

Привет Хабр! Сегодня мы продолжим прошлый рассказ о ДНК. В нем мы поговорили о том, сколько ее бывает, как ДНК хранится и почему так важно то, как она хранится. Сегодня мы начнем с исторической справки и закончим основами кодирования информации в ДНК.
История
Сама по себе ДНК была выделена еще в 1869 году Иоганном Фридрихом Мишером из лейкоцитов, которые он получал из гноя. Лейкоциты это белые клетки крови, выполняющие защитную функцию. В гное их довольно много, ведь они стремятся к поврежденным тканям, где «поедают» бактериальные клетки. Он выделил вещество, в состав которого входят азот и фосфор. Вначале оно получило название нуклеин, однако, когда у него обнаружили кислотные свойства, название изменили на нуклеиновую кислоту. Биологическая функция новооткрытого вещества была неясна, и долгое время считалась, что в нем запасается фосфор. Даже в начале XX века многие биологи считали, что ДНК не имеет никакого отношения к передаче информации, поскольку строение молекулы, как тогда казалось, было слишком однообразным и не могло закодировать столько информации.
К 1901 году Альбрехт Коссель выделил и описал пять азотистых оснований, входящих в состав ДНК и РНК. А еще чуть позже Петр Левен установил, что углеводным компонентом нуклеиновых кислот являются дезоксирибоза и рибоза. Нуклеиновые кислоты, в состав которых входит рибоза стали называть рибонуклеиновыми кислотами или, сокращенно, РНК, а те, которые содержали дезоксирибозу, дезоксирибонуклеиновыми кислотами, или ДНК.
Теперь, встал вопрос, как отдельные звенья соединены между собой. Для этого цепи ДНК нужно было разрушить и посмотреть на то, что получится после разрушения. Для этого полимер ДНК подвергался гидролизу. Однако Левен изменил метод гидролиз. Теперь вместо многочасового кипячения в закисленной среде он использовал ферменты. На этот раз из гидролизатов удалось выделить не только отдельные аденин, гуанин, тимин, цитозин, дезоксирибозу и фосфорную кислоту, но и более крупные фрагменты, например соединения азотистых оснований с углеводом или углевода с фосфорной кислотой. Вместе с тем в гидролизатах нуклеиновых кислот не были обнаружены соединения, состоящие из двух азотистых оснований, или соединения типа основание – фосфорная кислота. То есть стало понятно, что фосфорная кислота соединяется с сахаром, а он в свою очередь, с азотистым основанием. Соединения азотистых оснований с углеводом было предложено называть нуклеозидами, а фосфорные эфиры нуклеозидов назвали нуклеотидами.
В результате этих работ Левен пришел к выводу, что нуклеиновые кислоты являются полимерами. В качестве мономеров служат нуклеотиды. Содержание каждого из четырех нуклеотидов в ДНК, или РНК, по данным химического анализа того времени, представлялось Левену равным. Поэтому Левен предложил следующую теорию строения нуклеиновых кислот: они являются полимерами, мономерами которых служат блоки из четырех нуклеотидов, соединенных последовательно.
Теория тетрануклеотидного строения в то время выглядела вполне обоснованно, войдя во все учебники довоенного времени. Однако вопрос функции ДНК оставался неясным. Чтобы прояснить этот вопрос понадобилось почти полвека.
Наступил период, во время которого биологи накапливали сведения об распространении нуклеиновых кислот в различных типах животных и растительных тканей, в бактериях и вирусах, в некоторых одноклеточных организмах.
В то время научное сообщество всерьез полагало, что за хранение генетической информации ответственны именно белки. Традиционное представление о первичной роли белков в жизненном процессе не позволяло и думать о том, что столь важное вещество, как вещество наследственности, могло быть чем-либо, кроме белка. Белки были крайне разнообразны по своей структуре, чего тогда не могли сказать о нуклеиновых кислотах. Известный советский генетик-цитолог Н. К. Кольцов подсчитал, что, варьируя последовательность 20 аминокислот, входящих в состав белковой молекулы, можно создать триллионы непохожих друг на друга белков.
Если бы мы захотели напечатать в самой упрощенной форме, как печатаются логарифмические таблицы, этот триллион молекул и предоставили для выполнения этого плана все ныне существующие типографии мира, выпуская в год 50000 томов по 100 печатных листов, то до конца предпринятой работы протекло б столько времени, сколько его прошло с архейского периода д наших дней.
