
В основе материала — расшифровка доклада Андрея Филатова, ведущего системного инженера компании EPAM Systems, c нашей октябрьской конференции DevOops 2017.
Что такое SCM и с чем его едят?

Что же такое SCM? В первую очередь это штука, которая позволяет нашу инфраструктуру из состояния A при помощи выполнения какого-то кода привести к состоянию Б. Многие разработчики, которые не являются на практике DevOps инженерами, думают, что каким-то «автомагическим» способом что-то происходит на инфраструктуре.
«Автомагический» способ нам реализует SCM (System Configuration Management). Для чего это нужно? В первую очередь для того, чтобы строить повторяемые и консистентные инфраструктуры. SCM хорошо расширяет CI/CD-процессы. Так как это код, его можно хранить в любой системе контроля версий: Git, Mercurial. Его достаточно просто развивать и поддерживать.
Финальное — это замкнутый цикл автоматизации: все можно делать в автоматическом режиме, от создания инфраструктуры до ее развертывания и deployment-а кода.
Что такое SCM: Ansible

Рассмотрим наших претендентов. Первый — Ansible. Имеет безагентную архитектуру, если мы говорим об open source-версии, написан на Python, имеет Yaml-подобный DSL, легко расширяемый за счет модулей, написанных на Python, очень простой и легковесный. Ansible имеет самый низкий порог вхождения — вы можете научить кого угодно.
Есть опыт, когда человек, не зная Python, не зная ничего о SCM, вошел в Ansible буквально за два дня и уже начал что-то делать.
Ниже пример ChatOps: нотификатор в Slack. Код на Ansible, кто видел Yaml — ничего нового.
- block:
- name: "SlackNotify : Deploy Start"
local_action:
module: slack
token: "{{ slack_url }}"
attachments:
- title: "Deploy to {{ inventory_hostname }} has been Started"
text: "<!here> :point_up_2:"
color: "#551a8b"
- include: configure.yml
tags:
- configure
- include: remote-fetch.yml
tags:
- remote
- include: assets.yml
Что такое SCM: Chef

Chef — это клиент-серверная архитектура, есть Chef-сервер и Chef-клиент. Конфигурация основана на поиске, написан на Ruby, имеет Ruby DSL. Соответственно, внутри своих cookbook-ов и рецептов вы можете использовать всю мощь Ruby, но я не советую этого делать. У Chef огромное комьюнити и самый большой набор инструментов среди всех SСM. Вот так выглядит код на Chef, это разворачивание Jetty.
#
# Cookbook Name:: dg-app-edl
# Recipe::fe
#
node.normal[:jetty][:home] = "/usr/share/jetty"
node.normal[:jetty][:group] = "deploy"
include_recipe "dg-auth::deploy"
include_recipe "newrelic::repository"
include_recipe "newrelic::server-monitor"
include_recipe "dg-jetty::jetty9"
include_recipe "newrelic::java-agent"
directory "edl" do
action :create
owner
group "deploy"
mode "0775"
path "/usr/share/where/edl"
recursive true
end
Что такое SCM: SaltStack

SaltStack имеет как безагентную архитектуру, которая работает в push-режиме при помощи Salt-SSH, так и клиент-серверную архитектуру, когда есть Salt-master и Salt-minion. Упор сделан на автоматизацию в реальном времени, имеет из коробки параллельное исполнение всех процессов и написан на Python. Тоже Yaml-подобный язык, код очень похож на Ansible.
#ntp-packages:
pkg.installed:
- pkgs:
- ntp
- ntpdate
#/etc/ntp.conf:
file:
- managed
- source: salt://common/ntpd/ntp.conf
- template: jinja
- mode: 644
#/etc/sysconfig/ntpd:
file:
- managed
- source: salt://common/ntpd/ntpd
- template: jinja
- mode: 644
#ntp-service:
service.running:
- name: ntpd
Что такое SCM: Puppet

