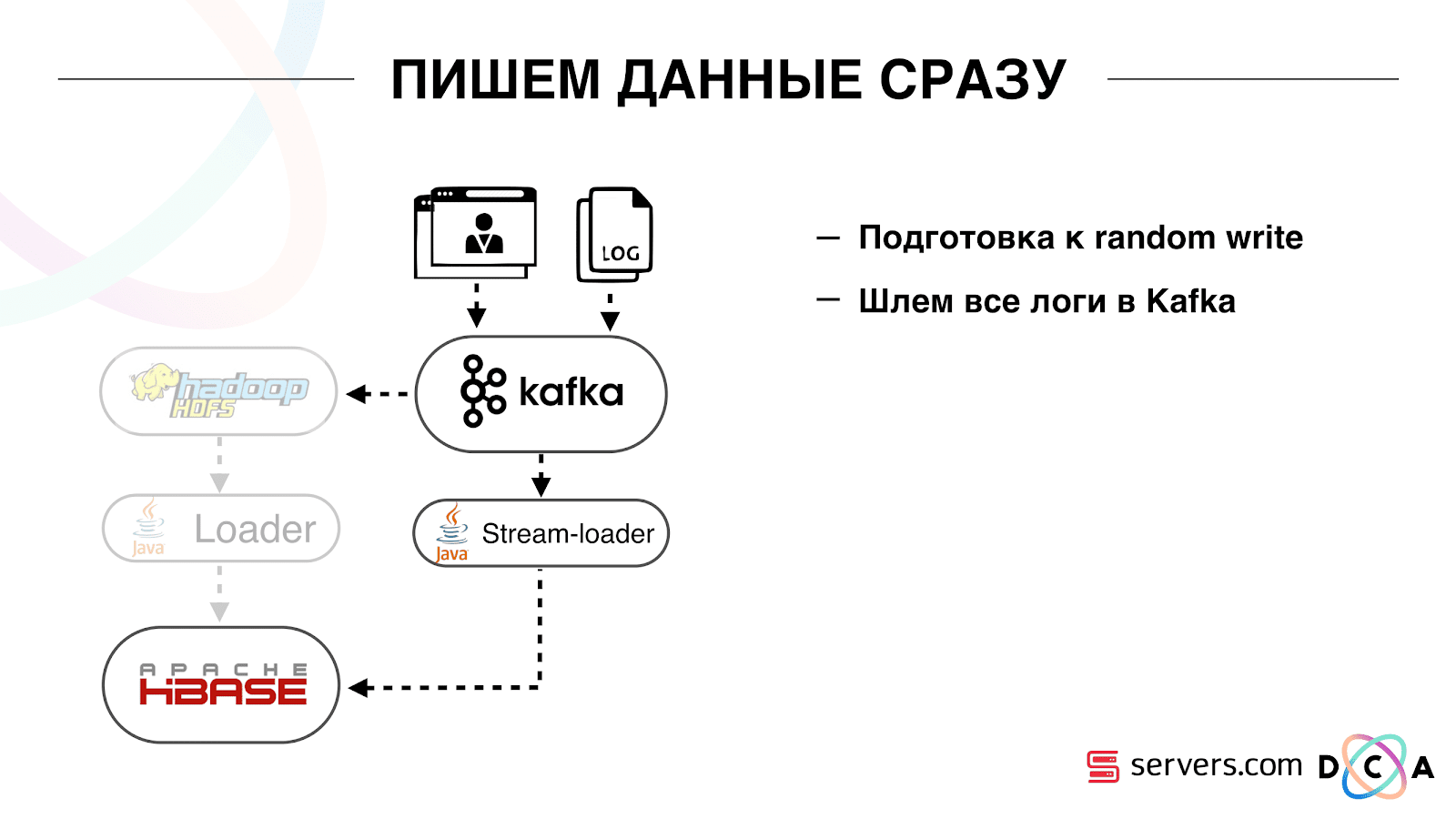
Далее мы переключили все наши источники данных на запись данных в Kafka. Уже из Kafka записывали данные в HDFS для сохранения обратной совместимости, в том числе, чтобы наши аналитики могли работать с данными, запускать MapReduce задачи и анализировать их результаты.
Мы подключили отдельную consumer group, которая пишет данные в HBase. Это, по факту, wrapper, который читает из Kafka и формирует PUT-ы в HBase.
Запустили параллельно две схемы для того, чтобы не ломать обратную совместимость и не ухудшить характеристик системы. Новую схему запустили только на определенном проценте трафика. На 10% всё было довольно здорово. Но на большей нагрузке сегментаторы не справлялись с потоком на сегментацию.

Мы собираем метрику «сколько сообщений пролежало в Kafka до того, как было оттуда прочитано». Это хорошая метрика. Изначально мы собирали метрику «сколько сейчас необработанных сообщений», но она ни о чем особо не говорит. Вы смотрите: «у меня миллион необработанных сообщений», и что? Чтобы интерпретировать этот миллион, нужно знать, с какой скоростью работает сегментатор (потребитель), что не всегда наглядно.
С этой метрикой вы сразу видите, что данные пишутся в очередь, забираются из нее и видите сколько они ожидают своей обработки. Мы увидели, что не успеваем сегментировать, и сообщение лежит в очереди несколько часов до его прочтения.
Можно было просто добавить мощностей, но этого было бы слишкомдорого просто. Поэтому попробовали оптимизировать.
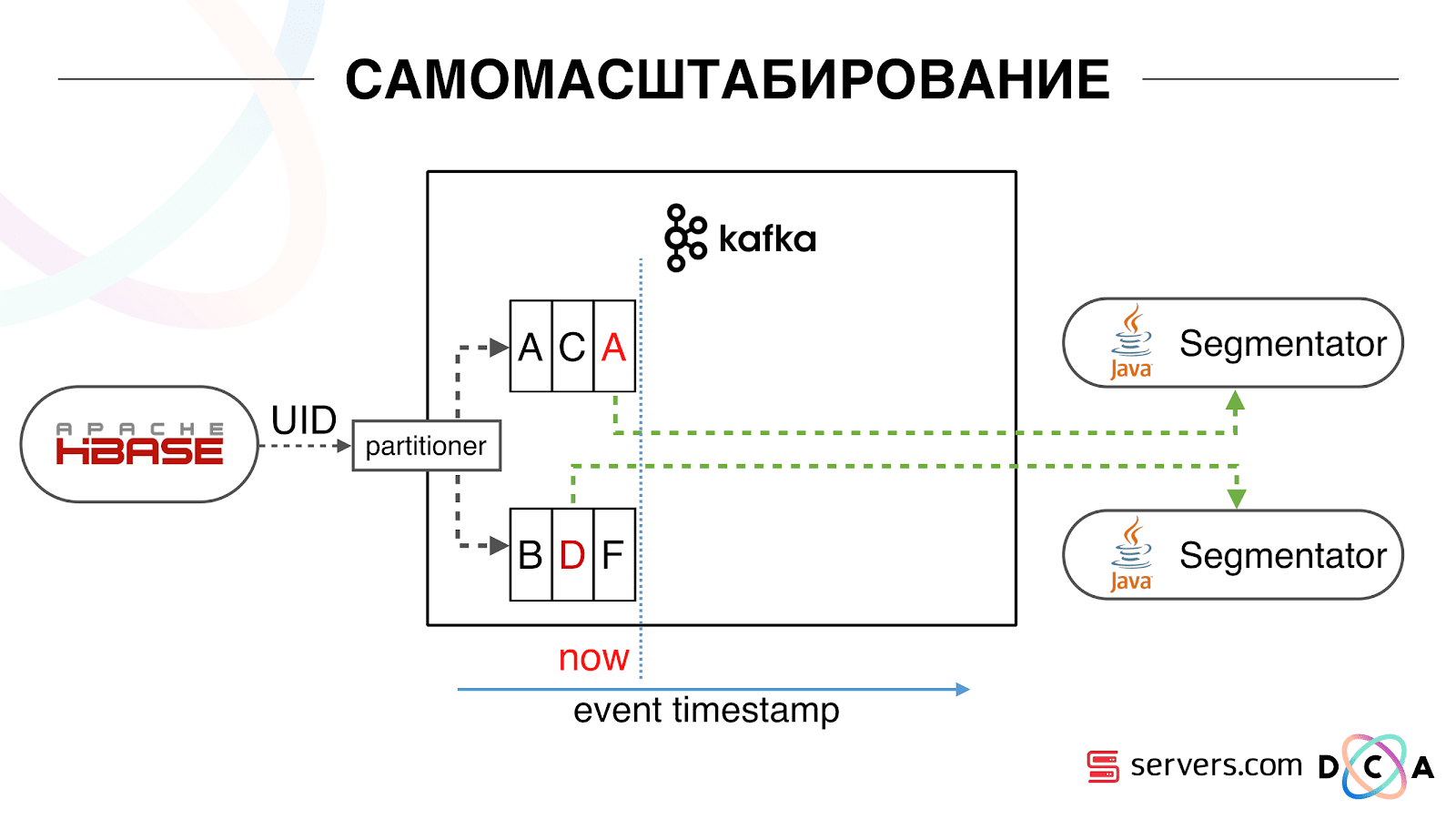
У нас есть HBase. Меняется пользователь, его идентификатор летит в Kafka. Топик разбит на partition-ы, целевой partition выбирается по идентификатору пользователя. Это значит, что когда вы видите пользователя «Вася» — он отправляется в partition 1. Когда видите «Петю» — в partition 2. Это удобно – вы можете добиться того, что будете видеть одного потребителя на одном инстансе вашего сервиса, а второго – на другом.