Действительно много… 20 в 20й… А ведь последовательности бывают куда длиннее чем 20 аминокислот.
А вот как пишет по этому поводу А. Р. Кизель – один из наиболее эрудированных биохимиков того времени.
Из только что приведенных воззрений на роли нуклеиновой кислоты… вытекает ее непричастность к строению генов и следует, что гены составлены из какого-то другого материала. Этого материала мы еще достоверно не знаем, несмотря на то, что он в большинстве случаев прямо называется белком.Первый успех пришел из микробиологии. В 1944 г. были опубликованы результаты опытов Эвери и сотрудников (США) по трансформации бактерий. Пару слов о трансформации.
Сама трансформация была открыта в 1928 году микробиологом Гриффитсом.
Гриффит работал с культурами пневмококка (Streptococcus pneumoniae) возбудителя одной из форм пневмонии. Некоторые штаммы этой бактерии являются вирулентными, вызывая воспаление легких. Их клетки покрыты полисахаридной капсулой, защищающей бактерию от действия иммунной системы. В культуре такие бактерии образуют крупные гладкие колонии правильной сферической формы. Благодаря этому, они получили название S–штаммы (от английского smooth – гладкий).
Существуют различные вирулентные штаммы пневмококка, они отличаются по антителам, которые вырабатываются в организме при попадании в него бактерий. Их называют IS, IIS, IIIS и т. д. Время от времени некоторые клетки вирулентных штаммов S мутируют, утрачивая способность синтезировать полисахаридную оболочку, и становятся авирулентными. В культуре они образуют мелкие шероховатые колонии неправильной формы, из-за этого получили название R–штаммов (от английского rough – шероховатый). Иногда происходят обратные мутации, восстанавливающие способность к синтезу полисахаридной оболочки, но только в группах соответствующих штаммов:
IIS — IIR
IIIS — IIIR
Это говорит о том, что авирулентные R–штаммы всегда соответствуют родительскому вирулентному S–штамму.
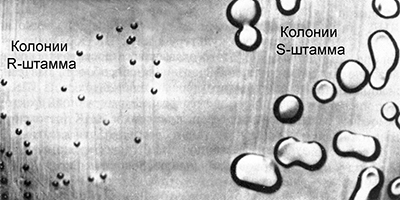
Гриффит вводил разным группам лабораторных мышей вирулентный и авирулентный штамм пневмококка. В первой контрольной группе инъекция вирулентного штамма IIIS приводила к гибели животных. Животные второй контрольной группы после инъекции авирулентного штамма IIR оставались живы. После этого Гриффит нагревал раствор с культурой вирулентого штамма IIIS при температуре 60 °С, что привело к гибели бактерий. Убитые нагреванием бактерии он ввел третьей группе подопытных мышей. Животные остались живы, что в принципе и ожидалось. Однако это не все. Он ввел части выживших мышей бактерии авирулентного штамма IIR.
Казалось, ни к каким страшным последствиям для мышей это не могло привести. Однако вопреки ожиданиям, животные погибли. Когда из их тел были выделены бактерии и высеяны в культуру, оказалось, что они относятся к вирулентному штамму IIIS.

Тот факт, что вызывающие гибель мышей клетки синтезировали полисахаридную оболочку типа III, а не II, свидетельствовал о том, что они не могли возникнуть в результате обратной мутации IIR — IIS. Из этого Гриффит сделал очень важный вывод. Авирулентные бактерии штамма IIR могут трансформироваться в вирулентные как-то взаимодействуя с убитыми нагреванием бактериями штамма IIIS, которые еще оставались в теле мышей. Другими словами, авирулентные бактерии штамма IIR получают от мертвых бактерий штамма IIIS некий фактор, превращающий их в вирулентные. Однако, что это за фактор, Гриффит не знал.
Собственно этот феномен и был назван бактериальной трансформацией. Он представляет собой однонаправленный перенос наследственных признаков от одной бактериальной клетки к другой.
