

?? В сети можно найти огромное количество разнообразных статей о методах использования алгоритмов математической статистики, о нейронных сетях и в целом о пользе машинного обучения. Данные направления способствуют существенному улучшению жизни человека и светлому будущему роботов. Например, заводы нового поколения, способные работать полностью или частично без вмешательства человека или машины с автопилотом.
??Разработчики объединяют комбинации этих подходов и методов машинного обучения в различные направления. Эти направления впоследствии получают названия, оригинальные и не очень, например: IOT (Internet Of Things), WOT (Web Of Things), Индустрия 4.0 (Industry 4.0), Artificial Intelligence (AI) и другие. Данные концепции объединяет то, что их описание является верхнеуровневым, то есть не рассматриваются ни конкретные инструменты и технологии, ни уже готовые к внедрению системы, а основной целью является визуализация желаемого результата. Но технологии уже существуют, хотя часто не имеют единой платформы.
Решения предоставляют как крупные вендоры ПО: SAS, SAP, Oracle, IBM, так и маленькие стартапы, составляющие крупным игрокам сильную конкуренцию, а также решения с открытым исходным кодом — open source решения. Все это многообразие сильно осложняет быстрое и эффективное выполнение поставленной задачи, так как требует трудоемкой интеграции различных систем между собой, огромных трудов разработчиков по созданию хороших моделей машинного обучения и будущую имплементацию этих решений в продуктив. Но в то же время основной критерий успешности любого инновационного проекта, который меняет подход компании к ведению бизнеса часто требует быстрого доказательства успешности и состоятельности, а иначе никто не рискнет его запустить. А это невозможно без использования единой платформы, которая позволит выполнять быстро весь цикл подготовки (поиска, сбора, очистки, консолидации) данных и получать финальные результаты в виде качественной аналитики (в том числе с использованием алгоритмов машинного обучения), и, как следствие, прибыли для компании.
Про SAS
?? Многие возможно согласятся, что SAS занимает высокие позиции на рынке решений для продвинутой аналитики. Отзывы о решениях SAS могут быть разные, но равнодушных нет, что подтверждается наличием большого числа заказчиков в России и в мире. Во многом благодаря уже готовым алгоритмам и моделям, которые можно легко и быстро внедрить в компании и быстро получить результат. Об этом много было написано в первой статье в блоге компании SAS – прочитать можно здесь. В этой статье описываются предпосылки успешности компании SAS и история ее возникновения. Но IT и бизнес сообщество стремительно развиваются и становятся все требовательнее к инструментам, поэтому компания SAS выпустила новую аналитическую платформу SAS Viya. Эта платформа включает в себя все лучшее, что было создано в компании SAS с момента возникновения до настоящего времени, для того, чтобы предопределять современные тенденции класса решений для продвинутой аналитики. Возвращаясь к красивым названиям и определениям, SAS Viya дает единую платформу для такого направления как self-service data science c использованием возможностей in-memory, которая разработана с использованием подходов распределенных(облачных) вычислений и микросервисной архитектуры. Итак, эта статья открывает цикл статей про платформу SAS Viya, чтобы по порядку разобраться с тем, что такое Viya, что она может и как ее использовать.
Трудности выбора
?? Мы уже выяснили, что сейчас на рынке существует огромное количество продуктов известных вендоров и игроков поменьше, а также open source, который позволяет решать различные аналитические задачи во всех сферах бизнеса. Какие же критерии, кроме цены, должны учитываться при принятии решения о выборе той или иной платформы?
??????????????

??Начнем с того, что сейчас бизнес пользователь становится все больше вовлечен в полный аналитический цикл и требует большей независимости от ИТ. На первый план выходят понятные этим пользователям критерии – удобство использования (единые интерфейсы), минимизация обучения новым системам (меньше кода, больше графики), производительность (в разрезе аналитики — это возможность быстрого получения результата на больших массивах данных), наличие готовых алгоритмов и моделей для работы. Время “черных” экранов уходит, терминальные окна, хотя и в другом виде, все еще доступны и позволяют писать и отлаживать код прямо на ходу, но большую часть функций уже давно можно реализовать в виде блоков в графическом интерфейсе, что открывает двери для пользователей любых уровней для работы с продвинутой аналитикой (хотя математику знать все же желательно).
