
На выходе мы получаем транспортную систему, для добавления в которую новой сущности нужно будет ограничиться инициализацией одного бина в каждом элементе связки репозиторий-сервис-контроллер.
Сразу ресурсы.
Ветка, как я не делаю: standart_version.
Подход, о котором рассказывается в статье, в ветке abstract_version.
Я собрал проект через Spring Initializr, добавив фреймворки JPA, Web и H2. Gradle, Spring Boot 2.0.5. Этого будет вполне достаточно.

Для начала, рассмотрим классический вариант транспорта от контроллера до репозитория и обратно, лишённый всякой дополнительной логики. Если же Вы хотите перейти к сути подхода, проматывайте вниз до абстрактного варианта. Но, всё же, рекомендую прочитать статью целиком.
Классический вариант.
В ресурсах примера представлены несколько сущностей и методов для них, но в статье пусть у нас будет только одна сущность User и только один метод save(), который мы протащим от репозитория через сервис до контроллера. В ресурсах же их 7, а вообще Spring CRUD / JPA Repository позволяют использовать около дюжины методов сохранения / получения / удаления плюс Вы можете пользоваться, к примеру, какими-то своими универсальными. Также, мы не будем отвлекаться на такие нужные вещи, как валидацию, мапинг dto и прочее. Это Вы сможете дописать сами или изучить в других статьях Хабра.
Domain:
@Entity
public class User implements Serializable {
private Long id;
private String name;
private String phone;
@Id
@GeneratedValue
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Column(nullable = false)
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Column
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
//equals, hashcode, toString
}Repository:
@Repository
public interface UserRepository extends CrudRepository<User, Long> {
}Service:
public interface UserService {
Optional<User> save(User user);
}Service (имплементация):
@Service
public class UserServiceImpl implements UserService {
private final UserRepository userRepository;
@Autowired
public UserServiceImpl(UserRepository userRepository) {
this.userRepository = userRepository;
}
@Override
public Optional<User> save(User user) {
return Optional.of(userRepository.save(user));
}
}Controller:
@RestController
@RequestMapping("/user")
public class UserController {
private final UserService service;
@Autowired
public UserController(UserService service) {
this.service = service;
}
@PostMapping
public ResponseEntity<User> save(@RequestBody User user) {
return service.save(user).map(u -> new ResponseEntity<>(u, HttpStatus.OK))
.orElseThrow(() -> new UserException(
String.format(ErrorType.USER_NOT_SAVED.getDescription(), user.toString())
));
}
}У нас получился некий набор зависимых классов, которые помогут нам оперировать сущностью User на уровне CRUD. Это в нашем примере по одному методу, в ресурсах их больше. Этот нисколько не абстрактный вариант написания слоёв представлен в ветке standart_version.
Допустим, нам нужно добавить ещё одну сущность, скажем, Car. Мапить на уровне сущностей мы их друг к другу не будем (если есть желание, можете замапить).
Для начала, создаём сущность.
@Entity
public class Car implements Serializable {
private Long id;
private String brand;
private String model;
@Id
@GeneratedValue
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
//геттеры, сеттеры, equals, hashcode, toString
}Потом создаём репозиторий.
public interface CarRepository extends CrudRepository<Car, Long> {
}Потом сервис…
public interface CarService {
Optional<Car> save(Car car);
List<Car> saveAll(List<Car> cars);
Optional<Car> update(Car car);
Optional<Car> get(Long id);
List<Car> getAll();
Boolean deleteById(Long id);
Boolean deleteAll();
}Потом имплементация сервиса…… Контроллер………
Да, можно просто скопипастить те же методы (они же у нас универсальные) из класса User, потом поменять User на Car, потом проделать то же самое с имплементацией, с контроллером, далее на очереди очередная сущность, а там уже выглядывают ещё и ещё… Обычно устаёшь уже на второй, создание же служебной архитектуры для пары десятков сущностей (копипастинг, замена имени сущности, где-то ошибся, где-то опечатался...) приводит к мукам, которые вызывает любая монотонная работа. Попробуйте как-нибудь на досуге прописать двадцать сущностей и Вы поймёте, о чём я.
