

Предпосылки
Рынок труда постоянно находится в динамике, возникают новые профессии, другие исчезают, и хочется иметь актуальную категоризацию резюме. На hh.ru каталог профобластей и специализаций давно устарел: на нем многое завязано, поэтому изменения не вносили уже давно. Было бы полезно научиться безболезненно редактировать эти категории. Я же предпринимаю попытку автоматического выявления этих категорий. Надеюсь, что в дальнейшем это поможет решению проблемы.
Про выбранный подход и о кластеризации
Под кластеризацией я буду понимать объединение объектов с максимально похожими признаками в одну группу. В моем случае под объектом рассматривается резюме, а под признаками объекта — данные резюме: например, частота слова «менеджер» в резюме или размер зарплаты. Похожесть объектов определяется заранее выбранной метрикой. Пока можно думать о ней как о черном ящике, которому на вход подается два объекта, а на выходе получается число, отражающее, например, расстояние между объектами в векторном пространстве: чем меньше расстояние, тем более похожи объекты.
Подход, который я использовал, можно назвать восходящей агломеративной иерархической кластеризацией. Результатом кластеризации является бинарное дерево, где в листьях находятся отдельно взятые элементы, а корень дерева — это совокупность всех элементов. Восходящей она называется потому, что кластеризация начинается с самого нижнего уровня дерева, с листьев, где каждый отдельно взятый элемент рассматривается как кластер.

Затем надо найти два ближайших кластера и объединить их в новый кластер. Эту процедуру надо повторять до тех пор, пока не останется один кластер со всеми объектами внутри. При объединении кластеров записывается расстояние между ними. В будущем эти расстояния можно использовать, чтобы определить место, где эти расстояния достаточно велики, чтобы считать выбранные кластеры отдельными.
Большинство методов кластеризации предполагают, что число кластеров заранее известно, или пытаются выделить кластеры самостоятельно в зависимости от алгоритма и параметров этого алгоритма. Преимущество иерархической кластеризации в том, что можно попытаться определить нужное количество кластеров, исследуя свойства получившегося дерева, например, выделять в разные группы те поддеревья, расстояния между которыми достаточно велики. С получившейся структурой удобно работать для поиска в ней кластеров. Удобно то, что такая структура строится один раз и не нуждается в перестроении при поиске нужного количества кластеров.
Из недостатков я бы упомянул, что алгоритм достаточно требователен к потребляемой памяти. А ещё вместо присвоения конкретного класса хотелось бы иметь вероятность принадлежности резюме к классу, чтобы смотреть не на одну ближайшую специальность, а на совокупность.
Сбор и подготовка данных
Самая важная часть в работе с данными — это их подготовка, выбор и извлечение признаков. Именно исходя от того, какие признаки получатся в итоге, будет зависеть, найдутся ли в них закономерности, будут ли эти закономерности соответствовать ожидаемому результату и возможен ли этот «ожидаемый результат» вообще. Перед скармливанием данных какому-нибудь алгоритму машинного обучения нужно иметь представление о каждом признаке, есть ли пропуски, к какому типу относится признак, какими свойствами обладает такой тип признака и что из себя представляет распределение значений в этом признаке. Также очень важно правильно выбрать алгоритм, с помощью которого будут обработаны имеющиеся данные.
Я взял резюме, которые обновлялись в течение последнего полугода. Получилось 2.7 млн. Из данных о резюме выбрал самые простые признаки, от которых, как мне показалось, должна зависеть принадлежность резюме к той или иной группе. Забегая вперед, скажу, что результат кластеризации сразу всех резюме меня не удовлетворил. Поэтому пришлось сначала разделить резюме по уже существующим 28 профобластям.
По каждому признаку я строил график распределения, чтобы иметь представление о том, как выглядят данные. Возможно, их стоит как-то преобразовать или вообще отказаться от использования.
