
Вкратце:
- Пруф уже реализован на C++, JS и PHP, подходит для Java.
- Быстрее чем coroutine и Promise, больше фич.
- Не требует выделения отдельного программного стека.
- Дружит со всеми средствами безопасности и отладки.
- Работает на любой архитектуре и не требует особых флагов компилятора.
Взгляд назад
На заре ЭВМ был единый поток управления c блокировкой на ввод-вывод. Потом к нему добавили прерывания железа. Появилась возможность эффективного использования медленных и непредсказуемых устройств.
С ростом возможностей железа и его малой доступности, появилась необходимость выполнять несколько задач одновременно, что снабдили аппаратной поддержкой. Так появились изолированные процессы с абстрагированными от железа прерываниями в виде сигналов.
Следующим эволюционным этапом стала многопоточность, которая была реализована на фундаменте тех же процессов, но с общим доступом к памяти и другим ресурсам. Такой подход имеет свои ограничения и существенные накладные расходы на переключение в безопасной ОС.
Для общения между между процессами и даже различными машинами был предложена абстракция Promise/Future ещё 40+ лет назад.
Пользовательские интерфейсы и смешная сейчас проблема 10K клиентов привели к периоду расцвета Event Loop, Reactor и Proactor подходов, которые больше ориентированы на обработку событий чем ясную последовательную бизнес-логику.
Наконец пришли к современным coroutine (сопрограмма), которые по сути являются эмуляцией потоков поверх описанных выше абстракций с соответствующими техническими ограничениями и детерминированной передачей управления.
Для передачи событий, результата и исключений вернулись всё к той же концепции Promise/Future. Кое-какие конторы решили назвать чуть иначе — "Task".
В конечном счёте всё спрятали в красивую упаковку async/await, которая требует поддержки компилятора или транслятора в зависимости от технологии.
Проблемы с текущий ситуаций асинхронной бизнес-логики
Рассмотрим только coroutines и Promise, украшенные async/await, т.к. наличие проблем в более старых подходах подтверждает сам процесс эволюции.
Эти два термина не тождественны. Например, в ECMAScript нет сопрограмм, а есть синтаксические облегчения для использования Promise, которое в свою очередь лишь организует работу с адом обратных вызовов (callback hell). По факту, скриптовые движки вроде V8 идут дальше и делают особые оптимизации для чистых async/await функций и вызовов.
Высказывания экспертов о не попавших в C++17 co_async/co_await есть здесь на ресурсе, но давлением софтверного гиганта сопрограммы таки могут появиться в стандарте именно в их виде. Пока же традиционное признанное решение Boost.Context, Boost.Fiber и Boost.Coroutine2.
В Java так же до сих пор нет async/await на уровне языка, но есть такие решения как EA Async, которые как и Boost.Context необходимо подгоняться под каждую версию JVM и байт кода.
В Go присутствуют свои сопрограммы, но если внимательно посмотреть статьи и баг репорты открытых проектов, то выясняется что и здесь не всё так гладко. Возможно, потеря интерфейса сопрограммы как управляемой сущности не лучшая идея.
Мнение автора: сопрограммы на голом железе опасны
Лично автор мало чего имеет против сопрограмм в динамических языках, но крайне насторожено относится к любым заигрываниям со стеком на уровне машинного кода.
Несколько тезисов:
- Требуется выделять стек:
- стек на куче имеет целый ряд недостатков: проблемы своевременного определения переполнения, повреждение соседями и прочие проблемы надежности/безопасности,
- защищённый стек требует минимум одну страницу физической памяти, одну условную страницу и дополнительные накладные расходы для каждого вызова
asyncфункции: 4+KB (минимум) + повышенные системные лимиты, - в конечном итоге может быть так, что значительная часть выделенной под стеки памяти не используется во время простоя сопрограммы.
- Необходимо реализовать комплексную логику сохранения, восстановления и удаления состояния сопрограмм:
- под каждый случай архитектуры процессора (даже модели) и бинарного интерфейса (ABI): пример,
- новые или опциональные фичи архитектуры вносят потенциально латентные проблемы (например, Intel TSX, со-процессоры ARM или MIPS),
- другие потенциальные проблемы из-за закрытой документации проприетарных систем (документация Boost на это ссылается).
- Потенциальные проблемы с инструментами динамического анализа и с безопасностью в целом:
- например, требуется интеграция с Valgrind всё из-за тех же скачущих стеков,
- сложно говорить за антивирусы, но вероятно не особо им это нравится на примере проблем с JVM в прошлом,
- уверен, появятся новые виды атак и будут вскрыты уязвимости, связанные именно с реализацией сопрограмм.
Мнение автора: генераторы и yield принципиальное зло
Эта казалось бы сторонняя тема прямо связана с концепцией сопрограмм и свойства "продолжения".
Если вкратце, то для любой коллекции должен существовать полноценный итератор. Для чего создавать проблему обрезанного итератора-генератора — не понятно. Например, кейс с range() в Python скорее эксклюзивный выпендрёж, чем оправдание технического усложнения.
Если же кейс бесконечного генератора, то и логика его реализации элементарна. Для чего создавать дополнительные технические сложности чтобы внутри пихать бесконечный продолжаемый цикл.
Единственное дельное позже появившееся оправдание, которое приводят сторонники сопрограмм — это всякого рода поточные парсеры с инвертированием управления. По сути, это узкий специализированный кейс решения единичных проблем уровня библиотек, а не бизнес-логики приложений. При этом есть элегантное, простое и более дескриптивное решение через конечные автоматы. Область этих технических проблем сильно меньше области банальной бизнес-логики.
По факту, решаемая проблема получается высосана из пальца и требует сравнительно серьёзных усилий для изначальной реализации и длительной поддержки. На столько, что некоторые проекты могут ввести запрет на использование сопрограмм уровня машинного кода по примеру запрета на goto или использования динамического выделения памяти в отдельных индустриях.
Мнение автора: модель async/await на Promise из ECMAScript более надёжна, но требует адаптации
В отличии от продолжаемых сопрограмм, в этой модели куски кода скрытно делятся на непрерываемые блоки, оформленные в виде анонимных функций. В С++ это не совсем подходит из-за особенностей управления памятью, пример:
struct SomeObject {
using Value = std::vector<int>;
Promise funcPromise() {
return Promise.resolved(value_);
}
void funcCallback(std::function<void()> &&cb, const Value& val) {
somehow_call_later(cb);
}
Value value_;
};
Promise example() {
SomeObject some_obj;
return some_obj.funcPromise()
.catch([](const std::exception &e){
// ...
})
.then([&](SomeObject::value &&val){
return Promise([&](Resolve&& resolve, Reject&&){
some_obj.funcCallback(resolve, val);
});
});
}Во-первых, some_obj будет разрушен при выходе из example() и до вызова лямбда-функций.
Во-вторых, лямбда-функции с захватом переменных или ссылок являются объектами и скрытно добавляют копирование/перемещение, что может отрицательно сказаться на производительности при большом количестве захватов и необходимости выделять память на куче в ходе type erasure в обычной std::function.
В-третьих, сам интерфейс Promise зачат на концепции "обещания" результата, а не последовательного выполнения бизнес-логики.
Схематичное НЕ оптимальное решение может выглядеть примерно так:
Promise example() {
struct LocalContext {
SomeObject some_obj;
};
auto ctx = std::make_shared<LocalContext>();
return some_obj.funcPromise()
.catch([](const std::exception &e){
// ...
})
.then([ctx](SomeObject::Value &&val){
struct LocalContext2 {
LocalContext2(std::shared_ptr<LocalContext> &&ctx, SomeObject::Value &&val) :
ctx(ctx), val(val)
{}
std::shared_ptr<LocalContext> ctx;
SomeObject::Value val;
};
auto ctx2 = std::make_shared<LocalContext2>(
std::move(ctx),
std::forward<SomeObject::Value>(val)
);
return Promise([ctx2](Resolve&& resolve, Reject&&){
ctx2->ctx->some_obj.funcCallback([ctx2, resolve](){ resolve(); }, val);
});
});
}Примечание: std::move вместо std::shared_ptr не подходит из-за невозможности передачи в несколько лямбд сразу и роста их размера.
С добавлением async/await асинхронные "ужасы" приходят в удобоваримое состояние:
async void example() {
SomeObject some_obj;
try {
SomeObject::Value val = await some_obj.func();
} catch (const std::exception& e) (
// ...
}
// Capture "async context"
return Promise([async](Resolve&& resolve, Reject&&){
some_obj.funcCallback([async](){ resolve(); }, val);
});
}Мнение автора: планировщик сопрограмм — это перебор
Некоторые критики называют проблемой отсутствие планировщика и "нечестное" использование ресурсов процессора. Возможно более серьёзная проблема — это локальность данных и эффективное использование кэша процессора.
По первой проблеме: приоритизация на уровне отдельных сопрограмм выглядит большим оверхедом. Вместо этого ими возможно оперировать в общности для конкретной унифицированной задачи. Так поступают с транспортными потоками.
Такое возможно путём создания отдельных экземпляров Event Loop с собственными "железными" потоками и планированием на уровне ОС. Второй вариант — синхронизировать сопрограммы относительно ограничивающего по конкуренции и(или) производительности примитива (Mutex, Throttle).
Асинхронное программирование не делает ресурсы процессора резиновыми и требует абсолютно обычных ограничений по количеству одновременно обрабатываемых задач и ограничения общего времени выполнения.
Защита от длительного блокирования на одной сопрограмме требует тех же мер что и с обратными вызовами — избегать блокирующих системных вызовов и длительных циклов обработки данных.
По второй проблеме требуется исследование, но как минимум сами стеки сопрограмм и детали реализации Future/Promise уже нарушают локальность данных. Есть возможность пытаться продолжить выполнение той же сопрограммы, если Future уже имеет значение. Требуется некий механизм подсчёта времени выполнения или количества таких продолжений чтобы не дать одной сопрограмме захватить всё время процессора. Такое может либо не дать результата, либо дать весьма двоякий результат в зависимости от размера кэша процессора и количества потоков.
Есть ещё и третий момент — многие реализации планировщиков сопрограмм позволяют выполнять их на разных ядрах процессора, что наоборот добавляет проблем из-за обязательной синхронизации при доступе к общим ресурсам. В случае же единого потока Event Loop'а такая синхронизация требуется только на логическом уровне, т.к. каждый синхронный блок обратного вызова гарантированно работает без гонки с другими.
Мнение автора: всё хорошо в меру
Наличие потоков в современных ОС не отменяет использования отдельных процессов. Так же, обработка большого количества клиентов в Event Loop не отменяет использование обособленных "железных" потоков для иных нужд.
В любом случае, сопрограммы и различные варианты Event Loop'ов усложняют процесс отладки без необходимой поддержки в инструментах, а с локальными переменными на стеке сопрограмм всё становится ещё сложнее — к ним практически не добраться.

FutoIn AsyncSteps — альтернатива сопрограммам
За основу возьмём уже хорошо зарекомендовавший себя паттерн Event Loop и организацию схемы обратных вызовов по типу ECMAScript(JavaScript) Promise.
С точки зрения планирования выполнения нас интересуют следующие действия от Event Loop:
- Незамедлительный обратный вызов
Handle immediate(callack)с требованием чистого стека вызовов. - Отложенный обратный вызов
Handle deferred(delay, callback). - Отмена обратного вызова
handle.cancel().
Так получаем интерфейс с названием AsyncTool, который может быть реализован множеством способов, включая поверх уже существующих проверенных разработок. Прямого отношения к написанию бизнес-логики он не имеет, поэтому не будем вдаваться в дальнейшие детали.
Дерево шагов:
В концепции AsyncSteps, выстраивается абстрактное дерево синхронных шагов и выполняется проходом в глубину в последовательности создания. Шаги каждого более глубокого уровня динамично задаются по мере выполнения такого прохода.
Всё взаимодействие происходит через единый интерфейс AsyncSteps, который по конвенции передаётся первым параметром в каждый шаг. По конвенции название параметра asi или устарелое as. Такой подход позволяет практически полностью разорвать связь между конкретной реализацией и написанием бизнес-логики в плагинах и библиотеках.
