
Все мы пользуемся каким-либо видом пакетных менеджеров, включая уборщицу тетю Галю, у которой в кармане прямо сейчас обновляется айфон. Но общего соглашения о функциях пакетных менеджеров нет, и стандартные для ОС rpm и dpkg, и системы сборки называют пакетными менеджерами. Предлагаем поразмышлять на тему их функций — что это такое и для чего они нужны в современном мире. А потом будем копать в сторону Kubernetes и внимательно рассмотрим Helm с точки зрения этих функций.
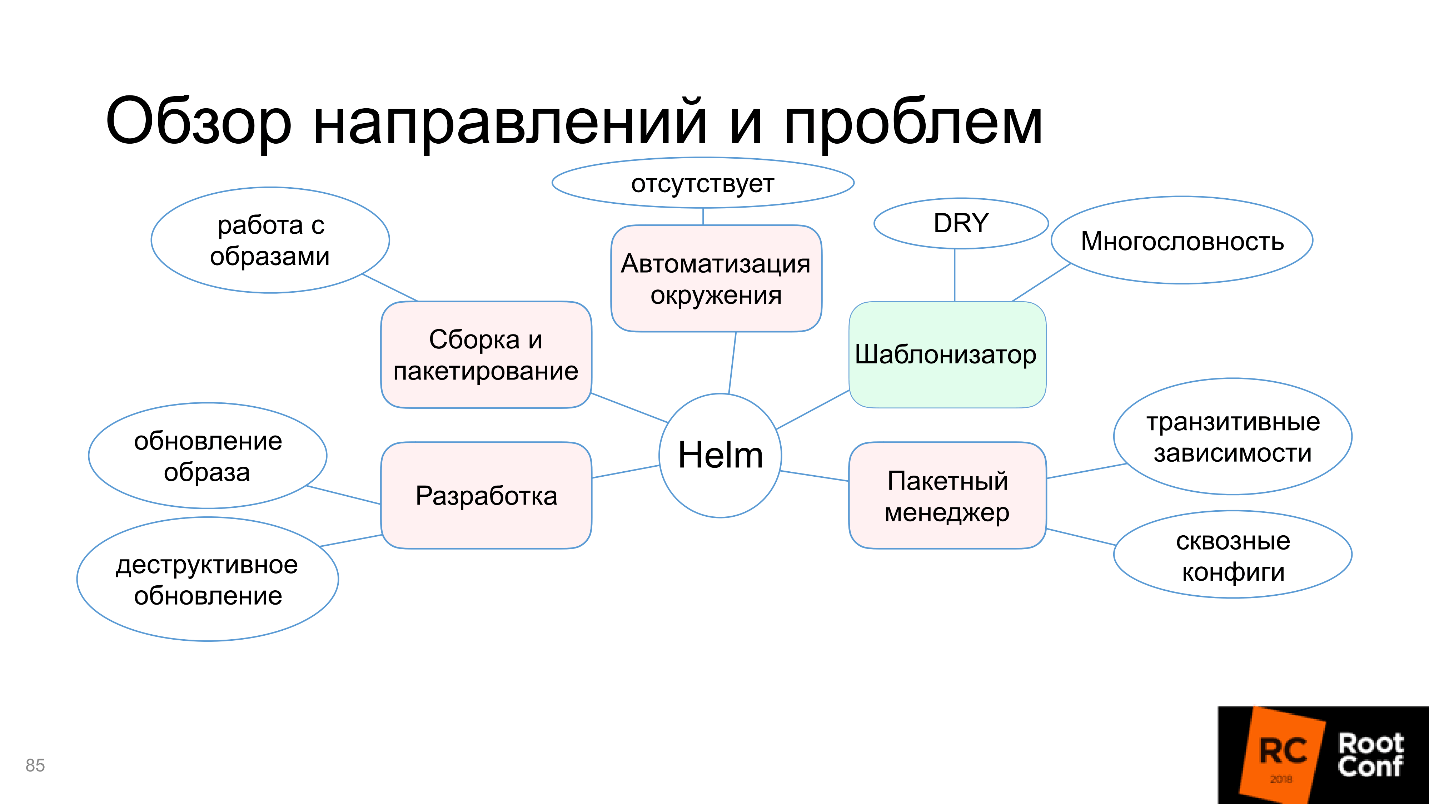
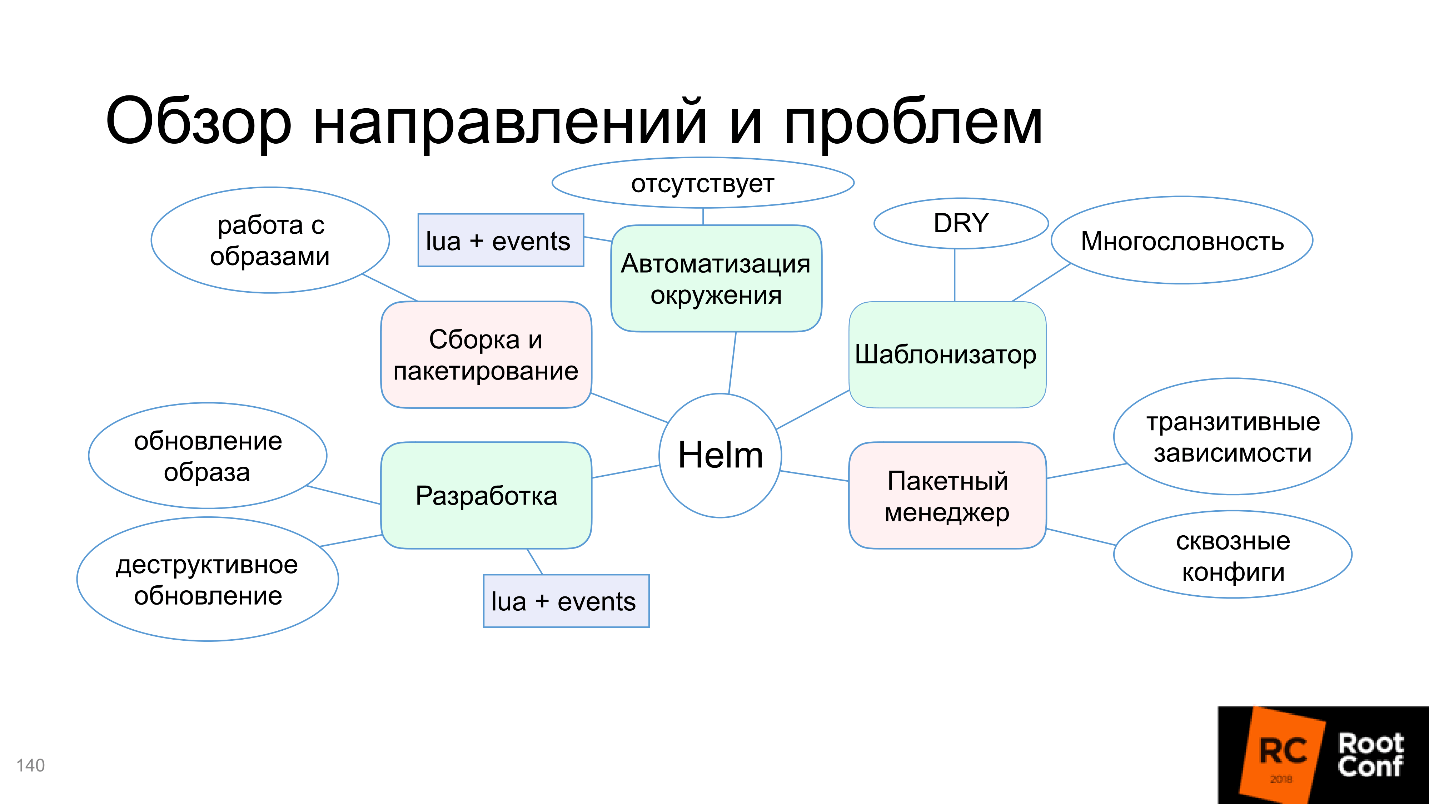
Разберемся, почему на этой схеме только функция шаблонизатора выделена зеленым, и в чем проблемы со сборкой и пакетированием, автоматизацией окружения и прочим. Но не беспокойтесь, статья не закончится на том, что все плохо. Сообщество не могло с этим смириться и предлагает альтернативные инструменты и решения — разберемся и с ними.
Помог нам в этом Иван Глушков (gli) своим докладом на РИТ++, видео и текстовая версия этого подробного и обстоятельного выступления ниже.
О спикере: Иван Глушков разрабатывает ПО уже 15 лет. Успел поработать в MZ, в Echo над платформой для комментариев, поучаствовать в разработке компиляторов для процессора Эльбрус в MCST. Сейчас занимается инфраструктурными проектами в Postmates. Иван один из ведущих подкаста DevZen, в котором рассказывают и о наших конференциях: здесь есть о РИТ++, а здесь о HighLoad++.
Пакетные менеджеры
Хотя все используют какие-либо виды пакетных менеджеров, единого соглашения, что это такое, нет. Есть общее понимание, и у каждого оно свое.
Давайте вспомним, какие виды пакетных менеджеров первым делом приходят в голову:
Главная их функция — выполнение команд установки пакета, обновления пакета, удаления пакета, управление зависимостями. В пакетных менеджерах внутри языков программирования, все немного сложнее. Например, есть команды вида «запустить пакет» или «создать релиз» (build/run/release). Получается, что это уже система сборки, хотя мы тоже называем это пакетным менеджером.

Все это только из-за того, что нельзя просто взять и… пусть простят любители Haskell это сравнение. Можно запустить бинарный файл, но нельзя запустить программу на Haskell или на C, сначала нужно ее каким-то образом подготовить. И подготовка эта довольно сложная, а пользователи хотят, чтобы все делалось автоматически.
Развитие
Тот, кто работал с GNU libtool, который сделан для большого проекта, состоящего из большого количества компонент, тот в цирке не смеется. Это действительно очень сложно, и некоторые случаи принципиально нельзя разрешить, а можно только обойти.
По сравнению с ним современные пакетные менеджеры языков типа cargo для Rust, гораздо удобнее — вы нажимаете кнопку и все работает. Хотя фактически под капотом решается большое количество проблем. При этом все эти новые функции требуют чего-то дополнительного, в частности, базы данных. Хотя в самом пакетном менеджере она может называться как угодно, я называю ее базой данных, т.к. там хранятся данные: об установленных пакетах, об их версиях, подключенных репозиториях, версиях в этих репозиториях. Все это обязательно должно где-то храниться, поэтому есть внутренняя база данных.
Разработка на этом языке программирования, тестирование для этого языка программирования, запуски — все это встроено и находится внутри, работа становится очень удобной. Большинство современных языков поддержали такой подход. Даже те, что не поддержали, начинают поддерживать, потому что сообщество давит и говорит, что в современном мире без этого невозможно.
Но у любого решения всегда есть не только плюсы, но и минусы. Здесь минусом является то, что необходимы обертки, дополнительные утилиты и встроенная «база данных».
Docker
Как бы нет, но по сути да. Я не знаю более правильной утилиты для того, чтобы полностью поставить приложение вместе со всеми зависимостями, и чтобы оно заработало по нажатию на одну кнопку. Что это, как не пакетный менеджер? Это замечательный пакетный менеджер!
Максим Лапшин уже рассказывал, что с Docker стало гораздо проще, и это так. У Docker есть встроенная система сборки, все эти базы данных, обвязки, утилиты.
Какова же цена всех преимуществ? Те, кто работает с Docker, мало задумываются о промышленном применении. У меня есть такой опыт, и цена, на самом деле, очень высокая:
Например, у меня была задача перевести одну программу на использование Docker. Программу разрабатывала сложившаяся годами команда. Я прихожу, мы делаем все, что написано в книжках: расписываем users stories, роли, смотрим, что и как они делают, их стандартные рутины.
Я говорю:
— Все ваши проблемы может решить Docker. Смотрите, как это делается.
— Все будет по кнопке — здорово! Но мы хотим SSH делать внутри контейнеров Kubernetes.
— Подождите, не надо нигде SSH.
— Да-да, все хорошо… А SSH можно?
Для того, чтобы повернуть восприятие пользователей в новое русло, требуется очень много времени, нужна образовательная работа и много усилий.
Еще один фактор цены это то, что Docker-registry — внешний репозиторий для образов, его нужно как-то инсталлировать и контролировать. Там есть собственные проблемы, garbage collector и прочее, и он может часто падать, если за ним не следить, но это все решаемо.
Kubernetes
Наконец мы дошли до Kubernetes. Это классная OpenSource система для управления приложениями, которая активно поддерживается сообществом. Хотя она изначально вышла из одной компании, сейчас у Kubernetes огромное сообщество, и угнаться за ним невозможно, альтернатив практически нет.
Интересно, что все узлы Kubernetes работают в самом Kubernetes через контейнеры, и все внешние приложения работают через контейнеры — всё работает через контейнеры! Это и плюс, и минус.
