
Мы начали изучать Control Groups (Cgroups) в Red Hat Enterprise Linux 7 – механизм уровня ядра, позволяющий управлять использованием системных ресурсов, кратко рассмотрели теоретические основы и теперь переходим к практике управления ресурсами CPU, памяти и ввода-вывода.

Однако, прежде чем что-то менять, всегда полезно узнать, как все устроено сейчас.
Есть два инструмента, с помощью которых можно увидеть состояние активных cgroups в системе. Во-первых, это systemd-cgls – команда, выдающая древовидный список cgroups и запущенных процессов. Ее вывод выглядит примерно так:
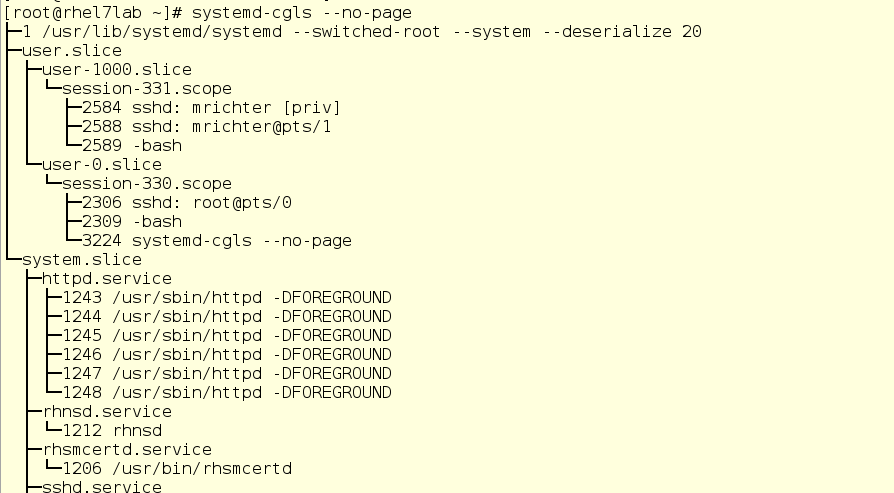
Здесь мы видим cgroups верхнего уровня: user.slice и system.slice. Виртуальных машин у нас нет, поэтому под нагрузкой эти группы верхнего уровня получают по 50 % ресурсов ЦП (поскольку слайс machine не активен). В user.slice есть два дочерних слайса: user-1000.slice и user-0.slice. Пользовательские слайсы идентифицируются по User ID (UID), поэтому определить владельца может быть непросто, разве что по запущенным процессам. В нашем случае по ssh-сеансам видно, что user 1000 – это mrichter, а user 0 – соответственно, root.
Вторая команда, которую мы будем использовать – это systemd-cgtop. Она показывает картину использования ресурсов в реальном времени (вывод systemd-cgls, кстати, тоже обновляется в реальном времени). На экране это выглядит примерно так:
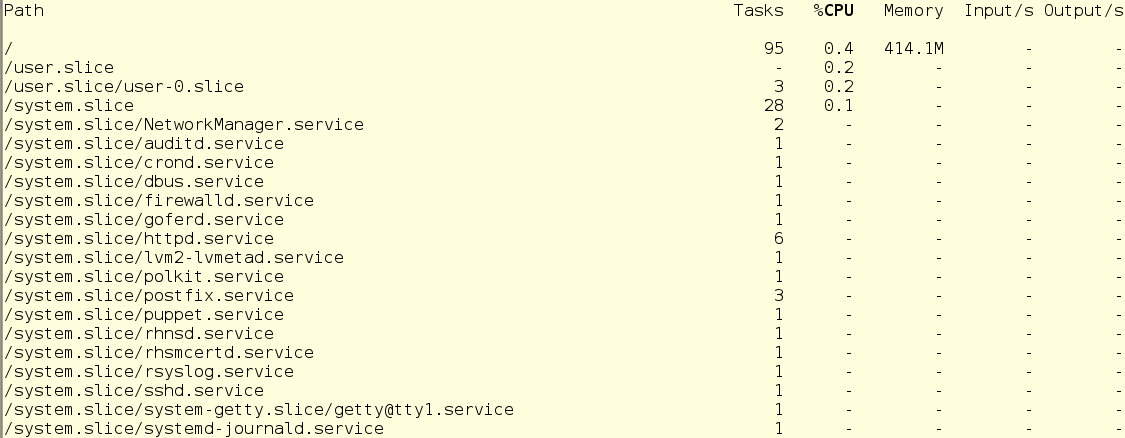
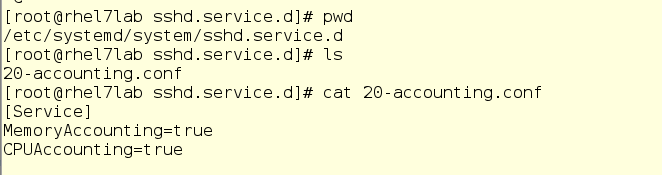
С systemd-cgtop есть одна проблема – она показывает статистику только по тем службам и слайсам, для которых включен учет использования ресурсов. Учет включается путем создания conf-файлов drop-in в соответствующих подкаталогах в /etc/systemd/system. Например, drop-in на скриншоте ниже включает учет ресурсов ЦП и памяти для службы sshd. Чтобы сделать так у себя, просто создайте такой же drop-in в текстовом редакторе. Кроме того, учет можно включить и командой systemctl set-property sshd.service CPUAccounting=true MemoryAccounting=true.