И вот, в один момент, когда я как раз увлекался дженериками и типовыми параметрами, меня осенило, что процесс можно сделать гораздо менее рутинным.
Итак, абстракции на основе типовых параметров.
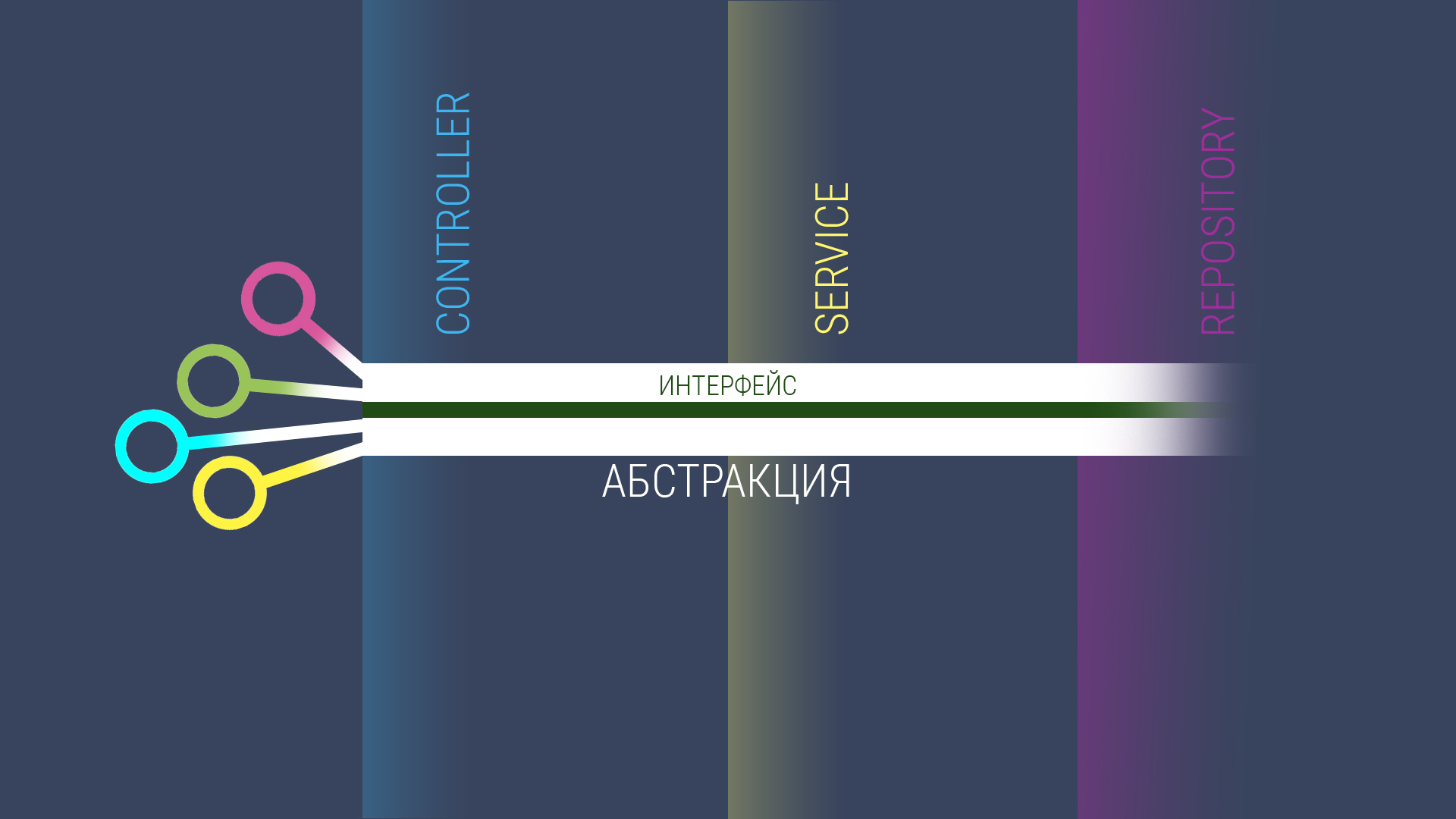
Смысл данного подхода заключается в том, чтобы вынести всю логику в абстракцию, абстракцию привязать к типовым параметрам интерфейса, а в бины инжектить другие бины. И всё. Никакой логики в бинах. Только инжект других бинов. Этот подход предполагает написать архитектуру и логику один раз и не дублировать её при добавлении новых сущностей.
