
Был интересный опыт, когда с другом восстанавливали .wav файл. Я решил описать наш мучительный процесс, вдруг кому-то пригодится.
Предыстория
Бывают грустные истории, когда диктофон зависает/или выдает ошибку при сохранении файла. Следовательно, при попытке открыть поврежденный файл мы получаем ошибки, типа: не удалось декодировать формат, неверный формат или программа не распознала формат файла.
Пытаемся разобраться
Так как открыть файл у нас не получилось, решили по гуглить. Мы хотели понять, как скормить .wav файл проигрывателю. Нашли кучу советов: загрузить его в Raw(сыром формате), поиграться с настройками и т.д. Все эти попытки потерпели фиаско.
Решили изучить, что такое вообще wav, нашли инфу про заголовки и их описание:

Устанавливаем хекс редактор (wxHexEditor), открываем и пытаемся хоть что-то найти похожее на заголовок.
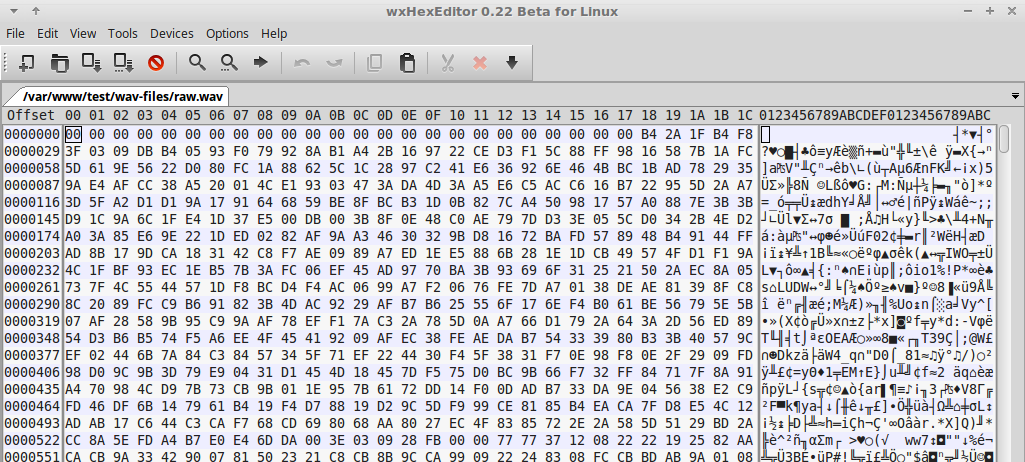
Провал… их не было.
Решили записать новую запись с удачным сохранением. Открыли его в редакторе и смотрим заголовки.
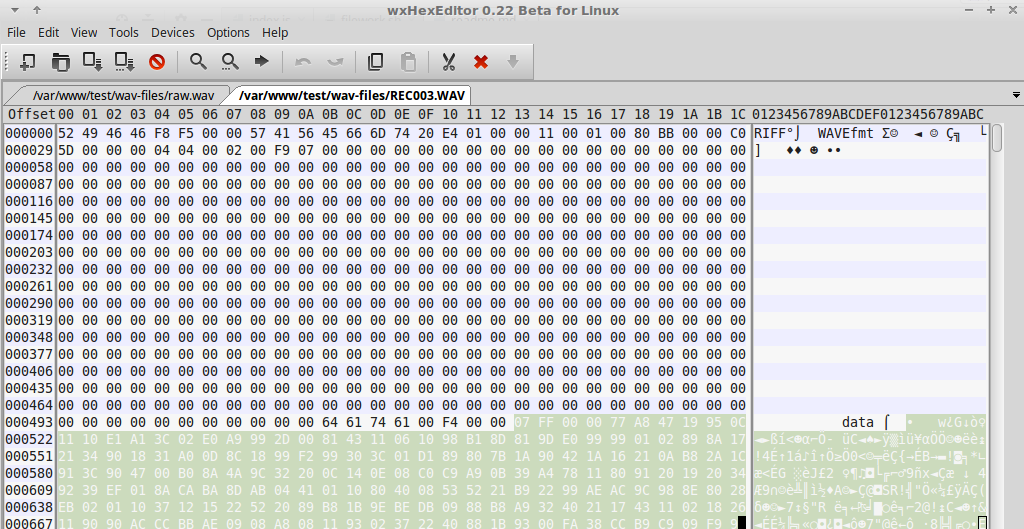
Копируем заголовки и вставляем в наш битый файл (далее БФ)! Судорожно сохраняем и запускаем файл в проигрывателе, и ничего не работает! (Я, как настоящий мужик, начал рыдать в углу комнаты)
Перед тем как что-то построить, нужно что-то сломать.