В каноничных реализациях, каждый шаг получает свой экземпляр объекта, реализующего AsyncSteps, что позволяет своевременно отслеживать логические ошибки в использовании интерфейса.
Абстрактный пример:
asi.add( // Level 0 step 1
func( asi ){
print( "Level 0 func" )
asi.add( // Level 1 step 1
func( asi ){
print( "Level 1 func" )
asi.error( "MyError" )
},
onerror( asi, error ){ // Level 1 step 1 catch
print( "Level 1 onerror: " + error )
asi.error( "NewError" )
}
)
},
onerror( asi, error ){ // Level 0 step 1 catch
print( "Level 0 onerror: " + error )
if ( error strequal "NewError" ) {
asi.success( "Prm", 123, [1, 2, 3], true)
}
}
)
asi.add( // Level 0 step 2
func( asi, str_param, int_param, array_param ){
print( "Level 0 func2: " + param )
}
)Результат выполнения:
Level 0 func 1
Level 1 func 1
Level 1 onerror 1: MyError
Level 0 onerror 1: NewError
Level 0 func 2: PrmВ синхронном виде выглядело бы так:
str_res, int_res, array_res, bool_res // undefined
try {
// Level 0 step 1
print( "Level 0 func 1" )
try {
// Level 1 step 1
print( "Level 1 func 1" )
throw "MyError"
} catch( error ){
// Level 1 step 1 catch
print( "Level 1 onerror 1: " + error )
throw "NewError"
}
} catch( error ){
// Level 0 step 1 catch
print( "Level 0 onerror 1: " + error )
if ( error strequal "NewError" ) {
str_res = "Prm"
int_res = 123
array_res = [1, 2, 3]
bool_res = true
} else {
re-throw
}
}
{
// Level 0 step 2
print( "Level 0 func 2: " + str_res )
}Сразу видна максимальная мимикрия традиционного синхронного кода, что должно помогать в читаемости.
С точки зрения бизнес-логики со временем нарастает большой ком требований, но мы можем разделить его на легко понимаемые части. Описанное ниже, результат обкатки на практике на протяжении четырёх лет.
Базовые API времени выполнения:
add(func[, onerror])— имитацияtry-catch.success([args...])— явное указание успешного завершения:
- подразумевается по умолчанию,
- может передавать результаты на вход в следующий шаг.
error(code[, reason)— прерывание выполнения с ошибкой:
code— имеет строковой тип чтобы лучше интегрироваться с сетевыми протоколами в микросервисной архитектуре,reason— произвольное пояснение для человека.
state()— аналог Thread Local Storage. Предопределённые ассоциативные ключи:
error_info— пояснение последний ошибки для человека,last_exception— указатель на объект последнего исключения,async_stack— стек асинхронных вызовов на сколько позволяет технология,- остальное — задаётся пользователем.
Предыдуший пример уже с реальным С++ кодом и некоторыми дополнительными фичами:
#include <futoin/iasyncsteps.hpp>
using namespace futoin;
void some_api(IAsyncSteps& asi) {
asi.add(
[](IAsyncSteps& asi) {
std::cout << "Level 0 func 1" << std::endl;
asi.add(
[](IAsyncSteps& asi) {
std::cout << "Level 1 func 1" << std::endl;
asi.error("MyError");
},
[](IAsyncSteps& asi, ErrorCode code) {
std::cout << "Level 1 onerror 1: " << code << std::endl;
asi.error("NewError", "Human-readable description");
}
);
},
[](IAsyncSteps& asi, ErrorCode code) {
std::cout << "Level 0 onerror 1: " << code << std::endl;
if (code == "NewError") {
// Human-readable error info
assert(asi.state().error_info ==
"Human-readable description");
// Last exception thrown is also available in state
std::exception_ptr e = asi.state().last_exception;
// NOTE: smart conversion of "const char*"
asi.success("Prm", 123, std::vector<int>({1, 2, 3}, true));
}
}
);
asi.add(
[](IAsyncSteps& asi, const futoin::string& str_res, int int_res, std::vector<int>&& arr_res) {
std::cout << "Level 0 func 2: " << str_res << std::endl;
}
);
}API для создания циклов:
loop( func, [, label] )— шаг с бесконечно повторяемым телом.forEach( map|list, func [, label] )— шаг-итерация по объекту коллекции.repeat( count, func [, label] )— шаг-итерация указанное количество раз.break( [label] )— аналог традиционного прерывания цикла.continue( [label] )— аналог традиционного продолжения цикла с новой итерации.
Спецификация предлагает альтернативные названия breakLoop, continueLoop и прочие в случае конфликта с зарезервированными словами.
Пример C++:
asi.loop([](IAsyncSteps& asi) {
// infinite loop
asi.breakLoop();
});
asi.repeat(10, [](IAsyncSteps& asi, size_t i) {
// range loop from i=0 till i=9 (inclusive)
asi.continueLoop();
});
asi.forEach(
std::vector<int>{1, 2, 3},
[](IAsyncSteps& asi, size_t i, int v) {
// Iteration of vector-like and list-like objects
});
asi.forEach(
std::list<futoin::string>{"1", "2", "3"},
[](IAsyncSteps& asi, size_t i, const futoin::string& v) {
// Iteration of vector-like and list-like objects
});
asi.forEach(
std::map<futoin::string, futoin::string>(),
[](IAsyncSteps& asi,
const futoin::string& key,
const futoin::string& v) {
// Iteration of map-like objects
});
std::map<std::string, futoin::string> non_const_map;
asi.forEach(
non_const_map,
[](IAsyncSteps& asi, const std::string& key, futoin::string& v) {
// Iteration of map-like objects, note the value reference type
});API интеграции с внешними событиями:
setTimeout( timeout_ms )— вызывает ошибкуTimeoutпо истечению времени, если шаг и его поддерево не закончили выполнение.setCancel( handler )— устанавливает обработчик отмены, который вызывается при общей отмене потока и при разворачивании стека асинхронных шагов во время обработки ошибки.waitExternal()— простое ожидание внешнего события.
- Примечание: безопасно использовать только в технологиях со сборщиком мусора.
Вызов любой из этих функций делает необходимым явный вызов success().
Пример C++:
asi.add([](IAsyncSteps& asi) {
auto handle = schedule_external_callback([&](bool err) {
if (err) {
try {
asi.error("ExternalError");
} catch (...) {
// pass
}
} else {
asi.success();
}
});
asi.setCancel([=](IAsyncSteps& asi) { external_cancel(handle); });
});
asi.add(
[](IAsyncSteps& asi) {
// Raises Timeout error after specified period
asi.setTimeout(std::chrono::seconds{10});
asi.loop([](IAsyncSteps& asi) {
// infinite loop
});
},
[](IAsyncSteps& asi, ErrorCode code) {
if (code == futoin::errors::Timeout) {
asi();
}
});Пример ECMAScript:
asi.add( (asi) => {
asi.waitExternal(); // disable implicit success()
some_obj.read( (err, data) => {
if (!asi.state) {
// ignore as AsyncSteps execution got canceled
} else if (err) {
try {
asi.error( 'IOError', err );
} catch (_) {
// ignore error thrown as there are no
// AsyncSteps frames on stack.
}
} else {
asi.success( data );
}
} );
} );API интеграции с Future/Promise:
await(promise_future[, on_error])— ожидание Future/Promise как шаг.promise()— превращает весь поток выполнения в Future/Promise, используется вместоexecute().
Пример C++:
[](IAsyncSteps& asi) {
// Proper way to create new AsyncSteps instances
// without hard dependency on implementation.
auto new_steps = asi.newInstance();
new_steps->add([](IAsyncSteps& asi) {});
// Can be called outside of AsyncSteps event loop
// new_steps.promise().wait();
// or
// new_steps.promise<int>().get();
// Proper way to wait for standard std::future
asi.await(new_steps->promise());
// Ensure instance lifetime
asi.state()["some_obj"] = std::move(new_steps);
};API контроля потока выполнения бизнес-логики:
AsyncSteps(AsyncTool&)— конструктор, который привязывает поток выполнения к конкретному Event Loop.execute()— запускает поток выполнения.cancel()— отменяет поток выполнения.
Здесь уже требуется конкретная реализация интерфейса.
Пример C++:
#include <futoin/ri/asyncsteps.hpp>
#include <futoin/ri/asynctool.hpp>
void example() {
futoin::ri::AsyncTool at;
futoin::ri::AsyncSteps asi{at};
asi.loop([&](futoin::IAsyncSteps &asi){
// Some infinite loop logic
});
asi.execute();
std::this_thread::sleep_for(std::chrono::seconds{10});
asi.cancel(); // called in d-tor by fact
}прочие API:
newInstance()— позволяет создать новый поток выполнения без прямой зависимости на реализацию.sync(object, func, onerror)— то же, но с синхронизацией относительно объекта, реализующего соответствующий интерфейс.parallel([on_error])— специальныйadd(), подшаги которого представляют из себя отдельные потоки AsyncSteps:
- у всех потоков общий
state(), - родительский поток продолжает выполнения по завершению всех дочерних,
- не перехваченная ошибка в любом дочернем сразу отменяет все остальные дочерние потоки.
- у всех потоков общий
Примеры C++:
#include <futoin/ri/mutex.hpp>
using namespace futoin;
ri::Mutex mtx_a;
void sync_example(IAsyncSteps& asi) {
asi.sync(mtx_a, [](IAsyncSteps& asi) {
// synchronized section
asi.add([](IAsyncSteps& asi) {
// inner step in the section
// This synchronization is NOOP for already
// acquired Mutex.
asi.sync(mtx_a, [](IAsyncSteps& asi) {
});
});
});
}
void parallel_example(IAsyncSteps& asi) {
using OrderVector = std::vector<int>;
asi.state("order", OrderVector{});
auto& p = asi.parallel([](IAsyncSteps& asi, ErrorCode) {
// Overall error handler
asi.success();
});
p.add([](IAsyncSteps& asi) {
// regular flow
asi.state<OrderVector>("order").push_back(1);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(4);
});
});
p.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(2);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(5);
asi.error("SomeError");
});
});
p.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(3);
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order").push_back(6);
});
});
asi.add([](IAsyncSteps& asi) {
asi.state<OrderVector>("order"); // 1, 2, 3, 4, 5
});
};Стандартные примитивы для синхронизации
Mutex— ограничивает одновременное исполнение вNпотоков с очередью вQ, по умолчаниюN=1, Q=unlimited.Throttle— ограничивает количество входовNв периодPс очередью вQ, по умолчаниюN=1, P=1s, Q=0.Limiter— комбинацияMutexиThrottle, которая типично используется на входе обработки внешних запроса и при вызове внешних систем с целью устойчивой работы под нагрузкой.
В случае выхода за лимиты очереди, поднимается ошибка DefenseRejected, смысл которой ясен из описания Limiter.
Ключевые преимущества
Концепция AsyncSteps не была самоцелью, а родилась вследствие необходимости более контролируемого асинхронного выполнения программ с точки зрения лимита времени, отмены и в целом связности отдельных обратных вызовов. Ни одно из универсальных решений на тот момент и сейчас не предоставляет такой же функциональности. Поэтому:
Единая спецификация FTN12 для всех технологий — быстрая адаптация для разработчиков при переключение с одной технологии на другую.
Интеграция отмены setCancel() — позволяет отменять все внешние запросы и подчищать ресурсы ясным и безопасным способом при внешней отмене или появлении ошибки времени исполнения. Это избегает проблемы асинхронного выполнения тяжёлых задач, результат которых уже не требуется. Это аналог RAII и atexit() в традиционном программировании.
Непосредственно отмена выполнения cancel() — типично используется при отсоединении клиента, истечения максимального срока выполнения запроса или иных причин завершения. Это аналог SIGTERM или pthread_cancel(), оба из которых весьма специфичны в реализации.