У Kubernetes есть много полезной функциональности и свойств: распределенность, отказоустойчивость, возможность работать с разными облачными сервисами, ориентация на микросервисную архитектуру. Все это интересно и здорово, но как в Kubernetes установить приложение?
Как установить приложение?
За этой фразой скрывается бездна. Вы представляете себе — у вас есть приложение, написанное, скажем, на Ruby, и вы должны Docker-образ положить в Docker-registry. Это значит, вы должны:
На самом деле это большая-большая боль в одной строчке.
Плюс еще нужно описать манифесты приложения в терминах (ресурсах) k8s. Самый простой вариант:

На слайде Ганди потирает руки — похоже, я нашел пакетный менеджер в Kubernetes. Но kubectl — это не пакетный менеджер. Он просто говорит, что я хочу видеть вот такое конечное состояние системы. Это — не установка пакета, не работа с зависимостями, не сборка — это просто «я хочу видеть это конечное состояние».
Helm
Наконец мы подошли к Helm. Helm — это многоцелевая утилита. Сейчас мы рассмотрим, какие направления развития Helm и работы с ним есть.
Шаблонизатор
Во-первых, Helm — это шаблонизатор. Мы обсуждали, что нужно подготовить ресурсы, и проблема — написать в терминах Kubernetes (можно и не только в yaml). Самое интересное, что это статические файлы для вашего конкретного приложения в этом конкретном окружении.
Однако, если вы работаете с несколькими окружениями и у вас есть не только Production, а еще Staging, Testing, Development и разные окружения для разных команд, нужно иметь несколько подобных манифестов. Например, потому что в одном из них несколько серверов, и нужно иметь большое количество реплик, а в другом — только одну реплику. Там нет базы данных, доступа к RDS, и нужно установить PostgreSQL внутрь. А тут у нас старая версия, и нужно немного все переписать.
Все это многообразие приводит к тому, что вы должны взять ваш манифест для Kubernetes, везде его скопировать и везде подправить: здесь подменить одну цифру, здесь еще что-нибудь. Это становится очень неудобно.
Решение простое — надо ввести шаблоны. То есть вы формируете манифест, в нем определяете переменные, а потом определенные снаружи переменные подаете в виде файла. Шаблон создает конечный манифест. Получается переиспользование одного и того же манифеста для всех окружений, что гораздо удобнее.
Для примера манифест для Helm.

Простейшая команда запуска для того, чтобы установить chart — helm install ./wordpress (папка). Чтобы переопределить какие-то параметры, говорим: «Я хочу переопределить именно эти параметры и задать такие-то значения».
Helm справляется с этой задачей, поэтому на схеме отметим её зеленым.
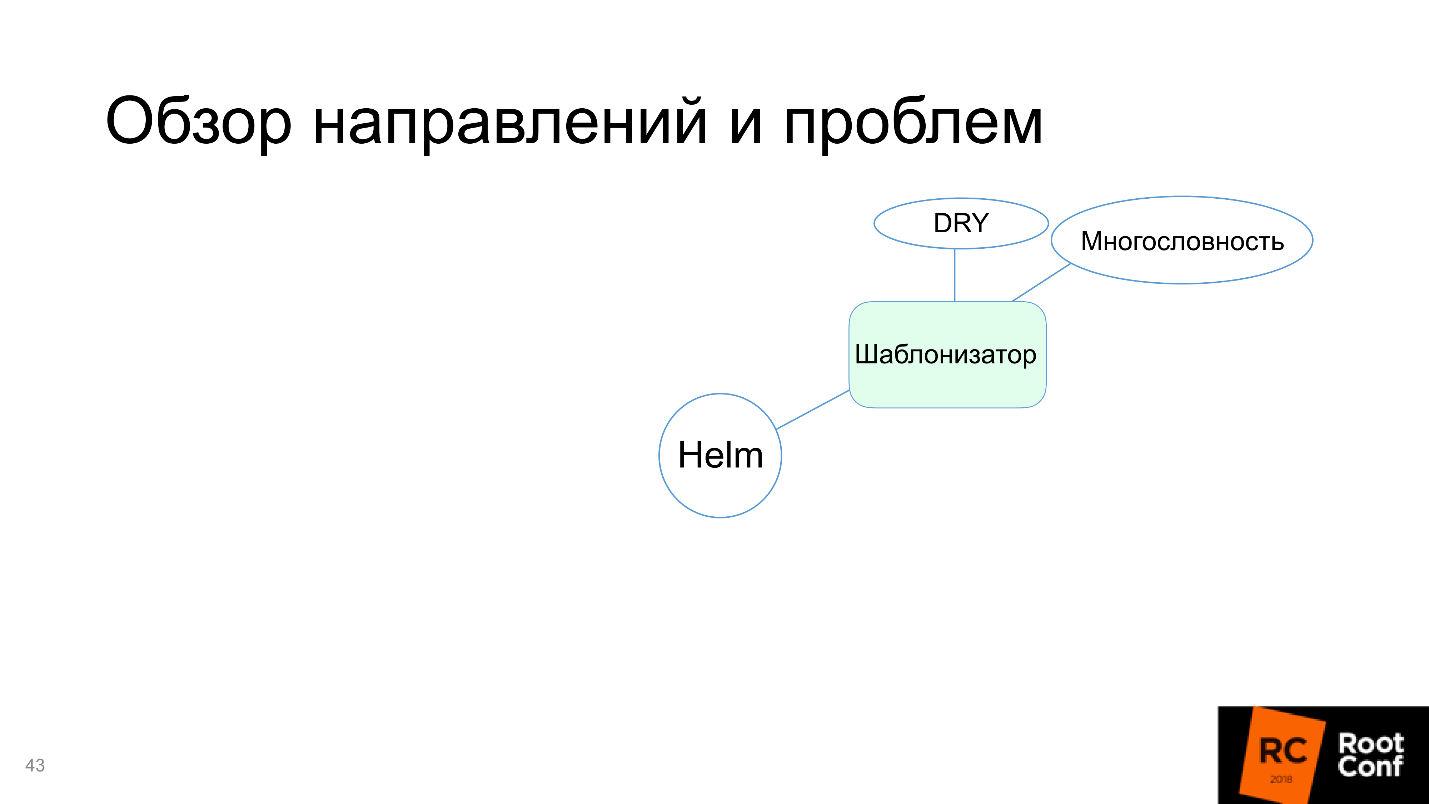
Правда появляются минусы:
Прежде, чем окунуться в направление Helm — пакетный менеджер, ради чего я все это рассказываю, давайте разберемся, как Helm работает с зависимостями.
Работа с зависимостями
С зависимостями Helm работает сложно. Во-первых, есть файл requirements.yaml, в который вписывается то, от чего мы зависим. Во время работы с requirements, он делает requirements.lock — это текущее состояние (слепок) всех зависимостей. После этого он их скачивает в папку с названием /charts.
Есть инструменты, для того чтобы управлять: кого, как, куда подключать — tags и conditions, с помощью которых определяется, в каком окружении, в зависимости от каких внешних параметров подключать или не подключать какие-то зависимости.
Скажем, у вас есть PostgreSQL для окружения Staging (или RDS для Production, или NoSQL для тестов). Устанавливая этот пакет в Production, вы не установите PostgreSQL, потому что он там не нужен — как раз с помощью tags и conditions.
Что здесь интересно?
После того, как мы скачали все зависимости в /charts (этих зависимостей может быть, например, 100), Helm внутри себя берет и копирует все ресурсы. После того, как он отрендерил шаблоны, он собирает все ресурсы в одном месте и сортирует в каком-то своем собственном порядке. Вы не можете повлиять на этот порядок. Вы должны сами определить, от чего зависит ваш пакет, и если пакет имеет транзитивные зависимости, то необходимо их все включить в описание в requirements.yaml. Это надо иметь в виду.
Пакетный менеджер
Helm устанавливает приложения и зависимости, и вы можете сказать Helm install — и он установит пакет. Значит это пакетный менеджер.
Одновременно, если у вас есть внешний репозиторий, в который вы закачиваете пакет, вы можете обращаться к нему не как к локальной папке, а просто сказать: «Из этого репозитория возьми этот пакет, установи его с такими-то параметрами».
Есть открытые репозитории с большим количеством пакетов. Например, можно запустить: helm install -f prod/values.yaml stable/wordpress
Из репозитория stable вы возьмете wordpress и установите к себе. Можно делать все: search / upgrade / delete. Получается, действительно, Helm — пакетный менеджер.
Но есть минусы: все транзитивные зависимости необходимо включать внутрь. Это большая проблема, когда транзитивные зависимости — это независимые приложения, и вы хотите с ними отдельно работать для тестирования и разработки.
Еще один минус — сквозное конфигурирование. Когда у вас есть база данных и ее имя нужно передать во все пакеты, это можно, но сложно сделать.

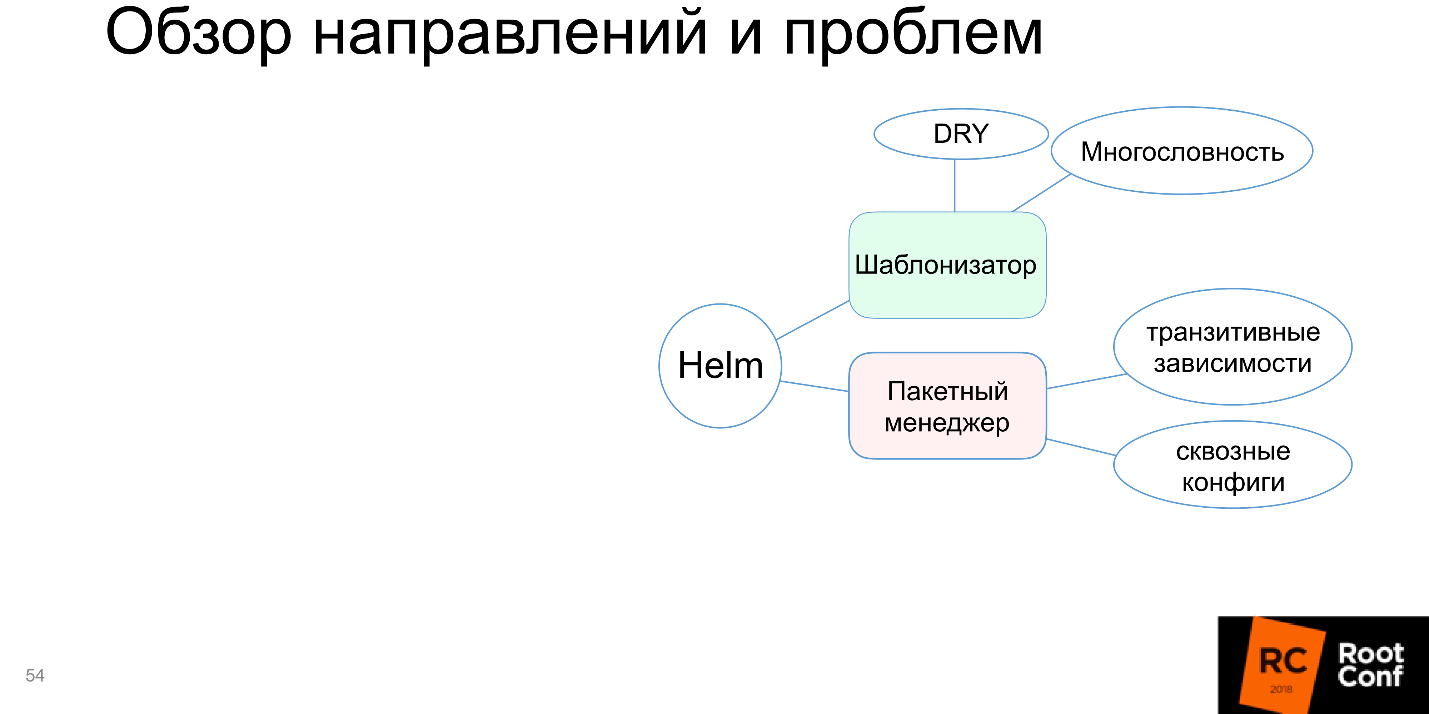
Чаще всего не бывает так, что вы установили один маленький пакетик, и он работает. Мир сложный: приложение зависит от приложения, которое в свою очередь тоже зависит от приложения — вам надо их как-то хитро сконфигурировать. Helm не умеет это поддерживать, или поддерживает с большими проблемами, и иногда приходится много плясать с бубном, чтобы все заработало. Это плохо, поэтому «пакетный менеджер» на схеме выделяем красным.
Сборка и пакетирование
«Нельзя просто взять и» запустить приложение в Kubernetes. Нужно его собрать, то есть сделать Docker-образ, записать в Docker-registry и т.д. Хотя все определение пакета в Helm есть. Мы определяем, что такое пакет, какие там функции и поля должны быть, подписи и проверка подлинности (система безопасности вашей компании будет очень рада). Поэтому, с одной стороны, сборка и пакетирование вроде поддерживается, а с другой — не настроена работа с Docker-образами.
