
Начнем с архитектуры примера нашей системы. Предположим, что у нас есть три микросервиса, которые общаются друг с другом через URL полученные из Spring Cloud Eureka приложения.
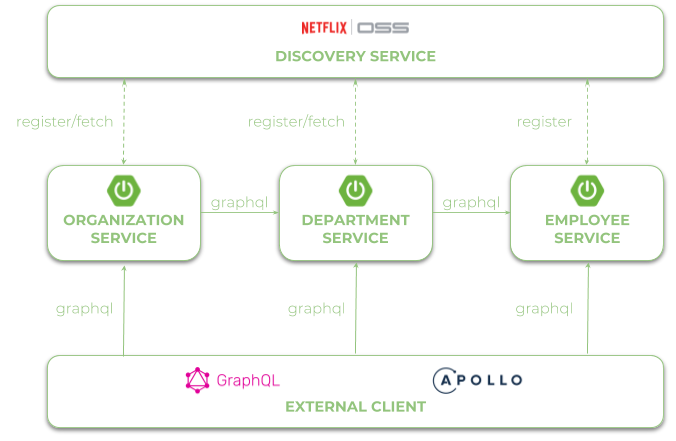
Включаем поддержку GraphQL в Spring Boot
Мы можем легко включить поддержку для GraphQL на серверной стороне приложения Spring Boot с помощью стартеров. После добавления graphql-spring-boot-starter сервлет GraphQL будет автоматически доступен по пути /graphql. Мы можем переопределить этот путь по умолчанию через указание свойства graphql.servlet.mapping в application.yml файле. Мы также включаем GraphiQL – браузерную IDE для написание, проверки и тестирования GraphQL запросов и библиотеку GraphQL Java Tools, которая содержит полезные компоненты для создания запросов и мутаций. Благодаря этой библиотеки все файлы в classpath с расширением .graphqls будут использованы для создания определения схемы.
compile('com.graphql-java:graphql-spring-boot-starter:5.0.2')
compile('com.graphql-java:graphiql-spring-boot-starter:5.0.2')
compile('com.graphql-java:graphql-java-tools:5.2.3')
Описание GrpahQL схемы
Каждое описание схемы содержит декларацию типов, связи между ними и множество операций включающих запросы для поиска объектов и мутаций для создания, обновления или удаления данных. Обычно мы начинаем с определения типа, который отвечает за домен описываемого объекта. Вы можете указать является ли поле обязательным с помощью
! символа или если это массив – […]. Описание должно содержать декларируемы тип или ссылку на другие типы доступные в спецификации.type Employee {
id: ID!
organizationId: Int!
departmentId: Int!
name: String!
age: Int!
position: String!
salary: Int!
}
Следующая часть определения схемы содержит декларации запросов и мутаций. Большинство запросов возвращают список объектов, которые помечены в схеме как [Employee]. Внутри типа EmployeeQueries мы объявляем все методы поиска, в то время как в типе EmployeeMutations методы для добавления, обновления и удаления сотрудников. Если вы передаете целый объект в метод, вы должны объявить его как input тип.
schema {
query: EmployeeQueries
mutation: EmployeeMutations
}
type EmployeeQueries {
employees: [Employee]
employee(id: ID!): Employee!
