
Данный материал знакомит с понятием сентимент-анализа, основными методами определения тональности и новыми подходами в этой области.

Текст на естественном языке, помимо информации, может выражать эмоциональную оценку того, о чём сообщается. Например, такое предложение содержит отрицательную оценку происходящего:
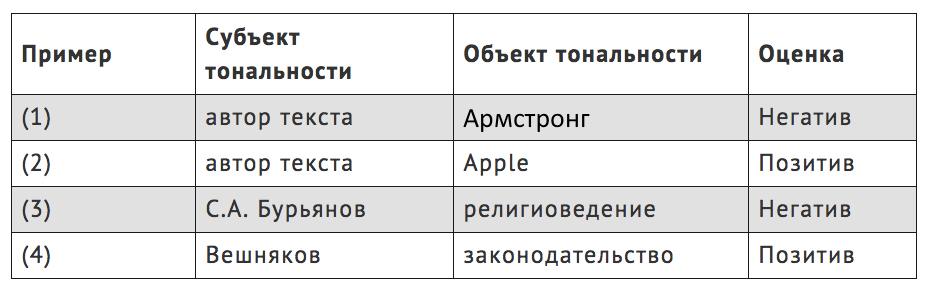
(1) В 2012 году Армстронг по итогам расследования Американского антидопингового агентства был уличен в использовании запрещенных препаратов.
А такое — положительную:
(2) Apple получила окончательное разрешение на строительство нового кампуса.
Выраженная в тексте эмоциональная оценка называется тональностью или сентиментом (от англ. sentiment — чувство; мнение, настроение) текста. Человек оценивает мир сразу по многим шкалам (хороший-плохой, сильный-слабый, большой-маленький, счастливый-несчастливый, весёлый-грустный, быстрый-медленный и т.п.), и шкалы эти по-разному эмоционально нагружены. Но для простоты можно считать, что эмоциональная оценка сводится к шкале хороший-плохой или позитивный-негативный.
Исторически сложилось так, что традиционный подход к сентимент анализу представляет собой задачу классификации текста (части текста) на две-три категории (негативный, позитивный, нейтральный или просто: негативный или позитивный) [Pang & Lee; Turney ]. Именно с такой задачи начал свое развитие анализ тональности: оценить сентимент оценочных отзывов по какой-либо тематике (кино, рестораны, электроника и пр.).
Тем не менее, это не единственный и не определяющий тип задачи, которую должен решать сентимент анализ текста. В настоящее время читателей интересует не общая эмоциональная оценка текста (средняя температура по больнице), а отношение сентимента к конкретному объекту, упоминаемому в тексте, либо отношение субъекта высказывания к обсуждаемому объекту.
Объект, относительно которого выражается эмоциональная оценка, принято называть объектом тональности. Так, в предложении (1) объектом тональности является Армстронг, а в предложении (2) — Apple. Такой вид сентимент анализа называется объектной тональностью (object-based).
Носителем выраженной в тексте эмоциональной оценки также обычно является вполне определённое лицо, в общем случае это автор текста. Однако если автор текста ссылается на чьё-нибудь мнение, как в предложении (3) ниже, или цитирует высказывание другого человека, как в предложении (4), то носителем эмоциональной оценки, или, как ещё говорят, субъектом тональности будет тот, на чьё мнение ссылаются.
(3) Религиоведение, по мнению С. А. Бурьянова, сегодня не представляет собой точной науки, характеризующейся единством и располагающей строгими и общепринятыми принципами
(4) Глава ЦИК Вешняков вчера в очередной раз похвалил изменения в закон о выборах и сказал, что теперь законодательство перекрывает многие лазейки для злоупотреблений.
Таким образом, тональность высказывания определяется тремя компонентами: субъектом тональности (кто высказал оценку), объектом тональности (о ком или о чём высказана оценка) и собственно тональной оценкой (как оценили). В наших примерах можно обнаружить такие компоненты тональности:
В одном предложении может высказываться одновременно несколько эмоциональных оценок относительно разных объектов тональности:
(5) Samsung обязали выплатить Apple компенсацию в 290 млн долларов.
Относительно Apple это скорее позитивное событие, чего не скажешь об Samsung.
Так же может быть и разная тональность относительно одного и того же объекта:
(6) Лимонад «Любимый» на основе карамели, так полюбившийся покупателям нашего региона, может провоцировать развитие болезней.
Тут объект «лимонад» упоминается как в позитивном ключе, так и в негативном.
Еще одним направлением сентимент анализа является выявление негативности / позитивности атрибутов объекта тональности (feature-based / aspect-based sentiment analysis), Например,
(7) Еще плюс этого смартфона — индикатор света, что существенно экономит заряд аккумулятора, поддерживает флешки до 8 ГБ, а вот камера совсем слабая.