Мы стали смотреть, что происходит. Одно типичное поведение пользователя в интернете – зайти на какой-то сайт и открыть несколько фоновых вкладок. Второе – зайти на сайт и сделать несколько кликов, чтобы добраться до целевой страницы.
Смотрим в очередь на сегментацию и видим следующее: пользователь А посетил страницу. Приходит еще 5 событий от этого пользователя – каждое обозначает открытие страницы. Мы обрабатываем каждое событие от пользователя. Но на самом деле данные в HBase содержат все 5 визитов. Мы первый раз обрабатываем все 5 визитов, второй раз и так далее – впустую тратим ресурсы CPU.
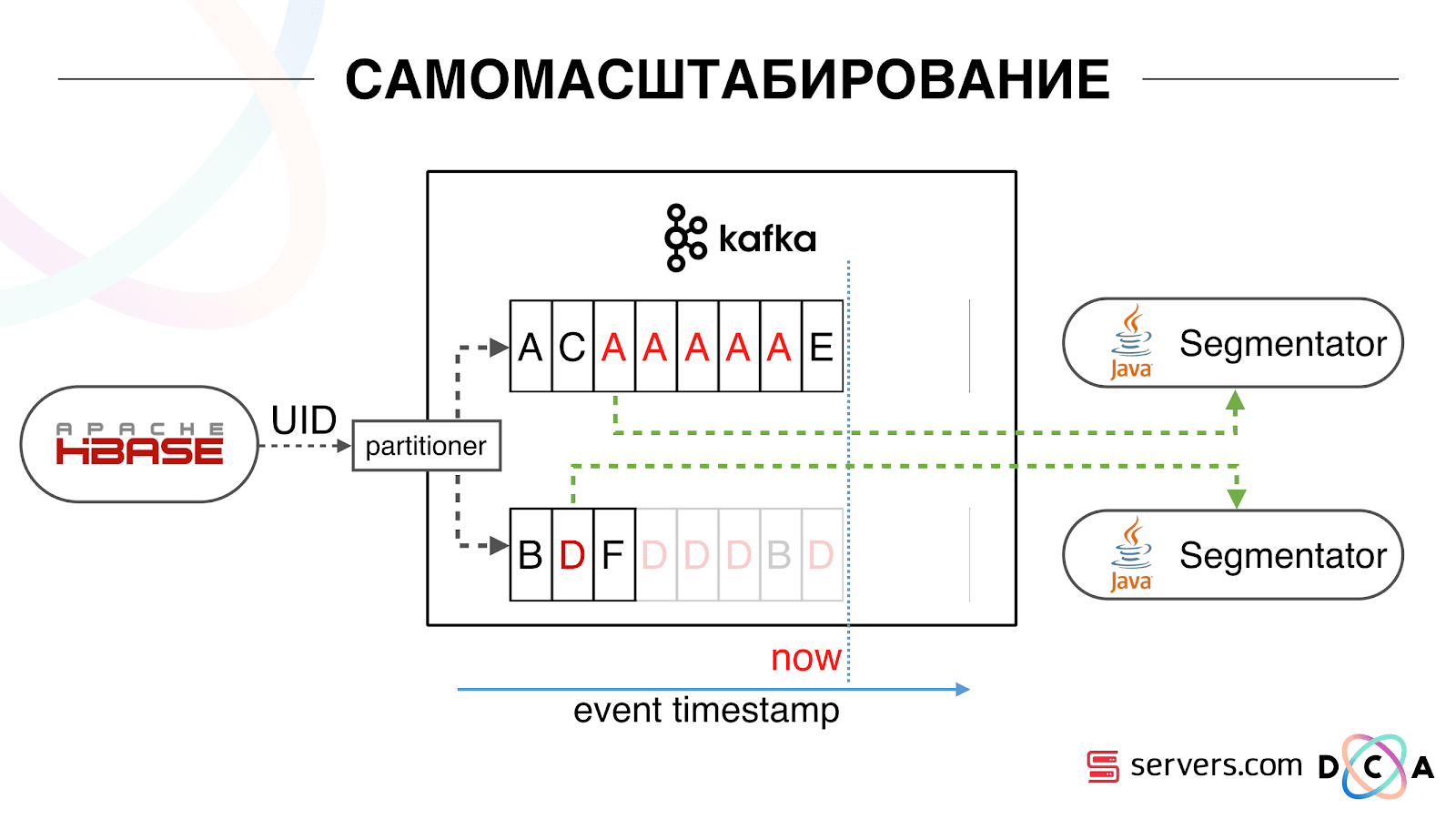
Поэтому мы стали хранить некий локальный кэш на каждом из сегментаторов с датой, когда в последний раз мы проводили анализ этого пользователя. То есть мы его обрабатывали, записали в кэш его userid и timestamp. У каждого сообщения kafka так же есть timestamp – мы просто сравниваем его: если timestamp в очереди меньше даты последней сегментации – пользователя по этими данными мы уже проанализировали, и это событие можно просто пропустить.
События пользователя (Красные А) могут быть разными, и идут они не по порядку. Пользователь может открыть несколько фоновых вкладок, открыть несколько ссылок подряд, возможно на сайте есть сразу несколько наших партнеров, каждый из которых присылает эти данные.
Наш пиксель может увидеть визит пользователя, а затем еще какое-то действие — мы его шлем сами себе. Приходит пять событий, мы обрабатываем первую красную А. Если событие пришло, значит оно уже в HBase. Мы видим события, прогоняем через набор скриптов. Видим следующие событие, а там всё те же события, потому что они уже записаны. Прогоняем еще раз и сохраняем кэш с датой, сравниваем её с timestamp события.

Благодаря этому система получила свойство самомасштабируемости. По оси У – процентное соотношение того, что мы делаем с идентификаторами пользователя, когда они к нам приходят. Зеленое – работа, которую мы выполнили, запустили скрипт сегментации. Желтое – мы не стали этого делать, т.к. уже сегментировали ровно эти данные.