После создания drop-in’а надо обязательно ввести команду systemctl daemon-reload, а также команду systemctl restart <имя_службы> для соответствующей службы. В результате вы будете видеть статистику использования ресурсов, но это создаст дополнительную нагрузку, поскольку на ведение учета тоже будут расходоваться ресурсы. Поэтому учет стоит включать осмотрительно и лишь для тех служб и cgroups, которые нужно мониторить подобным образом. Впрочем, часто вместо systemd-cgtop можно обойтись командами top или iotop.
Теперь посмотрим, как изменение процессорных шар (CPU Shares) отражается на производительности. Для примера у нас будет два непривилегированных пользователя и одна системная служба. Пользователь с логином mrichter имеет UID 1000, что можно проверить по файлу /etc/passwd.

Это важно, поскольку пользовательские слайсы именуются по UID, а не по имени учетной записи.
Теперь пробежимся по каталогу drop-in’ов и посмотрим, если там уже что-нибудь для его слайса.
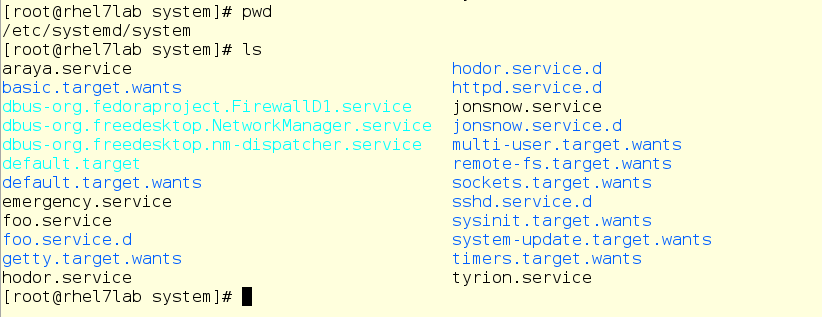
Нет, ничего нет. Хотя есть кое-что другое – взгляните на вещи, относящиеся к foo.service:
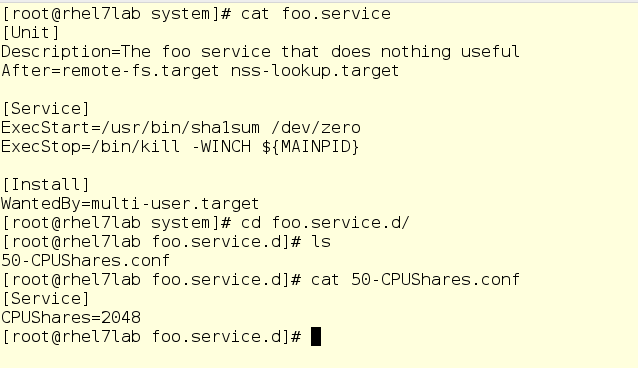
Если вы знакомы с юнит-файлами systemd, то увидите здесь вполне обычный юнит-файл, который запускает команду /usr/bin/sha1sum /dev/zero в качестве службы (иначе говоря, демона), Для нас важно то, что foo будет брать буквально все процессорные ресурсы, которые система разрешит ему использовать. Кроме того, здесь у нас есть drop-in, устанавливающий для службы foo значение CPU-шары, равное 2048. По умолчанию, как вы помните, используется значением 1024, поэтому под нагрузкой foo будет получать двойную долю CPU-ресурсов в рамках system.slice, своего родительского слайса верхнего уровня (так как foo – это служба).
