
Что ж, настроим тестовый, но близкий к реальному кластер и разберем катастрофу по косточкам. Измерим все просадки производительности, найдем утечки памяти, разберем процесс восстановления обслуживания. И все это под руководством Артемия Капитулы, который потратив почти год на изучение подводных камней, заставил при отказе производительность кластера не падать в ноль, и latency не подскакивать до неприличных значений. И получил красный график, который ну сильно лучше.
Далее вы найдете видео и текстовую версию одного из лучших докладов DevOpsConf Russia 2018.
О спикере: Артемий Капитула системный архитектор RCNTEC. Компания предлагает решения для IP телефонии (совместная работа, организация удаленного офиса, программно-определяемые системы хранения и системы управления/распределения питанием). Компания в основном работает в enterprise секторе, поэтому не очень известна на рынке DevOps. Тем не менее, накоплен определенный опыт работы с Ceph, который во многих проектах используется как базовый элемент инфраструктуры хранилища.
Ceph — это программно-определяемое хранилище с множеством программных компонентов.
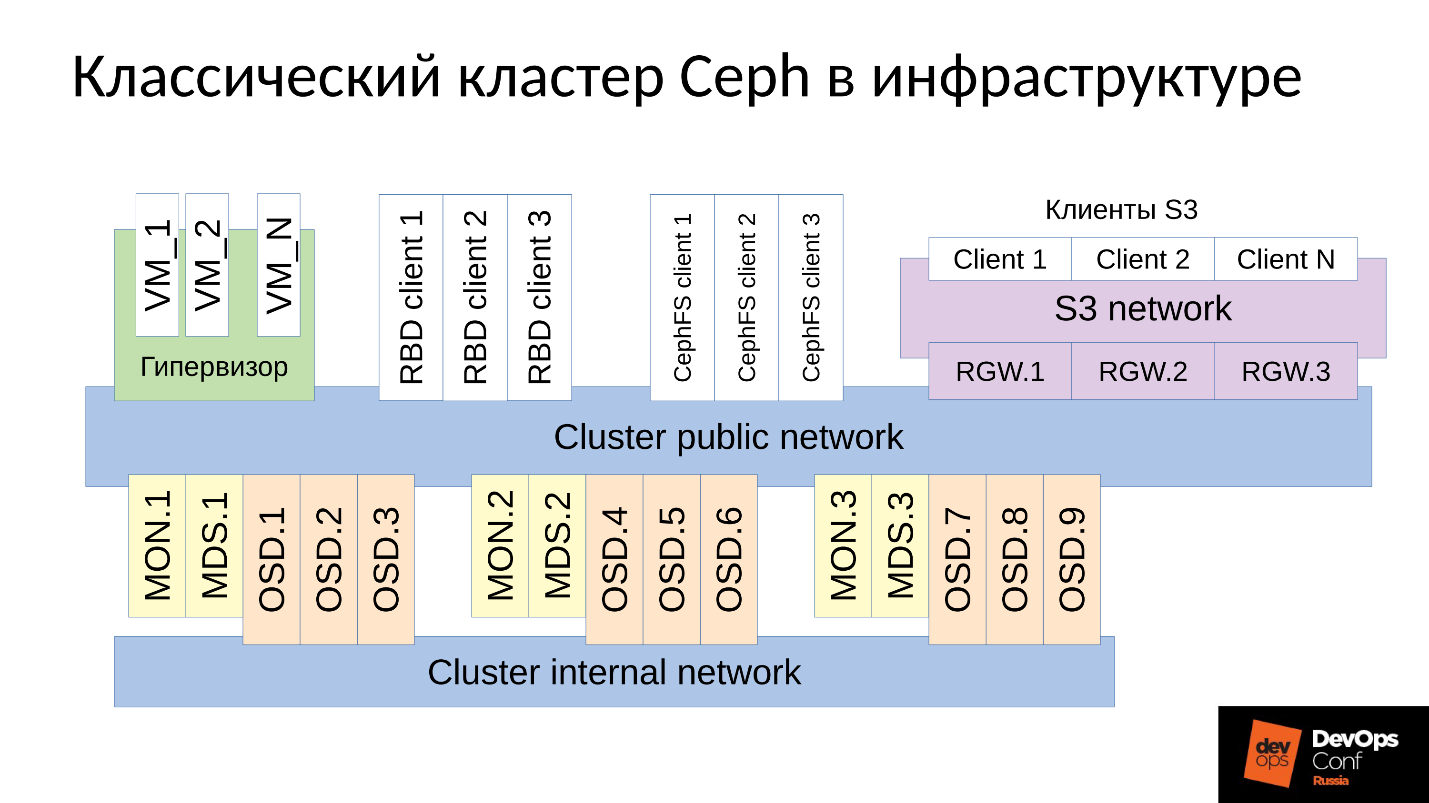
На схеме:
- Верхний уровень — внутренняя кластерная сеть, по которой коммуницирует сам кластер;
- Нижний уровень — собственно Ceph — набор внутренних Ceph’ских демонов (MON, MDS и OSD), которые хранят данные.
Все данные, как правило, реплицируются, на схеме я специально выделил три группы, в каждой по три OSD, и в каждой из таких групп обычно лежит одна реплика данных. В результате данные хранятся в трех копиях.
Выше уровнем кластерная сеть — это сеть, через которую клиенты Ceph получают доступ к данным. Через нее клиенты коммуницируют с монитором, с MDS (кому надо) и с OSD. Каждый клиент работает с каждым OSD и с каждым монитором самостоятельно. Поэтому система лишена единой точки отказа, что очень радует.
Клиенты
?? ? Клиенты S3
S3 — это API для HTTP. Клиенты S3 работают по HTTP и подключаются к компонентам Ceph Rados Gateway (RGW). Они практически всегда коммуницируют с компонентом через выделенную сеть. В этой сети (я ее назвал S3 network) используется только HTTP, исключения редки.
?? ? Гипервизор с виртуальными машинами
Данная группа клиентов часто используется. Они работают с мониторами и с OSD, с которых получают общую информацию о состоянии кластера и распределении данных. За данными эти клиенты непосредственно ходят на OSD-демонов через Cluster public network.
?? ? RBD-клиенты
Также есть физические BR metals хосты, на которых, как правило, Linux. Они являются RBD-клиентами и получают доступ к образам, хранящимся внутри кластера Ceph (образы диска виртуальных машин).
?? ? CephFS-клиенты
Четвертая группа клиентов, которая еще есть не у многих, но вызывает все больший интерес, это клиенты кластерной файловой системы CephFS. Кластерная система CephFS может быть смонтирована одновременно со многих узлов, и все узлы получают доступ к одним и тем же данным, работая с каждой OSD. То есть нет как таковых Gateways (Samba, NFS и прочих). Проблема в том, что такой клиент может быть только Linux, причем достаточно современной версии.

Наша компания работает на корпоративный рынок, а там бал правит ESXi, HyperV и другие. Соответственно, от кластера Ceph, который так или иначе используется в корпоративном секторе, в обязательном порядке требуется поддержка соответствующих методик. Нам этого в Ceph не хватило, поэтому пришлось дорабатывать и расширять кластер Ceph своими компонентами, фактически строя уже нечто большее, чем Ceph, — свою платформу для хранения данных.
Кроме того, клиенты в корпоративном секторе не на Linux, а в большинстве своем Windows, изредка Mac OS, в кластер Ceph сами идти не могут. Их приходится запускать через какие-то шлюзы, которые в этом случае становятся узкими местами.
Нам пришлось добавить все эти компоненты, и мы получили несколько более широкий кластер.

У нас появились два центральных компонента — это группа SCSI Gateways, которые предоставляют доступ к данным в кластере Ceph через FibreChannel или iSCSI. Эти компоненты используются для того, чтобы соединить HyperV и ESXi с Ceph-кластером. Клиенты PROXMOX по-прежнему работают родным для них способом — через RBD.
Файловых клиентов мы не пускаем напрямую в кластерную сеть, для них выделено несколько отказоустойчивых Gateway. Каждый Gateway предоставляет доступ к файловой кластерной системе по NFS, по AFP или по SMB. Соответственно, практически любой клиент, будь это Linux, FreeBSD или не только клиент, сервер (OS X, Windows), получает доступ к CephFS.
Для того, чтобы всем этим управлять, нам пришлось фактически разработать свой оркестратор Ceph и всех наших компонентов, которых там множество. Но говорить о нем сейчас нет смысла, поскольку это именно наша разработка. Большинству будет, наверное, интересен все-таки сам «голый» Ceph.
Ceph много где используется, и местами периодически случаются отказы. Наверняка все, кто работает с Ceph, знают легенду о CloudMouse. Это страшная городская легенда, но там все не так плохо, как кажется. Есть новая сказка о Росреестре. Там везде крутился Ceph, и везде был его отказ. Где-то это закончилось фатально, где-то удалось быстро устранить последствия.
К сожалению, у нас не принято делиться отрицательным опытом, все стараются спрятать соответствующую информацию. Зарубежные компании чуть более открыты, в частности, в DigitalOcean (известный провайдер, который раздает виртуалки) тоже случился отказ Ceph почти на сутки, это было 1 апреля — замечательный день! Часть репортов они выложили, ниже краткий лог.

Проблемы начались в 7 утра, в 11 они поняли, что происходит, и начали устранять отказ. Для этого они выделили две команды: одна зачем-то бегала по серверам и устанавливала туда память, а вторая почему-то вручную стартовала один сервер за другим и тщательно следила за всеми серверами. Почему? Мы же все привыкли, чтобы все включалось одним нажатием.
Что в принципе происходит в распределенной системе, когда она эффективно построена и работает почти на пределе своих способностей?
Для ответа на этот вопрос нам нужно посмотреть, как работает кластер Ceph и как происходит отказ.

