
 Недавно мы рассказали, почему придумали свой RFM-сегментатор, который помогает сделать RFM-анализ за 20 секунд, и показали, как использовать его результаты в маркетинге.
Недавно мы рассказали, почему придумали свой RFM-сегментатор, который помогает сделать RFM-анализ за 20 секунд, и показали, как использовать его результаты в маркетинге.
Теперь рассказываем, как он устроен.
Задача: написать новый алгоритм RFM-анализа
Нас не устроили имеющиеся подходы к RFM-анализу. Поэтому мы решили сделать свой сегментатор, который:
- Работает полностью автоматически.
- Строит от 3 до 15 сегментов.
- Подстраивается под любую сферу деятельности клиента (неважно, что это: магазин цветов или электроинструментов).
- Определяет количество и расположение сегментов на основе имеющихся данных, а не заранее заданных параметров, которые не могут быть универсальными.
- Выделяет сегменты так, чтобы в них всегда были потребители (в отличие от некоторых подходов, когда часть сегментов оказываются пустыми).
Как решали задачу
Когда мы осознали задачу, поняли, что человеку она не под силу, и попросили помощи у искусственного интеллекта. Чтобы научить машину делить потребителей на сегменты, решили использовать методы кластеризации.
Методы кластеризации используются для поиска структуры в данных и выделения в них групп похожих объектов — как раз то, что нужно для RFM-анализа.
Кластеризация относится к методам машинного обучения класса «обучение без учителя». Класс называется так, потому что есть данные, но никто не знает, что с ними делать, поэтому не может научить машину.
Нам не удалось найти на рынке компании, использующие подобный подход. Хотя нашли одну статью, в которой автор проводит научное исследование на эту тему. Но, как мы поняли на собственном опыте, от науки до бизнеса совсем не один шаг.
Этап 1. Предобработка данных
К кластеризации данные нужно подготовить.
Сначала проверяем их на наличие некорректных значений: отрицательные величины и т. п.
Затем удаляем выбросы — потребителей с необычными характеристиками. Их немного, но они могут сильно повлиять на результат, причем не в лучшую сторону. Чтобы их отделить, используем специальный метод машинного обучения — Local Outlier Factor.

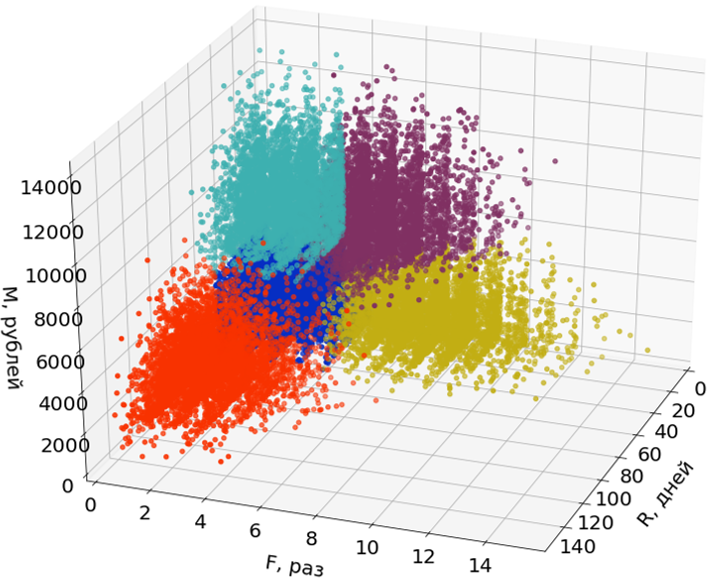
Здесь на картинках использую только два измерения (R и M) из трех для облегчения восприятия.
Выбросы не участвуют в построении сегментов, но распределяются по ним после того, как сегменты сформированы.
Этап 2. Кластеризация потребителей
Уточняю терминологию: кластерами я называю группы объектов, которые получаются в результате использования алгоритмов кластеризации, а сегментами — конечный результат, то есть результат RFM-анализа.
Алгоритмов кластеризации несколько десятков. Примеры работы некоторых из них можно посмотреть в документации пакета scikit-learn.
Мы попробовали восемь алгоритмов с различными модификациями. Большинству не хватало памяти. Или же время их работы стремилось к бесконечности. Почти все алгоритмы, которым технически удалось справиться с задачей, выдавали жутковатые результаты: например, популярный DBSCAN счел 55% объектов шумом, а остальные разделил на 4302 кластера.
