
 В начале года мы решили научиться хранить и читать отладочные логи ВКонтакте более эффективно, чем раньше. Отладочные логи — это, к примеру, логи конвертации видео (в основном вывод команды ffmpeg и список шагов по предварительной обработке файлов), которые иногда бывают нам нужны лишь спустя 2-3 месяца после обработки проблемного файла.
В начале года мы решили научиться хранить и читать отладочные логи ВКонтакте более эффективно, чем раньше. Отладочные логи — это, к примеру, логи конвертации видео (в основном вывод команды ffmpeg и список шагов по предварительной обработке файлов), которые иногда бывают нам нужны лишь спустя 2-3 месяца после обработки проблемного файла.На тот момент у нас было 2 способа хранения и обработки логов — наш собственный logs engine и rsyslog, которые мы использовали параллельно. Стали рассматривать другие варианты и поняли, что нам вполне подходит ClickHouse от Яндекса — решили его внедрять.
В этой статье я расскажу о том, как мы начали использовать ClickHouse ВКонтакте, на какие грабли при этом наступили, и что такое KittenHouse и LightHouse. Оба продукта выложены в open-source, ссылки в конце статьи.
Задача сбора логов
Требования к системе:
- Хранение сотен терабайт логов.
- Хранение месяцами или (редко) годами.
- Высокая скорость записи.
- Высокая скорость чтения (чтение происходит редко).
- Поддержка индексов.
- Поддержка длинных строк (>4 Кб).
- Простота эксплуатации.
- Компактное хранение.
- Возможность вставки с десятков тысяч серверов (UDP будет плюсом).
Возможные решения
Давайте вкратце перечислим варианты, которые мы рассматривали, и их минусы:
Logs Engine
Наш самописный микросервис для логов.
– Умеет отдавать только последние N строк, которые помещаются в RAM.
– Не очень компактное хранение (нет прозрачного сжатия).
Hadoop
– Не во всех форматах есть индексы.
– Скорость чтения могла быть и выше (зависит от формата).
– Сложность настройки.
– Нет возможности вставки с десятков тысяч серверов (нужна Kafka или аналоги).
Rsyslog + файлы
– Нет индексов.
– Низкая скорость чтения (обычный grep/zgrep).
– Архитектурно не поддерживаются строки >4 Кб, по UDP ещё меньше (1,5 Кб).
± Компактное хранение достигается путем logrotate по крону
Мы использовали rsyslog как запасной вариант для долговременного хранения, но длинные строки обрезались, поэтому его сложно назвать идеальным.
LSD + файлы
– Нет индексов.Отличия от rsyslog в нашем случае в том, что LSD поддерживает длинные строки, но для вставки с десятков тысяч серверов требуются существенные доработки внутреннего протокола, хотя это и можно сделать.
– Низкая скорость чтения (обычный grep/zgrep).
– Не особо расчитан на вставку с десятков тысяч серверов.
± Компактное хранение достигается путем logrotate по крону.
ElasticSearch
– Проблемы с эксплуатацией.ELK стек является уже почти промышленным стандартом для хранения логов. По нашему опыту — всё хорошо со скоростью чтения, а вот с записью бывают проблемы, например, во время слияния индексов.
– Нестабильная запись.
– Нет UDP.
– Плохое сжатие.
ElasticSearch прежде всего предназначен для полнотекстового поиска и относительно частых запросов на чтение. Нам же важнее стабильная запись и возможность более-менее быстро прочитать наши данные, причём по точному совпадению. Индекс у ElasticSearch заточен под полнотекстовый поиск, и занимаемый объём на диске довольно велик по сравнению с gzip оригинального содержимого.
ClickHouse
— Нет UDP.
По большому счёту, единственное, что нас не устраивало в ClickHouse — отсутствие общения по UDP. По факту, из перечисленных вариантов оно было только у rsyslog, но при этом rsyslog не поддерживал длинные строки.
По остальным критериям ClickHouse нам подошел, и мы решили использовать его, а проблемы с транспортом решить в процессе.
Зачем нужен KittenHouse
Как Вы, наверное, знаете, ВКонтакте работает на PHP/KPHP, с «движками» (микросервисами) на C/C++ и немножко на Go. У PHP нет концепции «состояния» между запросами, кроме, возможно, общей памяти и открытых соединений.