?? Второй тренд, который неизбежно завоевывает рынки – это облачные технологии. С точки зрения компаний это возможность гибкого управления доступными ресурсами под любые проекты. Существует много исследований о времени полного вытеснения облачными технологиями классических решений. Но здесь важно понимать, что облачные вычисления — это не только железо, которое живет где-то далеко во внешних цодах, но и сам подход гибкого предоставления всевозможных услуг в виде сервисов, которые можно получить быстро и без необходимости выстраивания или перестраивания сложной IT инфраструктуры.
??Еще один тренд – использование Big Data технологий. Да и использование всей Hadoop экосистемы в целом со своими языками и технологиями, а также других доступных open source систем, которые дают интерфейсы для работы с данными, такие как R, Python и другие. В этой области нет смысла конкурировать, но есть смысл иметь технологии для интеграции с этой экосистемой. Или не просто интегрироваться, а использовать возможности этой экосистемы как в случае с SAS Hadoop Embedded Process или использование Kafka для построения High Availability для систем ESP (SAS Event Stream Processing). А иногда даже улучшать и ускорять, как например возможность запускать код на R на движке CAS в SAS Viya.
Универсальная платформа
??Спрос рождает предложение и SAS Viya не исключение из правил. Если обратиться к официальному определению SAS Viya, которое было дано Джимом Гуднайтом (очень сильно сокращено, но смысл сохранен) во время анонса в 2016 году на глобальном SAS форуме, то SAS Viya это: "Облачная система, которая использует подходы распределенных вычислений…и дает единую платформу для аналитики"
??Ну а если коротко сформулировать идею и цели платформы SAS Viya – то это универсальная платформа для любого вида анализа на всех стадиях проекта от подготовки данных до применения сложных алгоритмов машинного обучения. Можно выделить 4 блока задач:
?1. Подготовка данных
?2. Визуализация и исследование данных
?3. Прогнозная аналитика
?4. Продвинутая аналитика в виде алгоритмов машинного обучения
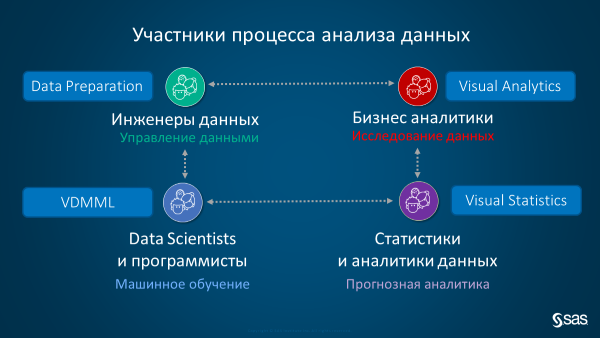
Информация для читателей
??Так как в рамках одной статьи все рассказать достаточно трудно без ущерба важным нюансам, то эти шаги будут рассмотрены в следующих статьях на примерах. В этой статье мы рассмотрим важную тему движка SAS Viya, который обеспечивает быструю работу аналитических инструментов. Статьи про современные и красивые интерфейсы следующие в очереди.