Таймеры отмены шага setTimeout() — типично используется для ограничения общего времени выполнения запроса и для ограничения времени ожидания подзапросов и внешних событий. Действуют на всё поддерево, выкидывает перехватываемую ошибку "Timeout".
Интеграция с другими технологиями асинхронного программирования — использование FutoIn AsyncSteps не требует отказываться от уже используемых технологий и не требует разработки новых библиотек.
Универсальная реализация на уровне конкретного языка программирования — нет необходимости в специфичных и потенциально опасных с изменениями ABI манипуляциях на уровне машинного кода, которые требуются для сопрограмм. Хорошо подходит для Embedded и безопасно на неполноценных MMU.

К цифрам
Для тестов используется Intel Xeon E3-1245v2/DDR1333 с Debian Stretch и последним обновлением микрокода.
Сравниваются пять вариантов:
- Boost.Fiber с
protected_fixedsize_stack. - Boost.Fiber с
pooled_fixedsize_stackи выделением на общей куче. - FutoIn AsyncSteps в стандартном исполнении.
- FutoIn AsyncSteps в динамически отключенным пулом памяти (
FUTOIN_USE_MEMPOOL=false).
- приведено лишь для свидетельства эффективности
futoin::IMemPool.
- приведено лишь для свидетельства эффективности
- FutoIn NitroSteps<> — альтернативная реализация со статическим выделением всех буферов во время создания объекта.
- конкретные параметры лимитов задаются в виде продвинутых параметров шаблона.
Ввиду функциональной ограниченности Boost.Fiber сравниваются следующие показатели производительности:
- Последовательное создание и выполнение 1 млн. потоков.
- Параллельное создание потоков с лимитом в 30 тыс. и исполнение 1 млн. потоков.
- ограничение в 30 тыс. исходит из потребности вызывать
mmap()/mprotect()дляboost::fiber::protected_fixedsize_stack. - большая цифра так же выбрана для давления на кэш процессора.
- ограничение в 30 тыс. исходит из потребности вызывать
- Параллельное создание 30 тыс. потоков и 10 млн. переключений в ожидании внешнего события.
- в обоих случаях "внешнее" событие удовлетворяется в отдельном потоке в рамках той же технологии.
Используется одно ядро и один "железный" поток, т.к. это позволяет добиться максимальной производительности, исключая гонки на спинлоках и атомарных операциях. Наилучшие значения из серии тестов идут в результат. Проверяется стабильность показателей.
Сборка сделана с GCC 6.3.0. Результаты с Сlang и tcmalloc также проверялись, но различия несущественны для статьи.
Исходный код тестов доступен на GitHub и GitLab.
1. Последовательное создание
| Технология | Время | Гц |
|---|---|---|
| Boost.Fiber protected | 4.8s | 208333.333Hz |
| Boost.Fiber pooled | 0.23s | 4347826.086Hz |
| FutoIn AsyncSteps | 0.21s | 4761904.761Hz |
| FutoIn AsyncSteps no mempool | 0.31s | 3225806.451Hz |
| FutoIn NitroSteps | 0.255s | 3921568.627Hz |
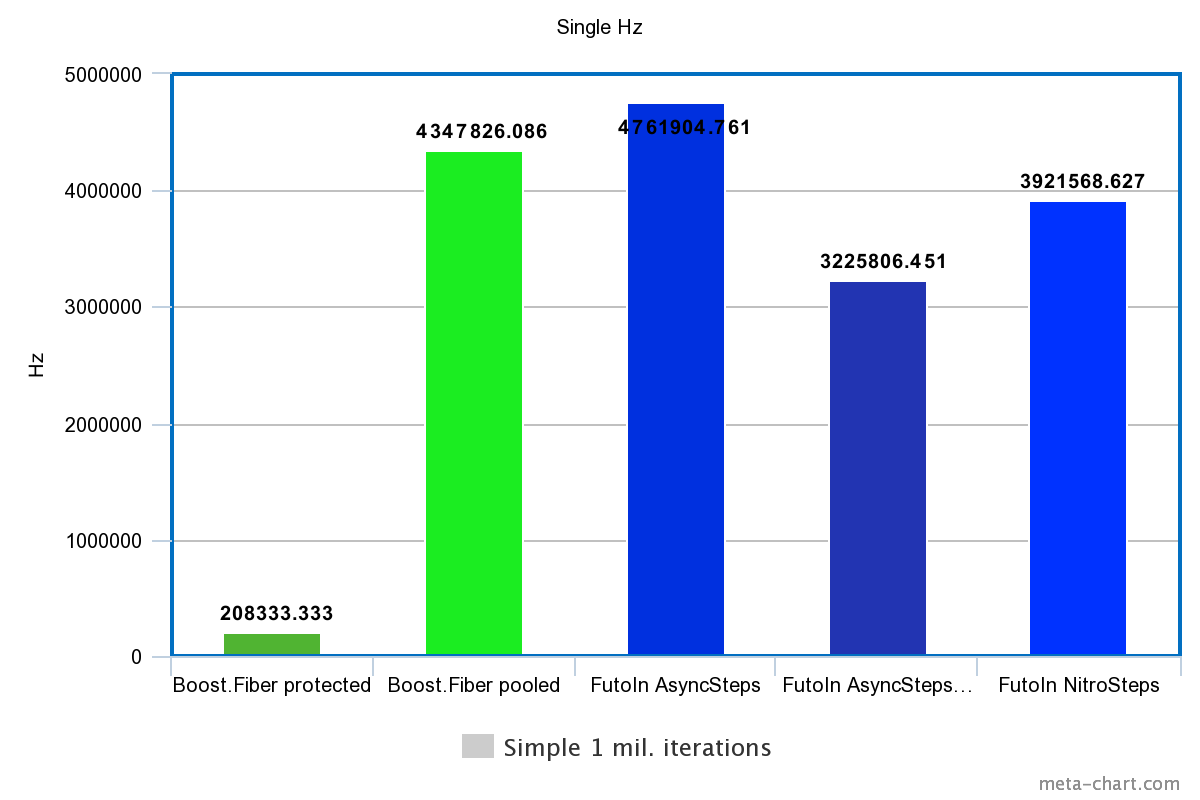
Больше — лучше.
Здесь основная потеря у Boost.Fiber из-за системных вызовов работы со страницами памяти, но даже менее безопасный pooled_fixedsize_stack оказывается более медленным, чем стандартная реализация AsyncSteps.
2. Параллельное создание и исполнение
| Технология | Время | Гц |
|---|---|---|
| Boost.Fiber protected | 6.31s | 158478.605Hz |
| Boost.Fiber pooled | 1.558s | 641848.523Hz |
| FutoIn AsyncSteps | 1.13s | 884955.752Hz |
| FutoIn AsyncSteps no mempool | 1.353s | 739098.300Hz |
| FutoIn NitroSteps | 1.43s | 699300.699Hz |
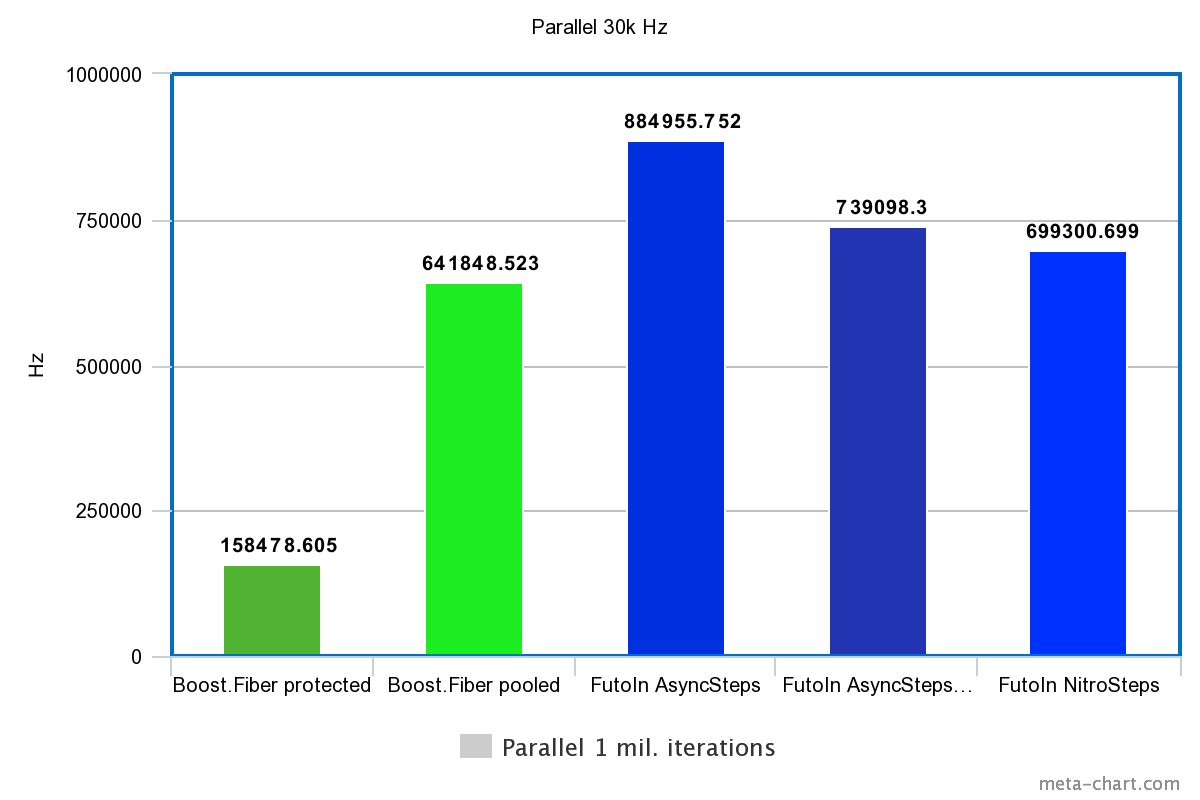
Больше — лучше.
Здесь те же проблемы, но мы видим значительное замедление по сравнению с первым тестом. Нужен более детальный анализ, но теоретическая догадка указывает на неэффективность кэширования — выборочные значения количества параллельных потоков дают картину функции с множеством явных изломов.
3. Параллельные циклы
| Технология | Время | Гц |
|---|---|---|
| Boost.Fiber protected | 5.096s | 1962323.390Hz |
| Boost.Fiber pooled | 5.077s | 1969667.126Hz |
| FutoIn AsyncSteps | 5.361s | 1865323.633Hz |
| FutoIn AsyncSteps no mempool | 8.288s | 1206563.706Hz |
| FutoIn NitroSteps | 3.68s | 2717391.304Hz |
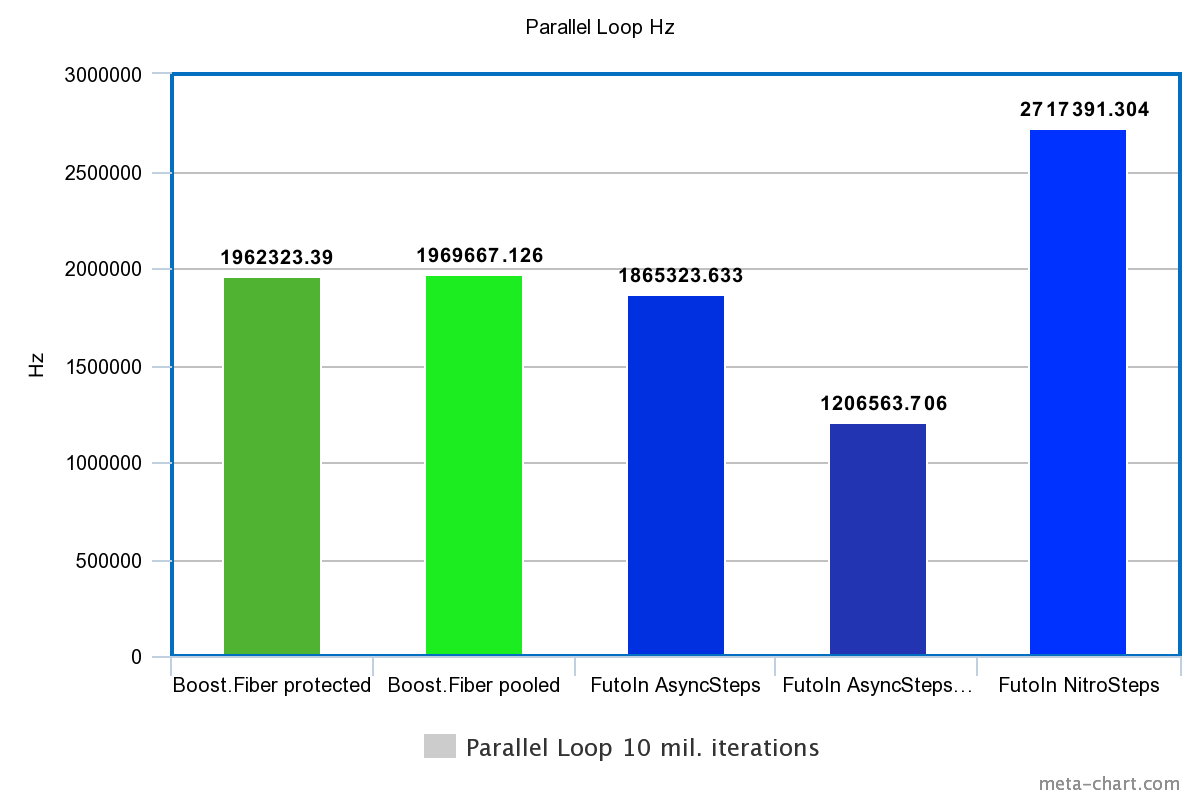
Больше — лучше.
