

Автор: Екатерина Семашко, Strong Junior iOS Developer, DataArt
Немного о проекте: мобильное приложение для платформы iOS, написанное на языке Swift. Цель приложения — возможность шаринга дисконтных карт между сотрудниками компании и их друзьями.
Одной из целей проекта было изучить и попробовать на практике популярные технологии и библиотеки. Для хранения локальных данных выбрали Realm, для работы с сервером — Alamofire, для аутентификации использовался Google Sign-In, для загрузки изображений — PINRemoteImage.
Основные функции приложения:
- добавление карты, ее редактирование и удаление;
- просмотр чужих карт;
- поиск карт по названию магазина/имени пользователя;
- добавление карт в список избранных для быстрого доступа к ним.
Возможность использовать приложением без подключения к сети предполагалась с самого начала, но только в режиме чтения. Т.е. мы могли просматривать информацию о картах, но не могли модифицировать их без интернета. Для этого в приложении всегда была копия всех карт и брендов базы с сервера, плюс список избранных для текущего пользователя. Поиск тоже реализовывался локально.
Позже мы решили расширить оффлайн, добавив режим записи. Информация об изменениях, сделанных пользователем, сохранялась и при появлении интернет-соединения синхронизировалась. О реализации такого read-write оффлайн-режима и пойдет речь.
Что необходимо для полноценного оффлайн-режима в мобильном приложении? Нам нужно убрать зависимость пользователя от качества интернет-соединения, в частности:
- Убрать зависимость ответов пользователю на его действия в UI от сервера. В первую очередь запрос будет взаимодействовать с локальным хранилищем, потом уже будет отправляться на сервер.
- Помечать и хранить локальные изменения.
- Реализовать механизм синхронизации — при появлении интернет-соединения нужно отправлять изменения на сервер.
- Отображать пользователю какие изменения синхронизированы, какие нет.
Offline-first-подход
Первым делом мне пришлось изменить существующий механизм взаимодействия с сервером и базой данных. Цель была в том, чтобы пользователь не чувствовал зависимости от наличия или отсутствия интернета. В первую очередь он должен взаимодействовать с локальным хранилищем данных, а запросы на сервер должны идти в фоновом режиме.
В предыдущей версии присутствовала сильная связь между слоем хранения данных и сетевым слоем. Механизм работы с данными был следующим: сначала шел запрос на сервер через класс NetworkManager, мы ждали результата, после этого данные сохранялись в базу через класс Repository. Потом результат отдавался на UI, как представлено на схеме.
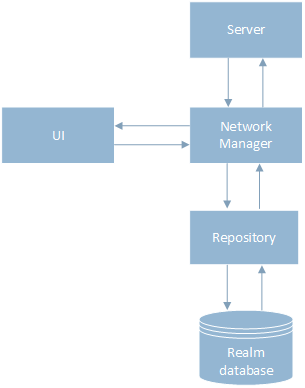
Для реализации offline-first-подхода я разделила слой хранения данных и сетевой слой, введя новый класс Flow, который управлял порядком вызова NetworkManager и Repository. Теперь данные сначала сохраняются в базу через класс Repository, потом результат отдается на UI, и пользователь продолжает работу с приложением. В фоновом режиме идет запрос на сервер, после ответа обновляются информация в базе данных и UI.
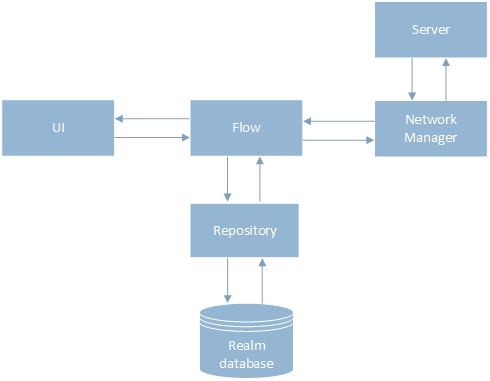
Работа с идентификаторами объектов
При новой архитектуре появилось несколько новых задач, одна из которых — работа с id объектов. Раньше мы получали их от сервера при создании объекта. Но теперь объект создавался локально, соответственно, необходимо было генерировать id и после синхронизации обновлять их на актуальные. Тут я столкнулась с первым ограничением Realm: после создания объекта менять его первичный ключ нельзя.
Первым вариантом было отказаться от первичного ключа в объекте, сделать id обычным полем. Но при этом терялись преимущества использования первичного ключа: индексирование Realm, что ускоряет fetch объекта, возможность обновления объекта с флагом create (создать объект, если его не существует), соблюдение требования уникальности объекта.
Я хотела сохранить первичный ключ, но он не мог быть id объекта с сервера. В результате рабочим решением было иметь два идентификатора, один из них серверный, optional поле, а второй — локальный, который и был бы первичным ключом.
В итоге локальный id генерируется на клиенте при создании объекта локально, а в случае, когда объект приходил с сервера, он равен серверному id. Т. к. в приложении single source of truth является база данных, при получении данных с сервера объекту проставляется актуальный локальный идентификатор, и работа идет только с ним. При отправке данных на сервер передается серверный идентификатор.
Хранение несинхронизированных изменений
Изменения объектов, которые еще не были отправлены на сервер, необходимо хранить локально. Это можно реализовать следующими способами:
- добавлением полей к существующим объектам;
- хранением несинхронизированных объектов в отдельных таблицах;
- хранением отдельных изменений полей в каком-то формате.
Я не использую объекты Realm напрямую в своих классах, а делаю их маппинг на свои, чтобы избежать проблем с многопоточностью. Автообновление интерфейса идет с помощью auto-updating results выборок, где я подписываюсь на обновления запросов. Только первый подход работал с моей текущей архитектурой, поэтому выбор пал на добавление полей к существующим объектам.