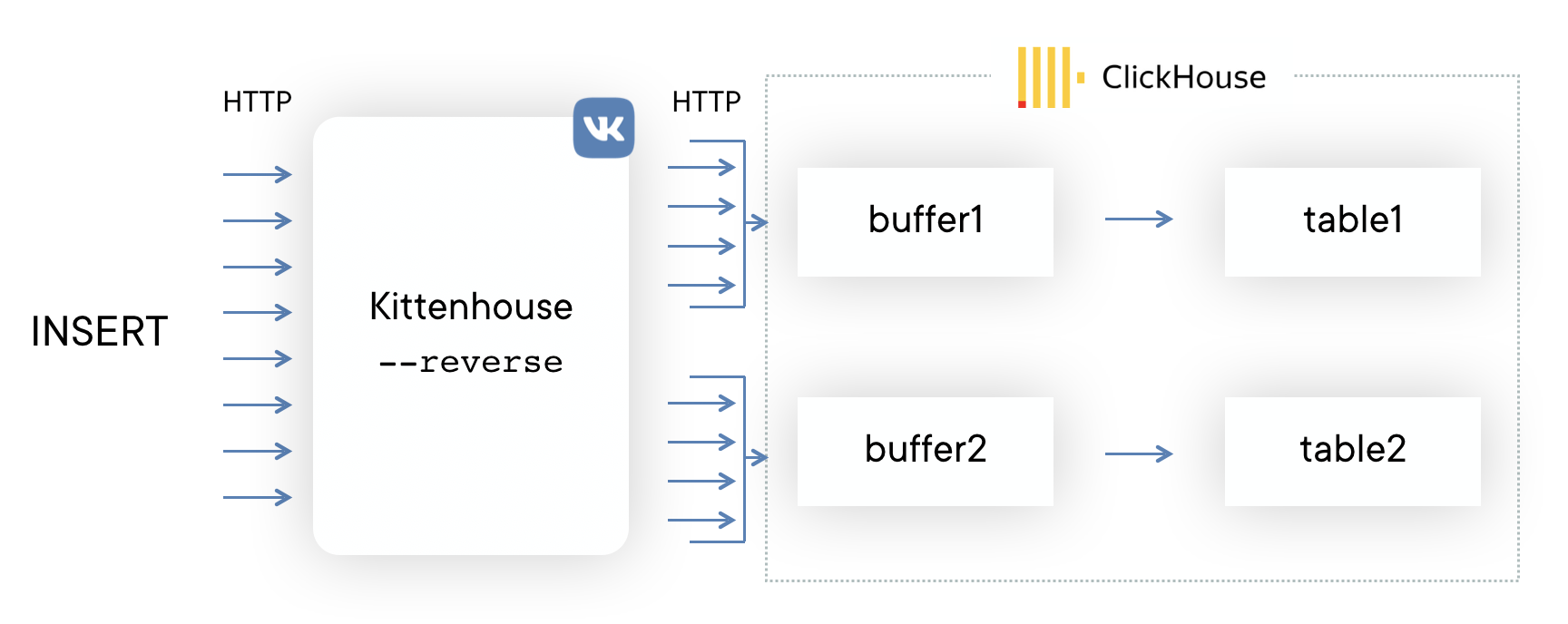
Поскольку у нас десятки тысяч серверов, с которых мы хотим иметь возможность отправлять логи в ClickHouse, держать открытым соединения из каждого PHP-worker'а было бы накладно (на каждый сервер может приходиться по 100+ воркеров). Поэтому нам нужен какой-то прокси между ClickHouse и PHP. Мы назвали этот прокси KittenHouse.
KittenHouse, v1
Сначала решили попробовать как можно более простую схему, чтобы понять, будет наш подход работать или нет. Если Вам на ум при решении этой задачи приходит Kafka, то Вы не одиноки. Мы, однако, не хотели использовать дополнительные промежуточные сервера — в этом случае можно было легко упереться в производительность этих серверов, а не самого ClickHouse. К тому же, мы собирали логи и нам нужна была предсказуемая и небольшая задержка вставки данных. Схема выглядит следующим образом:

На каждом из серверов ставится наш локальный прокси (kittenhouse), и каждый инстанс держит строго одно HTTP-соединение с нужным ClickHouse-сервером. Вставка осуществляется в буферные таблицы, поскольку в MergeTree часто вставлять не рекомендуется.
Возможности KittenHouse, v1
Первая версия KittenHouse умела довольно мало, однако для тестов этого было достаточно:
- Общение через наш RPC (TL Scheme).
- Поддержание 1 TCP/IP соединения на сервер.
- Буферизация в памяти по умолчанию, с ограниченным размером буфера (остальное выбрасывается).
- Возможность записи на диск, в этом случае есть гарантия доставки (не менее одного раза).
- Интервал вставки — раз в 2 секунды.
Первые проблемы
С первой проблемой мы столкнулись, когда «погасили» ClickHouse сервер на несколько часов и потом включили обратно. Ниже можно видеть load average на сервере после того, как он «поднялся»:
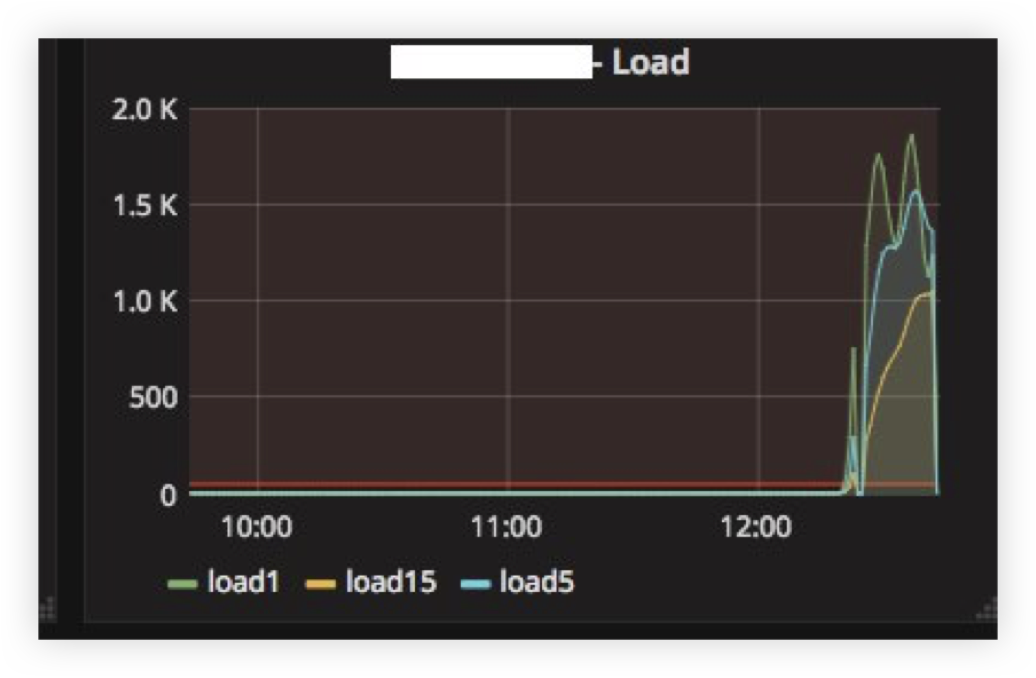
Объясняется это довольно просто: у ClickHouse модель работы по сети — thread per connection, поэтому при попытке сделать INSERT с тысячи узлов одновременно, началась очень сильная конкуренция за ресурсы CPU и сервер еле отвечал. Тем не менее, все данные в конечном счёте вставились и ничего не упало.