Убирая оверхед создания, мы видим что в голом переключении потоков Boost.Fiber начинает выигрывать у стандартной реализации AsyncSteps, но значительно проигрывает NitroSteps.
Использование памяти (по RSS)
| Технология | Память |
|---|---|
| Boost.Fiber protected | 124M |
| Boost.Fiber pooled | 505M |
| FutoIn AsyncSteps | 124M |
| FutoIn AsyncSteps no mempool | 84M |
| FutoIn NitroSteps | 115M |
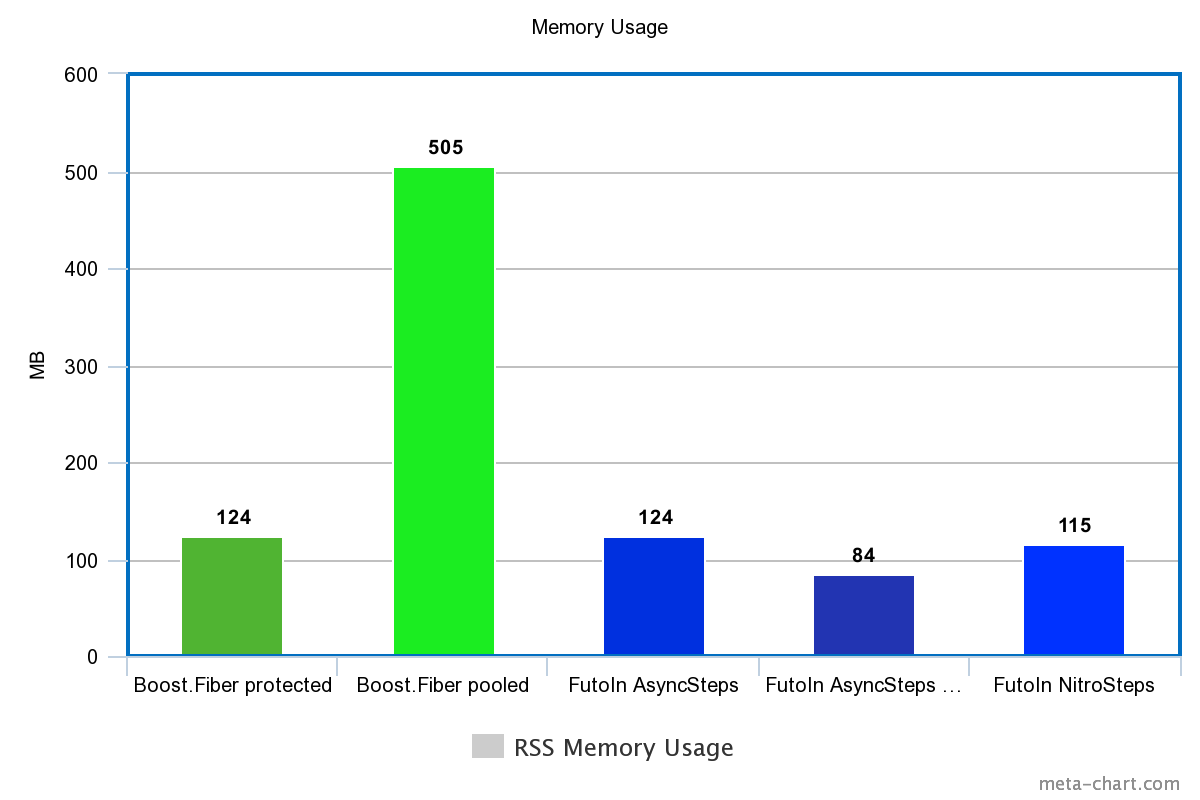
Меньше — лучше.
И снова, Boost.Fiber нечем гордиться.
Бонус: тесты на Node.js
Всего два теста так же из-за ограниченности Promise: создание+выполнение и циклы по 10 тыс. итераций. Каждый тест 10 секунд. Берутся средние значения в Гц второго прохода после оптимизирующего JIT при NODE_ENV=production, используя пакет @futoin/optihelp.
Исходный код так же на GitHub и GitLab. Используются версии Node.js v8.12.0 и v10.11.0, установленные через FutoIn CID.
| Tech | Simple | Loop |
|---|---|---|
| Node.js v10 | ||
| FutoIn AsyncSteps | 1342899.520Hz | 587.777Hz |
| async/await | 524983.234Hz | 630.863Hz |
| Node.js v8 | ||
| FutoIn AsyncSteps | 682420.735Hz | 588.336Hz |
| async/await | 365050.395Hz | 400.575Hz |
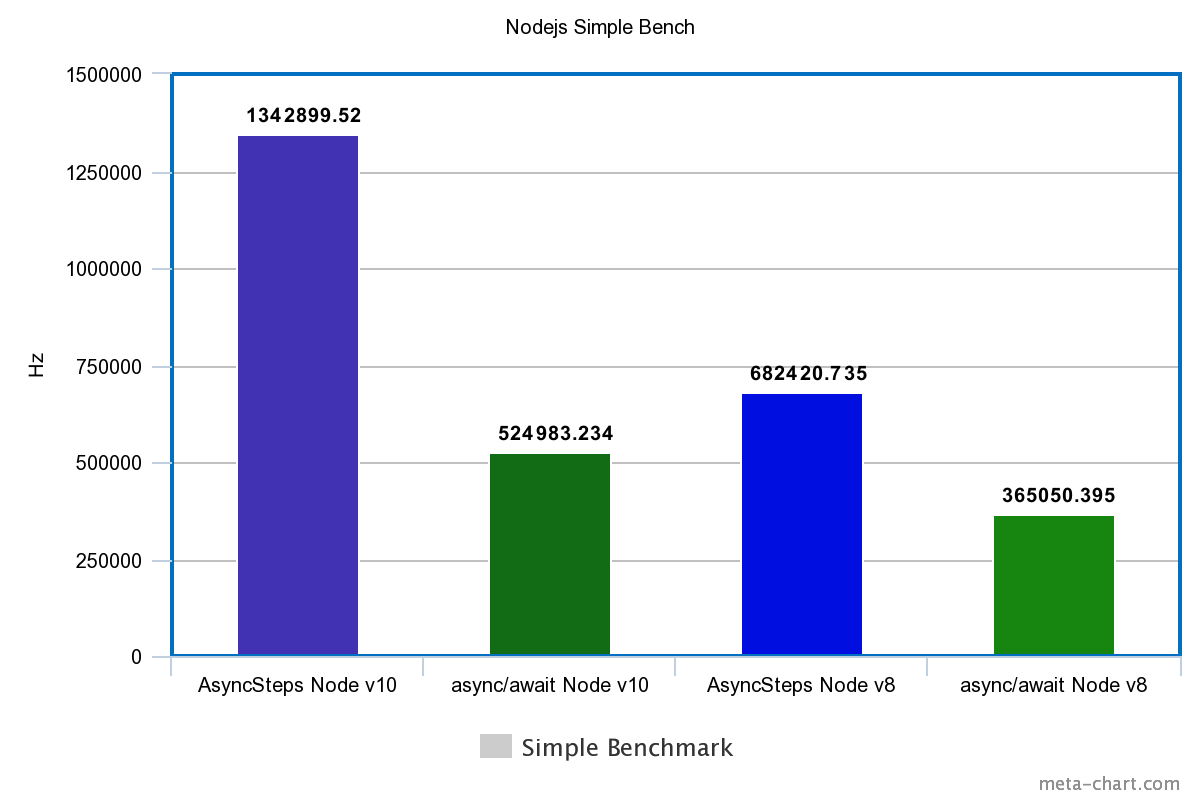
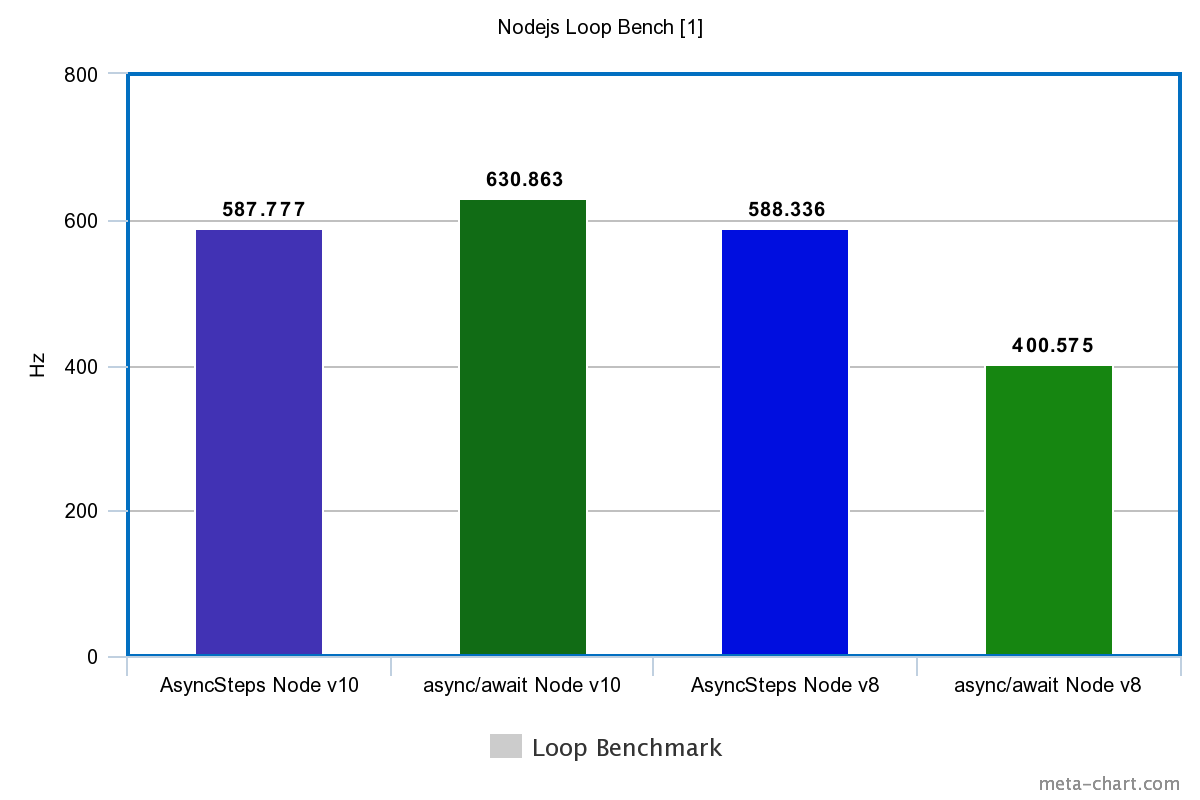
Больше — лучше.
