
Тотальная стандартизация
Я готовил этот материал для выступления на конференции и спросил у нашего технического директора, в чем главная фишка Kubernetes для нашей организации. Он ответил:
Разработчики сами не понимают, сколько лишней работы делали.
Видимо, его вдохновила недавно прочитанная книга «Factfulness» — сложно заметить незначительные и непрерывные изменения к лучшему, и мы постоянно упускаем из виду свой прогресс.
Но переход на Kubernetes точно нельзя назвать незначительным.

Почти 30 наших команд запускают все или некоторые рабочие нагрузки на кластерах. Примерно 70% нашего HTTP-трафика создается в приложениях на кластерах Kubernetes. Наверное, это самая масштабная конвергенция технологий с моего прихода в компанию после того, как в 2010 году группа Forward купила uSwitch, когда мы перешли с .NET и физических серверов на AWS и с монолитной системы на микросервисы.
И все произошло очень быстро. В конце 2017 все команды использовали свою инфраструктуру AWS. Они настраивали балансировщики нагрузки, экземпляры EC2, обновления кластеров ECS и все в таком духе. Прошло чуть больше года, и все изменилось.
Мы потратили на конвергенцию минимум времени, и в итоге Kubernetes помог нам решить насущные проблемы — наше облако разрасталось, организация усложнялась, и мы с трудом вписывали в команды новых людей. Мы не меняли организацию, чтобы использовать Kubernetes. Наоборот — мы использовали Kubernetes, чтобы изменить организацию.
Может, разработчики и не заметили больших изменений, но данные говорят сами за себя. Об этом чуть позже.
Много лет назад я был на конференции по Clojure и слышал лекцию Майкла Найгарда об архитектуре, которую нельзя привести в конечное состояние. Он открыл мне глаза. Аккуратная и упорядоченная система выглядит карикатурно, когда он сравнивает телемагазины с товарами для кухни и крупномасштабную архитектуру ПО — существующая система похожа на тупой нож, и выходит какая-то каша вместо ровных ломтиков. Без нового ножа нечего и думать о салате.
Это о том, как организации обожают трехлетние проекты: первый год — разработка и подготовка, второй год — внедрение, третий — отдача. В лекции он говорит, что такие проекты обычно делаются непрерывно и редко добираются до конца второго года (часто из-за приобретения другой компанией и изменения направления и стратегии), так что обычная архитектура представляет собой
наслоение перемен в некоем подобии стабильности.
И uSwitch отличный тому пример.
Мы перешли на AWS по многим причинам — наша система не справлялась с пиковыми нагрузками, а развитию организации мешала слишком жесткая система и тесно связанные друг с другом команды, которые формировались под конкретные проекты и разделялись по специализации.
Мы не собирались все бросить, перенести все системы и начать заново. Мы создавали новые сервисы с проксированием через существующий балансировщик нагрузки и постепенно душили старое приложение. Мы хотели сразу показать отдачу и в первую же неделю провели A/B-тестирование первой версии нового сервиса в продакшене. В итоге мы взяли долгосрочные продукты и стали формировать под них команды из разработчиков, дизайнеров, аналитиков и т. д. И сразу увидели результат. В 2010 году это казалось настоящей революцией.
Год за годом мы добавляли новые команды, сервисы и приложения и постепенно «душили» монолитную систему. Команды прогрессировали быстро — теперь они работали независимо друг от друга и состояли из специалистов во всех нужных областях. Мы свели к минимуму взаимодействие команд для выпуска продукта. Мы выделили несколько команд только для конфигурации балансировщика нагрузки.
Команды сами выбирали методы разработки, инструменты и языки. Мы ставили перед ними задачу, и они сами находили решение, ведь они лучше всех разбирались в вопросе. С AWS такие перемены стали проще.
Мы интуитивно следовали принципам программирования — слабо связанные друг с другом команды будут реже общаться, и нам не придется тратить драгоценные ресурсы на координацию их работы. Все это здорово описано в недавно вышедшей книге «Accelerate».
В итоге, как и описывал Майкл Найгард, у нас получилась система из множества слоев изменений — некоторые системы были автоматизированы c Puppet, некоторые с Terraform, где-то мы использовали ECS, где-то — EC2.
В 2012 году мы гордились своей архитектурой, которую можно было легко менять, чтобы экспериментировать, находить удачные решения и развивать их.