Сценарий сбоя Ceph
Сначала кластер работает нормально, все идет замечательно. Затем случается что-то, после чего демоны OSD, где хранятся данные, теряют связь с центральными компонентами кластера (мониторами). В этот момент случается таймаут и весь кластер встает колом. Кластер стоит некоторое время, пока не поймет, что что-то с ним неладно, и уже после этого, корректирует свое внутреннее знание. После чего обслуживание клиентов в какой-то мере восстанавливается, и кластер снова работает уже в деградировавшем режиме. Причем самое смешное, что он работает быстрее, чем в штатном режиме — это удивительный факт.
Затем мы устраняем отказ. Допустим, у нас пропало электропитание, стойку вырубило полностью. Электрики прибежали, все восстановили, питание подали, серверы включились и тут начинается самое интересное.
Все привыкли к тому, что когда отказывает сервер, все становится плохо, а когда мы включаем сервер, все становится хорошо. Здесь все совершенно не так.
Кластер практически останавливается, проводит первичную синхронизацию и потом начинает плавное, медленное восстановление, постепенно выходя на штатный режим.

Выше график производительности кластера Ceph по мере развития сбоя. Обратите внимание, здесь очень четко прослеживаются те самые интервалы, о которых мы говорили:
- Нормальная работа примерно до 70 секунды;
- Провал на минуту примерно до 130 секунды;
- Плато, которое заметно выше, чем работа в нормальном режиме — это работа кластеров degraded;
- Затем мы включаем отсутствующий узел — это учебный кластер, там всего 3 сервера и 15 SSD. Пускаем сервер в работу где-то в районе 260 секунды.
- Сервер включился, вошел в кластер — IOPS’ы упали.
Давайте попробуем разобраться, что же там происходило в действительности. Первое, что нас интересует, — это провал вниз в самом начале графика.
Отказ OSD
Рассмотрим пример кластера с тремя стойками, по несколько узлов в каждой. Если левая стойка отказывает, все OSD демоны (не хосты!) пингуют себя Ceph’овскими сообщениями с определенным интервалом. Если произошла потеря нескольких сообщений, отправляется сообщение на монитор «Я, OSD такая-то, не могу достучаться до OSD такой-то».