Последний из наших претендентов — Puppet. Тоже имеет клиент-серверную архитектуру, как Chef, конфигурация основана не на поиске, а на «фактах», которые приходят с Puppet-master-а, написан на Ruby, имеет Ruby-подобный DSL. Но ребята из Puppet не разрешают использовать в своих манифестах чистый код Ruby. Это и плюс, и минус. Вот так выглядит код манифеста на Puppet:
class { 'mysql::server' :
root_password => 'password'
}
mysql::db{ ['test', 'test2', 'test3']:
ensure => present,
charset => 'utf8',
require => Class['mysql::server'],
}
mysql::db{ 'test4':
ensure => present,
charset => 'latin1',
}
mysql::db{ 'test5':
ensure => present,
charset => 'binary',
collate => 'binary',
}
SСM на практике
SaltStack в условиях демилитаризованной среды
В первую очередь я хотел бы поделиться проектом, который был написан на SaltStack. Это наш предыдущий проект и самая свежая боль, а свежая боль всегда самая больная. Наш заказчик занимается хранением данных — это производство железных серверов для хранения данных на GPFS, GlusterFS, но сборки кастомные. Он пришел к нам со следующими задачами:
- Создание USB/DVD инсталлятора. Нужно создать медиа, из которого все инсталлируется. Это делается для клиентов заказчика, которые живут в закрытых зонах, где на серверах чаще всего нет интернета. Нам нужно упаковать в одну ISO, отправлять field-инженерам, которые на месте развернут все необходимое.
- Развертывание кластера с продуктом. У заказчиков несколько крупных продуктов, мы должны уметь их разворачивать в кластерном режиме.
- Управление, настройка и сопровождение кластера с помощью CLI-утилиты. Наш фреймворк должен помогать field-инженерам управлять кластером.
У заказчика было несколько требований. В первую очередь, у него огромное количество Python-экспертизы, по факту только C и Python-разработчики. Заказчик сразу сказал: «Мы хотим SaltStack», не оставив выбора.
С чем мы столкнулись? У заказчика в инсталляции есть несколько продуктов, все должны быть c Salt-Master’ами. Но мы столкнулись с проблемой масштабирования Multi-Master-конфигурации. К примеру, у нас в NODЕ Info (состояние конкретного сервера) выбиралось при двухмастерной конфигурации миллисекунды, при трех — уже секунды, а при пяти мы ни разу не дождались завершения операции. MultiMaster хорошая фишка, но масштабируется плохо.
Вторая проблема, с которой мы столкнулись — командная работа: в SaltStack есть Runner и Module. Module — расширение, которое выполняется на Salt Minion, на стороне машины. Runner выполняется на стороне сервера. У нас очень часто возникали баталии: что делать Runner, и что делать Modules.
Затем столкнулись с небольшим сюрпризом от сache.mine:
ime = ImeActions()
id = __grains__['id']
if id == ime.master_id:
ret = __salt__['mine.get'](id, 'ime_actions.make_bfs_uuid')
ime_dict = ret.get(id, None)
if not ime_dict:
try:
result = __salt__['mine.send']('ime_actions.make_bfs_uuid')
except Exeption, e:
log.error("Failed to generate uuid: {0}.".format(str(e)))
result = False
else:
У нас есть утилита, которая написана на C. Мы ее запускаем, она генерирует случайный ID. Он должен быть уникален среди всех участников кластера, соответственно, нам это нужно делать один раз на мастере, и дальше распространять среди машин. Мы для этого использовали cache.mine. Как оказалось, он не переживает перезагрузки.

