
 В самом сердце информационно-поисковых систем Meltwater и Fairhair.ai работает набор кластеров Elasticsearch с миллиардами статей из СМИ и социальных медиа.
В самом сердце информационно-поисковых систем Meltwater и Fairhair.ai работает набор кластеров Elasticsearch с миллиардами статей из СМИ и социальных медиа.Индексные шарды в кластерах сильно отличаются по структуре доступа, рабочей нагрузке и размеру, что поднимает некоторые очень интересные проблемы.
В этой статье мы расскажем, как применили линейное программирование (линейную оптимизацию) для максимально равномерного распределения рабочей нагрузки поиска и индексирования по всем узлам в кластерах. Это решение уменьшает вероятность, что один узел станет узким местом в системе. В результате мы увеличили скорость поиска и сэкономили на инфраструктуре.
Предыстория
Информационно-поисковые системы Fairhair.ai содержат около 40 миллиардов сообщений из социальных медиа и редакционных статей, ежедневно обрабатывая миллионы запросов. Платформа предоставляет клиентам поисковые результаты, графики, аналитику, экспорт данных для более продвинутого анализа.
Эти массивные наборы данных размещаются в нескольких кластерах Elasticsearch на 750 узлов с тысячами индексов в более 50 000 шардов.
Подробнее о нашем кластера см. предыдущие статьи о его архитектуре и балансировщике нагрузке на машинном обучении.
Неравномерное распределение рабочей нагрузки
И наши данные, и пользовательские запросы обычно привязаны к дате. Большинство запросов попадают в определённый период времени, например, прошлая неделя, прошлый месяц, последний квартал или произвольный диапазон. Для упрощения индексации и запросов мы используем индексирование по времени, похожее на стек ELK.
Такая архитектура индексов даёт ряд преимуществ. Например, можно выполнять эффективное массовое индексирование, а также удалять целые индексы при устаревании данных. Это также означает, что рабочая нагрузка для данного индекса сильно меняется со временем.
К последним индексам идёт экспоненциально больше запросов, по сравнению со старыми.

Рис. 1. Схема доступа для индексов по времени. На вертикальной оси отложено количество выполненных запросов, по горизонтальной оси — возраст индекса. Чётко видны недельные, месячные и годичные плато, за которыми следует длинный хвост более низкой рабочей нагрузки на более старые индексы
Паттерны на рис. 1 были вполне предсказуемы, так как наши клиенты больше заинтересованы в свежей информации и регулярно сравнивают текущий месяц с прошлым и/или этот год с прошлым годом. Проблема в том, что Elasticsearch не знает об этом паттерне и не выполняет автоматическую оптимизацию для наблюдаемой рабочей нагрузки!
Встроенный алгоритм размещения шардов Elasticsearch учитывает только два фактора:
- Количество шардов на каждом узле. Алгоритм пытается равномерно сбалансировать количество шардов на узел по всему кластеру.
- Метки свободного места на дисках. Elasticsearch рассматривает доступное дисковое пространство на узле, прежде чем принять решение о выделении этому узлу новых шардов или перемещения сегментов с этого узла на другие. При 80% используемого диска на узел запрещено размещать новые шарды, на 90% система начнёт активно переносить шарды с этого узла.
Фундаментальное предположение алгоритма в том, что каждый сегмент в кластере получает примерно одинаковое количество рабочей нагрузки и что у всех одинаковый размер. В нашем случае это очень далеко от истины.
Стандартное распределение нагрузки быстро приводит к появлению «горячих точек» в кластере. Они появляются и исчезают случайным образом, поскольку рабочая нагрузка меняется с течением времени.
Горячая точка — это, по сути, узел, работающий вблизи своего предела одного или нескольких системных ресурсов, таких как CPU, дисковый ввод-вывод или пропускная способность сети. Когда такое происходит, узел сначала ставит запросы в очередь на некоторое время, что увеличивает время ответа на запрос. Но если перегрузка продолжается долго, то в конечном итоге запросы отклоняются, а пользователи получают ошибки.