При этом сообщения, как правило, группируются по хостам, то есть, если два сообщения от разных OSD приходят на один хост, они объединяются в одно сообщение. Соответственно, если OSD 11 и OSD 12 рапортовали о том, что они не могут достучаться до OSD 1, это будет интерпретировано, как Host 11 пожаловался на OSD 1. Когда отрапортовали OSD 21 и OSD 22, это интерпретируется, как Host 21 недоволен OSD 1. После чего монитор считает, что OSD 1 в состоянии down и уведомляет об этом (через изменение OSD map) всех членов кластера, работа продолжается в деградировавшем режиме.
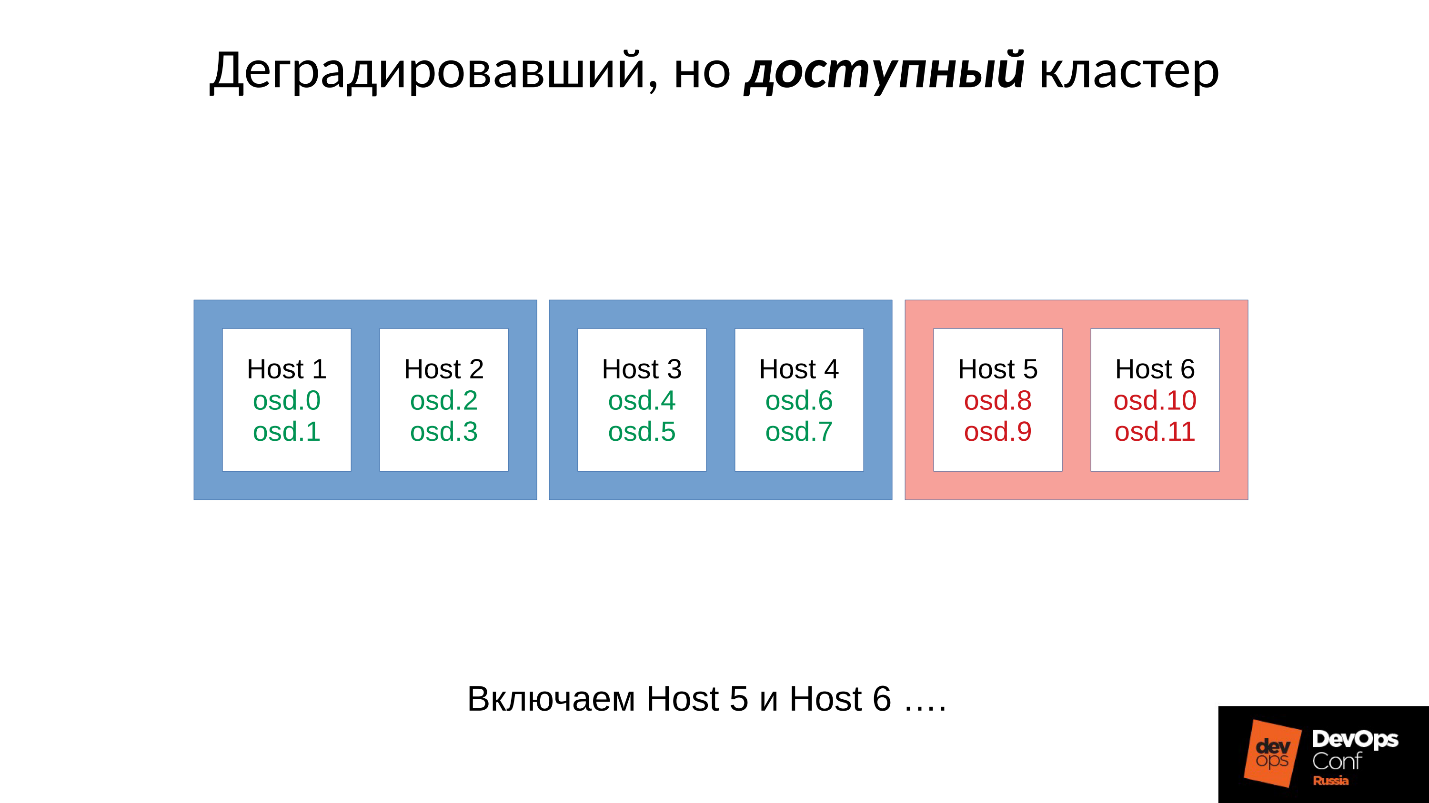
Итак, вот наш кластер и отказавшая стойка (Host 5 и Host 6). Включаем Host 5 и Host 6, поскольку питание появилось, и…
Внутреннее поведение Ceph
А теперь самое интересное — у нас начинается первоначальная синхронизация данных. Поскольку есть множество реплик, они должны быть синхронны и находиться в одной и той же версии. В процессе старта запуска OSD:
- OSD считывает имеющиеся версии, имеющуюся историю (pg_log — для определения текущих версий объектов).
- После чего определяет, на каких OSD лежат последние версии деградировавших объектов (missing_loc), а на каких отставшие.
- Там, где хранятся отставшие версии нужно провести синхронизацию, а новые версии могут быть использованы в качестве опорных для чтения и записи данных.
Используется история, которая собирается со всех OSD, и этой истории может быть достаточно много; определяется фактическое расположение множества объектов в кластере, где лежат соответствующие версии. Сколько объектов в кластере, столько получается записей, если кластер долго простоял в деградировавшем режиме, то история большая.
Для сравнения: типичный размер объекта, когда мы работаем с RBD-образом, составляет 4 Мбайта. Когда мы работаем в erasure coded — 1Мбайт. Если у нас диск на 10 Тбайт, то получается миллион мегабайтных объектов на диске. Если у нас 10 дисков в сервере, то уже 10 миллионов объектов, если 32 диска (мы строим эффективный кластер, у нас плотное размещение), то 32 миллиона объектов, которые надо удержать в памяти. Причем фактически информация о каждом объекте хранится в нескольких копиях, потому что каждая копия говорит о том, что в этом месте он лежит в такой версии, а в этом — в такой.
Получается огромный объем данных, который размещается в оперативной памяти:
- чем больше объектов, тем больше история missing_loc;
- чем больше PG — тем больше pg_log и OSD map;
кроме того:
- чем больше размер дисков;
- чем выше плотность размещения (количество дисков в каждом сервере);
- чем выше нагрузка на кластер и чем быстрее ваш кластер;
- чем дольше OSD находится дауне (в состоянии Offline);
другими словами, чем более крутой кластер мы построили, и чем дольше часть кластера не отвечала — тем больше оперативной памяти потребуется при старте.
Экстремальные оптимизации — корень всех зол
«… а к плохим мальчикам и девочкам ночью приходит черный ООМ и убивает все процессы направо и налево»
Городская сисадминская легенда
Итак, оперативной памяти требуется много, потребление памяти растет (мы же стартовали сразу в треть кластера) и система в теории может уйти в SWAP, если вы конечно его создали. Думаю, есть достаточно много людей, которые думают, что SWAP — это плохо, и его не создают: «Зачем? У нас же много памяти!» Но это неправильный подход.
Если SWAP-файл заранее не создан, так как решили, что Linux так будет работать эффективней, то рано или поздно случится out of memory killer (ООМ-killer) И не факт, что он убьет именно того, кто съел всю память, а не того, кому первому не повезло. Мы же знаем, что такое оптимистичная локация — мы запрашиваем память, нам ее обещают, мы говорим: «А теперь дай нам ее», в ответ: «А нету!» — и out of memory killer.
Это штатная работа Linux, если его не настраивать в области виртуальной памяти.
Процесс получает out of memory killer и вываливается быстро и безжалостно. При этом никакие другие процессы о том, что он умер, не знают. Он никого не успел ни о чем уведомить, его просто терминировали.
Потом процесс, естественно, перезапустится — у нас же systemd, он же запускает при необходимости OSD, которые упали. Упавшие OSD стартуют, и… начинается цепная реакция.
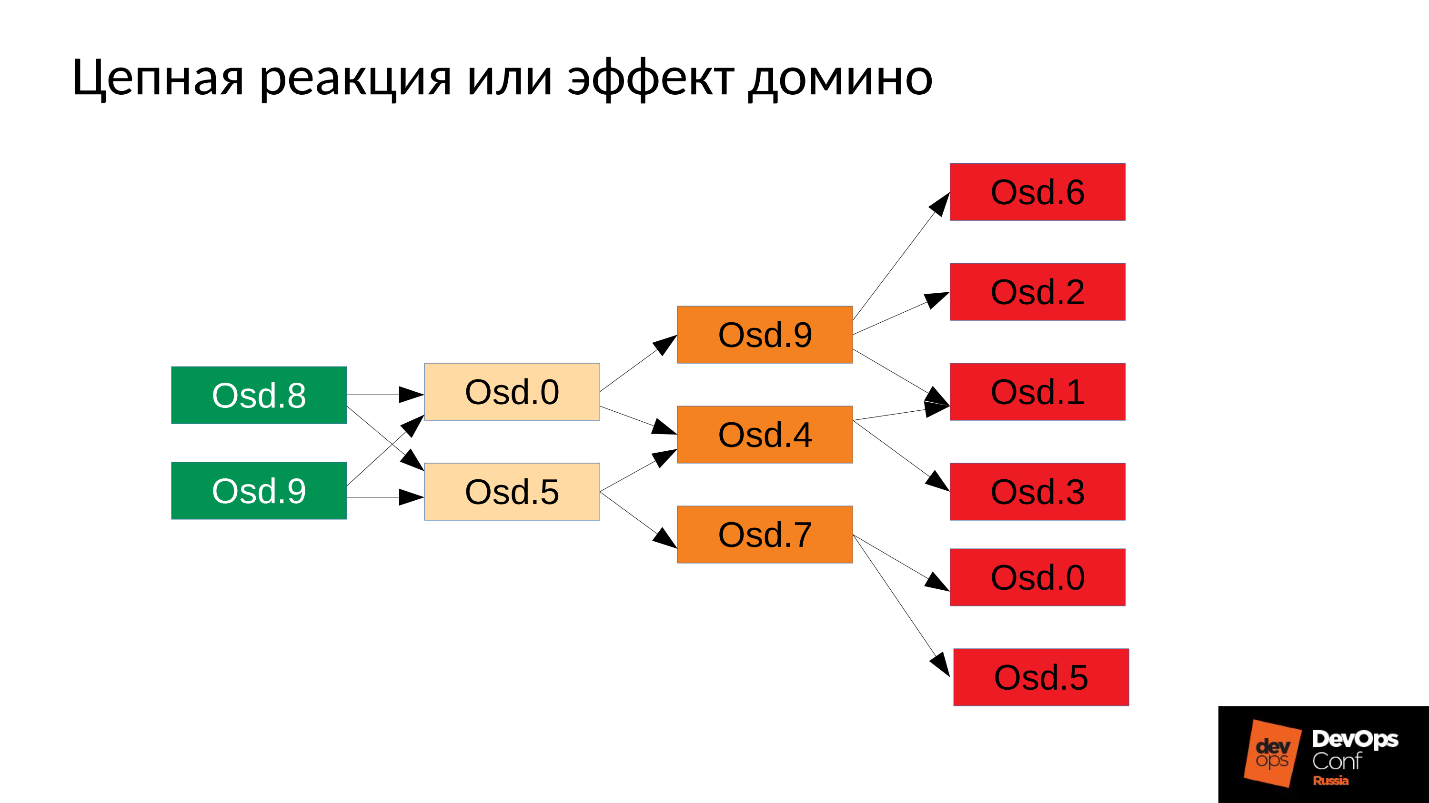
В нашем случае мы стартовали OSD 8 и OSD 9, они начали давить все, но не повезло OSD 0 и OSD 5. К ним прилетел out of memory killer и терминировал их. Они перезапустились — прочли свои данные, начали синхронизироваться и давить остальные. Не повезло еще трем (OSD 9, OSD 4 и OSD 7). Эти три перестартовали, начали давить на весь кластер, не повезло следующей пачке.
Кластер начинает разваливаться буквально на глазах. Деградация происходит очень быстро, и это «очень быстро» обычно выражается в минутах, максимум, в десятках минут. Если у вас есть 30 узлов (по 10 узлов в стойке), и вырубило стойку из-за сбоя питания — через 6 минут половина кластера лежит.
Итак, мы получаем примерно следующее.
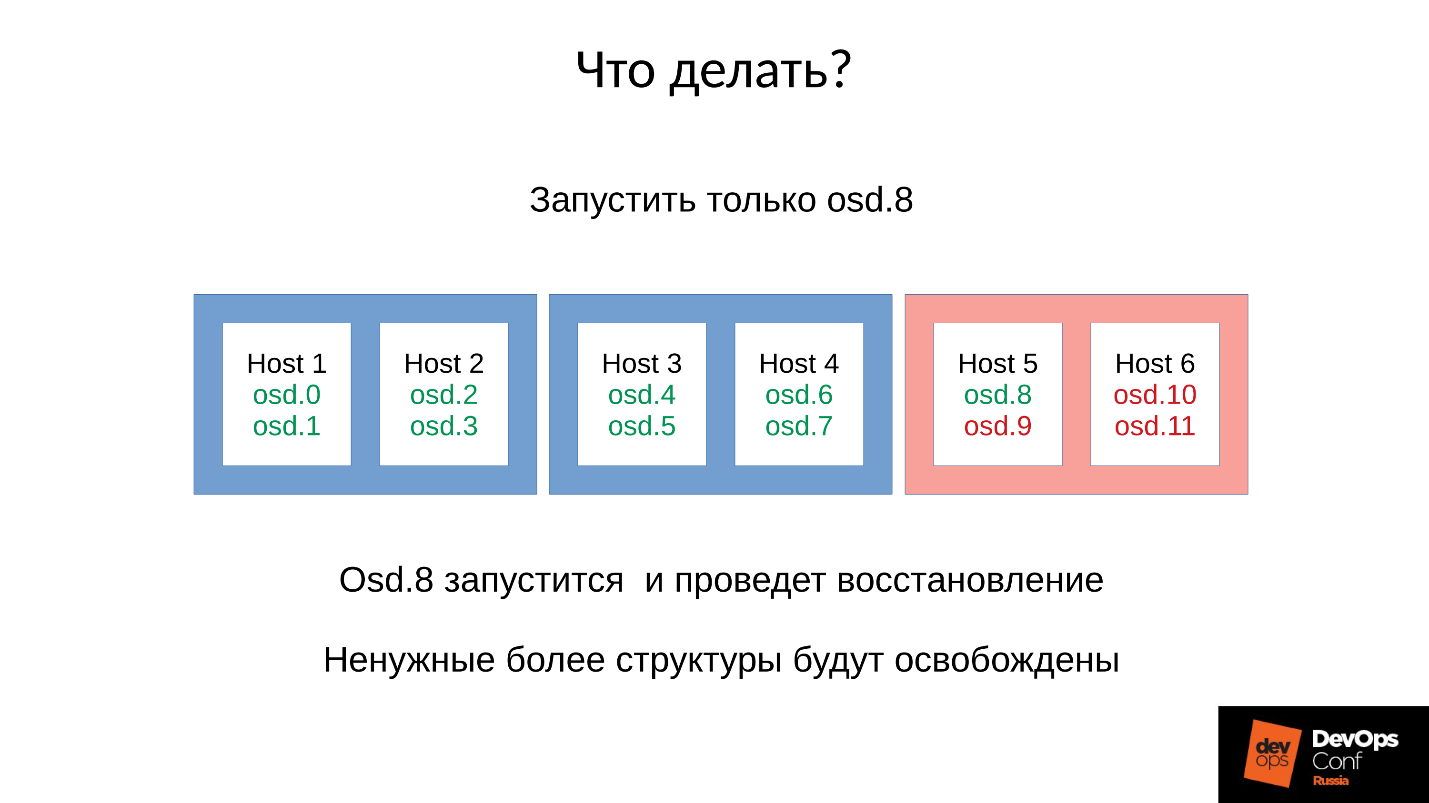
Практически на каждом сервере у нас есть отказавшая OSD. А если на каждом сервере она есть, то есть в каждом домене отказа у нас по отказавшей OSD, то большая часть наших данных недоступна. Любой запрос блокируется — на запись, на чтение — не имеет разницы. Все! Мы встали.
Что делать в такой ситуации? Точнее, что надо было делать?
Ответ: Не запускать кластер сразу, то есть всю стойку, а аккуратненько поднимать по одному демону.
Но мы этого не знали. Мы стартовали сразу, и получили то, что получили. Мы запустили в данном случае один демон из четырех (8, 9, 10, 11), расход памяти увеличится примерно на 20 %. Как правило, такой скачок мы выдерживаем. Потом расход памяти начинает снижаться, потому что часть структур, которые использовались для удержания информации о том, как кластер деградировал, уходит. То есть часть Placement Groups вернулась в нормальное состояние, и все, что нужно для удержания деградированного состояния, освобождается — в теории освобождается.
Давайте посмотрим пример. Код на С слева и справа практически идентичен, отличие только в константах.

Эти два примера запрашивают у системы разное количество памяти:
- левый — 2048 кусков по 1 Мбайту;
- правый — 2097152 куска по 1 Кбайту.
Затем оба примера ждут, чтобы мы их сфотографировали в top. А после нажатия ENTER, они освобождают память — всю, кроме последнего куска. Это очень важно — последний кусок остается. И опять ждут, чтобы мы их сфотографировали.
Ниже то, что фактически произошло.

- Сначала оба процесса запустились и отъели память. Похоже на правду — 2 Гб RSS.
- Жмем ENTER и удивляемся. Первая программа, которая выделяла большими кусками, память вернула. А вот вторая программа не вернула.
Ответ, почему же так произошло, кроется в Linux’овом malloc’е.
Если мы запрашиваем память большими кусками, она выдается с использованием механизма anonymous mmap, который отдается в адресное пространство процессора, откуда нам потом нарезают память. Когда мы делаем free(), память освобождается и страницы возвращаются в page cache (системе).
Если же мы выделяем память маленькими кусочками, у нас делается sbrk( ). sbrk( ) смещает указатель на хвост кучи, в теории смещенный хвостик можно вернуть обратно, вернув страницы памяти системе, если память не используется.
Теперь посмотрим на иллюстрацию. У нас было много записей в историю о расположении деградировавших объектов, а потом пришла пользовательская сессия — долгоживущий объект. Мы синхронизировались и все лишние структуры ушли, но долгоживущий объект остался, и мы не можем сдвинуть sbrk( ) назад.