Это то же самое, как если бы, чтобы сделать upgrade install для какой-нибудь маленькой библиотеки, вас отправляли бы в дальнюю папку запускать компилятор.
Поэтому мы и говорим, что Helm не умеет работать с образами.

Разработка
Следующая головная боль — это разработка. В разработке мы хотим быстро и удобно изменять наш код. Прошло время, когда вы на перфокартах набивали дырочки, а результат получали через 5 дней. Все привыкли, что заменяешь в редакторе одну букву на другую, нажимаешь компиляцию, и уже измененная программа работает.
Здесь же получается, что при изменении кода нужна масса дополнительных действий: подготовить Docker-файл; запустить Docker, чтобы он собрал образ; куда-то его запушить; развернуть в Kubernetes-кластере. И только тогда вы получите то, что вы хотите на Production, и сможете проверить работу кода.
Еще возникают неудобства из-за деструктивного обновления helm upgrade. Вы посмотрели, как все работает, через kubectl exec заглянули внутрь контейнера, все хорошо. В этот момент вы запускаете обновление, скачивается новый образ, запускаются новые ресурсы, а старые удаляются — надо все начинать с самого начала.
Самая большая боль — это большие образы. В большинстве компаний не работают с маленькими приложениями. Часто это если не супермонолит, то хотя бы маленький монолитик. Со временем нарастают годовые кольца, увеличивается объем кодовой базы, и постепенно приложение становится довольно большим. Я не раз сталкивался с Docker-образами размером больше 2 Гб. Представьте теперь, что вы делаете изменение одного байта в вашей программе, нажимаете кнопку, и начинает собираться двухгигабайтный Docker-образ. Потом вы нажимаете следующую кнопку, и начинается передача 2 Гб на сервер.
Docker позволяет работать со слоями, т.е. проверяет есть там тот или иной слой и отправляет недостающий. Но мир таков, что чаще всего это будет один большой слой. Пока 2 Гб уйдут на сервер, пока они с Docker-registry придут на Kubernetes, раскатаются по всем подам, пока вы наконец запустите — можно спокойно чай попить.
В работе с большими Docker-образами Helm не предполагает никакой помощи. Я считаю, что такого быть не должно, но разработчики Helm знают лучше, чем все пользователи, и Стив Джобс улыбается этому.

Блок с разработкой тоже окрасился в красный.
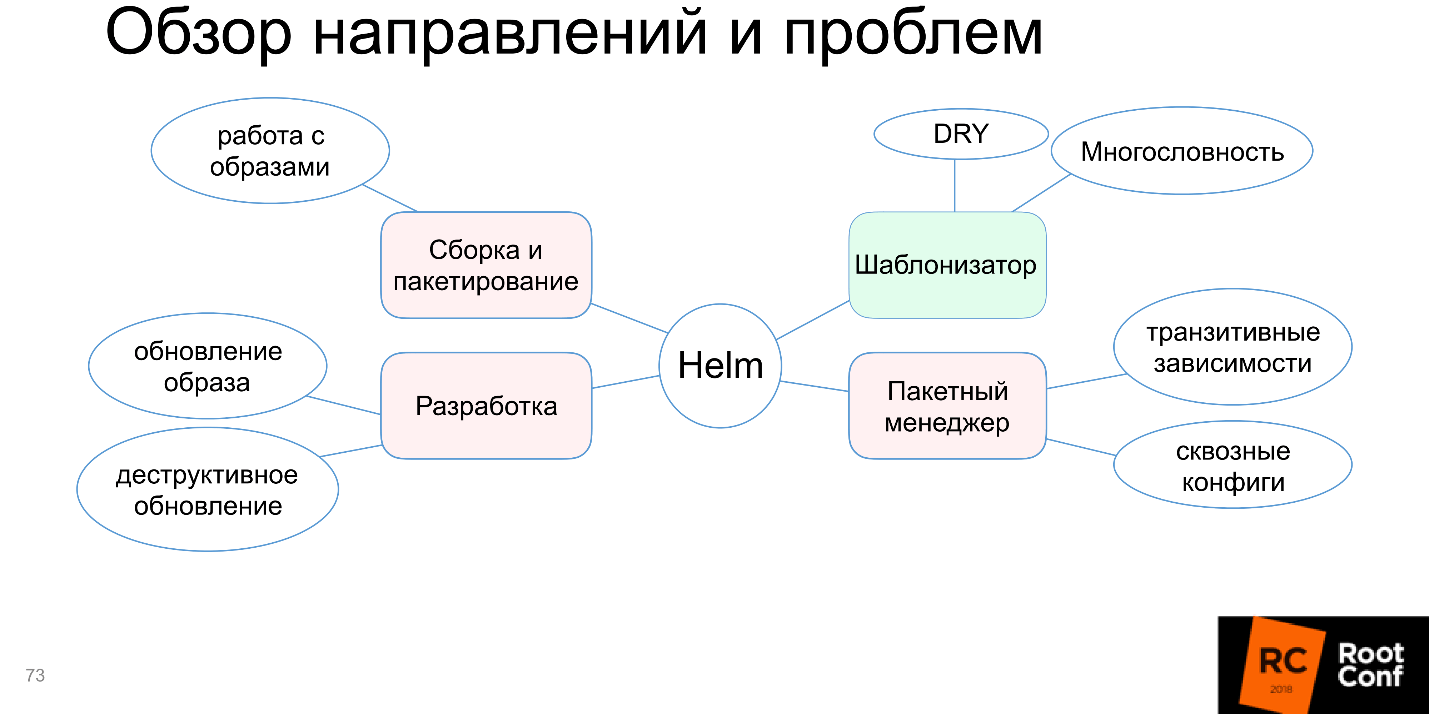
Автоматизация окружения
Последнее направление — автоматизация окружения — интересная область. До мира Docker (и Kubernetes, как связанной модели) не было возможности сказать: «Я хочу установить свое приложение на этот сервер или на эти серверы, чтобы там было n реплик, 50 зависимостей, и все это автоматически заработало!» Такое, можно сказать, что было, но не было!
Kubernetes это предоставляет и логично как-то этим пользоваться, например, сказать: «Я тут разворачиваю новое окружение и хочу, чтобы все команды разработки, которые приготовили свои приложения, просто могли нажать кнопочку, и все эти приложения автоматически бы установились на новое окружение». Теоретически Helm должен в этом помогать, чтобы при этом конфигурация могла быть взята из внешнего источника данных — S3, GitHub — откуда угодно.
Желательно, чтобы в Helm была специальная кнопка «Сделай мне хорошо уже наконец!» — и оно сразу становилось бы хорошо. Kubernetes позволяет это делать.
Особенно удобно это, потому что Kubernetes можно запускать где угодно, и он работает через API. Запуская minikube локально, или в AWS, или в Google Cloud Engine, вы получаете Kubernetes прямо из коробки и везде работаете одинаково: нажимаете кнопку, и сразу всё хорошо.
Казалось бы, естественно Helm позволяет это делать. Потому что иначе, в чем вообще был смысл создавать Helm?
Но оказывается, нет!
Автоматизация окружения отсутствует.
Альтернативы
Когда есть приложение от Kubernetes, которое все используют (это сейчас по факту решение номер 1), но при этом Helm имеет рассмотренные выше проблемы, сообщество не могло не ответить. Оно начало создавать альтернативные инструменты и решения.
Шаблонизаторы
Казалось бы, как шаблонизатор, Helm решил все проблемы, но все равно сообщество создает альтернативы. Напомню проблемы шаблонизатора: многословность и переиспользование кода.
Хороший представитель здесь — Ksonnet. Он использует принципиально другую модель данных и концепций, и работает не с Kubernetes-ресурсами, а со своими собственными определениями:
prototype(params) -> component -> application -> environments.
Там есть части (parts), которые составляют прототип. Прототип параметризуется внешними данными, и появляется component. Несколько component составляют приложение, которое можно запускать. Оно запускается в разных окружениях. Некоторые понятные связи с ресурсами Kubernetes здесь есть, но прямой аналогии может и не быть.
Основной целью появления Ksonnet было, конечно, переиспользование ресурсов. Они хотели сделать так, чтобы вы, написав однажды код, в дальнейшем могли использовать его где угодно, что повышает скорость разработки. Если вы создаете большую внешнюю библиотеку, люди могут постоянно размещать там свои ресурсы, а все сообщество сможет их переиспользовать.
Теоретически это удобно. Практически я это не использовал.
Пакетные менеджеры
Проблема здесь, как мы помним — это вложенные зависимости, сквозные конфиги, транзитивные зависимости. Их Ksonnet не решает. У Ksonnet очень похожая на Helm модель, которая точно так же определяет список зависимостей в файле, он закачивается в определенный каталог и т.д. Отличие в том, что можно делать патчи, то есть вы подготавливаете папку, в которую складываете патчи для конкретных пакетов.

Когда вы закачиваете папку, эти патчи накладываются, и результат, получаемый слиянием нескольких патчей, можно начинать использовать. Плюс есть валидация конфигураций для зависимостей. Это может быть удобно, но это все еще очень сырое, документации почти нет, а версия замерла в состоянии 0.1. Думаю, что использовать его пока рано.
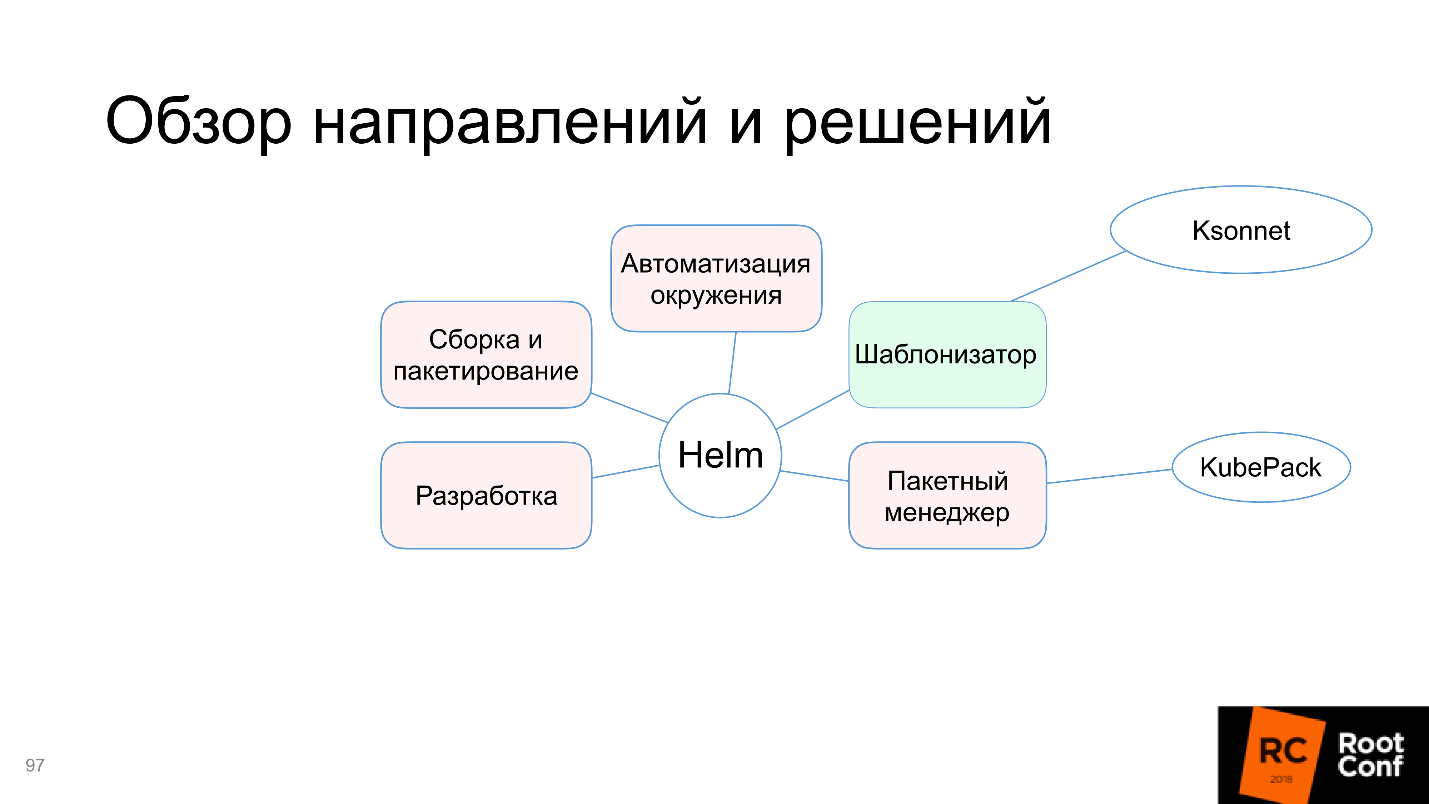
Итак, пакетный менеджер — это KubePack, и других альтернатив я пока не видел.