Больше всего изменений претерпел объект карты:
- synced — есть ли данные на сервере;
- deleted — true, если карта удалена только локально, необходима синхронизация.
Идентификаторы, о которых шла речь в предыдущей части:
- localId — первичный ключ сущности в приложении, либо равный серверному id, либо сгенерированный локально;
- serverId — id с сервера.
Отдельно стоит упомянуть хранение изображений. В сущности Attachment к полю serverURL изображения на сервере добавилось поле diskURL, хранящее адрес локального несинхронизированного изображения. При синхронизации изображения локальное удалялось, чтобы не засорять память устройства.
Синхронизация с сервером
Для синхронизации с сервером была добавлена работа с Reachability, чтобы при появлении интернета запускался механизм синхронизации.
Сначала проверяется, есть ли в базе данных изменения, которые нужно отправить. Потом на сервер идет запрос о получении актуального слепка данных, в результате на клиенте отсеиваются изменения, которые не нужно посылать (например изменение объекта, который на сервере уже удалили). Оставшиеся изменения формируют очередь запросов на сервер.
Для отправки изменений можно было реализовать bulk updates, посылая изменения массивом, или же сделать большой запрос на синхронизацию всех данных. Но к тому времени бэкенд-разработчик уже был занят в другом проекте, и помогал нам только в свободное время, поэтому для каждого типа изменения создается свой запрос.
Я реализовала очередь через OperationQueue и обернула каждый запрос в асинхронную Operation. Некоторые операции зависят друг от друга, например, мы не можем загрузить изображение карты до создания карты, поэтому я добавила dependency операции изображения на операцию карты. Также операции загрузки изображений на сервер был поставлен меньший приоритет, чем всем остальным, и добавляла в очередь я их тоже последними из-за их тяжеловесности.
При планировании оффлайн-режима большим вопросом было разрешение конфликтов с сервером при синхронизации. Но когда мы дошли до этого в ходе реализации, поняли, что случай, когда пользователь меняет одни и те же свои данные на разных устройствах, очень редкий. Значит нам достаточно реализовать механизм last writer wins. При синхронизации приоритет всегда отдается неотправленным изменениям на клиенте, они не перетираются.
Обработка ошибок пока в зачаточном состоянии, при неудачной синхронизации объект будет добавлен в очередь изменений при следующем появлении интернета. И потом если он так и будет висеть несинхронизированным после мерджа, пользователь сам решит, оставить его или удалить.
Дополнительные workaround при работе с Realm
При работе с Realm столкнулись еще с несколькими проблемами. Возможно, этот опыт также будет кому-то полезен.
При сортировке по строке порядок идет согласно порядку символов в UTF-8, поддержки регистронезависимого поиска нет. Мы столкнулись с ситуацией, когда названия в нижнем регистре идут после названий в верхнем регистре, например: Магнит, Пятерочка, Лента. Если список очень большой, все названия в нижнем регистре будут внизу, что очень неприятно.
Для сохранения порядка сортировки независимо от регистра пришлось вводить новое поле lowercasedName, обновлять его при обновлении name и сортировать по нему.
Также новое поле добавили для сортировки по наличию карты в избранном, так как по сути для этого нужен подзапрос по связям объекта.
При поиске в Realm есть метод CONTAINS[c] %@ для регистронезависимого поиска. Но, увы, он работает только с латиницей. Для русских брендов тоже пришлось создавать отдельные поля и вести поиск по ним. Но позже это оказалось нам на руку для исключения специальных символов при поиске.
Как видите, для мобильных приложений вполне можно реализовать оффлайн-режим с сохранением изменений и синхронизацией малой кровью, а иногда даже с минимальными изменениями на бэкенде.
Несмотря на некоторые сложности, вы можете использовать для его реализации Realm, получая при этом все преимущества в виде live updates, zero-copy architecture и удобного API.
Так что нет никакой причины лишать ваших пользователей возможности доступа к данным в любой момент, вне зависимости от качества соединения.
Ilya81
И как этот Realm? Мои впечатления от него ужасные, в итоге заменил на CoreData — с ним проблем меньше. Самая главная проблема с Realm у меня — потоки, решения я так и не нашёл, пришлось "менять коней на переправе". Если обращение к базе данных происходит из разных потоков — именно потоков, а не
DispatchQueue— выдаёт ошибку. Решения так и не нашёл, смотрел в исходники, а там всё проверяется в классе на C++. Понятно — это даёт межплатформенность, но работать с ним на Swift становится почти невозможно. Мало того, что единственный вариант — создавать свой STA через классThread, ибоDispatchQueue, даже если serial, может обрабатывать в разных потоках, ибо кто нынче так часто работает именно на уровне потоков в эпоху многоядерных процессоров, когда пришлось б оптимизировать под каждый процессор отдельно; так ещё и никаким способом не удаётся вообще не нагружать процессор, т. е. по факту избежать разряда аккумулятора. Я некогда в итоге плюнул на этот Realm и решил использовать CoreData.Интересно даже, кому и как удалось решить эту проблему с Realm.
DataArt Автор
Именно из-за проблем с многопоточностью я использовала Realm-объекты только в классах, отвечающих непосредственно за хранение/выдачу информации из базы данных. Дальше они маппились на обычные структуры, которыми я уже спокойно оперировала в остальных частях приложения. Чтобы обновлять свои объекты при изменении Realm-объектов, использовала нотификации, подписывалась на изменения результатов запросов.
Все операции с Realm-объектами происходили в соответствующих методах слоя работы с бд, в каждом методе я создавала instance Realm’а, с которым проводила операции по чтению или записи информации, так что Realm-объекты не передавались между потоками. Перед блоком операции записи проверяла, что мы не в главном потоке.