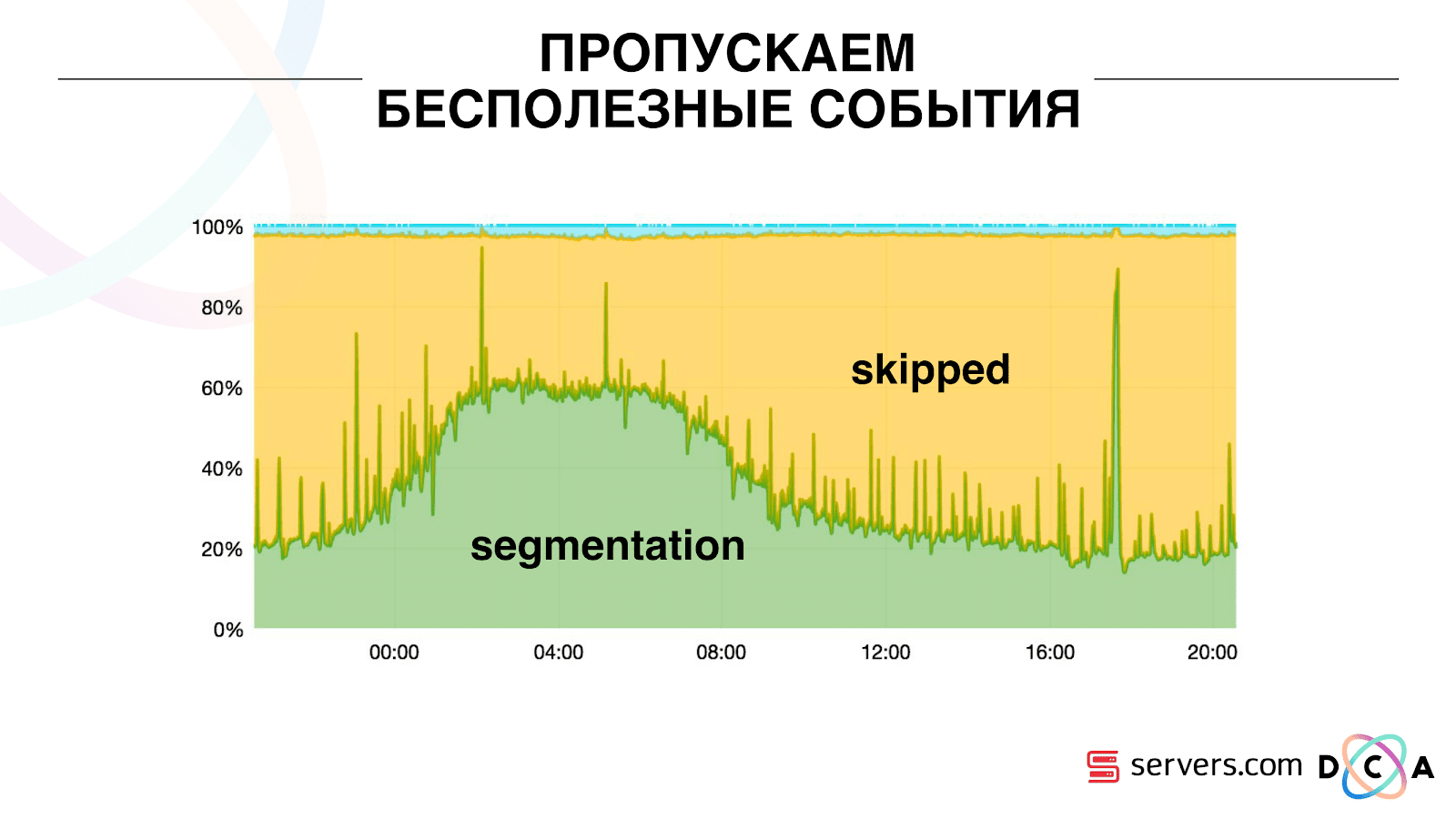
Видно, что ночью ресурсы есть, идет меньший поток данных, и можно сегментировать каждый второй ивент. Днем ресурсов поменьше, и мы сегментируем только 20% событий. Скачок в конце дня – партнер подлил файлы данных, которые мы раньше не видели, и их пришлось «честно» сегментировать.
Система сама адаптируется к росту нагрузки. Если у нас появляется очень крупный партнер – мы обрабатываем те же данные но чуть реже. В таком случае характеристики системы вечером немного ухудшатся, сегментация будет с задержкой не 2-3 секунды, а минуту. Утром добавим серверов и вернемся к нужным результатам.
Таким образом мы сэкономили примерно в 5 раз на серверах. Сейчас мы работаем на 10 серверах, а так потребовалось бы 50-60.
Синенькая штука сверху – боты. Это самая тяжелая часть сегментации. У них огромное число визитов, они создают очень большую нагрузку на железо. Каждого бота мы видим на отдельном сервере. Мы можем на нем собирать локальный кэш с черным списком ботов. Ввели простой антифрод: если юзер совершает слишком много визитов за определенное время, то с ним что-то не так, добавляем в блэклист на какое-то время. Это синенькая полосочка, где-то 5%. Они дали нам еще 30% экономии на CPU.
Таким образом мы добились того, что видим весь pipeline обработки данных на каждом этапе. Мы видим метрики, сколько сообщение пролежало в Kafka. Вечером где-то что-то затупило, время обработки увеличилось до минуты, потом отпустило и пришло в норму.

Мы можем мониторить, как наши действия с системой влияют на ее пропускную способность, можем видеть, сколько выполняется скрипт, где необходимо провести оптимизацию, на чем можно сэкономить. Можем видеть размеры сегментов, динамику размера сегментов, оценивать их объединение и пересечение. Это можно делать для более-менее одинаковых размеров сегментов.
У нас есть Hadoop-кластер с некоторыми вычислительными ресурсами. Он занят – на нем днем работают аналитики, но ночью он практически свободен. В целом, мы можем сегментатор контейнеризировать и запускать как отдельный процесс в рамках нашего кластера. Мы хотим более точно хранить статистику, чтобы точнее расчитывать объем пересечени. Еще нужна оптимизация на CPU т.к. это напрямую влияет на стоимость решения.
Подводя итоги: Kafka хороша, но, как и с любой другой технологией, нужно понимать, как она работает внутри и что с ней происходит. Например, гарантия на очередность сообщения работает только внутри partition. Если вы отправляете сообщение, которое пойдет в разные партиции, то непонятно, в какой последовательности они будут обработаны.
Очень важны реальные данные. Если бы мы не тестировались на реальном трафике, то, скорее всего, не увидели бы проблем с ботами, с сессиями пользователей. Разработали бы что-то в вакууме, запустили и прилегли. Важно мониторить то, что считаете нужным мониторить, и не мониторить то, что не считаете.
В основе материала — расшифровка доклада Артема Маринова, специалиста по большим данным в компании Directual, c конференции SmartData 2017.
Меня зовут Артём Маринов, я хочу рассказать о том, как мы перерабатывали архитектуру проекта FACETz DMP, когда я работал в компании Data Centric Alliance. Почему мы это делали, к чему это привело, по какому пути мы шли и с какими проблемами столкнулись.
DMP (Data Management Platform) – платформа по сбору, обработке и агрегации пользовательских данных. Данные – это очень много разных вещей. Платформа насчитывает порядка 600 миллионов пользователей. Это миллионы cookie, которые ходят по интернету и совершают различные события. В целом, день в среднем выглядит примерно вот так: мы видим порядка 5,5 млрд событий в сутки, они как-то размазаны по дню, а в пике достигают порядка 100 тысяч событий в секунду.
События – это различные пользовательские сигналы. К примеру, визит на сайт: мы видим, с какого браузера ходит пользователь, его useragent и всё, что мы можем извлечь. Иногда мы видим, как и по каким поисковым запросам он пришел на сайт. Это также могут быть различные данные из офлайн-мира, например, что он оплачивает скидочными купонами и так далее.Нам эти данные надо сохранить и разметить пользователя в так называемые группы аудиторных сегментов. Например, сегментами могут быть «женщина», которая «любит котиков» и ищет «автосервис», у нее «есть автомобиль старше трех лет».
Зачем сегментировать пользователя? Применений этому множество, например, реклама. Различные рекламные сети могут оптимизировать алгоритмы показа рекламы. Если вы рекламируете свой автосервис, то сможете настроить кампанию таким образом, чтобы показывать информацию только людям, у которых есть старый автомобиль, исключив владельцев новых. Вы можете динамически менять контент сайта, можете использовать данные для скоринга – применений множество.
Данные получаются из множества абсолютно разных мест. Это могут быть прямые установки пикселя – это в том случае, если клиент хочет анализировать свою аудиторию, он ставит пиксель на сайт, невидимую картинку, которая подгружается с нашего сервера. Суть в том, что мы видим визит пользователя на этот сайт: его можно сохранить, начать анализировать и понять портрет пользователя, вся эта информация доступна нашему клиенту.