employeesByOrganization(organizationId: Int!): [Employee]
employeesByDepartment(departmentId: Int!): [Employee]
}
type EmployeeMutations {
newEmployee(employee: EmployeeInput!): Employee
deleteEmployee(id: ID!) : Boolean
updateEmployee(id: ID!, employee: EmployeeInput!): Employee
}
input EmployeeInput {
organizationId: Int
departmentId: Int
name: String
age: Int
position: String
salary: Int
}
Реализация запросов и мутаций
Благодаря автоконфигурации GraphQL Java Tools и Spring Boot GraphQL нам не нужно прилагать много усилий для имплементации запросов и мутаций в нашем приложении. Бин EmployeesQuery должен реализовывать интерфейс GraphQLQueryResolver. Основываясь на этом, Spring сможет автоматически найти и вызывать правильный метод как ответ на один из GraphQL запросов, которые были декларированы внутри схемы. Вот класс, содержащий имплементацию ответов на запросы:
@Component
public class EmployeeQueries implements GraphQLQueryResolver {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeQueries.class);
@Autowired
EmployeeRepository repository;
public List employees() {
LOGGER.info("Employees find");
return repository.findAll();
}
public List employeesByOrganization(Long organizationId) {
LOGGER.info("Employees find: organizationId={}", organizationId);
return repository.findByOrganization(organizationId);
}
public List employeesByDepartment(Long departmentId) {
LOGGER.info("Employees find: departmentId={}", departmentId);
return repository.findByDepartment(departmentId);
}
public Employee employee(Long id) {
LOGGER.info("Employee find: id={}", id);
return repository.findById(id);
}
}
Если вы хотите вызывать, например, метод employee(Long id), напишите следующий запрос. Чтобы протестировать его в вашем приложении используйте GraphiQL, который доступен по адресу /graphiql.
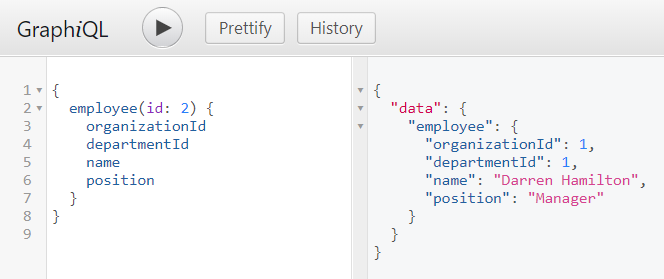
Бину ответственному за имплементацию методов мутаций нужно реализовать интерфейс GraphQLMutationResolver. Несмотря на название EmployeeInput мы продолжаем использовать тот же доменный объект Employee, который возвращается запросом.
@Component
public class EmployeeMutations implements GraphQLMutationResolver {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeQueries.class);
@Autowired
EmployeeRepository repository;
public Employee newEmployee(Employee employee) {
LOGGER.info("Employee add: employee={}", employee);
return repository.add(employee);
}
public boolean deleteEmployee(Long id) {
LOGGER.info("Employee delete: id={}", id);
return repository.delete(id);
}
public Employee updateEmployee(Long id, Employee employee) {
LOGGER.info("Employee update: id={}, employee={}", id, employee);
return repository.update(id, employee);
}
}
И здесь мы используем GraphiQL для тестирования мутаций. Вот команда, которая добавляет новый employee и принимает ответ с id и name сотрудника.
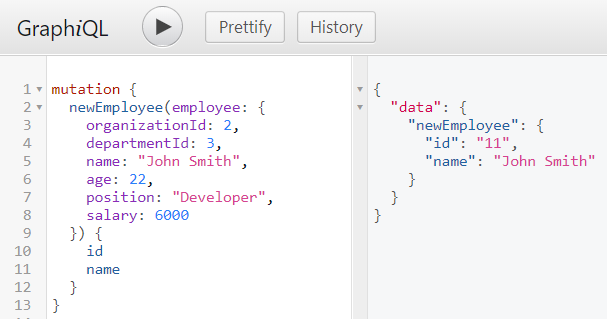
На этом я приостанавливаю перевод данной статьи и пишу свое «лирическое отступление», а фактически подменяю описание части микросервисного взаимодейстивя через Apollo Client, на взаимодействие через библиотеку GQL и Unirest – библиотеки для выполнения HTTP запросов.
GraphQL клиент на Groovy.
Для создания GraphQL запросов в микросервисе department-servive я буду использовать Query builders:
String queryString = DSL.buildQuery {
query('employeesByDepartment', [departmentId: departmentId]) {
returns {
id
name
position
salary
}
}
}
Данная конструкция на DSL GQL создает запрос вида:
{
employeesByDepartment (departmentId: 1) {
id
name
position
salary
}
}
И, далее, я буду выполнять HTTP запрос по переданному в метод адресу.
Как формируется адрес запроса узнаем далее.