Внезапный разгром async/await? Да, но в V8 для Node.js v10 подтянули оптимизацию циклов и стало чуть лучше.
Стоит добавить, что реализация Promise и async/await блокирует Node.js Event Loop. Бесконечный цикл без ожидания внешнего события попросту повесит процесс (пруф), но с FutoIn AsyncSteps такого не случается.
Периодический выход из AsyncSteps в Node.js Event Loop и есть причина ложной победы async/await в тесте-цикле на Node.js v10.
Оговорюсь, что сравнивать показатели производительности с С++ будет некорректно — разная реализация методологии тестирования. Для приближения, результаты тестирования циклов Node.js нужно умножить на 10 тыс.
Выводы
На примере C++, FutoIn AsyncSteps и Boost.Fiber показывают схожую длительную производительность и потребление памяти, а вот на запуске Boost.Fiber серьёзно проигрывает и ограничен системными лимитами по количеству mmap()/mprotect.
Максимальная производительность зависит от эффективного использования кэша, но в реальной жизни данные бизнес-логики могут оказывать большее давление на кэш, чем реализация сопрограмм. Вопрос полноценного планировщика остаётся открытым.
FutoIn AsyncSteps для JavaScript превосходит async/await в производительности даже в последней версии Node.js v10.
В конечном счёте, основная нагрузка должна быть непосредственно от бизнес-логики, а не от реализации концепции асинхронного программирования. Поэтому незначительные отклонения не должны быть существенным аргументом.
Разумно написанная бизнес-логика внедряет асинхронные переходы только когда подразумевается ожидание внешнего события в любом виде или когда объём обрабатываемых данных слишком велик и на долго блокирует "железный" поток выполнения. Исключение из этого правила — написание библиотечных API.
Заключение
Принципиально, интерфейс FutoIn AsyncSteps проще, понятнее и более функционален чем любые из конкурентов без "сахара" async/await. Вдобавок, он реализован стандартными средствами и унифицирован для всех технологий. Как и в случае с Promise из ECMAScript, AsyncSteps может получить свой "сахар" и его поддержку в компиляторах или средах выполнения практически любого языка.
Замеры производительности не сильно оптимизированной реализации показывают сравнимые и даже превосходящие результаты относительно альтернативных технологий. Гибкость возможной реализации доказана двумя разными подходами AsyncSteps и NitroSteps для единого интерфейса.
Помимо уже указанной выше спецификации, есть ориентированная на разработчика-пользователя документация.
По запросам возможна реализация версии для Java/JVM или любого другого языка с адекватными анонимными функциями — иначе читаемость кода падает. Любая помощь проекту приветствуется.
Если вам действительно нравится такая альтернатива, то не стесняйтесь поставить звёздочки на GitHub и/или GitLab.
Комментарии (57)

mayorovp
25.09.2018 19:23стек на куче имеет целый ряд недостатков
Зато локальные переменные в куче чувствуют себя превосходно.
Необходимо реализовать комплексную логику сохранения, восстановления и удаления состояния сопрограмм
Только когда сопрограмма реализуется хаками на стороне библиотеки, а не средствами языка.
сложно говорить за антивирусы, но вероятно не особо им это нравится на примере проблем с JVM в прошлом
Какое дело антивирусам до локальных переменных в куче?
В отличии от продолжаемых сопрограмм, в этой модели куски кода скрытно делятся на непрерываемые блоки, оформленные в виде анонимных функций.
Нет. В этой модели либо сопрограмма нарезается в конечный автомат, либо используется сохранение IP. В любом случае, каждый раз когда делается then, туда передается по сути одна и та же функция.
PS автор, добавь, пожалуйста, в свои сравнения варианты использующие Coroutines TS
andvgal Автор
25.09.2018 19:46Зато локальные переменные в куче чувствуют себя превосходно.
Повреждение данных на куче не столь опасно как повреждение стека, которое издревле используется для атак.
Только когда сопрограмма реализуется хаками на стороне библиотеки, а не средствами языка.
Не суть где логика реализована, она необходима. Так же как и в обработчиках системных вызовов.
Нет. В этой модели либо сопрограмма нарезается в конечный автомат, либо используется сохранение IP. В любом случае, каждый раз когда делается then, туда передается по сути одна и та же функция.
Допускаю, что не совсем корректное определение в "сахаре"
async/await, но изначальныйPromiseв ECMAScript берёт именно функцию-callback вthen. О нём и речь в контексте С++.
PS автор, добавь, пожалуйста, в свои сравнения варианты использующие Coroutines TS
Была такая идея, но посмотрев на прения в GCC — идея пока отложена.
vanxant
25.09.2018 19:40+1Очень крутая штука.
Во введении к статье («взгляд назад») не помешал бы обзор недостатков традиционной реализации асинхронности на коллбэках. Просто не все в курсе, зачем вообще весь этот хайп вокруг промисов, асинков и корутин. Ну типа такой:
1. Более-менее сложный алгоритм обработки превращается в жуткий спагетти-код, когда логика размазана тонким слоем по десяткам неявно вызывающих друг друга функций. Особенно печально с обработкой ошибок (та же отмена обработки из-за отвала клиента становится очень нетривиальной).
2. Без поддержки замыканий в языке получается ужас-ужас по утечкам памяти. Т.е. лямбды можно реализовать самостоятельно на базе функторов (объектов с перегруженным operator() и почти неизбежным delete this), но очень непросто это сделать правильно. Впрочем, даже поддержка замыканий и наличие сборщика мусора совершенно не мешает памяти течь, особенно при неявном захвате переменных замыканием (привет JS).
3. Даже при наличии замыканий код остаётся однопоточным, хотя и асинхронным. Многопоточность можно реализовать только вручную, и только при наличии стальных тестикул. Хоть с асинками, хоть с сопрограммами.andvgal Автор
25.09.2018 19:48Благодарю за отзыв.
Давайте ваш коммент заменит часть статьи. Иначе она уж совсем некультурно разрастётся.
Fedcomp
26.09.2018 00:49Читая такие ужасы понимаю почему так любят асинхронщину в rust на tokio, где оно не только асинхронно но и выполняется сразу в многопоточном режиме.
eao197
26.09.2018 08:54+11. Более-менее сложный алгоритм обработки превращается в жуткий спагетти-код, когда логика размазана тонким слоем по десяткам неявно вызывающих друг друга функций. Особенно печально с обработкой ошибок (та же отмена обработки из-за отвала клиента становится очень нетривиальной).
Неужели описанный в статье подход от этих ужасов избавляет? От таких ужасов как раз избавляет простой линейный код, который раньше писали в виде однопоточных процессов (и форкали процессы для распараллеливания), затем в виде нитей внутри многопоточных процессов. Затем, поскольку у процессов и нитей слишком высокие накладные расходы, стали использовать stackful coroutines. Которые значительно дешевле, чем реальный нити ОС, но так же позволяют писать линейный код в синхронном стиле (пряча от пользователя детали переключения контекстов).
Автор же как раз предлагает от stackful coroutines перейти к размазыванию логики по множеству коллбэков.
Да, по каким-то критериям (в том числе и по перечисленным автором в статье), этот подход может быть где-то выгоднее. Но вот то, что этот подход упрощает написание бизнес-логики — это спорный тезис. По крайней мере в статье это явно не показано.
Goldseeker
26.09.2018 11:27Предложение автора это и есть жуткий спагетти код, в котором логика размазана по куче коллбеков, плюс перереализовано куча ключевых слов языка: условия, циклы вот это всё.
0xd34df00d
26.09.2018 19:49+1Я вообще ничего не понял, чем оно лучше и за счёт чего именно выигрывает у тех же буст.фиберов.
В какой-то момент оно, конечно, стало напоминать, скажем, dataflow parallelism, когда там asi и это всё, но как-то очень быстро всё превратилось в месиво.
ijsgaus
25.09.2018 20:39+2Честно говоря, опять велосипед. Идеи и мысли верные, но проработка… Предлагаю автору почитать вот это www.cambridge.org/us/academic/subjects/computer-science/distributed-networked-and-mobile-computing/concurrent-programming-ml
andvgal Автор
25.09.2018 20:52Вы похоже пытаетесь меня убедить, что неправильно делаю то, с чем не согласен априори — у меня другое видение проблемы.
Давайте вы сначала развернёте свою мысль, а не будете наводить тень на плетень. Потом я объясню где вы возможно не правы.
ijsgaus
25.09.2018 21:16+1Основная притензия к текущим реализациям, насколько я понял — неконтролируемая отмена и очистка (и неудобная) конкуретных процессов. Про стек — это вопрос не к библиотекам, а скорее к компилятору. Это он должен конечный автомат генерить, соответственно, стека данных там и нет. А в книге, что я порекомендовал, очень неплохая математика на альтернативах и negative knowledge. Если интересно, есть даже рабочая реализация этого подхода (на .NET, не моя github.com/Hopac/Hopac/blob/master/Docs/Programming.md)
andvgal Автор
25.09.2018 23:19Вот к этому я и веду. Вы смотрите на AsyncSteps через призму CML, обособленных потоков-сопрограмм и каналов связи. Именно такая концепция меня не устраивает, т.к. она имитирует ещё историческую модель разделения на процессы в UNIX, где множество запросов/событий обрабатываются в одном и том же процессе в цикле без перерыва. У каждого процесса своя задача в этом конвейере. Им требуется постоянно передавать работу друг-другу.
Потом с процессов переползли на потоки, но принцип остался: поток на чтение с сокетов, поток на запись в сокеты, поток на таймер и т.д. Далее с потоков переползли на сопрограммы, но принцип остался.
Благо [для меня] когда-то часть разработчиков решила сменить вектор. Вместо конвейера под каждый запрос стали создавать отдельный поток, который обслуживал запрос от и до. Это стало стандартом в веб серверах. Ключевое отличие — отсутствует обмен сообщениями между потоками. Они изолированы и независимы.
AsyncSteps идёт именно этим путём: один поток — один запрос, максимальное подражание синхронному программированию с абстрактным линейным потоком управления. Каждый поток изолирован от всех других. Здесь мало уместны наработки каналов связи и синхронизации CML, goroutine и прочих решений из соседней оперетты.
К слову, каноничный
async/await,Promiseи Boost.Fiber идут тем же путём, а вот goroutine идёт частично по пути CML. Статья о разнице в технической реализации общего пути "один поток-один запрос", о том что сделать его на рельсах а-ля CML (Boost.Fiber) выходит менее эффективно в реальных цифрах, что в чистомPromiseне хватает функционала, ну и конечно немного камней в огород иного подхода.
По-моему, именно из-за этого различия во взглядах вы не поняли при чём же здесь стек. Вы хотите в лошади увидеть верблюда и резонно возмущаетесь отсутствию горбов.
vamireh
25.09.2018 23:30+1Тестирование Boost.Fiber не может считаться полным без segmented stack — он обеспечит и гораздо меньшее потребление памяти, и быстрый старт.
Принципиально, интерфейс FutoIn AsyncSteps проще, понятнее и более функционален чем любые из конкурентов без «сахара» async/await
Как раз таки Boost.Fiber даёт писать самый простой и понятный код. Писать так, как спроектирован язык — в линейной логике. А не передавать функции обратного вызова. Это неудобно в любом языке, тем более в C++, где необходимо следить за временем жизни и списком захвата.andvgal Автор
25.09.2018 23:36Я бы с вами согласился, если бы не одно "НО" — это необходимость пользоваться всё той же парой
boost::fibers::promise<>иboost::fibers::future. Для меня это выглядит обструкцией.
