
Эта тенденция наблюдается уже несколько лет.
Почему это происходит?
Разумеется потому, что качество Яндекс-выдачи уступает качеству Гуугл выдачи.
Связано это с тем, что в выдаче Яндекса огромное количество дублей, левых сайтов, наполненных копипастом, и сайтов, продвигаемых при помощи СЕО-технологий.
А вот оригинальных сайтов, первоисточников, авторских сайтов и первопубликаций в Яндексе почти нет.
А кому охота рыться в копипастерских помойках, забитых тизерами и Яндекс-директом?
Почему же Яндекс вот уже который год не может наладить адекватную выдачу, где авторский текст, первопубликация первична, а копипастеры вторичны или вовсе ликвидированы?
Много лет я пытался это понять. Оказалось, что все предельно просто.
Яндекс не умеет правильно определять дату публикации текста.
Возьмем, например, мой текст .........../article4.htm
В поисковой выдаче Яндекса более сотни копий (копипастов) этой моей статьи, но нет моего оригинала.
«Возраст» моей страницы Яндекс определяет лишь 2007 годом!
Это при том, что, например, в 2001 или 2002 он спокойно эту страницу знал и выдавал первой над копипастами.
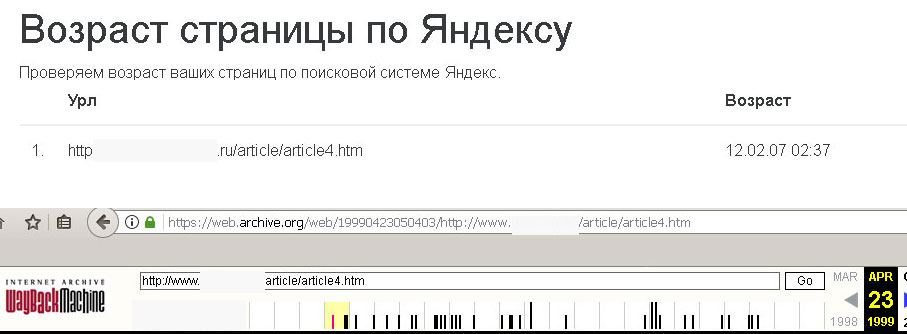
Реальный возраст моей страницы 1998г.
А по сегодняшнему Яндексу выходит — 2007.
И Яндекс считает ее копипастом, а всех, кто своровал и разместил мой текст с 1998 по 2007 год — оригиналами. Этих воров более сотни.
Доказать, что Яндекс неверно определяет возраст довольно просто. Достаточно заглянуть в web.archive.org.
Но это, оказывается, Яндексу не под силу.
3000 сотрудников, куча денег, а возраст страницы определить выше сил.
Т.е. сервис, утверждающий, что решает сложнейшие задачи, не может решить элементарной!
Похоже на математика, утверждающего, что справится с любым интегралом, но не знающим таблицы умножения и арифметики.
Аналогичная картина наблюдается для огромного количества первопубликаций на моем сайте.
(Поскольку я создал сайт в 1998 году и только я определял тексты для публикации, а часто и писал их, то я точно знаю, какие тексты были первопубликациями, а какие нет).
Яндекс работает с 1997 года.
Значит его робот должен был посетить мою страницу в 1998-1999 году, не позднее. И посещал.
Но получается, что робот эти данные потерял, если определяет возраст страницы, созданной в 1998г, лишь 2007 годом, а не 1998.
Верное определение возраста страницы — это единственный способ борьбы с копипастом, вторичным и не оригинальным контентом.
И как заявляет Яндекс, ИКС учитывает первичность и вторичность контента.
На деле, как я понимаю, не учитывает. Получается обман.
Опять получается пессимизация тех, кто создает контент, и опять в фаворе у Яндекса те, кто копипастит, т.е. ворует.
Необходимо сделать так, чтобы возраст публикации оказывал существенное влияние на отображение сайта в выдаче.
Иначе получается, что нет никакого смысла создавать оригинальный контент, создавать первопубликации.