(Unirest.post(serverUrl)
.body(JsonOutput.toJson([query: queryString]))
.asJson()
.body.jsonObject['data']['employeesByDepartment'] as List)
.collect { JsonUtils.jsonToData(it.toString(), Employee.class) }
После получения ответа выполняем его преобразование из JSONObject к виду списка Employee.
GrpahQL клиент для микросервиса сотрудников
Рассмотрим реализацию микросервиса сотрудников. В этом примере я пользовался Eureka клиентом напрямую. eurekaClient получает все запущенные экземпляры сервисов, зарегистрированные как employee-service. Затем он случайно выбирает какой-то экземпляр из зарегистрированных (2). Далее, берет номер его порта и формирует адрес запроса (3) и передает его в объект EmployeeGQL который является GraphQL клиентом на Groovy и, который, описан в предыдущем пункте.
@Component
public class EmployeeClient {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeClient.class);
private static final String SERVICE_NAME = "EMPLOYEE-SERVICE";
private static final String SERVER_URL = "http://localhost:%d/graphql";
Random r = new Random();
@Autowired
private EurekaClient discoveryClient; // (1)
public List<Employee> findByDepartment(Long departmentId) {
Application app = discoveryClient.getApplication(SERVICE_NAME);
InstanceInfo ii = app.getInstances().get(r.nextInt(app.size())); // (2)
String serverUrl = String.format(SERVER_URL, ii.getPort()); // (3)
EmployeeGQL clientGQL = new EmployeeGQL();
return clientGQL.getEmployeesByDepartmentQuery(serverUrl, departmentId.intValue()); // (4)
}
}
Далее, я «передаю» снова слово автору, точнее продолжаю перевод его статьи.
И наконец, EmployeeClient внедряется в класс который отвечает на запросы DepartmentQueries и используется внутри запроса departmentsByOrganizationWithEmployees.
public List<Department> departmentsByOrganizationWithEmployees(Long organizationId) {
LOGGER.info("Departments find: organizationId={}", organizationId);
List<Department> departments = repository.findByOrganization(organizationId);
for (int i = 0; i < departments.size(); i++) {
departments.get(i).setEmployees(employeeClient.findByDepartment(departments.get(i).getId()));
}
return departments;
}
Перед выполнением нужного запросы нам следуем взглянуть на схему созданную для department-service. Каждый объект Department может содержать список назначенных сотрудников, и мы также определили тип Employee на который ссылается тип Department.
schema {
query: DepartmentQueries
mutation: DepartmentMutations
}
type DepartmentQueries {
departments: [Department]
department(id: ID!): Department!
departmentsByOrganization(organizationId: Int!): [Department]
departmentsByOrganizationWithEmployees(organizationId: Int!): [Department]
}
type DepartmentMutations {
newDepartment(department: DepartmentInput!): Department
deleteDepartment(id: ID!) : Boolean
updateDepartment(id: ID!, department: DepartmentInput!): Department
}
input DepartmentInput {
organizationId: Int!
name: String!
}
type Department {
id: ID!
organizationId: Int!
name: String!
employees: [Employee]
}
type Employee {
id: ID!
name: String!
position: String!
salary: Int!
}
Теперь мы можем вызвать наш тестовый запрос с списком нужных полей используя GraphiQL. Приложение department-service по умолчанию доступно на порте 8091, то есть мы можем увидеть его по адресу http://localhost:8091/graphiql
Заключение
Возможно, GraphQL может быть интересной альтернативой стандартным REST API. Однако, нам не следует рассматривать его как замену REST. Существуют несколько случаев, где GraphQL может быть лучшим выбором, но те, где лучшим выбором будет REST. Если вашим клиентам не нужно иметь все поля, возвращаемые серверной частью, и более того у вас есть много клиентов с разными требованиями для одной точки входа, то GraphQL хороший выбор. Если посмотреть на то, что есть в микросервисном сообществе, то можно увидеть, что сейчас там нет решение основанных на Java, которые позволяют вам использовать GraphQL вместе с обнаружением сервисов, балансировщиком или API gateway из коробки. В этой статье я показал пример использования GQL и Unirest для создания GraphQL клиента вместе с Spring Cloud Eureka для микросервисной коммуникации. Пример кода автора статьи на английском на GitHub github.com/piomin/sample-graphql-microservices.git.