Здесь объектом тональности является «смартфон», но его тональность складывается из нескольких факторов (индикатор света, аккумулятор, флешка, камера), которые могут иметь разную полярность. Таким образом, здесь задача сводится к выявлению атрибутов продукта (объекта) и определения их тональности. Причем одна и та же качественная характеристика для одного атрибута может быть положительной, и она же для другого атрибута – отрицательной (например, «большой аккумулятор» для телефона – это скорее хорошо, а вот «большой вес» телефона – скорее плохо).
Помимо самой тональности, текст можно оценивать по субъективности / объективности суждения (Opinion Mining). Если это мнение автора высказывания, содержащее субъективную оценку описываемого, то текст считается субъективным. И наоборот, если это сообщение СМИ или мнение, по умолчанию разделяемое участниками диалога, то оно считается объективным.
Например, сообщение из соц.сети:
(8) Пока что я остаюсь при своем — Samsung Galaxy Note 3 — это лучший гаджет, что проходил через мои руки!
имеет субъективную оценку относительно смартфона. А текст из СМИ:
(9) Промсвязьбанк укрепил свои позиции в топ-10 российских банков по портфелю кредитов организациям.
содержит объективную информацию.
К субъективной информации будут относиться прямая и косвенная речь в тексте, а также цитирование (см. примеры 3 и 4). В таких случаях автоматическое определение субъективности / объективности высказывания реализовать технически гораздо проще, нежели в общем случае.
Методы определения тональности
Существует два основных метода решения этой задачи автоматического определения тональности:
- Статистический метод. Для него нужны заранее размеченные по тональности коллекции (корпуса) текстов, на которых происходит обучение модели, с помощью которой и происходит определение тональности текста или фразы.
- Метод, основанный на словарях и правилах. Для этого заранее составляются словари позитивных и негативных слов и выражений. Этот метод может использовать как списки шаблонов, так и правила соединения тональной лексики внутри предложения, основанные на грамматическом и синтаксическом разборе.
Кроме того, иногда используют смешанный метод (комбинацию первого и второго подходов).
При статистическом подходе для решения задачи общей классификации текстов на классы тональности широко используют метод опорных векторов (SVM), Байесовы модели, различного рода регрессии [Chetviorkin & Loukachevitch — описание соревнования ROMIP-2011 по сентимент анализу данных, практически все участники использовали SVM или Байес].
Если же целью является определение тональности у определенного, заранее заданного объекта (нескольких объектов), то применяют более сложные статистические алгоритмы, такие как CRF [Антонова и Соловьев], алгоритмы семантической близости (например, латентно-семантический анализ – LSA, латентное размещение Дирихле — LDA) и др., а также методы, основанные на правилах [Пазельская и Соловьев].
Для определения атрибутивной тональности используют языковые модели [Garcia-Moya & all], нейросети [Tarasov], либо тематические тезаурусы.
Модуль определения тональности SentiFinder
Модуль SentiFinder определяет три вида тональности русскоязычных текстов (позитивную, негативную и нейтральную) относительно заданного объекта тональности как в пределах одного предложения, так и усредненную по всему документу.
Модуль реализован на алгоритме случайных марковских полей с использованием тональных словарей. Это позволило достичь не только хорошего качества (средняя точность по трем видам тональности около 87%.) и высокой скорости обработки текстов (скорость работы модуля SentiFinder более 100 кБ/сек на одном потоке).
Особенностью данного модуля является то, что он позволяет оценить силу эмоциональности. Таким образом, пользователю предоставляется возможность не только получить качественную эмотивную оценку документа в целом относительно интересующего объекта тональности, но и количественное соотношение негативного и позитивного отношения к нему.
Модуль может работать как с «классическими» текстами новостного потока, так и «неклассическим» языком сообщений соц. медиа.
Ознакомиться с данным сервисом можно на сайте eurekaengine.ru
Список литературы
- Bo Pang, Lillian Lee, Shivakumar Vaithyanathan Thumbs up? Sentiment Classification using Machine Learning Techniques // — 2002. — С. 79–86.
- Peter Turney Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews // Proceedings of the Association for Computational Linguistics. — 2002. — С. 417–424. — ar?iv: LG/0212032
- Анна Антонова и Алексей Соловьев, Использование метода условных случайных полей для обработки текстов на русском языке. Компьютерная лингвистика и интеллектуальные технологии: «Диалог-2013». Сб. научных статей / Вып. 12 (19).- М.: Изд-во РГГУ, 2013.– С.27-44.
- Sentiment Analysis Track at ROMIP-2012. Chetviorkin I.I.,Loukachevitch N.V. Компьютерная лингвистика и интеллектуальные технологии. Компьютерная лингвистика и интеллектуальные технологии: «Диалог-2013». Сб. научных статей том 2, с. 40-50.