Но в 2017 году мы поняли, что многое изменилось.
Сейчас инфраструктура AWS гораздо сложнее, чем в 2010. Она предлагает массу вариантов и возможностей — но не без последствий. Сегодня любой команде, которая работает с EC2, приходится выбирать VPC, конфигурацию сети и еще много всего.
Мы испытали это на себе — команды стали жаловаться, что тратят все больше времени на обслуживание инфраструктуры, например обновление экземпляров в кластерах AWS ECS, EC2 машины, переход с балансировщиков ELB на ALB и т. д.
В середине 2017 года на корпоративном мероприятии я призвал всех стандартизировать работу, чтобы повысить общее качество систем. Я использовал избитую метафору про айсберг, чтобы показать, как мы создаем и обслуживаем ПО:

Я сказал, что большинство команд в нашей компании должно заниматься созданием сервисов или продуктов и сосредоточиться на решении задач, коде приложений, платформах и библиотеках и т. д. Именно в таком порядке. Под водой остается много работы — интеграция логов, повышение наблюдаемости, управление секретами и т. д.
В то время каждая команда разработчиков приложения занималась почти всем айсбергом и сама принимала все решения — выбирала язык, среду разработки, библиотеку и инструмент метрик, операционную систему, тип экземпляра, хранилище.
В основании пирамиды у нас была инфраструктура Amazon Web Services. Но не все сервисы AWS одинаковы. У них есть Backend-as-a-Service (BaaS), например для аутентификации и хранения данных. И есть другие, относительно низкоуровневые сервисы, например EC2. Я хотел изучить данные и понять, что у команд есть основания жаловаться и они действительно тратят больше времени на работу с низкоуровневыми сервисами и принимают множество не самых важных решений.
Я разделил сервисы на категории, с помощью CloudTrail собрал всю доступную статистику, а потом использовал BigQuery, Athena и ggplot2, чтобы увидеть, как изменилось положение дел для разработчиков за последнее время. Рост для таких сервисов, как RDS, Redshift и т. д. мы считаем желаемым (и ожидаемым), а рост для EC2, CloudFormation и т. д. — наоборот.

Каждая точка на диаграмме показывает 90-й (красный), 80-й (зеленый) и 50-й (синий) процентили для количества низкоуровневых сервисов, которые наши люди использовали каждую неделю в течение определенного периода. Я добавил сглаживающие линии, чтобы показать тренд.
И хотя мы стремились к высокоуровневым абстракциям при развертывании ПО, например, с помощью контейнеров и Amazon ECS, наши разработчики регулярно использовали все больше и больше служб AWS и недостаточно абстрагировались от сложностей управления системами. За два года число служб удвоилось для 50% сотрудников и почти утроилось для 20%.
Это ограничивало рост нашей компании. Команды стремились к автономности, но как при этом нанимать новых людей? Нам нужны были сильные разработчики приложений и продуктов и знания об усложняющейся системе AWS.
Мы хотели расширять команды и при этом сохранить принципы, с которыми добились успеха: автономность, минимальная координация и самообслуживаемая инфраструктура.
С Kubernetes мы достигли этой цели благодаря абстракциям с фокусом на приложения и возможности обслуживать и настраивать кластеры для минимальной координации команд.
Абстракции с фокусом на приложения
Концепции Kubernetes легко сопоставить с языком, который использует разработчик приложения. Допустим, вы управляете версиями приложений в виде развертывания. Вы можете запустить несколько реплик за сервисом и сопоставить их с HTTP через Ingress. А через пользовательские ресурсы можно расширять и специализировать этот язык в зависимости от того, что вам нужно.
С этими абстракциями команды работают продуктивнее. В принципе, в этом примере есть все необходимое для развертывания и запуска веб-приложения. Остальным занимается Kubernetes.
На картинке с айсбергом эти концепции находятся на уровне воды и соединяют задачи разработчика сверху с платформой внизу. Команда управления кластерами может принимать низкоуровневые и малозначимые решения (об управлении метриками, ведении логов и т. д.) и при этом говорить на одном языке с разработчиками над водой.
В 2010 году в uSwitch были традиционные команды для обслуживания монолитной системы, а совсем недавно у нас был ИТ-отдел, который частично управлял нашим аккаунтом AWS. Мне кажется, отсутствие общих концепций серьезно мешало работе этой команды.