Теперь вернемся к опытам Эвери. Схема их экспериментов несколько схожа с экспериментами Гриффитса. Эвери и сотрудники поставили перед собой задачу выяснить химическую природу трансформирующего агента. Они разрушали суспензию пневмококков и удаляли из экстракта белки, капсульный полисахарид и РНК, однако трансформирующая активность экстракта сохранялась. Трансформирующая активность препарата не терялась при его обработке кристаллическим трипсином или химотрипсином (разрушающими белки), рибонуклеазой (разрушает РНК). Было ясно, что препарат не являлся ни белком, ни РНК. Однако трансформирующая активность препарата полностью утрачивалась при обработке его дезоксирибонуклеазой (разрушающей ДНК), причем ничтожные количества фермента вызывали полную инактивацию препарата. Таким образом, было установлено, что трансформирующий фактор у бактерий является чистой ДНК. Этот вывод явился значительным открытием, и Эвери отлично сознавал это. Он писал, что это как раз то, о чем давно мечтали генетики, а именно вещество гена. Кажется вот оно доказательство. Но уж слишком сильна была вера в белок, как вещество наследственности. Некоторые считали, что трансформацию могут вызывать и те ничтожные примеси белка, которые оставались в препарате.
Новым доказательством прямой генетической роли ДНК явились опыты вирусологов Херши и Чейз. Они работали с бактериофагом Т2 (Бактериофаги — вирусы бактерий), который заражает бактерию Escherichia coli (кишечную палочку).
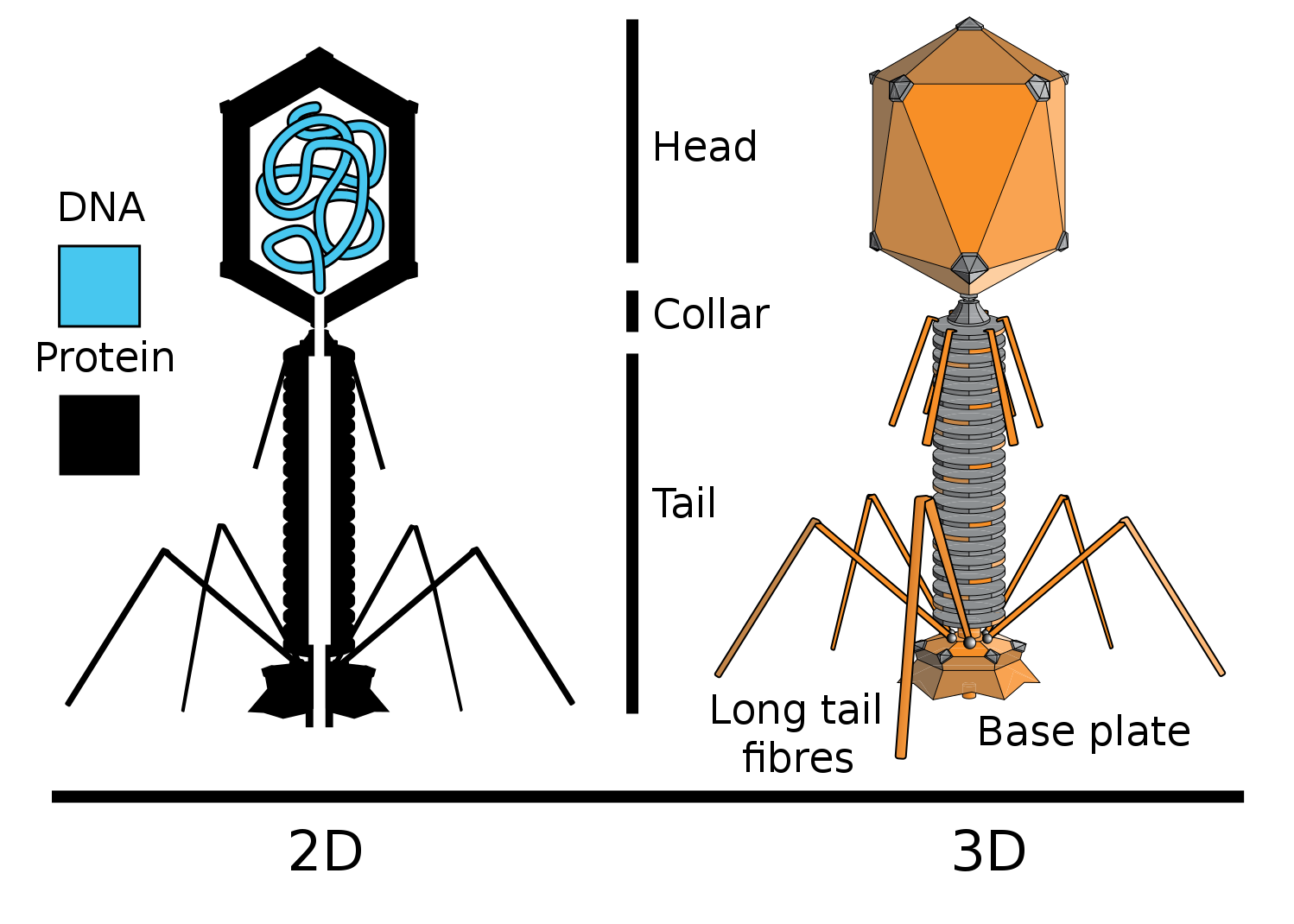