У нас осталось большое неиспользуемое пространство, которое можно было бы освободить, если бы у нас был SWAP. Но мы же умные — мы SWAP отключили.
Конечно, потом какая-то часть памяти из начала кучи будет использована, но это лишь некоторая часть, а очень существенный остаток так и будет удерживаться занятым.
Что в такой ситуации делать? Ответ ниже.
Контролируемый запуск
- Запускаем один демон OSD.
- Ждем, пока он синхронизируется, проверяем бюджеты памяти.
- Если понимаем, что выдержим старт следующего демона, стартуем следующий.
- Если нет, то быстренько перезапускаем демон, который занял больше всего памяти. Он был в состоянии down недолго, у него не так много истории, missing locs и прочего, поэтому он съест меньше памяти, бюджет памяти слегка увеличится.
- Пробегаемся по кластеру, контролируем его, и постепенно все поднимаем.
- Проверяем, можно ли приступать к следующей OSD, переходим к ней.
DigitalOcean фактически это и выполнили:
«Our Datacenter team performs memory augments while another team slowly continues to bring up nodes while manually managing the memory budget of each host».
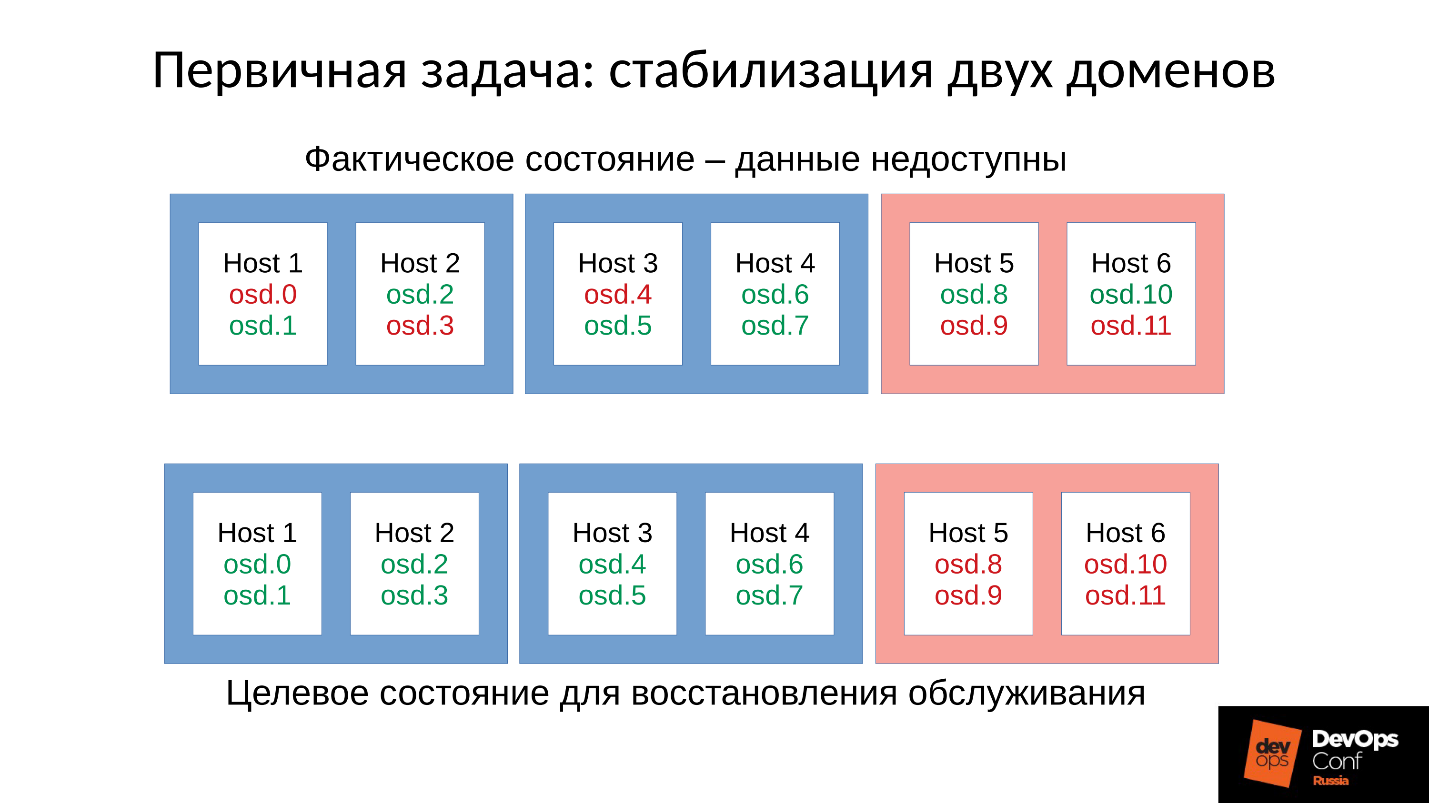
Вернемся к нашей конфигурации и сложившейся ситуации. Сейчас мы имеем разваленный кластер после цепной реакции out of memory killer. Мы запрещаем автоматический перезапуск OSD в красном домене, и один за другим стартуем узлы из синих доменов. Потому что наша первая задача всегда — восстановить обслуживание, не разбираясь, почему это случилось. Разбираться будем потом, когда восстановим обслуживание. В эксплуатации всегда именно так.
Мы приводим кластер в целевое состояние для того, чтобы восстановить обслуживание, а потом начинаем запускать одну OSD за другой по нашей методике. Первую смотрим, при необходимости перезапускаем другие, чтобы скорректировать бюджет памяти, следующую — 9, 10, 11 — и кластер вроде бы синхронизировался и готов начать обслуживание.
Проблема заключается в том, как выполняется обслуживание записи в Ceph.
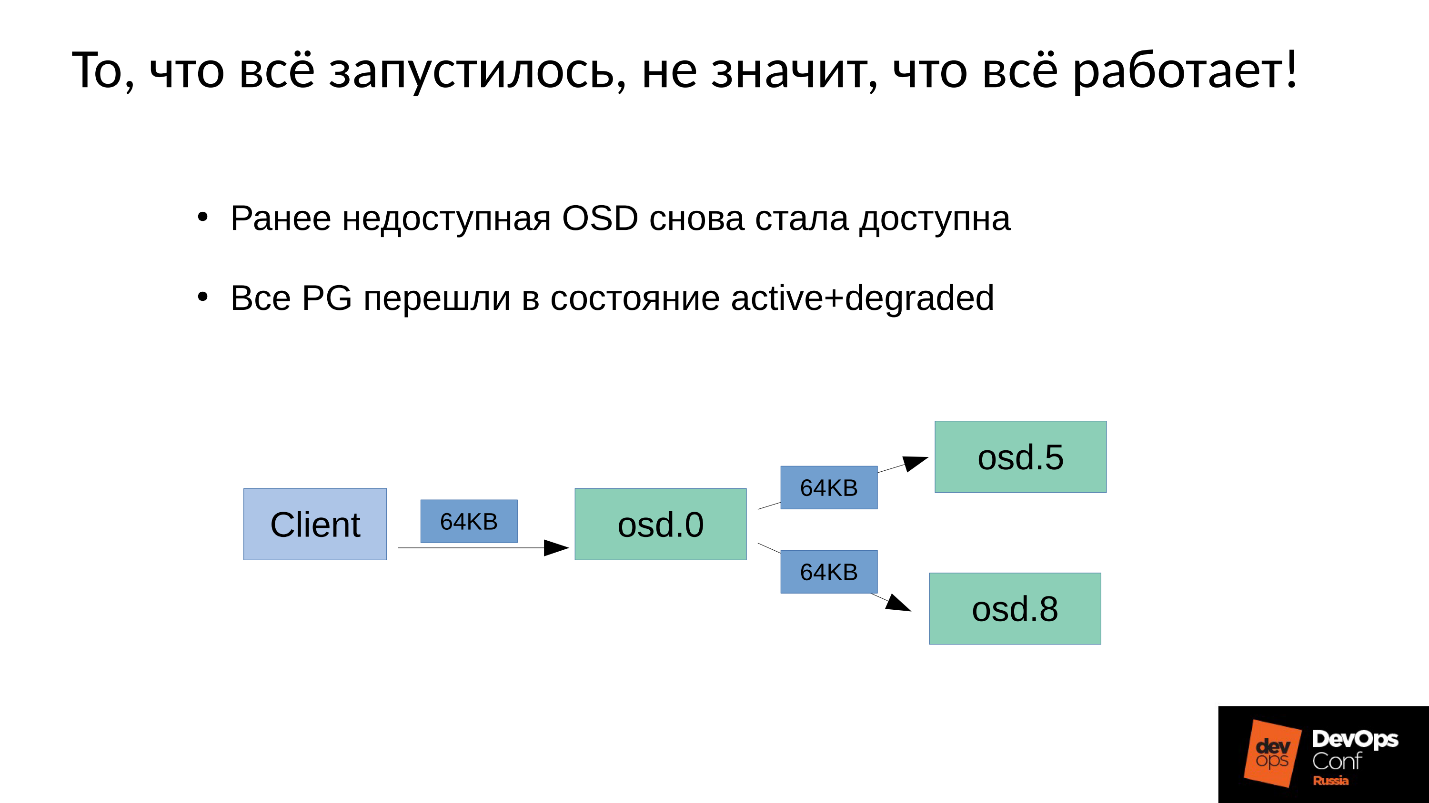
У нас есть 3 реплики: одна master OSD и два slave для нее. Уточним, что master/slave в каждой Placement Group свои, но в каждой один master и два slave.
Операция записи или чтения попадает на master. При чтении, если у master есть нужная версия, он ее отдаст клиенту. С записью немного сложнее, запись должна быть повторена на всех репликах. Соответственно, когда клиент пишет 64 Кб в OSD 0, эти же 64 Кб в нашем примере попадают на OSD 5 и OSD 8.
Но дело в том, что у нас же OSD 8 очень сильно деградировавшая, поскольку мы перезапускали много процессов.

Поскольку в Ceph любое изменение — это переход от версии к версии, на OSD 0 и OSD 5 у нас будет новая версия, на OSD 8 — старая. Это означает, что для того, чтобы повторить запись (разослать 64 Кб) нам нужно на OSD 8 обновить версию — а это 4 Мб (размер объекта). То есть мы читаем 4 Мб на OSD 0, посылаем на OSD 8, она записывает, приходит в синхронное состояние. Теперь у нас везде одинаковые свежие версии, и только тогда мы записываем 64 Кб.
Теперь пойдут цифры — самое интересное.

