
Продолжаем изучать cgroups. В Red Hat Enterprise Linux 7 они задействуется по умолчанию, поскольку здесь используется systemd, а он, в свою очередь, имеет уже встроенные cgroups. С Red Hat Red Hat Enterprise Linux 6 все немного иначе. На самом деле контроллеры cgroups изначально были и там, а вышла эта версия, напомним, в январе 2010 года, то есть пару столетий назад в пересчете на компьютерные годы.

Однако cgroups в Red Hat Enterprise Linux 6 и сегодня на многое способны, что мы сегодня и проиллюстрируем.
Разберем возможности cgroups в Red Hat Enterprise Linux 6 на одном чисто гипотетическом примере, целиком и полностью основанном на реальных событиях. Но для начала, по традиции, маленькое отступление.
С безопасностью в ИТ еще никогда не было столько проблем как сейчас. Неудивительно, ведь сегодня к сети подключены не только все компьютеры и телефоны, но и холодильники, пылесосы и куча разных других вещей – простор для сетевых угроз просто необъятный. И борьба с этими угрозами, как правило, начинается сразу по всем фронтам. Оперативная установка исправлений безопасности? Да, обязательно! Усиление защиты системы – брандмауэры, SELinux, грамотная аутентификация, вот это вот все? Безусловно! Антивирусные сканеры на Linux-машинах? Ну-у, как сказать…
На Linux-машинах от антивирусных сканеров иногда бывает больше вреда, чем пользы. Однако у безопасников свои резоны, и они зачастую требуют регулярно запускать антивирусные проверки, не особо задумываясь об их обоснованности с технической точки зрения. И это реальность, с которой приходится мириться, и с которой, рано или поздно, сталкивается практический любой ИТ-шник.
Второй момент заключатся в том, что Red Hat Enterprise Linux 7 – это конечно модно, продвинуто и круто, но многие всё еще используют Red Hat Enterprise Linux 6 и не думают от нее отказываться. Вообще-то, люди поэтому и выбирают Red Hat – можно годами сидеть на одной и той же версии и при этом иметь все последние патчи, обновления и поддержку.
Возвращаемся к нашему примеру… Представьте, что есть парень по имени Джерри. Джерри работает в большой конторе и отвечает за сервера Red Hat Enterprise Linux 6. Его полностью устраивает, как они работают, и новые проблемы и головняки ему не нужны.
Но тут ребята из отдела безопасности решают, что на все его сервера надо поставить одну штуку под названием ScanIT. И поскольку эта штука будет периодически проверять диски и память на вирусы и прочие зловреды, ей нужен полный root-доступ.
Джерри вздыхает, откладывает гитару и идет ставить ScanIT на тестовую машину. Довольно быстро выясняется вот что:
В общем, с этим надо что-то делать.
Джерри берет гитару и, наигрывая Grateful Dead, начинает думать. Довольно быстро ему в голову приходит мысль, что здесь наверно могут помочь те самые cgroups из Red Hat Enterprise Linux 7, про которые ему прожужжал все уши приятель по имени Алекс. Джерри опять откладывает гитару и берется читать присланные Алексом доки по Red Hat Enterprise Linux 6. Выясняется, что первым делом ему понадобиться libcgroup.
На тестовой машине libcgroup нет, поэтому Джерри начинает ее ставить:
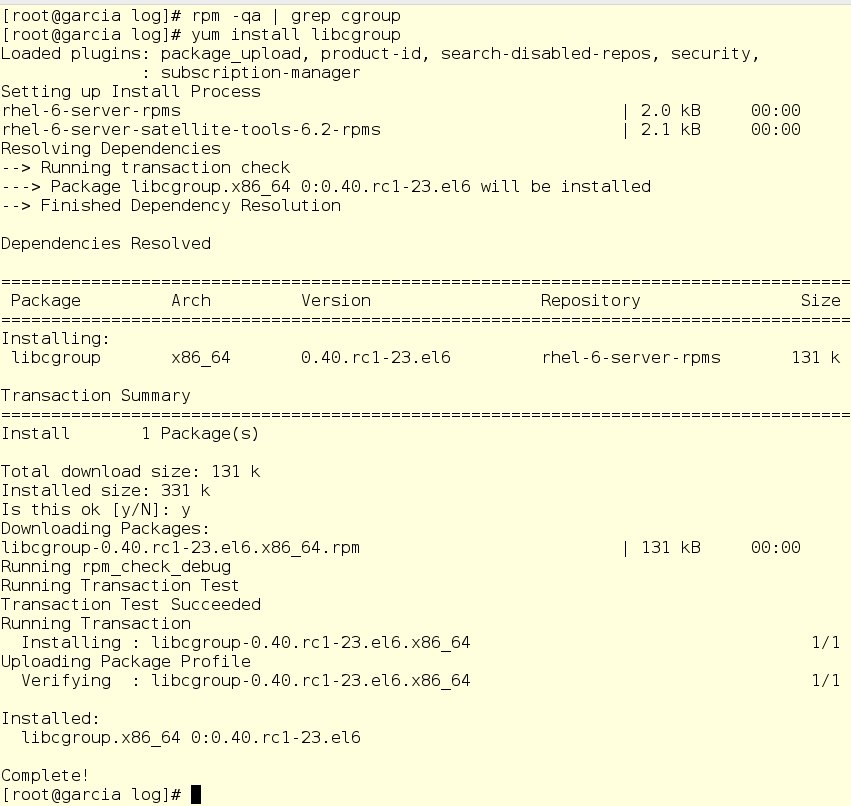
Кроме того, Джерри включает две службы, которые нужны для работы постоянных (персистентных) cgroups:

Установив и настроив все это, Джерри наконец-то может приступать непосредственно к самой проблеме. Хорошенько все обдумав, он принимает следующее решение:
Джерри придется иметь дело с двумя наборами конфигурационных файлов:
Вот как по умолчанию выглядит файл cgconfig.conf:

Джерри мог бы внести необходимые правки прямо в него, но лучше использовать для этого conf-файлы drop-in. Как это работает? Если положить (англ. drop-in – вбросить) в папку /etc/cgconfig.d любой файл с расширением .conf, система обработает его и внесет соответствующие изменения в конфигурацию. Это удобно тем, что можно создавать drop-in’ы под разные задачи и добавлять или удалять их из конфигурации с помощью тех, инструментов, которые вам больше нравятся (допустим, Ansible, ну, это же все-таки блог Red Hat).
Вначале Джерри создает файл drop-in для CPU:
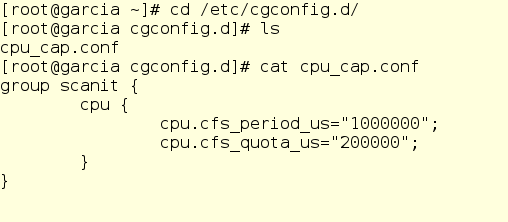
Смотрим, что тут у нас и как это работает.
Ключевое слово group просто задает имя новой группы cgroup, в нашем случае – scanit. Внутри фигурных скобок мы указываем регуляторы cgroup, которые хотим использовать. Здесь это cpu.cfs_period_us и cpu.cfs_quota_us, они позволяют задавать соответствующие лимиты в Completely Fair Scheduler, планировщике ядра, который по умолчанию используется в Red Hat Enterprise Linux 6. Давайте посмотрим, что про них написано в Руководстве по управлению ресурсами Red Hat Enterprise Linux 6:

Иначе говоря, Джерри написал в своем drop-in вот что: «Для каждого процесса, относящегося к cgroup по имени scanit, раз в секунду проверять объем выделенных ему CPU-ресурсов. Если суммарное процессорное время по всем процессам в этой группе больше 200 000 миллисекунд, то полностью перестать выдавать процессорное время этим процессам». Ну, то есть выделять всем процессам в cgroup-группе scanit, а также их дочерним процессам, суммарно не более 20% процессорного времени.
После перезапуска cgconfig сервер обновит конфигурацию, и если залезть в файловую систему, мы увидим, что scanit теперь располагается в каталоге контроллера CPU:

Это, конечно, хорошо, но нам еще надо как-то засунуть в эту cgroup собственно сам scanit. Тут пригодится crged, по умолчанию он выглядит примерно так:
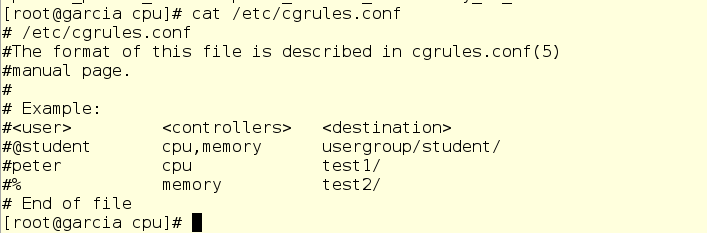
Пользоваться этим файлом более-менее легко. Правда, для этого нам придется напрямую редактировать файл cgrules.conf, поскольку механизм drop-in’ов здесь не поддерживается. Мы указываем пользователя или группу, которые являются владельцами процесса, а также имя конкретного – если хочется – процесса, а также настраиваемый регулятор и группу назначения cgroup.
В нашем примере мы вместо реального антивирусного сканера scanit используем сценарий, который тоже называется scanit, но на самом деле просто эмулирует нагрузку. Без cgroup все это выглядит вот так:

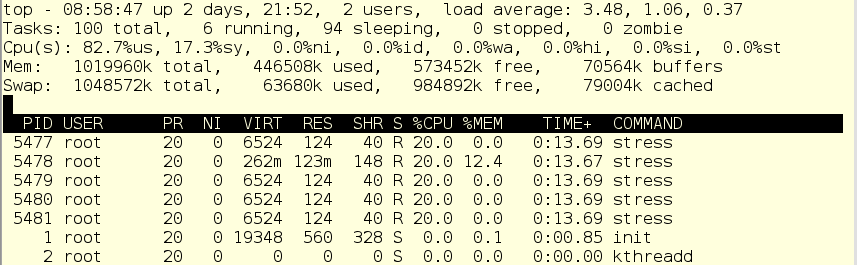
CPU полностью занят, в основном user space’ом и немного system.
Джерри чешет бороду. Он запускает vi и, пользуясь строго одним указательным пальцем, вносит кое-какие изменения и перезапускает демон cgred:

Потом он вручную запускает scanit…:

И – ура! Победа.
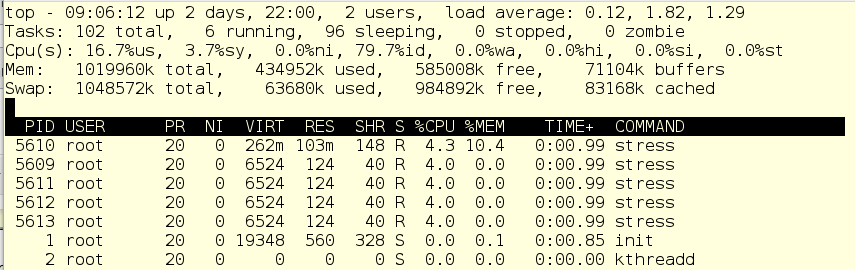
Как видите, наши процессы-эмуляторы нагрузки (дочерние процессы scanitс) теперь суммарно потребляют 20 % ресурсов CPU, в основном в user space и немного в system. Значит, этот чертов антивирус больше не будет грузить машину до полной невменяемости.
Обрадованный успехом, Джерри чуть было не забыл про память. Но потом все-таки вспоминает и снова запускает vi, чтобы поправить свой config-файл.
Теперь он добавляет туда две настройки, касающиеся памяти:

О-о, нет! Да что не так-то?
Джерри смотрит топ и видит, что дочерние процессы scanit по-прежнему работают. Поскольку эта cgroup сейчас используется, Джерри не может запустить службу. Поэтому он убивает дочерние процессы вручную и такие перезапускает службы.