Регион. Чтобы значения этого признака можно было сравнивать между собой, каждому региону я присвоил общее число резюме, входящих в этот регион, и взял от этого числа логарифм, чтобы сгладить разницу между очень крупными и мелкими городами.
Пол. Преобразовал в бинарный признак.
Дата рождения. Пересчитал в количество месяцев. День рождения указан не у всех. Пропуски я заполнял средними значениями возраста из специализации, к которой это резюме принадлежит.
Уровень образования. Это категориальный признак. Я его закодировал LabelBinarizer-ом.
Название позиции. Прогнал через TfidfVectorizer с ngram_range=(1,2), использовал стеммер.
Зарплата. Перевел все значения в рубли. Пропуски заполнил тем же способом, что и в возрасте. Взял от значения логарифм.
График работы. Закодировал LabelBinarizer-ом.
Уровень занятости. Сделал бинарным, разделив на две части: полный рабочий день и все остальные.
Уровень владения языком. Выбрал топ самых используемых. Каждый язык выставил в качестве отдельного признака. Уровням владения сопоставил числа от 0 до 5.
Ключевые навыки. Прогнал через TfidfVectorizer. В качестве стоп-слов собрал небольшой словарь общих навыков и слов, которые, как мне показалось, не влияют на специальность. Все слова пропустил через стеммер. Каждый ключевой навык может состоять не только из одного слова, но и из нескольких. В случае нескольких слов в ключевом навыке я сортировал слова, а также каждое слово дополнительно использовал как отдельный признак. Данный признак хорошо зашел только в профобласти “Информационные технологии, интернет, телеком”, т. к. люди часто указывают релевантные своей специальности навыки. В остальных профобластях я его не использовал из-за обилия в навыках общих слов.
Специализации. Каждую из поставленных пользователем специализаций я выставил в качестве бинарного признака.
Опыт работы. Взял логарифм от количества месяцев + 1, т. к. есть люди без опыта работы.
Стандартизация
В итоге каждое резюме стало представлять из себя вектор чисел-признаков. Выбранный алгоритм кластеризации основан на подсчете расстояния между объектами. Как определить, какой вклад в это расстояние должен делать каждый признак? Например, есть бинарный признак — 0 и 1, а другой признак может принимать очень много значений от 0 до 1000.
На помощь приходит стандартизация. Я использовал StandardScaler. Он преобразует каждый признак таким образом, что его среднее значение равно нулю и стандартное отклонение от среднего — единице. Таким образом мы пытаемся привести все данные к одному и тому же распределению — стандартному нормальному. Конечно, далеко не факт, что сами данные имеют природу нормального распределения. Как раз это одна из причин, чтобы построить графики распределения своих параметров и порадоваться, что они похожи на гауссиану.
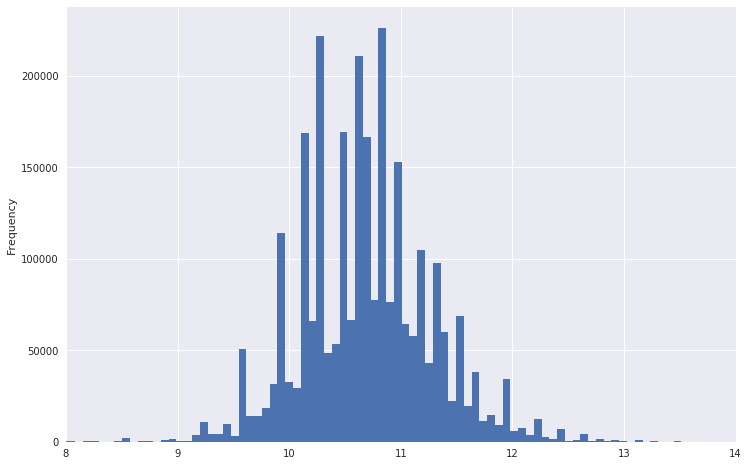
Так, например, выглядел график распределения зарплат.