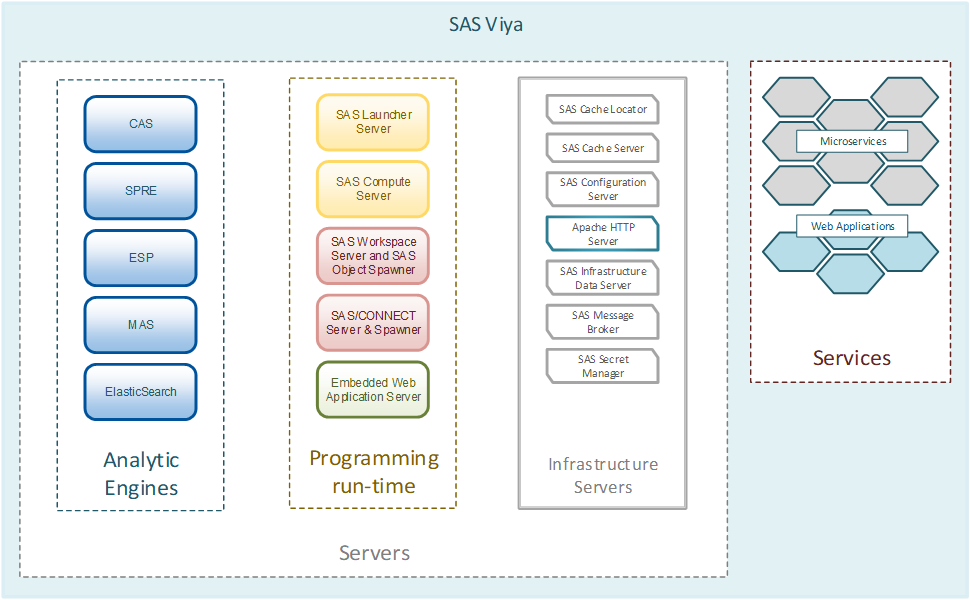
Основа платформы SAS Viya
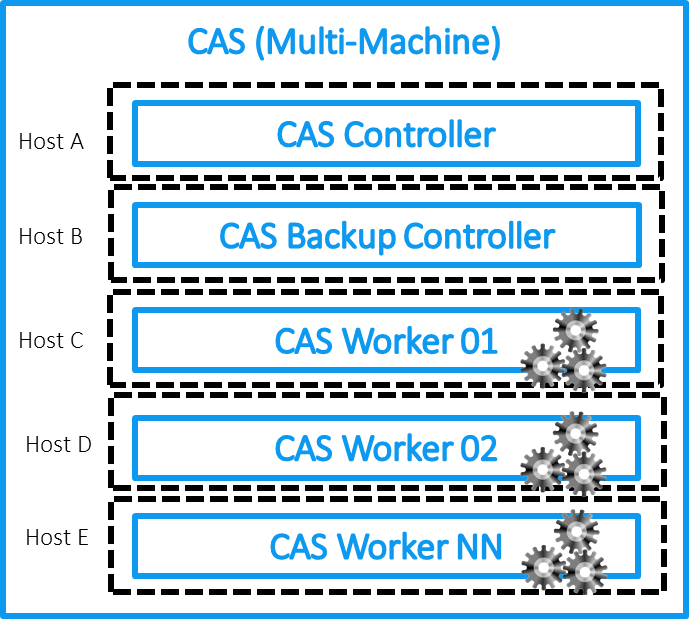
??У SAS Viya есть несколько ключевых особенностей, с которых необходимо начать. Тем, кто работал с решениями SAS, известно, что в основе SAS лежит специальный аналитический язык SAS Base, который выполняет аналитические задачи на своем движке. Его можно использовать в конфигурации Grid на кластере или на одной мощной вычислительной машине. Здесь кроется основное отличие SAS Viya от классических решений для аналитики SAS 9. В основе SAS Viya лежит новый уникальный движок обработки данных CAS (Cloud Analytics Service). Две ключевые особенности: первое — это in-memory технология, которая выполняет все операции с данными в оперативной памяти, а второе – это подход распределенных вычислений. CAS может работать на одном хосте, но оптимизирован для работы на кластере из машин – контроллере и серверах обработки данных, которые позволяет хранить и обрабатывать данные на разных узлах кластера для распараллеливания нагрузки (идейно подход очень близок к концепции Hadoop систем). Если отобразить на схеме архитектуру CAS, то мы получим следующую картинку для MPP или SMP установки:

Почему Cloud?