Другое распространённое следствие перегрузки — неустойчивое давление мусора JVM из-за запросов и операций индексирования, что приводит к феномену «страшного ада» сборщика мусора JVM. В такой ситуации JVM или не может достаточно быстро получить память и вылетает с ошибкой (out of memory), или застревает в бесконечном цикле сборки мусора, зависает и перестаёт отвечать на запросы и пинги кластера.
Проблема усугубилось, когда мы произвели рефакторинг своей архитектуры под AWS. Раньше нас «спасало» то, что мы запускали до четырёх узлов Elasticsearch на собственных мощных серверах (24 ядра) в своём дата-центре. Это маскировало влияние асимметричного распределения шардов: нагрузка в значительной степени сглаживалась относительно большим количеством ядер на машину.
После рефакторинга мы разместили только по одному узлу на менее мощных машинах (8 ядер) — и первые тесты сразу выявили большие проблемы с «горячими точками».
Elasticsearch назначает шарды в случайном порядке, и с более чем 500 узлами в кластере сильно выросла вероятность слишком большого количества «горячих» шардов на одном узле — и такие узлы быстро переполнялись.
Для пользователей это означало бы серьёзное ухудшение работы, поскольку перегруженные узлы медленно отвечают, а иногда вовсе отвергают запросы или падают. Если вывести такую систему в продакшн, то пользователи увидят частые, казалось бы, случайные замедления UI и случайные таймауты.
В то же время остаётся большое количество узлов с шардами без особой нагрузки, которые фактически бездействуют. Это приводит к неэффективному использованию наших кластерных ресурсов.
Обеих проблемы можно было бы избежать, если бы Elasticsearch более разумно распределял шарды, так как среднее использование системных ресурсов на всех узлах находится на здоровом уровне 40%.
Непрерывное изменение кластера
При работе более 500 узлов мы наблюдали ещё одну вещь: постоянное изменение состояния узлов. Шарды постоянно перемещаются туда-сюда по узлам под влиянием следующих факторов:
- Создаются новые индексы, а старые отбрасываются.
- Метки дисков срабатывают из-за индексирования и других изменений на шардах.
- Elasticsearch случайным образом решает, что на узле слишком мало или слишком много шардов по сравнению со средним значением кластера.
- Аппаратные сбои и сбои на уровне ОС приводят к запуску новых инстансов AWS с присоединением их к кластеру. С 500 узлами это происходит в среднем несколько раз в неделю.
- Новые узлы добавляются почти каждую неделю из-за обычного роста данных.
С учётом всего этого мы пришли к выводу, что для комплексного решения всех проблем необходим непрерывный и динамичный алгоритм повторной оптимизации.
Решение: Shardonnay
После длительного изучения доступных вариантов мы пришли к выводу, что хотим:
- Построить собственное решение. Мы не нашли хороших статей, кода или других существующих идей, которые хорошо сработают в нашем масштабе и для наших задач.
- Запустить процесс повторной балансировки за пределами Elasticsearch и использовать кластерные API перенаправления, а не пытаться создать плагин. Мы хотели быстрый цикл обратной связи, а деплой плагина на кластере такого масштаба может занять несколько недель.
- Использовать линейное программирование для расчёта оптимальных перемещений шарда в любой момент времени.
- Выполнять оптимизацию непрерывно, чтобы состояние кластера постепенно пришло к оптимальному.
- Не перемещать слишком много шардов одновременно.
Мы заметили интересную вещь, что если переместить слишком много шардов одновременно, то очень легко вызвать каскадный шторм перемещения шардов. После начала такого шторма он может продолжаться часами, когда шарды неконтролируемо перемещаются туда и обратно, вызывая появление меток о критическом уровне дискового пространства в различных местах. В свою очередь, это приводит к новым перемещениям шардов и так далее.
Чтобы понять происходящее, важно знать, что при перемещении активно индексируемого сегмента он начинает фактически использовать намного больше места на том диске, откуда перемещается. Это связано с тем, как Elasticsearch сохраняет логи транзакций. Мы видели случаи, когда при перемещении узла индекс вырастал вдвое. Это означает, что узел, который инициировал перемещение шарда из-за высокого использования дискового пространства, некоторое время будет использовать ещё больше дискового пространства, пока не переместит достаточное количество шардов на другие узлы.