Производительность тестового кластера:
- Операция записи размером 4 Кбайта занимает 1 мс, производительность 1000 операций/секунду в 1 поток.
- Операция размером 4 Мбайта (размером объекта) занимает 22 мс, производительность 45 операций/секунду.
Следовательно, когда отказывает один домен из трех, кластер некоторое время находится в деградировавшем состоянии, и половина горячих объектов распространится по разным версиям, то половина операций записей будет начинаться с принудительного восстановления.
Время принудительного восстановления рассчитываем примерно — операции записи в деградировавший объект.

Сначала мы читаем 4 Мбайта за 22 мс, пишем 22 мс, и затем 1 мс мы пишем 4 Кб собственно данных. Итого суммарно 45 мс на одну операцию записи в деградировавший объект на SSD, когда штатная производительность у нас была 1 мс — падение производительности в 45 раз.
Чем больше у нас процент деградировавших объектов, тем все становится страшнее.
Усредненное время обслуживания
- Когда деградировала половина объектов, среднее время обслуживания — (45+1) / 2 = 23 мс.
- Если деградировало 75% объектов, то (45 * 3 + 1) / 4 = 34 мс.
- Если 90% —(45 * 9 + 1) / 10 = 41 мс — в 40 раз медленнее, чем штатный режим.
Это заводской механизм работы Ceph, и с ним ничего нельзя делать. Если ваш кластер частично побывал в офлайн и в это время другая его часть обслуживала запросы клиентов, то после включения будет резкое, в несколько десятков раз, падение производительности на некоторых операциях.
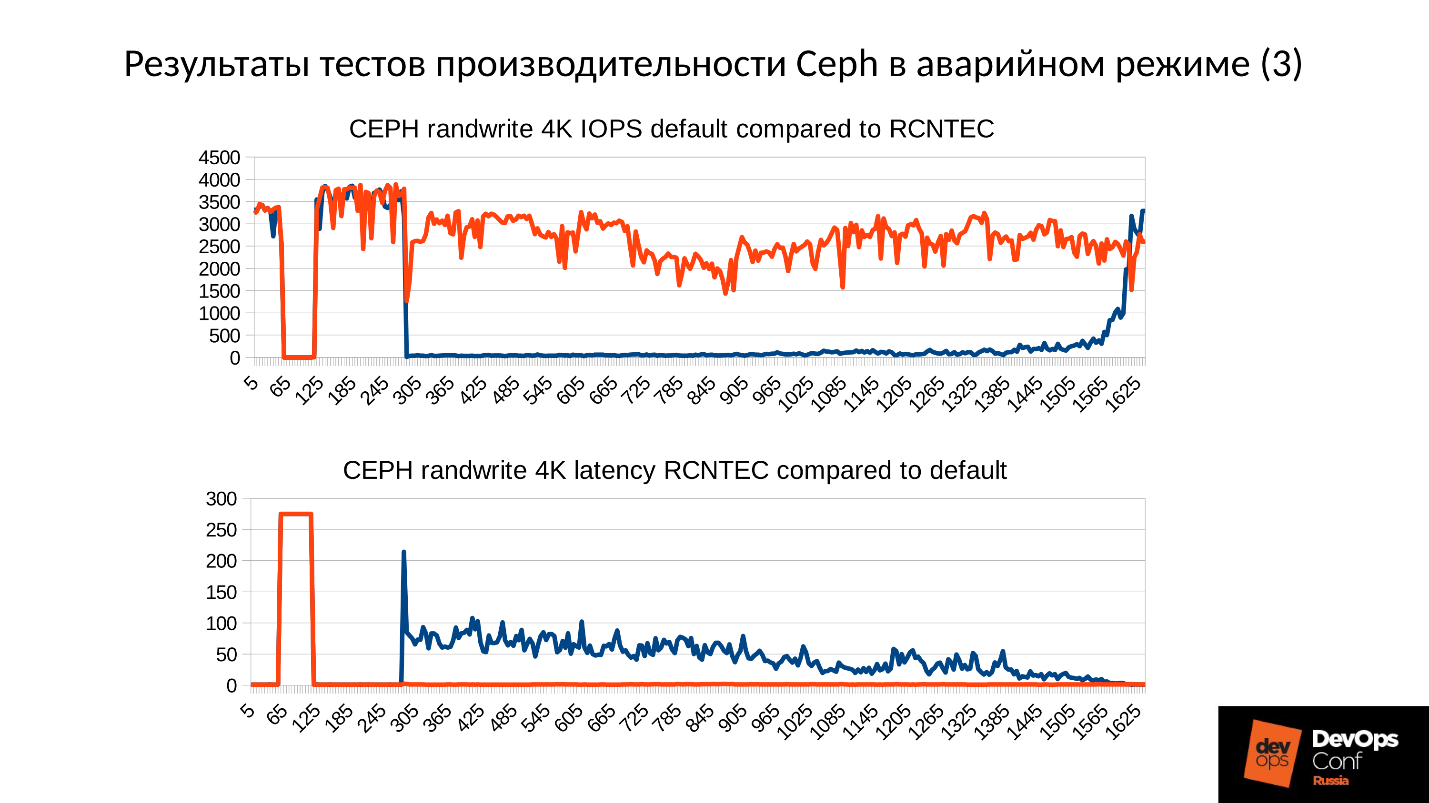
Теперь рассмотрим результаты тестов производительности Ceph в аварийном режиме сразу на двух графиках.

- Нижний график нам знаком — это производительность кластера: нормальный режим, провал, обнаружение отказа, деградировавший режим, работа в деградировавшем режиме.
- Сверху — latency. Здесь фактически latency даже хуже, чем мы рассчитывали. Этот кластер деградировал почти на 100% в ходе теста (я специально подольше его подержал, чтобы картинки были зрелищными и до вас дошла глубина поражения). Latency от 60 мс за счет накладных расходов, которые мы в изначальных расчетах не учитывали.

Кластер будет восстанавливаться в ходе штатной работы, и мы упираемся прежде всего в сеть. Сеть 10 Гбит, то есть 1 200 Мб/с, а это означает 300 объектов в секунду на один сервер, вне зависимости от того, сколько там дисков. Будет 10 SSD — все равно 300 объектов в секунду, один диск — возможно, будет по-прежнему 300 объектов в секунду.
Мы строили эффективный кластер, а попали в сеть репликаций.
Кроме того, еще есть полоса пропускания диска. Наш диск в штатном режиме выдает 900 Мбайт/с (это средний SSD). Обычно он обслуживает порядка 2 500 операций в 128 Кбайт в секунду (как правило, ESXi и HyperV выравнивают свои запросы под 128 Кбайт). Но если мы входим в degraded, упираемся в 225 объектов в секунду. А если мы используем file store, а не object store, то у нас же есть еще и журнал (двойная запись), то вообще получается 110 операций в секунду, и все становится вообще очень-очень печально.
SSD выдает 110 операций в секунду — катастрофа!
Что мы можем сделать?
Ответ 1: Бороться можно только архитектурой — делать больше доменов отказа.

Здесь столбцы слева направо: сколько доменов отказало; процент деградировавших PG;
среднее время обслуживания с учетом соответствующего отказа.
Если у нас отказал:
- Один домен из трех, то 45 мс — это оптимистичная оценка.
- Один домен из десяти (по теории вероятности с учетом мат. ожидания), получается примерно 14 мс.
- Один домен из двадцати, то 8 мс (деградировало примерно 10% PG).
То есть добавлять домены эффективно, но дорого, поскольку домен отказа проектируется под отказ питания, серверов, прочего оборудования, и это не всегда возможно.
Ответ 2: Второй вариант — уменьшить размер объекта (order, objectsize) в образе.
Если мы уменьшаем размер объекта, то, например, операции из 4 Мбайт станут 2 или 1 Мбайт. Тогда все станет в разы быстрее, но все равно сильно медленнее, чем штатный режим. При этом:
- кратно уменьшается время репликации объекта;
- пропорционально уменьшается время обслуживания (latency) на кластере во время восстановления.
Но за все надо платить:
- кратно увеличивается количество объектов;
- почти кратно увеличивается расход памяти;
- самое неприятное — невозможно изменить размер объекта для уже созданного образа. Как он создался в 4 Мбайта, так и останется.
Если мы создали его под максимальную производительность (32 Мбайт объект) — тогда мы попали очень конкретно сразу!
Ответ 3: Еще один путь — это дорабатывать Ceph.
В рамках функциональных обязанностей я, как системный архитектор-разработчик, полез вглубь Ceph. В ходе изысканий нам удалось заставить кластер не заниматься репликацией на каждый чих при записи в деградировавший объект, но при этом сохранить консистентность кластера, то есть усечь часть передаваемых данных. Получилось вот такая интересная картина.
На верхнем графике производительность кластера, на нижнем — Latency. Синий — штатный график, красный — экспериментальный. Latency на самом деле подрастает на 30% минимум, просто в этом масштабе этого не видно, то есть не все так хорошо.
В Community этого кода пока что нет, поскольку он находится в preproduction состоянии. Его нельзя включать на ходу, а это нас не устраивает. Когда мы это доведем до конца, мы это сделаем.
Заключение
У нас суммарно ушло примерно человеко-год на то, чтобы получить этот рабочий график. Если у вас нет возможности вложить столько трудозатрат, залезть внутрь Ceph и сделать там что-нибудь кардинальное, то вот, что вы можете сделать.
?? ? Во время аварии что-то делать бесполезно.
Во время аварии нельзя паниковать, к ней надо быть готовым. Это означает, что надо в обязательном порядке проводить учения. Без этого все ваши теоретические изыскания бесполезны. Более того, учения очень рекомендуется проводить примерно на тех же конфигурациях, где у вас production. Потому что, если у вас в учениях мало данных, то на проблему с памятью, с которой столкнулись DigitalOcean и мы, вы не наступите. Если данных много, то наступите, и будете не знать, что делать.
К тому же, если у вас мало данных и небольшая нагрузка, то вы не увидите этого адского падения производительности. К вам придут клиенты, начнут кричать: «У вас ничего не работает! Что случилось?!» Они будут дергать вашу техподдержку, техподдержка вас, вы будете хвататься за голову. Все будет печально, и к этому надо быть готовым: понимать, где мы просядем, сколько примерно продлится down time.
?? ? Нельзя удалять компоненты кластера (OSD).
Каждый раз, когда вы удаляете вроде бы тормозящий компонент, вы теряете часть данных — часть избыточных пока что данных, но, если что-то пойдет не так в другом месте, они могут понадобиться. Поэтому не удаляйте компоненты кластера OSD — мониторы и прочие — на ходу никогда. Если вы это делаете, вы сами себе злобный Буратино.
?? ? Правильно проектируйте кластер.
Следует на этапе проектирования минимизировать количество недоступных OSD в случае плановых работ или неплановых ситуаций. Делайте больше доменов отказа, если это возможно. Если нельзя, хотя бы выбирайте такое железо, чтобы можно было менять диски, не выключая сервер.
?? ? Выделяйте достаточно RAM на узлах OSD.
?? ? Не отключайте SWAP.
Поведение со SWAP это не только Ceph’овское поведение, а вообще общее Linux’овое поведение. Вы должны быть к этому готовы и это помнить.
?? ? Максимизируйте производительность репликационной сети кластера.
Пусть она не используется в штатном режиме на 100%, и даже на 10%. Но, если случится нештатный режим, каждый лишний гигабит облегчит вам жизнь, причем очень существенно.
?? ? Иногда имеет смысл уменьшить размер часто модифицируемых объектов RBD или уменьшить размер объекта в Rados Getway.
Но помните, что уменьшение размера объекта будет требовать дополнительной оперативной памяти. Не забывайте добавлять SWAP — его бояться не надо. То, что активность по SWAP есть — это не так страшно, поскольку, скорее всего, система сносит туда то, что не особо активно используется.
Это статья — расшифровка одного из лучших докладов DevOpsConf Russia. Скоро мы откроем видео и опубликуем в текстовом варианте еще насколько интересных тем. Подпишитесь здесь, на youtube или в рассылке, если хотите не пропустить подобные полезные материалы и быть в курсе DevOps-новостей.
Комментарии (82)