Проще копипастить.
Итог — океаны копипаста.
Разве это нужно Яндексу?
Комментарии (32)

Slowz
21.11.2018 15:42+2Забавно. Статья с места в карьер начинается с постулирования ложных фактов.
"Все больше пользователей отказываются", "Эта тенденция наблюдается уже несколько лет". Своеобразное клеше разоблачительных статей.
Интересно, а в других поисковиках ситуация лучше? Просто есть подозрения, что индексирование сайтов (не только у Яндекса) обращает внимание не только на дату авторства, но и на миллион других факторов. Вы точно уверены, что ваш сайт отсутствует в выдаче? Точно ли он должен быть выше других сайтов с тем же контентом, но более дружелюбных к SEO?asdoc Автор
21.11.2018 16:05-1Посмотрите статистику. Я лишь констатировал факт падения доли поискового трафика у Яндекса. Это давно не новость.
«Точно ли он должен быть выше других сайтов с тем же контентом, но более дружелюбных к SEO?» — да, уверен. На сегодняшний день сайт технически и т.д. безупречен по всем параметрам Гуугла и Яндекса.MasteR_GeliOS
21.11.2018 16:26Что-то мне подсказывает что даже если такая метрика и имеет место быть, то дело не в качестве. Скорее всего дело в самой многочисленной прослойке устройств — смартфонах. И, как логическое продолжение, самом популярном браузере. Скорее всего такого рода статистика создается от неосознаемости процесса поиска в интернете неотделимости его в массовом сознании от устройства/браузера.
dididididi
21.11.2018 15:59А примеры посвежее есть, а то 1998 год — даже не смешно. Вполне возможно, что поиск перестает учитывать «новизну» очень старых материалов.
asdoc Автор
21.11.2018 16:10-1Смотрите. Если текст идентичен «до запятой», то в чем тогда «новизна» сворованного текста?
Если Ваша догадка верна, то профессионализм сотрудников Яндекса вызывает серьезные сомнения.
1998 год как раз очень удобен «для примера». Сайтов и копипастеров тогда было меньше, чем сейчас. И с тех пор накопилось большое количество (более сотни на 1 статью) копипастов.
Если взять текст, например, прошлого года, то такой яркой «картинки» не получится.Alexeyslav
21.11.2018 16:43А не нужна яркая картинка, нужна всего лишь убедительная. Ладно там 1998 год, может у них СХД архивный сгорел к чертям и они потеряли данные по текстам до 2007 года… Гораздо наглядней был бы пример ХОТЯБЫ 2015 года, а ещё лучше — 2018-го.
И в третьих… поисковики не любят индивидуальный подход, они не могут самостоятельно искать документы или статьи где-то там на каком-то архиве каждый раз когда кто-то ищет похожий документ… на это никаких вычислительных мощностей не хватит. Поэтому приводить аргументы вроде «вот же он тут есть мой документ, почему поисковик посмотреть не может?» не имеет никакого смысла. Какой-то там веб-архив… у яндекса свои хранилища есть, более доверенные. Пофиг что они поломались и т.д. это не повод поисковику доверять внешним хранилищам, иначе будут массовые манипуляции.asdoc Автор
21.11.2018 16:49-1Вот и я думаю, что «СХД архивный сгорел». И, похоже, году в 2012-м.
Второй Ваш абзац очень важен! Речь именно о мощностях!
Если бы Яндекс не тратил мощности на дубли, копипаст и мусор, то остались бы мощности на более полезные функции.
Я как раз об этом.
Один раз — восстановить то, что «сгорело».
Один раз индексировать новый текст.
Выкидывать из индексации повторные тексты.
Но начать нужно как раз с определения верной датировки.