Для решения этой проблемы мы поставили nginx перед ClickHouse и, в целом, это помогло.
Дальнейшее развитие
В процессе эксплуатации столкнулись ещё с некоторым количеством проблем, в основном связанных не с ClickHouse, а с нашим способом его эксплуатации. Вот ещё грабли, на которые мы наступили:
Большое количество «кусков» у Buffer таблиц приводит к частым сбросам буфера в MergeTree
В нашем случае было 16 кусков буфера и интервал сброса раз в 2 секунды, а таблиц 20 штук, что давало до 160 вставок в секунду. Это периодически очень плохо сказывалось на производительности вставки — появлялось много фоновых слияний и утилизация дисков достигала 80% и выше.
Решение: увеличили интервал сброса буфера по умолчанию, уменьшили число кусков до 2.
Nginx отдает 502, когда заканчиваются соединения с upstream
Само по себе это не является проблемой, но в сочетании с частым сбросом буфера это давало достаточно высокий фон 502 ошибок при попытке вставки в любую из таблиц, а также при попытке выполнить SELECT.
Решение: написали свою reverse proxy с использованием библиотеки fasthttp, которая группирует вставку по таблицам и очень экономно расходует соединения. Также она различает SELECT и INSERT и имеет раздельные пулы соединений для вставки и для чтения.
Начала заканчиваться память при интенсивной вставке
У библиотеки fasthttp есть свои достоинства и недостатки. Один из недостатков — то, что запрос и ответ полностью буферизуются в памяти перед тем, как отдать управление обработчику запроса. У нас это выливалось в то, что если вставка в ClickHouse «не успевала», то буферы начинали расти и в конечном итоге заканчивалась вся память на сервере, что приводило к убийству reverse proxy по OOM. Коллеги нарисовали демотиватор:

Решение: патчинг fasthttp для поддержки стриминга тела POST-запроса оказался непростой задачей, поэтому решили использовать Hijack() соединения и апгрейдить соединение на свой протокол, если пришел запрос с HTTP-методом KITTEN. Поскольку сервер должен ответить MEOW в ответ, если понимает этот протокол, вся схема называется протоколом KITTEN/MEOW.
Мы читаем только из 50 случайных соединений одновременно, поэтому, благодаря TCP/IP, остальные клиенты «ждут» и мы не расходуем память на буферы, пока до соответствующих клиентов не дошла очередь. Это сократило потребление памяти минимум в 20 раз, и больше подобных проблем у нас не было.
ALTER таблиц может идти долго, если есть долгие запросы
У ClickHouse неблокирующий ALTER — в том смысле, что он не мешает выполняться как SELECT-запросам, так и INSERT-запросам. Но ALTER не может начаться, пока не закончили исполняться запросы в эту таблицу, отправленные до ALTER.
Если у вас на сервере есть фон «долгих» запросов в какие-нибудь таблицы, то вы можете столкнуться с ситуацией, что ALTER на эту таблицу не будет успевать выполняться за дефолтный таймаут в 60 секунд. Но это не значит, что ALTER не пройдет: он выполнится, как только закончат выполняться те самые SELECT-запросы.
Это означает, что вы не знаете, в какой на самом деле момент времени произошел ALTER, и у вас нет возможности автоматически пересоздать Buffer-таблицы, чтобы их схема всегда была одинаковой. Это может приводить к проблемам при вставке.


Решение: Планируем в итоге полностью отказаться от использования буферных таблиц. В целом, у буферных таблиц есть сфера применения, мы пока используем их и не испытываем огромных проблем. Но сейчас мы наконец дошли до момента, когда проще реализовать функциональность буферных таблиц на стороне reverse proxy, чем продолжать мириться с их недостатками. Примерная схема будет выглядеть вот так (пунктирной линией показана асинхронность ACK на INSERT).

Чтение данных
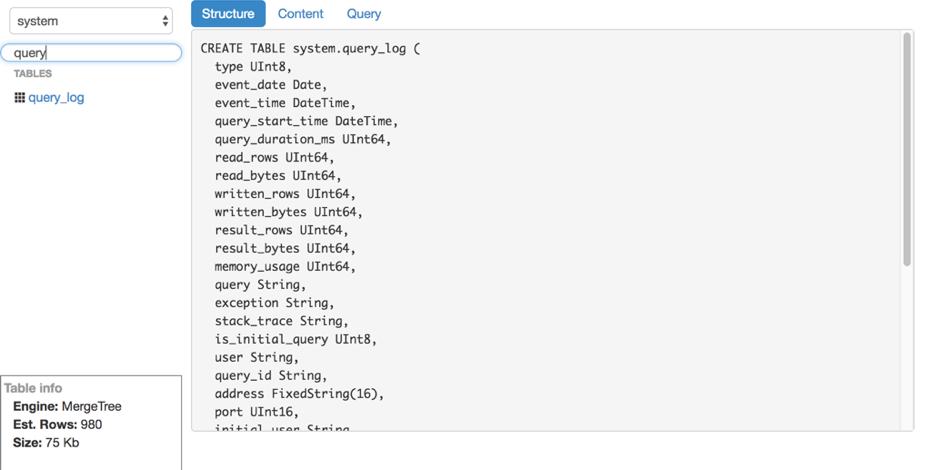
Допустим, мы разобрались со вставкой. Как читать эти логи из ClickHouse? К нашему сожалению, удобных и простых в эксплуатации инструментов для чтения сырых данных (без построения графиков и прочего) из ClickHouse мы не нашли, поэтому написали своё решение — LightHouse. Его возможности довольно скромные:
- Быстрый просмотр содержимого таблиц.