Мы решили разобраться, как можно сломать нормальный файл и получить такую уродскую картину, как поврежденный файл.
Рисунок: сверху склеенный БФ, внизу нормальная запись.
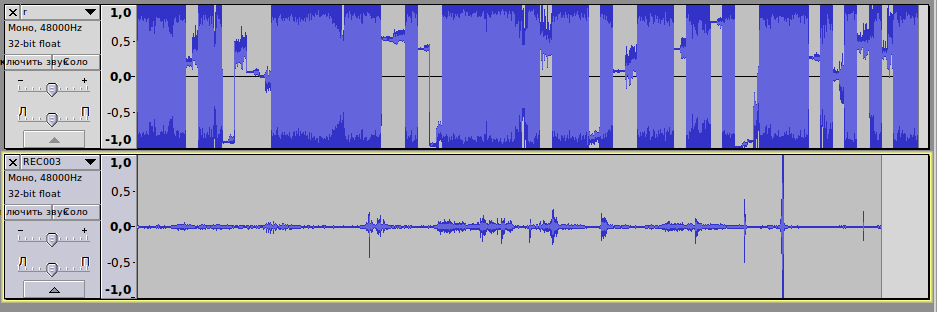
Оказалось что, если удалить в хексРедаторе 1 байт в нормальном файле и сохранить, картина становится похожей. А если вернуть байт, даже пустой забитый нулями, то все становится нормально.
Написание баш скрипта
Решили побайтово удалять и сохранять файл, чтобы получить нормальную картину, как на рисунке выше. Создали 2 файла, один только заголовки, а другой поврежденный файл (предварительно его обрезав чуть меньше мегабайта).
Написали небольшой скрипт, который удаляет один байт из файла и склеивает с заголовком, после чего сохраняет с порядковым номером.
#!/bin/bash
for i in {1..1000}
do
cat header.wav > "./wav/$i.wav"
tail -c +$i raw.wav >> "./wav/$i.wav"
doneЗапускаем скрипт и с трепетом, на краешке стульчика, ждем результат. К сожалению, нам пришлось просматривать эти файлы вручную, но как лучше сделать по другому мы не знали. Закидывали по 250 файлов в audacity и просматривали дорожки:
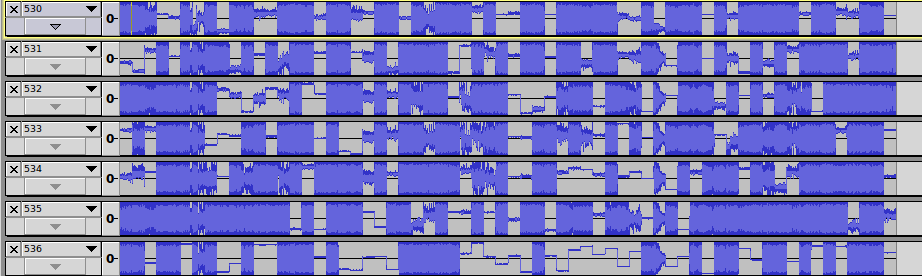
Скроллить пришлось недолго, потому что на 537 файле мы нашли, то что искали:
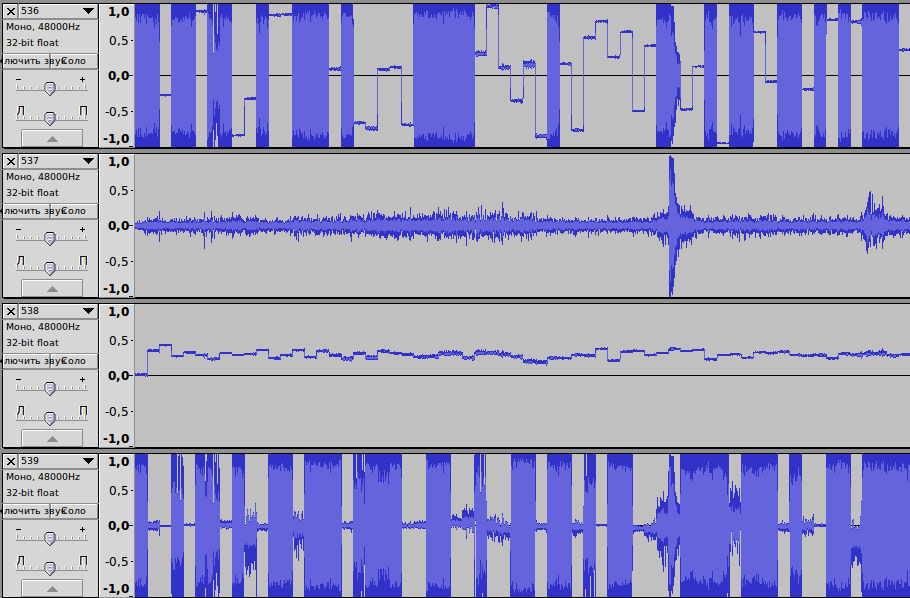
Осталось дело за малым. Смотрим этот файл в хеш редаторе, где он остановился. Открываем БФ в редакторе и удаляем после заголовка нужную нам длину байтов. Вот и все, двухчасовой файл нормально воспроизводится.
P.S.
Скорее всего, это можно было сделать проще. Кто знает, как облегчить работу или как-то ее оптимизировать, пишите, добавлю в этот "гайд".
Всем спасибо за внимание.
Комментарии (10)

vassabi
14.12.2018 18:42судя по гистрограммам — можно было сначала передавать «восстановленные кандидаты» аудио в ffmpeg, который бы отрезал первые Н секунд, и выдавал бы ее громкость, а потом фильтровать слишком громкие, чтобы не смотреть все подряд.
ashumkin