Начнём с краеугольного камня нашей абстракции — абстрактной сущности. Именно с неё начнётся цепочка абстрактных зависимостей, которая послужит каркасом сервиса.
У всех сущностей есть как минимум одно общее поле (обычно больше). Это ID. Вынесем это поле в отдельную абстрактную сущность и унаследуем от неё User и Car.
AbstractEntity:
@MappedSuperclass
public abstract class AbstractEntity implements Serializable {
private Long id;
@Id
@GeneratedValue
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
}Не забудьте пометить абстракцию аннотацией @MappedSuperclass — Hibernate тоже должен узнать, что это абстракция.
User:
@Entity
public class User extends AbstractEntity {
private String name;
private String phone;
//...
}С Car, соответственно, то же самое.
В каждом слое у нас, помимо бинов, будет один интерфейс с типовыми параметрами и один абстрактный класс с логикой. Кроме репозитория — благодаря специфике Spring Data JPA, здесь всё будет намного проще.
Первое, что нам потребуется в репозитории — общий репозиторий.
CommonRepository:
@NoRepositoryBean
public interface CommonRepository<E extends AbstractEntity> extends CrudRepository<E, Long> {
}В этом репозитории мы задаём общие правила для всей цепочки: все сущности, участвующие в ней, будут наследоваться от абстрактной. Далее, для каждой сущности мы должны написать свой репозиторий-интерфейс, в котором обозначим, с какой именно сущностью будет работать эта цепочка репозиторий-сервис-контроллер.
UserRepository:
@Repository
public interface UserRepository extends CommonRepository<User> {
}На этом, благодаря особенностям Spring Data JPA, настройка репозитория заканчивается — всё будет работать и так. Далее следует сервис. Мы должны создать общий интерфейс, абстракцию и бин.
CommonService:
public interface CommonService<E extends AbstractEntity> { {
Optional<E> save(E entity);
//какое-то количество нужных нам методов
}AbstractService:
public abstract class AbstractService<E extends AbstractEntity, R extends CommonRepository<E>>
implements CommonService<E> {
protected final R repository;
@Autowired
public AbstractService(R repository) {
this.repository = repository;
}
//другие методы, переопределённые из интерфейса
}Здесь мы переопределяем все методы, а также, создаём параметризированный конструктор для будущего репозитория, который мы переопределим в бине. Таким образом, мы уже используем репозиторий, который мы ещё не определили. Мы пока не знаем, какая сущность будет обработана в этой абстракции и какой репозиторий нам потребуется.
UserService:
@Service
public class UserService extends AbstractService<User, UserRepository> {
public UserService(UserRepository repository) {
super(repository);
}
}В бине мы делаем заключительную вещь — явно определяем нужный нам репозиторий, который потом вызовется в конструкторе абстракции. И всё.
При помощи интерфейса и абстракции мы создали магистраль, по которой будем гонять все сущности. В бине же мы подводим к магистрали развязку, по которой будем выводить нужную нам сущность на магистраль.
Контроллер строится по тому же принципу: интерфейс, абстракция, бин.
CommonController:
public interface CommonController<E extends AbstractEntity> {
@PostMapping
ResponseEntity<E> save(@RequestBody E entity);
//остальные методы
}AbstractController:
public abstract class AbstractController<E extends AbstractEntity, S extends CommonService<E>>
implements CommonController<E> {
private final S service;
@Autowired
protected AbstractController(S service) {
this.service = service;
}
@Override
public ResponseEntity<E> save(@RequestBody E entity) {
return service.save(entity).map(ResponseEntity::ok)
.orElseThrow(() -> new SampleException(
String.format(ErrorType.ENTITY_NOT_SAVED.getDescription(), entity.toString())
));
}
//другие методы
}UserController:
@RestController
@RequestMapping("/user")
public class UserController extends AbstractController<User, UserService> {
public UserController(UserService service) {
super(service);
}
}Это вся структура. Она пишется один раз.