(вебархивом не поманипулируешь :) )
Vsevo10d
21.11.2018 16:07Просто пишите интересные и оригинальные статьи на хорошо посещаемых сайтах. Вот например по запросу «патологическая наука» моя статья на Хабре на первом месте и в Гугле, и в Яндексе. Я доволен :)
</режим самолюбования>asdoc Автор
21.11.2018 16:12-1Я предпочитаю писать на своем сайте :)
Привык уже за 20 лет…ky0
21.11.2018 16:26Ну так вы приведите пример из текущего века, а не прошлого. Со статьями 2010-х годов аналогичная ситуация?
asdoc Автор
21.11.2018 16:44А давайте сначала разберемся со старыми текстами. От того, что текст 1998 года сворован в 2015 и находится в выдаче выше, текст-то не изменился.
Не нужно «замыливать» тему.
Я отвечу, что в 2010 тоже, Вы спросите про 2015-й и т.д.
В тоже время, решать проблему датировки «старых» текстов проще, чем новых. Поэтому начать нужно именно с них.
Пока эта проблема будет решаться, решится автоматически вопрос с текстами 2010 года или накопится достаточная статистика.ky0
21.11.2018 16:50Окей, давайте разберёмся. Хорошо, что у Яндекса есть разел обратной связи. Вы, разумеется, уже воспользовались им? Что они вам ответили?
slavait
21.11.2018 16:14+1Не только хорошо посещаемые сайты должны быть в поиске.
Уже давно заметил, ищу в яндексе и когда в нем ничего нет, то ищу в гугле и надо же вероятность найти в гугле быстрее и полезнее куда больше.
Но в большинстве своем люди ищут мусор и в яндексе его полно, поэтому и пользуемся яндексом.
А если это правда, что заявляет автор стать и яндекс не способен определить первоисточник, то выгоднее не создавать материал, а его копипастить и дублировать на сотнях сайтах. И выручка будет больше чем у автора. Автор вымрет от голода, а помойки только увеличатся.
Личное дело яндекса как ему поступить, но а пользователи проголосуют в соответствии со своим пониманием и интересом.
cooladmin
21.11.2018 16:14+2Подскажите, а вы знаете способ, как можно вычислить дату какой либо публикации или её части, не сохраняя всю публикацию (и все её версии) на своих серверах? Этот способ поддерживает изменения оригинала, т.е. отслеживает версии публикации? Этот способ позволяет отследить\справляется с ситуацией копирования из нескольких источников?
Подскажите, а есть примеры когда гугл с этой задачей справляется?
asdoc Автор
21.11.2018 16:36Прекрасный комментарий! Буду рад, если специалисты Яндекса его прочитают.
proton17
21.11.2018 16:21+1Хоть это и не принципиально, но я так понял речь о сайте med2000.ru? Вообще судя по Вашим остальным публикациям у вас к Я личная неприязнь?))
asdoc Автор
21.11.2018 16:35Нет. У меня нет личной неприязни к Яндексу.
До 2010 года Яндекс, на мой взгляд, искал лучше Гуугла.
Скорее «мне за Державу обидно».
Но переписка с «Платоном» была эффективна, м.б. году в 2003. А последние несколько лет она совершенно бесполезна. Хотя, конечно, я сначала пишу в поддержку, потом жду реакции… Потом не остается иного выхода.
dernasherbrezon
21.11.2018 16:25+2Посмотрите статьи этого автора. Сейчас их всего 3. И все они про одно и то же:
- Выпадение страниц из выдачи Яндекс-поиска
- Яндекс поощряет копипаст. Или почему упал Яндекс?
- Почему выдача в Яндексе не релевантная
Выходят примерно раз в год. Выглядит очень подозрительно.
asdoc Автор
21.11.2018 16:32В чем подозрительность?
Когда у меня формулируется текст, тогда я его публикую.
Тексты на другие темы я публикую в других местах.
Когда я публикую текст здесь, то получаю отзывы и комментарии, в т.ч. от сотрудников Яндекса.
Потом делаю новый эксперимент и нахожу новую причину и ошибку (свою или Яндекса).
Потом нужно подождать результат.
На это требуется время.
tvr
21.11.2018 16:35Выходят примерно раз в год. Выглядит очень подозрительно.