Данные могут быть получены от различных партнеров, которые видят много данных и хотят их монетизировать различными способами. Партнеры могут поставлять данные как в реальном времени, так и делать периодические выгрузки в виде файлов.
Ключевые требования:
- Горизонтальная масштабируемость;
- Оценка объема аудитории;
- Удобство мониторинга и разработки;
- Хорошая скорость реакции на события.
Одно из ключевых требований системы – горизонтальная масштабируемость. Тут есть такой момент, что когда вы разрабатываете портал или интернет-магазин, то можете оценить количество ваших пользователей (как оно будет расти, как будет меняться) и примерно понять, сколько нужно ресурсов, и как магазин будет жить и развиваться со временем.
Когда вы разрабатываете платформу, подобную DMP, нужно быть готовыми к тому, что любой крупный сайт – условный Amazon, — может поставить к себе ваш пиксель, и вы должны будете работать с трафиком всего этого сайта, при этом вы не должны падать, и показатели системы не должны от этого как-то меняться.
Также довольно важно уметь понимать объем определенной аудитории, чтобы потенциальный рекламодатель или кто-то иной мог проработать медиаплан. К примеру, к вам приходит человек и просит узнать, сколько беременных женщин из Новосибирска ищут ипотеку, чтобы оценить, есть смысл на них таргетироваться или нет.
С точки зрения разработки надо уметь классно мониторить все, что у вас происходит в системе, отлаживать какую-то часть реального трафика и так далее.
Одно из самых важных требований к системе – хорошая скорость реакции на события. Чем быстрее системы реагируют на события, тем лучше, это очевидно. Если вы ищете билеты в театр, то, если вы увидите какую-то скидочную акцию спустя день, два дня или даже час – это может быть уже неактуально, так как вы могли уже купить билеты или сходить на спектакль. Когда вы ищете дрель – вы ее ищете, находите, покупаете, вешаете полку, а через пару дней начинается бомбардировка: «Купи дрель!».
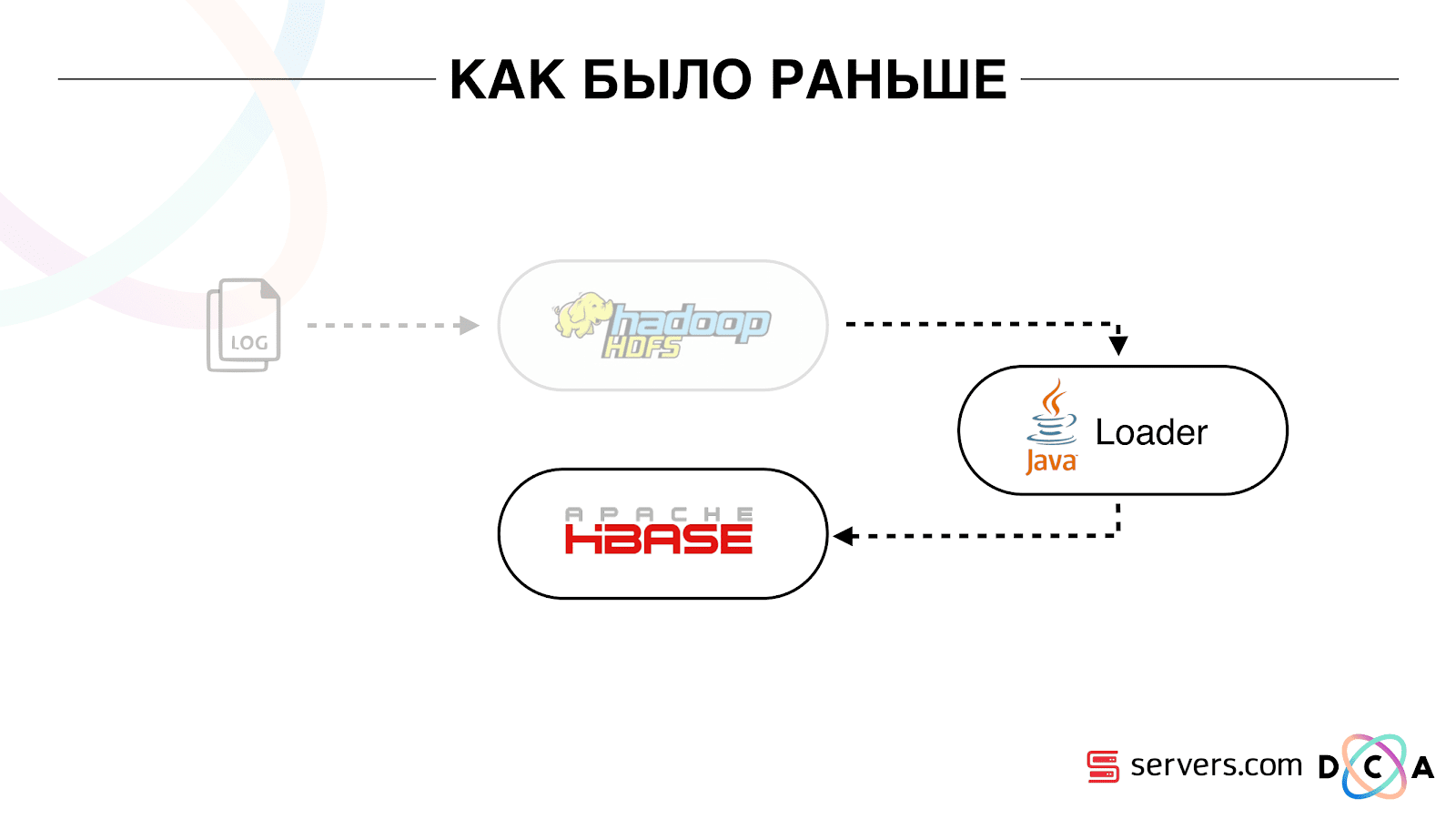
Как было раньше
Статья в целом про переработку архитектуры. Хотелось бы рассказать, что было нашей отправной точкой, как все работало до изменений.
Все данные, что у нас были, будь это прямой поток данных или логи, складывались на HDFS – распределенное файловое хранилище. Далее был некий процесс, который периодически запускался, брал все необработанные файлы из HDFS и преобразовывал их в запросы на обогащение данных в HBase («PUT запросы»).