В С++ безусловно появляется описанная в статье проблема с временем жизни локальных объектов, но она отсутствует в языках с GC.vamireh
25.09.2018 23:43Я бы с вами согласился, если бы не одно «НО» — это необходимость пользоваться всё той же парой boost::fibers::promise<> и boost::fibers::future
Зачем ими пользоваться? Вы ведь сами пишете в другом комментарии
Вместо конвейера под каждый запрос стали создавать отдельный поток, который обслуживал запрос от и до
Вот и создавайте fiber на запрос и обрабатывайте его от и до.
В С++ безусловно появляется описанная в статье проблема с временем жизни локальных объектов, но она отсутствует в языках с GC
Что не делает обратные вызовы радикально более удобными. За это всегда ругали Node.js. Не я сказал, но я полностью согласен: Node.js — это для не осиливших Erlang.andvgal Автор
26.09.2018 01:01Вот и создавайте fiber на запрос и обрабатывайте его от и до.
Основная претензия всё же была к манипуляциям со стеком и связанными с этим ограничениями и угрозами. Без вызова псевдо-блокирующего API, не будет переключения между fibers. При пироге из фреймворков может быть не очевидно, где требуется вручную впихнуть
yieldчтобы чрезмерно не занимать процессор.
Во-вторых, fiber не решает проблемы частичной отмены подзапроса по таймеру — это требуется делать во внешней реализации обработчика, куда должен передаваться таймаут и "надеяться", что он будет корректно обработан. Например, может задаваться одно общее ограничение на обработку всего запроса, на каждый подзапрос своё более маленькое ограничение. В свою очередь подзапрос может делать ещё и свои подзапросы со своими ограничениями времени. Как всё это считать? Как отменить первый подзапрос чётко по времени и продолжить выполнение по альтернативному пути?
Эта реальная проблема была решена одной из первых в AsyncSteps, убирая хрупкую логику подсчёта таймеров из реализации внешних событий. Неэффективные таймеры могут дать задержки в производительности в несколько порядков — вместо этого навязывается протокол запрос-отмена.
В-третьих, когда речь заходит про внешнее событие, которое обычно представляет из себя вызов ОС, начинают плодиться сущности в виде promise и future. Интерфейс AsyncSteps попросту заменяет их и сводит всё сложность к работе с одним указателем.
vamireh
26.09.2018 02:06Основная претензия всё же была к манипуляциям со стеком и связанными с этим ограничениями
Озвученные вами ограничения снимаются при segmented stack.
угрозами
Вы не назвали конкретных угроз, связанных именно с необходимость поддержки стека для fibers. Если же речь идёт о стандартных угрозах, то, во-первых, ваша библиотека от них никак не спасает, а во-вторых, мы же не замшелые сишники, чтобы использовать всякие sprintf в ограниченный буфер — у нас есть stream'ы, контейнеры и прочие плюшки. Так что не вижу каким образом Fiber увеличивает риски.
Без вызова псевдо-блокирующего API, не будет переключения между fibers. При пироге из фреймворков может быть не очевидно, где требуется вручную впихнуть yield чтобы чрезмерно не занимать процессор
А как вы меня остановите, если я в callback'е вашей библиотеки начну считать число «пи» до рекордного знака? Только насильственными методами, что не уживается с корректным освобождением ресурсов. Так что претензия не принимается.
Кроме того, если между вызовами асинхронного API проходит так много времени, что необходимо заботиться о yield, то и все эти библиотеки используются совершенно напрасно — вычислительные задачи должны вращаться в отдельном пуле потоков, возможно, даже на другой машине.
Во-вторых, fiber не решает проблемы частичной отмены подзапроса по таймеру — это требуется делать во внешней реализации обработчика, куда должен передаваться таймаут и «надеяться», что он будет корректно обработан. Например, может задаваться одно общее ограничение на обработку всего запроса, на каждый подзапрос своё более маленькое ограничение. В свою очередь подзапрос может делать ещё и свои подзапросы со своими ограничениями времени. Как всё это считать? Как отменить первый подзапрос чётко по времени и продолжить выполнение по альтернативному пути?
Ну, асинхронное API всегда предоставляет *_for и *_until методы. Так что описанную проблему можно решать по аналогии с интеграцией Fiber с ASIO. Передавать извне только общее время (таймаут на всю операцию), и таймаут на операцию. Логика подсчёта интегрируется в прослойку, и бизнес-логика в fiber'ах ею не нагружается.
В-третьих, когда речь заходит про внешнее событие, которое обычно представляет из себя вызов ОС, начинают плодиться сущности в виде promise и future. Интерфейс AsyncSteps попросту заменяет их и сводит всё сложность к работе с одним указателем.
Я не очень понимаю проблемы. Но тем не менее, абсолютно линейный и последовательный вызов future.get() в fiber'е всегда проще и понятнее, чем callback.andvgal Автор
26.09.2018 08:34Вы пересказываете тезисы из статьи. Проблему таймеров вы не поняли.
segmented_stackимеет свои оговорки и нюансы.
Вас никто не заставляет отказываться от более медленного Boost.Fiber с кучей оговорок по ABI и поддержкой со стороны компилятора, как и от "железных" потоков.
Из первого вашего абзаца следует, что у вас повреждений памяти С++ программы не бывает в принципе. На этом вас и оставлю.
vamireh
26.09.2018 08:57+2Вы пересказываете тезисы из статьи
Но где, простите? Я топлю за последовательный и линейный код, а статья про передачу callback'ов друг другу.
Проблему таймеров вы не поняли
Возможно. А возможно, что вы не поняли её решения. Что вам не понравилось в моих словах?
segmented_stack имеет свои оговорки и нюансы
Как и всё в этой жизни. Но вы ничего в статье не написали. Не пишите и в комментариях.
Вас никто не заставляет отказываться от более медленного Boost.Fiber
Вы этого не показали. Не надо в технической дискуссии постулировать ваши желания.
Из первого вашего абзаца следует, что у вас повреждений памяти С++ программы не бывает в принципе
Да, знаете, это запрещено в бортовых авиационных комплексах, которые мы разрабатываем. Лётчик может сильно обидеться…
А вы, простите, что же, по выражению одного erlang'иста, «выгребаете core'ки по утрам»?
На этом вас и оставлю
Да? Так скоро? Ну, ладно, бывайте.andvgal Автор
26.09.2018 09:10… а статья про передачу callback'ов друг другу.
Вот вы совершенно не разобрались. Нет такого.
А возможно, что вы не поняли её решения.
Кто по вашему будет делать обработку таймеров и все
_forAPI. Вы в каждой библиотеке будете их реализовывать?
Покажу на более понятно примере: операторы сравнения в С++. Как решение, добавили оператор
<=>. Если суть проблемы и решения не понятны, то помочь далее вам не могу.
Да, знаете, это запрещено в бортовых авиационных комплексах...
Зато
segmented_stackтам разрешён? Вот вы меня уморили…vamireh
26.09.2018 09:38Вот вы совершенно не разобрались. Нет такого.
Я так смотрю, я не один такой. Раскройте же секрет: где мы заблуждаемся?
Кто по вашему будет делать обработку таймеров и все _for API. Вы в каждой библиотеке будете их реализовывать?
Да, я в том числе. И времени уйдёт меньше, чем на написание библиотеки по вызову callback'ов.
Покажу на более понятно примере: операторы сравнения в С++. Как решение, добавили оператор <=>. Если суть проблемы и решения не понятны, то помочь далее вам не могу.
Мне то как раз всё понятно. Я вам предложил такой оператор <=> — это прослойка интеграции API и Fiber. Вопросы?
Зато segmented_stack там разрешён? Вот вы меня уморили…
Возможно, пока не существует сертифицированной реализации (хотя за весь мир говорить не могу), но вы уморились так уверенно, что я убеждён: вам не составит труда процитировать мне пункт(ы) с запретом из КТ-178.
Antervis
26.09.2018 01:23допустим, такой подход действительно оптимален по утилизации ресурсов. Но библиотека точно не даст забыть о том, что вы её используете — посудите сами, 2/3 кода с++-примеров относятся к ней, а не к бизнес-логике. Хотелось бы конечно, чтобы намерение сделать код асинхронным передавалось буквально одним-двумя ключевыми словами языка:
detach alpha(); detach { beta(); } then { gamma(); } then { delta(); }; parallel { auto a = sigma(); auto b = tau(); { auto c = theta(); // ... auto d = omega(c); } }; auto e = async kappa(); auto f = xi(); // ... auto g = pi(a, b);
Думаю, здесь мои намерения очевидны. Код на AsyncSteps больно тяжело читатьandvgal Автор
26.09.2018 08:23Об этом как раз и писалось в заключении про "сахар", который возможно добавить. Некорректно сравнивать по читаемости. Пример
Promiseиasync/awaitв JS — совершенно разный уровень читаемости, а суть одна.
В примерах много кода AsyncSteps чтобы показывать суть интерфейса. Так же сравнительно много кода не бизнес-логики во всех примерах Boost.Fiber и
Promiseв JS.
В реальной жизни основная часть кода остаётся за бизнес-логикой.
eao197
26.09.2018 08:46Простите, я, видимо, сильно торможу, но для меня остались непонятными следующие вещи:
1. Как у вас происходит отображение ваших AsyncStep-ов на реальные рабочие потоки (нити) ОС? Складывается ощущение, что за AsyncTool-ом прячется всего один рабочий поток, а все привязанные к этому AsyncTool-у объекты с коллбэками будут запускаться по очереди на этом единственном рабочем потоке.
2. Не понятно, зачем вы заложились на единообразие интерфейсов своих AsyncStep-ов для разных языков программирования. Например, меня, как C++ разработчика, мало интересует тот факт, что AsyncStep-ы выглядят точно так же в JS. JS-разработчиков, полагаю, так же мало интересует интерфейс C++ной реализации. Разработчиков, которые пишут и на C++, и на JS, среди читателей статьи, полагаю, сильно меньше, чем тех, кто использует всего один из этих языков. Соответственно, непонятно, какие выгоды может дать такая межъязыковая унификация.
3. Сложилось ощущение, что в своей статье вы термином «сопрограммы» называли и stackful- и stackless coroutines. Между тем это довольно таки разные вещи по своим возможностям, стоимости и удобству применения. При этом вы явно не обозначили (как мне показалось) какому именно типу сопрограмм вы противопоставляете свое решение. Если stackful coroutines, то по сути ваше предложение сводится к тому, чтобы погрузить пользователя в callback hell, объяснив ему это преимуществами в безопасности, переносимости и более высокой эффективности. Правильно?andvgal Автор
26.09.2018 09:01-1Вы совсем не тормозите, а хорошо понимаете.
Да + одна программа может иметь множество экземпляров AsyncTool для горизонтальной масштабируемости.
Это скорей философский вопрос. Такая концепция.
Оба типа сопрограмм объединены с абстрактной точки зрения. Краткое описание проблемы callback hell — это когда на в стеке есть более одного фрейма обратного вызова. Вот тогда оно нарастает как снежный ком и неконтролируемо. AsyncSteps так никогда не делает — всё идёт через возврат в AsyncTool и чистый вызов следующего шага. Того же добивались через Promise в JS.
eao197
26.09.2018 10:06+1Да + одна программа может иметь множество экземпляров AsyncTool для горизонтальной масштабируемости.
Тогда непонятен смысл примитивов синхронизации, которые вы предоставляете. Вот эти Mutex-ы и Throtlle — они зачем нужны при работе в строго однопоточном режиме, да еще с гарантией того, что активным может быть только один callback?
Это скорей философский вопрос. Такая концепция.
Но ведь за ней должна быть какая-то мотивация? Мне, например, понятно, когда в 90-е пытались делать единообразное отображение какой-нибудь CORBA в разные языки программирования. Но тут-то какая выгода преследуется?
Краткое описание проблемы callback hell — это когда на в стеке есть более одного фрейма обратного вызова.