Видно, что у него очень тяжелый хвост. Чтобы распределение было больше похоже на нормальное, можно взять от этих данных логарифм. Заодно выбросы станут не такими сильными.
Понижение размерности
Теперь имеет смысл перевести данные в пространство меньшей размерности, чтобы в дальнейшем алгоритм кластеризации смог их переварить за приемлемые время и память. Я использовал TruncatedSVD, т. к. он умеет работать с разреженными матрицами и на выходе дает обычную dense-матрицу, которая нам понадобится для дальнейшей работы. Кстати, в TruncatedSVD тоже нужно подавать стандартизованные данные.
На этом же этапе стоит попробовать визуализировать получившийся датасет, переведя его в двумерное пространство, используя t-SNE. Это очень важный шаг. Если на вид в получившемся изображении не просматривается никакой структуры или, наоборот, эта структура выглядит очень странной, то либо в ваших данных нет нужной закономерности, либо где-то допущена ошибка.
Я получал много очень подозрительных изображений, прежде чем всё стало хорошо. Например, один раз было вот такое красивое изображение:

Причиной получившихся червяков стало попадание в датасет идентификаторов резюме. А вот так выглядит что-то более похожее на правду:

Кластеризация
Если кажется, что с данными всё в порядке, то можно приступать к кластеризации. Я использовал пакет Hierarchical clustering из SciPy. Он позволяет выполнить кластеризацию при помощи метода linkage. Я попробовал все метрики расстояния между кластерами, предложенные в алгоритме. Наилучший результат дал метод Ward-а.
Главная проблема, с которой я столкнулся, — алгоритм кластеризации считает матрицу расстояний между всеми элементами, а это значит — квадратичная зависимость по памяти от количества элементов. Для 2.7 млн резюме у меня это сделать не получилось, т.к. объем необходимой памяти составляет терабайты. Все вычисления проводились на обычном компьютере. У меня нет столько оперативки. Поэтому мне показалось разумным, что можно сначала объединить резюме, находящиеся рядом, взять центры получившихся групп и уже их кластеризовать нужным алгоритмом. Я взял MiniBatchKMeans, сформировал с его помощью 30 000 кластеров и уже их отправил на иерархическую кластеризацию. Это сработало, но результат получился так себе. Выделилось множество самых ярких групп резюме, но детализации недостаточно, чтобы на хорошем уровне находить специализации.
Чтобы повысить качество получаемых специализаций, я разбил данные на профобласти. Получились датасеты от 400 000 резюме и меньше. В этот момент мне пришло в голову, что кластеризовать сэмпл данных лучше, чем использовать подряд два алгоритма. Поэтому я отказался от MiniBatchKMeans и взял до 100 000 резюме для каждой специализации, чтобы метод linkage смог их переварить. 32 Gb оперативной памяти не хватило, поэтому я выделил под своп дополнительные 100 Gb. В результате linkage дает матрицу с расстояниями между кластерами, объединенными на каждом шаге и количеством элементов в получившемся кластере.
В качестве метрики проверки качества для сравнения разных вариантов датасетов и разных методов подсчета расстояния между кластерами в алгоритме использовался cophenetic correlation coefficient, получаемый из cophenet. Этот коэффициент показывает, насколько хорошо получившаяся дендрограмма отражает непохожесть объектов друг на друга. Чем ближе значение к единице, тем лучше.
Визуализация
Лучше всего валидировать качество работы кластеризации мне помогала визуализация. Метод dendrogram рисует получившиеся дендрограммы, на которых можно выделить кластеры по расстоянию или по уровню в дереве:

На следующем графике показана зависимость расстояния между кластерами от номера шага итерации, на котором два ближайших кластера объединяются в новый. Зеленая линия показывает, как меняется ускорение — быстрота изменения расстояния между объединяемыми кластерами.
