

Ликбез о регуляторах и их требованиях
Чтобы выпускать электронные деньги, нужно получить лицензию регулятора. Если вы открываете платёжную систему, например, в России, вашим регулятором станет Центробанк РФ. ePayments — английская платёжная система, наш регулятор — Financial Conduct Authority (FCA), орган, подотчётный Минфину Великобритании. FCA следит, чтобы мы соблюдали политику Anti-money laundering (борьба с отмыванием денежных средств, AML), частью которой является набор процедур Know Your Customer («Знай своего клиента», KYC).
Согласно KYC, мы обязуемся проверять, кто наш клиент и не связан ли он с общественно опасными группами. Поэтому у нас два обязательства:
- Определение и подтверждение личности клиента.
- Сверка его данных с различными списками: террористов, лиц под санкциями, членов правительства и многими другими.
С каждым годом требования по KYC становятся строже и подробнее. В начале 2017 года клиенты ePayments без верификации ещё могли получать оплату или совершать переводы. Теперь это невозможно, пока они не подтвердят личность.
Ручная верификация
Несколько лет назад мы справлялись своими силами. Россияне для подтверждения личности присылали скан определённых страниц паспорта, для подтверждения адреса – скан договора аренды, квитанции об оплате услуг ЖКХ. Помните игру Papers, please? В ней вы, играя за таможенника, проверяете документы по всё более усложняющимся требованиям правительства. Наш клиентский отдел играл в неё на работе каждый день.

Клиенты верифицируются удалённо, без визита в офис. Чтобы процедура проходила быстрее, мы нанимали новых сотрудников, но это тупиковый путь. Тогда и появилась мысль поручить часть работы нейронной сети. Если она хорошо справляется с распознаванием лиц, значит, совладает и с нашими задачами. С точки зрения бизнеса, система быстрой верификации должна уметь следующее:
- Классифицировать документ. Нам присылают удостоверение личности и подтверждение адреса проживания. Система должна ответить, что она получила на вход: паспорт гражданина РФ, договор аренды или что-то другое.
- Сравнить лицо на фотографии и документе. Мы просим клиентов прислать селфи с удостоверением личности, чтобы убедиться, что они сами регистрируются в платёжной системе.
- Извлечь текст. Заполнять десятки полей со смартфона не очень удобно. Гораздо проще, если приложение всё само сделало за тебя.
- Проверить файлы изображений на фотомонтаж. Нельзя забывать о мошенниках, которые хотят попасть в систему обманным путём.
На выходе система должна указывать определённый уровень доверия к клиенту: высокий, средний или низкий. Ориентируясь на такую градацию, мы будем быстрее верифицировать и не злить клиентов затянутыми сроками.
Классификатор документов
Задача этого модуля — удостовериться, что пользователь отправляет валидный документ и дать ответ, что конкретно он загрузил: паспорт гражданина Казахстана, договор аренды или квитанцию для оплаты ЖКХ.
Классификатор получает входные данные:
- Фотографию или скан документа
- Страну проживания
- Тип документа, указанный клиентом (удостоверение личности или подтверждение адреса проживания)
- Извлеченный текст (об этом чуть ниже)
На выходе классификатор сообщает, что он получил (паспорт, водительское удостоверение и так далее) и насколько он уверен в правильности ответа.

Сейчас решение работает на архитектуре Wide Residual Network. Мы пришли к ней не сразу. Первая версия системы быстрой верификации работала на базе архитектуры, на которую нас вдохновила VGG. У неё было 2 очевидные проблемы: большое количество параметров (около 130 миллионов) и неустойчивость к положению документа. Чем больше параметров, тем труднее обучить такую нейронную сеть — она плохо обобщает знания. Документ на фотографии должен быть расположен по центру, иначе классификатор пришлось бы обучать на выборках, в которых он находится в разных частях фотографии. В итоге мы отказались от VGG и решили перейти на другую архитектуру.
Residual Network (ResNet) была круче, чем VGG. Благодаря skip connections можно создать большое количество слоёв и добиться высокой точности работы. У ResNet всего около 1 млн параметров и ей было безразлично положение документа. Неважно, где он находится на изображении, решение на этой архитектуре справлялось с классификацией.
Пока мы дорабатывали решение напильником, вышла новая модификация архитектуры, Wide Residual Network (WRN). Главное отличие от ResNet — шаг назад в плане глубины. У WRN меньше слоёв, но больше сверточных фильтров. Сейчас это лучшая архитектура нейронной сети для большинства задач и наше решение работает на ней.