Собственно что они сделали. В состав ДНК одних бактериофагов они включили радиоактивный фосфор (P32), а в состав белков других — изотоп серы (S35). Для этого одни бактерии выращивались на среде с добавлением радиоактивного фосфора в составе фосфат иона, другие — на среде с добавлением радиоактивной серы в составе сульфат иона. Затем к этим бактериям добавлялся бактериофаг Т2, который, размножаясь в клетках бактерий, включал радиоактивную метку в свою ДНК (P есть в ДНК, но нет в белках), или белки (S есть в белках, но нет в ДНК).
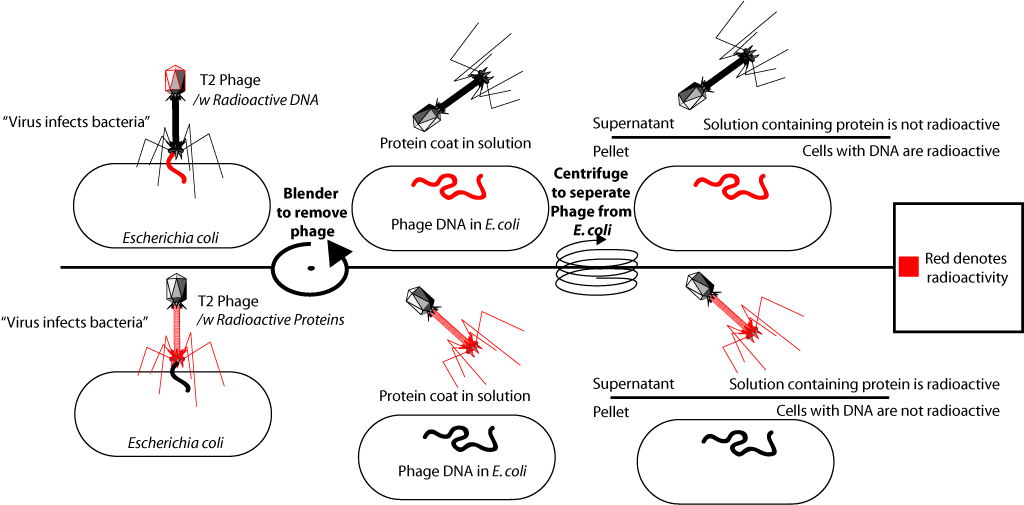
После выделения радиоактивно-меченых бактериофагов их добавляли к культуре свежих (не содержащих изотопов) бактерий. Что приводило к инфицированию этих бактерий. Бактериофаг присоединяется к клетке бактерии и «впрыскивает» свою ДНК. После этого среду с бактериями подвергали энергичному встряхиванию в специальном смесителе (было показано, что при этом оболочки фага отделяются от поверхности бактериальных клеток), а затем инфицированных бактерий отделяли от среды. Когда в первом опыте к бактериям добавлялись меченые фосфором-32 бактериофаги, оказалось, что радиоактивная метка находилась в бактериальных клетках. Когда же во втором опыте к бактериям добавлялись бактериофаги, меченые серой-35, то метка была обнаружена во фракции среды с белковыми оболочками, но её не было в бактериальных клетках. Это подтвердило, что материалом, которым инфицировались бактерии, является ДНК. Поскольку внутри инфицированных бактерий формируются полные вирусные частицы, содержащие белки вируса, данный опыт стал одним из решающих доказательств того факта, что генетическая информация (информация о структуре белков) содержится в ДНК.