- Фильтрация, сортировка.
- Редактирование SQL-запроса.
- Просмотр структуры таблицы.
- Показ примерного количества строк и занимаемого на диске места.
Однако, LightHouse быстрый и умеет делать то, что нужно именно нам. Вот пара скриншотов:
Просмотр структуры таблицы
Фильтрация содержимого

Результаты
ClickHouse — практически единственная open-source база данных, которая «прижилась» ВКонтакте. Мы довольны скоростью её работы и готовы мириться с недостатками, о которых ниже.
Сложности в работе
В целом, ClickHouse — очень стабильная база данных и очень быстрая. Однако, как и с любым продуктом, особенно таким молодым, есть особенности в работе, которые нужно учитывать:
- Не все версии одинаково стабильны: не обновляйтесь на продакшене сразу на новую версию, лучше подождать несколько bugfix-релизов.
- Для оптимальной производительности крайне желательно настраивать RAID и некоторые другие вещи согласно инструкциям. Об этом недавно был доклад на highload.
- Репликация не имеет встроенных ограничений по скорости и может вызывать существенную деградацию производительности сервера, если её не ограничивать самим (но это обещают исправить).
- В Linux есть неприятная особенность механизма работы виртуальной памяти: если вы активно пишете на диск и данные не успевают сбрасываться, в какой-то момент сервер полностью «уходит в себя», начинает активно сбрасывать page cache на диск и практически полностью блокирует процесс ClickHouse. Это иногда происходит при больших мержах, и за этим нужно следить, например периодически сбрасывать буферы самим или делать sync.
Open-source
KittenHouse и LightHouse теперь доступны в open-source в нашем github-репозитории:
- KittenHouse: github.com/vkcom/kittenhouse
- LightHouse: github.com/vkcom/lighthouse
Спасибо!
Юрий Насретдинов, разработчик в отделе backend-инфраструктуры ВКонтакте
Комментарии (47)

f4llou7
22.11.2018 21:40К нашему сожалению, удобных и простых в эксплуатации инструментов для чтения сырых данных
А чем не устроил JDBС драйвер и скажем DataGrip? Пробовал эту схему, все хорошо отображается и работает.youROCK Автор
22.11.2018 21:41В целом, это неплохой вариант, но на тот момент DataGrip не поддерживал ClickHouse :). К тому же, всё-таки есть некоторые шероховатости с его работой, плюс он платный. LightHouse также не нуждается в установке и настройке, что во многих случаях тоже оказывается очень удобным.
moscas
23.11.2018 10:37Если расскажете про шероховатости, мы с радостью их поправим :)
FranciscoSuarez
23.11.2018 21:25+11. Возможно, много хочу, но экспериментальные фичи типа LowCardinality (String), чтобы не обрабатывались как or DEFAULT expected, got '('.
Вся консоль красная в итоге, — у меня очень много полей таких.
2. Nested( структуры плохо форматируются…
Наверное, логично было бы сделать вложенность какую-то.
3. Мой основной паттерн работы — это работа на кластере и мне совершенно неважно, какие там машины в кластере — то есть важно, но редко. То есть сейчас у меня 10 машин слева в списке вида ch******. А когда их будет 40? Кластер про шардирование и репликацию, а не про раздельное хранение разных данных.
В связи с этим меняется немного логика работы, — уже было бы приятно вести проект, иметь какой-то Project Explorer — Database Consoles всё же опять про то, что есть много серверов с разными таблицами, а не про 50 тачек в кластере, на которых просто создаются таблицы, альтерятся одновременно и т.д.
4. Говоря про ClickHouse, хотелось бы видеть всякие условные замеры размеров колонок, коэффициентов сжатия, — да и всей таблицы в целом. Да и опять же видеть это всё на кластере… Раз уж я вбил все сервера, то такая сущность как cluster, которая бы объединяла в себе эти сервера была бы удобна очень. До банального «запустить на кластере». Сейчас для того же «SET allow_experimental_low_cardinality_type = 1;» я выбираю галочками все машины (хорошо, что 1 раз).
P.S.
1. Чуток подтормаживает на запросах — потому я использую DataGrip скорее как некоторый «проект» для администрирования, чем как инструмент для работы с данными
2. В связи с этим или LightHouse или консоль — они быстрые, — там я и стараюсь крутить-вертеть данные.
3. Но если резюмировать, я в целом наслаждаюсь работой с DataGrip — это на мой вкус такой промежуточный вариант между какой-то полноценной средой для разработчика и консолью. Пользуюсь, лицензию купили :)
v_m_smith
23.11.2018 22:09А Dbeaver рассматривали?
Бесплатен и поддерживает Clickhouse почти с момента появления.youROCK Автор
23.11.2018 22:26Не рассматривали, но установил для интереса. Не сказать, чтобы Dbeaver был прямо таким уж легким и быстрым, но при некотором желании пользоваться можно :). Не нашел, как там увидеть размер таблицы и количество строк в ней, для нас это важно. Может быть, где-нибудь все-таки это показывается.
v_m_smith
24.11.2018 23:30количество строк есть в Prop / Statistics github.com/dbeaver/dbeaver/wiki/Clickhouse
А вот размер в *б — не знаю как
neenik
22.11.2018 22:331. Почему не loghouse?