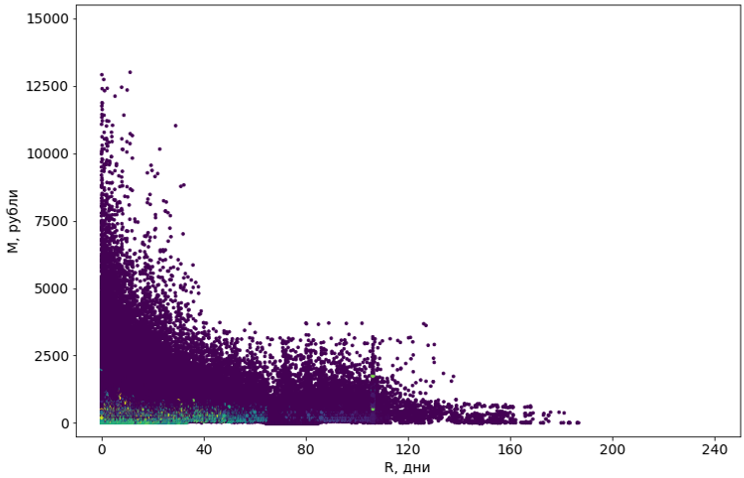
Фиолетовые объекты определены как «шум»
В результате мы выбрали алгоритм K-Means (K-средних), потому что он не ищет скоплений точек, а просто группирует точки вокруг центров. Как оказалось, это было верным решением.
Но сначала мы решили несколько проблем:
Неустойчивость. Это известная проблема большинства алгоритмов кластеризации и K-Means в том числе. Неустойчивость заключается в том, что при повторных запусках результаты могут быть разными, так как используется элемент случайности.
Поэтому мы кластеризуем многократно, а затем снова кластеризуем, но уже центры кластеров. В качестве конечных центров кластеров берем центры полученных кластеров (то есть кластеров, образованных центрами первых кластеров).
Число кластеров. Данные могут быть разными, и число кластеров тоже должно быть разным.
Чтобы найти оптимальное число кластеров для каждой базы потребителей мы проводим кластеризацию с разным числом кластеров, а затем выбираем лучший результат.
Скорость. Алгоритм K-means работает не очень быстро, но приемлемо (несколько минут для средней базы в несколько сотен тысяч потребителей). Однако мы запускаем его многократно: во-первых, для повышения устойчивости, во-вторых, для выбора числа кластеров. И время работы увеличивается очень сильно.
Для ускорения мы используем модификацию Mini Batch K-Means. Она пересчитывает центры кластеров на каждой итерации не по всем объектам, а только по небольшой подвыборке. Качество падает совсем немного, а вот время сокращается значительно.
Как только мы решили эти проблемы, кластеризация стала проходить успешно.
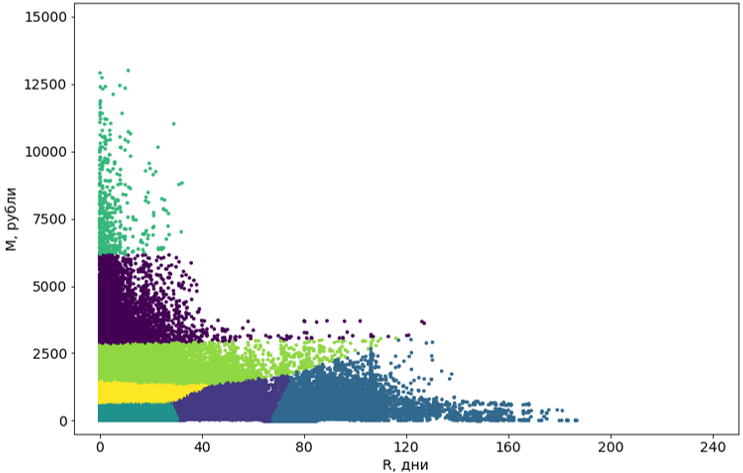
Этап 3. Постобработка кластеров
Полученные с помощью алгоритма кластеры нужно привести к удобному для восприятия виду.
Во-первых, мы превращаем эти кластеры из кривых в прямоугольные. Собственно, это и делает их сегментами. Прямоугольность сегментов — требование нашей системы и, кроме того, добавляет самим сегментам понятности. Для преобразования используем еще один алгоритм машинного обучения — дерево решений.