17.12.2018 08:45+1Мне грустно видеть статью плана бложика "мы взяли битый файл, нашли спецификацию файла, ничего в ней не поняли, и путём полуручного подбора нашли что-то похоже, и, о, счастье, нам повезло, и мы восстановили файл"
Ладно бы, автоматизировали (как указано выше; или путем спектрального какого-нибудь анализа...) хотя бы определение подходящих кандидатур для ручного просмотра из множества перебора… а так...
QwertyOFF
Должно было бы помочь просто сделать корректный заголовок с правильным количеством байт и перебрать пару вариантов с удалением байта-двух в зависимости от того где слетела запись (по краю сэмпла или в середине, если это вообще возможно исходя из разрядности).
UPD: посмотрел по заголовку, у вас не PCM, так что возможно все иначе.
staticlab
Почему не PCM?
И вообще проблема ребят в том, что они не попытались понять, что именно содержится в заголовке WAV и каким он должен быть для их данных.
AlNi89
Потому что с РСМ такого не получится:
файл может исказиться, но в звуковом редакторе не будет таких явных блочных проблем. И вообще, судя по ступенькам, там скорее всего АДИКМ сжатие.
staticlab
Если они удаляли из начала файла, то могло быть, потому что произошло бы смещение слов.
yesworld Автор
Ну не то чтобы не пытались… Может действительно, что-то не так сделали.
Я правильно вас понял, что при помощи заголовков можно всегда все исправить и не важно на каком участке были удалены данные?
vassabi
Совсем «всё» — нет, во-вторых — не только при помощи заголовков, а при помощи выравнивания (т.е. удалением невосстановимых или добавлением пустых данных,
так как типичное кодирование видео\аудио редко когда не содержит опорных данных внутри потока), когда установлены правильные заголовки.
staticlab
В большинстве случае PCM кодируется 16-битными значениями. То есть, если смещение имело место быть, то Audacity помог бы найти этот участок, а затем в хекс-редакторе достаточно было бы удалить (или добавить) всего один байт.