Попробуйте сказать что-то полезное, если у вас в словарном запасе одни экземпляры EC2, балансировщики нагрузки и подсети. Описать суть приложения было сложно или даже невозможно. Это мог быть пакет Debian, развертывание через Capistrano и так далее. Мы не могли описать приложение на общем для всех языке.
В начале 2000-х я работал в лондонском ThoughtWorks. На собеседовании мне посоветовали прочитать «Проблемно-ориентированное проектирование» Эрика Эванса. Я купил книгу по пути домой и начал читать еще в поезде. С тех пор я вспоминаю о ней почти в каждом проекте и системе.
Одна из главных концепций книги — единый язык, на котором общаются разные команды. Kubernetes как раз обеспечивает такой единый язык для разработчиков и команд по обслуживанию инфраструктуры, и это одно из главных его преимуществ. Плюс его можно расширять и дополнять другими предметными областями и направлениями бизнеса.
На общем языке общение идет продуктивнее, но все же нам нужно максимально ограничить взаимодействие между командами.
Необходимый минимум взаимодействия
Авторы книги «Accelerate» выделяют характеристики слабосвязанной архитектуры, с которой ИТ-команды работают эффективнее:
В 2017 году успех непрерывной поставки зависел от того, может ли команда:
Серьезно менять структуру своей системы без разрешения руководства.
Серьезно менять структуру своей системы, не дожидаясь, пока другие команды изменят свои, и не создавая много лишней работы для других команд.
Выполнять свои задачи, не общаясь и не координируя свою работу с другими командами.
Развертывать и выпускать продукт или сервис по требованию, независимо от других сервисов, связанных с ним.
Делать большую часть тестов по запросу, без интегрированной тестовой среды.
Нам нужны были централизованные программные мультитенантные кластеры для всех команд, но при этом мы хотели сохранить эти характеристики. Идеала мы пока не достигли, но стараемся как можем:
- У нас есть несколько рабочих кластеров, и команды сами выбирают, где запускать приложение. Мы пока не используем федерацию (ждем поддержки AWS), зато у нас есть Envoy для балансировки нагрузки на балансировщиках Ingress в разных кластерах. Большую часть этих задач мы автоматизируем с помощью конвейера непрерывной поставки (у нас это Drone) и других сервисов AWS.
- У всех кластеров одинаковые пространства имен. Примерно по одному на каждую команду.
- Доступ к пространствам имен мы контролируем через RBAC (управление доступом на основе ролей). Для аутентификации и авторизации мы используем корпоративное удостоверение в Active Directory.
- Кластеры масштабируются автоматически, и мы делаем все возможное, чтобы оптимизировать время запуска узла. На это все равно уходит пара минут, но, в целом, даже при больших рабочих нагрузках мы обходимся без координации.
- Приложения масштабируются автоматически на базе метрик на уровне приложения из Prometheus. Команды разработчиков управляют автоматическим масштабированием своего приложения по метрикам запросов в секунду, операций в секунду и т. д. Благодаря автомасштабированию кластера система подготавливает узлы, когда спрос превышает возможности текущего кластера.
- Мы написали в Go инструмент командной строки под названием u, который стандартизирует аутентификацию команд в Kubernetes, использование Vault, запросы временных учетных данных AWS и так далее.
Не уверен, что с Kubernetes автономности у нас стало больше, но она определенно осталась на высоком уровне, и при этом мы избавились от некоторых проблем.
Переход на Kubernetes был быстрым. На диаграмме показано общее количество пространств имен (примерно равное количеству команд) в наших рабочих кластерах. Первый появился в феврале 2017 года.