??SAS при разработке платформы Viya и CAS в частности использовала преимущества концепции облачных вычислений. Их можно выделить в 4 группы:
?1. Доступность через большой набор API разных клиентов. Для SAS это большой шаг вперед. Больше нет ограничений на использование только языка SAS Base для аналитики. Можно использовать Python (Например, из Jupiter Notebook), R, Lua и др., выполнение которых будет происходить в CAS на платформе SAS Viya.
?2. Эластичность. Можно легко масштабировать систему, подключая/отключая узлы кластера CAS. Приложения доступны через web и организованы в виде микросервисов. Они независимы друг от друга в вопросах установки, обновления и работы.
?3. Высокая доступность. В CAS используется система зеркалирования данных между узлами кластера. Один набор данных хранится на нескольких узлах, что уменьшает риск потери данных. Переключение в случае отказа одного из узлов происходит автоматически с сохранением состояния выполнения задания, что часто бывает критично для тяжелых аналитических расчетов.
?4. Повышенная безопасность. Так как облако может быть получено от публичного провайдера, то реализация должна соответствовать более жестким требованиям к надежности каналов передачи данных.
Развернуть платформу Viya можно где угодно — в облаке, на выделенной машине в своем цоде, в кластере из любого количества машин. Автоматически обеспечивается отказоустойчивость решения.
Как же CAS работает?
Я буду разбирать работу CAS на примере MPP установки. SMP упрощает, но сохраняет принципы работы CAS. В реальной жизни SMP можно использовать в качестве тестовых локальных сред для отработки моделей с последующим переносом разработки на MPP платформу для лучшей производительности.
Давайте еще раз посморим на верхнеуровневую архитектуру CAS на SAS Viya:
?? Если говорить про CAS, то он состоит из контроллера, по-другому, мастер ноды (плюс есть возможность выделить еще один узел для резервной ноды контроллера) и рабочих узлов. Мастер нода хранит метаинформацию о данных, расположенных на узлах кластера, и отвечает за распределение запросов на эти узлы (CAS Workers), выполняющие обработку и хранение данных. Отдельно выделен сервер, на котором находятся аналитические сервисы и дополнительные модули, необходимые для работы платформы. Их тоже может быть несколько в зависимости от задач. Например, можно использовать на отдельной машине в рамках инсталляции Viya сервер для SPRE (SAS Programming Runtime Environment), который позволит запускать классические задачи SAS 9 на платформе Viya как с использованием CAS, так и SPRE.
??Есть интересная конфигурация, которая расширяет возможности использования CAS на платформе Viya, и оправдывает первую букву своего названия Cloud:
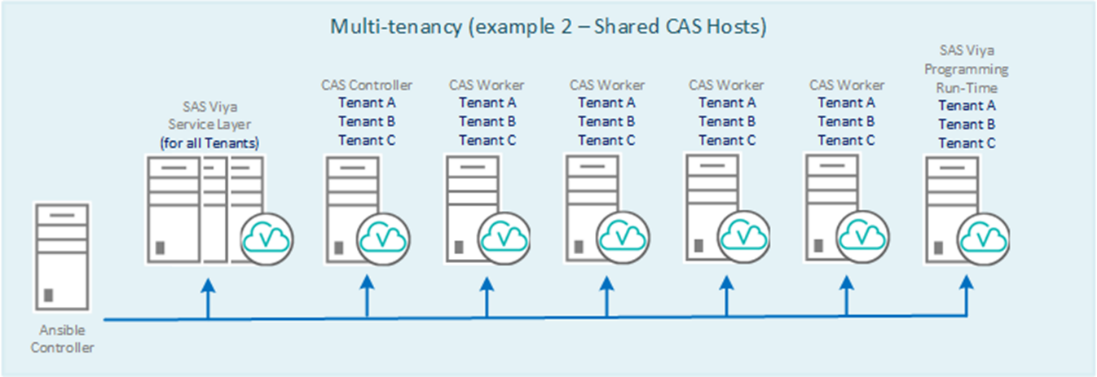
Мультиарендность (multitenancy) дает возможность разделить ресурсы и данные между департаментами. При этом “арендаторам” дается единый интерфейс доступа к платформе и обеспечивается логическое разделение различных функций платформы Viya. Вариантов достаточно много. Возможно, этот вопрос будет рассмотрен в отдельной статье.