maydjin
30.11.2018 02:07IBM решил ещё землицы сверху присыпать?
gecube
30.11.2018 09:43Поясните, пожалуйста, что Вы имели в виду.
maydjin
30.11.2018 12:09IBM купил RedHat который развивал Ceph. Спустя месяц, поддержка Ceph была передана OSF. У IBM есть своё, аналогичное проприетарное решение за много денег. Ещё спустя пару недель начались статьи про то сколько много проблем в Ceph. Хотя до этого, на том же хабре все кушали кактус видимо.
Я мимокрокодил, просто слежу за новостями и не верю в совпадения, поэтому и спросил:)
gecube
30.11.2018 13:29Эта статья по мотивам конференции, которая была в МСК вроде бы в октябре.
Никакого отношения к IBM
Naves
30.11.2018 12:17Возможно имелось ввиду, что сейчас могут посыпаться статьи в стиле get the facts с факапами на продуктах от RedHat, и это как раз будет перед продажей RedHat-a.
Но мне кажется, что такие статьи сами по себе даже были бы полезней, как мы взяли технологию X и споткнулись об грабли здесь, и прострелили себе палец там, чем простые мануалы вида «развернуть кластер за 10 минут для чайников».maydjin
30.11.2018 12:20Я кончено так себе аналитег, но смысл им продавать красношапку тем более дешевле чем купили? Избавиться от убыточных или конкурирующих решений и иметь уважение.
Как бы под это дело гном не закопали. Хотя, может лучше бы и закопали, а то сообщество расслабилось на корпоративных харчах :)
Naves
30.11.2018 12:24Я что-то и не заметил, а сделка уже завершилась, или пока еще идут процессы?
a5b
30.11.2018 18:56Запустили сделку 28 октября 2018, есть не более года до её завершения или отмены. Вероятно будут какие-то дополнительные отчеты в SEC и пресс-релизы об окончательном завершении.
https://www.sec.gov/Archives/edgar/data/51143/000110465918064384/a18-37205_28k.htm
… right of either party to terminate the Merger Agreement if the Merger is not consummated on or before October 28, 2019 (subject to certain extension rights), (ii) the right of Red Hat to terminate the Merger Agreement to accept a Superior Proposal (..) for an alternative acquisition transaction… and (iii) the right of IBM to terminate due to a change of recommendation by the Red Hat Board of Directors.
…
If the Merger Agreement is terminated under certain circumstances, including termination by Red Hat ..., Red Hat will be obligated to pay to IBM a termination fee of $975,000,000 in cash.Юридический план процесса совершенно непонятен и точных дат не содержит: https://www.sec.gov/Archives/edgar/data/1087423/000119312518310577/d640856dex21.htm
gecube
30.11.2018 13:30продать красношапку после покупки — легко.
Как минимум:
— забрать все патенты себе (и задушить конкурентов, чтоб они не смогли их использовать)
— забрать все перспективные технологии
— убить разработку всего конкурентного по отношению к продуктам IBM
а все остальное продать по бросовой цене — деньги ведь не пахнут.
Just big business, nothing personal.
celebrate
30.11.2018 05:59? Выделяйте достаточно RAM на узлах OSD.
Достаточно — это сколько?
? Не отключайте SWAP.
Разве своп поможет? Имхо только продлит агонию.ultral
30.11.2018 09:27достаточный — это что бы хватило, надо считать. посыл один чем больше — тем лучше. можно вот матчасть почитать. не плохо расписано от докладчика ceph.pro/linux_vm_swap.html и бонусом www.linuxatemyram.com
MrNobody
30.11.2018 09:40> Достаточно — это сколько?
По рекомендации разработчика ceph 1 Gb на 1Tb:
Hardware recommendations
Дополню:
Там приписка «Чем больше тем лучше».
gecube
30.11.2018 09:47Насчёт свопа согласен. Он скорее продлит агонию. Но мои эксперименты с безсвоповыми серверами показывают, что их действительно сложно готовить правильно. Тем более, когда на них крутится софт, который привык к оптимистичному выделению/распределению памяти. Это не означает, что все плохо. Можно. Но нужно понимать риски и иметь крепкие нервы )
Кстати, у меня есть подозрение, что при использовании без свопа, у нас ОЗУ недоутилизирована (парадокс), но это можно объяснить хотя бы тем, что нам ее понадобится в пиках больше (своп действительно позволяет их "сгладить" ценой на нагрузки на диск и латентность)ultral
30.11.2018 10:03+11. ceph плохо переживает, когда ОС ему на malloc говорит что память не выделит
2. пришедший OOM валит без разбора всех и вызывает шторм
если бы была возможность лимитировать ceph по памяти настройками самого ceph, то swapless конфигурация имела бы смысл. Но в наших реалиях потребление памяти ceph'ом можно только прогнозировать…gecube
30.11.2018 10:231. ceph плохо переживает, когда ОС ему на malloc говорит что память не выделит
архитектурный просчет, ИМХО. Памяти ведь никогда не бесконечное количество, к сожалению.
И еще я почти наверняка уверен, что любое ПО «течет» так или иначе. Просто какое-то — сильнее, а другое — меньше (я даже сталкивался с утечками в драйверах в ядре).
2. пришедший OOM валит без разбора всех и вызывает шторм
Ну, это тоже регулируется относительно. Тот же oom_score_adj никто не отменял. Но, понятное дело, лучше до этого не доводить.
Поэтому просто принимает за данность, что процессы должны умирать рано или поздно. Лучше всего — в контролируемые администратором промежутки времени.
outlingo
30.11.2018 10:36«oom_score_adj» — у вас есть десяток процессов OSD которые примерно одинаково загружены и примерно одинаково потребляют память и есть незначительные потребители типа cron/sshd/что-то ещё. Если вы убиваете какую-то OSD, это всё равно что её терминирует OOM-killer. Просто пройдет это мягче. А завершение ssd и высвобождение 50MB RAM вам ничего не даст, потому что у вас OSD (например!) весит 7GB RSS.
outlingo
30.11.2018 16:56Уточним — отказ malloc сеф не «плохо переживает» — он его вообще не переживает. OSD тут же абортися. Проверяли :-)
MrNobody
30.11.2018 10:07Если объем данных большой, можно swap запихать на NVME какой-нибудь, что, безусловно, медленнее оперативной памяти, но по крайней мере не даст процессам умирать и отсрочит проблему, а возможно и вовсе избавит. Эффект домино происходит именно из-за того что процессы умирают без разбора. Повезет — умрет osd, не повезет — ssh или что похуже.
Интереснее вот что: выгоднее держать много маленьких серверов или мало больших имеющих swap на NVME и кучей памяти. Особенно если учесть что плотные чипы DDR дороже чем менее плотные, да и слоты под них не бесконечные. При этом в маленькие сервера нужны 10G карты, нужна коммутация, что тоже затраты.
amarao
30.11.2018 17:17Для многих систем даже своп на чём попало — это круто. На многогигабайтных системах в своп может улетать всякая редкоиспользуемая (читай, не используемая) фигня, и лежать там до скончания смерти сервера.
Надо различать swapping и thrashing. Свапинг — 5-20 операций в секунду, устройство свопа утилизировано меньше 10%, thrashing — красное в atop'е (>90%). Второе — аварийный режим и должен ловиться мониторингом по факту «началось», ещё до того, как обсыпется прикладной софт.gecube
30.11.2018 17:25+1Глупости говорите.
Я бы разделил так. swap для определенных видов нагрузок категорически нежелателен. Например, мы делаем бескомпромиссно быструю систему и самое главное — предсказуемую по latency. Fail fast & fail safe. Но при этом распределенную и масштабируемую. Тот же куб предполагает, что своп выключен. Например, serverfault.com/questions/881517/why-disable-swap-on-kubernetes
github.com/kubernetes/kubernetes/issues/53533
kubernetes.io/docs/setup/independent
Swap disabled. You MUST disable swap in order for the kubelet to work properly.
Для других типов нагрузок swap необходим.
Касательно ceph… ну, не знаю. Я не спец по нему. Но думаю, что можно и обойти.
Надо различать swapping и thrashing. Свапинг — 5-20 операций в секунду, устройство свопа утилизировано меньше 10%,
касательно своппинга. Ядро вообще им заниматься не должно, т.к. тот же page cache должно быть можно сбросить и считать все немодифицированные страницы с диска. Если страница модифицирована, то там, очевидно, НУЖНЫЕ данные. А если они не нужны, то, извините, вопрос к тому через какое место написан софт.amarao
30.11.2018 17:52+2Давайте без экстрима. Да, есть случаи, когда swap недопустим. Однако, таких случаев меньшинство. Если мы рассчитываем на realtime, сюрприз, мы ошиблись ОС. Особой разницы между мегапромахом NUMA при скедулинге и swap'ом на 10-20 страниц с нормальной SSD (менее 10ms на всё) нет.
Насчёт «вопросы к тому, через какое место написан софт».
Ну вот смотрите. У нас есть python. Python всегда хранит в памяти исходный текст того, что выполняет, но работает с байткодом. Что делать? Все эти десятки мегабайт help(), копии всех объявлений строк, включая локализации т.д. Оно всё отлично улетает в swap, но не может быть выкинуто из кеша (потому что RSS).
Если у вас есть вопросы к софту, и он является индустриальным стандартом, то можно либо быть д'Артаньяном, либо жить с тем, что есть.
Если страница модифицирована, это может быть копия конфига, это может быть данные инициализации сервиса, структур кода, который не используется и т.д.
В видео отлично объяснено откуда появляются неиспользуемые страницы памяти — фрагментация памяти. Многие языки программирования не делают дефрагментации, и даже SLAB не сильно помогает из-за того, что used области перемежаются с unused.
Опять же, вы можете заявить «ваш софт говно», но я могу сказать только одно в ответ: «другого софта у меня для вас нет, жрите что дали».gecube
30.11.2018 18:10Спасибо за подробный ответ.
Ну вот смотрите. У нас есть python. Python всегда хранит в памяти исходный текст того, что выполняет, но работает с байткодом. Что делать? Все эти десятки мегабайт help(), копии всех объявлений строк, включая локализации т.д. Оно всё отлично улетает в swap, но не может быть выкинуто из кеша (потому что RSS).