Может быть это так, если вводить формализм со стороны технической реализации. С точки зрения же понятности кода callback hell начинается тогда, когда для выяснения очередного шага алгоритма приходится разбираться с тем, какой именно callback будет вызван. И когда.powerman
26.09.2018 12:27+1Лет 7 назад я попытался сделать нечто подобное описанному в статье на Perl: Async::Defer. У меня тогда это не пошло именно потому, что как callback-и не маскируй — всё-равно такой код поддерживать намного сложнее, чем на CSP (горутинах и каналах). Описанные в статье недостатки горутин, особенно если брать реализацию из Go с 2KB contiguous стеком (Five things that make Go fast, go 1.4 runtime changes, eliminate STW stack re-scanning), на мой взгляд не совсем корректны и не настолько критичны, как это кажется автору.
eao197
26.09.2018 12:39+1Применительно к C++. Реализация на callback-ах может быть хороша, если вам требуется максимальная переносимость для фреймворка. И вы не знаете, где и как вы будете работать завтра, будет ли там поддержка Boost.Fiber/Boost.Coroutine вообще. Т.е. если у вас сильно ненулевая вероятность попасть на экзотическую архитектуру/платформу.
В случае же с прикладным софтом, который зачастую разрабатывается под конкретное железо и ОС (ну или выбор этого железа и ОС сильно ограничивается), вполне можно рассчитывать на наличие актуальной и работающей реализации stackful coroutines (как из Boost-а, так и не из Boost-а). Поэтому ряд аргументов автора статьи против короутин, имхо, для прикладной разработки не столь актуальны.
Сравнивать же описанный инструмент с Go, где есть CSP-ные каналы, а так же специальная поддержка со стороны рантайма для переключения гороутин при обращении к блокирующим вызовам, вообще достаточно странно.
andvgal Автор
26.09.2018 13:26Тогда непонятен смысл примитивов синхронизации, которые вы предоставляете....
Она логическая в первую очередь, но поддерживает и классическую синхронизацию. Например, ограничить количество активных запросов к внешней системе.
Мне, например, понятно, когда в 90-е пытались делать единообразное отображение какой-нибудь CORBA в разные языки программирования.
Всё верной дорогой мыслите. Проект FutoIn и есть переосмысление ошибок в том числе CORBA и взятие всего лучшего из него. Сначала встал вопрос поддержи и синхронного, и асинхронного кода, но потом стало ясно, что первое не перспективно. Далее, возникает вопрос каким образом организовать асинхронную работу когда в рамках одного процесса могут смешиваться разные языки (C++, Python, ECMAScript PHP) без транспортного протокола взаимодействия. Use case: .net/CLR, JVM/AppServers и свои цели у FutoIn.
… какой именно callback будет вызван. И когда.
В AsyncSteps с этим всё чётко: либо продолжение следующего шага со следующей итерации AsyncTool, либо развёртывание стека с ошибкой. Третьего не дано. При развёртывании вызывается зачистка. Всё в строго оговорённом порядке.
eao197
26.09.2018 14:00Она логическая в первую очередь
А можно пример? Кроме ограничения количества запросов к внешней системе.
Например, ограничить количество активных запросов к внешней системе.
Т.е. если у вас какой-то коллбэк «повиснет» на обращении к экземпляру Mutex-а или Throttle, то вы такой коллбэк заблокируете, правильно? И дадите возможность отработать какому-то другому коллбэку. Или как?
Далее, возникает вопрос каким образом организовать асинхронную работу когда в рамках одного процесса могут смешиваться разные языки (C++, Python, ECMAScript PHP) без транспортного протокола взаимодействия.
Тут непонятно. Вы говорите про случай, когда в рамках одного процесса ОС нужно смешать модули, разработанные на разных языках программирования? Т.е. пишем основной код на C++, но вставляем туда же V8, который будет исполнять JavaScript-код…
В AsyncSteps с этим всё чётко: либо продолжение следующего шага со следующей итерации AsyncTool, либо развёртывание стека с ошибкой.
Чего-то я все-таки не понимаю. Вот при обычном task-based parallelism-е можно записать что-то вроде:
auto result = async(calculate_first_value, args...).get() + async(calculate_second_value, args...).get();
В случае с FutoIn, как я понимаю, нужно будет создать три шага вычислений:
- первый шаг содержит вызов calculate_first_value и сохранение этого результата куда-то;
- второй шаг содержит вызов calculate_second_value и сохранение этого результата куда-то;
- третий шаг складывает результаты двух первых шагов.
И каждый шаг будет представлен своей отдельной лямбдой. Правильно?andvgal Автор
26.09.2018 15:13А можно пример? Кроме ограничения количества запросов к внешней системе.
Их множество — все те же, что и при классическом варианте. Например, при cache miss не эффективно генерировать значения всем интересующимся потокам — один берёт на себя эту задачу, другие ожидают чтобы проверить наличия кэшированного значения снова при захвате мутекса. Если уж и тогда его нет, тогда генерировать в "единственном лице". Другой вопрос, что мало разработчиков понимают как правильно организовать кэш и поддерживать его горячим.
Т.е. если у вас какой-то коллбэк «повиснет» на обращении к экземпляру Mutex-а или Throttle
Они реализованы иным путём и такого не происходит по определению. Если лимит не превышен — продолжается обработка следующего шага через AsyncTool. Иначе, AsyncSteps находится в ожидании завершения внешнего события (освобождения ресурса) в строгой последовательности. Если предполагается более одного "железного" потока, то эти примитивы могут быть реализованы через lockfree или же классические примитивы синхронизации. К слову, последние часто оказываются более эффективными и предсказуемыми в многопоточных приложениях вопреки расхожему мнению. Здесь нет обмена сообщениями и нет каналов связи.
В случае с FutoIn, как я понимаю, нужно будет создать три шага вычислений:
FutoIn работает на уровне бизнес-логики, для параллелизма вычислений есть совершенно иные инструменты вроде OpenCL. Конкретно
parallel()имеет своей целью запускать параллельные внешние запросы с автоматическим барьером, а не ускорять вычисления. Каждый из подзапросов может делать захват переменной для записи результата или же использоватьstate().
И каждый шаг будет представлен своей отдельной лямбдой. Правильно?
Не обязательно лямбдой, это может быть и обычная функция и обычный функтор с реализацией
operator()(IAsyncSteps& [, ...args]) [const]. На практике такое может использоваться для улучшения читаемости кода.eao197
26.09.2018 15:34Их множество — все те же, что и при классическом варианте.
Простите, но я не понимаю. В классическом варианте есть два (или более) независимых потока управления и общий ресурс, который нужно получить в эксклюзивный доступ. При этом один поток доступ получает, второй приостанавливается и возобновляет свою работу при освобождении ресурса.
У вас же, как вы говорите, нет параллельно работающих потоков исполнения. Есть мелкие задачи, которые исполняются строго последовательно и строго на одном потоке. Не может быть, по вашим же словам, двух задач, которые должны бороться за общий ресурс. Сперва одна задача спокойно ресурс использует, затем другая.
Посему вопрос «Зачем здесь Mutex?» для меня до сих пор не раскрыт.
Но если уж у вас есть примитивы синхронизации, то не очень понятно, как должна выглядеть работа с ними. С традиционными mutex-ами все просто: lock(); какие-то действия; unlock(). Если на lock()-е нас блокируют, то у нас текущее состояние сохраняется на стеке.
А что у вас? У вас же нельзя написать: lock(); ...; unlock(); для mutex-а. Как же с вашими mutex-ами происходит работа?
Если лимит не превышен — продолжается обработка следующего шага через AsyncTool. Иначе, AsyncSteps находится в ожидании завершения внешнего события (освобождения ресурса) в строгой последовательности.
Опять непонятно. У вас, по сути очередь тасков внутри AsyncTool. Вы выполнили первые N тасков и они исчерпали лимит в каком-то Throtlle-объекте (или что там у вас под «примитивами синхронизации» подразумевается). Берете (N+1) таску и она пытается взять Throtlle объект. Но не может, т.к. лимит выбран. И что, вы блокируете свой AsyncTool со всеми оставшимися тасками?
Вряд ли у вас такой бред происходит. Расскажите, пожалуйста, как работают ваши «примитивы синхронизации».
FutoIn работает на уровне бизнес-логики...
Ну т.е. разработчику таки придется написать эти самые три шага. Вместо одной конструкции, которую мы имеем при классическом task-based подходе. Это и есть прямая дорога к callback hell.andvgal Автор
26.09.2018 16:05Посему вопрос «Зачем здесь Mutex?» для меня до сих пор не раскрыт.
Вы не учитываете, что этот самый захвативший поток может прерваться на внешнем вызове. Тогда в дело может вступать другой поток. Для этого и требуется логическая синхронизация. Во-вторых, Mutex может выступать в роли семафора с N>1 одновременных потоков. Это не моя выдумка, если что.
Как же с вашими mutex-ами происходит работа?
Смотрите на
asi.sync(object, func, onerror)как наstd::lock_guard<>для поддерева шагов, начинающегося сfunc(). А всё остальное — детали реализации.
И что, вы блокируете свой AsyncTool со всеми оставшимися тасками?
AsyncTool (Event Loop) никогда не блокируется за исключением случая отсутствия работы, т.е. отсутствия активных
immediate()иdeferred(). При логической блокировке AsyncSteps либо становится в очередь и возвращает управление в AsyncTool, либо сразу отваливается с ошибкой по лимиту. Если же лимит не достигнут изначально, то управление всё равно возвращается в AsyncTool (!), который потом вызоветfunc()— именно поэтому здесь нет никакого callback hell.
При освобождении ресурса, первый AsyncSteps в очереди получает "завершение внешнего события" через вызов
asi.success(), который ставит дальнейшие шаги в обработку черезAsyncTool::immediate(), а не вызывает их напрямую.
Все эти принципы Event Loop тоже не новы, и уж не первое десятилетие работают в Python Twisted, Node.js, разных UI thread и прочих реализациях.
Callback hell как раз-таки городят поверх, если не выходят обратно в Event Loop и если завершают запрос более чем одним путём.
eao197
26.09.2018 16:21Вы не учитываете, что этот самый захвативший поток может прерваться на внешнем вызове.
Вы хотите сказать, что показанный в ваших примерах ri::Mutex — это полноценный аналог std::mutex-а? Т.е. это не механизм синхронизации работы ваших тасков внутри AsyncSteps, а механизм синхронизации ваших тасков с внешним миром?
Смотрите на asi.sync(object, func, onerror) как на std::lock_guard<> для поддерева шагов, начинающегося с func().
Ну т.е. речь идет о том, что если кто-то напишет что-то вроде:
as.add([&](IAsyncSteps & as) { foo(); // (1) as.sync(mtx, [&](IAsyncSteps & as) { boo(); // (2) }); baz(); // (3) });
То у него сперва будет вызван foo() в точке (1), затем baz() в точке (3) и лишь затем, когда-нибудь, boo() в точке (2)?
А всё остальное — детали реализации.
ИМХО, вам пора уже начать рассказывать об этих самых деталях, а то обычные смертные, вроде меня, из ваших объяснений в высоком штиле мало что понимают.
Callback hell как раз-таки городят поверх, если не выходят обратно в Event Loop и если завершают запрос более чем одним путём.
Вероятно, у кого-то из нас сильно специфический взгляд на callback hell.andvgal Автор
26.09.2018 16:56Не очень понял первый вопрос. Объекты с интерфейсом
futoin::ISyncне могут использоваться для классической синхронизации, т.к. они по факту не блокируют "железный" поток. Они делают что-то вроде coroutine suspend для абстрактного потока AsyncSteps.
То у него сперва будет вызван foo() в точке (1), затем baz() в точке (3) и лишь затем, когда-нибудь, boo() в точке (2)?
Верно, если надо по-другому, то:
as.add([&](IAsyncSteps & as) { foo(); // (1) as.sync(mtx, [&](IAsyncSteps & as) { boo(); // (2) }); asi.add( [](IAsyncSteps& asi){ baz(); // (3) } ); });
Этот момент описывается в документации и при необходимости может отслеживаться статическими анализаторами.