Как же быть с надежностью оперативной памяти и как загрузить данные в CAS?
??Так как мы говорим про аналитику, а тем более про передовые решения для продвинутой аналитики, то понятно, что мы говорим про большие объемы данных. И важная часть процесса – быстрая загрузка данных в оперативную память для выполнения операций с ними и обеспечение высокой доступности этих данных.
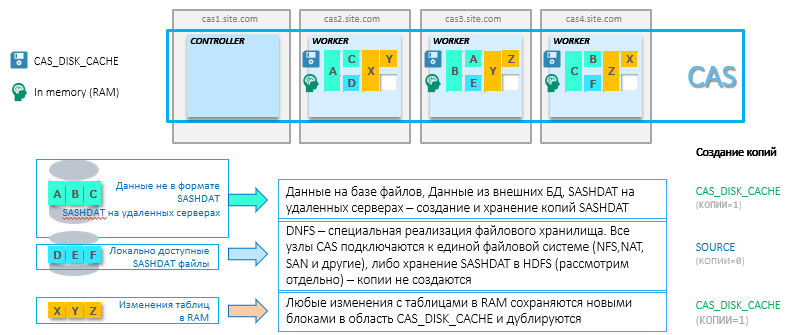
??Любая in-memory система для надежности требует бэкапирования данных, которые находятся в RAM. RAM не умеет сохранять состояние при отключении питания плюс все данные могут не поместиться в область оперативной памяти, и необходим механизм для быстрой перезагрузки данных в RAM. Поэтому для таблиц, которые загружаются в CAS для аналитики, создаются копии в области постоянной памяти специального формата SASHDAT. Для обеспечения высокой доступности эти файлы зеркалируются на нескольких узлах кластера. Этот параметр можно настроить. Идея в том, что при потере узла данные будут автоматически загружены в оперативную память на соседнем узле из копии файла SASHDAT. Область хранения этих копий в структуре CAS называется CAS_DISK_CACHE.
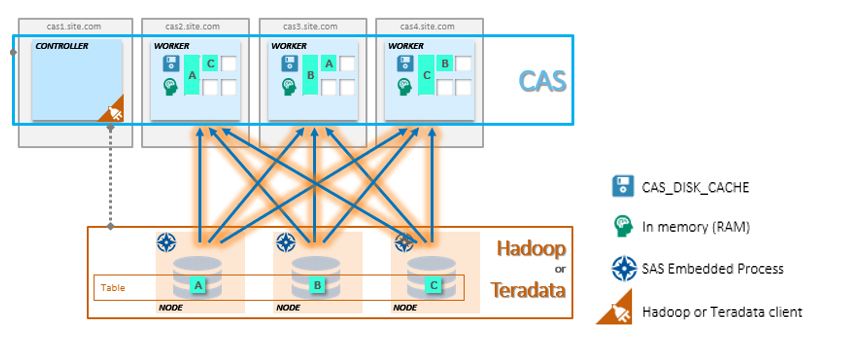
??CAS_DISK_CACHE это важная часть в составе CAS, которая нужна не только для обеспечения отказоустойчивости, но и оптимизации использования памяти. На схеме ниже отображены разные способы хранения SASHDAT и принцип загрузки данных в RAM. Например, датасет A получен из БД Oracle и хранится на одном узле CAS в RAM и на диске. Плюс этот датасет A дублируется на другом узле только на жесткий диск. Вариантов много (некоторые из них не требуют дополнительного резервирования – это будет рассмотрено ниже), но основная идея в том, чтобы всегда иметь копию для быстрого восстановления ранее загруженных данных в оперативную память. Кстати, в случае установки двух параметров: MAXTABLEMEM=0 и COPIES=0 на уровне сессии, данные будут жить только в оперативной памяти.