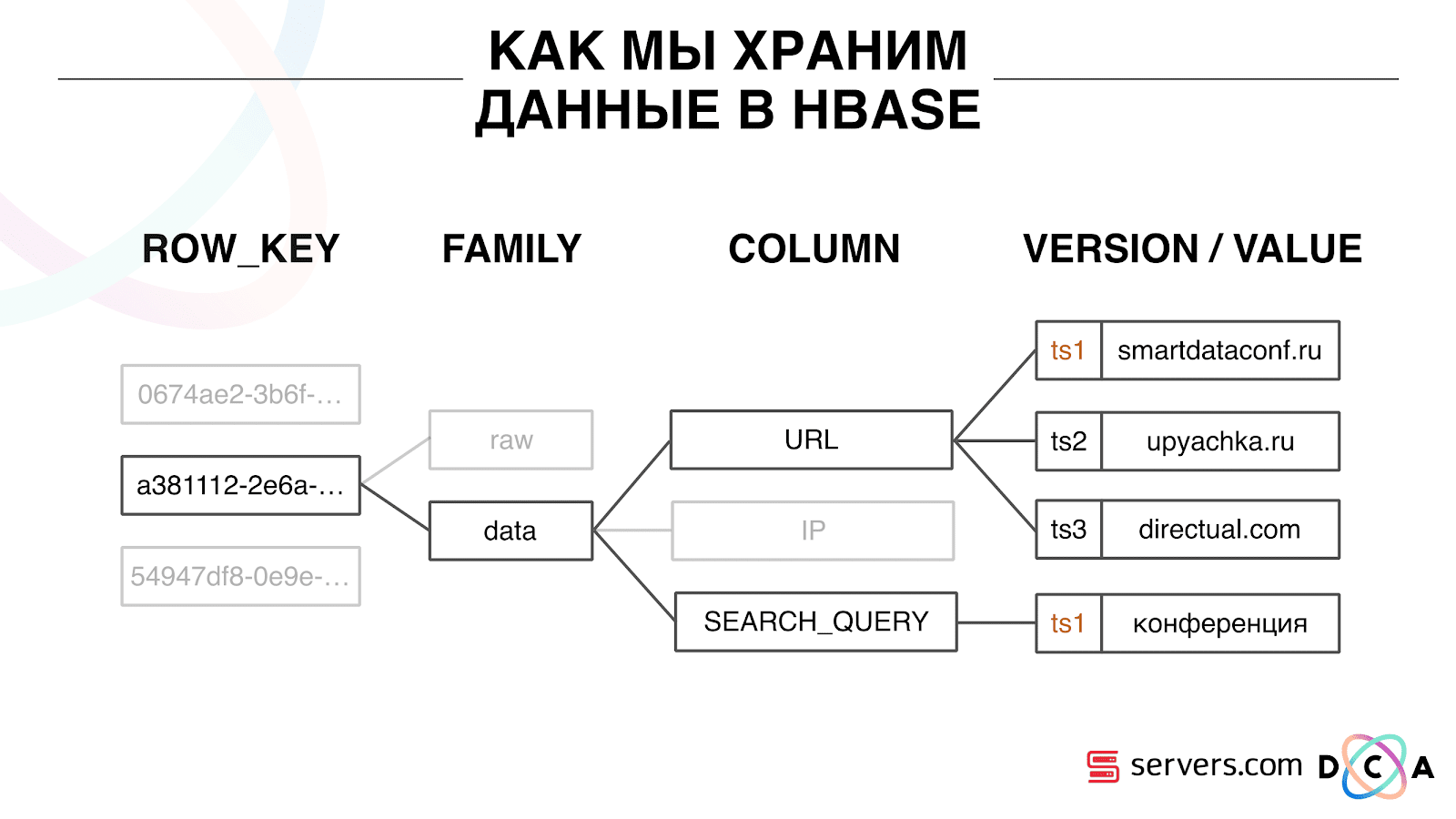
Как мы храним данные в HBase
Это колоночная Time Series база данных. У нее есть понятие Row Key — это ключ, под которым вы храните свои данные. Мы в качестве ключа используем идентификатор пользователя, user id, который мы генерируем, когда видим юзера в первый раз. Внутри каждого ключа данные разбиты на Column Family – сущности, на уровне которых вы можете управлять мета-информацией ваших данных. Например, вы можете для Column Family «data» хранить тысячу версий записей и хранить их два месяца, а для Column Family «raw»– год, как вариант.
В рамках Column Family существует множество Column Qualifier (далее column). Мы в качестве column используем различные атрибуты пользователя. Это может быть URL, на который он ходил, IP-адрес, поисковый запрос. А самое важное, что внутри каждого column хранится много информации. Внутри column URL может быть указано, что юзер ходил на smartdataconf.ru, затем еще на какие-то сайты. И в качестве версии используется timestamp – вы видите упорядоченную историю визитов пользователя. В нашем случае мы можем определить, что пользователь пришел на сайт smartdataconf по ключевому слову «конференция», потому что timestamp у них совпадает.
Работа с HBase
Есть несколько вариантов работы с HBase. Это могут быть PUT запросы (запрос на изменение данных), GET-запрос («дай мне все данные по пользователю Вася» и так далее). Вы можете запускать SCAN запросы — многопоточное последовательное сканирование всех данных в HBase. Это мы и использовали раньше для разметки в аудиторные сегменты.
Была задача, которая называлась Analytics Engine, она запускалась раз в день и сканировала HBase в несколько потоков. Для каждого пользователя, она поднимала из HBase всю историю и прогоняла через набор аналитических скриптов.
Что такое аналитический скрипт? Это некоторый черный ящик (java class), который на вход принимает все данные пользователя, а на выход отдает набор сегментов, которые считает подходящими. Мы отдаем скрипту всё, что видим – IP, визиты, UserAgent и пр., а на выходе скрипты выдают: «это женщина, любит котиков, не любит собак».
Эти данные отдавались партнерам, считалась статистика. Нам было важно понимать, сколько вообще женщин, сколько мужчин, сколько людей любит кошек, сколько имеет или не имеет автомобиль и так далее.
Статистику мы хранили в MongoDB и писали путем инкремента определенного счетчика сегмента за каждый день. У нас был график объема каждого сегмента за каждый день.
Эта система была хороша для своего времени. Она позволила горизонтально масштабироваться, расти, позволяла оценивать объем аудитории, но в ней был ряд недостатков.
Не всегда можно было понять, что происходит в системе, посмотреть логи. Пока мы находились у предыдущего хостера, задача довольно часто по разным причинам падала. Там был Hadoop-кластер из 20+ серверов, раз в день стабильно один из серверов вылетал. Это приводило к тому, что задача могла частично упасть и не досчитать данные. Нужно было успеть ее перезапустить, а, учитывая, что она работала несколько часов, был ряд определенных нюансов.
Самое основное, что не выполняла существующая архитектура – было слишком большое время реакции на событие. Есть даже история на эту тему. Была компания, которая выдавала микрокредиты населению в регионах, мы с ними запартнерились. Их клиент приходит на сайт, заполняет заявку на микрокредит, компании необходимо за 15 минут дать ответ: готовы выдать кредит или нет. Если готовы – сразу переводили деньги на карточку.
Все работало вроде как хорошо. Клиент решил проверить, как оно вообще происходит: взяли отдельный ноутбук, установили чистую систему, посетили множество страниц в интернете и зашли на свой сайт. Видят, что идет запрос, а мы в ответ говорим, что данных еще нет. Клиент спрашивает: «А почему нет данных?»
Мы объясняем: есть некий лаг перед тем, как пользователь совершит действие. Данные отправляются в HBase, обрабатываются, и только потом клиент получает результат. Казалось бы, если юзер не увидел рекламу – все в порядке, ничего страшного не случится. Но в этой ситуации пользователю из-за лага могли не дать кредит.
Это не единичный случай, и нужно было переходить на realtime-систему. Что мы от нее хотим?
Мы хотим писать данные в HBase сразу же, как видим их. Увидели визит, обогатили всем, что знаем, и отправили в Storage. Как только данные в Storage изменились – нужно сразу запускать весь набор аналитических скриптов, что у нас есть. Хотим удобства мониторинга и разработки, возможность писать новые скрипты, отлаживать их на части реального трафика. Хотим понимать чем прямо сейчас занята система.
Первое, с чего мы начали – это с решения второй задачи: сегментировать пользователя сразу же после изменения данных о нем в HBase. Изначально у нас worker-ноды (на них запускались map-reduce задачи) находились там же, где HBase. В ряде случаев это было очень даже хорошо – вычисления производятся рядом с данными, задачи работают достаточно быстро, мало трафика идет по сети. Понятно, что задача потребляет какие-то ресурсы, потому что она выполняет сложные аналитические скрипты.
Когда мы переходим на работу в реальном времени, меняется характер нагрузки на HBase. Мы переходим к случайным чтениям вместо последовательных. Важно, чтобы нагрузка на HBase была ожидаемой – мы не можем позволить, чтобы кто-то запустил задачу на Hadoop кластере и испортил этим производительность HBase.
Первое, что мы сделали – вынесли HBase на отдельные сервера. Также подкрутили BlockCache и BloomFilter. Потом хорошо поработали над тем, как храним данные в HBase. Довольно сильно переработали систему, о которой рассказывал вначале, и пожали сами данные.
Из очевидного: мы хранили IP в виде строки, а стали в long числа. Какие-то данные классифицировали, вынесли словарные вещи и так далее. Суть в том, что из-за этого мы смогли пожать HBase примерно в два раза – с 10 ТБ до 5 ТБ. У HBase есть механизм, схожий с триггерами в обычной базе данных. Это механизм coprocessor. Мы написали такой coprocessor, который при изменении пользователя в HBase отправляет идентификатор этого пользователя в Kafka.
Идентификатор пользователя попадает в Kafka. Далее есть некий сервис «сегментатор». Он читает поток пользовательских идентификаторов и прогоняет на них всё те же скрипты, которые были до этого, запрашивая данные из HBase. Процесс запустили на 10% трафика, посмотрели, как оно работает. Все было довольно неплохо.