Эти открытия сильно повлияли на многих биологов того времени. В особенности на знаменитого своими правилами Чаргаффа. Он считал, что Эвери по сути открыл 'новый язык', или как минимум показал, где его искать.
Чаргафф принялся искать разницу в нуклеотидном составе и расположении нуклеотидов в препаратах ДНК, полученных из различных источников. И, поскольку методов позволяющих точно дать химическую характеристику ДНК, в то время не существовало… ему пришлось их придумать. Им было показано, что старая тетрануклеотидная теория строения нуклеиновых кислот неверна. ДНК у разных организмов по составу и строению сильно отличаются. При этом обнаружились новые факты, не установленные ранее для других природных полимеров, а именно регулярности в соотношении отдельных оснований в составе всех исследованных ДНК. Сейчас даже школьники знают их, как правила Чаргаффа.
- Количество аденина равно количеству тимина, а гуанина — цитозину: А=Т, Г=Ц.
- Количество пуринов равно количеству пиримидинов: А+Г=Т+Ц.
- Вытекает из первого и второго. Количество оснований с аминогруппами в положении 6 равно количеству оснований с кетогруппами в положении 6: А+Ц=Т+Г.
Механизм мы затрагивали в прошлой статье, поэтому тут я останавливаться на нем не буду.
Потихоньку мы подошли к двум легендарным людям, открывшим структуру ДНК. Фрэнсис Крик и Джеймс Уотсон встретились впервые в 1951 году. Уотсон тогда решил заняться структурой ДНК. Как биолог, он понимал, что при выборе определенной структуры ДНК нужно учитывать существование какого-то простого принципа удвоения молекулы ДНК, заложенного в ее структуре. Ведь одним из важнейших свойств генов является передача наследственной информации.
Криком же была создана теория дифракции рентгеновских лучей на спиралях, позволяющая определить, находится исследуемая структура в спиральной конформации или нет. В то время рентгенограммы ДНК уже существовали. Их получили в Лондоне Морис Уилкинс и Розалинд Фрэнклин.
По характеру рентгенограммы ДНК Уотсон и Крик поняли, что исследуемая структура находится в спиральной конформации. Они знали также, что молекула ДНК представляет собой длинную линейную полимерную цепь, состоящую из мономеров-нуклеотидов. Фосфодезоксирибозный костяк этого полимера непрерывен, а сбоку к дезоксирибозным остаткам присоединены азотистые основания. Для построения моделей оставалось решить вопрос, сколько цепей линейного полимера уложено в компактную структуру.
На основании рентгенограммы В-формы ДНК Уотсон и Крик предположили, что молекула ДНК состоит из двух линейных полинуклеотидных цепей с фосфодезоксирибозным остовом снаружи молекулы и азотистыми основаниями внутри ее. Что в последствии подтвердилось. Оставалось только решить вопрос о порядке расположения азотистых оснований двух цепей внутри биспирали.
Рассматривая возможные комбинации пар азотистых оснований, Уотсон обнаружил, что пары аденин–тимин и гуанин–цитозин имеют одинаковый размер и стабилизируются водородными связями. Сразу же объяснялись и правила Чаргаффа: если в биспирали ДНК аденин одной цепи всегда соединяется с тимином другой цепи, а гуанин всегда входит в паре с цитозином, то аденина в составе ДНК должно быть всегда столько же, сколько тимина, а гуанина – столько же, сколько цитозина. Ясно было также, как должно происходить удвоение молекулы ДНК. Каждая цепь комплементарна другой, и в процессе репликации ДНК цепи биспирали должны разойтись и на каждой полинуклеотидной цепи должна достроиться комплементарная к ней цепь. Тут тоже было несколько теорий, но о них через неделю, в следующей статье.
Кодирование информации
Итак, мы знаем, что ДНК — носитель информации, знаем из чего она состоит. Но как кодирует информацию — все еще не понятно.