«Race condition». Параллелизация — хорошо, но в базовой конфигурации state.orchestrate приходит в состояние state.sls is running, если происходят длительные процессы. По таймауту он считает, что State уже выполнился, хотя тот еще выполняется, и пытается запустить следующий. Возникает ошибка. И эта проблема пока ещё не исправлена.
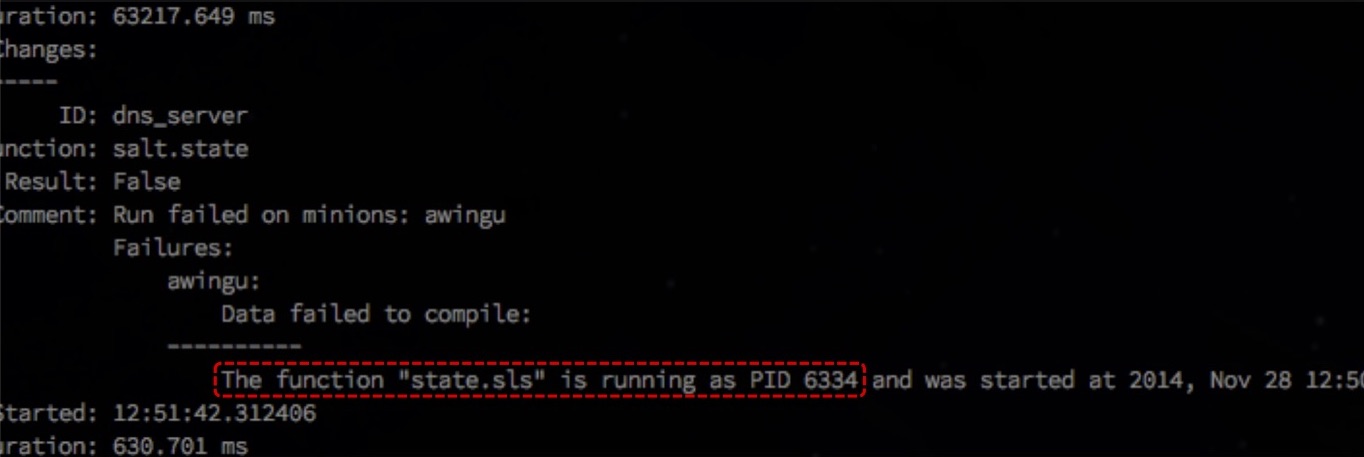
Можно посмотреть на GitHub.
Что мы могли использовать, кроме SaltStack?
SaltStack в DMZ окружении