Далее мы стали увеличивать нагрузку и увидели ряд проблем. Первое, что мы увидели – сервис работает, сегментирует, а затем отваливается от Kafka, подключается и снова начинает работать. Сервисов несколько – они помогают друг другу. Затем отваливается следующий, еще один и так по кругу. При этом очередь пользователей на сегментацию почти не разгребается.
Это было связано с особенностью работы механизма heartbeat в Kafka, тогда это еще была версия 0.8. Heartbeat это когда консьюмеры сообщают брокеру, живые они или нет, в нашем случае сообщает сегментатор. Происходило следующее: мы получали довольно большую пачку данных, отправляли ее на обработку. Какое-то время оно работало, пока работало – heartbeat не отправлялись. Брокеры считали, что консьюмер умер, и выключали его.
Консьюмер дорабатывал до конца, тратя драгоценные CPU, пытался сказать, что пачка данных отработана и можно взять следующую, а ему отказывали, потому что другой забрал то, с чем он работал. Мы это починили сделав свои фоновые heatbeat, потом правда вышла более новая версия Kafka где эту проблему исправили.
Дальше появился вопрос: на какое железо устанавливать наши сегментаторы. Сегментация – это ресурсоемкий процесс (CPU bound). Важно, что сервис не только потребляет много CPU, но еще и нагружает сеть. Сейчас трафик достигает 5 Gbit/sec. Стоял вопрос: куда поставить сервисы, на много маленьких серверов или немного больших.
В тот момент мы уже переехали в servers.com на bare metal. Пообщались с ребятами из servers, они помогли нам, дали возможность протестировать работу нашего решения как на небольшом количестве дорогих серверов, так и на множестве недорогих с мощными CPU. Выбрали подходящий вариант, посчитав удельную стоимость обработки одного события в секунду. К слову, выбор пал на достаточно мощные и при этом крайне приятные по цене Dell R230, запустили – все заработало.
Важно, что после того, как сегментатор разметил пользователя в сегменты, результат его анализа попадает обратно в Kafka, в некий топик Segmentation Result.
Далее мы можем независимо подключиться к этим данным разными потребителями которые не будут друг другу мешать. Это позволяет нам отдавать данные независимо каждому партнеру, будь это какие-то внешние партнеры, внутренние DSP, Google, статистика.
Со статистикой тоже интересный момент: раньше мы могли увеличивать значение счетчиков в MongoDB, сколько пользователей было в определенном сегменте за определенный день. Теперь же этого сделать не получится потому, что каждого пользователя мы теперь анализируем после совершения им события, т.е. несколько раз в день.
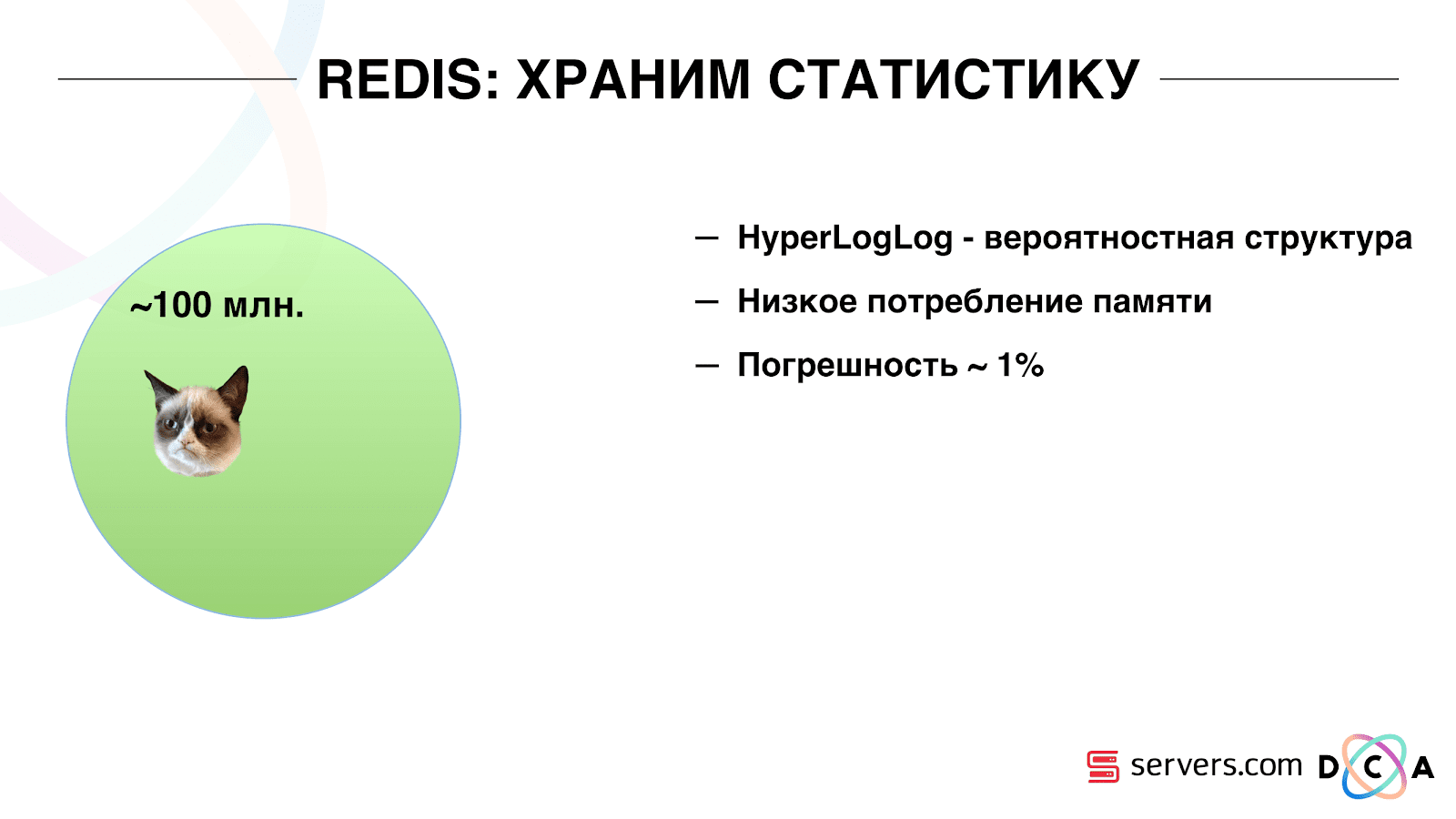
Поэтому нам пришлось решать задачу подсчета уникального количества пользователей в потоке. Для этого мы использовали структуру данных HyperLogLog и ее реализацию в Redis. Структура данных – вероятностная. Это значит, что вы можете туда добавлять идентификаторы пользователя, сами идентификаторы храниться не будут, поэтому можно крайне компактно в HyperLogLog хранить миллионы уникальных идентификаторов, и это будет занимать по одному ключу до 12 килобайт.
Вы не сможете получить сами идентификаторы, но сможете узнать размер этого множества. Так как структура данных вероятностная, существует некоторая погрешность. Например, если у вас есть сегмент «любит котиков», делая запрос за размером этого сегмента за определенный день, вы получите 99.2 млн и это будет значить что-то типа «от 99 млн до 100 млн».
Также в HyperLogLog можно получать размер объединения нескольких множеств. Допустим у вас есть два сегмента «любит котиков» и «любит собак». Допустим, первых 100 млн, вторых 1 млн. Можно спросить: «сколько вообще любят животных?» и получите ответ «около 101 млн» с погрешностью в 1%. Было бы интересно посчитать, сколько одновременно любят и котиков, и собак, но сделать это довольно сложно.
С одной стороны, вы можете узнать размер каждого множества, узнать размер объединения, сложить, вычесть одно из другого и получить пересечение. Но из-за того, что размер погрешности может быть больше размера итогового пересечения, итоговый результат может быть вида «от -50 до 50 тысяч».
Мы довольно много поработали над тем, как увеличить производительность при записи данных в Redis. Изначально мы достигли 200 тыс. операций в секунду. Но когда на каждого пользователя приходится более 50 сегментов – запись информации о каждом пользователе – 50 операций. Получается что мы довольно ограничены в пропускной способности и на данном примере не можем писать информацию более чем о 4 тыс. пользователей в секунду, это в разы меньше необходимого нам.