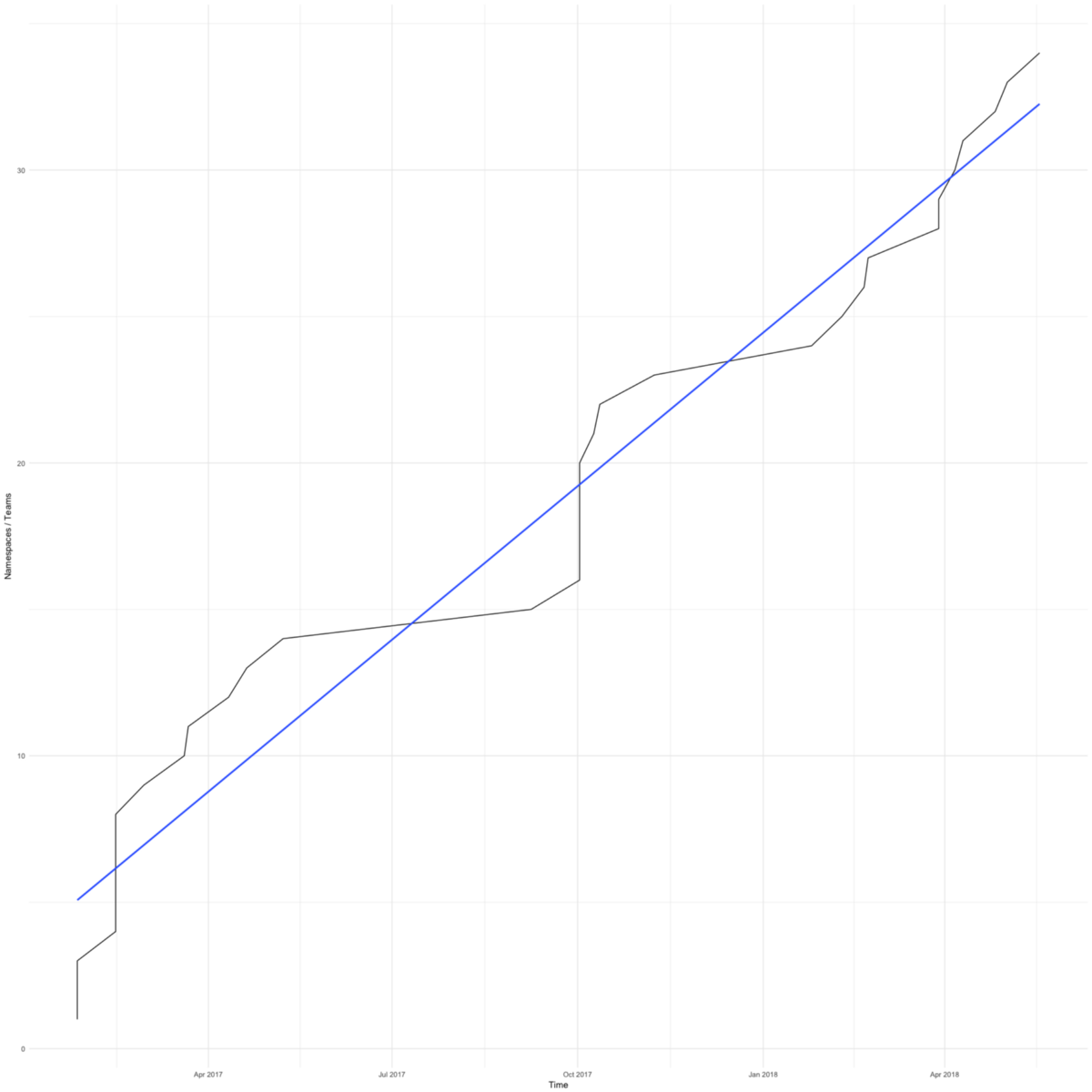
У нас были причины торопиться — мы хотели избавить небольшие команды, сосредоточенные на своем продукте, от забот об инфраструктуре.
Первая команда согласилась перейти на Kubernetes, когда на их сервере приложений закончилось место из-за неправильной настройки logrotate. Переход занял всего несколько дней, и они снова занялись делом.
В последнее время команды переходят на Kubetnetes ради улучшенных инструментов. Кластеры Kubernetes упрощают интеграцию с нашей системой управления секретами (Hashicorp Vault), распределенной трассировкой (Google Cloud Trace) и подобными инструментами. Все наши команды получают еще больше эффективных функций.
Я уже показывал диаграмму с процентилями количества служб, которые наши сотрудники использовали каждую неделю с конца 2014 по 2017 годы. А вот продолжение этой диаграммы по сегодняшний день.