Пойдем от задачи. ДНК кодирует 20 аминокислот (можно сказать, что 21, но селеноцистенин пока не трогаем). Нуклеотидов имеется 4 варианта. То есть один нуклеотид может кодировать 4 варианта, 2 — 16, 3 -64. Логично предположить, что код — триплетен (то есть три основания кодируют одну аминокислоту). Про экспериментальное подтверждение можете почитать здесь. Боюсь, что тут и без того много истории…
Собственно у нас есть 64 варианта и 20 аминокислот. Аминокислоты могут кодироваться разными кодонами. Так же существуют старт и стоп кодоны, с которых начинается считывание.
Не забываем, что сначала ДНК считывается в РНК, с которой уже происходит считывание в белок.
Таблица внизу — соответствие кодонов РНК аминокислотам. Помним, что в РНК нет тимина, вместо него идет урацил.

Если вы не нашли в таблице старт кодон — поищите AUG. Он кодирует метионин и одновременно является стартовым. При трансляции генов прокариот, пластидных и митохондриальных генов стартовой аминокислотой является N-формилметионин (это просто для справки)).
Если расписать весь путь от ДНК до белка, получим что-то такое.
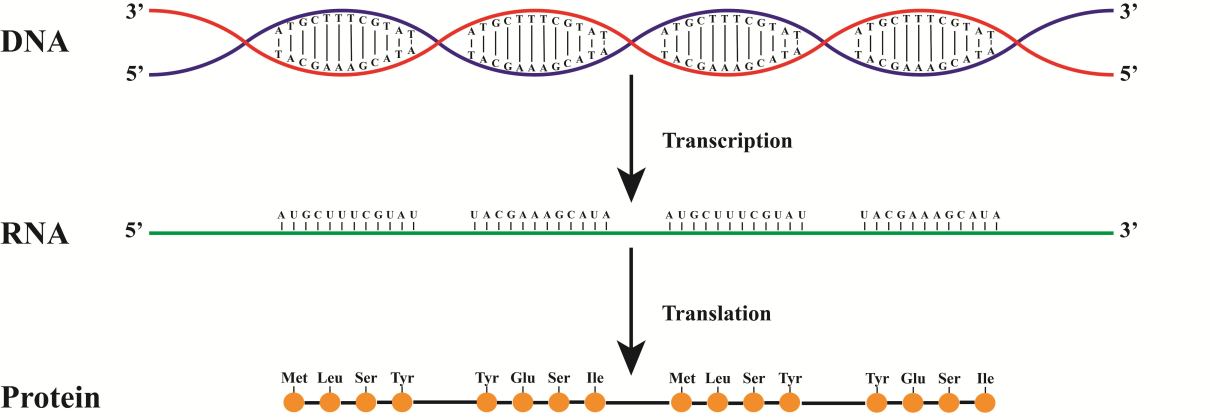
На данном рисунке синтез идет с красной цепи. Как следствие РНК будет совпадать с синей цепью (не забываем про замену Т на У)
Как я уже говорил, каждую аминокислоту может кодировать несколько кодонов. На первый взгляд это кажется не особо нужным побочным эффектом избыточности числа кодонов. Но у него, на самом деле, довольно важная роль.