2. Как ищите по логам без ключевых полей (ip/id пользователя/что-то ещё)?
3. Какой объём данных в день и количество шардов, если не закрытая информация?
4. Если используете rsyslog, то почему не его протокол для приёма логов?youROCK Автор
22.11.2018 22:38> 1. Почему не loghouse?
Пока что не используем Kubernetes
> 2. Как ищите по логам без ключевых полей (ip/id пользователя/что-то ещё)?
Обычно у нас структурированные логи, в которых все поля есть. Если их все же нет, то либо LIKE '%что-то%', либо с помощью visitParam* функций (так называются функции по работе с JSON в ClickHouse)
> 3. Какой объём данных в день и количество шардов, если не закрытая информация?
Любая информация, которую бы я привел, стала бы неактуальной очень быстро :). Конкретно видео логи занимают 1 шард (2 сервера), а всего хостов с ClickHouse несколько десятков, но эта цифра очень быстро растет.neenik
22.11.2018 22:501. Loghouse и просто в виде контейнера запускается.
2. То есть, у вас в строках, в полях message/content — json? И скорость работы поиска в таком случае устраивает?
3. Я больше спрашивал про дневной объём логов в гигабайтах, если не секрет (в сжатом виде в папке КХ)?
И мне кажется, что у вас не так много логов, если вы не натыкались на:
1. Нехватку памяти при работе с одной таблицей. У loghouse отдельные именно таблицы подневные/почасовые.
2. Медленным поиском по строкам. У loghouse кривоватый подход, но иначе в КХ и не получится. И в итоге данные можно заливать в уже структурированном виде. И поиск будет получше.youROCK Автор
22.11.2018 23:04> 1. Loghouse и просто в виде контейнера запускается.
Возможно, я что-то неправильно понял в описании loghouse. У меня сложилось впечатление, что он заточен под kubernetes, которого у нас нет, соответственно для нас это не преимущество, а огромный недостаток. Если можно запустить отдельно в контейнере, то это хорошо.
> 2. То есть, у вас в строках, в полях message/content — json? И скорость работы поиска в таком случае устраивает?
Как я уже сказал, у нас структурированные логи и как правило мы ищем по конкретным полям, а не по строке. Если нам все-таки нужен поиск по строке, то производительность обычно устраивает :).
> 3. Я больше спрашивал про дневной объём логов в гигабайтах, если не секрет (в сжатом виде в папке КХ)?
Порядка 60-70 Гб в сутки, если речь про видео логи. При этом, нам часто нужно смотреть эти логи хотя бы за месяц, так что объем просматриваемых данных уже измеряется терабайтами :).
> 1. Нехватку памяти при работе с одной таблицей. У loghouse отдельные именно таблицы подневные/почасовые.
Неясно, откуда она должна возникнуть. У нас есть таблицы на 10-15 Тб и нам хватает памяти :).
> 2. Медленным поиском по строкам. У loghouse кривоватый подход, но иначе в КХ и не получится. И в итоге данные можно заливать в уже структурированном виде. И поиск будет получше.
Мы заливаем структурированные логи, так что такой проблемы не возникает.neenik
24.11.2018 02:09Спасибо. Да, логов у вас достаточно большой объём. Вероятно, фронтент логхауса что-то не то делает при выборках — из-за этого нам пришлось перейти с дневных партиций на почасовые.
DIegoR
23.11.2018 00:48Как-то это все странно выглядит вместе: текстовые файлы, http, мерджи, reverse proxy, буферизация. А почему не дать всем писать все напрямую в файлопомойку хадуп? А потом асинхронно, без суеты, но производительно, не перекладывать оттуда куда уже удобно?
Где у вас узкое место, ведь не в записи на диск же?
Вот тема с load average: если у вас много network latency — так это же хорошо, что load average большой — процессы сидят и ждут своего медленного сетевого io. Расшивают вам узкое место — сеть. Чем этих процессов «на подхвате» больше — тем больше bulk io и соответственно disk io. Ну конечно есть свои границы, но их нужно смотреть экспериментально. Тысячу-две процессов на машине с десятками ядер — это нормально.
blind_oracle
23.11.2018 11:48Хадуп — это не быстро. Совсем. Аналитические колоночные БД вроде ClickHouse или Vertica в большинстве случаев быстрее на порядки
DIegoR
23.11.2018 12:02все напрямую в файлопомойку хадуп? А потом асинхронно, без суеты, но производительно, не перекладывать оттуда куда уже удобно?
вот — «куда угодно» это и было бы ClickHouse или Vertica
6ec_uk
23.11.2018 01:10Сhproxy рассматривали? Судя по докладу на HL, у вас получился аналог.
youROCK Автор
23.11.2018 22:49Рассматривали, но лично у меня сложилось впечатление, что chproxy больше предназначен для роутинга SELECT запросов и просто как прокси к ClickHouse (что следует из названия, в принципе :)). Цель же kittenhouse немного другая: он занимается агрегацией вставки (причём как на стороне отправителя, так и на стороне получателя — во втором случае это kittenhouse --reverse). То, что kittenhouse ещё умеет выполнять и SELECT-запросы — это не его главная функциональность. В теории, вы можете использовать kittenhouse и chproxy вместе, хотя мы так не делаем.
kkirsanov2
23.11.2018 06:49Скажите, а почему вам так критично наличие UDP?