Мы сделали отдельную «хранимую процедуру» в Redis через Lua, загрузили ее туда и стали передавать в нее строку со всем списком сегментов одного пользователя. Процедура внутри нарежет переданную строку на необходимые обновления HyperLogLog-ов и сохранит данные, так мы достигли примерно 1 млн обновлений в секунду.
Немного хардкора: Redis является однопоточным, можно запинить его на одно ядро процессора, а сетевую карту на другое и добиться еще 15% производительности, экономя на переключениях контекста. Помимо этого, важным моментом является также то, что вы не можете просто кластерризировать структуру данных, потому что операции получения мощности объединений множеств некластеризируемы
Kafka — прекрасный инструмент
Вы видите, что Kafka является у нас основным инструментом транспорта в системе.
В ней есть сущность «топик». Это то, куда вы пишете данные, а по сути – очередь. В нашем случае есть несколько очередей. Одна из них – идентификаторы пользователей, которых необходимо сегментировать. Вторая – результаты сегментации.
Топик – это набор partition-ов. Он разделен на некоторые кусочки. Каждый partition – файл на жестком диске. Когда ваши продюсеры пишут данные – они пишут кусочки текста в конец partition. Когда ваши консьюмеры читают данные – они просто читают из этих partition.
Важно то, что вы можете подключить независимо несколько групп консьюмеров (consumer group), они будут потреблять данные не мешая друг другу. Это определяется по имени consumer group и достигается следующим образом.
Есть такая вещь, как offset, позиция, где сейчас находятся consumer group на каждом partition. Например, группа А потребляет из partition1 седьмое сообщение, а из partition2 — пятое. Группа Б, независимая от А, имеет другие offset.
Вы можете горизонтально масштабировать ваши consumer group, добавить еще один процесс или сервер. Произойдет partition reassignment (Kafka broker назначит каждому потребителю список partition на потребление) Это означает, что первая consumer group начнет потреблять только partition 1, а вторая — только partition 2. Если какой то из потребителей умирает (например не приходят hearthbeat) – происходит новый reassignment, каждый потребитель получает актуальный список partition на обработку.
Это довольно удобно. Во-первых, вы можете манипулировать offset для каждой consumer group. Представьте, что есть партнер, которому вы передаете данные из этого топика с результатами сегментации. Он пишет, что случайно в результате бага потерял последний день данных. И вы для consumer group этого клиента просто откатываетесь на день назад и переливаете ему день данных целиком. Также мы можем иметь свою consumer group, подключаться к продакшн-трафику смотреть, что происходит, заниматься отладкой на реальных данных.
Итак, мы добились того, что начали сегментировать пользователей при изменении, мы можем независимо подключать новых consumer-ов, мы пишем статистику и можем ее смотреть. Теперь надо добиться записи данных в HBase сразу же после того, как они к нам пришли.
Как мы это делали. Раньше была пакетная загрузка данных. Был Batch Loader, он обрабатывал файлы логов пользовательской активности: если пользователь совершил 10 визитов, приходил batch на 10 событий, его записывали в HBase одной операцией. Приходило лишь одно событие на сегментацию. Теперь мы хотим каждое отдельное событие писать в хранилище. У нас сильно вырастет поток на запись и поток на чтение. Количество событий на сегментацию также увеличится.
Первое, что мы сделали – перенесли HBase на SSD. Стандартными средствами это не особо делается. Это делалось средствами HDFS. Вы можете сказать, что определенная директория на HDFS должна находиться на такой-то группе дисков. Была прикольная проблема с тем, что, когда мы взяли и втупую запинили HBase на SSD, туда же попали и все snapshot-ы, и наши SSD довольно быстро закончились.
Это тоже решается, мы стали периодически экспортировать snapshot-ы в файл, писать в другую директорию HDFS и удалять всю метаинформацией о snapshot-е. Если надо восстановить – берем сохраненный файл, импортируем и восстанавливаемся. Эта операция очень нечастая, к счастью.
Также на SSD вынесли Write Ahead Log, подкрутили MemStore, включили опцию cache block on write. Она позволяет при записи данных сразу класть их и в block cache. Это очень удобно т.к. в нашем случае если мы записали данные, то они с высокой вероятностью будут сразу прочитаны. Это тоже дало некоторые плюсы.
Далее мы переключили все наши источники данных на запись данных в Kafka. Уже из Kafka записывали данные в HDFS для сохранения обратной совместимости, в том числе, чтобы наши аналитики могли работать с данными, запускать MapReduce задачи и анализировать их результаты.
Мы подключили отдельную consumer group, которая пишет данные в HBase. Это, по факту, wrapper, который читает из Kafka и формирует PUT-ы в HBase.
Запустили параллельно две схемы для того, чтобы не ломать обратную совместимость и не ухудшить характеристик системы. Новую схему запустили только на определенном проценте трафика. На 10% всё было довольно здорово. Но на большей нагрузке сегментаторы не справлялись с потоком на сегментацию.
Мы собираем метрику «сколько сообщений пролежало в Kafka до того, как было оттуда прочитано». Это хорошая метрика. Изначально мы собирали метрику «сколько сейчас необработанных сообщений», но она ни о чем особо не говорит. Вы смотрите: «у меня миллион необработанных сообщений», и что? Чтобы интерпретировать этот миллион, нужно знать, с какой скоростью работает сегментатор (потребитель), что не всегда наглядно.
С этой метрикой вы сразу видите, что данные пишутся в очередь, забираются из нее и видите сколько они ожидают своей обработки. Мы увидели, что не успеваем сегментировать, и сообщение лежит в очереди несколько часов до его прочтения.
Можно было просто добавить мощностей, но этого было бы слишком
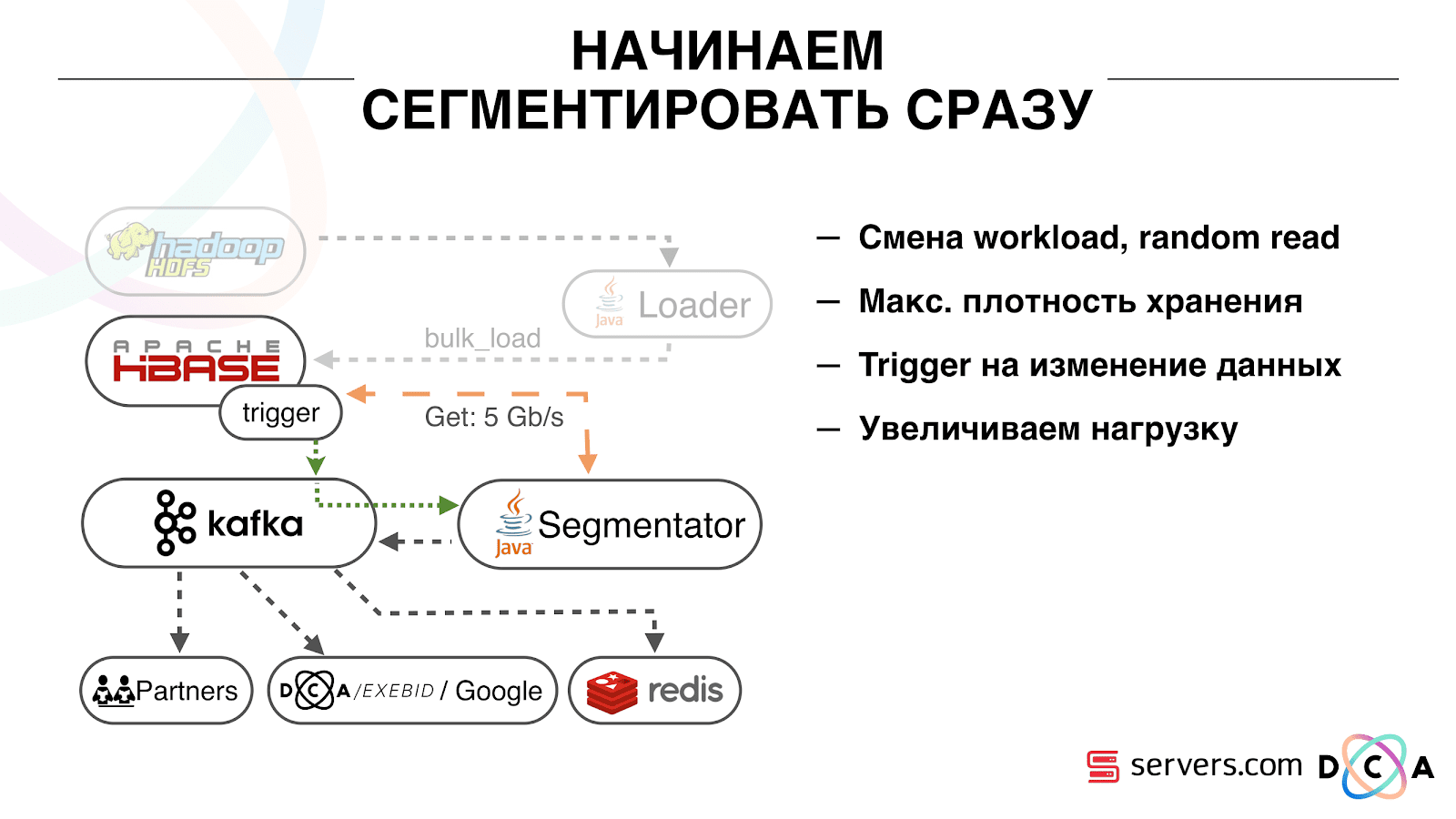
Самомасштабирование
У нас есть HBase. Меняется пользователь, его идентификатор летит в Kafka. Топик разбит на partition-ы, целевой partition выбирается по идентификатору пользователя. Это значит, что когда вы видите пользователя «Вася» — он отправляется в partition 1. Когда видите «Петю» — в partition 2. Это удобно – вы можете добиться того, что будете видеть одного потребителя на одном инстансе вашего сервиса, а второго – на другом.