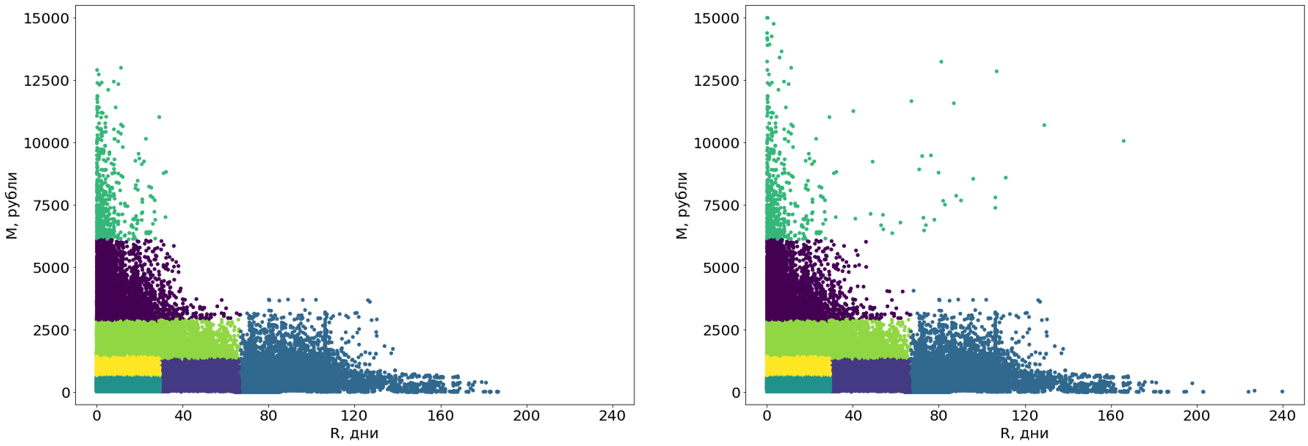
Решающее дерево строится на данных без выбросов, а выбросы затем распределяются по готовым сегментам
Во-вторых, мы сделали еще одну крутую штуку — описание сегментов. Специальный алгоритм, используя словарь, описывает каждый сегмент на живом русском языке, чтобы люди не испытывали тоску, глядя на бездушные цифры.

Тестирование результатов
Продукт готов. Но перед началом продаж его нужно протестировать. То есть проверить, выполняется ли RFM-анализ так, как мы задумали.
Мы знаем, что лучший способ понять, сделали ли мы что-то стоящее, это узнать, насколько анализ полезен нашим клиентам. И мы так и сделаем. Но это долго, и результаты будут потом, а мы хотим знать, насколько успешно мы справились с задачей, уже сейчас.
Поэтому в качестве более простой и быстрой метрики мы использовали метод «исторической контрольной группы».
Для этого взяли несколько баз данных и просегментировали их с помощью RFM-анализа на разные моменты прошлого: одну базу на состояние полгода назад, другую — год назад и т. д.
На основании каждой сегментации для каждой базы мы построили свой прогноз действий клиентов от выбранного момента до настоящего. Затем сравнили эти прогнозы с реальным поведением покупателей.

Пример тестирования на исторической контрольной группе с контрольным периодом полгода
На картинке:
- Столбцы R, F и M условно обозначают границы сегментов по каждой из осей. Это результат сегментации базы в том виде, в котором она была полгода назад.
- Столбец «Размер» показывает размер сегмента полгода назад относительно общего размера базы.
- Столбы «Вероятность покупки» и «Сумма» — это данные о реальном поведении потребителей в течение следующих полугода.
- Вероятность покупки определяется как отношение количества потребителей из сегмента, совершивших покупку, к общему количеству потребителей в сегменте.
- Сумма — общая потраченная потребителями из сегмента сумма относительно суммы, потраченной потребителями из всех сегментов.
Результаты совпали. Например, клиенты из сегментов, для которых мы прогнозировали высокую частоту покупок, действительно покупали чаще.
Хотя мы и не можем на основании такого тестирования гарантировать правильность работы алгоритма на 100 процентов, мы решили, что оно прошло успешно.
Что мы поняли
Машинное обучение реально способно помочь бизнесу решить нерешаемые или решаемые очень плохо задачи.
Но реальная задача — это не соревнование на Kaggle. Здесь, кроме достижения лучшего качества по заданной метрике, нужно подумать о том, сколько алгоритм будет работать, будет ли он удобен людям и, вообще, нужно ли решать задачу при помощи ML или можно придумать способ попроще.
И, наконец, отсутствие формальной метрики качества в несколько раз усложняет задачу, потому что трудно правильно оценить результат.
ioppoi
спасибо