- Анна Пазельская и Алексей Соловьев, Метод определения эмоций в текстах на русском языке. Компьютерная лингвистика и интеллектуальные технологии. Компьютерная лингвистика и интеллектуальные технологии: «Диалог-2011». Сб. научных статей / Вып. 11 (18).- М.: Изд-во РГГУ, 2011.– С.510-523.
- Tarasov D.S. Deep Recurrent Neural Networks for Multiple Language Aspect-Based Sentiment Analysis // Computational Linguistics and Intellectual Technologies: Proceedings of Annual International Conference “Dialogue-2015”, Issue 14(21), V.2, pp. 65-74 (2015).
- Garcia-Moya, L., Anaya-Sanchez, H., Berlanga-Llavori, R.: Retrieving product features and opinions from customer reviews. IEEE Intelligent Systems 28(3), 19–27 (2013)
Комментарии (7)

VasilyCherny Автор
15.07.2015 12:37Нельзя не согласиться с комментариями – все по делу. Но разговор много шире. Разговор в принципе о новом маркетинге. Если заострить вопрос, то можно считать, что все мнения потребителей надо слушать в соцмедиа. Там резонирует любая, в том числе офлайновая активность, будь то бизнес или политика.
В итоге имея Social Big Data, инструменты автоматизированного анализа и аналитическую платформу для доступа к этим данным, можно решать очень широкий спектр маркетинговых задач – вплоть до анализа рынка/бренда/продукта/ЦА/каналов продвижения и выстраивания коммуникационных стратегий, анализа эффективности реализации выработанной стратегии.
Например, трудно себе представить, как без подобных инструментов будут работать редакции новых медиа. Как быть уверенным, что ты не пропустил никакой зарождающийся тренд? Даже журналистские расследования уже проводятся с использованием подобных инструментов.
Да и сами медийные продукты для конечного пользователя будут построены с использованием подобной технологии.
Применений масса. Попробуйте сами пофантазировать, это действительно интересно )
А я припасу еще один пример, который опишу попозже )
kentastik
А какое коммерческое применение этой штуки? То есть как можно использовать тональность?
AlexanderAnisimov
Насколько я знаю, классическое применение — это сбор фидбэка пользовательской аудитории о каком-нибудь продукте. Грубо говоря, допустим выпустила твоя фирма что-то новое на рынок (автомобиль, книгу, тарифный план и т.п.) а потом можно из твиттера и прочих блогов выковыривать отзывы с упоминанием этого продукта и смотреть какая в среднем по больнице тональность высказываний. Если положительная то можно активно продвигать продукт, развивать его. Если отрицательная, то нужно что-то в нем менять, лишить премии ответственных за продукт и т.п.
Понятно, что в основном это подходит для массовых продуктов — для чебуречной на углу это мало подойдет. И нужно наверно как-то учитывать что пишут в основном про негативный опыт, а позитивом делятся меньше.
OzzyTech
1. Вот здесь презентация с несколькими реальными практическими кейсами, которые невозможны без применения высокоскоростной автоматической тональности:
www.slideshare.net/Taylli01/sociological-research-in-social-media
2. «Эту штуку» (высокоскоростную лингвистику), для европейских языков, IBM недавно купил за $100млн (AlchemyAPI) — без таких систем сейчас практически не двинуться во множестве направлений.
3. Вчера Rambler приобрел 51% RCO (говорят, что за 75млн.р) — компания, которая обладает определенными наработками и клиентами в лингвистическом секторе.
kentastik
Итого для социологов и поисковиков эта штука интересна + корпорации различные, желающие получить отзывы о своем продукте. Интересно как это можно использовать еще, эти варианты в принципе были на поверхности.
OzzyTech
На мой взгляд, неправильная постановка вопроса: «Есть некая фигня, а для чего можно ее использовать?» ;)
Высокоскоростная лингвистика появилась _вследствие_ новых потребностей: выросший в тысячи-миллионы раз потоки неструктурированной информации, требующие обработки и анализа.
Если у Вас таких задач или такой потребности нет, то можно (а может и нужно) изобретать: кто-то придумывает сервисы «только позитивные ролики с YouTube!», «самые позитивные фотки Инстаграм за день!»
А в это время администрации мегаполисов задыхаются от выросшего потока входящей корреспонденции и растет необходимость перенаправить обращения граждан в правильный департамент. Или МЧС с редакциями СМИ не знают что случился «челябинский метеорит», потому как есть только устаревшие технологии «на словарях» NER и невозможно увидеть новую сущность…
VasilyCherny Автор
О, пока писал свой коммент, не увидел очень верные примеры – про городские потребности (сейчас Мэрия Москвы развивает сигнальную информационную систему) и про медиа, о чем сам и упомянул. Так что тут кучность идей налицо )