Разработка
Решения делятся на несколько разных категорий:
1. Разработка поверх Helm
Хороший представитель — это Draft. Его цель — возможность попробовать приложение еще до того, как закоммичен код, то есть посмотреть текущее состояние. Draft использует метод программирования — Heroku-style:
Это можно сделать в любом каталоге с кодом, вроде все быстро, легко и хорошо.
Но в дальнейшем лучше все равно начать работать с Helm, потому что Draft создает Helm-ресурсы, и когда ваш код дойдет до состояния production ready, надеяться на то, что Draft хорошо создаст Helm-ресурсы, не стоит. Вам придется все равно создавать их вручную.
Получается, что Draft нужен чтобы быстро стартануть и попробовать в самом начале до того, как вы написали хоть один Helm-ресурс. Draft — первый претендент на это направление.
2. Разработка без Helm
Разработка без Helm Charts предполагает построение тех же самых Kubernetes-манифестов, которые были бы иначе построены через Helm Charts. Предлагаю три альтернативы:
Они все очень похожи на Helm, отличия в небольших деталях. В частности, часть решений предполагает, что вы будете использовать command line interface, а Chart предполагает, что вы будете делать git push и управлять хуками.
В конце концов, вы все равно запускаете docker build, docker push и kubectl rollout. Все те проблемы, которые мы перечисляли для Helm, никак не решаются. Это просто альтернатива с теми же самыми недостатками.
3. Разработка на языке приложения
Следующая альтернатива — разработка на языке приложения. Здесь хороший пример — Metaparticle. Допустим, вы пишите код на Python, и прямо внутри Python начинаете мыслить, что вы хотите от приложения.
Если правильно описать рабочее приложение, из каких частей оно состоит, каким образом они взаимодействуют, теоретически какая-то магия поможет превратить это знание с точки зрения приложения в Kubernetes-ресурсы.
С помощью декораторов определяем: где находится репозиторий, как туда надо правильно пушить; какие есть сервисы, и как они между собой взаимодействуют; столько должно быть реплик на кластере и т.д.

Я не знаю, как вы, но лично я не люблю, когда вместо меня какая-то магия решает, что из Python-определений нужно сделать именно такой Kubernetes-конфиг. А если мне надо другое?
Все это работает до какого-то предела, пока приложение достаточно стандартное. После этого начинаются проблемы. Скажем, я хочу, чтобы до запуска основного контейнера запускался preinstall контейнер, который выполнит какие-то действия для конфигурирования будущего контейнера. Это все делается в рамках Kubernetes-конфигов, но делается ли это в рамках Metaparticle, я не знаю.
Я привожу банальные простейшие примеры, а их гораздо больше, в спецификации Kubernetes-конфигов очень много параметров. Я уверен, что они не полностью присутствуют в декораторах, подобных Metaparticle.
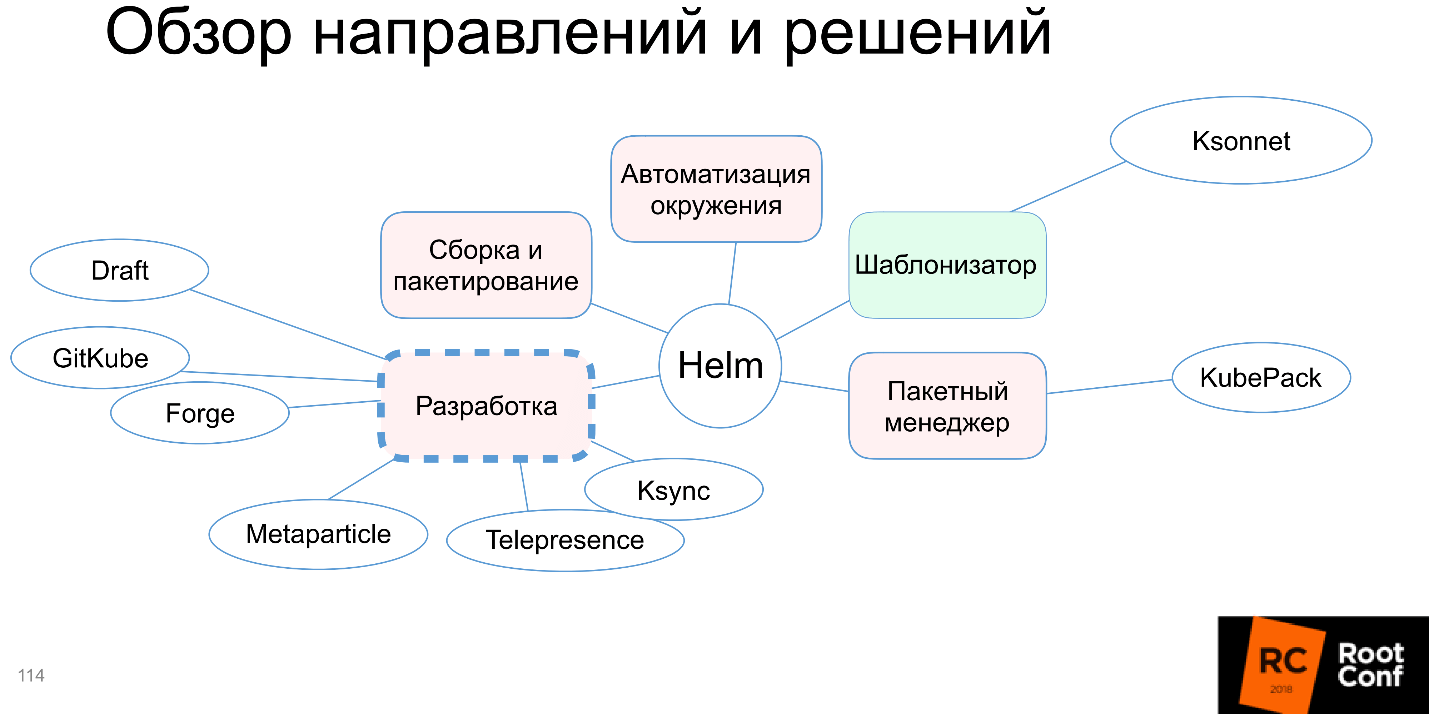
На схеме появляется Metaparticle, и мы обсудили три альтернативных Helm подхода. Однако есть дополнительные, и они очень перспективны на мой взгляд.
Telepresence/Ksync — один из них. Представим, у вас есть уже написанное приложение, есть Helm-ресурсы, которые тоже написаны. Вы установили приложение, оно запустилось где-то в кластере, и в этот момент вы хотите что-то попробовать, например, поменять одну строчку в вашем коде. Конечно, я говорю не про Production-кластеры, хотя некоторые и на Production что-то правят.
Проблема Kubernetes в том, что нужно эти локальные правки через обновление Docker, через registry, перенести в Kubernetes. Но донести до кластера одну измененную строчку можно другими способами. Можно синхронизировать локальную и удаленную папку, которая находится на поде.
Да, конечно, при этом в образе должен быть компилятор, всё необходимое для Development должно быть там на месте. Но зато какое удобство: устанавливаем приложение, меняем несколько строк, синхронизация срабатывает автоматически, на поде становится обновленный код, запускаем компиляцию и тесты — ничего не ломается, ничего не обновляется, никаких деструктивных обновлений, как в Helm, не происходит, получаем уже обновленное работающее приложение.
На мой взгляд, это отличное решение проблемы.
4. Разработка для Kubernetes без Kubernetes
Раньше мне казалось, что нет смысла работать с Kubernetes без Kubernetes. Я считал, что лучше один раз правильно сделать Helm-определения и пользоваться подходящими инструментами, чтобы в локальной разработке иметь единые конфиги для всего. Но со временем я столкнулся с реальностью и увидел приложения, для которых это сделать чрезвычайно сложно. Сейчас я пришел к выводу, что проще написать Docker-compose файл.
Когда вы делаете Docker-compose файл, вы запускаете все те же самые образы, и монтируете точно также, как в предыдущем случае, локальную папку на папку в контейнере Docker, только уже не внутри Kubernetes, а просто в Docker-compose, который запущен локально. Потом точно также запускаете компилятор, и все отлично работает. Минус в том, что необходимо иметь дополнительные конфиги для Docker. Плюсом является скорость и простота.
В моем примере я пытался запустить в minikube то же самое, что и пытался сделать с Docker-compose, и разница была громадная. Плохо работало, были непонятные проблемы, а Docker-compose — в 10 строчек поднимаешь и все работает. Так как вы работаете с теми же самыми образами, это гарантирует повторяемость.
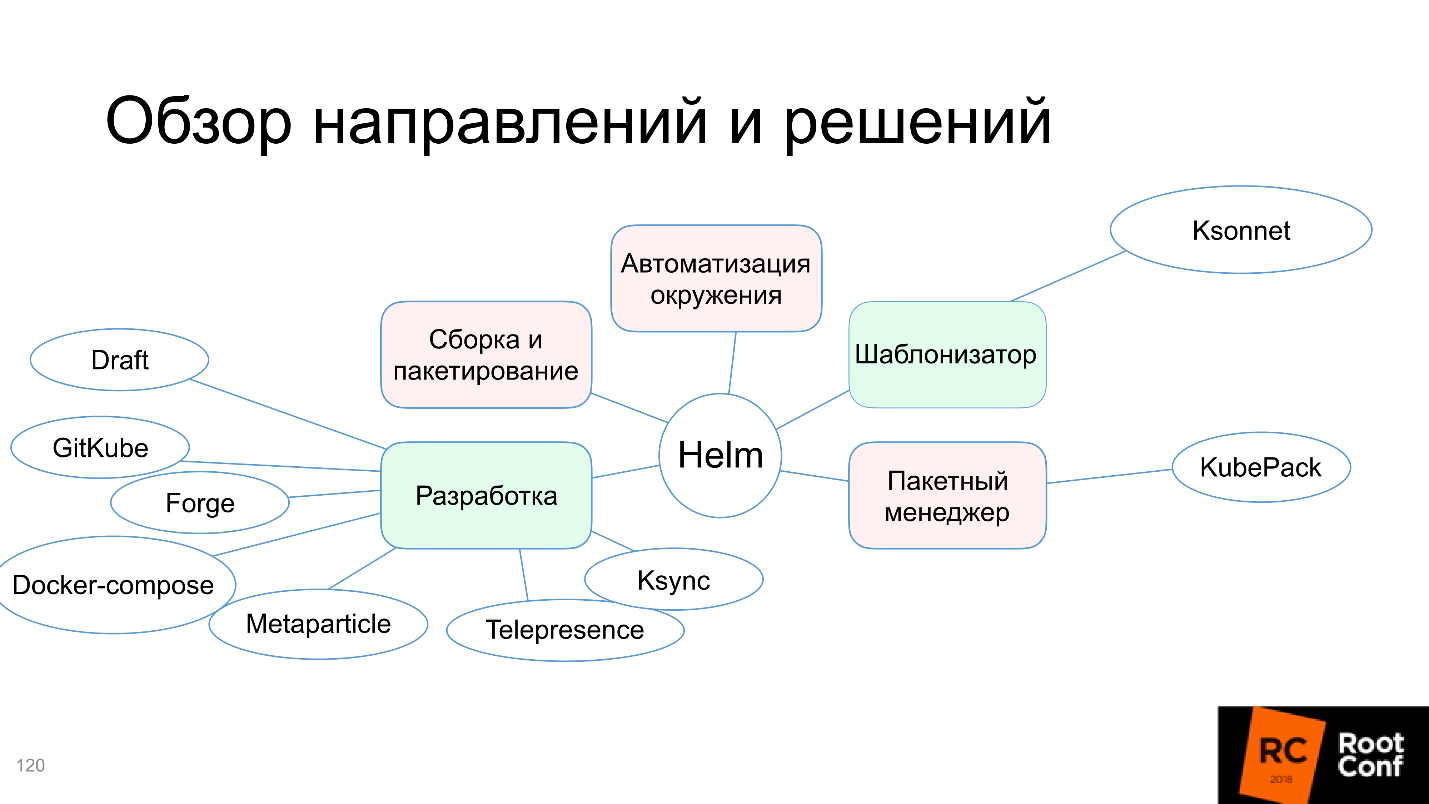
На нашу схему добавляется Docker-compose, и в целом получается, что сообщество суммарно этими всеми решениями закрыло проблему разработки.
Сборка и пакетирование
Да, сборка и пакетирование — это проблема Helm, но, наверное, разработчики Helm все-таки были правы. У каждой компании есть своя система CI/CD, которая собирает артефакты, проверяет и тестирует. Если она уже есть — зачем закрывать эту проблему в Helm, когда у каждого это свое? Возможно, одно правильное решение не получится, у каждого будут модификации.