Что дальше?
И вот теперь давайте представим, что у нас появилась новая сущность, которую мы уже унаследовали от AbstractEntity, и нам нужно прописать для неё такую же цепочку. На это у нас уйдёт минута. И никаких копипаст и исправлений.
Возьмём уже унаследованный от AbstractEntity Car.
CarRepository:
@Repository
public interface CarRepository extends CommonRepository<Car> {
}CarService:
@Service
public class CarService extends AbstractService<Car, CarRepository> {
public CarService(CarRepository repository) {
super(repository);
}
}CarController:
@RestController
@RequestMapping("/car")
public class CarController extends AbstractController<Car, CarService> {
public CarController(CarService service) {
super(service);
}
}Как мы видим, копирование одинаковой логики состоит в простом добавлении бина. Не надо заново писать логику в каждом бине с изменением параметров и сигнатур. Они написаны один раз и работают в каждом последующем случае.
Заключение
Конечно, в примере описана этакая сферическая ситуация, в которой CRUD для каждой сущности имеет одинаковую логику. Так не бывает — какие-то методы Вам всё равно придётся переопределять в бине или добавлять новые. Но это будет происходить от конкретных потребностей обработки сущности. Хорошо, если процентов 60 от общего количества методов CRUD будет оставаться в абстракции. И это будет хорошим результатом, потому что чем больше мы генерим лишнего кода вручную, тем больше времени мы тратим на монотонную работу и тем выше риск ошибки или опечатки.
Надеюсь, статья была полезна, спасибо за внимание.
UPD.
Благодаря предложению aleksandy удалось вынести инициализацию бина в конструктор и тем самым значительно улучшить подход. Если Вы видите, как ещё можно улучшить пример, пишите в комментариях, и, возможно, Ваши предложения будут внесены.Комментарии (24)

aleksandy
24.09.2018 10:21Если в абстрактные классы сервиса.контроллера добавить конструктор, принимающий репозиторий/сервис, то и геттеры не нужно будет писать в наследниках. Достаточно только сузить тип аргумента в наследнике.
public abstract class AbstractController< E extends AbstractEntity, R extends CommonRepository<E>, S extends CommonService<E, R>> implements CommonController<E, R, S> { private final S service; protected AbstractController(S service) { this.service = service; } public getService() { return this.service; } }
public class UserController extends AbstractController<User, UserRepository, UserService> { public UserController(UserService service) { super(service); } }xpendence Автор
24.09.2018 10:45Да, это действительно, круто. Я добавлю, с Вашего позволения, Ваше замечание в статью.
dididididi
24.09.2018 11:13Спасибо за статью. А вот чтоб не писать по контроллеру/сервису на каждую Entity, припахать фильтр на контроллер, чтоб он делал CRUD по имени Entity? Я пытался у нас сделать, но времени не хватило.
xpendence Автор
24.09.2018 11:34Да, я размышлял об этом подходе, с тем, чтобы попытаться вообще обойтись без бинов, но без них тут, к сожалению, никак, потому что на каком-то этапе нужно будет добавлять / переопределять персональные реализации методов, и тогда для каждой сущности необходимо будет создавать бин и ломать архитектуру. Под это дело есть, как было указано в комментарии выше, Spring Data Rest, но для приложений с хоть какой-то логикой он не подходит. В любом случае, спасибо за комментарий!
dididididi
25.09.2018 09:43Фи-фи-фи… Но тут нет к сожалению стримов, дженериков, опшиналов, спринг дата, сервисов, интерфейсов, энтитей, наследования и копипаста сервисов, контроллеров, и репозиториев для каждой энтити. Всего одна строчка делает все, что Ваш код и еще немного)))). Хотя я не знаю как спринг сериализует ResultSet.