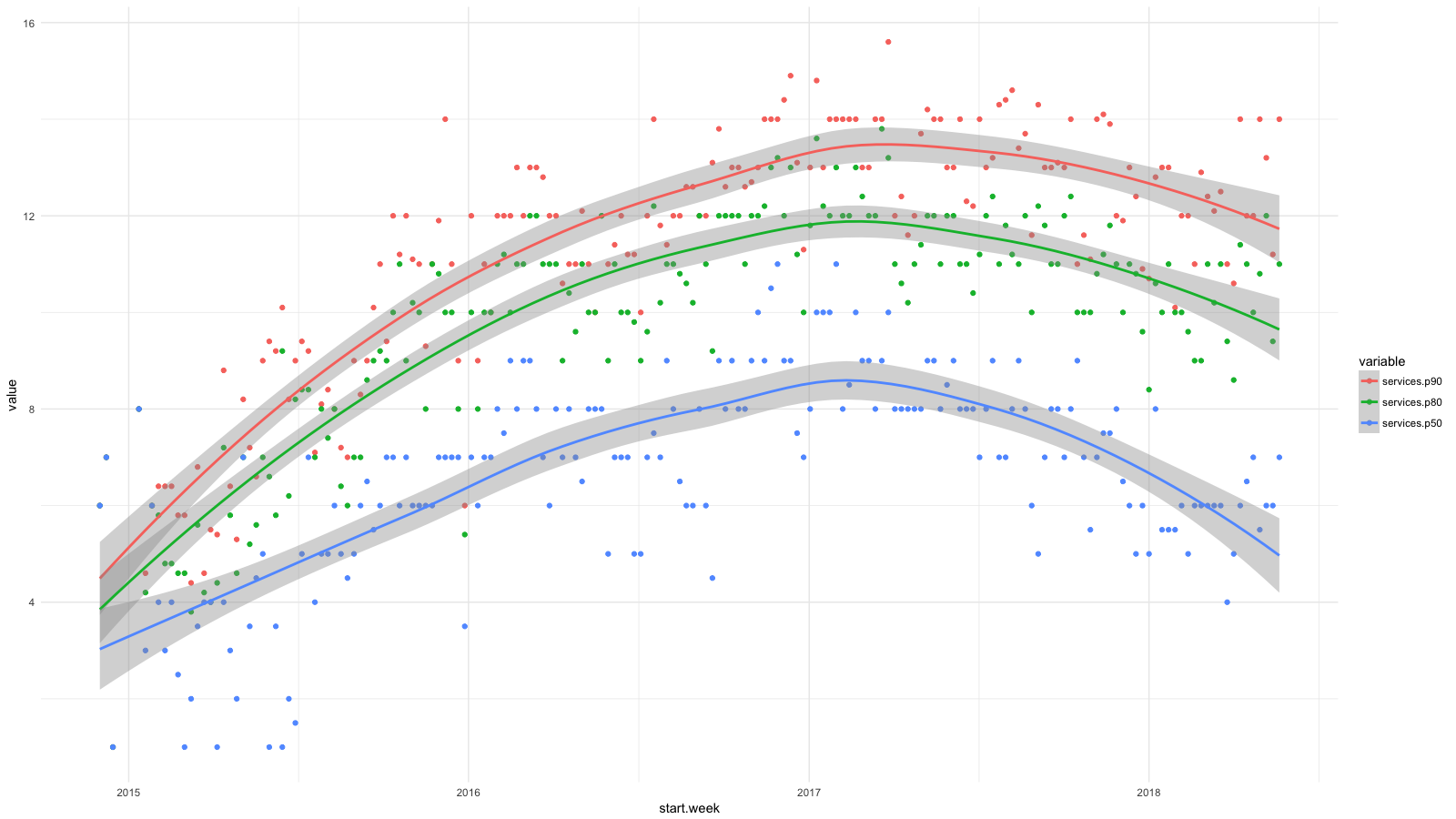
Мы достигли прогресса в управлении сложной структурой AWS. Радует, что теперь у половины сотрудников дела идут так же, как в начале 2015 года. В команде облачных вычислений у нас 4–6 сотрудников, где-то 10% от общего числа — неудивительно, что 90-й процентиль почти не сдвинулся с места. Но я надеюсь на подвижки и здесь.
Наконец я расскажу о том, как изменился наш цикл разработки, и снова вспомню недавно прочитанную книгу Accelerate.
В книге упоминается два показателя бережливой разработки: время выполнения и размер пакета. Время выполнения считается от запроса до доставки готового решения. Размер пакета — это объем работы. Чем меньше размер пакета, тем эффективнее работа:
Чем меньше пакет, тем короче цикл производства, меньше вариативность процессов, меньше рисков, расходов и издержек, мы быстрее получаем обратную связь, работаем эффективнее, у нас больше мотивации, мы стараемся быстрее закончить и реже откладываем сдачу.