Мне сейчас Кафка кажется оптимальным вариантом — масштабируется почти под любой объем записи и далее разгребаем в удобном темпе и масштабе.youROCK Автор
23.11.2018 10:22UDP позволяет не устанавливать соединения и просто слать запросы вне зависимости от количества клиентов (иначе бы пришлось устанавливать 100 воркеров * 10к хостов = 1 млн соединений, причем воркеры живут ограниченное время, так что соединения пришлось бы ещё постоянно переоткрывать).
Касаясь кафки, тут несколько важных соображений
- Из каждого воркера вставку по 1 записи кафка в любом случае не потянет, значит нужен прокси
- Некоторые логи мы хотим доставлять надёжно, даже если с кафкой проблемы, значит нам надо уметь писать на локальный диск машины
- Нет уверенности, не будет ли точно таких же проблем с потреблением памяти у кафки, если в нее пишут быстрее, чем она успевает писать на диск (кажется, что будут, если соединений десятки тысяч).
- Нам не очень удобен формат записи JSONEachRow или любой другой формат, в котором имело бы смысл писать в кафку (где нет понятия структуры таблицы)
- В чатик телеграма на момент принятия решения поступало много жалоб на реализацию Kafka engine в ClickHouse, что тоже не добавляло желания ее использовать
- У меня нет опыта работы с кафкой и это ещё одна точка отказа в цепочке, причем по которой лично у меня нет никакой экспертизы и нет никакого желания в ней разбираться и поддерживать ее работу
- Не все логи нам нужно доставлять надёжно. Большинство лучше наоборот дропать, если поток вставки в эту таблицу слишком большой (типичный пример – ошибки PHP или JS, начиная с некоторого объема нам уже не нужно больше писать в секунду :)). В системе с кафкой такого варианта не будет.
- Кафка удобна, если мы хотим делать какую-то батчевую обработку записей перед тем, как вставить их в ClickHouse, но у нас логи и мы их никак предварительно не обрабатываем, так что этого преимущества кафки тоже нет.
- Некоторых событий так много, что если хранить их в кафке всего одни сутки, места нам не хватит, или нужно будет добавить ещё примерно столько же серверов, сколько у нас сейчас выделено под ClickHouse, что звучит неразумно. (В ClickHouse эти данные занимают меньше благодаря сжатию и/или агрегации).
kkirsanov2
23.11.2018 11:32А бывает так что из за отсутствия подтверждения в UDP вы теряете нужный лог и потом его приходится искать в других местах?
youROCK Автор
23.11.2018 11:56Наш внутренний RPC протокол основан на UDP, но умеет осуществлять перепосылку пакетов и умеет присылать подтверждения. Но поскольку ClickHouse не поддерживает UDP и нам иногда нужна надёжная доставка, при общении с ClickHouse мы используем только TCP и в нашем случае нам этого хватает. Но Kittenhouse поддерживает UDP в дополнение к TCP, и мы используем это при посылке логов из "труднодоступных" мест вроде nginx модулей. В этом случае у нас нет гарантии доставки.
kkirsanov2
23.11.2018 11:543 Нет уверенности, не будет ли точно таких же проблем с потреблением памяти у кафки, если в нее пишут быстрее, чем она успевает писать на диск
9 Некоторых событий так много, что если хранить их в кафке всего одни сутки, места нам не хватит,Я что то не могу найти ваши объемы, интересно сколько у вас в день логов и сколько занимает база в CH?
youROCK Автор
23.11.2018 12:04Входящий поток иногда может достигать нескольких гигабит/сек на одну машину. Это происходит редко, но когда происходит, мы должны эту нагрузку держать и не падать :). Про объемы написано в постановке задачи: нам иногда требуется хранить сотни терабайт.
kkirsanov2
23.11.2018 12:28>нескольких гигабит/сек на одну машину.
Судя по всем тестам что я читал и личному оптыту это штатная ситуация для весьма скромных инсталляций кафки. Вот например events.static.linuxfound.org/sites/events/files/slides/HTKafka2.pdf
Там и бюджетный вариант и дорогой :)blind_oracle
23.11.2018 17:31Кафка, в общем случае, упирается в производительность последовательной записи на диск. А несколько гигабит\сек это одна Consumer-Grade SSD либо RAID-массив из пары дисков.
kkirsanov2
23.11.2018 18:20>одна Consumer-Grade SSD либо RAID-массив из пары дисков.
Я и говорю — весьма скромных инсталляций кафки.
C одной стороны стони терабайт логов (и видимо тысячи серверов генерирующих их), а с дрогой нет ресурсов на лишний брокер кафки и одновременно с этим есть ресурсы на разработку и внедрения своего буфера перед CH.
blind_oracle
23.11.2018 18:49Ну они все равно хотят UDP, в который Кафка не умеет и прочие фишки вроде локального кеширования, поэтому какую-то прослойку все равно писать бы пришлось.
dovg
23.11.2018 18:43>Из каждого воркера вставку по 1 записи кафка в любом случае не потянет, значит нужен прокси
Кафка из коробки умеет в батч (max.request.size, ...ms)
>Некоторые логи мы хотим доставлять надёжно, даже если с кафкой проблемы, значит нам надо уметь писать на локальный диск машины
Кафка из коробки умеет в кластер
>Нет уверенности, не будет ли точно таких же проблем с потреблением памяти у кафки, если в нее пишут быстрее, чем она успевает писать на диск (кажется, что будут, если соединений десятки тысяч).
Вопрос не в количестве соединений, а в общем размере сообщений.
