

Классификация текста — одна из наиболее распространенных задач в NLP и обучении с учителем, когда датасет содержит текстовые документы, а метки используются для тренировки текстового классификатора.
С точки зрения NLP, задача классификация текста решается путем обучения представления на уровне слов с использованием встраивания слов и последующего обучения представления на уровне текста, используемого в качестве функции для классификации.
Тип методов, основанных на кодировании, игнорирует мелкие детали и ключи для классификации (поскольку общее представление на уровне текста изучается путем сжатия представлений на уровне слов).
Методы для классификации текста с сопоставлением на уровне текста, основанные на кодировании
EXAM — новый метод классификации текста
Исследователи из Университета Шаньдун и Национального университета Сингапура предложили новую модель классификации текста, которая включает сигналы сопоставления на уровне слов в задачу классификации текста. В их методе используется механизм взаимодействия для введения в процесс классификации детальных подсказок на уровне слов.
Чтобы решить проблему включения более точных сигналов сопоставления на уровне слов, исследователи предложили явно вычислить оценки соответствия между словами и классами.
Основная идея состоит в том, чтобы вычислить матрицу взаимодействия из представления на уровне слов, которая будет нести соответствующие ключи на уровне слов. Каждая запись в этой матрице — оценка соответствия между словом и конкретным классом.
Предлагаемая структура для классификации текста, названная EXAM — EXplicit interAction Model (GitHub), содержит три основных компонента:
- кодировщик на уровне слов,
- слой взаимодействия и
- слой агрегации.
Эта трехуровневая архитектура позволяет кодировать и классифицировать текст, используя как мелкие, так и обобщенные сигналы и подсказки. Вся архитектура приведена на изображении ниже.

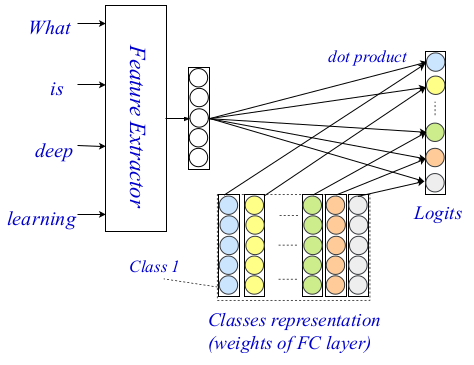
Архитектура EXAM
В прошлом, кодировщики на уровне слов широко исследовались в сообществе NLP, появились очень мощные кодировщики. Авторы используют соверменный метод в качестве кодировщика на уровне слов, и в своей работе они подробно описывают два других компонента своей архитектуры: уровень взаимодействия и агрегации.
Слой взаимодействия, основной вклад и новизна в предлагаемом методе основаны на хорошо известном механизме взаимодействия. Исследователи используют обучаемую матрицу представлений для кодирования каждого из классов, чтобы позже иметь возможность вычислять оценки взаимодействия между классами. Окончательные оценки проставляются с использованием точечного произведения в качестве функции взаимодействия между целевым словом и каждым классом. Более сложные функции не рассматривались из-за увеличения сложности вычислений.
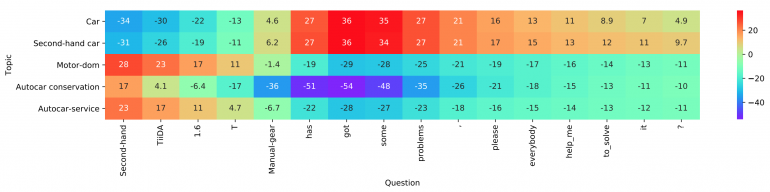
Визуализация работы слоя
Наконец, в качестве слоя агрегации они используют простой полносвязный двухслойный MLP. Они также упоминают, что здесь можно использовать более сложный уровень агрегации, включающий CNN или LSTM. MLP используется для вычисления окончательных классификационных логитов с использованием матрицы взаимодействия и кодировок на уровне слов. Кросс-энтропия используется как функция потерь для оптимизации.
Оценки
Чтобы оценить предложенную фреймворк для классификации текста, исследователи провели обширные эксперименты как в мультиклассовых, так и в мультитеговых условиях. Они показывают, что их метод значительно превосходит современные соответствующие современные методы.
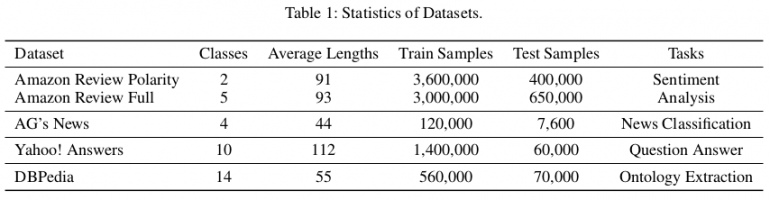
Статистика используемых датасетов для оценки
Для оценки они устанавливают три различных базовых типа моделей:
- Модели, основанные на разработке признаков;
- Глубокие модели на основе символов;
- Глубокие модели на основе слов.
Авторы использовали общедоступные эталонные наборы данных (Zhang, Zhao и LeCun 2015) для оценки предложенного метода. Всего имеется шесть наборов классификационных текстовых данных, соответствующих задачам анализа настроений, классификации новостей, вопросов-ответов и извлечения онтологий соответственно. В статье они показывают, что EXAM достигает наилучшей производительности среди трех наборов данных: AG, Yah. А. и ДАД. Оценку и сравнение с другими методами можно увидеть в таблицах ниже.
![Test Set Accuracy [%] on multi-class document classification tasks and comparison with other methods](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

Выводы
Эта работа является важным вкладом в области обработки естественного языка (NLP). Это первая работа, которая вводит более точные подсказки соответствия на уровне слов в классификацию текста в модели глубоких нейронных сетей. Предложенная модель обеспечивает state-of-the-art показатели для нескольких наборов данных.
Перевод — Станислав Литвинов
kuil
Не очень понятно, сравнивают с работами 2015-2017 годов и говорят о state of the art.
А как же, например, BERT?
Или другие языковые модели, например, от солнцеликого Джереми Ховарда — Universal Language Model Fine-tuning by Howard and Ruder (2018)?