Пример моего когда с библиотекой GQL: github.com/lynx-r/sample-graphql-microservices
Комментарии (41)

Fengol
01.09.2018 13:43+1Может я не понимаю, но мне кажется, что graphql, это всего-лишь описание языка запросов. facebook, ещё создал описание того, как рекомендуется реализовывать логику запросов на клиенте и логику выдачи на сервере. То есть, api как было, так и осталось, только теперь оно не на уровне https, а на программном уровне. Ведь один контроллер не может делать все и сразу, придется разбить логику на множество контроллеров. Но доступ к ним будет не через https, а черз один рутовый контроллер. Кроме того описание того, как работать с логикой, придумали уже давно, это клиентское и серверное orm. Разница только в том, что они не в функциональном стиле и их придумали не в facebook.
Да, удобства от использования действительно есть. Но достигается оно за счет того, что из любого места приложения можно получить любые данные. То есть данные лежат в общей куче. В ооп, такое просто не допустимо. Но лично мне, как лежат данные, если их раскладываю не я лично, безразлично. Поэтомуон действительно делает работу проще и понятнее, при условии что есть готовые библиотеки, которые покрывают все потребности. Иначе придется окунутся в мир того, что только вчера придумали.apapacy
01.09.2018 14:14Вы правильно поняли. Но это как раз то чего не хватает restapi описания то есть стандарта, пусть даже не утвержденного сообществом. Попытка создать стандарт для restapi это jsonapi. Если сравнить с graphql то graphql проще и мощнее. Плюс встроенная документация и даже консоль для тестовых запросов.
zim32
02.09.2018 11:28Есть swagger. Не знаю можно ли его рассматриватт как некий стандарт но штука мощная с консолью и документацией.
apapacy
02.09.2018 11:36+1Swagger который теперь openapi это стандарт. Но стандарт в котором они определяются сервисы отдельно от реализации. То есть swagger отчасти созвучен graphql но не гарантирует соответствие сервисов их описанию в то время как graphql описание сервисов неразрывно связано с их реализацией и не может в принципе разойтись. Кроме того будет обеспечена валидация входных и выходных параметров сервиса при их вызове на соответствие описанию.
apapacy
01.09.2018 14:30+1С orm все хорошо пока Вам нужно вернуть плоский объект. Когда нужно вернуть скажем объект со связями то сразу возникает вопрос. А нужно ли возвращать связанные объекты? А все ли связанные объекты нужно возвращать? А нужно ли возвращать связанные объекты со связанными объектами и так далее по рекурсии. Если например нужно вернуть более одного разнородного объекта то это уже для фрнймвкркам задача не тривиальная. Плюс документация. Никто не когда не сталкивался с устаревшей документацией?
solver
01.09.2018 14:55Смешались в кучу, кони, люди…
То есть, api как было, так и осталось, только теперь оно не на уровне https, а на программном уровне.
API никогда и нигде не было на уровне https. Потому что https это транспортныый уровень, а не програмный. И graphql и rest и даже soap используют https для безопасного соединения, а не для реализации API.
Но доступ к ним будет не через https, а черз один рутовый контроллер.
В нормальном сервисе доступ всегда будет через https. А вот количество ендпоинтов в сервисе будет разным. В rest приложении будет много ендпоинтов, условно «на каждый случай». А в приложении с graphql будет один эндпоинт позволяющий получать различные данные.napa3um
01.09.2018 15:56+1HTTP, несмотря на парадоксальную расшифровку букв в своей аббревиатуре, является прикладным протоколом, application layer.
ZurgInq
01.09.2018 15:57API никогда и нигде не было на уровне https. Потому что https это транспортныый уровень, а не програмный. И graphql и rest и даже soap используют https для безопасного соединения, а не для реализации API.
