
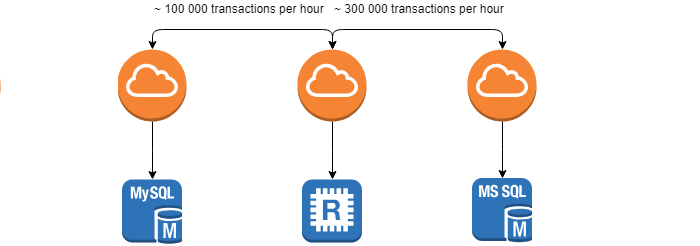
При разработке и использовании распределенных систем перед нами возникает задача контроля целостности и идентичности данных между системами — задача реконсиляции.
Требования, которые выставляет заказчик — минимальное время данной операции, поскольку чем раньше расхождение будет найдено, тем легче будет устранить его последствия. Задача заметно усложняется тем, что системы находятся в постоянном движении (~ 100 000 транзакций в час) и добиться 0% расхождений не получится.
Основная идея
Основную идею решения можно описать следующей диаграммой.
Рассмотрим каждый из элементов отдельно.
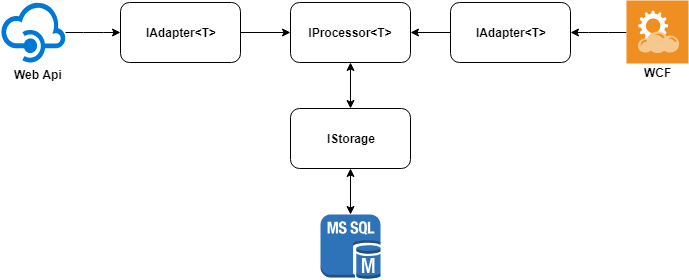
Адаптеры данных
Каждая из систем создана для своей предметной области и как следствие описания объектов могут существенно различаться. Нам же требуется сравнить только определенный набор полей из этих объектов.
Для упрощения процедуры сравнения, приведем объекты к единому формату, написав для каждого источника данных свой адаптер. Приведение объектов к единому формату, позволяет заметно сократить объем используемой памяти, поскольку хранить мы будем только сравниваемые поля.
Под капотом у адаптера может быть любой источник данных: HttpClient, SqlClient, DynamoDbClient и т.д.
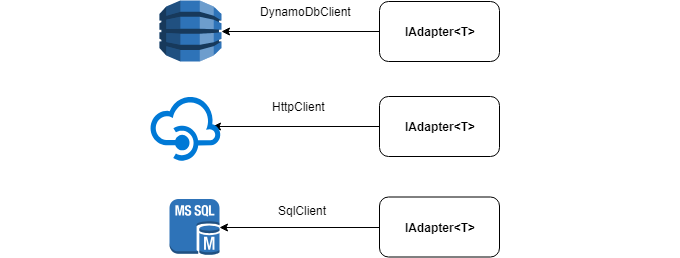
Ниже представлен интерфейс IAdapter, который требуется реализовать:
public interface IAdapter<T> where T : IModel
{
int Id { get; }
Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel);
}
public interface IModel
{
Guid Id { get; }
int GetHash();
}Хранилище
Реконсиляцию данных можно начинать только после того как все данные прочитаны, поскольку адаптеры могут возвращать их в произвольном порядке.
В таком случае объема оперативной памяти может не хватить, особенно если вы запускаете несколько реконсиляций одновременно, указывая большие временные интервалы.
Рассмотрим интерфейс IStorage
public interface IStorage
{
int SourceAdapterId { get; }
int TargetAdapterId { get; }
int MaxWriteCapacity { get; }
Task InitializeAsync();
Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId);
Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model);
}
public interface ISearchDifferenceModel
{
int Offset { get; }
int Limit { get; }
}Хранилище. Реализация на базе MS SQL
Мы реализовали IStorage, используя MS SQL, что позволило выполнять сравнение полностью на стороне Db сервера.