При добавлении "сахара", он исчезает и последовательность не будет нарушаться.
awaitдаже не потребуется использовать — вызов синхронных и асинхронных функций не будет отличаться в коде.
asi bool some_func() { return true; } asi [](){ foo(); sync(mtx) { boo(); } bool res = some_func(); baz(); };
Такой сахар может транслироваться в :
void some_func(IAsyncSteps& asi) { asi.success(true); } [](IAsyncSteps& asi){ foo(); asi.sync(mtx, [](IAsyncSteps& asi){ boo(); }); asi.add(some_func); asi.add([](IAsyncSteps& asi, bool res){ baz(); }); };eao197
26.09.2018 17:05+1Не очень понял первый вопрос.
Вопрос в том, для чего предназначен ri::Mutex. Если он нужен для синхронизации доступа к некоторому ресурсу из таска AsyncTool-а и из внешнего по отношению AsyncTool-а потоку управления, то его роль понятна. Но если ri::Mutex нужен для того, чтобы доступ к ресурсу синхронизировался между тасками одного AsyncTool-а, то непонятно, зачем он нужен.
Верно, если надо по-другому, то:
Боюсь показаться слишком грубым, но как только пользователю придется писать такой код вместо линейного:
то ваш фреймворк отложат до лучших времен не смотря на якобы имеющиеся преимущества в скорости перед Boost.Fiber.foo(); { lock_guard lock{mtx}; boo(); } baz();
Такой сахар может транслироваться в :
И кто в мире C++ будет иметь такой транслятор?andvgal Автор
26.09.2018 17:17-1И кто в мире C++ будет иметь такой транслятор?
Не всё сразу, У С++ был Cfront, у Qt есть moc, у ECMAScript — Babel, у FutoIn может появиться свой.
Сразу отвечаю на "когда сделаешь — тогда приходи", статья про универсальную модель, а не про конкретно С++ реализацию.
mayorovp
26.09.2018 17:19Универсальная модель, которая медленно но верно шагает из языка в язык уже есть, и это async/await.
eao197
26.09.2018 17:58Сразу отвечаю на «когда сделаешь — тогда приходи»
Как раз это-то и не интересует. Интересует ответ на вопрос про ri::Mutex, но этого-то ответа и нет.andvgal Автор
26.09.2018 18:20Если мои объяснения не устраивают, попробуйте спросить у авторов Boost.Fiber зачем им mutex (https://www.boost.org/doc/libs/1_68_0/libs/fiber/doc/html/fiber/synchronization/mutex_types.html) или у автора cppcoro зачем им async_mutex (https://github.com/lewissbaker/cppcoro), а потом доказывайте им, что
они тоже идиотыэто не требуется.
К слову, по функциональности Mutex, Throttle и Limiter очевидно, что это не какое-то бездумное копирование из альтернативных решений.
eao197
26.09.2018 18:29попробуйте спросить у авторов Boost.Fiber зачем им mutex
Как раз там это вопросов не вызывает вообще, т.к., если мне не изменяет склероз, Boost.Fiber обеспечивает конкурентное выполнение для сопрограмм. Т.е. там сопрограмма — это как очень легковесный поток (thread), разве что его планировкой занимается не ОС.
А вот зачем нужен Mutex у вас, если у вас одна таска не может быть приостановлена посередине и эта же рабочая нить не может начать выполнять другую таску из этого же AsyncTool-а, вот это непонятно. Если ваш Mutex нужен для координации с внешним миром — тогда все становится на свои места.
К слову, по функциональности Mutex, Throttle и Limiter очевидно, что это не какое-то бездумное копирование из альтернативных решений.
Простите мне мою прямоту, но есть ощущение, что вы и в статье, и в комментариях ведете рассказ с позиции «вы все в дерьме, а я один Д'Артаньян». Из-за этого тяжело вытаскивать крупицы полезной информации из ваших рассказов о том, что и зачем вы сделали.andvgal Автор
26.09.2018 18:49А вот зачем нужен Mutex у вас, если у вас одна таска не может быть приостановлена посередине и эта же рабочая нить не может начать выполнять другую таску из этого же AsyncTool-а, вот это непонятно.
Совершенно неверное утверждение.
У вас ведь есть понимание что такое Event Loop (он же AsyncTool)? Task — это AsyncSteps, каждый шаг (AsyncSteps::add()) — это отдельное событие, которое планируется через AsyncTool::immediate(). Это и обеспечивает высокую конкуренцию "тасков".
Соответственно,
AsyncSteps1 step_1_1 step_1_1_1 step_1_1_2 step_1_2 step_1_2_1 AsyncSteps2 step_2_1 step_2_1_1 step_2_1_2 step_2_2 step_2_2_1
будут выполнены в таком порядке:
step_1_1 step_2_1 step_1_1_1 step_2_1_1 step_1_1_2 step_2_1_2 step_1_2 step_2_2 step_1_2_1 step_2_2_1
Эта ясно показано на примере
parallel()— смотрите внимательно.
Если AsyncSteps1 начинает что-то делать с неким ресурсом в step_1_1, то ему требуется взять Mutex чтобы продолжать с ним эксклюзивно работать в step_1_1_1 и step_1_1_2 так, чтобы другой "таск" не смог изменить состояние этого ресурса. Речь о логической гонке, а не хардверной.
Если вам всё ещё не понятно, то вы очевидно обыкновенный тролль, уважаемый.
eao197
26.09.2018 20:01У вас ведь есть понимание что такое Event Loop
Есть, но Event Loop служит для реактивной обработки событий, поступающих извне. У вас же, насколько можно судить по приведенным примерам, какое-то общение с внешним миром вообще не предусмотрено.
Это и обеспечивает высокую конкуренцию «тасков».
И конкурируют они, я так полагаю, разве что за время на той единственной нити, которая скрывается за AsyncTool.
Если AsyncSteps1 начинает что-то делать с неким ресурсом в step_1_1, то ему требуется взять Mutex чтобы продолжать с ним эксклюзивно работать в step_1_1_1 и step_1_1_2 так, чтобы другой «таск» не смог изменить состояние этого ресурса. Речь о логической гонке, а не хардверной.
Так стало понятно. Не понятно, зачем кому-то потребуется плодить кучу подтасков step_1_1_1, step_1_1_2 и т.д. Но если вы уж взялись их плодить, то тогда роль Mutex-ов в вашей модели становится понятной. А аналоги condition_variable или Window-вых event-ов у вас есть?
Если вам всё ещё не понятно, то вы очевидно обыкновенный тролль, уважаемый.
Есть еще тот вариант, что вы недостаточно хорошо объясняете.andvgal Автор
26.09.2018 20:20В идеальной ситуации каждый такой переход — это связь с внешним миром и соответственно ожидание ответа от него. Внешний мир — это интерфейсы различных проектов: Boost.Asio, базы данных, неблокирующие системные вызовы и т.д.
Смотрите "API интеграции с внешними событиями" в статье.
DistortNeo
26.09.2018 14:36Mutex-ы как раз нужны, а вот остальное мне действительно непонятно.
Типичный юзкейс: синхронизация доступа к ресурсу, обрабатывающему одновременно только одного клиента. Вместо того, чтобы в пользовательском коде городить очереди, гораздо проще реализовать примитив, аналогичный многопоточному.
picul
26.09.2018 12:13Наличие потоков в современных ОС не отменяет использования отдельных процессов.
Это почему это? Насколько я знаю, процессы вместо потоков используют только x86 легаси-монстры, которые не в состоянии адаптировать код под x64, вследствие чего для одного процесса выскакивает ограничение в 2ГБ по адресному пространству (вроде всякими хаками выгрызают 4ГБ, но это не точно, ну и в 2018 году этого частенько не хватает). Еще, насколько я знаю, иногда в целях безопасности. А в общем случае создавать отдельные процессы вместо потоков смысла нет.powerman
26.09.2018 12:35+2Процессы, в отличие от потоков, обеспечивают немало уникальных плюшек: возможность запускать их на разных машинах (хотя Erlang умеет это делать и для потоков, но это скорее исключение, потому что в других языках с чистыми функциями всё сложно), усиленная изоляция памяти (хотя последние дыры в процессорах помогают её обойти :)), увеличенная устойчивость (падение одного процесса не обрушивает другие… обычно), реализация разных процессов на разных языках, независимый менеджмент (перезапуск, обновление) процессов (хотя горячее обновление в Erlang…).
picul
26.09.2018 13:08возможность запускать их на разных машинах
Согласен, я мыслил в контексте одной машины…
независимый менеджмент (перезапуск, обновление) процессов
Можно поподробнее? Я ведь вроде все что угодно с потоками делать могу.powerman
26.09.2018 20:46+1Деплой новой версии микросервиса реализуется перезапуском процесса этого микросервиса. Другие микросервисы, работающие на этом же сервере и общающиеся с первым — продолжают работать. Обновить таким образом одну горутину (или группу горутин) из всех работающих в текущем процессе вроде умеет только Erlang (из известных мне языков).
mayorovp
27.09.2018 12:39В .NET таком образом можно выгружать и перезапускать AppDomain (что из коробки умеет делать ASP.NET).
DistortNeo
26.09.2018 14:30Интересно, а есть ли здесь вообще выигрыш от снижения оверхеда? Асинхронные вызовы используются не для CPU-кода, а для легковесной многозадачности при работе с IO-операциями. То есть добавление новой задачи, либо завершение текущей всегда сопряжено с системным вызовом. А накладные расходы на системный вызов на порядок (если не на два) превышают расходы на переключение асинхронной задачи.
andvgal Автор
26.09.2018 14:45А если я вам скажу, что вместо системных вызов возможно общаться с ОС и сторонними процессами через неблокирующие очереди запросов-ответов в виде конвейера. Идея так же не нова.
В таком случае, количество переключений контекста не привязано к количеству обрабатываемых событий.
gorodnev
26.09.2018 20:55+1Идея хорошая! Но расскажите поподробнее, как общаться со сторонними процессами без блокировок и системных вызовов? Ведь даже в случае с non-blocking POSIX Message Queue от системных вызовов Вы вряд ли куда уйдете. Да, на первый взгляд это будет неблокирующий системный вызов, но все равно вызов с соотвествующими накладными расходами на переключение контекста. Опять же, очередь не засунишь в демультиплексирующие вызовы (кажется). Но есть костыли в виде прослушки еще одним процессом очереди сообщений, который перекладывает эти сообщения в неименованный канал, который и запихивают в демультиплексирующие вызовы. Но все это не обходится без системных вызовов все равно.
andvgal Автор
26.09.2018 21:42Самое простое, что можно потрогать — это Boost.Interprocess + Boost.Lockfree.
Конкретно под разного рода Event Loop, сопрограммы и FutoIn AsyncSteps в т.ч. возможно:
- Сделать специальный модуль ядра с lock-free очередью системных вызовов и обратной очередью завершений в памяти процесса,
- Вместо ожидания на куче дескрипторов, каждый железный поток сможет слушать всего одну очередь и обрабатывать эти завершения.
- В любой очереди сможет включаться получение событий (GUI, system events).
- Это сможет заменить прямые системные вызовы со сменой контекста и поллинг (select/poll/epoll/kqueue) в высоконагруженных системах.
- Используя lock-free структуры с одним записывающим и одним читающим, пропускная способность будет предельной, а вот приемлемые задержки появятся, но практически исчезнет оверхед от переключения контекстов.
Разумеется, есть мелкие решаемые нюансы с безопасным засыпанием потока при пустой очереди, продолжением при добавлении со стороны ядра, вопросами обработки множества очередей на стороне ядра, игнорирование пустых очередей от потока и отслеживание добавления.
Опять же, я не придумываю велосипед, а предлагаю рабочее решение. Такими очередями host-guest оперируют драйвера в виртуализованной среде для работы с устройствами. Может что-то пропустил и уже даже кто-то сделать очереди для syscall'ов.
NeoCode
Любопытно. Эту библиотеку планируется включать в буст?
andvgal Автор
Во-первых, это совершенно не от меня зависит, но потребуется множество изменений в стиле и внутренностях.
Во-вторых, стиль и концепция намеренно отходит от канонов написания С++ кода и проектирования интерфейсов в пользу универсального решения для множества технологий.