Если у вас есть CI/CD, есть интеграция с внешним репозиторием, на каждый коммит автоматически собираются docker’ы, запускаются set-тесты, и вы можете нажать кнопку и задеплоить это все, вы решили проблему — ее не осталось.
CI/CD — это действительно решение проблемы сборки и пакетирования, и мы закрашиваем её зеленым.
Итоги

Из 5 направлений сам Helm закрывает только шаблонизатор. Сразу становится понятно, для чего его создавали. Остальные решения сообщество совместно добавило, проблемы разработки, сборки и пакетирования полностью решены внешними решениями. Это не до конца удобно, не всегда легко сделать в рамках сложившихся традиций внутри компании, но возможно, по крайней мере.
Будущее Helm
Боюсь, что никто из нас не знает наверняка, к чему Helm должен прийти. Как мы видели, разработчики Helm иногда лучше нас знают, что надо сделать. Думаю, что большинство из тех проблем, которые мы рассмотрели, не закроются ближайшими релизами Helm.
Посмотрим, что добавилось в текущий Road Map. Есть такой репозиторий Kuberneres Helm в community, в котором есть планы развития и неплохая документация на то, что будет в следующей версии Helm V3.
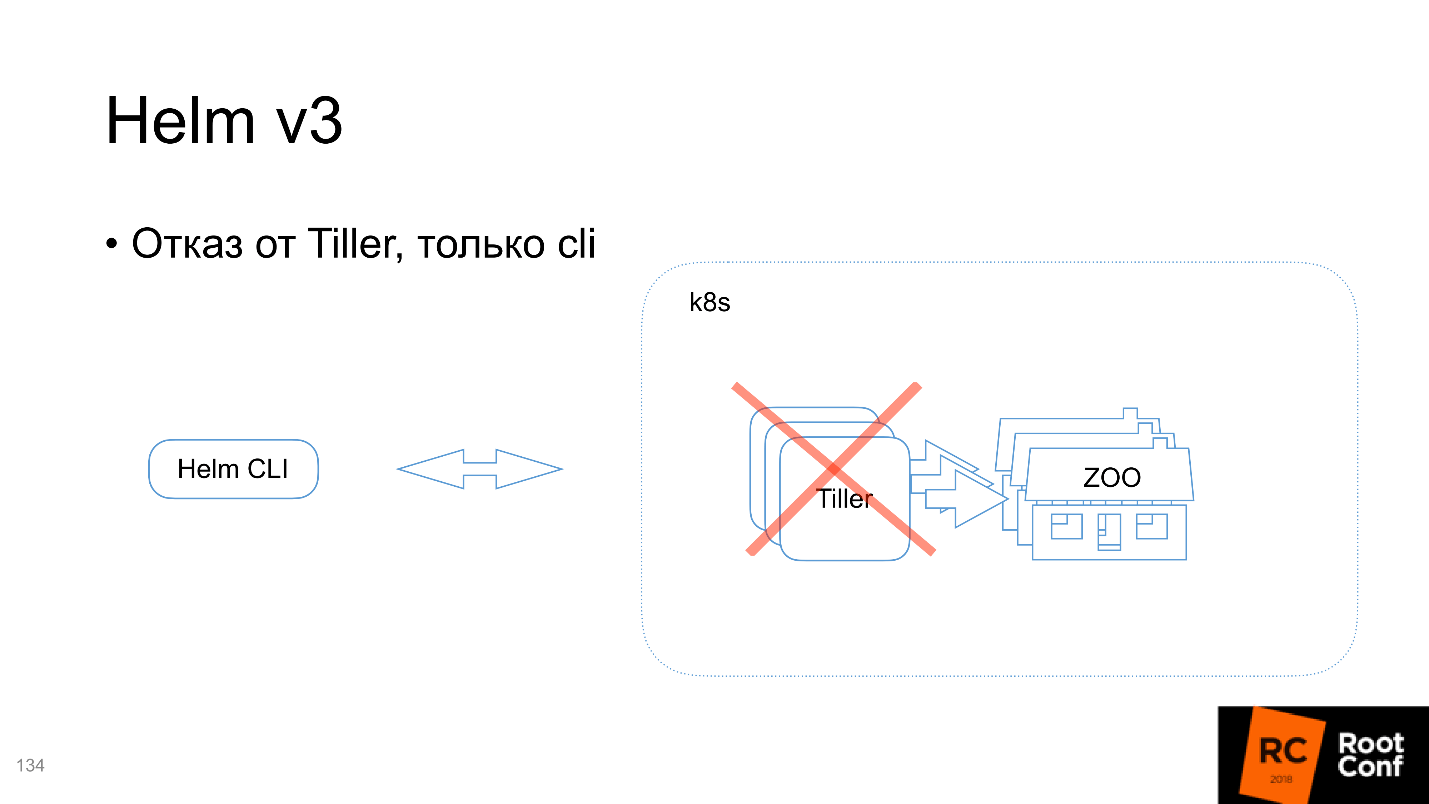
Отказ от Tiller, только cli
Мы еще не обсуждали эти детали, поэтому рассмотрим сейчас. Архитектура Helm состоит из двух частей:
Tiller обрабатывает запросы, которые вы посылаете через Command Line Interface. То есть вы говорите: «Я хочу установить вот этот Chart» — и фактически Helm собирает его, запаковывает, отсылает Tiller’у, а он уже решает: «О, мне что-то пришло! Похоже, что это проецируется в следующие Kubernetes-ресурсы» — и запускает.
По мнению разработчиков Helm, должен работать один Tiller на кластер и управлять всем зоопарком технологий, которой есть в кластере. Но у нас получилось, что для того, чтобы правильно разделять доступ, нам выгоднее иметь не один, а несколько Tiller’ов — для каждого namespace свой. Чтобы Tiller мог создавать ресурсы только в namespace, в котором он запущен, и не имел права ходить в соседние. Это дает возможность разделять область ответственности, область видимости для разных команд.
В следующей версии V3 Tiller не будет.
А зачем он вообще нужен? По сути, он содержит информацию, передаваемую через Command Line Interface, которую использует, чтобы запускать ресурсы в Kubernetes. Получается, что в Kubernetes уже содержится ровно та же информация, что содержится в Tiller. Но я могу с помощью kubectl cli делать то же самое.
Вместо Tiller вводится система событий. На все новые ресурсы, которые вы посылаете в Kubernetes через Command Line Interface будут события: установки, изменения, удаления, pre- и post-события. Этих событий довольно много.
Lua-скрипты в Chart
Часть из них вы не можете редактировать, часть — можете, и делать это можно с помощью lua-скриптов. На этапе создания Chart вы добавляете сборник lua-скриптов, который кладете в специальную папку. Они будут полностью отслеживать обработку внешних событий. Наверное, это удобно. На самом деле, часть наших проблем, которые мы обсуждали ранее, можно решить с помощью этого подхода.
Lua и события могут закрыть проблемы разработки, потому что станет возможным управлять тем, что нужно делать, когда что-то произошло, и на стороне сервера, и на стороне автоматизации окружения тоже.
К сожалению, еще нет реализации, можно только предполагать. Но теоретически, самую главную для меня проблему автоматизации окружения мы сможем полностью закрыть. Можно будет написать новое приложение в Kubernetes, отправлять в него какие-то конфиги, и с помощью механизма, который вы сами запрограммируете, приложение установит все, что вам будет угодно. Посмотрим, что из этого получится.
Release-объект + secret версии релиза
Для того, чтобы полностью отслеживать процесс релиза, появится Release-объект с информацией о том, какой Release был написан. Пока не объявлено, что это будет за Release-объект, каким образом он будет создаваться, может быть, это будет CRD, а может, нет.
Привязка к namespace релиза
Этот Release-объект будет создаваться в том namespace, в котором все было запущено, и соответственно из-за этого отпадает необходимость привязки Tiller’а к namespace — та проблема, о которой я говорил чуть ранее.
CRD: controller
Дополнительно в отдаленном будущем разработчики думают о том, чтобы создать CRD-controller для Helm для тех случаев, которые не могут быть покрыты стандартной push-моделью. Но информации про реализацию этого пока совсем нет.
Сборник рецептов
Итого суммарно, как я рекомендую пользоваться системой.

Конечно же, это Helm. Он создается сообществом, все альтернативные решения создаются независимыми командами, про которые мы не уверены, долго ли они будут существовать. К сожалению, послезавтра они могут отказаться от своих проектов, и вы останетесь у разбитого корыта. А Helm — это все-таки уже часть Kubernetes. К тому же он будет как-то развиваться и, может быть, решит проблемы.
Конечно же, CI/CD, автоматическая сборка по коммиту. В нашей компании мы сделали интеграцию со Slack, у нас есть бот, который сообщает, когда в master прошла новая сборка, и что все тесты прошли успешно. Ты ему говоришь: «Я хочу это установить в Staging» — и он устанавливает, говоришь: «Я хочу запустить там тест!» — и он запускает. Довольно удобно.
Для разработки использовать Docker-compose или Telepresence.
Несколько версий одного сервиса
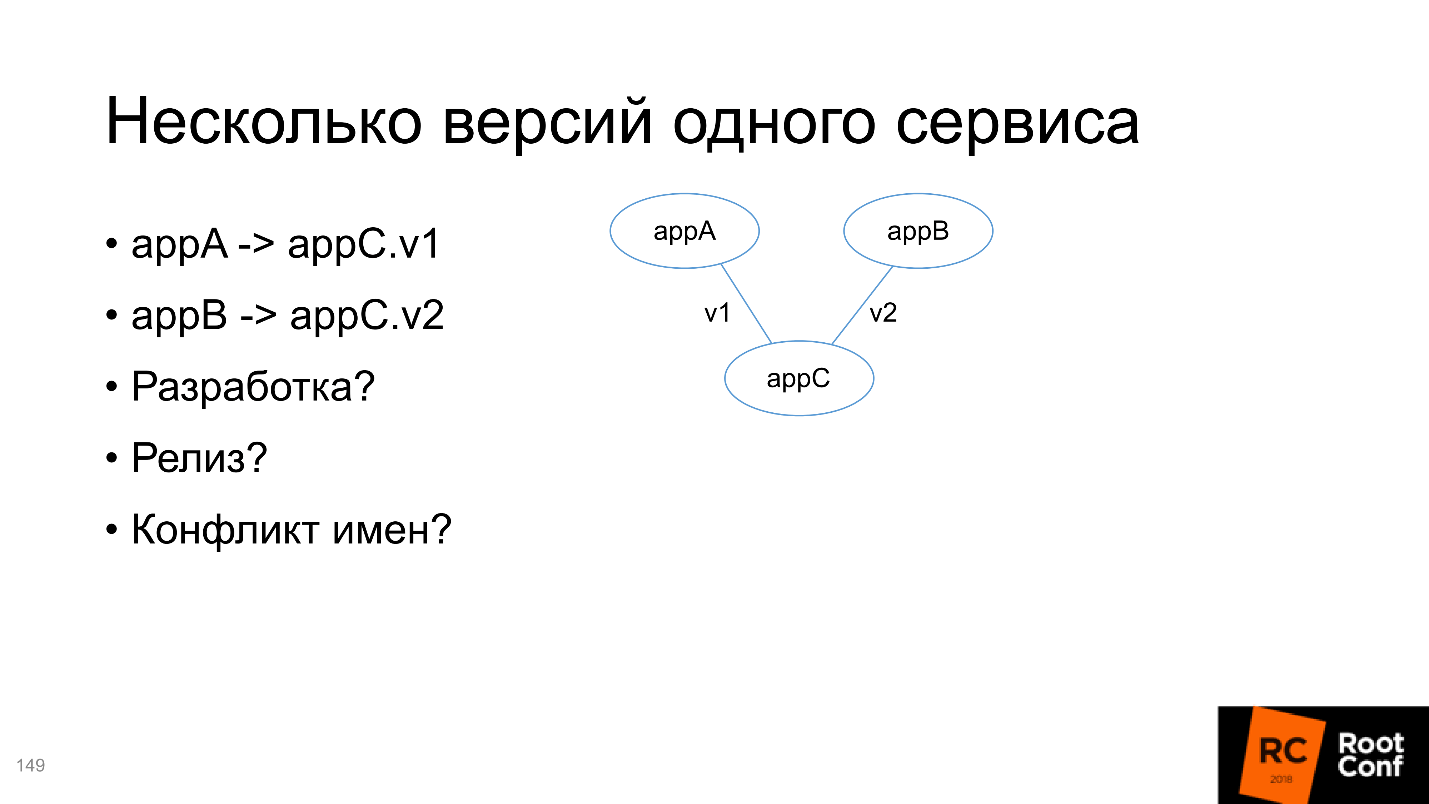
В конце разберем ситуацию, когда есть два приложения A и B, которые зависят от C, но C разных версий. Нужно решить эту проблему:
На самом деле, Kubernetes все решает за нас — просто надо правильно этим воспользоваться.