"Понимаете, каждый год 31 декабря мы с друзьями ходим в баню. Это у нас такая традиция…"
vitykut
21.11.2018 16:36А сам сайт менялся с 1998 года? а то, может, он выглядит так, что оригинальные статьи и не спасут
asdoc Автор
21.11.2018 16:39Конечно. И сейчас меняется, т.е. дополняется новыми оригинальными текстами. Но URL размещенного текста не менялся ни разу. Ни у одного текста.
А сайт, разумеется, начинался с десятка текстов. Сейчас текстов тысячи.
И в техническом плане сайт сейчас идеален с точки зрения рекомендаций поисковиков, дизайна, рекламной нагрузки и пр.
Lordbl4
21.11.2018 16:51Как я перестал пользоваться поиском от яндекс:
По долгу работы приходилось искать драйверы на разные модели %девайснеймов%, и, как человеку ленивому, мне зачастую было проще и быстрее набрать в поисковой системе %девайснейм% и волшебное слово "drivers". Кто сталкивался, тот знает, что сходу разобраться на сайте производителя %девайснейма% не так уж и просто и требуется некоторое количество кликов мышью, но зачем наступать на одни и те же грабли, если за вас это сделает грамотный и продуманный поисковый индекс?
И тут самое интересное — результаты поисковика от Г-компании с вероятностью в 99% в первых вариантах вели на необходимую страницу официального сайта производителя %девайснейма%, на которой в пару кликов скачивался нужный драйвер или программа.
Яндекс же, в свою очередь, в первых 10-ти результатах во всю предлагал мне купить вышеупомянутый %девайснейм% по самой выгодной цене и «бла бла бла». Следующие результаты вели на сторонние сайты с архивами драйверов (ака скачать без регистрации и смс, введи капчу, ещё раз капчу, подтверди что ты не робот, подожди 59 секунд и т.д.). И только спустя кучу ненужной маркетинговой выдачи можно было найти ссылку на сайт производителя, но опять же — увы, на его главную страницу.
Если сейчас всё изменилось и поисковая выдача приводит на нужные сайты, как у поисковика от Г-компании, то я скорее рад, но осадок остался, поэтому я использую не-яндекс.
''Хочу помочь советом'' или ''Вы всё врёти'' ?Желающие оптимизировать советом в стиле «есть же драйверпаки» «скинь все драйвера на флешку и так далее» — спасибо вам, но это не относится к поисковой выдаче. А тем, кто уже бежит проверять, правдива ли моя история и так ли всё плохо с выдачей у яндекса — рекомендую к приобретению ДеЛориан или хотя бы Тардис, дальше — прыгайте на 6 лет назад и проверяйте, сколько хотите.Slavik_Kenny
21.11.2018 16:56А почему Вы считаете, что старые тексты должны в выдаче стоять выше?
Я не говорю что вы не правы, просто если я ищу какой-то материал (тем более технический), то меня интересует что-то посвежее, чем статьи 20-ти летней давности…
И разве я один такой, кто не хочет на первых местах поиска видеть самые старые публикации на искомую тему?
Может оригинальная статья была дополнена, были по ней расписаны какие-то изменения в связи с прошедшим временем? А может даже в более новой публикации и источник укажут — это никак не повлияет на место в выдаче, так почему давность должна в выдаче материал ставить выше?
Hardcoin
Нет. Подмена понятий не делает вашу позицию сильнее, а наоборот ослабляет её.
Копировать ваш текст без ссылки на оригинал — не хорошо. Однако обвинение Яндекса в том, что там работают "фальшивые математики" к делу не относится. Какие плохие, а ну давайте делайте, а то совсем все к Гуглу уйдут — как-то не серьезно, извините.
asdoc Автор
Мне кажется, что это как раз Вы «подменили понятия».
Определить возраст публикации не так уж сложно.
Я не писал «фальшивые математики», а Вы это закавычили как цитату.
Яндекс многократно заявлял, что будет пессимизировать не оригинальный контент. По факту — пессимизирует как раз оригинальный.
Причина — Яндекс не может понять, где оригинал, а где копия, поскольку не может определить дату публикации.