Несколько полезных решений
Проблема № 1. Классификатор нужно было обучить. Мы должны были загрузить много русских, казахстанских и белорусских паспортов и водительских удостоверений. Но брать документы клиентов, разумеется, нельзя. В сети лежат образцы, но их слишком мало для успешного обучения нейросети.
Решение. Наш технический отдел сгенерировал выборку из 8000+ образцов каждого вида. Мы создаём шаблон документа и размножаем на много рандомных образцов. Затем генерируем случайное положение документа в пространстве относительно камеры, учитывая её математическую модель и характеристики: фокусное расстояние, разрешение матрицы и так далее. При генерации искусственнои? фотографии в качестве фона выбирается случаи?ное изображение из готового набора данных. После этого документ с перспективными искажениями размещается на изображении случаи?ным образом. На такой выборке наша нейросеть хорошо обучилась и прекрасно определяла документ «на бою». Результаты — в конце статьи.
Проблема № 2. Банальное ограничение на вычислительные ресурсы и память. Нет смысла подавать глубокой нейронной сети на вход изображения больших размеров. А фотографии с современных смартфонов именно такие.
Решение. Перед подачей на вход фотография сжимается до размера примерно 300х300 пикселей. По изображению такого разрешения можно легко отличить один документ, удостоверяющий личность, от другого. Для решения этой задачи мы можем использовать стандартную архитектуру Wide ResNet.
Проблема № 3. С документами, подтверждающими адрес проживания, всё сложнее. Договор аренды или банковскую выписку можно отличить только по тексту на листе. После уменьшения размера изображения до тех самых 300х300 пикселей любой из этих документов выглядит одинаково – как лист формата А4 с неразборчивым текстом.
Решение. Для классификации произвольных документов мы внесли изменения в саму архитектуру нейронной сети. В ней появился дополнительный входной слой нейронов, который связан с выходным слоем. Нейроны этого входного слоя получают на вход вектор, описывающий предварительно распознанный текст с помощью модели Bag-of-Words.
Сначала мы обучали нейронную сеть для классификации документов, удостоверяющих личность. Веса обученной сети мы использовали при инициализации другой сети с дополнительным слоем для классификации произвольных документов. У этого решения была высокая точность, но распознавание текста требовало определённое время. Разницу в скорости обработки разными модулями и точность классификации можно посмотреть в таблице №2.
Распознавание лиц
Как обмануть платёжную систему, которая проверяет документы? Можно позаимствовать чужой паспорт и зарегистрироваться с помощью него. Чтобы убедиться, что клиент регистрируется сам, мы просим сделать селфи с удостоверением личности. И модуль распознавания должен сличить лицо на документе и лицо на селфи и ответить, это один человек или два разных.
Как сравнить 2 лица, если ты машина и мыслишь как машина? Превратить фотографию в набор параметров и сравнить между собой их значения. Так работают нейросети, распознающие лица. Они принимают изображение и превращают его в 128-мерный (например) вектор. Когда вы подаёте на вход другое изображение лица и просите их сравнить, нейросеть превратит второе лицо в вектор и вычислит расстояние между ними.
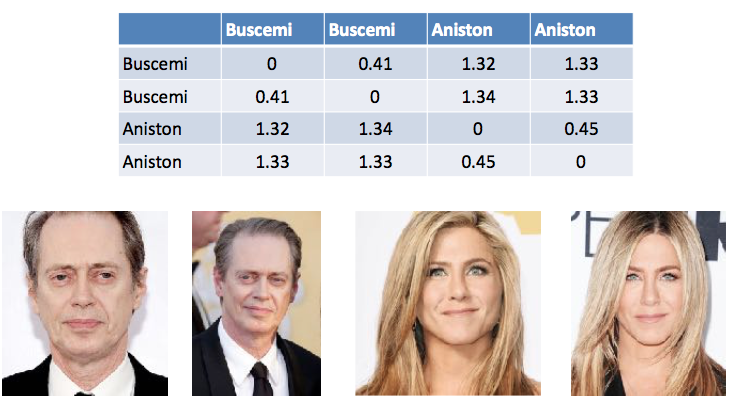
Таблица 1. Пример вычисления разницы между векторами при распознавании лиц. Стив Бушеми отличается от себя на разных фотографиях на 0.44. А от Дженнифер Энистон – в среднем на 1.33.
Разумеется, есть отличия между тем как человек выглядит в жизни и на паспорте. Мы также подбирали значение расстояния между векторами и тестировали на реальных людях, чтобы добиться результата. В любом случае сейчас окончательное решение будет принимать человек, а замечание от системы будет только рекомендацией.