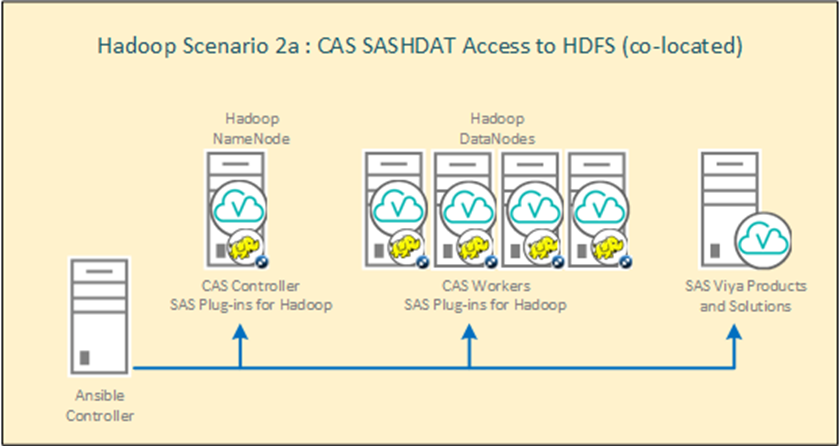
??Отдельно хочется рассмотреть интересную конфигурацию CAS с Hadoop. Для использования этой конфигурации CAS вместе с Hadoop системой нужна установка SAS Plugins for Hadoop. Основная идея подхода в том, что узлы кластера Hadoop становятся также рабочими узлами CAS. Данные затягиваются в оперативную память напрямую из файлов в hdfs без сетевой нагрузки. Это лучший вариант с точки зрения производительности. Можно использовать Hadoop либо только для хранения SASHDAT файлов (HDFS на кластере будет выполнять роль CAS_DISK_CACHE –резервирование на уровне HDFS), либо вместе с другими данными. Распределение ресурсов на кластере Hadoop выполняется через YARN. Схема установки CAS на кластер Hadoop:
Загрузка
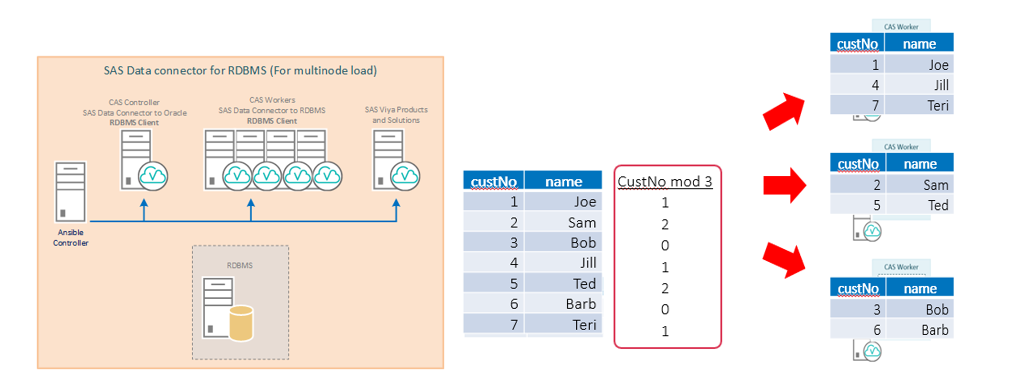
??С загрузкой данных все просто. Мы можем указать различные источники на вход CAS. Их можно загружать или в один поток или параллельно. Так как реляционные базы данных используются гораздо чаще в качестве источников, мы рассмотрим тему загрузки данных в CAS из RDBMS. Для оптимизации загрузки данных в кластер CAS желательно установить клиентское ПО базы данных источника на каждый узел кластера. В этом случае каждый узел CAS кластера будет получать свою порцию данных в параллельном режиме. При установке клиента только на контроллер все данные будут передаваться через CAS контроллер.