Для хранения реконсилируемых значений достаточно создать следующую таблицу:
CREATE TABLE [dbo].[Storage_1540747667]
(
[id] UNIQUEIDENTIFIER NOT NULL,
[adapterid] INT NOT NULL,
[qty] INT NOT NULL,
[price] INT NOT NULL,
CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid])
)Каждая запись содержит системные поля ([id], [adapterId]) и поля, по которым осуществляется сравнение ([qty], [price]). Пару слов о системных полях:
[id] — уникальный идентификатор записи, одинаковый в обеих системах
[adapterId] — идентификатор адаптера, через который была получена запись
Так как процессы реконсиляции могут быть запущены параллельно и иметь пересекающиеся интервалы, мы создаем для каждой из них таблицу с уникальным именем. В случае если реконсиляция прошла успешно, данная таблица удаляется, в противном случае отправляется отчет со списком записей, в которых есть расхождения.
Хранилище. Сравнение значений
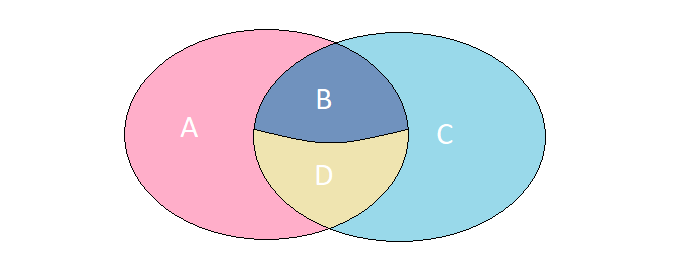
Представим, что у нас есть 2 множества, элементы которого имеют абсолютно идентичный набор полей. Рассмотрим 4 возможных случая их пересечения:
A. Элементы присутствуют только в левом множестве
B. Элементы присутствуют в обоих множествах, но имеют разные значения
С. Элементы присутствуют только в правом множестве
D. Элементы присутствуют в обоих множествах и имеют одинаковые значения
В конкретной задаче нам требуется найти элементы, описанные в случаях A, B, C. Получить требуемый результат можно за один запрос к MS SQL через FULL OUTER JOIN:
select
[s1].[id],
[s1].[adapterid]
from [dbo].[Storage_1540758006] as [s1]
full outer join [dbo].[Storage_1540758006] as [s2]
on [s2].[id] = [s1].[id]
and [s2].[adapterid] != [s1].[adapterid]
and [s2].[qty] = [s1].[qty]
and [s2].[price] = [s1].[price]
where [s2].[id] is nulВывод данного запроса может содержать 4 вида записей, отвечающих исходным требованиям
| # | id | adapterid | comment |
|---|---|---|---|
| 1 | guid1 | adp1 | Запись присутствует только в левом множестве. Случай A |
| 2 | guid2 | adp2 | Запись присутствует только в правом множестве. Случай С |
| 3 | guid3 | adp1 | Записи присутствует в обоих множествах, но имеют разные значения. Случай B |
| 4 | guid3 | adp2 | Записи присутствует в обоих множествах, но имеют разные значения. Случай B |
Хранилище. Хэширование
Используя хэширование по сравниваемым объектам, можно значительно удешевить операции записи и сравнения. Особенно, когда заходит речь о сравнении десятков полей.
Наиболее универсальным оказался способ хэширования сериализованного представления объекта.
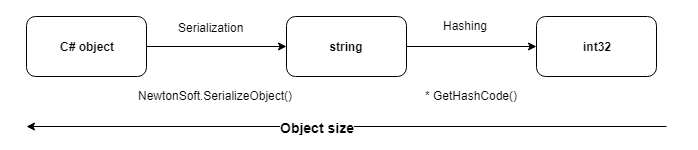
1. Для хэширования мы используем стандартный метод GetHashCode(), возвращающий int32 и переопределенный для всех примитивных типов.
2. В данном случае вероятность коллизий маловероятна, поскольку сравниваются только записи имеющие одинаковые идентификаторы.
Рассмотрим структуру таблицы, используемую при данной оптимизации:
CREATE TABLE [dbo].[Storage_1540758006]
(
[id] UNIQUEIDENTIFIER NOT NULL,
[adapterid] INT NOT NULL,
[hash] INT NOT NULL,
CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash])
)Преимущество такой структуры — это константная стоимость хранения одной записи (24 байта), которая не будет зависеть от числа сравниваемых полей.