Теперь запустим foo через systemctl и посмотрим, что нам покажет команда top:
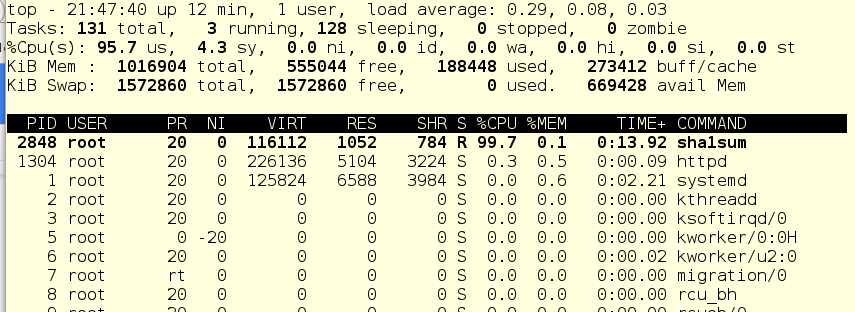
Поскольку в системе практически нет других работающих вещей, служба foo (pid 2848) потребляет почти все процессорное время одного CPU.
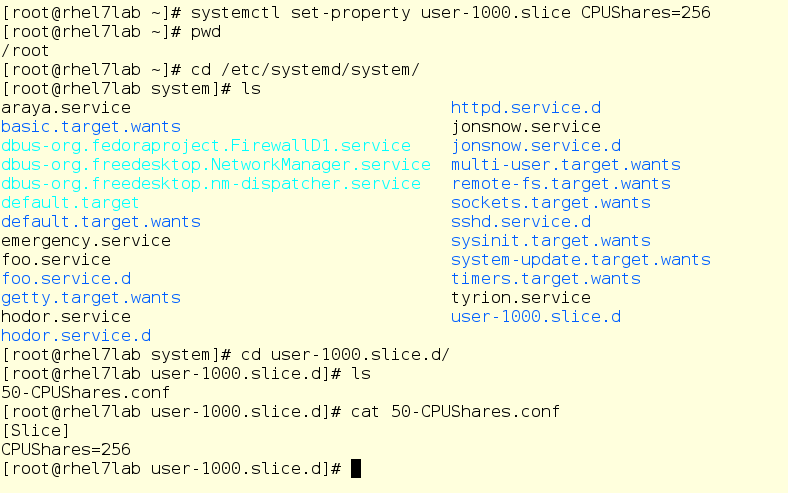
Теперь введем в уравнение пользователя mrichter. Сначала урежем ему CPU-шару до 256, затем он войдет в систему и запустит foo.exe, иначе говоря, ту же самую программу, но как пользовательский процесс.
Итак, mrichter запустил foo. И вот что теперь показывает команда top:
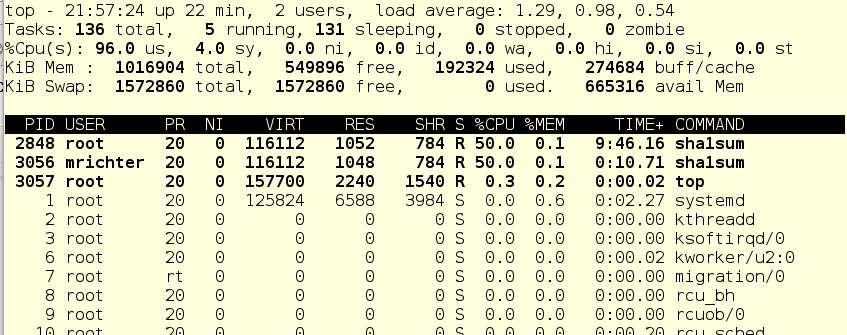
Странно, да? Пользователь mrichter вроде как должен получить процентов 10 процессорного времени, поскольку у него шара = 256, а у foo.service – целых 2048, нет?