Я бы советовал создать 4 Chart’а в терминах Helm, 3 репозитория (для репозитория C это будет просто две разных ветки). Что самое интересное, все инсталляции для v1 и для v2 должны содержать внутри себя информацию о версия или, для какого сервиса она была создана. Одно из решений на слайде, приложение C; в имени релиза указано, что это версия v1 для сервиса A; имя сервиса тоже содержит версию. Это простейший пример, вы можете делать совершенно по-другому. Но самое главное, чтобы имена были уникальными.
Второе — это транзитивные зависимости, и здесь сложнее.
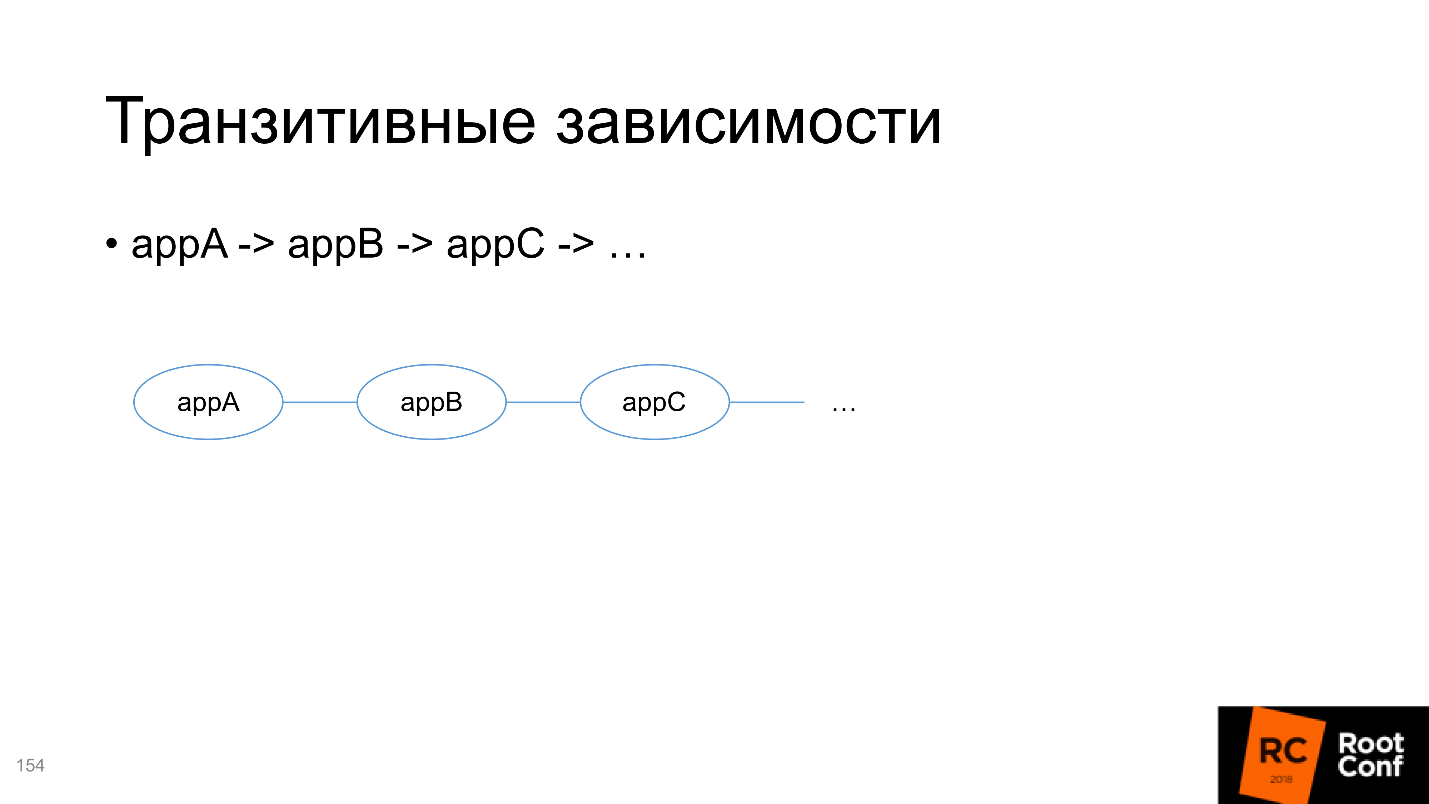
Например, вы разрабатываете цепочку сервисов и хотите тестировать A. Для этого, вы должны в Helm-определение вашего пакета передать все зависимости, от которых зависит A, в том числе транзитивные. Но в то же время вы хотите разрабатывать B и тоже его тестировать — как это делать непонятно, потому что в него нужно точно также положить все транзитивные зависимости.
Поэтому я советую не добавлять все зависимости внутрь каждого пакета, а делать их независимыми и извне управлять тем, что где запущено. Это неудобно, но это меньшее из двух зол.
Полезные ссылки
• Draft
• GitKube
• Helm
• Ksonnet
• Telegram stickers: раз, два
• Sig-Apps
• KubePack
• Metaparticle
• Skaffold
• Helm v3
• Docker-compose
• Ksync
• Telepresence
• Drone
• Forge
Профиль спикера Ивана Глушкова на GitHub, в twitter, на Хабре.
Разберемся, почему на этой схеме только функция шаблонизатора выделена зеленым, и в чем проблемы со сборкой и пакетированием, автоматизацией окружения и прочим. Но не беспокойтесь, статья не закончится на том, что все плохо. Сообщество не могло с этим смириться и предлагает альтернативные инструменты и решения — разберемся и с ними.
Помог нам в этом Иван Глушков (gli) своим докладом на РИТ++, видео и текстовая версия этого подробного и обстоятельного выступления ниже.
Видеозаписи этого и других выступлений по DevOps на РИТ++ опубликованы и открыты для свободного просмотра на нашем youtube-канале — заходите в поисках ответов на свои рабочие вопросы.
О спикере: Иван Глушков разрабатывает ПО уже 15 лет. Успел поработать в MZ, в Echo над платформой для комментариев, поучаствовать в разработке компиляторов для процессора Эльбрус в MCST. Сейчас занимается инфраструктурными проектами в Postmates. Иван один из ведущих подкаста DevZen, в котором рассказывают и о наших конференциях: здесь есть о РИТ++, а здесь о HighLoad++.
Пакетные менеджеры
Хотя все используют какие-либо виды пакетных менеджеров, единого соглашения, что это такое, нет. Есть общее понимание, и у каждого оно свое.
Давайте вспомним, какие виды пакетных менеджеров первым делом приходят в голову:
- Стандартные пакетные менеджеры всех операционных систем: rpm, dpkg, portage, ...
- Пакетные менеджеры для разных языков программирования: cargo, cabal, rebar3, mix, ...
Главная их функция — выполнение команд установки пакета, обновления пакета, удаления пакета, управление зависимостями. В пакетных менеджерах внутри языков программирования, все немного сложнее. Например, есть команды вида «запустить пакет» или «создать релиз» (build/run/release). Получается, что это уже система сборки, хотя мы тоже называем это пакетным менеджером.
Все это только из-за того, что нельзя просто взять и… пусть простят любители Haskell это сравнение. Можно запустить бинарный файл, но нельзя запустить программу на Haskell или на C, сначала нужно ее каким-то образом подготовить. И подготовка эта довольно сложная, а пользователи хотят, чтобы все делалось автоматически.
Развитие
Тот, кто работал с GNU libtool, который сделан для большого проекта, состоящего из большого количества компонент, тот в цирке не смеется. Это действительно очень сложно, и некоторые случаи принципиально нельзя разрешить, а можно только обойти.
По сравнению с ним современные пакетные менеджеры языков типа cargo для Rust, гораздо удобнее — вы нажимаете кнопку и все работает. Хотя фактически под капотом решается большое количество проблем. При этом все эти новые функции требуют чего-то дополнительного, в частности, базы данных. Хотя в самом пакетном менеджере она может называться как угодно, я называю ее базой данных, т.к. там хранятся данные: об установленных пакетах, об их версиях, подключенных репозиториях, версиях в этих репозиториях. Все это обязательно должно где-то храниться, поэтому есть внутренняя база данных.
Разработка на этом языке программирования, тестирование для этого языка программирования, запуски — все это встроено и находится внутри, работа становится очень удобной. Большинство современных языков поддержали такой подход. Даже те, что не поддержали, начинают поддерживать, потому что сообщество давит и говорит, что в современном мире без этого невозможно.
Но у любого решения всегда есть не только плюсы, но и минусы. Здесь минусом является то, что необходимы обертки, дополнительные утилиты и встроенная «база данных».
Docker
Как вы думаете, Docker — это пакетный менеджер или нет?
Как бы нет, но по сути да. Я не знаю более правильной утилиты для того, чтобы полностью поставить приложение вместе со всеми зависимостями, и чтобы оно заработало по нажатию на одну кнопку. Что это, как не пакетный менеджер? Это замечательный пакетный менеджер!
Максим Лапшин уже рассказывал, что с Docker стало гораздо проще, и это так. У Docker есть встроенная система сборки, все эти базы данных, обвязки, утилиты.
Какова же цена всех преимуществ? Те, кто работает с Docker, мало задумываются о промышленном применении. У меня есть такой опыт, и цена, на самом деле, очень высокая:
- Объем информации (размер образов), который надо хранить в Docker-образе. Необходимо все зависимости, части утилит, библиотек запаковать внутрь, образ получается большой и с ним надо уметь работать.
- Гораздо сложнее то, что происходит смена парадигмы.
Например, у меня была задача перевести одну программу на использование Docker. Программу разрабатывала сложившаяся годами команда. Я прихожу, мы делаем все, что написано в книжках: расписываем users stories, роли, смотрим, что и как они делают, их стандартные рутины.
Я говорю:
— Все ваши проблемы может решить Docker. Смотрите, как это делается.
— Все будет по кнопке — здорово! Но мы хотим SSH делать внутри контейнеров Kubernetes.
— Подождите, не надо нигде SSH.
— Да-да, все хорошо… А SSH можно?
Для того, чтобы повернуть восприятие пользователей в новое русло, требуется очень много времени, нужна образовательная работа и много усилий.
Еще один фактор цены это то, что Docker-registry — внешний репозиторий для образов, его нужно как-то инсталлировать и контролировать. Там есть собственные проблемы, garbage collector и прочее, и он может часто падать, если за ним не следить, но это все решаемо.
Kubernetes
Наконец мы дошли до Kubernetes. Это классная OpenSource система для управления приложениями, которая активно поддерживается сообществом. Хотя она изначально вышла из одной компании, сейчас у Kubernetes огромное сообщество, и угнаться за ним невозможно, альтернатив практически нет.
Интересно, что все узлы Kubernetes работают в самом Kubernetes через контейнеры, и все внешние приложения работают через контейнеры — всё работает через контейнеры! Это и плюс, и минус.
У Kubernetes есть много полезной функциональности и свойств: распределенность, отказоустойчивость, возможность работать с разными облачными сервисами, ориентация на микросервисную архитектуру. Все это интересно и здорово, но как в Kubernetes установить приложение?
Как установить приложение?
Установить Docker-образ в Docker-registry.
За этой фразой скрывается бездна. Вы представляете себе — у вас есть приложение, написанное, скажем, на Ruby, и вы должны Docker-образ положить в Docker-registry. Это значит, вы должны:
- подготовить Docker-образ;
- понимать, как он собирается, на каких версиях основан;
- уметь его протестировать;
- собрать, залить в Docker-registry, который вы до этого, кстати, установили.
На самом деле это большая-большая боль в одной строчке.
Плюс еще нужно описать манифесты приложения в терминах (ресурсах) k8s. Самый простой вариант:
- описать deployment + pod, service + ingress (возможно);
- запустить команду kubectl apply -f resources.yaml, и все ресурсы в эту команду передать.
На слайде Ганди потирает руки — похоже, я нашел пакетный менеджер в Kubernetes. Но kubectl — это не пакетный менеджер. Он просто говорит, что я хочу видеть вот такое конечное состояние системы. Это — не установка пакета, не работа с зависимостями, не сборка — это просто «я хочу видеть это конечное состояние».
Helm
Наконец мы подошли к Helm. Helm — это многоцелевая утилита. Сейчас мы рассмотрим, какие направления развития Helm и работы с ним есть.
Шаблонизатор
Во-первых, Helm — это шаблонизатор. Мы обсуждали, что нужно подготовить ресурсы, и проблема — написать в терминах Kubernetes (можно и не только в yaml). Самое интересное, что это статические файлы для вашего конкретного приложения в этом конкретном окружении.