Естественно и процедура сравнения претерпевает свои изменения и становится значительно проще.
select
[s1].[id],
[s1].[adapterid]
from [dbo].[Storage_1540758006] as [s1]
full outer join [dbo].[Storage_1540758006] as [s2]
on [s2].[id] = [s1].[id]
and [s2].[adapterid] != [s1].[adapterid]
and [s2].[hash] = [s1].[hash]
where [s2].[id] is nullПроцессор
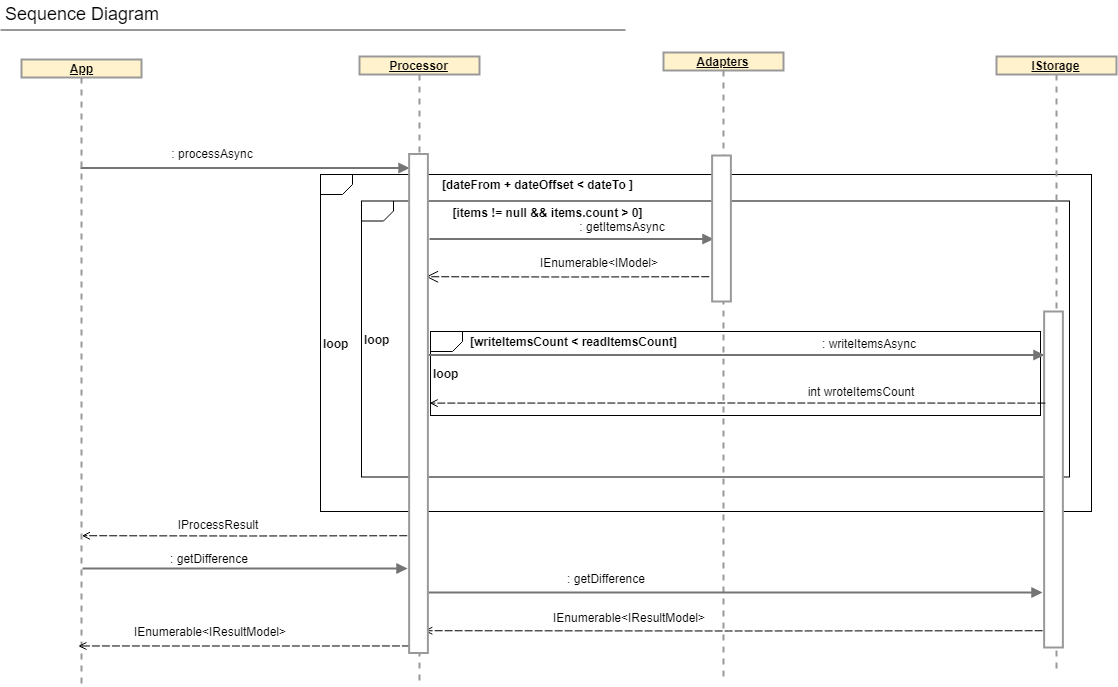
В данном разделе пойдет речь о классе, содержащем всю бизнес-логику реконсиляции, а именно:
1. параллельное чтение данных из адаптеров
2. хэширование данных
3. буферизованная запись значений в БД
4. выдача результатов
Более комплексное описание процесса реконсиляции можно получить, рассмотрев диаграмму последовательностей и интерфейс IProcessor.
public interface IProcessor<T> where T : IModel
{
IAdapter<T> SourceAdapter { get; }
IAdapter<T> TargetAdapter { get; }
IStorage Storage { get; }
Task<IProcessResult> ProcessAsync();
Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model);
}
Благодарности
Огромная благодарность моим коллегам из MySale Group за фидбек: AntonStrakhov, Nesstory, Barlog_5, Косте Кривцуну и VeterManve — автору идеи.
Комментарии (10)

VeterManve
01.11.2018 16:42Я думаю можно было еще указать в статье, что при наличии адаптеров при расхождении, можно потом по id этих записей выбрать их из адаптеров и глазами на них посмотреть (если сделать в адаптере поддержку не только выборку по диапазону дат, но еще и по массиву id).