К сожалению, rest API строится именно на уровне http (можно без s). Так называемый HTTP REST — это надстройка над http, который строго говоря, именно программный уровень. Можно использовать http исключительно как транспортный уровень, но для этого приложение не должно знать тонкости реализации уровня http, например не обрабатывать http коды ответов, что противоречит «правильному» rest.DarthVictor
01.09.2018 18:10К сожалению, rest API строится именно на уровне http (можно без s). Так называемый HTTP REST — это надстройка над http, который строго говоря, именно программный уровень. Можно использовать http исключительно как транспортный уровень, но для этого приложение не должно знать тонкости реализации уровня http, например не обрабатывать http коды ответов, что противоречит «правильному» rest.
Строго говоря, в оригинальном определении REST про правильные коды HTTP ничего нет, даже использование GET для запроса ресурса приводится лишь как пример. Все требования, о которых Вы пишете, придумали позднее.apapacy
02.09.2018 10:41+2В статье идёт скорее всего не о rest а о restapi. Rest это принципы построения приложений которое мы используем даже тогда когда об этом не подозреваем. Restapi это конкретно н где строго не описанная и не стандартизированная фича которая реализует crud сервисы посредством http методов put, get, update, delete и как вишенка в торте patch. Поначалу этот restapi очаровывает своей простотой. Потом когда переходишь от функционала todoapp к реальным приложениям, начинаешь желать чего то более стандартизированного.
Кстати restapi не выполняет всех принципов rest ТК как правило полагается на данные сессии клиента которые есть ни что иное как хранение состояния приложения на сервере. Я уже не говорю о смешении транспортного протокола с протоколом уровня приложения. Например сходу разобрать чего нет на сервере получив 404 ответ невозможно. user/joe — 404 это в базе нет пользователя Джо или же нет url user ТК сервис расположено по url users?
zelenin
01.09.2018 15:30Может я не понимаю, но мне кажется, что graphql, это всего-лишь описание языка запросов
а так же описание как эти запросы обрабатывать на стороне сервера. Другими словами это стандарт на API.
То есть данные лежат в общей куче
какие данные? чьи данные? в какой общей куче? На сервере у вас точно та же БД, что и была.
В ооп, такое просто не допустимо.
причем здесь ООП? Мы же про апи разговариваем.
Fengol
02.09.2018 10:27я про клиент. реализации, которые я видел, на клиенте все данные хранят в общем хранилище и доступны в любой части программы по запросу.
Huan
02.09.2018 12:48State management никак не связан с REST или GraphQL.
Fengol
02.09.2018 14:39я знаю что нет. и мне безразлично, что запросы к state manager выполняются путем строковых query, что просто распахивает ворота к ним для всех частей программы. главное удобно и быстро. Но не правильно! мне кажется, что эволюцию не должна деградировать. Это я относительно клиентской части говорю.Там так все таким образом эволюционирует, как-будто java и c# их ничему не научили.
Huan
02.09.2018 14:47Я во многом с Вами согласен, но тема то GraphQL. Понимаю, что фейсбук имеет отношение к появлению и того и другого, но все же.
zelenin
02.09.2018 16:23как уже сказали, с помощью state management строятся современные js-приложения, работающие с api или не работающие с api.
humbug
01.09.2018 15:10Ребята, а как разруливать права доступа в graphql?
apapacy
01.09.2018 15:13Этот вопрос graphql не ркшает. Скорее всего его Фейсбук делает это разделение на другом уровне приложения. С разделением доступа насколько мы знаем у них всё в порядке. Друзей друзей не выдают. Кому не следует по api
defint
01.09.2018 19:15Если API у роли полностью отличается, то это делается отдельным инстансом graphql (например, для админки и для пользователя полностью отличаются входные/выходные данные).
Если АПИ более-менее похожий, то разруливается на уровне резолверов.