Теперь немного правки в cgred.conf:
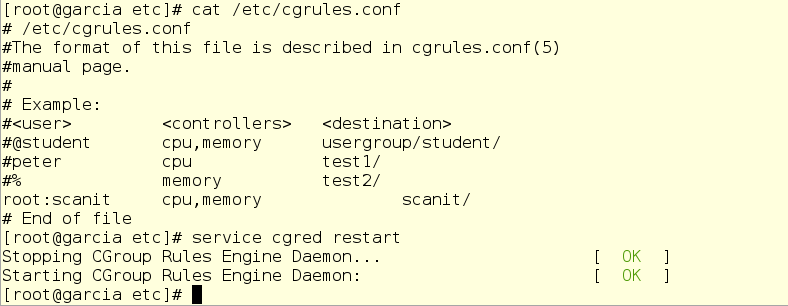
Для проверки Джерри запускает сразу несколько задач scanit, чтобы OOM killer сработал наверняка.
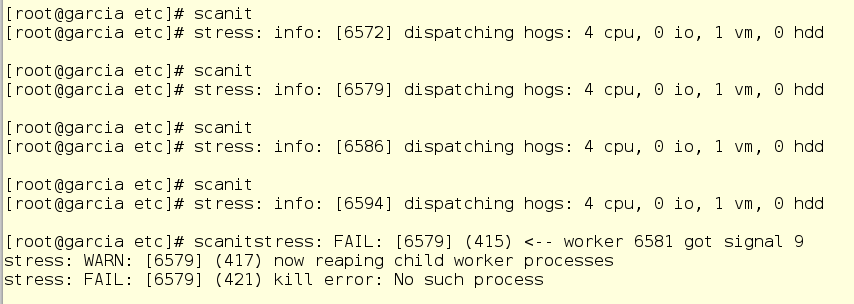
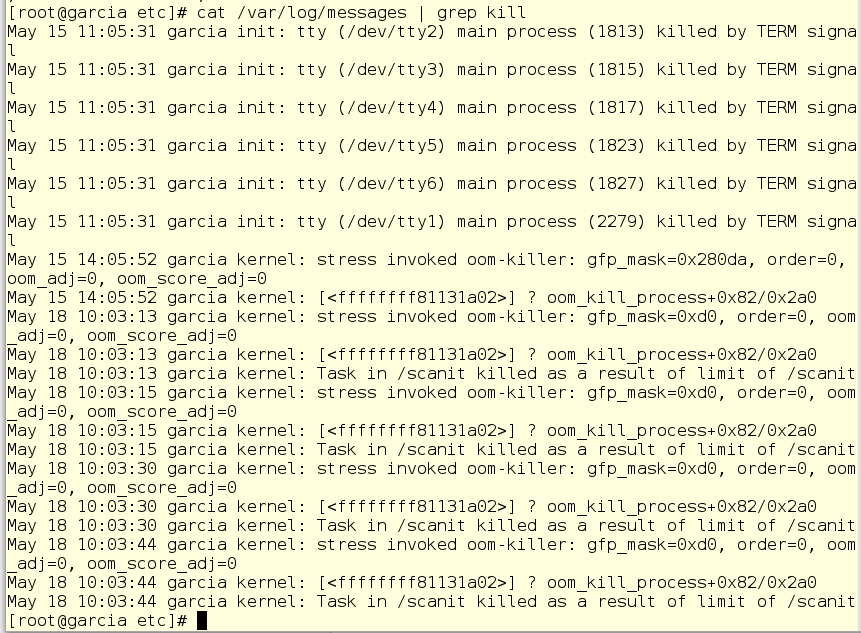
Потом Джерри смотрит системный лог и удовлетворенно кивает – scanit больше не может безнаказанно отъедет память в любых количествах.
Надеемся, наша серия статей по cgroups помогла вам понять, что это такое, как ими пользоваться в Red Hat Enterprise Linux 7, как создавать их в Red Hat Enterprise Linux 6, а также как использовать их в вашей среде.
Вопросы?
Однако cgroups в Red Hat Enterprise Linux 6 и сегодня на многое способны, что мы сегодня и проиллюстрируем.
Разберем возможности cgroups в Red Hat Enterprise Linux 6 на одном чисто гипотетическом примере, целиком и полностью основанном на реальных событиях. Но для начала, по традиции, маленькое отступление.
С безопасностью в ИТ еще никогда не было столько проблем как сейчас. Неудивительно, ведь сегодня к сети подключены не только все компьютеры и телефоны, но и холодильники, пылесосы и куча разных других вещей – простор для сетевых угроз просто необъятный. И борьба с этими угрозами, как правило, начинается сразу по всем фронтам. Оперативная установка исправлений безопасности? Да, обязательно! Усиление защиты системы – брандмауэры, SELinux, грамотная аутентификация, вот это вот все? Безусловно! Антивирусные сканеры на Linux-машинах? Ну-у, как сказать…
На Linux-машинах от антивирусных сканеров иногда бывает больше вреда, чем пользы. Однако у безопасников свои резоны, и они зачастую требуют регулярно запускать антивирусные проверки, не особо задумываясь об их обоснованности с технической точки зрения. И это реальность, с которой приходится мириться, и с которой, рано или поздно, сталкивается практический любой ИТ-шник.
Второй момент заключатся в том, что Red Hat Enterprise Linux 7 – это конечно модно, продвинуто и круто, но многие всё еще используют Red Hat Enterprise Linux 6 и не думают от нее отказываться. Вообще-то, люди поэтому и выбирают Red Hat – можно годами сидеть на одной и той же версии и при этом иметь все последние патчи, обновления и поддержку.
Возвращаемся к нашему примеру… Представьте, что есть парень по имени Джерри. Джерри работает в большой конторе и отвечает за сервера Red Hat Enterprise Linux 6. Его полностью устраивает, как они работают, и новые проблемы и головняки ему не нужны.
Но тут ребята из отдела безопасности решают, что на все его сервера надо поставить одну штуку под названием ScanIT. И поскольку эта штука будет периодически проверять диски и память на вирусы и прочие зловреды, ей нужен полный root-доступ.
Джерри вздыхает, откладывает гитару и идет ставить ScanIT на тестовую машину. Довольно быстро выясняется вот что:
- При выполнении антивирусного сканирования scanit (это скрипт для запуска процесса) отъедает все процессорное время, до которого только может дотянуться. И это о-очень плохо отражается на работе тестовой машины – один раз Джерри даже не мог до нее достучаться по ssh.
- Кроме того, процесс scanit время от времени ест память как не в себя. В результате, просыпается OOM Killer и начинает убивать какие угодно процессы, кроме самого scanit.
В общем, с этим надо что-то делать.