@RestController @RequestMapping("/rest") public class Rest Controller{ @RequestMapping("/{tableName}/read}") public ResultSet read(String tableName) { return dbConnection.prepareStatement("Select * from "+tableName.replaceAll(" ","")).executeQuery();xpendence Автор
25.09.2018 10:27Первый комментатор к посту описал подход, при котором эндпоинт тащится в репозиторий. Вы описали подход, при котором репозиторий тащится в контроллер. Я ему, кстати, тоже описал, в чём, на мой взгляд, заключается несостоятельность такого подхода. И Вам, кстати, тоже.
А что это у Вас за класс такой модный, Rest Controller?dididididi
25.09.2018 11:14Ой, не придирайся к опечаткам. Там еще по синтаксису есть проблемы, например @RequestMapping на методе и tableName тоже вроде какой то аннотации требует. А в чем проблема архитектуры? Архитектура-норм, есть общий крудКонтроллер, для стандартных КРУД запросов, а если тебе надо добавить метод, пишешь цепочку контроллер-сервис-репозиторий-энтити без всяких дженериков. Писанины меньше, код примитивный и понятный, как лом.
xpendence Автор
25.09.2018 11:38Да, согласен, ошибками и опечатками Ваш код кишит. Проблема Вашего подхода в том, что бэкенд-разработка давно ушла от низкоуровнего программирования, которое Вы описываете. Конечно, в старых компаниях, особенно в банковском секторе, очень много легаси-проектов, на которых, предположу, Вы выросли. Если же Вы считаете Ваш подход правильным и современным, напишите об этом статью. Если вылезете из минусов, конечно. Всего хорошего.
dididididi
25.09.2018 15:45И сразу на личности, Слава(((И карма-то у меня низкая, и опечатки в коде. Причем здесь высоко-низко, использовать надо то, что подходит и удобно, а не то, что стильно, молодежно и с подворотами. Данную задачу мож удобней сделать sql и Spring MVC, в другой использовать дженерики и спринг дату.
Ждем следующую статью, как с помощью вейпа, гироскутера и смузи смыть за собой в туалете;)xpendence Автор
25.09.2018 22:26Короче, пришёл Дмитрий Дьячков и занялся своим любимым занятием разводить бессмысленные дискуссии ни о чём. Карма -8 — это показатель, Дмитрий.
Я рад тебя видеть на просторах Хабра, но очередному бесполезному спору я не рад. Продолжать его не буду. Лучше займись делом и почитай хорошую статью, вместо того, чтобы убеждать себя, почему очередная технология тебе не нужна.
Почему больше всего «прорывных идей, простых как лом», исходит от людей, которые не могут освоить даже инкапсуляцию, не говоря уже про стримы?dididididi
26.09.2018 14:50Нуу блин, ты еще забыл сказать, что я так и не смог освоить
модный и современный метод Objects.notNull() и у меня вызывает искреннее удивление его использование;).
А про карму спасибо, что сказал, я сегодня узнал о ее существовании))
solver
24.09.2018 12:38У вас примеры совсем не равнозначны. В простом примере контроллер завязан только на сервис. Что правильно. А вот в абстрактном примере к контроллер прибит гвоздями к сервису и даже знает про сущность через параметры. Это ненормально)
xpendence Автор
24.09.2018 13:04Не совсем понял, о чём Вы. В простом примере сервис явно автовайрится в контроллер, а сущность вшита в сигнатуру каждого метода. В абстрактном примере в бине мы переопределяем только конструктор. И да, конечно, мы задаём сущность через параметры, потому что один бин работает только с одной сущностью. Если где-то сервисный бин работает сразу с несколькими сущностями, вот это как раз ненормально :)
Кстати, ресурсы и код в примере обновился благодаря толковому предложению одного из комментаторов. Теперь в бине мы переопределяем только конструктор абстракции (которого ранее не было). Рекомендую ознакомиться с изменениями — возможно, тогда разногласия исчезнут :)solver
24.09.2018 15:43Дело не в том, что и где вы переопределяете, а что с чем связано.