Распознавание текста
На документах есть текстовые поля, которые помогают классификатору понять, что перед ним находится. Пользователю будет удобно, если текст с того же паспорта будет перенесён автоматически и не придётся набирать вручную, кем и когда он выдан. Для этого мы сделали следующий модуль — распознавание и извлечение текста.
На некоторых документах, например, новых паспортах РФ есть Machine-readable zone (MRZ). С её помощью легко снимать информацию — это легко читаемый чёрный текст на белом фоне, который просто распознать. К тому же MRZ имеет известный формат, благодаря которому проще получить необходимые данные.

Если в задаче есть документы с MRZ, то нам становится проще. Весь процесс лежит в области компьютерного зрения. Если этой зоны нет, то после распознавания текста нужно решить одну интересную задачу — понять, а какую информацию мы распознали? Например, «15.05.1999» — это дата рождения или дата выдачи? На этом этапе тоже можно совершить ошибку. MRZ хорош тем, что декодируется однозначным образом. Мы всегда знаем, какую информацию и в какой части MRZ искать. Это очень удобно для нас. Но MRZ не было на самом популярном документе, с которым будет работать сеть — паспорте РФ.
Для распознавания текста нам нужно было очень эффективное решение. Текст придётся снимать с изображения, сделанного камерой телефона и не самыми профессиональными фотографами. Мы протестировали Google Tesseract и несколько платных решений. Не подошло ничего — или плохо работало, или стоило неоправданно дорого. В итоге мы стали разрабатывать собственное решение. Сейчас мы заканчиваем его тестирование. Решение показывает приличные результаты — о них можно прочитать ниже. О модуле проверки на фотомонтаж мы расскажем чуть позже, когда будут точные результаты исследований на тестовых выборках и на «бою».
Результат
Система на данный момент тестируется на сегменте заявок на верификацию из России. Сегмент определяется случайной выборкой, результаты сохраняются и сверяются с решениями оператора клиентского отдела по конкретному клиенту.
| Страна | Тип классификатора | Точность | Время работы, с |
| Россия | Удостоверение личности | 99,96% | 0,41 |
| Россия | Произвольный документ | 98,62% | 6,89 |
| Казахстан | Удостоверение личности | 99,51% | 0,47 |
| Казахстан | Произвольный документ | 97,25% | 7,66 |
| Белоруссия | Удостоверение личности | 98,63% | 0,46 |
| Белоруссия | Произвольный документ | 98,63% | 9,66 |
Таблица 2. Точность классификатора документов (корректная классификация документа по сравнению с оценкой оператора).
Один из огромных плюсов машинного обучения заключается в том, что нейросеть действительно учится и делает всё меньше ошибок. Вскоре мы закончим тестирование на сегменте и запустим систему верификации в «боевом» режиме. 30% заявок на верификацию приходят в ePayments из России, Казахстана и Беларуси. По нашим прикидкам, запуск поможет снизить нагрузку на клиентский отдел на 20–25%. В дальнейшем, решение можно масштабировать на страны Европы.
Ищете работу?
Мы ищем сотрудников для работы в офисе в Санкт-Петербурге. Если вам интересен международный проект с большим пулом амбициозных задач, мы ждём вас. Нам не хватает людей, которые не боятся их реализовывать. Ниже вы найдёте ссылки на вакансии на hh.ru.
Комментарии (13)

molec
25.10.2018 14:07А что понимаете под точностью? Обычно еще в таких чувствительных областях разделяют ложнопозитивные и ложнонегативные ошибки. Лучше лишних несколько процентов прогнать через ручную верификацию, чем пропустить лишнего мошенника.
Можете объяснить, почему не могли использовать свою базу фото документов для обучения сети? У вас же есть разрешение на обработку этих данных. Мне кажется, генерированные семплы из нескольких реальных фото документов, сделанных небольшим числом камер — не лучший материал для обучения.m_ePayments Автор
25.10.2018 17:31В нашем случае, точность — отношение правильно распознанных классификатором документов ко всему массиву документов в тестовой выборке, предварительно размеченной человеком. Показатель точности снижали неправильные ответы или ответы «я не знаю». Статистика по ложнопозитивным и ложнонегативным ответам есть, но статья больше ликбез, пока не стал прикреплять. В следующей статье обнародуем.
По поводу использования базы: пока не могу сказать точную причину. Мы обратились к юристам, которые не разрешили использовать базу. Могу уточнить в ближайшее время.