- DMZ. Chef отлично пакуется, Puppet тоже. А с Ansible проблема — если нет Tower, — нет возможности запустить конфигурацию в Pull-режиме с наших нод, что необходимо делать в демилитаризованной зоне.
- Framework for CLI (на Python). Chef и Puppet не очень подходят, но если у вас нет ограничений использовать только Python — можно писать на Ruby и использовать API Chef или Puppet. Ansible подобный инструментарий не поддерживает.
- Cluster Management. Chef хорошо подходит для управления кластерами, Puppet тоже, а Ansible изначально писался для того, чтобы управлять кластерами в Amazon.
Chef в большой и динамичной среде
Заказчик пришел с задачей консолидировать все ресурсы в одном облаке — это был Openstack. До этого все было разбросано: что-то на Rackspace Cloud, что-то на выделенных серверах или своих приватных датацентрах.
Они хотели полностью динамическое управление ресурсами, а также, чтобы их приложения в случае необходимости могли добавить себе мощностей. То есть нужна полная динамическая инфраструктура и полностью динамическое окружение как вверх, так и вниз.
Для того чтобы правильно построить процесс CD, нужна полностью автоматизированная среда. Мы создали для них SDLC — Software Development Lifecycle, и применили его, в том числе, для SCM. У них проходят интеграционные тесты не только приложений, но и инфраструктуры.
Соответственно, когда у нас идет что-то не так, мы должны, как ребята из Netflix, уметь убивать дефективные ресурсы и на их место восстанавливать свежие и гарантированно рабочие.
С какими проблемами мы столкнулись:
- Это был 2013 год, использовали Chef 10, в котором медленный поиск. Мы запускали поиск, обходя все машины, и это занимало вечность. Попытались решить проблему naming-конвенцией, а также выбором и поиском по fqdn. Это сужало область поиска, за счет чего он ускорялся.
Но некоторые операции нужно делать на всем окружении. Соответственно, поиск запускался один раз в самом начале, результат сохранялся в атрибуте, и с помощью Ruby фильтровали результаты: парсили нужные нам кусочки и делали, что было нужно.
if !Chef::Config[:solo] search(:node, "fqdn:*metro-#{node[:env]}-mongodb*").each do |mongo| @mongodbs << mongo.fqdn end else @mongodbs = ["lvs-metro-#{node[:env]}-mongodb3001.qa.example.com"] end
Итог: используйте нейминг-конвенции, запускайте поиск один раз, используйте Ruby для фильтрации нужных результатов.
- Использовать «node.save» небезопасно, будьте внимательны и осторожны. Мы столкнулись с этой проблемой, когда разворачивали MySQL-кластеры, и использовали внутри рецепта node.save на не полностью сконфигурированной MySQL-ноде. И в момент Scale-up некоторые приложения выдавали 500 ошибку. Выяснилось, что мы не в то время сохраняли ноду: она уходит на Chef-сервер, тут же Chef-клиент на UI подхватывает новую ноду, которая не сконфигурировалась до рабочего режима.
- Отсутствие «splay» может убить chef-сервер. Splay — параметр Chef-клиента, который позволяет задать диапазон, когда клиент пойдет к серверу за конфигурацией. При большой нагрузке, когда нужно развернуть много нод одновременно, это позволит не убить сервер.
Что мы можем использовать вместо Chef?
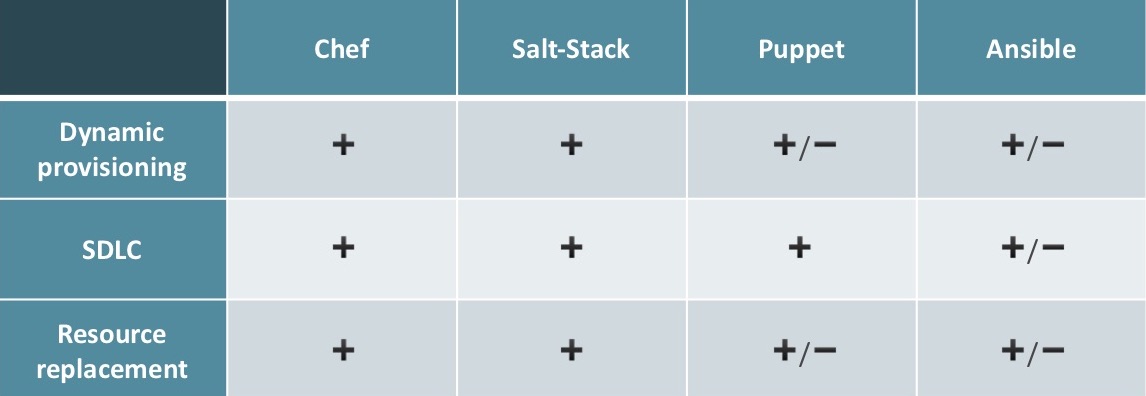
- Dynamic provisioning. SaltStack подходит идеально, так как у него есть SaltCloud, который отлично интегрируется куда угодно. В Puppet есть подобная функциональность, но она доступна только в Puppet Enterprise, за деньги. Ansible хорошо подходит, если компания «живет» в Amazon, если что-то другое — можно завязать его в альтернативы, но это не так удобно.
- SDLC. В Chef есть всё, начиная от Test Kitchen до выбора инструментов для интеграционного тестирования. В SaltStack есть весь доступный Python-инструментарий, сейчас в Puppet тоже все есть. В Ansible есть Role Spec, можно использовать Test Kitchen от Chef, но это не нативный инструмент.
- Resource replacement. В Chef все устроено хорошо, в SaltStack можно допилить SaltCloud до нужного состояния, в Puppet инструменты только в Enterprise-версии, а Ansible хорошо работает только с Amazon.
EPAM Private Cloud с Chef
За год-полтора до появления AWS OpsWorks мы хотели создать расширенный Amazon CloudFormation, интегрировав Chef, чтобы ресурсы не только разворачивались, но и настраивались.
Вторая глобальная задача — создание сервис-каталога, чтобы заказчики и пользователи могли при помощи CLI развернуть полностью готовый к использованию например LAMP-стек.

Мы выбрали Chef, но проект должен был поддерживать разные SCM. Мы стартовали со встроенным Chef-Server’ом, а также пользователи могли использовать собственный Chef-Server, который хостится где-то у них. То есть мы не получали доступа к пользовательским ресурсам и ноутбукам, но это все равно работало.