Для решения этой проблемы мы разработали сервис Shardonnay в честь знаменитого сорта винограда Шардоне.
Линейная оптимизация
Линейная оптимизация (или линейное программирование, ЛП) — это метод достижения наилучшего результата, такого как максимальная прибыль или наименьшая стоимость, в математической модели, требования которой представлены линейными отношениями.
Метод оптимизации основан на системе линейных переменных, некоторых ограничениях, которые должны быть выполнены, и целевой функции, которая определяет, как выглядит успешное решение. Цель линейной оптимизации — найти значения переменных, которые минимизируют целевую функцию при соблюдении ограничений.
Распределение шардов как задача линейной оптимизации
Shardonnay должен работать непрерывно, а на каждой итерации он выполняет такой алгоритм:
- С помощью API Elasticsearch извлекает информацию о существующих шардах, индексах и узлах в кластере, а также об их текущем размещении.
- Моделирует состояние кластера как набор двоичных переменных ЛП. Каждая комбинация (узел, индекс, шард, реплика) получает собственную переменную. В модели ЛП есть ряд тщательно разработанных эвристик, ограничений и целевая функция, об этом ниже.
- Отправляет модель ЛП в линейный солвер, который выдаёт оптимальное решение с учётом ограничений и целевой функции. Решением является новое назначение шардов на узлы.
- Интерпретирует решение ЛП и преобразует его в последовательность перемещений шардов.
- Поручает Elasticsearch выполнить перемещения шардов через API перенаправления кластера.
- Ждёт, пока кластер переместит шарды.
- Возвращается к шагу 1.
Главное — разработать правильные ограничения и целевую функцию. Остальное сделают солвер ЛП и Elasticsearch.
Неудивительно, что задача оказалось очень непростой для кластера такого размера и сложности!
Ограничения
Некоторые ограничения в модели мы основываем на правилах, продиктованных самим Elasticsearch. Например, всегда придерживаться меток диска или запрет на размещение реплики на том же узле, где находится другая реплика того же шарда.
Другие добавлены на основе накопленного опыта за годы работы с большими кластерами. Вот некоторые примеры наших собственных ограничений:
- Не перемещать сегодняшние индексы, так как они являются самыми горячими и получают почти постоянную нагрузку на чтение и запись.
- Отдавать предпочтение перемещению более мелких шардов, потому что Elasticsearch быстрее с ними справляется.
- Создавать и размещать будущие шарды желательно за несколько дней до того, как они станут активными, начнут индексироваться и подвергнутся большой нагрузке.
Функция стоимости
Наша функция стоимости взвешивает вместе ряд различных факторов. Например, мы хотим:
- минимизировать дисперсию индексирования и поисковых запросов, чтобы уменьшить количество «горячих точек»;
- сохранить минимальную дисперсию использования диска для стабильной работы системы;
- минимизировать количество перемещений шардов, чтобы не начинались «штормы» с цепной реакцией, как описано выше.
Сокращение переменных ЛП
В нашем масштабе проблемой становится сам размер этих ЛП-моделей. Мы быстро поняли, что задачи не решить за разумное время при более чем 60 млн переменных. Поэтому мы применили много трюков оптимизации и моделирования, чтобы резко уменьшить количество переменных. Среди них — предвзятая выборка, эвристики, метод «разделяй и властвуй», итеративные релаксации и оптимизации.