Семплы на практике показали себя хорошо, классификатор проверяли на тестовой выборке из реальных документов. Я точно знаю, что мы не первые, кто обучает решение на такой генерированной выборке, и у них также есть хорошие результаты.molec
25.10.2018 17:43Спасибо за подробный ответ.
Правда хотелось бы узнать причину отказа от реальных данных. Может перестраховались.
Т.е. вся работа классификатора — это 1)паспорт РФ, 2) паспорт РБ, 3) права и т.д.?
Почему задал вопрос про семплы. По идее, большая часть работы НС — это и есть разнообразные повороты, работа со светом и цветом, нарезка исходного изображения. Т.о. труд по набивке базы повернутыми изображениями должен приносить мало пользы. А вот с фоном идея должна была сработать хорошо.
mpa4b
25.10.2018 16:06> для подтверждения адреса – скан договора аренды, квитанции об оплате услуг ЖКХ.
А что делать, если оплачивать в интернет-банке, где даже и квитанции нормальной (pdf) не выдают (вместо этого предлагают распечатать страничку из браузера)?m_ePayments Автор
25.10.2018 17:33У нас есть и другие варианты: help.epayments.com/hc/ru/articles/360008855654-Документы-для-верификации-аккаунта. Выбираете любой и прикрепляете к заявке на верификацию.
Sabubu
25.10.2018 17:32Не понимаю, зачем нужна прописка. Что, KYC требует проверять прописку? Сомневаюсь.
А фотографироваться с паспортом вообще неправильно. Это отношение к людям как к каким-то порноактерам.
Скорее бы распространились криптовалюты, без этого маразма.

botka4aet
25.10.2018 17:35Как обмануть платёжную систему, которая проверяет документы? Можно позаимствовать чужой паспорт и зарегистрироваться с помощью него. Чтобы убедиться, что клиент регистрируется сам, мы просим сделать селфи с удостоверением личности. И модуль распознавания должен сличить лицо на документе и лицо на селфи и ответить, это один человек или два разных.
Сейчас же научили нейросеть заменять лица в видеороликах.
Что злоумышленникам помешает проделать тоже самое с селфи?
m_ePayments Автор
25.10.2018 17:38Ничего не помешает, способов фрода с каждым днем все больше. Но есть способы проверить даже такие подделки изображений. Мы сейчас работаем над этим, решение пока тестируется и я пока не могу раскрыть все карты.
chouck
25.10.2018 18:49+1Созрело несколько оффтоп коллективных вопросов к ePayments:
1) когда наконец восстановят приём USD из банков частных лиц и компаний, кроме внутри-европейских SEPA?
2) когда можно будет наконец заказать EUR карточку?
3) почему ePayments (в противоречие официально заявленным правилам в соглашении где это не запрещено) не разрешает принимать в систему платежи от покупателей за товары?m_ePayments Автор
26.10.2018 11:59Сходил с вашими вопросами в клиентский отдел, вот, что они ответили:
1. Пока точно сказать не можем. Дело в том, что во внутренней политике нашего партнера произошли значительные изменения, которые затронули исполнение банковских переводов в валюте USD, и мы были вынуждены приостановить прием таких платежей. Сейчас мы работаем над вопросом, однако назвать точные сроки возобновления сервиса возможности пока нет.
2. Тоже самое по выпуску карт. Мы ориентируемся на сроки mastercard®, и пока не можем точно назвать день, когда завершится процесс пересмотра условий нашей карточной программы.
Мы со своей стороны делаем все возможное, чтобы и USD, и карты вернулись как можно скорее. Как только у нас появится какая-либо информация, мы оповестим всех наших клиентов.
3. Мы были вынуждены прекратить прием средств за онлайн торговлю по решению Департамента по управлению рисками (пункт 2.4 (b), www.epayments.com/documents/Epayments_Systems_Limited_Terms_and_Conditions.pdf). Такие операции сопровождаются высокими рисками и для нас, и для банков, которые их обрабатывают.
DimonSmart
26.10.2018 12:31Приложу ссылку на выступление на DevDay с довольно близкой темой: "Когда учиться хочется но не на чем"
stepuncius
Очень высокая точность, обычно люди — операторы, тоже допускают ошибки.
У Вас один оператор, с которым сверяется ИИ или их много?
(Во втором случае — поздравляю, в первом — есть риск заточки ИИ под одного оператора)
m_ePayments Автор
Операторов много, в клиентском отделе есть подразделение, которое занимается онбордингом. Они отсматривают документы, их результаты сверяются с результатами нейросети. Результаты сверки получает отдел разработки, который вносит коррективы. Сама сеть не получает эти данные на обучение, она отталкивается только от своих параметров.