Для реализации CloudFormation + OpsWork можно использовать любой SCM, подходят все. Для создания каталога — все, кроме SaltStack, хорошо с этим справятся. У SaltStack есть нюансы: найти специалиста, который хорошо знает SaltStack и может создавать сервис и наполнять каталог, крайне сложно.
Популярность SCM в EPAM

Это статистика популярности SCM внутри EPAM. SaltStack очень далеко позади. На первом месте Ansible, он самый простой и с низким порогом вхождения. Когда мы пытаемся найти кого-то на рынке со знанием SCM — рынок выглядит примерно так же.
Работа с Ansible
Советы, которые я могу дать при работе с Ansible:
- Используйте ‘accelerate’, он в 2-6 раз быстрее SSH разворачивает конфигурации (для el6). Для всех остальных есть ‘pipelining’. Для обратной совместимости он выключен, но включить обратно ‘pipelining’ очень легко, рекомендую это делать.
- Используйте ‘with_items’
- name: project apt dependencies installed apt: name: "{{ item }}" become: yes with_items: - build-essential - acl - git - curl - gnupg2 - libpcre3-dev - python-apt - python-pycurl - python-boto - imagemagick - libmysqlclient-dev # needed for data import
В данном примере мы устанавливаем пакеты, эту схему можно использовать для создания пользователей и тому подобных операций.
- Аккуратно используйте ‘local_action’ и ‘delegated’. Первый позволяет получить нечто похожее на SaltStack Runner, второй умеет делегировать задачи конкретным машинам.
- name: create postgresql database postgresql_db: name: "{{ database_name }}" login_host: "{{ database_host }}" login_user: "{{ database_master_user }}" login_password: "{{ database_master_password }}" encoding: "UTF-8" lc_collate: "en_US.UTF-8" lc_ctype: "en_US.UTF-8" template: "template0" state: present delegate_to: "{{ groups.pg_servers|random}}"
Это кусок по созданию баз данных. Без последней строчки операция выполнилась бы несколько раз и свалилась на второй попытке создать ту же самую базу данных.
- Оптимизируйте ваши роли и исполнение при помощи тегов. Это позволяет значительно сократить время выполнения.
Выводы
Лично для меня Ansible — фаворит. SaltStack очень хороший, очень гибкий, но требует знания Python, без них SaltStack лучше не использовать. Chef — универсальная серебряная пуля для любых задач и любых масштабов, но требует больших знаний, чем Ansible. А кто использует Puppet — я не знаю. В принципе, он очень похож на Chef, но со своими нюансами.
Минутка рекламы. Если вам понравился этот доклад с конференции DevOops — обратите внимание, что 14 октября в Санкт-Петербурге пройдет новый DevOops 2018, в его программе тоже будет много интересного. На сайте уже есть первые спикеры и доклады.
Комментарии (14)