Теперь введем в уравнение dorf’а. Это еще один обычный пользователь со стандартной CPU-шарой, равной 1024. Он тоже запустит foo, а мы опять посмотрим, как изменится распределение процессорного времени.

dorf – пользователь старой школы, он просто запускает процесс, без всяких умных сценариев и прочего. А мы опять смотрим вывод top:
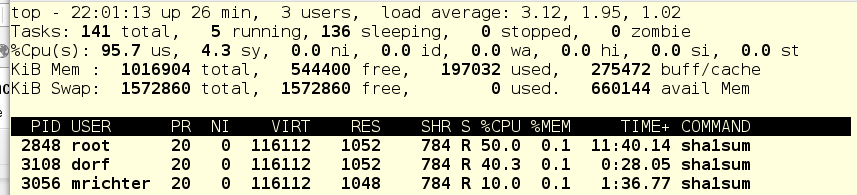
Так… давайте-ка глянем дерево cgroups и попробуем разобраться, что к чему:

Если помните, обычно в системе есть три cgroups верхнего уровня: System, User и Machine. Поскольку виртуальных машин в нашем примере нет, остаются только слайсы System и User. Каждый из них имеет CPU-шару по 1024, и поэтому под нагрузкой получает половину процессорного времени. Так как foo.service живет в System, и других претендентов на процессорное время в этом слайсе нет, то foo.service получает 50% ресурсов CPU.
Далее, в слайсе User живут пользователи dorf и mrichter. У первого шара равна 1024, у второго – 256. Поэтому dorf получает в четыре раза больше процессорного времени, чем mrichter. Теперь смотрим, что показывает top: foo.service – 50%, dorf – 40%, mrichter – 10%.
Переводя это на язык сценариев использования, можно сказать, что dorf имеет больший приоритет. Соответственно, cgroups настроены так, что пользователю mrichter урезают ресурсы на то время, пока они нужны dorf'у. Действительно, ведь пока mrichter был в системе один, он получал 50% процессорного времени, поскольку в слайсе User больше никто не конкурировал на ресурсы CPU.
По сути, CPU-шары – это способ обеспечить некий «гарантированный минимум» процессорного времени, даже для пользователей и служб с пониженным приоритетом.
Кроме того, у нас есть способ установить жесткую квоту на ресурсы CPU, некий лимит в абсолютных цифрах. Сделаем это для пользователя mrichter и посмотрим, как изменится картина распределение ресурсов.

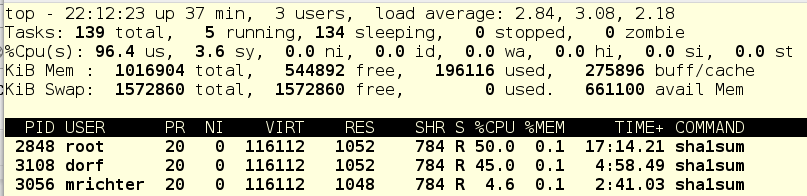
А теперь убьем задачи пользователя dorf, и вот что получится:

Для mrichter’прописан абсолютный CPU-лимит в 5%, поэтому foo.service получает все остальное процессорное время.
Продолжим издевательства и остановим foo.service:

Что мы здесь видим: mrichter имеет 5% процессорного времени, а оставшиеся 95 % система простаивает. Форменное издевательство, да.
На самом деле, такой подход позволяет эффективно усмирить службы или приложения, которые любят внезапно взбрыкивать и оттягивать на себя все процессорные ресурсы в ущерб остальным процессам.
Итак, мы узнали, как контролировать текущую ситуацию с cgroups. Теперь копнем чуть глубже и посмотрим, как cgroup реализуются на уровне виртуальной файловой системы.
Корневой каталог для всех работающих cgroups располагается по адресу /sys/fs/cgroup. При загрузке системы он заполняется по мере запуска сервисов и прочих задач. При запуске и остановке служб, их подкаталоги появляются и исчезают.