>Нам не очень удобен формат записи JSONEachRow или любой другой формат, в котором имело бы смысл писать в кафку (где нет понятия структуры таблицы)
В кафку можно писать все, что угодно. Типизацию можно сделать в продьюсере и консьюмере
>В чатик телеграма на момент принятия решения поступало много жалоб на реализацию Kafka engine в ClickHouse, что тоже не добавляло желания ее использовать
После кафки можно/нужно поставить прокси
Еще в кафке есть дефлейт из коробки.youROCK Автор
23.11.2018 19:29> Кафка из коробки умеет в батч (max.request.size, ...ms)
Это же настройка клиента на Java? У нас запросы обрабатываются в PHP. В PHP нет общего состояния между запросами, поэтому и батчить на стороне PHP не получится.
> Кафка из коробки умеет в кластер
Кластер решает лишь часть проблем. Например, мы можем в какой-то момент начать слать слишком много логов, и без записи на локальный диск мы можем в этом случае терять данные. Плюс бывают (редко) проблемы с сетью или фаерволами. Также обслуживание кластера усложняется — нет возможности его потушить целиком на какое-то время и произвести работы.
> Вопрос не в количестве соединений, а в общем размере сообщений.
Я не тестировал кафку на предмет того, как она будет себя вести, если мы будем активно в неё писать с десятков тысяч TCP/IP соединений. У меня есть подозрение, что могут возникнуть проблемы. Возможно, я не прав.
> В кафку можно писать все, что угодно. Типизацию можно сделать в продьюсере и консьюмере
У нас задача вполне конкретная — доставить (структурированные) логи до ClickHouse. Тот факт, что в кафку можно писать в любом формате в нашем случае это не плюс. Насколько я понимаю, есть 2 формата, которые поддерживаются при записи в Kafka:
1. JSONEachRow, в котором нельзя передавать бинарные данные (нам это нужно) и есть существенный оверхед на имена колонок
2. Cap'n'Proto, который эти проблемы решает, но мы этот формат нигде не используем, и из PHP в таком формате писать неудобно.
Ни один из этих форматов для нас не удобен.
> Еще в кафке есть дефлейт из коробки.
Интересно.kkirsanov2
23.11.2018 20:50У нас запросы обрабатываются в PHP. В PHP нет общего состояния между запросами, поэтому и батчить на стороне PHP не получится.
Могу ошибаться, но в данном случае лучшая практик — из короткоживущих инстансов писать в stdout, а от туда собирать долгоживущим процессом и отправлять в ту же кафку.
Например, мы можем в какой-то момент начать слать слишком много логов,
Кафка прекрасно масштабируется и "слишком много" для неё скорее всего окажется также и "слишком много" для вообще любой системы. Астрономы, из ссылки что я давл ранее на 2-х машинах получают 1.3Gbps из 2 — 20 делаются довольно просто.
Также обслуживание кластера усложняется — нет возможности его потушить целиком на какое-то время и произвести работы.
А зачем тушить его целиком?Прописываете репликацию у топика например 3 и можете тушить на обслуживание или апгрейд 2 из 3 брокеров на которых будут жить данные.
У нас задача вполне конкретная — доставить (структурированные) логи до ClickHouse. Тот факт, что в кафку можно писать в любом формате в нашем случае это не плюс.
Но ведь кафка всего лишь транспорт. Вас же не смущает отправка через UDP байт, вот и через кафку не должна смущать.
Насколько я понимаю, есть 2 формата, которые поддерживаются при записи в Kafka:
Это не так. Кафка поддерживает байты.
Разные клиентские библиотеки кроме простых байт или строк ещё предлагает разные варианты сериализации. Например (https://www.confluent.io/ из коробки поддерживает AVRO со схемами. Там и разные варианты сжатия в комплекте есть. У нас, например, неделя жизни банка (правда маленького) умещается в 35 гигов в том же AVROyouROCK Автор
23.11.2018 20:59> Это не так. Кафка поддерживает байты.
Я имел в виду, какие форматы поддерживает ClickHouse, когда забирает данные из кафки. Я понимаю, что в саму кафку сообщения можно писать в любом виде.
dth_apostle
23.11.2018 15:37хотел спросить — Splunk совсем не рассматривали? В short-list'е не увидел.
youROCK Автор
23.11.2018 16:32Нет, не рассматривали :). Стоимость хранения сотен терабайт в splunk будет очень велика, насколько я понимаю, а также не очень понятно, насколько компактно он хранит данные. Как я описывал в требованиях, нам нужно прежде всего компактное хранение и большая скорость записи, а чтение довольно редкое и оно должно быть быстрым, но скорость ClickHouse нас устраивает.
recompileme
23.11.2018 17:28+1Можно вопрос по kittenhouse/go?
Разве блокировку на элемент надо ставить до снятия блокировки с контейнера? Код очень тяжело читается из-за этого — это оправдано?
github.com/VKCOM/kittenhouse/blob/f07cfa44a8d67bbfb7015fca1e459f7731ab27c0/core/inmem/buffer.go#L48
Как может появиться новый элемент вот тут? Читатели не блокирует друг друга, но писатель же блокирует читателей и эта ситуация невозможна или я заблуждаюсь?
github.com/VKCOM/kittenhouse/blob/f07cfa44a8d67bbfb7015fca1e459f7731ab27c0/core/inmem/buffer.go#L75
В целом. мне кажется проще и правильней было сделать так — писать напрямую в файл. При этом FS будет писать в буфер. В бэкграундтаске — раз в секунду или реже делать fsync — чтобы сбросить буфер на диск. А сейчас — вы по сути написали второй буфер — над файловой системой. Плюс я не смотрел код внимательно — но кажется синков -нет. Те вы пишете в буфер — потом в буфер файловой системы — во первых двойной буфер во вторых вы ничего не добились если не синкаете, разве нет? У меня очень похожая задача — массив файлов и запись в них — я решил ее напрямую и мне кажется так правильней: github.com/recoilme/pudge/blob/master/pudge.goyouROCK Автор
23.11.2018 19:46> Разве блокировку на элемент надо ставить до снятия блокировки с контейнера? Код очень тяжело читается из-за этого — это оправдано?