Вообще отдельный вопрос зачем Python так делает. Чтобы потом всегда можно было перекомпилировать код? Ну, такое себе. Либо получается, что разрабы языка и интерпретатора не считают, что это проблема (и доп. расходы на эти «лишние» данные не такие большие).
Опять же, вы можете заявить «ваш софт говно», но я могу сказать только одно в ответ: «другого софта у меня для вас нет, жрите что дали».
эт точно. Хорошо, когда софт пишут по заказу ) там можно выдвигать требования. А когда уже есть готовая коробка или решение — ну, да, приходится жить с тем, что есть.amarao
30.11.2018 18:13Потому что интроспекция. Можно ругать его в продакшене, но у интроспекции есть значительные плюсы.
… Когда софт пишут по заказу обычно выдвигаемые требования кроются выдвигаемыми инвоисами и вопрос экономии десятка мегабайт на копии процесса автоматически снимается.
. Я только что завернул предложение уменьшить число серверов на локацию (не важно в чём). Аргумент: сервер стоит 100 баксов в месяц, на 4 локации это экономит 400 евро в месяц. Причина, почему завернул? 2 месяца работы команды из трёх человек для поддержки такого режима. Берём 6 зп, делим на 400 евро и видим, что окупаемость за горизонтом планирования.
outlingo
30.11.2018 10:32Вы точно знаете, что ваши процесс точно-точно не начнут потреблять памяти больше, чем вы ожидаете? В случае с сефом это крайне критично — если если у вас падает по OOM OSD, это ещё более нагружает остальные узлы. Ну и всё осложняется архитектурой сефа. Фактически, если у вас упала одна OSD по OOM — у вас всё еще всё сравнительно нормально. Но если её перезапуск убивает другую, то пора «напрягаться». Потому что как только вылетит сразу две OSD в разных доменах отказа — всё, у вас проблемы с доступностью данных.
Свап не «продлевает агонию» — он позволяет сохранить доступность данных с деградацией производительности. Большой latency («тормозит») лучше чем полная недоступность данных.gecube
30.11.2018 11:07Свап не «продлевает агонию» — он позволяет сохранить доступность данных с деградацией производительности. Большой latency («тормозит») лучше чем полная недоступность данных.
если речь не про Ceph, то все ровно наоборот. Тормозит == недоступность сервиса (условно у пользователя страница открывается 5 минут — мы все равно его потеряли) и приплыли.
К тому же зачастую наличие swap'а маскирует проблему, заметает ее под ковер. Что приводит к ее возникновению уже сильно позже и существенно с более серьезными последствиями (речь не про самые простые случаи, ес-но, типа самого дешевого хостинга, который лишь бы хоть как-то работал).
Грамотным видится подход с ограничением доступного объем для каждого OSD, но действительно есть риск не угадать с точными значениями и создать проблемы на ровном месте.mayorovp
30.11.2018 11:52Не надо путать нормальную работу и аварийную. Своп мешает первой но нужен для второй.
А чтобы проблемы не заметались под ковер — нужен мониторинг.
gecube
30.11.2018 13:31Варианты как обеспечить работу в аварийном режиме, но без сильного запаса по железу?
(и кроме варианта — сделать swap)amarao
30.11.2018 18:18+1Без запаса всегда будет тонко.
Дело в том, что аварии-то не было. Было… снижение производительности на время переходных процессов.
Я даже не шучу. Просто в 40 раз меньшая производительность. Но ни одного запроса не потеряно, данные не потеряны. Latency в сотни секунд, очереди в тысячи запросов, но всё хорошо.
Чтобы снижения производительности не было, надо иметь запас по мощности.
scruff
30.11.2018 06:57Если у вас стойка «легла по питанию» это значит в ней нет ИБП? Вам не кажется, что нужно начинать планирование кластера именно с этой части?
gecube
30.11.2018 09:49Допускаю, что возможен отказ любого другого плана. Помимо "легла по питанию". Ну, свитчи сдохли. Или человеческий фактор — что-то кривой настроили или обновили. Короче — отказы случаются и лучше к ним быть готовыми заранее
scruff
30.11.2018 11:04Я сильно не вникал, но судя по описанию, вылегло 30% кластера. Как по мне, это уже много и ждать магии в ребьюлде структуры бесполезно.
outlingo
30.11.2018 10:23Не имеет значения причина отказа. Приедет экскаватор и перекопает коммуникации, откажет коммутатор, сетевики совершат непреднамеренный теракт в процессе настройки своего оборудования, ядро свалится в kernel panic. Как «все реки текут вниз», так и все отказы приводят к одному и тому же финалу: offline OSD => start OSD => PG peering => Recovery.
amarao
30.11.2018 17:15Фирмваря умной розетки решила, что потребности в электричестве больше нет. Или блоки питания не подружились друг с другом.
scruff
30.11.2018 07:02Таки без SWAP-a совсем не здорово. Можно настроить swapeness таким образом, что свап будет использоваться только в том случае когда с RAM совсем беда, здесь есть хоть какая-то вероятность, что нода не ляжет.
blind_oracle
30.11.2018 10:39К сожалению swapinness не панацея. У меня есть сервер на котором 80% памяти это пейдж кеш т.е. свободно но ядро даже при нуле сваппинесс свапит еще как.
scruff
30.11.2018 11:23Как вариант демонтировать swap из системы совсем. За возможность это осуществить, а также за последствия ручаться не могу.
blind_oracle
30.11.2018 12:11На большинстве серверов у меня он и так отключен — так безопаснее. Особенно в кластерной среде, когда тупящая нода хуже дохлой.
Этот же — личный сервер, на котором в некоторых случаях (очень редких) возможен всплеск потребления памяти, поэтому пока не отключаю.
Меня просто удивляет невозможность заставить систему не свапить при наличии большого объема page cache и\или свободной памяти. По идее ручка vm.swappiness как раз призвана регулировать это поведение, но судя по всему она носит рекомендательный характер :)scruff
30.11.2018 12:27С «крутилкой» swappiness согласен с вами. Её метрики вообще не прослеживаются. Недавно настраивал 1С+PostreSQL+CentOS на весьма дряблой виртуалке. Так вот при создании чистой БД установщик жаловался на нехватку RAM и «затыкался». В swappiness, были «попробованы» цифры 50,60,80,90....98,99 — не помогало пока не поставил 100, т.е. предельное значение, когда система свапит всё, что можно. И только тогда, скрежеча винчестером, установка завершилась. Поэтому, образно весь swapiness можно привести только к двум состояниям — вкл и выкл, без каких либо промежуточных.
blind_oracle
30.11.2018 12:44Вот тут интересный анализ поведения этой ручки и как оно изменилось после 3.15 ядра: eklitzke.org/swappiness
wild_one
30.11.2018 13:15Потому что нулевой сваппинесс — это не означает, что свапаться будет запрещено совсем.
Поэтому если нужно старое поведение ядер до 3.15 — ставим свопность в 1.blind_oracle
30.11.2018 13:40+1Потому что нулевой сваппинесс — это не означает, что свапаться будет запрещено совсем.
Никто и не ожидает что оно не будет свапиться вообще. Но я ожидаю что пока у меня page cache дофига еще то оно не будет свапиться, а это не так:
# free -h total used free shared buff/cache available Mem: 15G 2.5G 417M 35M 12G 12G Swap: 14G 1.1M 14G
1.1Мб все равно уже в свапе и это через полчаса после того как я сделал swapoff/swapon. Через сутки там уже будет метров 300-500.
Поэтому если нужно старое поведение ядер до 3.15 — ставим свопность в 1.
Не влияет. Картина выше как раз с:
# sysctl vm.swappiness vm.swappiness = 1
При 12Гб доступной памяти ядро все равно упорно лезет в свап.
# uname -a Linux ams 4.4.0-138-generic #164-Ubuntu SMP Tue Oct 2 17:16:02 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
Naves
30.11.2018 09:155 лет прошло, а ceph все так же не хватает памяти. Что можно сделать людям, у которых есть много серверов с большими дисками, но нет памяти. Как пример комментарий
Ну кроме варианта продать все и забыть.blind_oracle
30.11.2018 16:01Что можно сделать людям, у которых есть много серверов с большими дисками, но нет памяти.
Собрать RAID60 из дисков со всех серверов, подключенных по iSCSI :)
Да, будет SPOF, но можно довольно быстро собрать тот же RAID на другом сервере кластера при гибели первого.amarao
30.11.2018 17:14-1Консистентность данных? Split brain? «Не, не слышали» (сказало левое полушарие), «не, не слышали, но я обновлю запись» (сказало правое полушарие).
blind_oracle
01.12.2018 12:42Вообще это шутка была — такое вываливать в прод мне бы в голову не пришло :)
Но консистентность там ровно такая же как в рейде с локальными дисками. Если нет буфферизации записи на сетевом (ISCSI/FCoE/NBD) уровне — тут уже зависит от настроек таргета.
Еще можно сделать DRBD9 — он умеет >2 реплик, собрать какую-нибудь хитрую конфигурацию.
SergeyMax
30.11.2018 17:40Можно диски собрать в lvm и засунуть в pacemaker, тогда spof вообще не будет.
blind_oracle
01.12.2018 21:25+1SPOF будет в любом случае, просто с пейсмейкером после помирания SPOF он его мигрирует на живую ноду. Но пока это будет происходить — массив будет недоступен.
SergeyMax
02.12.2018 00:08SPOF будет в любом случае
Разумеется нет. Active-Passive резервирование — это тоже fault-tolerant решение.
Но пока это будет происходить — массив будет недоступен.
С учётом того, что драйвер дисковой системы обычно ждёт ответа 30-60 секунд до того, как поднимет ошибку в приложение — переключение может быть произведено вполне прозрачно для клиентов.blind_oracle
02.12.2018 00:14Зависит от терминологии и скорости переключения. На мой взгляд, если клиенты не замечают отказа — то SPOF нет.
В данном же случае непонятны условия эксплуатации и миграции, и в каких случаях будут проблемы у клиентов.SergeyMax
02.12.2018 00:19Чтобы не было разногласий в терминологии — предлагаю пользоваться общеупотребимой. А в ней вообще никакого упоминания скорости переключения нет)