Если используете Apollo, то вот есть статья, где расписывается как они работает через директивы: www.apollographql.com/docs/guides/access-control.html
teknik2008
02.09.2018 15:40Я сейчас думаю так сделать, на каждую роль сгенерировать свою схему доступа к определенным ресурсам и полям ресурсов. И помере прохождения пользователя по уровням авторизации переключать схемы. Мне не хочется решать на уровне резолверов, тк злоумышленник сможет видеть всю схему. Да можно разделить на 2 части (паблик, админ). Я считаю — что дано ролью то и пользователь должен видеть. + на основе схемы можно сразу строить фронт, отключая определенные элементы ui в зависимости доступности ресурсов. К примеру — нет доступа на создание статьи — нет формы. Я вижу это самым перспективным. Еще можно реализовать crud на клиенте, если дать всем типам вменяемые название. user_create, user_find, user_update, user_remove — первая часть до последнего нижнего подчеркивает складывается и на клиенте можно сделать объект user с 4-мя методами. ИМХО
apapacy
02.09.2018 16:01По поводу того что злоумышленник сможет видеть схему. Фейсбук опубликовал документацию на сервисы а которым доступ может получить и любое приложение и приложение после размещения клиента на доступ и по приложение которое запросило дополнительный доступ на Фейсбуке. Я лично такого никогда не получал думаю это не бесплатно. Так что схему в был все а доступ имеют не все.
Конечно есть у них и какие то админские схемы, скорее всего, на и внутри этих админские схемы также доступ разделен по полям и тп. Вообще тема разделения доступа в graphql пока открыта. И разделение схем это не решение ТК даже для самых простых случаев например типа блогов. Я и кю доступ к редактированию своих статей и к чтению чужих и тп не будешь же каждому юсеру свою схему даватьteknik2008
02.09.2018 16:46Я и кю доступ к редактированию своих статей и к чтению чужих и тп не будешь же каждому юсеру свою схему давать
— это одна схема, только какие именно записи можно решить на resolve. Но если есть различие, к примеру — кто-то может удалять комментарии — это уже 2 схемы. Не надо давать каждому схему, но отделить различные, по мне, лучше сразу на этапе генерации. Это более секьюрно, когда невидно что и как происходит на сервере. Сервер всегда должен быть черной коробкой для клиента.
Gemorroj
01.09.2018 16:15можно ли воспринимать graphql как современную реинкарнацию soap?
serf
01.09.2018 18:05+1На soap не особенно и похоже, а вот на OData да.
Envek
02.09.2018 15:38Похоже! 1-в-1, только на новомодных JSON'ах вместо старых-добрых XML-ей :trollface:
SOAP и GraphQL прям как близнецы-братья. Оба заявляют независимость от транспортного протокола, оба описывают формат взаимодействия и требуют описания схемы передаваемых данных (у SOAP — это WSDL), в которой описываются запросы и возвращаемые типы.serf
02.09.2018 16:34+2В SOAP жестко задан набор методов, с форматов запроса и ответа, RPC по сути. В GraphQL можно по одному ендпоинту вытянуть самые разлиные данные, так запрос на выборку формируется непосредственно на клиентской стороне. А вот в OData запрос как раз формируется на клиенте, GraphQL оттуда идея видимо и взяли и добавили легковестности и свой синтаксис запросов. Схожесть разе что в том что нужно описывать схему взаимодествия, но по этому признаку 90%+ всех форматов клиент-сервер взаимодействий будут похожи. К тому же SOAP громоздкая штуковина сама по себе.
intet
01.09.2018 18:20Нет решение основанных на Java, которые позволяют вам использовать GraphQL вместе с обнаружением сервисов, балансировщиком или API gateway из коробки
Балансировка и транспорт между сервисами это больная проблема подхода микросервисов. Сейчас в принципе нет простого подхода для решения проблем взаимодействия между отдельными сервисами.
Bsplesk
02.09.2018 08:12Первое, что нужно это определить подходит ли вам лицензия.
Первые версии были под патентами, потом (~год назад) тип лицензии был изменен на OWFa 1.0 (патенты никуда не делись, но права использование предоставили). Хотите ли вы быть связаны идеями/патентами facebook?
Упомянутая odatav4 от microsoft куда более гуманнее в этом деле + это реальный стандарт: www.oasis-open.org/committees/tc_home.php?wg_abbrev=odata, но microsoft не в моде, а там все очень даже на уровне, рекурсивные запросы в том числе + api строится от модели данных/DDD ложится хорошо — подход сначала подумать, а потом api рисовать.