Мы стали смотреть, что происходит. Одно типичное поведение пользователя в интернете – зайти на какой-то сайт и открыть несколько фоновых вкладок. Второе – зайти на сайт и сделать несколько кликов, чтобы добраться до целевой страницы.
Смотрим в очередь на сегментацию и видим следующее: пользователь А посетил страницу. Приходит еще 5 событий от этого пользователя – каждое обозначает открытие страницы. Мы обрабатываем каждое событие от пользователя. Но на самом деле данные в HBase содержат все 5 визитов. Мы первый раз обрабатываем все 5 визитов, второй раз и так далее – впустую тратим ресурсы CPU.
Поэтому мы стали хранить некий локальный кэш на каждом из сегментаторов с датой, когда в последний раз мы проводили анализ этого пользователя. То есть мы его обрабатывали, записали в кэш его userid и timestamp. У каждого сообщения kafka так же есть timestamp – мы просто сравниваем его: если timestamp в очереди меньше даты последней сегментации – пользователя по этими данными мы уже проанализировали, и это событие можно просто пропустить.
События пользователя (Красные А) могут быть разными, и идут они не по порядку. Пользователь может открыть несколько фоновых вкладок, открыть несколько ссылок подряд, возможно на сайте есть сразу несколько наших партнеров, каждый из которых присылает эти данные.
Наш пиксель может увидеть визит пользователя, а затем еще какое-то действие — мы его шлем сами себе. Приходит пять событий, мы обрабатываем первую красную А. Если событие пришло, значит оно уже в HBase. Мы видим события, прогоняем через набор скриптов. Видим следующие событие, а там всё те же события, потому что они уже записаны. Прогоняем еще раз и сохраняем кэш с датой, сравниваем её с timestamp события.
Благодаря этому система получила свойство самомасштабируемости. По оси У – процентное соотношение того, что мы делаем с идентификаторами пользователя, когда они к нам приходят. Зеленое – работа, которую мы выполнили, запустили скрипт сегментации. Желтое – мы не стали этого делать, т.к. уже сегментировали ровно эти данные.
Видно, что ночью ресурсы есть, идет меньший поток данных, и можно сегментировать каждый второй ивент. Днем ресурсов поменьше, и мы сегментируем только 20% событий. Скачок в конце дня – партнер подлил файлы данных, которые мы раньше не видели, и их пришлось «честно» сегментировать.
Система сама адаптируется к росту нагрузки. Если у нас появляется очень крупный партнер – мы обрабатываем те же данные но чуть реже. В таком случае характеристики системы вечером немного ухудшатся, сегментация будет с задержкой не 2-3 секунды, а минуту. Утром добавим серверов и вернемся к нужным результатам.
Таким образом мы сэкономили примерно в 5 раз на серверах. Сейчас мы работаем на 10 серверах, а так потребовалось бы 50-60.
Синенькая штука сверху – боты. Это самая тяжелая часть сегментации. У них огромное число визитов, они создают очень большую нагрузку на железо. Каждого бота мы видим на отдельном сервере. Мы можем на нем собирать локальный кэш с черным списком ботов. Ввели простой антифрод: если юзер совершает слишком много визитов за определенное время, то с ним что-то не так, добавляем в блэклист на какое-то время. Это синенькая полосочка, где-то 5%. Они дали нам еще 30% экономии на CPU.
Таким образом мы добились того, что видим весь pipeline обработки данных на каждом этапе. Мы видим метрики, сколько сообщение пролежало в Kafka. Вечером где-то что-то затупило, время обработки увеличилось до минуты, потом отпустило и пришло в норму.
Мы можем мониторить, как наши действия с системой влияют на ее пропускную способность, можем видеть, сколько выполняется скрипт, где необходимо провести оптимизацию, на чем можно сэкономить. Можем видеть размеры сегментов, динамику размера сегментов, оценивать их объединение и пересечение. Это можно делать для более-менее одинаковых размеров сегментов.
Что хотелось бы доработать?
У нас есть Hadoop-кластер с некоторыми вычислительными ресурсами. Он занят – на нем днем работают аналитики, но ночью он практически свободен. В целом, мы можем сегментатор контейнеризировать и запускать как отдельный процесс в рамках нашего кластера. Мы хотим более точно хранить статистику, чтобы точнее расчитывать объем пересечени. Еще нужна оптимизация на CPU т.к. это напрямую влияет на стоимость решения.
Подводя итоги: Kafka хороша, но, как и с любой другой технологией, нужно понимать, как она работает внутри и что с ней происходит. Например, гарантия на очередность сообщения работает только внутри partition. Если вы отправляете сообщение, которое пойдет в разные партиции, то непонятно, в какой последовательности они будут обработаны.
Очень важны реальные данные. Если бы мы не тестировались на реальном трафике, то, скорее всего, не увидели бы проблем с ботами, с сессиями пользователей. Разработали бы что-то в вакууме, запустили и прилегли. Важно мониторить то, что считаете нужным мониторить, и не мониторить то, что не считаете.
Минутка рекламы. Если вам понравился этот доклад с конференции SmartData — обратите внимание, что 15 октября в Санкт-Петербурге пройдет SmartData 2018 — конференция для тех, кто погружен в мир машинного обучения, анализа и обработки данных. В программе будет много интересного, на сайте уже есть первые спикеры и доклады.
Комментарии (4)

fuCtor
24.08.2018 17:57А вот от этого habr.com/company/dca/blog/260845 отказались получается? Или это параллельные вещи?
onexdrk
25.08.2018 01:58+1Изначально мы разрабатывали описанное в статье решение параллельно со «старым» realtime модулем. Когда новый сегментатор заработал на 100% трафика мы смогли отказаться от решения на Akka. Основное бизнес преимущество новой схемы по сравнению со старой в том, что тут мы каждый раз анализируем все данные пользователя, в старой же схеме в реальном времени анализировалась лишь пользовательская текущая активная сессия, чего не всегда хватало
time2rfc
Спасибо огромное за интересную статью! Я правильно понял что часть данных это кликстрим от ваших партнеров ?
onexdrk
Да, все верно. Выгрузки партнеров также могут быть как потоковые (прямая поставка в Kafka через различные интеграции) так и периодические выгрузки в виде файлов, эти файлы по приходу так же загружались в Kafka