На скриншоте ниже мы перешли в подкаталог для CPU-контроллера, а именно в слайсе System. Как видим, подкаталога для foo здесь пока нет. Запустим foo и проверим пару вещей, а именно, его PID и его текущую CPU-шару:
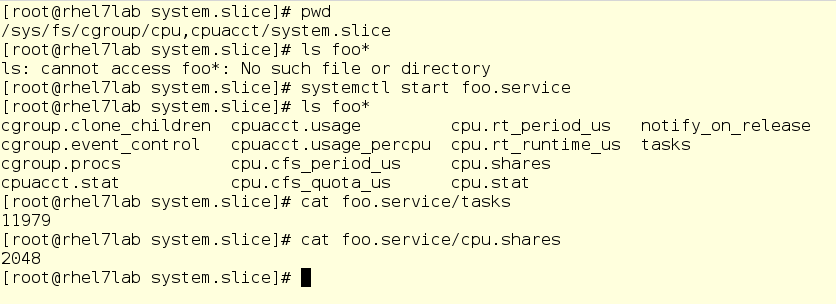
Важное предостережение: здесь можно менять значения на лету. Да, в теории это выглядит круто (и в реальности тоже), но может обернуться большим бардаком. Поэтому прежде чем что-то менять, тщательно все взвесьте и никогда не играйтесь на боевых серверах. Но в любом случае, виртуальная файловая система – это то, в чем стоит поковыряться по мере изучения того, как работают cgroups.
Однако, прежде чем что-то менять, всегда полезно узнать, как все устроено сейчас.
Есть два инструмента, с помощью которых можно увидеть состояние активных cgroups в системе. Во-первых, это systemd-cgls – команда, выдающая древовидный список cgroups и запущенных процессов. Ее вывод выглядит примерно так:
Здесь мы видим cgroups верхнего уровня: user.slice и system.slice. Виртуальных машин у нас нет, поэтому под нагрузкой эти группы верхнего уровня получают по 50 % ресурсов ЦП (поскольку слайс machine не активен). В user.slice есть два дочерних слайса: user-1000.slice и user-0.slice. Пользовательские слайсы идентифицируются по User ID (UID), поэтому определить владельца может быть непросто, разве что по запущенным процессам. В нашем случае по ssh-сеансам видно, что user 1000 – это mrichter, а user 0 – соответственно, root.
Вторая команда, которую мы будем использовать – это systemd-cgtop. Она показывает картину использования ресурсов в реальном времени (вывод systemd-cgls, кстати, тоже обновляется в реальном времени). На экране это выглядит примерно так:
С systemd-cgtop есть одна проблема – она показывает статистику только по тем службам и слайсам, для которых включен учет использования ресурсов. Учет включается путем создания conf-файлов drop-in в соответствующих подкаталогах в /etc/systemd/system. Например, drop-in на скриншоте ниже включает учет ресурсов ЦП и памяти для службы sshd. Чтобы сделать так у себя, просто создайте такой же drop-in в текстовом редакторе. Кроме того, учет можно включить и командой systemctl set-property sshd.service CPUAccounting=true MemoryAccounting=true.
После создания drop-in’а надо обязательно ввести команду systemctl daemon-reload, а также команду systemctl restart <имя_службы> для соответствующей службы. В результате вы будете видеть статистику использования ресурсов, но это создаст дополнительную нагрузку, поскольку на ведение учета тоже будут расходоваться ресурсы. Поэтому учет стоит включать осмотрительно и лишь для тех служб и cgroups, которые нужно мониторить подобным образом. Впрочем, часто вместо systemd-cgtop можно обойтись командами top или iotop.
Изменяем CPU-шары по приколу и с пользой
Теперь посмотрим, как изменение процессорных шар (CPU Shares) отражается на производительности. Для примера у нас будет два непривилегированных пользователя и одна системная служба. Пользователь с логином mrichter имеет UID 1000, что можно проверить по файлу /etc/passwd.
Это важно, поскольку пользовательские слайсы именуются по UID, а не по имени учетной записи.
Теперь пробежимся по каталогу drop-in’ов и посмотрим, если там уже что-нибудь для его слайса.
Нет, ничего нет. Хотя есть кое-что другое – взгляните на вещи, относящиеся к foo.service:
Если вы знакомы с юнит-файлами systemd, то увидите здесь вполне обычный юнит-файл, который запускает команду /usr/bin/sha1sum /dev/zero в качестве службы (иначе говоря, демона), Для нас важно то, что foo будет брать буквально все процессорные ресурсы, которые система разрешит ему использовать. Кроме того, здесь у нас есть drop-in, устанавливающий для службы foo значение CPU-шары, равное 2048. По умолчанию, как вы помните, используется значением 1024, поэтому под нагрузкой foo будет получать двойную долю CPU-ресурсов в рамках system.slice, своего родительского слайса верхнего уровня (так как foo – это служба).