Да, потому что элемент удаляют из мапы вот тут:
github.com/VKCOM/kittenhouse/blob/f07cfa44a8d67bbfb7015fca1e459f7731ab27c0/core/inmem/flusher.go#L112
И потом сбрасывают его содержимое вот тут:
github.com/VKCOM/kittenhouse/blob/f07cfa44a8d67bbfb7015fca1e459f7731ab27c0/core/inmem/flusher.go#L53
Если сначала отпускать лок на мапу, а потом брать лок на элемент, то последняя запись в этот элемент может произойти после того, как содержимое буфера уже сбросили и выкинули.
Возможно, в этом месте это оверинжиниринг, то так точно не будет теряться запись в буфер.
> Как может появиться новый элемент вот тут? Читатели не блокирует друг друга, но писатель же блокирует читателей и эта ситуация невозможна или я заблуждаюсь?
Писатель блокирует читателей, однако писателей может быть несколько и между RUnlock() и Lock() может «вклиниться» другой писатель, который добавит элемент в мапу (или наоборот очистит её содержимое).
> В целом. мне кажется проще и правильней было сделать так — писать напрямую в файл.
Такое тоже есть. У kittenhouse 2 разных режима записи: в память и на диск. Во втором случае запись производится просто в файл и дальше отсылается содержимое из файла.
Запись: github.com/VKCOM/kittenhouse/blob/f07cfa44a8d67bbfb7015fca1e459f7731ab27c0/core/persist/log.go#L194
Чтение:
github.com/VKCOM/kittenhouse/blob/f07cfa44a8d67bbfb7015fca1e459f7731ab27c0/core/persist/send.go
> Плюс я не смотрел код внимательно — но кажется синков -нет.
Синков нет, всё правильно. Мы готовы пожертвовать тами данными, которые не сбросились на диск локальной машины в случае kernel panic или при потере питания (такое происходит довольно редко). Если добавить sync раз в секунду, то если мы будем писать в сотни файлов (что вполне возможно), мы будем создавать слишком большую нагрузку на локальный диск. Мы выбрали не делать sync вообще, но, в целом, нет причин, почему его нельзя добавить, как опцию.
nxao
23.11.2018 18:07А зачем пилить свой велосипед Lighthouse если есть tabix который умеет все что у вас и даже больше?
https://github.com/tabixio/tabix
nikolaynag
23.11.2018 22:11Спасибо за интересную статью, довольно интересный и полезный опыт. Подскажите пожалуйста, как вы решаете проблему с изменением структуры данных в Clickhouse? Сервисы ведь обычно развиваются и хочется добавить в структурированные логи какие-то новые параметры. Или вы используете одну и ту же структуру для всех логов? Часто ли в этом случае приходится использовать полнотекстовый поиск?
youROCK Автор
23.11.2018 22:28Мы удаляем буферную таблицу, делаем ALTER, добавляем новые поля, создаем буферную таблицу обратно.
У нас есть общая таблица для логов, но там довольно мало данных пишется. Как правило, мы создаем отдельную таблицу под каждый вид логов. В этом случае полнотекстовый поиск не требуется и мы используем фильтрацию по конкретным полям.
o6CuFl2Q
23.11.2018 23:07Проблема с ALTER таблиц типа Buffer сейчас решается: github.com/yandex/ClickHouse/pull/3603
youROCK Автор
23.11.2018 23:16Этот патч (если я правильно понял) решает только проблему с тем, что нельзя читать/писать в буферную таблицу, если её схема отличается. Но проблема с тем, что в некоторых случаях очень сложно гарантировать одинаковость схемы, в этом пул реквесте не решена. Насколько я понимаю, более хорошим (но и намного более сложным в реализации) решением для озвученной проблемы с долго идущим альтером было бы автоматическое изменение схемы буферной таблицы при смене схемы родительской таблицы.
o6CuFl2Q
23.11.2018 23:30Это действительно так, но я бы предпочёл встроить буфер непосредственно в MergeTree, чтобы избежать сразу всех проблем отдельных Buffer таблиц.
Для сохранения порядка данных и отсутствия блокировок при чтении, можно использовать такую же схему (иммутабельные куски) как в MergeTree, но для данных в оперативке.
С помощью табличных настроек можно было бы управлять такими параметрами как: наличие или отсутствие WAL; частота применения fsync для WAL и необходимость его ожидания; возможность синхронно дождаться сброса буфера в основную таблицу.youROCK Автор
23.11.2018 23:49Да, встраивание функциональности буфера в *MergeTree тоже решило бы проблему :). Спасибо за разъяснение.
Neyury
Уже успел посмотреть ваши видео с HighLoad и clickhouse meetup.
Не подскажите какое количество одиночных вставок может выдержать buffer таблица? Не хотелось бы прибегать к batcher'ам, так как они внесут задержку.
youROCK Автор
По моим бенчмаркам, буферные таблицы выдерживают примерно до 3 000 вставок в секунду. Если вставка больше, то всё же нужен батчинг :).
yleo
На всякий случай, вдруг пригодится:
youROCK Автор
Вы можете использовать только kittenhouse --reverse и вставлять 100к+ в секунду в буферную таблицу (реверс прокси вносит задержку в ~12.5мс в среднем) при условии, что держите соединение открытым постоянно. Если соединение постоянно открывать/закрывать, то скорее всего будет существенно меньше, хотя тоже должен весьма приличную нагрузку держать.