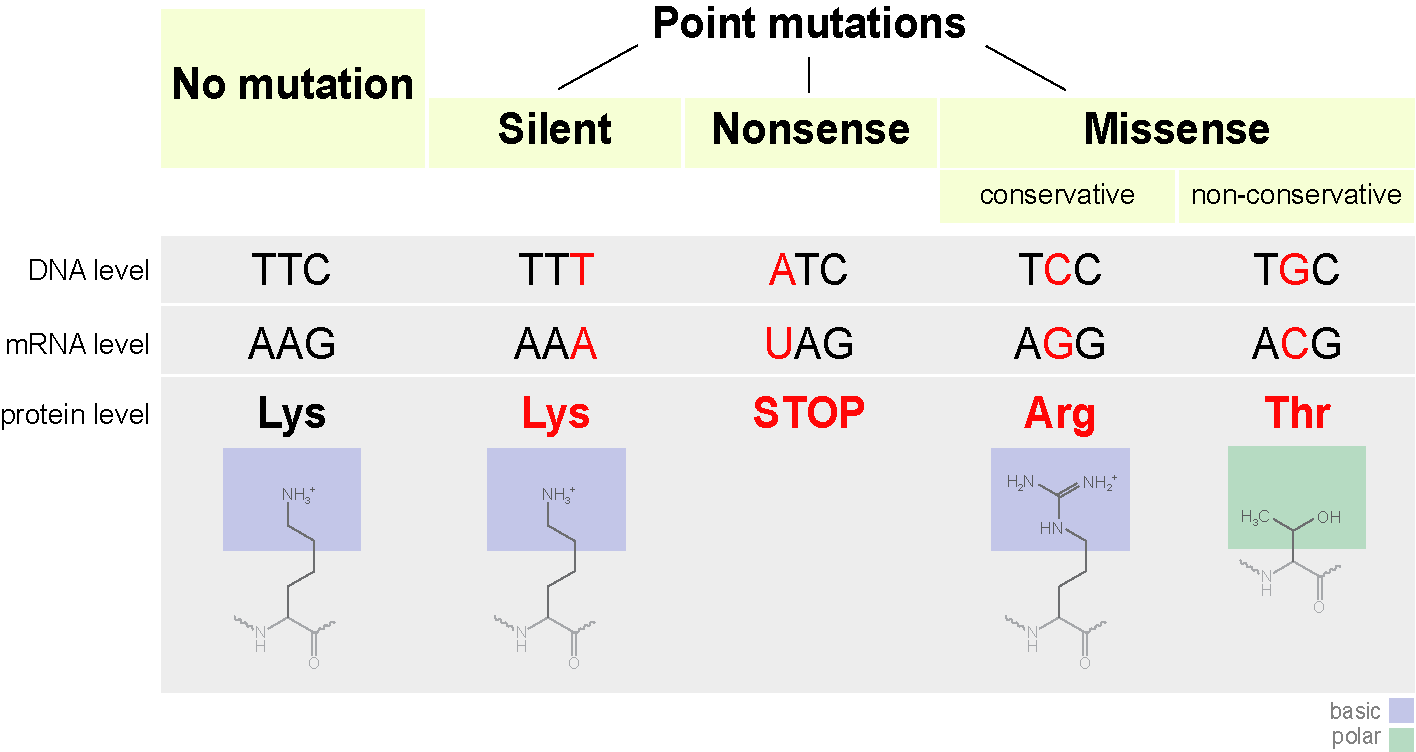
Тут мы немного затронем мутации. Они бывают разных типов. От хромосомных, когда целые куски хромосом удаляются из генома, меняются местами, дублируются, до точечных, когда происходит замена одного азотистого основания на другое. Сфокусируемся на точечных мутациях.
К чему могут привести точечные мутации?
Кодон может начать кодировать другую аминокислоту, что не всегда страшно. Такие мутации называются миссенс-мутацими (то есть со сменой смысла). Это может повлиять на структуру белка. Например если положительно заряженная аминокислота заменится на отрицательно заряженную — это может сделать белок нестабильным, или приведет к тому, что он свернется в другую конформацию (да, линейная последовательность аминокислот обычно сворачивается в определенную форму) и не сможет выполнять свои функции (или начнет делать это лучше, это уже попахивает эволюцией).
Если конкретно, то гемоглобин S имеет единичную замену нуклеотида (А на Т) в кодирующем гене. В результате триплет ГАГ, кодирующий глутамат, заменяется на ГТГ, кодирующий валин. Гемоглобин S тоже может транспортировать кислород, но делает это хуже чем обычный гемоглобин.
В молекуле гемоглобина Хикари аспарагин замещен на лизин, однако он все также хорошо перенести кислород.
Как пример с потерей функции рассмотрим гемоглобин M. Другая точечная мутация в гене гемоглобина приводит к полной утрате функции (гистидин меняется на тирозин в активном центре).
Кстати, сворачивание белка выглядит примерно так, если опустить все нюансы.

Что еще может произойти?
Замена одного азотистого основания может так же привести к появлению стоп кодона в центре последовательности, или наоборот стоп кодон в конце исчезнет. На выходе получится либо неполная цепь, либо экстремально длинная цепь, которые в любом случае не смогут нормально функционировать. Такие мутации называются нонсенс.