??Например, при установке параметра numreadnodes=3 таблица будет автоматически разбиваться на 3 порции данных для загрузки на разные узлы CAS – в этом случае распределение данных будет основано на группировке по первому числовому столбцу с применением операции mod 3.
??Если же в качестве источника используются Hadoop или Teradata, то с использованием Embedded Process для Hadoop или Teradata загрузка будет выполняться напрямую с каждого узла кластера Hadoop или Teradata. Обратите внимание, что в случае с отдельной инсталляцией кластера Hadoop (CAS установлен не на узлах Hadoop) область CAS_DISK_CACHE будет создана на кластере CAS.
С чего начать работу с CAS?
??Важными терминами в работе CAS являются библиотеки и сессии. При начале работы с CAS первое, что создается – это сессия. Ее можно определить вручную при работе через SAS Studio, или она автоматически создается через доступные графические интерфейсы на SAS Viya при подключении к CAS. Внутри сессии все данные и преобразования, которые определяются в новых библиотеках, по умолчанию создаются с локальной областью видимости. Данные (определенные в caslib) и результаты шагов локальной сессии видны только в этой сессии. В случае, если нам нужно сделать результаты общедоступными, то мы можем переопределить caslib параметром global и оператором promote, и данные будут доступны из других сессий. Библиотеки, которые уже определены с параметром global, будут доступны из любых сессий. Сделано это для оптимального разделения ресурсов и управления правами доступа к данным. После отключения от локальной сессии удаляются все временные данные, если caslib не был переопределен в global. Мы можем настроить параметр TIMEOUT для удаления данных при отключении от сессии, чтобы избежать возможных потерь при кратковременных сетевых сбоях или чтобы вернуться к этой сессии для дальнейшего анализа (например, можно выставить параметр TIMEOUT на 3600 секунд, что даст нам 60 минут времени для возврата к сессии). Плюс данные можно сохранить на любом шаге преобразований в специальный формат SASHDAT или в доступную БД, к которой настроено подключение простым оператором SAVE.
??Библиотеки caslibs описывают наборы данных, которые будут доступны в CAS. При создании caslib указывается тип подключения и параметры подключения. В определении caslib мы указываем сразу на источник данных и на целевую область в in-memory. Также на уровне caslib удобно задавать права доступа группам пользователей к данным, которые описаны в caslib. Делается это в графическом интерфейсе.
Пример описания caslib для разных типов источников:
caslib caspth path="/data/cust/" type=path; где caspth – указатель на область памяти, path - источник
caslib pgdvd datasource=(
srctype="postgres",
username="casdm",
password="xxxxxx",
server="sasdb.race.sas.com",
database="dvdrental",
schema="public",
numreadnodes=3) ;
caslib hivelib desc="HIVE Caslib"
datasource=(SRCTYPE="HIVE",SERVER="gatekrbhdp01.gatehadoop.com",
HADOOPCONFIGDIR="/opt/sas/hadoop/client_conf/",
HADOOPJARPATH="/opt/sas/hadoop/client_jar/",
schema="default",dfDebug=sqlinfo) GLOBAL ;??После определения caslib мы можем загружать данные в оперативную память для дальнейшей обработки. Пример загрузки данных caslib hivelib:
proc casutil;
load casdata="stocks" casout="stocks" outcaslib="hivelib" incaslib="hivelib" PROMOTE ;
quit;
/* где casdata – название источника(таблица в hive), casout – название целевой таблицы в CAS,
outcaslib – бибилиотека caslib, в которой мы хотим развернуть таблицу, incaslib – бибилиотека caslib, в которой находится источник.*/
/*Переопределение in/out caslib может быть полезно для создания витрины данных, которая состоит из разных источников*/??Внутри каждой сессии запросы (actions) выполняются последовательно. Это важно при написании кода вручную, но при использовании графических интерфейсов, доступных на Viya, об этом можно не думать. Клиентские приложения с GUI сами создают раздельные сессии для выполнения шагов в параллельном режиме.