Пусть меня заминусуют, но до WS-SOAP, где и асинхронность и распределенные транзакции и безопасность и не только http — им всем еще расти и расти, а там может и измениться веб. Web-socket — уже вполне, в том числе средства документирования асинхронных сервисов, webassembly потихоньку развивается и получает поддержку браузеров и возможно монополия js рухнет в ближайшем будущем и front и можно будет разрабатывать на различных языках.
Веб уходит от «чисто» страничек, сейчас всё больше SPA-приложений, размером в 20mb в сжатом виде уже никого не удивишь.
apapacy
02.09.2018 10:20Пусть меня заминусуют, но до WS-SOAP, где и асинхронность и распределенные транзакции и безопасность и не только http — им всем еще расти и расти, а там может и измениться веб.
Что Вы имеете в виду WS-SOAP не нашел такой аббревиатуры в поисуовой выдаче?
Никто не спорит с тем что SOAP мощный протокол. Но все же graphql имеет преимущество по сравнению с SOAP, хотя имеет и недостатки.
Я эти преимущества уже перечислил.
Graphql позволяет запрашивать произвольное количество разнородных объектов в одном запроса
Graphql позволяет запрашивать только необходимые поля и необходимые вложенные объекты
Graphql не только язык описания сервисов но имеет также принципы построения бэкэнда на основании функций resolver которые обеспечивают вот эту самую указанную выше функциональность.
Ну и в дополнение скажу что soap чрезмерно сложен. Хотя конечно проще чем CORBA. Не даром повсеместно вытесняет restapi. Из технологий которые имеют полноценную поддержку soap кроме к Майкрософт, это java, php, 1с. Node.js имеет две библиотеки и то с ограниченной поддержкой. Graphql все же проще. Он очень прост для понимания.
VolCh
03.09.2018 20:44Вроде же уже не один суд принял решение, что API не являются интеллектуальной собственностью.
Bsplesk
02.09.2018 15:16WS — сокращения от Web Services (еще называют «классическими» сервисами), и обычно читается, как сокращение соответствующего стека технологий (см. список ниже), SOAP просто указание на протокол обмена (среди которых может быть и XML-RPC к примеру)
Примеры:
- WS-Addressing
- WS-Discovery
- WS-MetadataExchange
- WS-Policy
- WS-ReliableMessaging
- WS-SecureConversation
- WS-Security
- WS-SecurityPolicy
- WS-Trust
www.w3.org/Submission/ws-addressing
К примеру: Spring-WS, JAX-WS
apapacy
02.09.2018 16:22Ну ws не такая однозначно принятая аббревиатура. В качестве аббревиатуры чаще применяется для веб сокетов ws://
Я именно и подумал что вы на советах предлагаете это сделать в первую очеркдь.
Bsplesk
02.09.2018 16:23Фишка REST, что он супер простой, дубовый(структуры описаны жестко), любой клиент который умеет работать с http сможет им пользоваться, что на мой взгляд — идеально для открытых(public) api.
Есть неплохой, простой инструмент создания контракта сервиса соответствующего спецификации (swagger editor), так и наоборот создание контракта по «коду».
И все ок пока всё просто, но как только «игрушки» кончаются, и начинается бизнес с его требованиями «Models with Polymorphism Support» смотря на открытие баги которые не правятся по несколько лет всё становится довольно уныло.
github.com/swagger-api/swagger-codegen/issues/6280
Они, конечно, потихонечку фиксятся, а иногда на них кладут болт. Так у нас появились свои генераторы.
Что касается: Graphql позволяет запрашивать произвольное количество разнородных объектов в одном запроса — так и в SOAP веб сервисах, это вообще не проблема.
Из известных реализаций: Посмотрите на Microsoft Dynamic CRM/MS SharePoint, как один из вариант реализации:
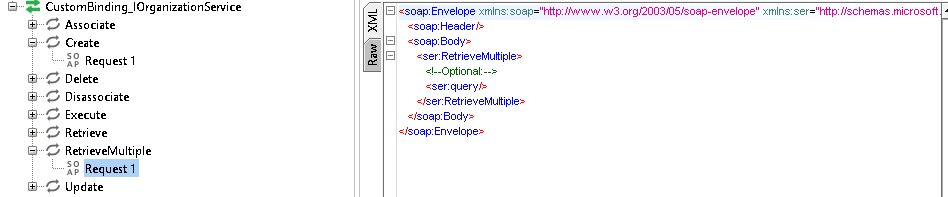
И да odatav4 от microsoft, которой сто лет в обед намного круче Graphql.