Теперь запустим foo через systemctl и посмотрим, что нам покажет команда top:
Поскольку в системе практически нет других работающих вещей, служба foo (pid 2848) потребляет почти все процессорное время одного CPU.
Теперь введем в уравнение пользователя mrichter. Сначала урежем ему CPU-шару до 256, затем он войдет в систему и запустит foo.exe, иначе говоря, ту же самую программу, но как пользовательский процесс.
Итак, mrichter запустил foo. И вот что теперь показывает команда top:
Странно, да? Пользователь mrichter вроде как должен получить процентов 10 процессорного времени, поскольку у него шара = 256, а у foo.service – целых 2048, нет?
Теперь введем в уравнение dorf’а. Это еще один обычный пользователь со стандартной CPU-шарой, равной 1024. Он тоже запустит foo, а мы опять посмотрим, как изменится распределение процессорного времени.
dorf – пользователь старой школы, он просто запускает процесс, без всяких умных сценариев и прочего. А мы опять смотрим вывод top:
Так… давайте-ка глянем дерево cgroups и попробуем разобраться, что к чему:
Если помните, обычно в системе есть три cgroups верхнего уровня: System, User и Machine. Поскольку виртуальных машин в нашем примере нет, остаются только слайсы System и User. Каждый из них имеет CPU-шару по 1024, и поэтому под нагрузкой получает половину процессорного времени. Так как foo.service живет в System, и других претендентов на процессорное время в этом слайсе нет, то foo.service получает 50% ресурсов CPU.
Далее, в слайсе User живут пользователи dorf и mrichter. У первого шара равна 1024, у второго – 256. Поэтому dorf получает в четыре раза больше процессорного времени, чем mrichter. Теперь смотрим, что показывает top: foo.service – 50%, dorf – 40%, mrichter – 10%.
Переводя это на язык сценариев использования, можно сказать, что dorf имеет больший приоритет. Соответственно, cgroups настроены так, что пользователю mrichter урезают ресурсы на то время, пока они нужны dorf'у. Действительно, ведь пока mrichter был в системе один, он получал 50% процессорного времени, поскольку в слайсе User больше никто не конкурировал на ресурсы CPU.
По сути, CPU-шары – это способ обеспечить некий «гарантированный минимум» процессорного времени, даже для пользователей и служб с пониженным приоритетом.
Кроме того, у нас есть способ установить жесткую квоту на ресурсы CPU, некий лимит в абсолютных цифрах. Сделаем это для пользователя mrichter и посмотрим, как изменится картина распределение ресурсов.
А теперь убьем задачи пользователя dorf, и вот что получится:
Для mrichter’прописан абсолютный CPU-лимит в 5%, поэтому foo.service получает все остальное процессорное время.
Продолжим издевательства и остановим foo.service:
Что мы здесь видим: mrichter имеет 5% процессорного времени, а оставшиеся 95 % система простаивает. Форменное издевательство, да.
На самом деле, такой подход позволяет эффективно усмирить службы или приложения, которые любят внезапно взбрыкивать и оттягивать на себя все процессорные ресурсы в ущерб остальным процессам.
Итак, мы узнали, как контролировать текущую ситуацию с cgroups. Теперь копнем чуть глубже и посмотрим, как cgroup реализуются на уровне виртуальной файловой системы.
Корневой каталог для всех работающих cgroups располагается по адресу /sys/fs/cgroup. При загрузке системы он заполняется по мере запуска сервисов и прочих задач. При запуске и остановке служб, их подкаталоги появляются и исчезают.
На скриншоте ниже мы перешли в подкаталог для CPU-контроллера, а именно в слайсе System. Как видим, подкаталога для foo здесь пока нет. Запустим foo и проверим пару вещей, а именно, его PID и его текущую CPU-шару:
Важное предостережение: здесь можно менять значения на лету. Да, в теории это выглядит круто (и в реальности тоже), но может обернуться большим бардаком. Поэтому прежде чем что-то менять, тщательно все взвесьте и никогда не играйтесь на боевых серверах. Но в любом случае, виртуальная файловая система – это то, в чем стоит поковыряться по мере изучения того, как работают cgroups.