В книге предлагается измерять размер пакетов частотой развертывания — чем чаще развертывание, тем меньше пакеты.
У нас есть данные для некоторых развертываний. Данные не совсем точные — некоторые команды отправляют выпуски прямо в главную ветвь репозитория, некоторые используют другие механизмы. Сюда входят не все приложения, но данные за 12 месяцев можно считать показательными.
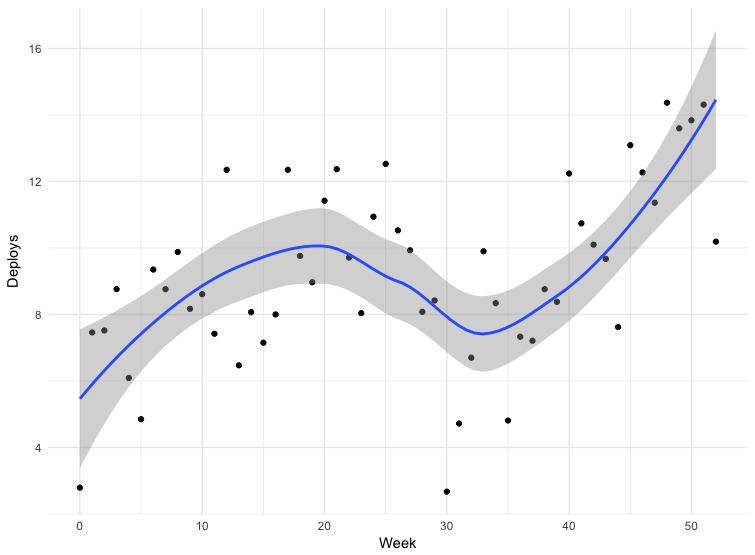
Провал на тридцатой неделе — это Рождество. В остальном мы видим, что частота развертывания возрастает, а значит размер пакета уменьшается. С марта по май 2018 частота выпусков почти удвоилась, а в последнее время мы иногда делаем больше ста выпусков в день.
Переход на Kubernetes — это только часть нашей стратегии стандартизации, автоматизации и усовершенствования инструментов. Скорее всего, на частоту выпусков повлияли все эти факторы.
Еще в Accelerate говорится о связи между частотой развертываний и количеством сотрудников и о том, как быстро компания может работать, если штат увеличить. Авторы подчеркивают ограниченность связанной архитектуры и команд:
Традиционно считается, что при расширении команды повышается общая производительность, но падает индивидуальная производительность разработчика.
Если взять те же данные о частоте развертываний и составить диаграмму зависимости от количества пользователей, видно, что мы можем увеличивать частоту выпусков, даже если у нас будет больше людей.

В начале статьи я упомянул книгу «Factfulness» (которая вдохновила нашего технического директора). Переход на Kubernetes стал для наших разработчиков самой значимой и быстрой конвергенцией технологий. Мы двигаемся маленькими шажками, и легко не заметить, насколько все изменилось к лучшему. Хорошо, что у нас есть данные, и они показывают, что мы добились желаемого, — наши люди занимаются своим продуктом и принимают важные решения в своей сфере.
Раньше нам и так было неплохо. У нас были микросервисы, AWS, устоявшиеся команды под продукты, разработчики, отвечающие за свои сервисы в продакшене, слабосвязанные команды и архитектура. Я говорил об этом в докладе «Our Age of Enlightenment» («Наш эпоха просвещения») на конференции в 2012 году. Но нет предела совершенству.
В конце я хочу процитировать еще одну книгу — Scale. Я начал ее недавно, и там есть интересный фрагмент о потреблении энергии в сложных системах:
Чтобы поддерживать порядок и структуру в развивающейся системе, нужен постоянный приток энергии, а она порождает беспорядок. Поэтому для поддержания жизни мы должны все время есть, чтобы победить неизбежную энтропию.
Мы боремся с энтропией, поставляя больше энергии для роста, инноваций, обслуживания и ремонта, который становится все сложнее по мере старения системы, и эта битва лежит в основе любых серьезных дискуссий о старении, смертности, устойчивости и самодостаточности любых систем, будь то живой организм, компания или общество.
Думаю, сюда же можно добавить ИТ-системы. Надеюсь, наши последние усилия еще хоть ненадолго сдержат энтропию.