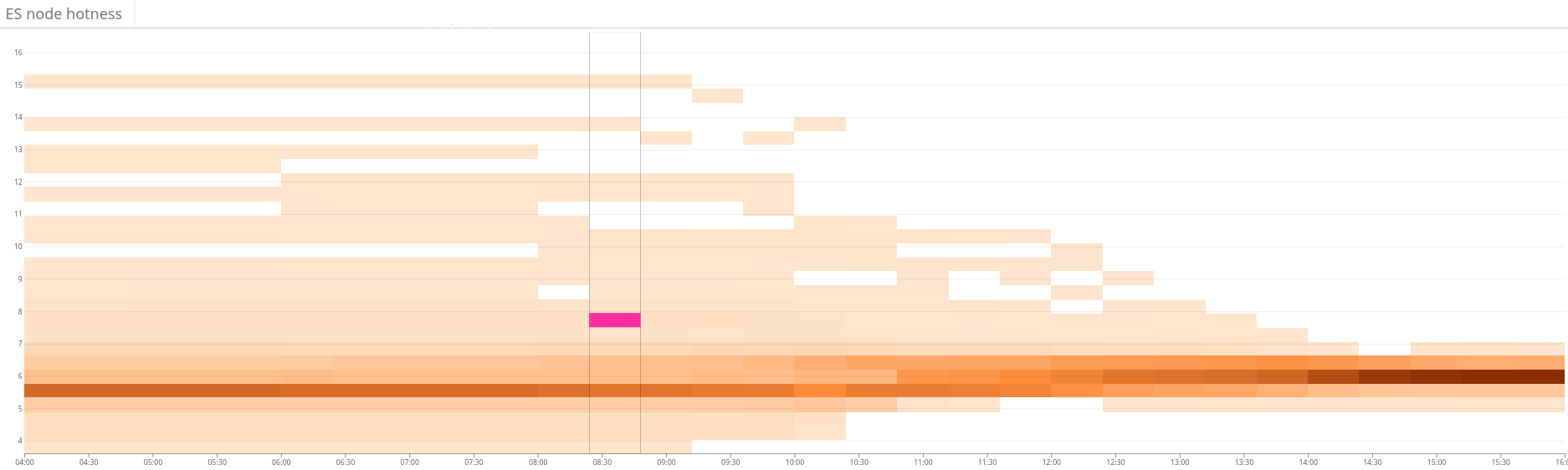
Рис. 2. Тепловая карта показывает несбалансированную нагрузку на кластер Elasticsearch. Это проявляется в большой дисперсии использования ресурсов в левой части графика. Благодаря непрерывной оптимизации ситуация постепенно стабилизируется
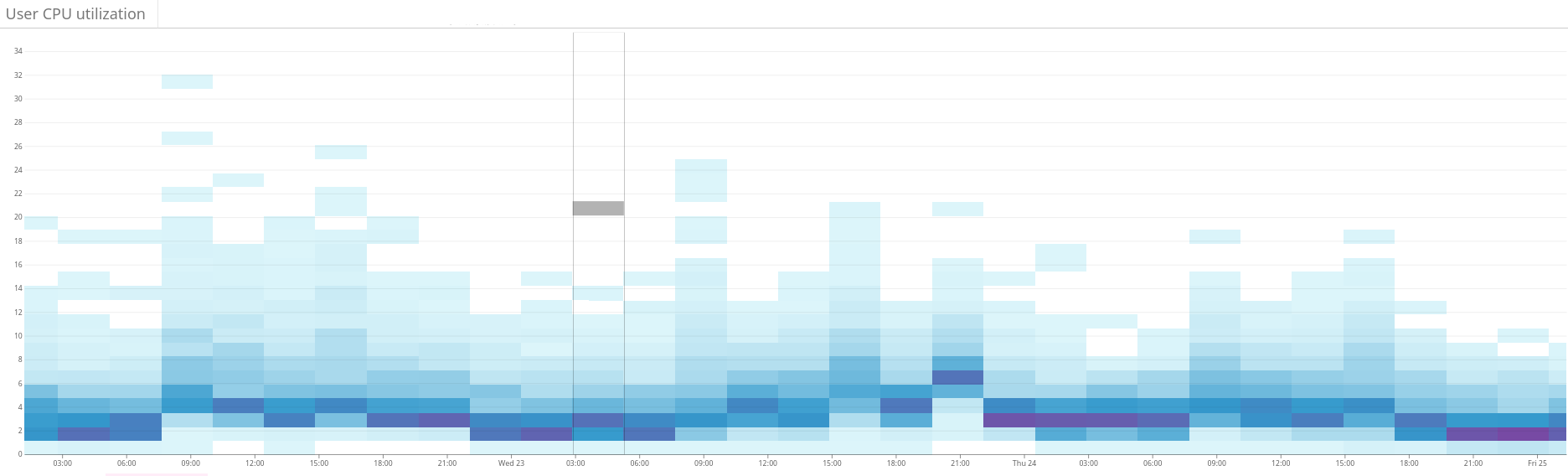
Рис. 3. Тепловая карта показывает использование CPU на всех узлах кластера до и после настройки функции hotness в Shardonnay. Видно значительное изменение в использовании CPU при неизменной рабочей нагрузке
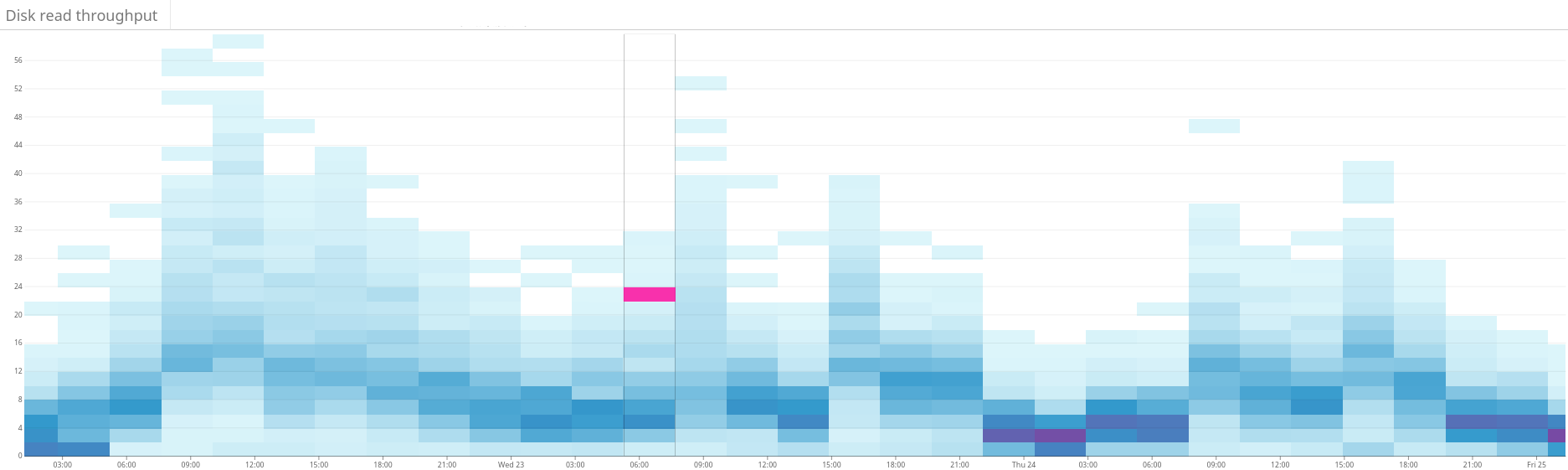
Рис. 4. Тепловая карта показывает пропускную способность чтения дисков в течение того же периода, что и на рис. 3. Операции чтения тоже более равномерно распределяются по кластеру
Результаты
В результате наш солвер ЛП находит хорошие решения за несколько минут, даже для нашего кластера огромного размера. Таким образом, система итеративно улучшаает состояние кластера в направлении оптимальности.
И самое приятное, что дисперсия рабочей нагрузки и использования дисков сходится как и ожидалось — и это близкое к оптимальному состояние поддерживается после многих намеренных и неожиданных изменений состояния кластера с тех пор!
Теперь мы поддерживаем здоровое распределение рабочей нагрузки в наших кластерах Elasticsearch. Всё благодаря линейной оптимизации и нашему сервису, который мы с любовью называем Шардоне.
Wolverine
А есть какие-то технические подробности, может быть реализация алгоритма?