Однако, если вы работаете с несколькими окружениями и у вас есть не только Production, а еще Staging, Testing, Development и разные окружения для разных команд, нужно иметь несколько подобных манифестов. Например, потому что в одном из них несколько серверов, и нужно иметь большое количество реплик, а в другом — только одну реплику. Там нет базы данных, доступа к RDS, и нужно установить PostgreSQL внутрь. А тут у нас старая версия, и нужно немного все переписать.
Все это многообразие приводит к тому, что вы должны взять ваш манифест для Kubernetes, везде его скопировать и везде подправить: здесь подменить одну цифру, здесь еще что-нибудь. Это становится очень неудобно.
Решение простое — надо ввести шаблоны. То есть вы формируете манифест, в нем определяете переменные, а потом определенные снаружи переменные подаете в виде файла. Шаблон создает конечный манифест. Получается переиспользование одного и того же манифеста для всех окружений, что гораздо удобнее.
Для примера манифест для Helm.
- Самая важная часть в Helm — это Chart.yaml, в котором описывается, что это за манифест, какие версии, как он работает.
- templates — это как раз шаблоны ресурсов Kubernetes, которые внутри себя содержат какие-то переменные. Эти переменные должны быть определены во внешнем файле или в командной строке, но обязательно снаружи.
- values.yaml — стандартное название для файла с переменными для этих шаблонов.
Простейшая команда запуска для того, чтобы установить chart — helm install ./wordpress (папка). Чтобы переопределить какие-то параметры, говорим: «Я хочу переопределить именно эти параметры и задать такие-то значения».
Helm справляется с этой задачей, поэтому на схеме отметим её зеленым.
Правда появляются минусы:
- Многословность. Ресурсы определяются полностью в терминах Kubernetes, не вводится концепций дополнительных уровней абстракции: просто пишем все, что мы хотели бы написать для Kubernetes, и подменяем там переменные.
- Don’t repeat yourself — не применяется. Приходится часто повторять одно и то же. Если у вас два похожих сервиса с разными названиями, нужно полностью скопировать всю папку (чаще всего делают так) и поменять необходимые файлы.
Прежде, чем окунуться в направление Helm — пакетный менеджер, ради чего я все это рассказываю, давайте разберемся, как Helm работает с зависимостями.
Работа с зависимостями
С зависимостями Helm работает сложно. Во-первых, есть файл requirements.yaml, в который вписывается то, от чего мы зависим. Во время работы с requirements, он делает requirements.lock — это текущее состояние (слепок) всех зависимостей. После этого он их скачивает в папку с названием /charts.
Есть инструменты, для того чтобы управлять: кого, как, куда подключать — tags и conditions, с помощью которых определяется, в каком окружении, в зависимости от каких внешних параметров подключать или не подключать какие-то зависимости.
Скажем, у вас есть PostgreSQL для окружения Staging (или RDS для Production, или NoSQL для тестов). Устанавливая этот пакет в Production, вы не установите PostgreSQL, потому что он там не нужен — как раз с помощью tags и conditions.
Что здесь интересно?
- Helm смешает все ресурсы всех зависимостей и приложения;
- sort -> install / update
После того, как мы скачали все зависимости в /charts (этих зависимостей может быть, например, 100), Helm внутри себя берет и копирует все ресурсы. После того, как он отрендерил шаблоны, он собирает все ресурсы в одном месте и сортирует в каком-то своем собственном порядке. Вы не можете повлиять на этот порядок. Вы должны сами определить, от чего зависит ваш пакет, и если пакет имеет транзитивные зависимости, то необходимо их все включить в описание в requirements.yaml. Это надо иметь в виду.
Пакетный менеджер
Helm устанавливает приложения и зависимости, и вы можете сказать Helm install — и он установит пакет. Значит это пакетный менеджер.
Одновременно, если у вас есть внешний репозиторий, в который вы закачиваете пакет, вы можете обращаться к нему не как к локальной папке, а просто сказать: «Из этого репозитория возьми этот пакет, установи его с такими-то параметрами».
Есть открытые репозитории с большим количеством пакетов. Например, можно запустить: helm install -f prod/values.yaml stable/wordpress
Из репозитория stable вы возьмете wordpress и установите к себе. Можно делать все: search / upgrade / delete. Получается, действительно, Helm — пакетный менеджер.
Но есть минусы: все транзитивные зависимости необходимо включать внутрь. Это большая проблема, когда транзитивные зависимости — это независимые приложения, и вы хотите с ними отдельно работать для тестирования и разработки.
Еще один минус — сквозное конфигурирование. Когда у вас есть база данных и ее имя нужно передать во все пакеты, это можно, но сложно сделать.
Чаще всего не бывает так, что вы установили один маленький пакетик, и он работает. Мир сложный: приложение зависит от приложения, которое в свою очередь тоже зависит от приложения — вам надо их как-то хитро сконфигурировать. Helm не умеет это поддерживать, или поддерживает с большими проблемами, и иногда приходится много плясать с бубном, чтобы все заработало. Это плохо, поэтому «пакетный менеджер» на схеме выделяем красным.
Сборка и пакетирование
«Нельзя просто взять и» запустить приложение в Kubernetes. Нужно его собрать, то есть сделать Docker-образ, записать в Docker-registry и т.д. Хотя все определение пакета в Helm есть. Мы определяем, что такое пакет, какие там функции и поля должны быть, подписи и проверка подлинности (система безопасности вашей компании будет очень рада). Поэтому, с одной стороны, сборка и пакетирование вроде поддерживается, а с другой — не настроена работа с Docker-образами.
Helm не позволяет запустить приложение без Docker-образа. В то же время Helm не настроена сборка и пакетирование, то есть по факту он не умеет работать с Docker-образами.
Это то же самое, как если бы, чтобы сделать upgrade install для какой-нибудь маленькой библиотеки, вас отправляли бы в дальнюю папку запускать компилятор.
Поэтому мы и говорим, что Helm не умеет работать с образами.
Разработка
Следующая головная боль — это разработка. В разработке мы хотим быстро и удобно изменять наш код. Прошло время, когда вы на перфокартах набивали дырочки, а результат получали через 5 дней. Все привыкли, что заменяешь в редакторе одну букву на другую, нажимаешь компиляцию, и уже измененная программа работает.
Здесь же получается, что при изменении кода нужна масса дополнительных действий: подготовить Docker-файл; запустить Docker, чтобы он собрал образ; куда-то его запушить; развернуть в Kubernetes-кластере. И только тогда вы получите то, что вы хотите на Production, и сможете проверить работу кода.
Еще возникают неудобства из-за деструктивного обновления helm upgrade. Вы посмотрели, как все работает, через kubectl exec заглянули внутрь контейнера, все хорошо. В этот момент вы запускаете обновление, скачивается новый образ, запускаются новые ресурсы, а старые удаляются — надо все начинать с самого начала.
Самая большая боль — это большие образы. В большинстве компаний не работают с маленькими приложениями. Часто это если не супермонолит, то хотя бы маленький монолитик. Со временем нарастают годовые кольца, увеличивается объем кодовой базы, и постепенно приложение становится довольно большим. Я не раз сталкивался с Docker-образами размером больше 2 Гб. Представьте теперь, что вы делаете изменение одного байта в вашей программе, нажимаете кнопку, и начинает собираться двухгигабайтный Docker-образ. Потом вы нажимаете следующую кнопку, и начинается передача 2 Гб на сервер.
Docker позволяет работать со слоями, т.е. проверяет есть там тот или иной слой и отправляет недостающий. Но мир таков, что чаще всего это будет один большой слой. Пока 2 Гб уйдут на сервер, пока они с Docker-registry придут на Kubernetes, раскатаются по всем подам, пока вы наконец запустите — можно спокойно чай попить.
В работе с большими Docker-образами Helm не предполагает никакой помощи. Я считаю, что такого быть не должно, но разработчики Helm знают лучше, чем все пользователи, и Стив Джобс улыбается этому.
Блок с разработкой тоже окрасился в красный.
Автоматизация окружения
Последнее направление — автоматизация окружения — интересная область. До мира Docker (и Kubernetes, как связанной модели) не было возможности сказать: «Я хочу установить свое приложение на этот сервер или на эти серверы, чтобы там было n реплик, 50 зависимостей, и все это автоматически заработало!» Такое, можно сказать, что было, но не было!
Kubernetes это предоставляет и логично как-то этим пользоваться, например, сказать: «Я тут разворачиваю новое окружение и хочу, чтобы все команды разработки, которые приготовили свои приложения, просто могли нажать кнопочку, и все эти приложения автоматически бы установились на новое окружение». Теоретически Helm должен в этом помогать, чтобы при этом конфигурация могла быть взята из внешнего источника данных — S3, GitHub — откуда угодно.
Желательно, чтобы в Helm была специальная кнопка «Сделай мне хорошо уже наконец!» — и оно сразу становилось бы хорошо. Kubernetes позволяет это делать.
Особенно удобно это, потому что Kubernetes можно запускать где угодно, и он работает через API. Запуская minikube локально, или в AWS, или в Google Cloud Engine, вы получаете Kubernetes прямо из коробки и везде работаете одинаково: нажимаете кнопку, и сразу всё хорошо.
Казалось бы, естественно Helm позволяет это делать. Потому что иначе, в чем вообще был смысл создавать Helm?
Но оказывается, нет!
Автоматизация окружения отсутствует.
Альтернативы
Когда есть приложение от Kubernetes, которое все используют (это сейчас по факту решение номер 1), но при этом Helm имеет рассмотренные выше проблемы, сообщество не могло не ответить. Оно начало создавать альтернативные инструменты и решения.
Шаблонизаторы
Казалось бы, как шаблонизатор, Helm решил все проблемы, но все равно сообщество создает альтернативы. Напомню проблемы шаблонизатора: многословность и переиспользование кода.
Хороший представитель здесь — Ksonnet. Он использует принципиально другую модель данных и концепций, и работает не с Kubernetes-ресурсами, а со своими собственными определениями:
prototype(params) -> component -> application -> environments.
Там есть части (parts), которые составляют прототип. Прототип параметризуется внешними данными, и появляется component. Несколько component составляют приложение, которое можно запускать. Оно запускается в разных окружениях. Некоторые понятные связи с ресурсами Kubernetes здесь есть, но прямой аналогии может и не быть.
Основной целью появления Ksonnet было, конечно, переиспользование ресурсов. Они хотели сделать так, чтобы вы, написав однажды код, в дальнейшем могли использовать его где угодно, что повышает скорость разработки. Если вы создаете большую внешнюю библиотеку, люди могут постоянно размещать там свои ресурсы, а все сообщество сможет их переиспользовать.
Теоретически это удобно. Практически я это не использовал.
Пакетные менеджеры
Проблема здесь, как мы помним — это вложенные зависимости, сквозные конфиги, транзитивные зависимости. Их Ksonnet не решает. У Ksonnet очень похожая на Helm модель, которая точно так же определяет список зависимостей в файле, он закачивается в определенный каталог и т.д. Отличие в том, что можно делать патчи, то есть вы подготавливаете папку, в которую складываете патчи для конкретных пакетов.
Когда вы закачиваете папку, эти патчи накладываются, и результат, получаемый слиянием нескольких патчей, можно начинать использовать. Плюс есть валидация конфигураций для зависимостей. Это может быть удобно, но это все еще очень сырое, документации почти нет, а версия замерла в состоянии 0.1. Думаю, что использовать его пока рано.
Итак, пакетный менеджер — это KubePack, и других альтернатив я пока не видел.
Разработка
Решения делятся на несколько разных категорий:
- пытаются работать поверх Helm;
- вместо Helm;
- используют принципиально другой подход, при котором пытаются работать прямо в языке программирования;
- и другие вариации, о которых позже.
1. Разработка поверх Helm
Хороший представитель — это Draft. Его цель — возможность попробовать приложение еще до того, как закоммичен код, то есть посмотреть текущее состояние. Draft использует метод программирования — Heroku-style:
- есть пакеты для ваших языков (pack);
- пишете, скажем, на Python «Hello, world!»;
- нажимаете кнопку, автоматически создается Docker-файл (вы его не пишете);
- автоматически создаются ресурсы, это все запускается, отправляется в docker-registry, который вы должны были сконфигурировать;
- приложение автоматически начинает работать.
Это можно сделать в любом каталоге с кодом, вроде все быстро, легко и хорошо.
Но в дальнейшем лучше все равно начать работать с Helm, потому что Draft создает Helm-ресурсы, и когда ваш код дойдет до состояния production ready, надеяться на то, что Draft хорошо создаст Helm-ресурсы, не стоит. Вам придется все равно создавать их вручную.
Получается, что Draft нужен чтобы быстро стартануть и попробовать в самом начале до того, как вы написали хоть один Helm-ресурс. Draft — первый претендент на это направление.
2. Разработка без Helm
Разработка без Helm Charts предполагает построение тех же самых Kubernetes-манифестов, которые были бы иначе построены через Helm Charts. Предлагаю три альтернативы:
- GitKube;
- Skaffold;
- Forge.