Джерри берет гитару и, наигрывая Grateful Dead, начинает думать. Довольно быстро ему в голову приходит мысль, что здесь наверно могут помочь те самые cgroups из Red Hat Enterprise Linux 7, про которые ему прожужжал все уши приятель по имени Алекс. Джерри опять откладывает гитару и берется читать присланные Алексом доки по Red Hat Enterprise Linux 6. Выясняется, что первым делом ему понадобиться libcgroup.
На тестовой машине libcgroup нет, поэтому Джерри начинает ее ставить:
Кроме того, Джерри включает две службы, которые нужны для работы постоянных (персистентных) cgroups:
- cgconfig – предоставляет более-менее простой интерфейс для работы с деревьями cgroup. Джерри конечно мог бы монтировать и конфигурировать cgroups вручную, но зачем, если можно сэкономить время?
- cgred – эта штука представляет собой движок правил cgroup: при запуске какого-либо процесса эта служба кладет его в ту или иную cgroup согласно заданным правилам.
Установив и настроив все это, Джерри наконец-то может приступать непосредственно к самой проблеме. Хорошенько все обдумав, он принимает следующее решение:
- scanit и его дочерние процессы должны потреблять не более 20 % CPU-ресурсов. На самом деле даже меньше – не более 20 % ресурсов одного процессорного ядра, даже на многоядерной машине. В cgroups это делается с помощью CPU-квот.
- Что касается памяти, то scanit и его дочерние процессы должны потреблять не более 512 Мб системной памяти. Если они переходя эту черту, система должны убивать именно их, а не какие-либо другие процессы.
Не надо говорить мне, что мне делать!
Джерри придется иметь дело с двумя наборами конфигурационных файлов:
- /etc/cgconfig.conf – автоматически генерируется при установке libcgroup.
- /etc/cgrules.conf – содержит набор правил ruleset, согласно которым cgred сортирует запускающиеся процессы по группам cgroups.
Вот как по умолчанию выглядит файл cgconfig.conf:
Джерри мог бы внести необходимые правки прямо в него, но лучше использовать для этого conf-файлы drop-in. Как это работает? Если положить (англ. drop-in – вбросить) в папку /etc/cgconfig.d любой файл с расширением .conf, система обработает его и внесет соответствующие изменения в конфигурацию. Это удобно тем, что можно создавать drop-in’ы под разные задачи и добавлять или удалять их из конфигурации с помощью тех, инструментов, которые вам больше нравятся (допустим, Ansible, ну, это же все-таки блог Red Hat).
Вначале Джерри создает файл drop-in для CPU:
Смотрим, что тут у нас и как это работает.
Ключевое слово group просто задает имя новой группы cgroup, в нашем случае – scanit. Внутри фигурных скобок мы указываем регуляторы cgroup, которые хотим использовать. Здесь это cpu.cfs_period_us и cpu.cfs_quota_us, они позволяют задавать соответствующие лимиты в Completely Fair Scheduler, планировщике ядра, который по умолчанию используется в Red Hat Enterprise Linux 6. Давайте посмотрим, что про них написано в Руководстве по управлению ресурсами Red Hat Enterprise Linux 6:
Иначе говоря, Джерри написал в своем drop-in вот что: «Для каждого процесса, относящегося к cgroup по имени scanit, раз в секунду проверять объем выделенных ему CPU-ресурсов. Если суммарное процессорное время по всем процессам в этой группе больше 200 000 миллисекунд, то полностью перестать выдавать процессорное время этим процессам». Ну, то есть выделять всем процессам в cgroup-группе scanit, а также их дочерним процессам, суммарно не более 20% процессорного времени.
После перезапуска cgconfig сервер обновит конфигурацию, и если залезть в файловую систему, мы увидим, что scanit теперь располагается в каталоге контроллера CPU:
Это, конечно, хорошо, но нам еще надо как-то засунуть в эту cgroup собственно сам scanit. Тут пригодится crged, по умолчанию он выглядит примерно так:
Пользоваться этим файлом более-менее легко. Правда, для этого нам придется напрямую редактировать файл cgrules.conf, поскольку механизм drop-in’ов здесь не поддерживается. Мы указываем пользователя или группу, которые являются владельцами процесса, а также имя конкретного – если хочется – процесса, а также настраиваемый регулятор и группу назначения cgroup.
В нашем примере мы вместо реального антивирусного сканера scanit используем сценарий, который тоже называется scanit, но на самом деле просто эмулирует нагрузку. Без cgroup все это выглядит вот так:
CPU полностью занят, в основном user space’ом и немного system.
Джерри чешет бороду. Он запускает vi и, пользуясь строго одним указательным пальцем, вносит кое-какие изменения и перезапускает демон cgred:
Потом он вручную запускает scanit…:
И – ура! Победа.
Как видите, наши процессы-эмуляторы нагрузки (дочерние процессы scanitс) теперь суммарно потребляют 20 % ресурсов CPU, в основном в user space и немного в system. Значит, этот чертов антивирус больше не будет грузить машину до полной невменяемости.
Помните, что дальше?
Обрадованный успехом, Джерри чуть было не забыл про память. Но потом все-таки вспоминает и снова запускает vi, чтобы поправить свой config-файл.
Теперь он добавляет туда две настройки, касающиеся памяти:
- Memory.limit_in_bytes – макс. объем RAM, который могут использовать все процессы в cgroup-группе scanit, суммарно. И без учета места в свопе. Джери ограничивает его 256 Мб
- Memory.memsw.limit_in_bytes – макс. объем RAM, плюс место в свопе-файле, которые могут выделяться всем процессам в cgroup-группе scanit, суммарно. При превышении этого порога процессы будут убиваться OOM killer’ом. Джерри устанавливает его равным 512 Мб.
О-о, нет! Да что не так-то?
Джерри смотрит топ и видит, что дочерние процессы scanit по-прежнему работают. Поскольку эта cgroup сейчас используется, Джерри не может запустить службу. Поэтому он убивает дочерние процессы вручную и такие перезапускает службы.
Теперь немного правки в cgred.conf:
Для проверки Джерри запускает сразу несколько задач scanit, чтобы OOM killer сработал наверняка.
Потом Джерри смотрит системный лог и удовлетворенно кивает – scanit больше не может безнаказанно отъедет память в любых количествах.
Надеемся, наша серия статей по cgroups помогла вам понять, что это такое, как ими пользоваться в Red Hat Enterprise Linux 7, как создавать их в Red Hat Enterprise Linux 6, а также как использовать их в вашей среде.
Вопросы?
Комментарии (7)

romychs
10.11.2018 11:21О-о, нет! Да что не так-то
Самое серьезное ограничение, на мой взгляд, когда процессов, на которые наложены ограничения cgroups много, проще будет перезагрузить сервер)
Andronas
10.11.2018 11:45Еще пожелание: были рассмотрены ресурсы CPU, память, диски, но не рассмотрели как ограничивать network траффик (например ширину канала для определенных приложений и/или пользователей). Планируете написать об этом? Тема непростая, там насколько понимаю применяется traffic controller для маркировки пакетов, и net_cls.
mikkisse
Очень хороший цикл статей. Было интересно почитать.
EvelinaN
Спасибо. После небольшого перерыва продолжим статьи на эту тему. А в перерыве — про RHEL и Ansible
mikkisse
Продолжайте в том же духе. Ваш блог хорош.