q2digger
30.11.2018 12:18Слушайте, отличный доклад. Читается как детектив. И вот вопрос от человека который с Ceph не работает. При таких проблемах в случае выхода из строя (отключения) части OSD, как это хозяйство вообще штатно-то выключается? весь кластер.
Вот ситуация — приходит грустный электрик и говорит, ребята завтра город будет кабель менять вводный, извините на полдня выключает нас. А дизеля у нас нет, и мы готовимся просто потушиться на это время. Как это штатно сделать — и главное как после этого взлететь чтобы и данные не деградировали и волосы на теле не поседели…gecube
30.11.2018 13:35Отличный вопрос! Меня тоже очень интересует штатная работа такой балалайки. Или предполагается что все живут в отказоустойчивых ЦОДах? А как насчет того, что даже яндекс отключает в рамках учений один из нескольких своих ЦОДов?
blind_oracle
30.11.2018 13:44Отключаешь всех клиентов от кластера и следуешь ceph.com/planet/how-to-do-a-ceph-cluster-maintenance-shutdown
gecube
30.11.2018 14:31бедные клиенты. А прозрачно-то никак не сделать?
blind_oracle
30.11.2018 14:35+1Ну вводная у оратора выше — отключение всего ДЦ, поэтому тут на клиентов Ceph, я думаю, плевать. Если же нужно выключить, допустим, одну стойку, то можно просто повыкидывать OSD из кластера docs.ceph.com/docs/master/rados/operations/add-or-rm-osds и дождаться окончания ребалансировки. Затем добавить обратно.
Я думаю это будет безболезненнее чем просто отключать OSD и держать кластер в деградированном состоянии.
outlingo
30.11.2018 16:51выставляем на кластере флаги noout (обязательно)
делаем shutdown / suspend клиентов (нет клиентов — нет нагрузки — нет дегрейдов — не будет рекавера)
опционально — делаем osd nodown
шатдауним сеф
обратное включение:
включаем оборудование
дожидаемся что все osd запустились
снимаем noout (и nodown если он стоял)
запускаем клиентовq2digger
30.11.2018 16:54Спасибо! Вместе с приведенными выше ссылками исчерпывающе отвечает на мой вопрос.
eostapets
30.11.2018 18:25ceph osd set noout чтобы предотвратить перебалансировку в ходе поочередного shutdown узлов, после удачного старта ceph osd unset noout.
amarao
30.11.2018 17:11+1Супердоклад. Что делать понятно, но рассказ о том, что происходило — бесценно.
Palamar
30.11.2018 18:25Где можно подробней почитать о CEPH.При попытке что то настроить возникает куча вопросов на которые нет ответа.
К примеру сколько нод нужно для организации ceph? Возможно ли чтоб ноды были с разными дисками? На proxmox стоит ли его поднимать? Нужен ли raid при настройке ceph?
Буду благодарен за помощь, начальство дало задачу слепить из хранилищ ceph, а как это организовать мало информации.Спасибо.Naves
30.11.2018 19:04В официальной документации же есть ответы.
pve.proxmox.com/pve-docs/chapter-pveceph.html
Если у вас уже стоит проксмокс, то лучше поднимать на нем, в нем уже есть удобный мониторинг и управление. Убедитесь только, что оперативной памяти хватит всем виртуалкам и хранилищу, и что у вас есть отдельная сеть для обмена данных.
Минимум три ноды, что для самого проксмокса, что для хранилища.
Диски можно разные, но желательно, чтобы не было перекоса по суммарному объему на нодах.
Для дисков хранилища рейд не нужен.
johndow
30.11.2018 19:27Делали мы миникластер из трёх нод на проксмоксе. Кое как запустили, вроде работает, через какое-то время одна года вылетела по железу — вроде работает, порадовались, починили железо, включили и прилегло всё намертво на восстановлении :(
Opik
30.11.2018 18:36А что за легенда о Cloudmouse? Она гласит о том, что не нужно включать опции yesIwantEnableThisDangerousFeature=1?
a5b
30.11.2018 18:37Ответ, почему же так произошло, кроется в Linux’овом malloc’е.
Только вот ceph использует другие реализации malloc — gperftools tcmalloc или jemalloc (https://www.msi.umn.edu/sites/default/files/MN_RH_BOFSC15.pdf https://ceph.com/geen-categorie/the-ceph-and-tcmalloc-performance-story/ https://github.com/ceph/ceph/blob/1ade7149106cfe12ed7af16edd609bdd0e561708/CMakeLists.txt#L339).
"specify memory allocator to use. currently tcmalloc, tcmalloc_minimal, \
jemalloc, and libc is supported. if not specified, will try to find tcmalloc, \
and then jemalloc. If neither of then is found. use the one in libc."Они умеет агрессивно отдавать все свободные страницы (из середины кучи, арены, или иной структуры учета памяти) обратно в ОС (через MADV_FREE или MADV_DONTNEED) — http://man7.org/linux/man-pages/man2/madvise.2.html
MADV_DONTNEED
Do not expect access in the near future. (For the time being,
the application is finished with the given range, so the
kernel can free resources associated with it.)
…
The kernel is free to delay freeing the pages until an
appropriate moment. The resident set size (RSS) of the
calling process will be immediately reduced however.
MADV_FREE (since Linux 4.5)
The application no longer requires the pages in the range
specified by addr and len. The kernel can thus free these
pages, but the freeing could be delayed until memory pressure
occurs.outlingo
30.11.2018 19:32Ага. Но ему это не слишком помогает. Либо куча фрагментирована либо еще что то. И jemalloc не используют. В определенных условиях оно крашит осд через несколько часов работы
a5b
30.11.2018 20:26Насколько я помню, для многих размерных классов tcmalloc группирует несколько страниц памяти для хранения объектов одного размерного класса (span, http://goog-perftools.sourceforge.net/doc/tcmalloc.html Set of Small Chunks gperftools/src/span.h Span.sizeclass; к "small" относит все что <= 32Кб), за счет чего фрагментация может несколько уменьшится. В отличие от glibc, где malloc экономит байты и смешивает все размеры, в tcmalloc внутри одной страницы все объекты имеют один размер, и, часто, сходные времена жизни.
Либо цеф просто слишком много навыделял. Полезно проверить профиль памяти — http://docs.ceph.com/docs/master/rados/troubleshooting/memory-profiling/ (в профиль попадают выделения памяти, совершенные после запуска профилирования).
Кто-нибудь пробовал ceph с glibc malloc?
le1ic
Ну как бы это сказать… Если вероятность вылета одного домена условно константа (скажем вероятность вылета питания, TOR свича), то при N доменах вероятность хоть одной аварии будет примерно в N раз выше. Да, как сказано в статье, аварии будут «меньше» – кластер быстрее восстанавливаться будет, но делать он это будет в N раз чаще
B0B
Вопрос к пользователям крупных ceph кластеров: а у вас нет проблем с таймаутами на клиентах во время ребаланса или подобных внутренних процессов кластера?
Порой количество таймаутов по блок девайсам (в ВМ virtio-scsi) просто зашкаливало. Кластерам перконы от такого оочень печально. В итоге похоронили саму идею довести кластер до приемлемого уровня производительности и просто ушли на покупной солюшн с ceph-a.
ultral
Не сказал бы, что тут прямая корреляция от размера кластера. Большее влияние оказывает
1. сеть
2. размер объектов
3. активность записи
B0B
1. утилизация не превышала и 10%
2. тут точно не отвечу
3. действительно высокая (простите, без цифр, только анатомия): именно на запись, т.к. базы весьма активно пишут данные (очень много insert/update запросов). Чтение не было проблемой — обычно валилось на записи
azmar
Почти год я с ними боролся, и моя история успеха с ceph крайне похожа на вашу. Масла в огонь еще добавляло то, что когда они происходят, systemd на ВМ считает что нужно уйти в emergency mode, из которого их нужно руками выводить. И происходило это не только на ребалансе, а еще иногда и на deep-scrub.
Короче говоря, с тех пор как мы отказались от цефа, жить стало намного проще и приятнее.