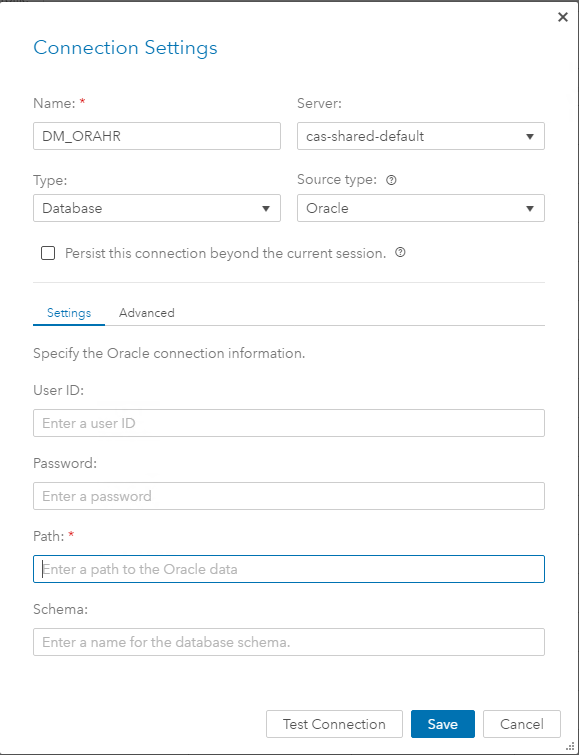
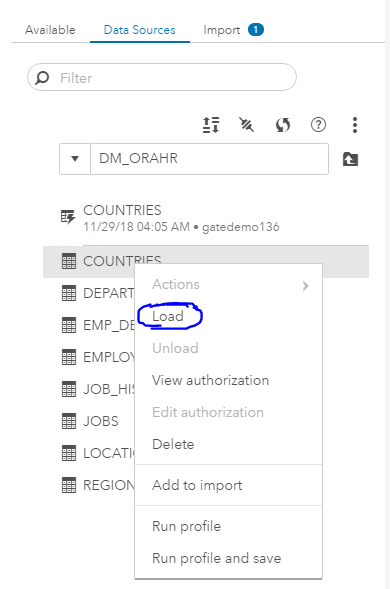
??Полноценно графические интерфейсы и подходы работы через них мы рассмотрим в следующих статьях. Здесь добавлю скриншоты шагов по созданию caslib DM_ORAHR и загрузки данных в RAM через GUI:
Это только начало
??На этом я заканчиваю часть про CAS и возвращаюсь к платформе Viya. Так как Viya создана для бизнес-пользователей, то в процессе работы не нужно будет глубоко понимать специфику работы CAS. Для всех операций есть удобные графические интерфейсы, а CAS будет обеспечивать быструю работу всех аналитических шагов за счет in-memory и распределенных вычислений.
??Теперь можно переходить к пользовательским интерфейсам, которые доступны на Viya. На текущий момент их достаточно много, и количество продуктов постоянно увеличивается. В начале статьи они были выделены в 4 группы, которые нужны для полного аналитического цикла. Возвращаясь к основной идее, Viya – это единая платформа для исследования данных и продвинутой аналитики. А начинается работа с подготовки и поиска этих данных. И в следующей части цикла статей про Viya я расскажу про инструменты подготовки данных, которые доступны аналитикам.
??Вместо заключения, название Viya происходит от слова Via (от англ. “посредством” или “через”). Основная идея этого названия в простом переходе от классического решения SAS 9 к новой платформе, которая создана, чтобы перевести аналитику на новый уровень.