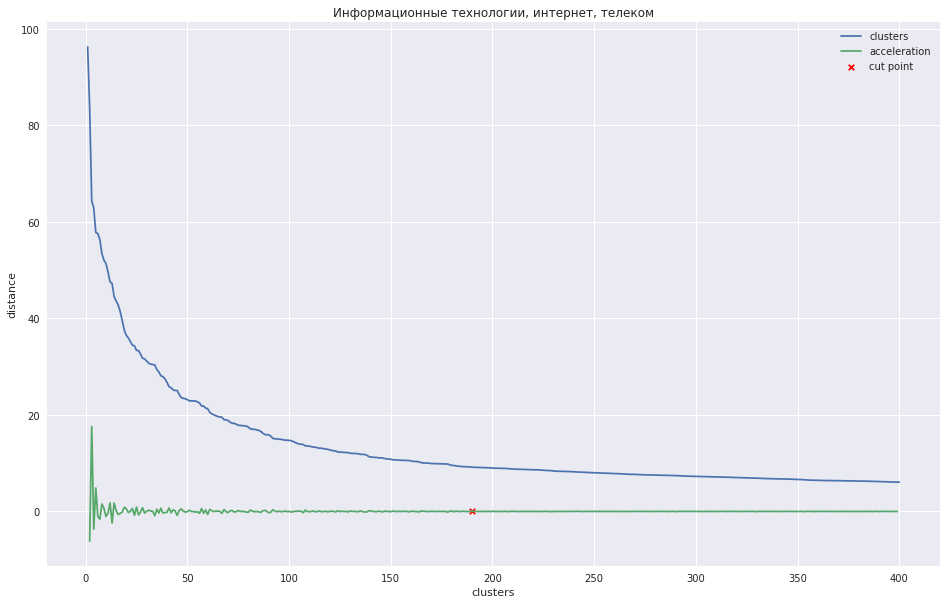
В случае с небольшим количеством кластеров можно было бы попробовать обрезать дерево в той точке, где максимально ускорение, т. е. расстояние в этот момент, когда объединялись два кластера было еще большим, а на следующем шаге уже меньше. В моем случае всё обстоит иначе — у меня много кластеров, и я предположил, что обрезать дендрограмму лучше в той точке, где ускорение начинает убывать более монотонно, т. е. расстояния между кластерами на этом уровне уже не обозначают отдельно стоящую группу. На графике это место примерно в той точке, где зеленая линия перестает плясать.
Можно было бы придумать какой-нибудь программный метод, но быстрее оказалось отметить для 28 профобластей эти места руками и подать в метод fcluster желаемое количество кластеров, который обрежет дерево в нужном месте.
Я сохранил данные, полученные ранее из t-SNE, и отметил на них получившиеся кластеры. Выглядит довольно неплохо:

В итоге я сделал веб-интерфейс, где можно поглядеть резюме из каждого кластера, на его положение на графике и дать осмысленное название. Для удобства вывел самое часто встречающееся название резюме — оно часто хорошо характеризует название кластера.
Посмотреть на результат кластеризации можно тут.
Я для себя сделал вывод, что система получилась рабочей. Хоть разбиение по кластерам неидеальное и какие-то группы сильно похожи друг на друга, а какие-то можно было бы, наоборот, разбить на части, но основные тренды рынка специальностей хорошо видны. Можно также увидеть, как формируются новые группы. Выгрузка резюме делалась ещё летом, поэтому выделились, например, водители, желающие работать на чемпионате мира по футболу. Если научиться матчить между собой кластеры от запуска к запуску, то можно наблюдать за тем, как меняются во времени основные направления специализаций. На самом деле идей по улучшению качества и развитию ещё полно. Если смогу найти в себе нужную мотивацию, буду развивать дальше.