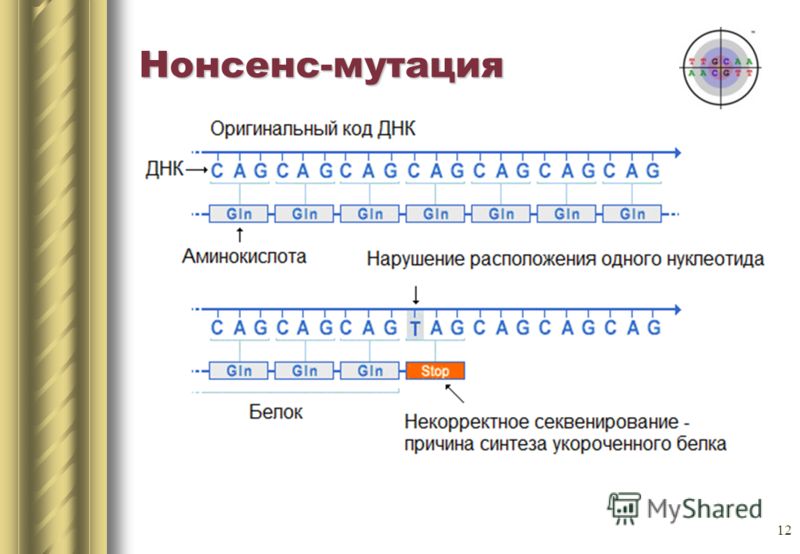
Есть еще третий тип мутации — сайленс-мутация. По сути происходит смена кодона на другой, кодирующий ту же аминокислоту. Свойства белка не меняются.
Подитожим общей схемой.
В завершение хотел бы еще рассказать об одной интересной особенности. Одну аминокислоту может кодировать несколько кодонов. Это мы знаем. Но что это значит? Организм использует сразу все кодоны для кодирования. Но какие-то чаще, какие-то реже.
Сравним человека и… кишечную палочку (Escherichia coli) по частоте использования кодонов кодирующих цистеин.
Он кодируется двумя кодонами UGU и UGC.
Человек
UGU 10.6
UGC 12.6
Кишечная палочка (штамм O127:H6)
UGU 19.1
UGC 0.0
Цифры это встречаемость триплета на тысячу. Видно, что мы используем оба кодона примерно с одинаковой частотой, в то время как E. coli почти не использует UGC кодон.
Об этой особенности нужно помнить, особенно когда ты занимаешься геноинженерией и хочешь нарабатывать продукт гена одного организма в другом. Если ген человека, с частой встречаемость UGC кодона попытаться вставить в кишечную палочку данного штамма — вас ждет разочарование. В клетке аминокислоты связаны с транспортными РНК, каждая из которых соответствует своему кодону. Так вот тРНК соответствующих UGC кодону будет крайне мало, что сильно замедлит синтез.
Если интересно, тут можно посмотреть отличия в кодонном составе у разных организмов.
Кодонный состав может сильно отличаться как у организмов разных видов, так и разных штаммов. Так у Escherichia coli O157:H7 EDL933 все более менее поровну в плане UGC и UGU. Или вот еще пример. У штаммов туберкулезной палочки выделенных в разных странах также отличается кодовый состав.
Подытожу
В этот раз было очень много истории и относительно мало биологии. Больше такого не будет. Мы поговорили о том, как стало понятно, что ДНК — носитель информации, как она хранится в самой ДНК. Поговорили об избыточности ген кода и о том, к чему это приводит. Немного затронули мутации и разницу в частоте использования определенных кодонов.
В следующий раз поговорим о репликации ДНК.
P.S.: там тоже будет история, но куда меньше. Постараюсь больше не делать таких пауз в написании.
Комментарии (2)

MisterParser
22.10.2018 18:59Всегда было интересно на более низком уровне как кодируется информация о человеке в ДНК. Например, форма уха. Ухо состоит из множества кривых. Каждая кривая в ухе, каждая самая маленькая завитушка имеет свою форму, чтобы закодировать каждую самую небольшую кривую нужно несколько коэффициентов. Ну, не в формате же IEEE 754 они там хранятся в ДНК. А как тогда?
Sunny-s
С удовольствием прочитал и жду продолжения.
А можно спойлер? Далеко ли до ДНК-компилятора? Ну, вот тебе библиотека генов, вот стандартные билдеры классов, наследуем, добавляем то что хочется, собираем, заливаем последовательность в программатор — и вот она, новая жизнь? )