Вот, в новом варианте более правильно сделано. Зависимость на репозиторий уехала из контроллера в сервис. Это гораздо более правильный вариант. Не должен контроллер ничего знать про то как хранится сущность.
braincooler
24.09.2018 21:59Почему не инжектить так:
@Autowired private final S service;xpendence Автор
24.09.2018 22:07Потому что Spring рекомендует инжектить через конструктор.
Более подробно Вы можете ознакомиться с вопросом в посте одного из контрибьюторов Spring Оливера Гирке.
Как Вы наверняка знаете, бин — это синглтон. Использовать один и тот же бин для всех сервисов при многопоточном подходе не безопасно, и Spring не рекомендует этого делать. Поэтому намного более безопасным подходом будет создать финальную копию бина и использовать её.
IoannGolovko
25.09.2018 09:13Потому что это и не скомпилируется вовсе)
А что будет, если конструктор добавить, уж лучше и не проверять)))xpendence Автор
25.09.2018 09:16Скомпилироваться-то скомпилируется, если конструктор оставить, но сам подход неправильный, Вы правы.
popandopolos
26.09.2018 11:22Не совсем про Spring Data (мы его пока не используем), но в тему Spring + Generics. Я реализовал следующий подход, который позволяет не использовать никакие общие абстрактные классы. Правда, потребовалась кастомная аннотация и фабрика для реализаций DAO.
Использование выглядит всего лишь вот так:
@Autowired @CoreDaoClass(Car.class) private CoreDao<Car> carDao;
Аннотация:
@Target(ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) @Qualifier("coreDaoByAnnotation") public @interface CoreDaoClass { Class<?> value(); }
Ну и фабрика для конкретных реализаций DAO:
@Configuration public class CoreDaoFactory { @Bean @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) @Lazy public <C> CoreDao<C> coreDaoForClass(Class<C> cls) { return new CoreDaoImpl<>(cls); } @Bean @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) @Lazy public CoreDao<?> coreDaoByAnnotation(InjectionPoint ip) { CoreDaoClass annotation = AnnotationUtils.findAnnotation(ip.getAnnotatedElement(), CoreDaoClass.class); if (annotation == null) { throw new NoSuchBeanDefinitionException("CoreDao", "CoreDaoClass is not defined"); } return new CoreDaoImpl<>(annotation.value()); } }
aol-nnov
Есть такая штука — spring data rest. :)
Там все тоже самое, только hateoas на выходе ) но я им, если честно, не проникся и колхозил решение, как в этой статье...
How not to hate hateoas? ;)
xpendence Автор
Если я не ошибаюсь, Spring Data Rest пришивает endpoint прямо к репозиторию. Такой подход не подразумевает сервиса и контроллера. То есть, Вы можете потом именно что "наколхозить", как Вы выразились, отдельно сервис и репозиторий и пройти всю цепочку для нестандартных запросов. Но тогда у Вас будет две параллельных архитектуры, с эндпоинтами в контроллере и репозитории.
Spring Data Rest, по моему мнению, подходит в том случае, если функция сервера чисто утилитарна и сводится к функциям "взять / положить в репозиторий".
aol-nnov
Да, я ещё забыл написать — зачем в вашей абстрактной системе сервис, который лишь вызывает метод репозитория? Не проще ли сразу реп инжектить в контроллер, раз уж пошла такая пьянка?
По поводу утилитарности — пример в статье тоже "взять/положить". Говорю же, как s-d-r, только "без крыльев" и "с перламутровыми пуговицами",
xpendence Автор
Сервис как раз затем, что, как написано в конце статьи, Вам неизбежно придётся добавлять какую-то дополнительную логику для обработки сущностей — переопределять существующие абстрактные методы и писать новые. Если, конечно, приложение шагает за рамки работы с репозиторием.
Конечно, пример в статье максимально лаконичен, чтобы как можно меньше отвлекать читателя от сути (в ресурсах он немного более развёрнут). Вы бы ещё спросили, почему я тесты не написал :)))
werklop
YAGNI, не, не слышали