Дополнительные материалы
Видео про агломеративную иерархическую кластеризацию из курса про поиск структуры в данных
Про масштабирование и нормализацию признаков
Tutorial по иерархической кластеризации из библиотеки SciPy, который я взял за основу своей задачи
Сравнение различных типов кластеризации на примере библиотек sklearn
Маленький бонус. Я подумал, что людям бывает интересно, как кто-то работает над задачей. Хочу сказать, что в некоторых вопросах неплохо прокачался, пока делал этот проект. Пробовал разные варианты, изучал, обдумывал, как работает та или иная штука. Во многих местах отсутствие хорошей математической базы компенсировалось находчивостью и большим количеством попыток. И я хотел бы поделиться выстраданным листком эвернота, в котором я делал пометки, работая над задачей. Размышления в нем были предназначены только для меня, там много ереси и непонятностей, но я думаю, что это нормально.
UPD: Выложил ноутбуки с кодом подготовки данных и кластеризации. Код не планировал выкладывать, так что за качество простите.
Комментарии (19)

maslyaev
31.10.2018 14:51Классная работа, но наталкивает на грустные размышления.
Допустим, получившийся продукт (действительно достойный) отправляется в промышленную эксплуатацию. То есть каждое поступающее резюме пропускается через этот кластеризатор, и первичное решение по нему принимается автоматически. Дальше уже оно или отправляется соответствующему специалисту с пометкой «hot», или засовывается в долгий ящик. Если в долгий ящик, то скорее всего это резюме ни один живой человек никогда глазами не увидит. Если алгоритм тупанул, триггернулся не на то, на что следовало (например, человек работал в клининговой фирме «Квант добра», и его классифицируют как физика-теоретика, со всеми вытекающими), то результативность резюме тоже существенно пострадает. Из функционирования ключевого бизнес-процесса исключается человеческий фактор, и как общий результат имеем то, что дела начинают делаться… как-то не по-человечески.
Мы живые люди. Нам время от времени приходится взаимодействовать с крупными структурами. По разным своим житейским ситуациям. В частности, искать работу. Или брать кредит. Или чинить холодильник. Или устраивать ребёнка в садик. Всё больше приходим к тому, что везде будет радикально повышена эффективность, отовсюду исключён человеческий фактор. Однажды проснувшись, мы обнаружим себя в мире, в котором буквально всё делается не по-человечески. В кафкианском «Замке» мирового масштаба.
P.S. Пример про «Квант добра» выдуман, но по мотивам реальных событий. Раз в несколько дней мне, программисту, до сих пор от одного горемычного роботизированного хедхантера прилетает список свежих вакансий крановщиков и трактористов.shurik2533 Автор
31.10.2018 15:00Мало вероятно, что проект будет развиваться по такому пути. Он скорее подходит для получения общей картины, чтобы, например, можно было поддерживать каталог специализаций в актуальном состоянии. Т.е. отдельные резюме не пострадают
maslyaev
31.10.2018 15:48Вопрос времени. Конкретно этот проект может быть и не станет поворотной точкой, но общая тенденция (не только в рекрутинге, но и почти везде) имеет место, и против неё грести весьма проблематично.
Rigidus
31.10.2018 15:29Есть ли код на гитхабе и данные, которые он использует, чтобы провести собственные эксперименты?
shurik2533 Автор
31.10.2018 16:31Ноутбуки с подготовкой данных и кластеризацией выложил. Выкладывать не планировал, поэтому в коде есть лишнее. Данные резюме мне выложить не позволят.
Rigidus
31.10.2018 16:32… даже если их обезличить?
shurik2533 Автор
31.10.2018 16:42Всё равно есть потенциальные риски каких-нибудь ликов. Плюс у нас есть коммерческие услуги по анализу данных резюме. Так что для публикации должен понабиться очень особый повод. Например, несколько лет назад проводился хакатон, где что-то предсказывали по резюме. Вероятно, где-то в сети можно найти с него данные
Rigidus
31.10.2018 16:47Т.е. для того чтобы воспроизвести результаты из статьи мне потребуется купить доступ к базе резюме, и спарсить их? Или есть какой-то более удачный способ?
shurik2533 Автор
31.10.2018 17:13Парсить базу резюме на hh.ru тоже нельзя. Скорее всего акой пользователь будет заблокирован.
