

Есть небольшой дата-центр около производственной компании в небольшом городе довольно далеко от Москвы. Он нужен круглосуточно. Так получилось, что ввод от электросети там только один, а ДГУ нет. Потому что компания не айтишная, а производственная, правильно проектировать они когда-то не стали. Потому что когда-то всё и так работало.
Луч питания начал шалить. Каждую неделю свет отрубали на несколько часов, причём лотерейным образом: могли на час, а могли и больше. Закономерностей нет.
Админ предложил купить дизель, но бизнес сказал, что это не админское дело. Его дело — обеспечить простой не больше часа. В оборудование они только что вбухали много денег, поэтому уходить в облако нельзя, а коммерческих дата-центров, чтобы перевезти туда оборудование, поблизости нет.
И что делать?
Именно с такой задачей заказчик пришёл к нам. Бюджета особо нет, нужно искать действующее решение.
Нормальный случай (это если не считать появления второго ввода, переноса оборудования или появления дизельного генератора) — развернуть второй точно такой же инстанс в облаке и переключать на него, если вдруг что-то падает. Называется Disaster Recovery. Некоторые вот себе второй ЦОД строят, он стоит холодным и ждёт, когда упадёт основной, либо работает в режиме active-active, принимая 50 % нагрузки.
Но денег на второй полноценный ЦОД нет.
Придумали вот что:

Есть тяжёлый физический сервер с базой данных в ЦОДе клиента. А есть приложения, работающие с этой базой, которые представляют собой набор виртуальных машин на ESXi.
Для репликации базы в облако поставили софт Carbonite Availability (ранее известен как Double-Take Availability), который работает на уровне операционки. А для репликации виртуалок поставили Zerto, этот софт работает на уровне гипервизора. Оба решения действуют примерно одинаково: сперва реплицируют весь объём данных сервера в облако, а затем перехватывают все записи на диски на основной площадке и дублируют их на диски в облако. Задержка конкретно в этом случае 10 секунд, то есть мы всегда имеем свежую копию данных 10-секундной давности.
Виртуальные машины не включены. По кнопке из панели управления Зерто мы можем запустить все ВМ сразу. Происходит это в течение примерно 28 минут (машины запускаются параллельно), SLA на простой у нас 1 час. Запуск делается по звонку дежурному администратору. Заказчик сам решает, когда это нужно.
ВМ подхватывают базу и начинают работать.
Когда на объекте включается питание, заказчик сам разбирается в своей инфраструктуре. Разруливает поломки, затем вручную включает реверс-репликацию. Накопленный за время работы приложений объём изменений в базе данных отправляется назад. Отреплицировали — переключаются. В этом конкретном примере на каждый час работы виртуальных машин накапливается трафика примерно на 5 минут перезаливки. Чем больше время работы аварийного инстанса, тем меньше доля трафика, потому что записи часто идут в одни и те же таблицы базы данных, а мы отправляем только разницу.
После обратного переключения в облаке выключаются виртуальные машины. Заказчик не платит за ресурсы, которые выключены. Квантование у нас по часам.
Оплата идёт только за объём хранимых данных, канал и лицензию на софт для репликации (Zerto и Carbonite). Мы делаем работы по принципу «Disaster Recovery as a Service», даём SLA на это всё. И финансово отвечаем за этот SLA.
Реплицирует заказчик вообще всё, виртуалка с теми же параметрами, что и его физика, все диски зеркальные.
Вот так делает Зерто:
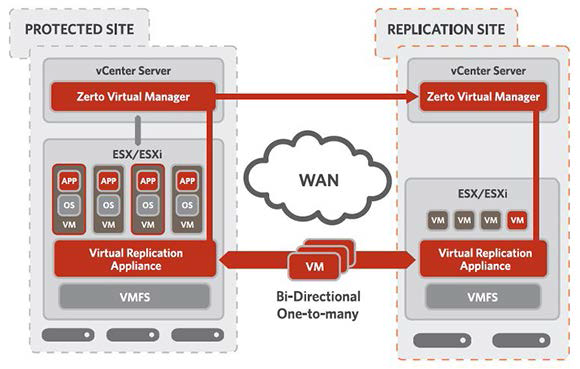
У него безагентская репликация, есть асинхронный режим, ВМ на DR-площадке выключены, журналируемая репликация, WAN-оптимизация, кросс-гипервизорная репликация, лицензирование по защищаемым виртуальным машинам.
Carbonite — это агентская репликация, поэтому без разницы какой гипервизор, есть асинхронный режим работы, есть поддержка снапшотов, компрессия передаваемых данных, лицензирование по защищаемым виртуальным машинам.
В инсталляции применены оба решения сразу. Так было надо из-за ряда особенностей. Обычно предлагают что-то одно.
Ещё можно решать похожую задачу отечественным решением Veeam Cloud Connect (обычно используем, если у вас уже есть бэкап Veeam).
Итог
Мы все понимаем, что задачу можно было решить по-другому, прокачав серверную установкой дизель-генератора. Однако бизнес спустил требования по организации резерва. Мы предоставили сервис, и всё заработало. Получился хороший пример того, как можно развернуть DR-площадку правильно и недорого.
Ссылки
- Софт: Carbonite Availability входит в портфель продуктов Vision Solutions, работает на уровне ОС. Zerto Virtual Replication — безагентская репликация для виртуальных сред VMware vSphere и Microsoft Hyper-V. Обязателен для сертификации Cisco Hybrid Cloud Services Certification. Veeam Cloud Connect особенно удобен в случае, если уже используется продукт Veeam Backup & Replication.
- Кейс переезда с разовым использованием Даблтейка: заказчика не отпускал провайдер.
- Виртуализация сетей хранения данных.
- Сборка дата-центра в кармане на базе Intel NUC.
- Моя почта — RSayfutdinov@croc.ru.
Комментарии (4)

SergeyMax
06.11.2018 23:26Однажды в три часа ночи спросонья админ выберет в интерфейсе неправильное направление репликации, перезатрёт данные репликой, сломанной две недели назад, и бизнес
спустит свои требования туда, куда и следовалокупит дизель-генератор.
Kutak
07.11.2018 04:29А как настроена сеть в репликах зерто? Делается ли переназначение IP на репликах (через зерто, или же в гостевых ВМ) или все используют те же самые адреса — вланы — подсети, что и в основном ДЦ? Также интересно, нет ли проблем с репликацией между домен-контроллерами типа USB rollback после переключения на реплики Зерто?
RenatS Автор
07.11.2018 15:57Между площадками сетевая связность на уровне L3. Подсети c разной адресацией. При переключении на резервную площадку происходит смена IP-адресов в ОС через VMware tools. Это штатный функционал Zerto.
В момент настройки репликации администратор мапит подсеть с основной площадки на подсеть в резервной площадке. Также на резервной площадке определена изолированная подсеть для тестовых переключений – Zerto поддерживает режим теста, при котором ВМ на основной площадке не выключаются. В случае тестового переключения ВМ на резервной площадке будут подняты в изолированном сегменте – проблем с инфраструктурой не будет.
С проблемой USN rollback в данном кейсе не сталкивались, так как реплицируемые ВМ используют ОС Linux c локальными пользователями. В случае кейса с AD лучшей практикой будет поднять контроллер домена на резервной площадке.
AndrewTishkin
Заголовок не раскрыт: конкретики про "дешевизну" не приведено. Может пять рублей в цифрах выиграли, а нагородили...