Реализаций «языков запросов» над http и не только уже столько… но тут вновь изобретают колесо.
Также не стоит забывать про такие вещи как JQL, который к примеру весьма успешно используется в jira.
Что касается: Он очень прост для понимания, на вкус и цвет, прост он только node.js/js разработчиков, более никому этот очереднойчеловекочитаемый*QL нафик не впился.
apapacy
02.09.2018 16:45-1Да не проблема в веб-сервисах запросить разнородные объекты. Весь вопрос в том что доля этого их предварительно необходимо описать для каждого случая. А в graphql это решает разработчик клиентской части приложения исходя из свои потребностей. Кстати graphql библиотеки не только на nodejs есть.
А кардинальное отличие graphql от swager/openapi в том что swaber/openapi это стандарт описания сервисов который даёт средство для документирования и запросов, но который никакие связан с кодом самих сервисов. Поэтому не гарантируется их соответствие. В graphql определение и документация серыисов является частью исполняемого кода поэтому всегда гарантируется их полная согласованность.
Bsplesk
02.09.2018 17:22Оооооо… habr
Всё таки ознакомьтесь с технологиями которые уже давно на рынке:
<ser:Retrieve> <!--Optional:--> <ser:entityName>contact</ser:entityName> <!--Optional:--> <ser:id>5CDAA018-1803-E611-811F-C4346BAC0910</ser:id> <!--Optional:--> <ser:columnSet> <!--Optional:--> <con:AllColumns>false</con:AllColumns> <!--Optional:--> <con:Columns> <!--Zero or more repetitions:--> <arr:string>fullname</arr:string> </con:Columns> </ser:columnSet> </ser:Retrieve>
— odatav4
http://srm.ent.ru/CRM/api/data/v8.1/contacts?$filter=main_document_number%20eq%20%000000%1111111111%27or%20(firstname%20eq%20%27Ivan%27%20and%20lastname%20eq%20%27Ivanov%27%20and%20middlename%20eq%20%27Ivanovish%27%20and%20birthdate%20eq%201991-01-10T21:00:00Z)&$expand=Contact_Appointments($orderby=scheduledstart%20asc;$filter=(scheduledstart%20ge%202018-01-01T05:00:00Z%20and%20scheduledstart%20le%202099-12-28T05:00:00Z);$top=5),Contact_Phonecalls($orderby=scheduledstart%20asc;$filter=(scheduledstart%20ge%202018-01-01T05:00:00Z%20and%20scheduledstart%20le%202099-12-28T05:00:00Z);$top=5)&$count=true
zelenin
03.09.2018 02:48Если бы производство нового останавливалось на ресерче старого рынка, то утром бы на работу вы поехали на бричке, и, дай бог, хотя бы на самоедущей, а не запряженной конями.
Суть не только в том, чтобы решить все проблемы связанные с апи и подготовить по этому документацию. Решение должно быть как можно проще, удобнее. Оно должно быть повернуто спиной к разработчику. И не только разработчику, который бородат и в свитере, но и только что вылупившемуся из яйца фронтендеру.
Если odata за 10+ лет так и осталась уделом 2.5 энтепрайзеров, то что-то здесь не так.
Bsplesk
02.09.2018 17:32даёт средство для документирования и запросов, но который никакие связан с кодом самих сервисов. --> связь прямая по контракту генерируются классы или наоборот.
apapacy
Я бы говоря о graphql в первую очередь акцентировал внимание на тот момент что
graphql это фактически стандарт
graphql это система которая жёстко связывает программный код и документацию. Документация всегда и на 100% актуальна
graphql позволяет без изменения на стороне бэкэнда делать запросы нескольких разнородных объектов в одном запроса, выбирать только необходимые для работы поля объектов, в том числе выбирать или не выбирать поля связанных объектов произвольной вложенности