PavelGhost
31.10.2018 16:32Отличная работа и очень грамотный последовательный стиль изложения. Побольше бы таких статей на Хабре.
Была бы карма, плюсанул бы с удовольствием.
gitKroz
31.10.2018 16:33Спасибо за статью. Давно интересуюсь вопросом, но с другой стороны.
Судя по всему, сейчас HR всё чаще применяют автоматическую обработку резюме. Проект описанный в данной статье — один из примеров.
А есть где-то открытые сервисы, хоть как-то приближённые к реальным, чтобы проверить свое резюме? Цель — подкорректировать резюме так, чтобы авто-парсер выдавал то, что я хотел донести, и чтобы резюме не было отсеяно по ошибке.shurik2533 Автор
31.10.2018 16:36Сомневаюсь, что такие есть. Каждый алгоритм уникален и кто знает, что он куда отнесет. Я бы советовал просто заполнять резюме максимально релевантно тому, чем собираетесь заниматься
Stas911
31.10.2018 23:27Не очень понятно зачем вам это. Насколько я понимаю логику работы ATS систем — они матчат резюме с описанием позиции и строят сортированный шортлист кандидатов. Что бы вы там не хотели донести, если данные вашего резюме не бьются с описанием позиции — его просто никто никогда не увидит. Вот есть такая тулза для быстрой проверки: www.jobscan.co
Я как-то писал подобную тулзу, которая тупо делала из резюме и позиции вектора ключевых слов и сравнивала их на cosine similarity — результат, кстати, весьма неплох был.gitKroz
01.11.2018 14:19Что касается логики — вот их уже две:
1. Сравнение ключевых слов в резюме с ключевыми словами в описании позиции
2. Кластеризация слов по примеру как описано в этой статье
При этом еще могут быть вариации. Например, в первом случае при сравнении можно учитывать базу данных синонимов (я, кстати, что-то похожее делал, только для других целей). А если скомбинировать два способа, то можно выявить специализацию кандидата в резюме, целевую специализацию в описании позиции, и потом ранжировать кандидатов в зависимости от того, насколько они близко к целевой специализации. «Девиации» от основной специализации могут трактоваться как в плюс так и в минус кандидату. А если алгоритмы основываются на алгоритмах машинного обучения, то еще важно на каких данных была натренирована система.
Наверняка есть и другие идеи.
За www.jobscan.co спасибо. Буду пользоваться.
Если еще есть что-то на примете — делитесь.
DaylightIsBurning
01.11.2018 01:27Теперь имеет смысл перевести данные в пространство меньшей размерности, чтобы в дальнейшем алгоритм кластеризации смог их переварить за приемлемые время и память.
Не могли бы Вы пояснить, зачем снижать размерность? Ведь алгоритмическая сложность кластеризации зависит только от числа элементов (резюме), а не числа признаков у них. Число признаков влияет на время расчета расстояний между парами элементов, но всего лишь линейно, да и время требуемое на снижение размерности (Truncated SVD) все равно будет больше, чем выигрыш от «облегчения» функции расстояний.shurik2533 Автор
01.11.2018 14:05Отличный вопрос. Кажется, вы правы. Я об этом не подумал. Надо будет проверить

Ava256
01.11.2018 14:06Интересно было бы посмотреть кластеризацию вакансий в области ИТ по скилам, можно увидеть какие скилы люди набирают наиболее часто, а какие отстают в развитии.
PhySci
Отличное описание реального применения!
Недавно столкнулся с похожей задачей. По-моему, проблему большого количества данных можно решать путём объединения (слияния) отдельных сэмплов, расстояние между которыми близко к нулю.