snp
12.07.2018 13:04Используйте ‘accelerate’, он в 2-6 раз быстрее SSH разворачивает конфигурации (для el6).
Он deprecated.
Используйте ‘with_items’
Совет в духе «когда на улице зима, одевайтесь тепло».
Ansible — фаворит. SaltStack очень хороший, очень гибкий, но требует знания Python,
Без питона Ansible тоже малопригоден, т.к. любые нестандартные вещи требуют написания своих модулей, фильтров, lookup'ов и т.п.
кто использует Puppet — я не знаю. В принципе, он очень похож на Chef, но со своими нюансами.
Puppet более всего похож на CFEngine.
lincore
12.07.2018 16:56Он deprecated.
Да, но к сожалению для el6(Centos/RHEL) он всё ещё актуален
Без питона Ansible тоже малопригоден
Очень даже пригоден, ведь уже очень много всего написано готового и шанс найти что-то подходящее достаточно велик. Особенно в сравнении с SaltStack.
Puppet более всего похож на CFEngine.
Они оба(Puppet и Chef) «выросли» из CFEngine и очень на него похожи.
chinacoolhacker
12.07.2018 13:53Аккуратно используйте ‘local_action’ и ‘delegated’. Первый позволяет получить нечто похожее на SaltStack Runner, второй умеет делегировать задачи конкретным машинам.
— name: create postgresql database
postgresql_db:
name: "{{ database_name }}"
login_host: "{{ database_host }}"
login_user: "{{ database_master_user }}"
login_password: "{{ database_master_password }}"
encoding: «UTF-8»
lc_collate: «en_US.UTF-8»
lc_ctype: «en_US.UTF-8»
template: «template0»
state: present
delegate_to: "{{ groups.pg_servers|random}}"
Это кусок по созданию баз данных. Без последней строчки операция выполнилась бы несколько раз и свалилась на второй попытке создать ту же самую базу данных.
есть же run_once: truelincore
12.07.2018 16:58есть же run_once: true
Такой комментарии был и в зале во время доклада, я же хотел показать пример именно с `delegate`
AlexGluck
12.07.2018 15:12А с Ansible проблема — если нет Tower, — нет возможности запустить конфигурацию в Pull-режиме с наших нод, что необходимо делать в демилитаризованной зоне.
У нас нет товера, но пулл работает с гитом нормально, ЧЯДНТ? Я даже больше скажу, вообще не понимаю нахрена он нужен для ansible-pull, товер же не выступает репозиторием для ансибла никак.
Framework for CLI (на Python). Ansible подобный инструментарий не поддерживает.
Это ansible-console нет или чего? Ансибл это как корутины, которые просто с параметрами правильными вызвать надо. Какой к нему фреймворк лепить то? На крайний случай взгляните на awx для REST API, не фреймворк конечно, но не такая уж и большая сложность.lincore
12.07.2018 17:06У нас нет товера, но пулл работает с гитом нормально, ЧЯДНТ? Я даже больше скажу, вообще не понимаю нахрена он нужен для ansible-pull, товер же не выступает репозиторием для ансибла никак.
Если я верно вас понял то вы имеете в виду pull из git с последующим локальным запуском плейбука, в нашей задаче мы не могли использовать этот подход, а сам ansible не имеет возможности стянуть все необходимое как это делают те же Chef-Client или Salt-Minion с соотвественно Chef-Server'a и Salt-Master'a
Какой к нему фреймворк лепить то?
Задача была не к нему фреймворк сделать, а на его основе сделать свой для простого и удобного написания CLI интерфейса который смогут использовать как продуктовые команды(те кто делают непосредственно само ПО которое мы разворачиваем) так и инженеры в поле(те кто этот продукт соотвественно настраивает в датацентре заказчика)
SlavikF
13.07.2018 01:44А с Ansible проблема — если нет Tower, — нет возможности запустить конфигурацию в Pull-режиме с наших нод, что необходимо делать в демилитаризованной зоне.
Простите если у меня нубский вопрос — сам я только присматриваюсь к этим систем и думаю какую выбрать для изучения на своём небольшом проекте. Вопрос такой:
А нельзя ли прокинуть Ansible в эту DMZ зону, чтобы DMZ хосты стали доступны для него? Да, это получается такая дырка в DMZ, но Tower — дырка ничуть не меньше.selivanov_pavel
13.07.2018 02:10+1Это так называемый bastion host. Вот мой например велосипед: https://selivan.github.io/2018/01/29/ansible-ssh-bastion-host.html
Или можно в ansible_ssh_common_args добавлять ProxyCommand
SlavikF
13.07.2018 02:14То есть никакой проблемы «пуллить» нету?
selivanov_pavel
13.07.2018 02:21ansible-pull достаточно примитивен, по сути это git pull + ansible-playbook. Он запускается на управляемой машине, ему нужен доступ к vcs-репозиторию, откуда он заберёт плейбуки и применит локально.
В нормальном режиме ansible запускается на управляющей машине, идёт по ssh(или по winrm для windows) на управляемую и там работает. И вот если прямого доступа по ssh на управляемую машину нету, то можно использовать соединение через бастион-хост, с которым соединение есть и который может ходить на управляемую.
jaroslavdextems
13.07.2018 16:11Мало написать плейбуки\кукбуки и что угодно еще, гораздо сложнее сделать так, чтобы все изменения выполнялись через систему контроля версий и только через SCM. Учитывая самый низкий порог вхождения, Ansible — фаворит, ибо настолько всё прозрачно и просто, что въехать в тему может за пару дней почти любой специалист.
snp
Было бы неплохо и CFEngine включить в сравнение.
lincore
Хорошее замечание, правда я последний раз его использовал лет 8 назад. Не думал что он ещё кому-то интересен и пользуется хоть какой-то популярностью.