Они все очень похожи на Helm, отличия в небольших деталях. В частности, часть решений предполагает, что вы будете использовать command line interface, а Chart предполагает, что вы будете делать git push и управлять хуками.
В конце концов, вы все равно запускаете docker build, docker push и kubectl rollout. Все те проблемы, которые мы перечисляли для Helm, никак не решаются. Это просто альтернатива с теми же самыми недостатками.
3. Разработка на языке приложения
Следующая альтернатива — разработка на языке приложения. Здесь хороший пример — Metaparticle. Допустим, вы пишите код на Python, и прямо внутри Python начинаете мыслить, что вы хотите от приложения.
Я вижу в этом очень интересную концепцию, потому что чаще всего разработчик не хочет думать о том, как приложение должно работать на серверах, какой правильный прописать конфиг в sysconfig и т.д. Ему важно рабочее приложение.
Если правильно описать рабочее приложение, из каких частей оно состоит, каким образом они взаимодействуют, теоретически какая-то магия поможет превратить это знание с точки зрения приложения в Kubernetes-ресурсы.
С помощью декораторов определяем: где находится репозиторий, как туда надо правильно пушить; какие есть сервисы, и как они между собой взаимодействуют; столько должно быть реплик на кластере и т.д.
Я не знаю, как вы, но лично я не люблю, когда вместо меня какая-то магия решает, что из Python-определений нужно сделать именно такой Kubernetes-конфиг. А если мне надо другое?
Все это работает до какого-то предела, пока приложение достаточно стандартное. После этого начинаются проблемы. Скажем, я хочу, чтобы до запуска основного контейнера запускался preinstall контейнер, который выполнит какие-то действия для конфигурирования будущего контейнера. Это все делается в рамках Kubernetes-конфигов, но делается ли это в рамках Metaparticle, я не знаю.
Я привожу банальные простейшие примеры, а их гораздо больше, в спецификации Kubernetes-конфигов очень много параметров. Я уверен, что они не полностью присутствуют в декораторах, подобных Metaparticle.
На схеме появляется Metaparticle, и мы обсудили три альтернативных Helm подхода. Однако есть дополнительные, и они очень перспективны на мой взгляд.
Telepresence/Ksync — один из них. Представим, у вас есть уже написанное приложение, есть Helm-ресурсы, которые тоже написаны. Вы установили приложение, оно запустилось где-то в кластере, и в этот момент вы хотите что-то попробовать, например, поменять одну строчку в вашем коде. Конечно, я говорю не про Production-кластеры, хотя некоторые и на Production что-то правят.
Проблема Kubernetes в том, что нужно эти локальные правки через обновление Docker, через registry, перенести в Kubernetes. Но донести до кластера одну измененную строчку можно другими способами. Можно синхронизировать локальную и удаленную папку, которая находится на поде.
Да, конечно, при этом в образе должен быть компилятор, всё необходимое для Development должно быть там на месте. Но зато какое удобство: устанавливаем приложение, меняем несколько строк, синхронизация срабатывает автоматически, на поде становится обновленный код, запускаем компиляцию и тесты — ничего не ломается, ничего не обновляется, никаких деструктивных обновлений, как в Helm, не происходит, получаем уже обновленное работающее приложение.
На мой взгляд, это отличное решение проблемы.
4. Разработка для Kubernetes без Kubernetes
Раньше мне казалось, что нет смысла работать с Kubernetes без Kubernetes. Я считал, что лучше один раз правильно сделать Helm-определения и пользоваться подходящими инструментами, чтобы в локальной разработке иметь единые конфиги для всего. Но со временем я столкнулся с реальностью и увидел приложения, для которых это сделать чрезвычайно сложно. Сейчас я пришел к выводу, что проще написать Docker-compose файл.
Когда вы делаете Docker-compose файл, вы запускаете все те же самые образы, и монтируете точно также, как в предыдущем случае, локальную папку на папку в контейнере Docker, только уже не внутри Kubernetes, а просто в Docker-compose, который запущен локально. Потом точно также запускаете компилятор, и все отлично работает. Минус в том, что необходимо иметь дополнительные конфиги для Docker. Плюсом является скорость и простота.
В моем примере я пытался запустить в minikube то же самое, что и пытался сделать с Docker-compose, и разница была громадная. Плохо работало, были непонятные проблемы, а Docker-compose — в 10 строчек поднимаешь и все работает. Так как вы работаете с теми же самыми образами, это гарантирует повторяемость.
На нашу схему добавляется Docker-compose, и в целом получается, что сообщество суммарно этими всеми решениями закрыло проблему разработки.
Сборка и пакетирование
Да, сборка и пакетирование — это проблема Helm, но, наверное, разработчики Helm все-таки были правы. У каждой компании есть своя система CI/CD, которая собирает артефакты, проверяет и тестирует. Если она уже есть — зачем закрывать эту проблему в Helm, когда у каждого это свое? Возможно, одно правильное решение не получится, у каждого будут модификации.
Если у вас есть CI/CD, есть интеграция с внешним репозиторием, на каждый коммит автоматически собираются docker’ы, запускаются set-тесты, и вы можете нажать кнопку и задеплоить это все, вы решили проблему — ее не осталось.
CI/CD — это действительно решение проблемы сборки и пакетирования, и мы закрашиваем её зеленым.
Итоги
Из 5 направлений сам Helm закрывает только шаблонизатор. Сразу становится понятно, для чего его создавали. Остальные решения сообщество совместно добавило, проблемы разработки, сборки и пакетирования полностью решены внешними решениями. Это не до конца удобно, не всегда легко сделать в рамках сложившихся традиций внутри компании, но возможно, по крайней мере.
Будущее Helm
Боюсь, что никто из нас не знает наверняка, к чему Helm должен прийти. Как мы видели, разработчики Helm иногда лучше нас знают, что надо сделать. Думаю, что большинство из тех проблем, которые мы рассмотрели, не закроются ближайшими релизами Helm.
Посмотрим, что добавилось в текущий Road Map. Есть такой репозиторий Kuberneres Helm в community, в котором есть планы развития и неплохая документация на то, что будет в следующей версии Helm V3.
Отказ от Tiller, только cli
Мы еще не обсуждали эти детали, поэтому рассмотрим сейчас. Архитектура Helm состоит из двух частей:
- Клиентская часть, которую вы запускаете на локальном компьютере (cmd и т.д.).
- Tiller — вторая часть, которая работает на сервере внутри Kubernetes.
Tiller обрабатывает запросы, которые вы посылаете через Command Line Interface. То есть вы говорите: «Я хочу установить вот этот Chart» — и фактически Helm собирает его, запаковывает, отсылает Tiller’у, а он уже решает: «О, мне что-то пришло! Похоже, что это проецируется в следующие Kubernetes-ресурсы» — и запускает.
По мнению разработчиков Helm, должен работать один Tiller на кластер и управлять всем зоопарком технологий, которой есть в кластере. Но у нас получилось, что для того, чтобы правильно разделять доступ, нам выгоднее иметь не один, а несколько Tiller’ов — для каждого namespace свой. Чтобы Tiller мог создавать ресурсы только в namespace, в котором он запущен, и не имел права ходить в соседние. Это дает возможность разделять область ответственности, область видимости для разных команд.
В следующей версии V3 Tiller не будет.
А зачем он вообще нужен? По сути, он содержит информацию, передаваемую через Command Line Interface, которую использует, чтобы запускать ресурсы в Kubernetes. Получается, что в Kubernetes уже содержится ровно та же информация, что содержится в Tiller. Но я могу с помощью kubectl cli делать то же самое.
Вместо Tiller вводится система событий. На все новые ресурсы, которые вы посылаете в Kubernetes через Command Line Interface будут события: установки, изменения, удаления, pre- и post-события. Этих событий довольно много.
Lua-скрипты в Chart
Часть из них вы не можете редактировать, часть — можете, и делать это можно с помощью lua-скриптов. На этапе создания Chart вы добавляете сборник lua-скриптов, который кладете в специальную папку. Они будут полностью отслеживать обработку внешних событий. Наверное, это удобно. На самом деле, часть наших проблем, которые мы обсуждали ранее, можно решить с помощью этого подхода.
Lua и события могут закрыть проблемы разработки, потому что станет возможным управлять тем, что нужно делать, когда что-то произошло, и на стороне сервера, и на стороне автоматизации окружения тоже.
К сожалению, еще нет реализации, можно только предполагать. Но теоретически, самую главную для меня проблему автоматизации окружения мы сможем полностью закрыть. Можно будет написать новое приложение в Kubernetes, отправлять в него какие-то конфиги, и с помощью механизма, который вы сами запрограммируете, приложение установит все, что вам будет угодно. Посмотрим, что из этого получится.
Release-объект + secret версии релиза
Для того, чтобы полностью отслеживать процесс релиза, появится Release-объект с информацией о том, какой Release был написан. Пока не объявлено, что это будет за Release-объект, каким образом он будет создаваться, может быть, это будет CRD, а может, нет.
Привязка к namespace релиза
Этот Release-объект будет создаваться в том namespace, в котором все было запущено, и соответственно из-за этого отпадает необходимость привязки Tiller’а к namespace — та проблема, о которой я говорил чуть ранее.
CRD: controller
Дополнительно в отдаленном будущем разработчики думают о том, чтобы создать CRD-controller для Helm для тех случаев, которые не могут быть покрыты стандартной push-моделью. Но информации про реализацию этого пока совсем нет.
Сборник рецептов
Итого суммарно, как я рекомендую пользоваться системой.
Конечно же, это Helm. Он создается сообществом, все альтернативные решения создаются независимыми командами, про которые мы не уверены, долго ли они будут существовать. К сожалению, послезавтра они могут отказаться от своих проектов, и вы останетесь у разбитого корыта. А Helm — это все-таки уже часть Kubernetes. К тому же он будет как-то развиваться и, может быть, решит проблемы.
Конечно же, CI/CD, автоматическая сборка по коммиту. В нашей компании мы сделали интеграцию со Slack, у нас есть бот, который сообщает, когда в master прошла новая сборка, и что все тесты прошли успешно. Ты ему говоришь: «Я хочу это установить в Staging» — и он устанавливает, говоришь: «Я хочу запустить там тест!» — и он запускает. Довольно удобно.
Для разработки использовать Docker-compose или Telepresence.
Несколько версий одного сервиса
В конце разберем ситуацию, когда есть два приложения A и B, которые зависят от C, но C разных версий. Нужно решить эту проблему:
- для разработки, потому что фактически мы должны разрабатывать одно и то же, но двух разных версий;
- для релиза;
- для конфликта имен, потому что во всех стандартных пакетных менеджерах установка двух пакетов разных версий может вызвать проблемы.
На самом деле, Kubernetes все решает за нас — просто надо правильно этим воспользоваться.
Я бы советовал создать 4 Chart’а в терминах Helm, 3 репозитория (для репозитория C это будет просто две разных ветки). Что самое интересное, все инсталляции для v1 и для v2 должны содержать внутри себя информацию о версия или, для какого сервиса она была создана. Одно из решений на слайде, приложение C; в имени релиза указано, что это версия v1 для сервиса A; имя сервиса тоже содержит версию. Это простейший пример, вы можете делать совершенно по-другому. Но самое главное, чтобы имена были уникальными.
Второе — это транзитивные зависимости, и здесь сложнее.
Например, вы разрабатываете цепочку сервисов и хотите тестировать A. Для этого, вы должны в Helm-определение вашего пакета передать все зависимости, от которых зависит A, в том числе транзитивные. Но в то же время вы хотите разрабатывать B и тоже его тестировать — как это делать непонятно, потому что в него нужно точно также положить все транзитивные зависимости.
Поэтому я советую не добавлять все зависимости внутрь каждого пакета, а делать их независимыми и извне управлять тем, что где запущено. Это неудобно, но это меньшее из двух зол.
Полезные ссылки
• Draft
• GitKube
• Helm
• Ksonnet
• Telegram stickers: раз, два
• Sig-Apps
• KubePack
• Metaparticle
• Skaffold
• Helm v3
• Docker-compose
• Ksync
• Telepresence
• Drone
• Forge
Профиль спикера Ивана Глушкова на GitHub, в twitter, на Хабре.
Отличные новости
На нашем youtube-канале мы открыли видео всех докладов по DevOps с фестиваля РИТ++. Это отдельный плейлист, но в полном списке видео найдется много полезного и с других конференций.
А еще лучше подписаться на канал и рассылку, потому что в приближающемся году нас ждет много девопса: в мае рамках РИТ++; весной, летом и осенью как секция HighLoad++, и отдельная осенняя DevOpsConf Russia.
diafour
Вот бы тут подробнее… «Kubernetes позволяет это делать.» — это в смысле «вот API, с помощью которого можно сделать хорошо»?