VeterManve
01.11.2018 17:32А какое количество данных и на каких мощностях вы реконсилировали в продакшне? Поставили ли этот подход на поток, как отображаете результаты реконсиляции?

ggo
02.11.2018 09:53+1Насколько я понял, в вашем случае, приложение реконсилляции подключается в двум разным базам, проводит аналитику, и показывает разницу по-экземплярно?
Сериализация и вычисление хеша действительно быстрее прямолинейого множественного сравнения строк и чисел через AND?stus Автор
02.11.2018 13:34Насколько я понял, в вашем случае, приложение реконсилляции подключается в двум разным базам, проводит аналитику, и показывает разницу по-экземплярно?
В 3 из 4 случаев реконсилируются приложения WebApi vs WebApi, в оставшемся WebApi vs SQL, поскольку интерфейс не поддерживает бачевые методы, либо структура данных избыточна — большой оверхед на транспорт и сериализацию.
Если перед вами стоит задача реконсилировать SQL vs SQL и базы находятся на одном сервер, то проще и эффективнее написать SQL jobs. Но при таком подходе придется следить за изменениями в структуре БД, в этом плане использовать API с версиями намного проще.
Сериализация и вычисление хеша действительно быстрее прямолинейого множественного сравнения строк и чисел через AND?
Здесь больший фокус на универсальности, получается идентичная структура таблицы, одинаковый запрос на сравнение и константная стоимость хранения.
По факту большая часть ресурсов тратится на получение данных по HTTPS и десериализация объектов. Оверхед на функцию GetHashCode() минимальный (взгляните на ее код).
dotnetdonik
Это поверх messaging надо еще городить еще один механизм? а как же low coupling между микросервисами при разработке таких костылей можно просто работать с монолитом — так как у вас все равно тесная зависимость на контракты другого сервиса, и если меняеться домен сервиса как либо надо диплоить все зависимость — и код обновлять?
stus Автор
Допустим у Вас есть 2 системы:
1. монолитный Dynamic CRM, отвечающий за учет стока на складах и построение отчетов-
2. микросервисный Stock Service, отвечающий за общее число товаров на сайтах, кол-во доступных товаров для данного сайта и резервацию товаров пользователями.
С первой системой работает исключительно внутренний персонал, со второй покупатели через веб-сайты или мобильные приложения, следовательно изменения данных возможны с любой стороны.
Естественно обе системы связаны сервисом интеграции через Messages Queue, поскольку производительность приложений разная.
Что произойдет если кол-ва начнут расходиться
1. вы можете продать больше товаров, чем у вас есть на самом деле и как следствие потерять клиента
2. не распродать весь сток и тем самым нанести компании убытки
Для мониторинга подобных проблем как раз и пишется сервис реконсиляции, запускающийся каждый час.
dotnetdonik
Понятно. То о чем вы говорите называется требование strong write consistency.
Вашим подходом вы не решаете эту проблему вроде как проблему. Если там кто-то у вас руками решает конфликты и получает письма, с сагами, например, вы можете собственно делать тоже самое и даже больше(делать роллбек не руками, в момент покупки и обеспечивать транзакционность даже для распределенных данных). При этом не уходя от event driven дизайна системы, не изобретая велосипед и не создавая связей между сервисами.
Еще можно обратить внимание на дизайн сервисов. Где находиться Core domain — например если склад первичен, то резервация по идее и должна делаться через него. В read-only стейт Stock Service вообще вроде как не имеет требований строгой read консистентности(там банально из-за concurrency может закончиться товар пока он лежит в корзине).
stus Автор
Реконсиляции — инструмент мониторинга целостности данных, а не способ устранения причины, почему данные разошлись. При этом ряд конфликтов (расхождений) действительно можно разрешить автоматически, но этим мы лечим следствие, а не причину.
То что вы описываете в комменте — способ устранение причины. Но конкретном случае мы не можем внести изменения в Dynamic CRM (Navision) и свести все к одному источнику данных.